GenAI(생성 AI) 애플리케이션을 구축하기 위한 언어, 프레임워크, 도구 옵션이 정말 많죠? 이제 막 시작하는 단계라면 이런 결정을 내리고 모든 것을 통합하는 방법을 알아내는 게 부담스러울 수 있어요.
우리 팀은 몇 가지 핵심 기술이 포함된 스타터 키트 프로젝트를 제공해서 이 프로세스를 단순화하려고 사전 패키지된 솔루션을 개발해 왔어요. 그 중 하나가 바로 오늘 포스팅 주제인 Java에서 Spring AI를 사용해서 GenAI 애플리케이션을 구축하는 방법이에요.
Spring AI란 무엇인가요?
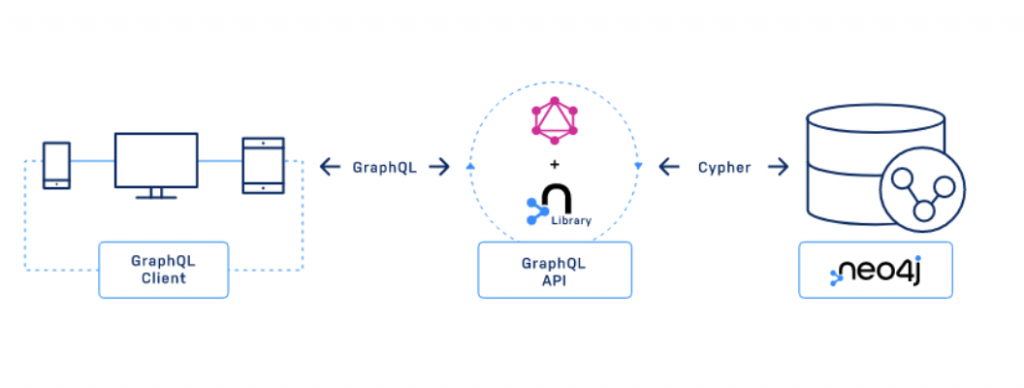
Spring AI는 GenAI 애플리케이션을 구축하기 위한 프레임워크예요. LLM(Large Language Model) 및 RAG(Retrieval-Augmented Generation)와 같은 GenAI 모델 및 아키텍처 작업을 위한 도구와 유틸리티를 제공하죠. Java에는 GenAI를 위한 다른 옵션도 있지만 Spring AI는 다양한 커뮤니티에 걸친 소수의 Neo4j 초기 통합 중 하나랍니다.
이 프로젝트에는 무엇이 포함되어 있나요?
모든 코드와 배경 정보는 spring-ai-starter-kit GitHub 저장소에 있어요. 여기서 일부 코드를 살펴볼 거지만, 언제든지 저장소를 다시 참조할 수 있어요.
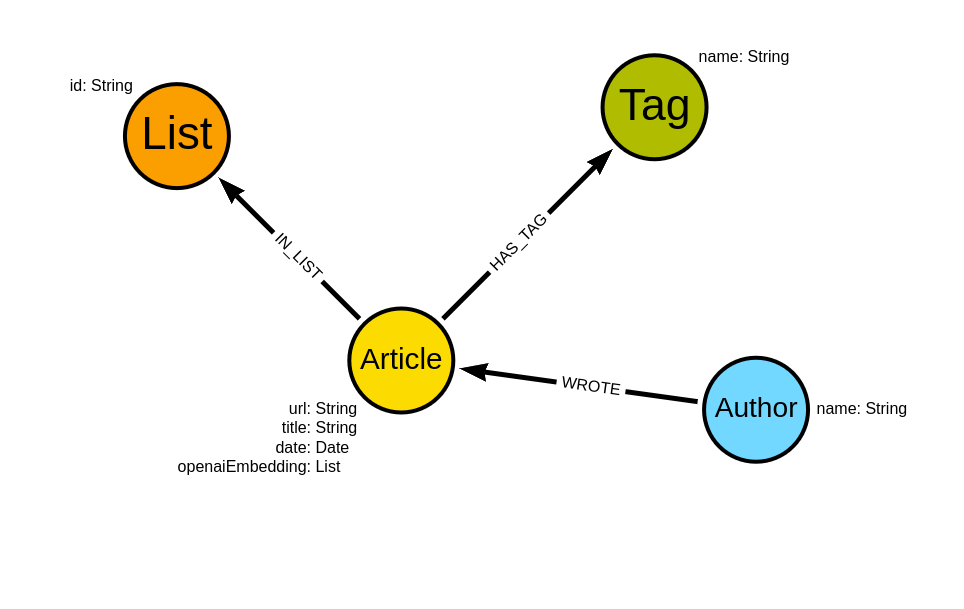
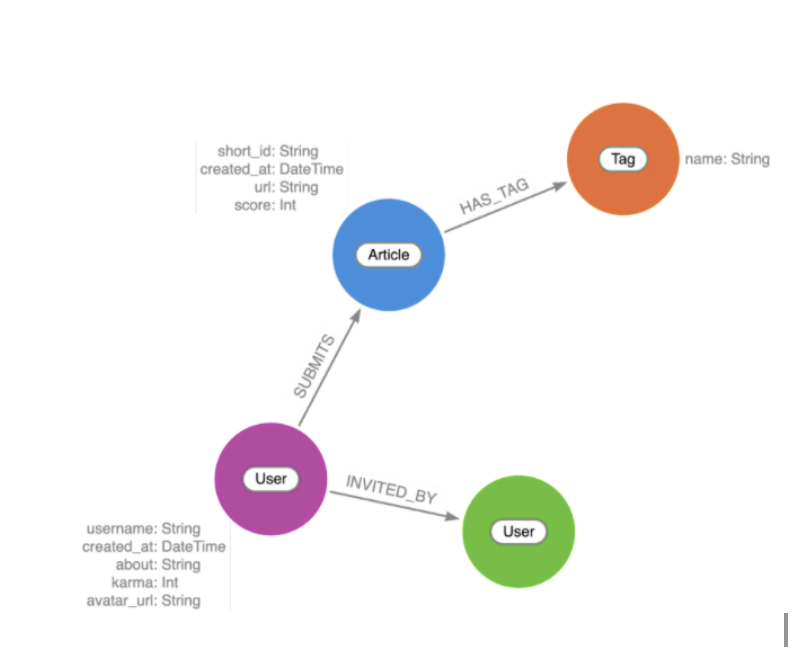
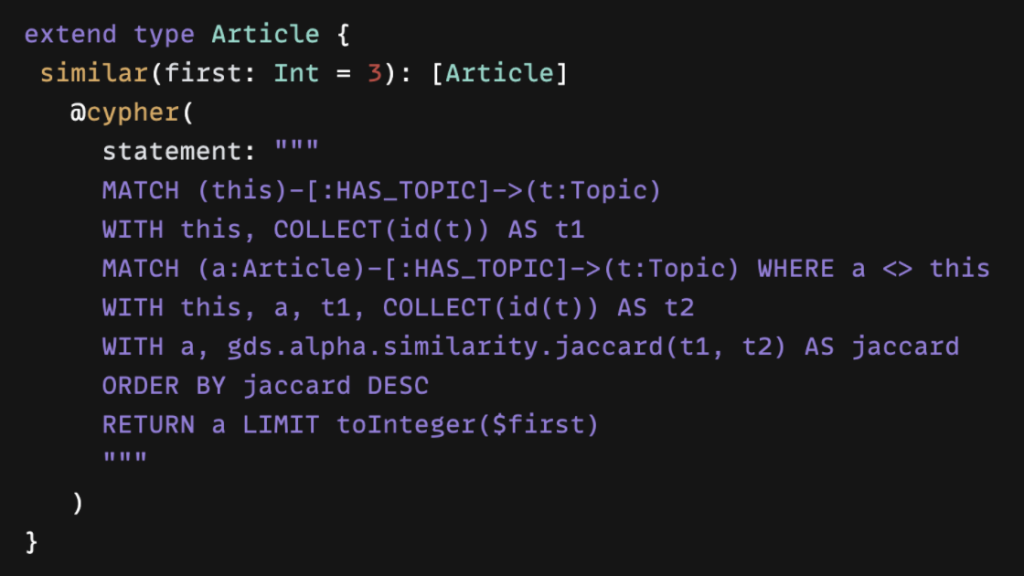
Neo4j를 사용해서 구조화된 데이터(예: entity 및 relationship)는 물론 관련 Vector Embedding이 포함된 구조화되지 않은 텍스트 데이터를 저장해요. 벡터에 대한 유사성 검색을 실행한 다음, 검색 `query`를 실행해서 추가 관련 entity를 가져올 수 있죠. 오늘은 OpenAI 모델을 선택할게요. 하지만 다른 모델로 교체할 수도 있어요. Spring AI 지원 LLM를 참고하세요.
프로젝트의 pom.xml 파일을 살펴보면 이 프로젝트에 포함된 네 가지 종속성을 확인할 수 있어요.
- Spring Web(REST API 생성용)
- OpenAI(또는 Mistral AI, Ollama 등과 같은 기타 LLM 모델)
- Neo4j 벡터 데이터베이스(벡터 저장 및 `query`용)
- Spring Data Neo4j(Spring 애플리케이션에서 Neo4j 작업용)
우리가 사용하는 데이터 세트는 EDGAR에서 제공한 SEC 서류예요. 여기에는 회사 및 개인 서류 제출을 위한 문서 모음이 포함되어 있죠. 문서는 일반 텍스트로 되어 있고, 다양한 회사에 대한 재무 정보가 포함되어 있어요. 우리 팀은 이 데이터를 회사, 재무 형태 및 관리자에 대한 정보가 포함된 Knowledge Graph로 정리했어요. 여기에는 다음이 포함돼요.
- 양식 10-K — 상장 회사가 SEC에 제출해야 하는 연례 보고서. 회사의 재무 성과에 대한 포괄적인 요약을 제공해요.
- 양식 13 — 1억 달러 이상의 자산을 관리하는 기관 관리자가 제출함
스타터 키트 애플리케이션은 기본적으로 공개 데이터베이스에 미리 로드된 데이터 세트 버전을 사용해요. Neo4j Aura 클라우드 데이터베이스 덕분이죠. 덕분에 데이터 가져오기 및 형식 지정으로 인한 번거로움이 사라진답니다. 또는 처음부터 자신만의 Knowledge Graph를 로드하거나, sec-edgar-notebooks 저장소에서 데이터 세트에 대해 자세히 알아볼 수도 있어요.
배경 정보를 살펴보고 코드를 확인해 볼까요?
프로젝트 저장소를 복제한 다음, 즐겨 사용하는 IDE에서 열어보세요. pom.xml 파일을 보면 이전의 네 가지 종속성과 함께 마일스톤 저장소가 포함되어 있음을 알 수 있을 거예요. Spring AI는 아직 일반 출시 버전이 아니기 때문에 마일스톤 저장소가 포함되어 있답니다.
OpenAI의 LLM을 사용하려면 OpenAI에 가입해서 API 키를 요청해야 해요. 해당 데이터베이스(직접 생성한 경우 데이터베이스 포함)가 있다면 application.properties 파일에서 구성을 설정할 수 있어요. 다음은 그 예시입니다.
spring.ai.openai.api-key=<YOUR API KEY HERE>
spring.neo4j.uri=neo4j+s://9fcf58c6.databases.neo4j.io
spring.neo4j.authentication.username=public
spring.neo4j.authentication.password=read_only
spring.data.neo4j.database=neo4j데이터베이스 자격 증명은 미리 로드된 기본 인스턴스에 대한 것이에요. 따라서 자체 데이터베이스를 사용하는 경우 .uri, .username 및 .password 속성을 해당 속성과 일치하도록 업데이트해야 합니다.
애플리케이션의 코드를 한번 검토해 볼까요?
Vector Embedding 및 벡터 저장소 설정
SpringAiApplication 클래스에서는 OpenAI 클라이언트용 Spring Bean 두 개와 애플리케이션에서 필요할 때마다 필요한 구성 요소에 액세스할 수 있는 Neo4j 벡터 저장소를 설정해야 해요.
@Bean
public EmbeddingClient embeddingClient() {
return new OpenAiEmbeddingClient(new OpenAiApi(System.getenv("SPRING_AI_OPENAI_API_KEY")));
}
@Bean
public Neo4jVectorStore vectorStore(Driver driver, EmbeddingClient embeddingClient) {
return new Neo4jVectorStore(driver, embeddingClient,
Neo4jVectorStore.Neo4jVectorStoreConfig.builder()
.withIndexName("form_10k_chunks")
.withLabel("Chunk")
.withEmbeddingProperty("textEmbedding")
.build());
}EmbeddingClient 빈은 OpenAI API용 클라이언트를 생성하고 속성 파일에서 API 키를 전달해요. 그런 다음 Neo4jVectorStore 빈은 Neo4j를 임베딩(벡터)용 저장소로 구성하죠. 이는 데이터베이스 자격 증명과 내장 클라이언트에서 자동 구성된 Driver를 가져와요. 벡터 Index 이름(Spring AI 기본값은 spring-ai-document-index), 임베딩을 저장할 Node의 Label(기본값은 Document 엔터티 검색), 임베딩을 포함하는 Property 이름을 지정하려면 벡터 저장소 구성을 사용자 정의해야 해요.
애플리케이션 모델
다음으로 애플리케이션 엔터티를 데이터베이스 모델에 매핑하는 몇 가지 표준 도메인 클래스가 있어요. Document Chunk Node를 나타내는 Chunk 클래스와 데이터베이스의 해당 엔터티를 나타내는 Form, Company 및 Manager에 대한 클래스도 있죠. Chunk 엔터티에는 유사성 검색에 사용할 임베딩(벡터)이 연결되어 있답니다.
이러한 엔터티는 표준 Spring Data Neo4j 코드이므로 여기에 코드를 표시하지는 않을게요. 하지만 각 클래스의 전체 코드는 프로젝트의 GitHub 저장소에서 확인할 수 있어요.
프로젝트의 저장소 인터페이스는 애플리케이션이 데이터베이스와 상호 작용할 수 있도록 도와줘요. 유사한 Chunk에 대한 관련 엔터티(Form, Company, Manager)를 찾는 정의된 Query 방법이 하나 있답니다.
다음으로 컨트롤러 클래스는 사용자 요청을 처리하고 응답을 생성하기 위해 모든 부분이 함께 모이는 곳이에요. 이 클래스에는 사용자로부터 질문을 받고 Neo4jVectorStore를 호출하여 가장 유사한 문서를 계산하고 반환하는 로직이 포함되어 있죠. 그런 다음 유사한 Chunk를 Neo4j Query에 전달해서 연결된 엔터티를 검색하고 LLM 프롬프트에 추가 컨텍스트를 제공할 수 있어요. 제공된 모든 정보를 사용해서 더욱 정확하게 답변하는 거죠.
제어 장치
컨트롤러 클래스는 유사성 검색을 실행하고, LLM을 호출하고, 데이터베이스를 Query하기 위해 Neo4jVectorStore 빈, OpenAiChatClient 빈 및 ChunkRepository 인터페이스를 삽입해야 해요.
@RestController
@RequestMapping("/api")
public class ChunkController {
private final OpenAiChatClient client;
private final Neo4jVectorStore vectorStore;
private final ChunkRepository repo;
@GetMapping("/chat")
String getGeneratedResponse(@RequestParam String question) {
List<Document> results = vectorStore.similaritySearch(SearchRequest.query(question));
List<Chunk> docList = repo.getRelatedEntitiesForSimilarChunks(results.stream()
.map(Document::getId)
.collect(Collectors.toList()));
var template = new PromptTemplate("""
You are a helpful question-answering agent. Your task is to analyze
and synthesize information from the top result from a similarity search
and relevant data from a graph database.
Given the user's query: {question}, provide a meaningful and efficient answer based
on the insights derived from the following data:
{graph_result}
""",
Map.of("question", question,
"graph_result", docList.stream().map(chunk -> chunk.toString()).collect(Collectors.joining("n"))));
System.out.println(" - - - PROMPT - - -");
System.out.println(template.render());
return client.call(template.create().getContents());
}
}마지막 부분은 사용자가 /chat 엔드포인트에 GET 요청을 보낼 때 호출되는 메서드를 정의하는 부분이에요. 이 메서드는 질문을 query 파라미터로 받아서, vectorStore의 similaritySearch() 메서드에 전달해서 유사한 문서 덩어리(chunks)를 찾죠.
Spring AI는 일반적인 Document 타입을 예상하기 때문에, 유사한 Chunk 노드가 Document 엔티티에 매핑돼요. Neo4jVectorStore 클래스에는 Document를 사용자 정의 레코드로 변환하는 메서드와, 반대로 레코드를 Document로 변환하는 메서드가 포함되어 있답니다.
컨트롤러 메서드로 다시 돌아와서, 이제 유사한 문서 청크가 있지만, 텍스트 청크만으로는 유용한 답변을 제공하기에 충분한 정보가 없을 수도 있어요. 이제 Neo4j에서 query를 실행해서 해당 청크와 관련된 양식, 회사, 관리자를 검색해야 해요. 바로 이 부분이 애플리케이션의 Retrieval-Augmented Generation (RAG) 부분이에요.
유사성 검색이 유사한 문서 청크를 반환한 후, 저장소의 getRelatedEntitiesForSimilarChunks() 메서드를 호출해서 (유사한 문서 ID 목록을 전달해서) 해당 청크에 대한 관련 항목을 찾아요.
다음 코드 블록은 관련 엔터티가 포함된 사용자의 질문과 그래프 결과를 함께 Large Language Model (LLM)으로 보낼 텍스트가 포함된 프롬프트 템플릿이에요. 마지막으로 템플릿의 create() 메서드를 호출해서 LLM에서 응답을 생성하고 응답 문자열에 대한 content 키를 반환하죠.
한번 시험해 볼까요!
애플리케이션 실행
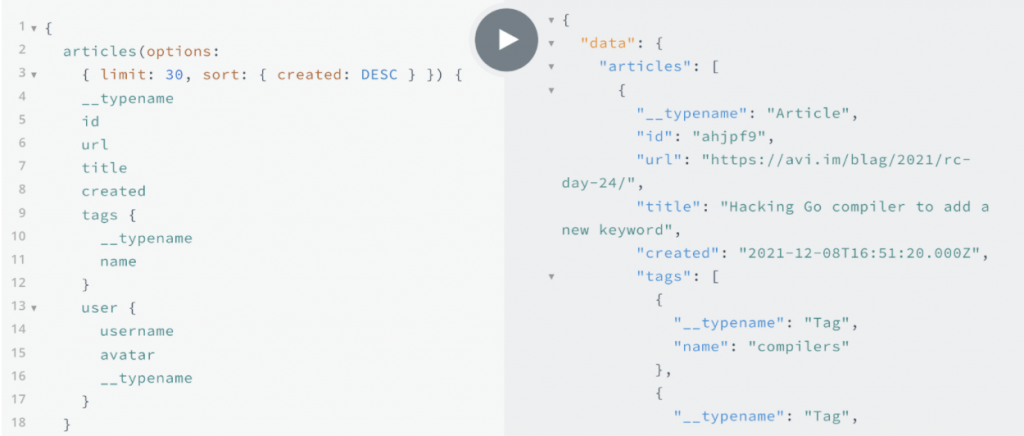
스타터 키트 애플리케이션을 실행하려면 터미널에서 ./mvnw spring-boot:run 명령을 사용하면 돼요. 애플리케이션이 실행되면 EDGAR 데이터에 대한 질문을 query 파라미터로 사용해서 /api/chat 엔드포인트에 GET 요청을 보낼 수 있어요. 몇 가지 예시를 보여드릴게요.
curl "http://localhost:8080/api/chat?question=How%20many%20forms%20are%20there%3F"
curl "http://localhost:8080/api/chat?question=Which%20companies%20are%20in%20healthcare%3F"
curl "http://localhost:8080/api/chat?question=Which%20managers%20own%20stock%20in%20more%20than%20one%20company%3F"SEC 관련 질문을 자유롭게 던져보거나, 애플리케이션이나 코드를 조정해서 어떻게 반응하는지 확인해보세요. 콘솔 출력을 확인해서 애플리케이션과 LLM 간에 데이터가 잘 주고받는지 확인할 수도 있답니다.
마무리
이번 포스팅에서는 Java로 GenAI 애플리케이션 구축을 시작하는 데 도움이 되는 Spring AI Neo4j 스타터 키트를 살펴봤어요. Spring AI를 사용해서 이미 잘 구축된 Spring 생태계의 풍부함을 확장해서 JVM 언어(이번 포스팅에서는 Java)로 GenAI 앱을 작성할 수 있었죠.
Spring AI는 다양한 LLM 모델과 Vector Store를 지원하지만, 저희는 OpenAI 모델과 Neo4j 데이터베이스를 선택했어요. Neo4j는 구조화되지 않은 텍스트 데이터 및 Vector Embedding과 함께 관계 및 표준 구조화된 데이터를 저장하는 기능을 제공하거든요. OpenAI 모델을 사용해서 데이터베이스의 유사성 검색 결과 및 관련 엔터티를 기반으로 사용자 질문에 대한 응답을 생성했답니다.
이 포스팅이 GenAI와 그 이상을 시작하는 데 도움이 되었기를 바라요! 즐거운 코딩 되세요!
자원
- 코드(GitHub 저장소):Spring AI 스타터 키트
- 무료 온라인 강좌:GraphAcademy를 통해 Neo4j 및 LLM에 대해 알아보세요
- 선적 서류 비치:스프링 AI
- 웹페이지:Spring AI 프로젝트
- java
- rag
- spring
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'GraphRAG' 카테고리의 다른 글
| Neo4j와 LangChain으로 구현하는 '로컬에서 글로벌로' GraphRAG: 그래프 구축하기 (0) | 2026.05.03 |
|---|---|
| Neo4j GraphRAG Python 패키지 시작하기: 초보자 가이드 (0) | 2026.05.03 |
| 단 4줄 코드로 만드는 GenAI 기반 노래 찾기: Neo4j와 GraphRAG 활용 (0) | 2026.05.02 |
| GenAI 그래프 수집 2.0: GraphRAG의 진화 (0) | 2026.05.02 |
| 클라우드에서 완성하는 풀 스택 그래프: Neo4j로 GraphRAG 마스터하기 (0) | 2026.05.01 |















.](https://dist.neo4j.com/wp-content/uploads/20230608064931/1LTfNOqZQB_M42KyvttjSyw.png)
.](https://dist.neo4j.com/wp-content/uploads/20230608064925/1zydD2GKzjpEyvL-d_cP0vA.png)