TL;DR — 접근 방식이 이전과는 다르고, 훨씬 쉽고 더 좋아졌다는 사실! 결과는 쉽게 확장될 수 있다는 점도 매력적이죠.
2019년에 저는 체험형 그래프 플랫폼 개발을 주도했는데요. 솔루션 구성, 아이디어/POC 유사성, 그리고 연례 보고서처럼 텍스트가 많은 문서에 대한 분석 등 그래프 모델링이 잠재력을 보여줄 수 있는 다양한 영역을 탐색했었어요. 당시 NLP 분석은 Azure Cognitive Services API를 활용했고, 저희 팀은 논문에서 주요 주제와 트렌드를 파악하는 분석 기능을 구현했죠. 또한 플랫폼 내 다른 모듈의 잠재적 솔루션과 결과를 매칭하는 기능까지 갖춘 멋진 솔루션을 개발했답니다. 당시 주요 접근 방식은 에 자세히 문서화되어 있어요.
그때는 그랬죠. 하지만 지금은 달라요!
Large Language Model(LLM)을 사용할 수 있게 되면서, 구조화되지 않은 텍스트를 분석하는 것은 물론이고, 결과를 Graph Database에 넣기 위한 코드까지 생성할 수 있게 되었잖아요. 이제 코딩을 거의 하지 않는 사람도 화이트보드에 스케치만 하면, 2019년에 저희 팀이 구현했던 NLP 솔루션을 다시 만들 수 있을까요?
우선, Kristof Neys에게 감사를 표하고 싶어요. 이 모든 것의 토대가 된 훌륭한 Colab 노트북을 공유해줬거든요. Kristof의 노트북은 환자 의료 기록에서 Graph Database를 읽고 생성하는 과정을 담고 있어요. 검토에 필요한 모든 백엔드 단계를 처리해줘서, 제가 원래 생각했던 비즈니스 과제에 집중할 수 있었죠. Kristof의 도움이 없었다면 시작조차 못했을 거예요.
바로 그거에요! 우리는 수년 동안 '데이터의 민주화'에 대해 이야기해 왔지만, 지금처럼 피부로 와닿았던 적은 없었던 것 같아요. 구현 기술의 복잡성에 시간을 쏟지 않고, 문제 자체에 집중해서 제 역량을 발휘할 수 있었으니까요.
제 좋은 친구이자 코치인 Peter Beijer 박사는 제가 소프트웨어 엔지니어에서 솔루션 아키텍트로 커리어를 전환하던 2000년대 초반에 솔루션 아키텍처의 원칙을 가르쳐줬어요. 그때 그가 해준 조언은 제 커리어를 완전히 바꿔놓았죠. 특히 솔루션을 비즈니스, 기능, 기술, 구현이라는 4개의 계층으로 나눌 수 있다는 원칙은 제가 거의 매일 적용하는 핵심적인 부분이에요. 솔루션 설계자로서의 경험과 현재 고객 성공 부서에서 일하면서 얻은 강점은, 기술 계층을 이해하고 다룰 수 있다는 점이죠. 물론, 확장성 좋고 성능 뛰어난 클라우드 아키텍처를 구현해달라고 하시면 곤란해요!
본격적으로 시작하기
기술적인 준비가 약간 필요했지만, 설정하는 과정이 고통스럽거나 하진 않았어요. OpenAI API 키를 설정하고, Neo4j AuraDB 인스턴스를 프로비저닝하는 정도였으니까요. 이걸 마치고 나니, Kristof의 노트북을 따라 하면서 샘플 Database를 만들 수 있는지 확인해볼 수 있었어요.
제 관심사는요.
저는 제 도전의 기반을 가치 있는 것에 두고 싶었어요. 판매와 성공의 핵심은 솔루션이 고객의 요구와 목표를 어떻게 충족하는지 이해하는 것이죠. 그러면 이걸 어디서 배울 수 있을까요? 이러한 정보에 대한 가장 신뢰할 수 있는 출처는 조직에서 발행하는 연례 보고서와 전략 문서인 경우가 많아요.
하지만 중요한 건, LLM(Large Language Model)은 허공에서 의미 있는 통찰력을 생성하지 않는다는 점이에요. 문제를 해결하려면 논리적인 접근 방식이 있어야 해요. 먼저, 해당 문서의 내용을 이해하고 목표를 정의해야 하죠. 연간 보고서에는 풍부한 데이터가 포함되어 있는데, 추출하려는 구체적인 정보는 무엇인가요? 재무제표, 인수 합병 세부 정보, 시장 동향, 산업 방향, 법적 측면, 위험 또는 외부 요인인가요? 이 단일 자산에서 얻을 수 있는 통찰력의 잠재력은 엄청나기 때문에 LLM이 검색해야 하는 것이 무엇인지 명확하게 정의하는 것이 중요해요.
둘째, 다음 단계는 그래프 모델을 설계하는 거예요. 문서에서 추출하려는 내용을 이해한 후에는 초기 그래프 모델 제작을 시작할 수 있죠. 제 초기 모델은 상당히 단순했어요…
arrows.app을 사용하여 생성된 연례 보고서의 잠재적인 Graph Data Model 개요
프롬프트
이게 2019년 접근 방식과 흥미롭고 다른 점이에요. 2019년에는 Natural Language Processing API가 모든 작업을 수행하도록 했어요. 우리는 여기에 텍스트 블록을 전달하고 결과로 entity와 category를 가져왔죠. LLM 접근 방식을 사용하면 제가 관심 있는 내용을 더 자세히 분석할 수 있었어요. Prompt를 사용하여 문제의 틀을 잡기 시작했죠. 이러한 Prompt는 비즈니스 상황에 맞게 조정되었으며 문서의 세부 구조를 설명할 필요가 없었어요. 대신 비즈니스 동향, 기술 동향, 주요 개인 등 모델이 중점을 두어야 할 사항을 설명했죠. 이러한 변화는 문서의 복잡성을 자세히 조사하지 않고도 귀중한 통찰력을 효율적으로 추출할 수 있음을 의미하며 프로세스를 더욱 민첩하게 만들고 특정 비즈니스 목표에 부합하게 만들었어요.
다음은 label 정의의 일부 예시예요.
label:'TechnologyTrend' name:string,name:string //any known technology term within the text,summary:string //Summary of the trend as defined by openAI;'name' property is the name of the technology trend, in lowercase & camel-case & should always start with an alphabet; summary is a description as defined within openai
label:'Risk' name:string,summary:string //any known factor which might present a risk to the organisation, summary:string //Summary of the trend as defined by openAI;'name' property is the name of the risk, in lowercase & camel-case & should always start with an alphabet; summary is a description as defined within openai
그래프 내에 생성될 각 label 또는 Node는 해당 name, 필수 property 값, 그리고 이러한 값을 식별하기 위해 LLM이 고려해야 할 사항에 대한 세부 정보로 설명돼요. 또한 OpenAI LLM 내에 정의된 일반 설명을 저장하기 위해 요약 property를 추가했어요.
Relationship도 비슷한 방식으로 설명돼요. 여기에는 텍스트 내에서 특정 항목이 언급된 횟수를 기록하는 counter 값도 포함했죠.
paper|MENTIONS_BUSINESSTREND{countof:sting}|businesstrend //the properties inside MENTIONS_BUSINESSTREND gets populated from the text and is a count of the number of times the trend is mentioned
결과
초기 결과에는 2019년 프로젝트 범위, 알려진 비즈니스 및 기술 동향에 해당하는 entity만 포함하기로 결정했어요. 생성된 데이터 측면에서는 2019년에 달성한 결과와 매우 유사했죠. 하지만 한 가지 주목할 만한 이점이 있었어요. Prompt를 간단히 수정하여 데이터 모델을 빠르게 반복할 수 있다는 것이죠.
신속한 수정을 통해 빠르게 모델을 개선하는 능력은 정말 획기적이에요. 이를 통해 출력을 Fine-tuning하는 데 더욱 동적이고 반응성이 뛰어난 접근 방식이 가능하므로 놀라운 속도로 결과를 조정하고 개선할 수 있죠. 이 반복적인 프로세스는 2019년 프로젝트의 범위를 유지했을 뿐만 아니라 데이터 추출에 새로운 유연성과 효율성을 도입했어요.
물론 제가 사전에 알고 있는 항목이나 category에만 결과를 제한하는 위험이 있어요. 이 문제는 Prompt 정의에 "catch all" label을 추가하여 해결되었죠.
label:'EoI' id:string,name:string, summary:string //any other entity within the text which is of potential interest //Summary is the general description of the entity as defined within OpenAI
샘플 결과 세트분류되지 않은 관심 항목만 보여주는 샘플 데이터 세트 — Neo4j Bloom의 시각화
제가 개발한 최종 데이터 모델은 초기 스케치를 훨씬 뛰어넘었어요. 그 결과 일련의 연례 보고서를 통해 철저하게 분석할 수 있는 보다 포괄적인 entity 집합이 탄생했죠. 데이터 모델의 발전으로 이러한 보고서에 포함된 정보를 더욱 깊고 세밀하게 이해할 수 있게 되었고, 이를 통해 데이터에서 도출할 수 있는 통찰력의 품질과 깊이가 향상되었어요.
"EntityOfInterest"라는 포괄적인 label을 포함한 최종 데이터 모델제가 개발한 모델과 프롬프트를 기반으로 한 샘플 데이터 세트
이것을 프로덕션에 적용
위의 노트북과 프로토타입은 LLM을 사용하여 주요 엔터티를 추출하고 Knowledge Graph를 생성하는 것의 높은 가치를 보여주죠. 이러한 접근 방식을 프로덕션에 적용하려면 2019년에 채택한 것과 동일한 방법을 적용해야 해요.
청킹(Chunking):
Azure NLP API에는 단일 호출 내에서 처리할 텍스트 길이에 대한 제한이 있고, LLM API에도 마찬가지로 적용돼요. API에는 7,500자 제한이 있으므로 문장 중간에 텍스트가 분할되어 컨텍스트가 손실되지 않도록 텍스트가 분할되는 위치를 고려해야 하죠.
API 비용: API를 호출할 때마다 비용이 발생해요. 2019년에는 이 문제를 해결하기 위해 각 텍스트 청크에 대한 MD5 값을 수집 및 저장하고 새 청크만 API로 보냈어요. 일치하는 텍스트 청크를 위해 기존 그래프를 검색했죠. API 호출을 강제하는 옵션을 사용하여 이 접근 방식을 여기에 적용해서 Prompt Engineering 정의에 대한 업데이트를 적용하고 LLM 자체 내 업데이트를 활용할 수도 있어요.
사용자가 문서를 설명하고 PDF 문서 세트를 끌어서 놓을 수 있는 잠재적인 경량 범용 애플리케이션을 구상할 수 있어요. 이러한 문서는 LLM에 의해 분류 및 분석되며 결과는 그래프 시각화로 표시되죠.하지만 이는 실제로 코딩할 수 있는 사람을 위한 거예요.
노트북 사본을 에서 사용할 수 있어요
참고 자료
Knowledge Graph 및 LLM: Neo4j로 Large Language Model 활용(오스카 헤인)
nlp
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
정부 분석의 핵심은 간단해요. 데이터에 대해 질문하고, 답변을 통해 배우고, 또 새로운 질문을 던지는 거죠. 호기심이 분석 과정을 이끌고, 모든 답변은 자연스럽게 더 깊은 질문으로 이어져야 해요.
저는 분석적 사고가 끊임없이 이어지는 상태를 라고 부르고 싶어요. 이는 훈련된 분석가가 제한이나 지연 없이 데이터를 자유롭게 사용할 때 경험하는 정신적인 명확성을 설명하는 말이죠. 이 상태에서 분석가는 질문에 집중력을 잃지 않고, 한 질문 수준에서 다음 수준으로 자연스럽게 넘어갈 수 있어요.
질문을 던지는 것은 리더가 문제를 새로운 시각으로 바라보고, 다른 방법으로는 얻을 수 없는 관점을 발견하도록 도와줘요. 탐구 과정은 활력을 불어넣지만, 방해 요소 때문에 추진력과 영감이 금세 깨질 수도 있죠.
깊은 사고는 취약하다
복잡한 문제 해결을 유지하는 건 생각보다 쉽지 않아요. 사람들은 장기간의 추론에 익숙하지 않거든요. 실제로 행동 과학에서는 깊은 사고가 쉽게 무너진다는 것을 보여주고 있어요.
Daniel Kahneman은 그의 대표적인 저서 “Thinking, Fast and Slow”에서 의사 결정을 안내하는 두 가지 사고 모드를 설명해요. 하나는 빠르고 자동적이며 본능과 친숙한 패턴에 의존하는 방식이죠. 하지만 더 복잡한 결정에는 더 느리고 신중한 사고가 필요해요.
정부 분석가의 업무는 거의 전적으로 신중한 사고로 이루어지지만, Kahneman은 이 모드가 지속적인 관심과 정신적 에너지를 필요로 하기 때문에 본질적으로 취약하다고 설명해요. 이는 "최소 노력의 법칙"에 따라 작동하는데, 뇌는 자연스럽게 인지적 부담을 최소화하려고 노력하고, 가능하면 빠르고 직관적인 사고로 돌아가려고 하죠.
기술이 분석 흐름을 방해하고 있어요
수십 년 동안 분석가들은 지연, 데이터 연결 끊김, 흐름을 방해하는 시스템 등 여러 장벽에 부딪혀 왔어요. 이런 일이 생기면 귀중한 통찰력을 얻지 못하고 영감이 사라지게 되죠.
저는 1990년대 초반부터 데이터 웨어하우징 분야에 몸담아 왔는데요. 제가 했던 가장 보람 있는 일 중 하나는 정부가 복잡한 데이터 문제를 해결하도록 돕는 거였어요. 하지만 항상 아쉬움이 남았죠. 데이터 문제가 성공적으로 해결되더라도 분석의 완전한 가능성은 여전히 닿을 수 없는 곳에 있는 것처럼 느껴졌거든요.
문제는 분석가가 아니었어요. 바로 기술이었죠. 이벤트, 통찰력, 행동 사이의 격차를 줄이는 것이 기술의 약속이었지만, 실제로는 기술이 격차를 만들고 더 크게 만들었던 거예요.
비즈니스 인텔리전스 시스템은 분석가를 엄격한 워크플로우에 가두었어요. 데이터는 사일로에 갇혀 있었고, 쿼리에는 테이블 전체에 걸쳐 복잡한 `join`이 필요했죠. 새로운 질문을 할 때마다 더 많은 코드를 작성하고, 결과를 기다리고, 데이터가 행과 열로 변환될 때 사라진 관계를 재구성해야 했어요. 그 결과 의도치 않은 설계로 인해 끊임없는 중단이 발생했죠.
Graph가 판도를 어떻게 바꿀까요?
Graph는 데이터를 바라보는 관점을 바꿔요. Graph 모델은 엔터티와 관계(사람, 장치, 계정, 위치, 이벤트)를 통해 각각의 새로운 신호가 살아있는 네트워크에 도달하여 "누가/무엇을/언제/어디서/어떻게" 연결되었는지에 대한 컨텍스트를 즉시 제공하죠. 이를 통해 기관은 결정이 서비스, 시스템 및 이해 관계자 전체에 어떤 영향을 미치는지 파악할 수 있어요.
그 결과 임무 결과를 더욱 완벽하게 볼 수 있게 돼요. 분석가는 여러 프로그램에서 문제를 추적하고, 위험을 조기에 식별하고, 프로그램의 한 부분의 변경 사항이 결과에 어떤 영향을 미치는지 확인할 수 있죠. 분석가는 단절된 도구에서 통찰력을 모으는 대신 연결된 단일 프레임워크를 통해 기관의 전체 프로그램 환경을 탐색할 수 있어요.
AI 시대에 대한 자신감
AI를 사용하면 리더가 데이터에 대해 더 쉽게 질문하고 몇 초 만에 답변을 받을 수 있지만, 환각(hallucination) 현상은 심각한 위험을 초래할 수 있어요. 이러한 답변은 자신감 있게 들리지만, 공공 안전, 국가 안보, 그리고 수십억 달러의 공공 자금에 영향을 미치는 결정을 위태롭게 하는 오류나 조작된 세부 정보가 포함될 수 있죠.
대부분의 AI 모델은 신뢰할 수 있는 데이터에 대해 직접 사실을 확인하는 대신 언어 패턴을 기반으로 답변을 생성해요. Knowledge Graph는 AI가 경로, 커뮤니티, 시간적 변화 등 관계 패턴을 추론하여 사기, 사이버 보안, 인텔리전스, 공급망과 같은 영역에 대한 심층 분석을 가능하게 함으로써 이 문제를 해결하죠.
Graph `쿼리`는 정확한 하위 그래프를 AI 모델로 검색하여 사실성을 높이고, 환각을 크게 줄이고, 밀리초 단위로 더 깊은 멀티홉 "이유" 설명을 가능하게 해줘요.
이를 통해 신뢰, 설명 가능성, 거버넌스가 최우선 순위로 높아지죠. 에이전트와 애플리케이션은 현재 재고 수준, 복잡한 프로그램을 탐색할 때 시민을 가장 잘 지원하는 방법, 특정 사이버 보안 위험과 같은 정확한 운영 질문에 답할 수 있게 되는 거예요.
Knowledge Graph와 AI가 함께 분석 연속체를 유지하는 거죠. 분석가(및 최종 사용자)는 방해를 받거나 더 기술적인 작업을 수행하도록 강요받지 않고, 한 질문에서 다음 질문으로 유연하게 이동할 수 있어요. 그리고 결정은 명시적인 `node`, `edge`, 그리고 타임스탬프를 기반으로 하기 때문에 AI가 따른 경로와 기록을 표시하여 권장 사항이 만들어진 "이유"를 추적할 수 있죠. 이는 규제 및 임무 환경에 매우 중요해요.
여러 기관에서 이미 그래프를 활용해 프로그램을 혁신하고 있어요. 정보 및 국방 기관에서는 그래프를 사용해서 대규모 데이터 세트 안에 숨겨진 네트워크를 찾아내고, 위협 행위자, 불법 금융 흐름, 운영 패턴 등을 식별하죠. 사이버 보안 팀은 취약점과 공격 경로를 파악하기 위해 네트워크 종속성을 모델링하고요. 또, 물류 조직은 위험을 분석하고 글로벌 운영을 최적화하기 위해 디지털 트윈을 만들기도 합니다.
그래프를 통해 기술은 추론의 든든한 파트너가 될 수 있어요. 정확한 맥락을 제공하고, 관련 연결을 보여주고, 분석가가 복잡한 정부 과제를 해결하는 데 필요한 심층적인 사고를 할 수 있도록 도와주죠.
그래프 기반의 인지 에이전트 AI 솔루션을 통해 기관은 높은 컨텍스트와 낮은 대기 시간으로 상호 작용하며 분석 연속성을 확보할 수 있습니다.
임무 결과 가속화
정부 기관이 어떻게 고립된 데이터를 신뢰할 수 있는 통찰력으로 바꾸는지 궁금하신가요? 저희 가이드에서는 그래프가 레거시 시스템을 현대화하고, 효율성을 높이고, 위협을 더 빠르게 찾아내는 방법을 알려드려요.
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
2020년 3월, Java 14가 출시되면서 `java.lang.Record`라는 `Record` 키워드가 처음 등장했어요. () `Record` 클래스는 특별한 종류의 클래스인데, 일반적인 클래스보다 더 간단한 형식으로 일반 데이터 집계를 모델링하는 데 도움을 줘요. 쉽게 말해 이라고 생각하면 될 것 같아요. 그 이후로 `Record`에는 많은 기능이 추가되었고, 앞으로도 계속 추가될 예정이에요.
사진 제공:믹 하웁트 on 언스플래시
그런데 "Record"는 Tuple과 거의 같은 의미로 쓰이잖아요? 그래서 다른 곳, 특히 데이터베이스 연결에서 널리 사용되고 있어요. jOOQ 같은 관계형 데이터베이스 추상화에서도 records를 다루고, Neo4j-Drivers, 특히 Java 드라이버에서도 마찬가지예요. 오랫동안 저희는 org.neo4j.driver.Record를 사용해서 튜플이나 행을 나타내고, 더 큰 쿼리 결과 집합을 만들었답니다.
Java 14 이전에는 이게 문제가 되지 않았어요. 하지만 Java 14에서 `java.lang.Record`가 등장했고, `java.lang` 패키지에 있기 때문에 실제 record를 뒷받침하는 클래스를 사용할 가능성이 거의 없더라도 항상 Java 프로그램으로 가져오게 되죠. IntelliJ를 비롯한 대부분의 IDE는 요즘 JDK 17에 이미 record 유형이 있기 때문에 import를 제안하지 않아요. 또한 `org.neo4j.driver.*`와 같은 star-imports는 컴파일 중에 `java: Record`에 대한 참조가 모호하다는 오류를 발생시켜요. org.neo4j.driver의 인터페이스 `org.neo4j.driver.Record`와 java.lang의 클래스 `java.lang.Record`가 충돌하는 거죠.
결과 셋을 처리하고 싶지만 해당 항목에 접근할 수 없는 난감한 상황에 놓이거나, 아니면 위에서 언급한 컴파일 오류가 발생할 수도 있어요. Neo4j-Java-Driver 사용자라면 "잘못된" record 유형을 범위로 가져오게 될 수도 있는 거죠.
과거에는 이런 일이 흔하지 않았지만, 새로운 Neo4j-Java-Driver 5.0 이상을 사용하면서 최신 Java LTS 릴리스 버전 17에 대한 요구 사항을 충족하게 되면서 이런 문제가 발생하기 시작했어요. 이건 Java 드라이버나 코드의 버그는 아니고요, 해당 라이브러리 제공자로서 저희가 알려드려야 할 부분이에요. 이 문제에 대해 저희만 고민하는 건 아니고요, 다른 분들도 변경하는 대신 알리는 쪽을 선택했답니다. (그들의 record 구현을요.)
내용을 설명하는 실제 예시를 보여드릴게요.
그리고 별표(*) 또는 와일드카드 import는 사용하지 않는 게 좋아요!
즐거운 코딩 되세요!
driver
java
java17
JDK
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
LangGraph 에이전트를 사용해서 법률 정보를 Knowledge Graph로 구성하고 답변 정확도를 높여봐요.
모든 비즈니스에서 법적 계약은 당사자 간의 관계, 의무, 책임을 정의하는 기본 문서죠. 파트너십 계약, NDA, 공급업체 계약 등 이러한 문서에는 의사 결정, 위험 관리, 규정 준수를 추진하는 중요한 정보가 담겨 있을 때가 많아요. 하지만 이런 계약에서 통찰력을 탐색하고 추출하는 건 복잡하고 시간이 꽤 걸릴 수 있어요.
이번 포스팅에서는 에이전트 GraphRAG를 사용해서 엔드투엔드 솔루션을 구현하고, 법적 계약을 이해하고 작업하는 프로세스를 간소화하는 방법을 알아볼 거예요. 저는 GraphRAG를 저장소에 저장된 정보를 검색하거나 추론하는 모든 방법을 가리키는 포괄적인 용어라고 생각하는데요. 특히 Knowledge Graph는 더욱 체계적이고 상황에 맞는 응답을 가능하게 해주죠.
Neo4j의 Knowledge Graph로 법적 계약을 구조화하면 쿼리하고 분석하기 쉬운 강력한 정보 저장소를 만들 수 있어요. 여기서 사용자가 계약에 대해 구체적인 질문을 할 수 있는 LangGraph 에이전트를 구축해서 새로운 통찰력을 빠르게 발견할 수 있도록 하는 거죠.
애플리케이션 응답 예시
코드는 에서 확인할 수 있어요.
데이터 구조화가 중요한 이유
일부 도메인은 순진한 RAG와 잘 작동하지만, 법적 계약에는 고유한 어려움이 있어요.
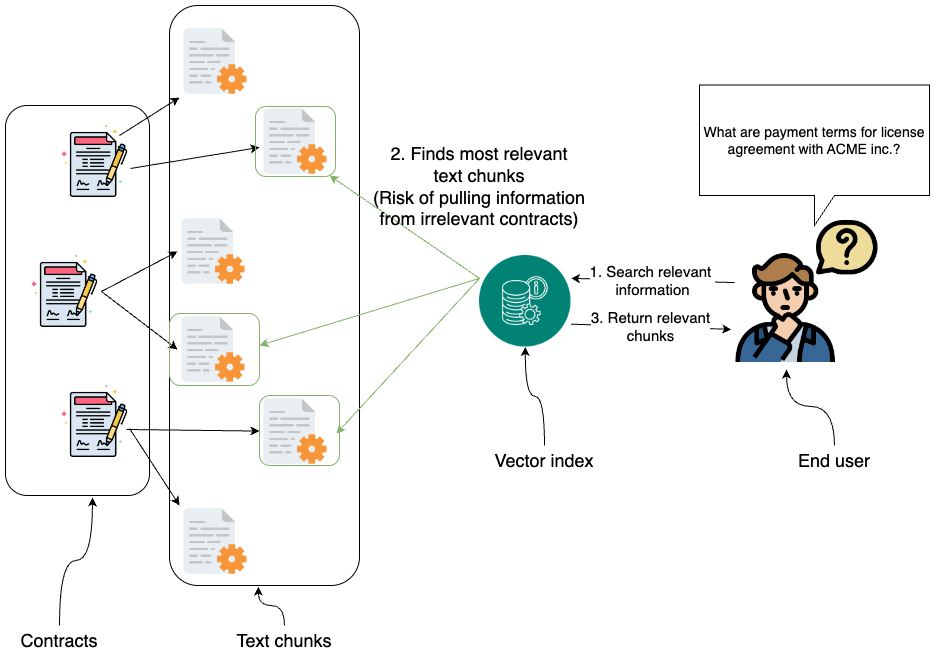
순진한 벡터 RAG를 사용해서 관련 없는 계약에서 정보를 가져오는 모습
위에 보이는 것처럼 관련 청크를 검색하기 위해 벡터 인덱스에만 의존하면 관련 없는 계약에서 정보를 가져오는 등의 문제가 생길 수 있어요. 법적 언어는 고도로 구조화되어 있고, 서로 다른 계약에서 비슷한 표현을 사용하면 부정확하거나 오해의 소지가 있는 검색 결과가 나올 수 있기 때문이죠. 이러한 한계 때문에 GraphRAG처럼 더 구조화된 접근 방식이 필요해요. 정확하고 상황에 맞는 검색을 보장해야 하니까요.
GraphRAG를 구현하려면 먼저 Knowledge Graph를 구성해야 해요.
정형 정보와 비정형 정보를 담은 법률 Knowledge Graph
법적 계약에 대한 Knowledge Graph를 구축하려면 문서에서 구조화된 정보를 추출하고, 이걸 원시 텍스트와 함께 저장하는 방법이 필요해요. Large Language Model(LLM)은 계약서를 읽고 당사자, 날짜, 계약 유형, 중요한 조항 같은 주요 세부 사항을 식별해서 도움을 줄 수 있죠. 계약을 단순한 텍스트 덩어리로 취급하는 대신, 기본적인 법적 의미를 반영하는 구조화된 구성 요소로 분해하는 거예요. 예를 들어 LLM은 "ACME Inc.가 2024년 1월 1일부터 월 $10,000를 지불하기로 동의합니다"라는 내용에 지불 의무와 시작 날짜가 모두 포함되어 있다는 걸 인식하고, 이걸 구조화된 형식으로 저장할 수 있어요.
이렇게 구조화된 데이터가 있으면 Knowledge Graph에 저장하는 거예요. 여기서 회사, 계약, 조항 같은 entities는 해당 relationships와 함께 표현되죠. 구조화되지 않은 텍스트도 계속 사용할 수 있지만, 이제 구조화된 레이어를 사용해서 검색을 세분화하고 훨씬 더 정확하게 검색할 수 있어요. 가장 관련성이 높은 텍스트 덩어리를 가져오는 대신, 해당 attributes를 기준으로 계약을 필터링할 수 있는 거죠. 이건 지난달에 체결된 계약 수, 특정 회사와 활성 계약이 있는지 여부 등 순진한 RAG로는 해결하기 어려운 질문에 답할 수 있다는 걸 의미해요. 이런 질문에는 집계 및 필터링이 필요한데, 표준 벡터 기반 검색만으로는 불가능하거든요.
구조화된 데이터와 구조화되지 않은 데이터를 결합하면 검색 시 상황에 맞는 정보를 더 많이 얻을 수 있어요. 사용자가 계약의 지불 조건에 대해 물어볼 때, 관련 없는 계약의 조건을 끌어낼 수 있는 텍스트 유사성에 의존하기보다는 검색이 올바른 계약으로 제한되도록 하는 거죠. 이 하이브리드 접근 방식은 단순한 RAG의 한계를 극복하고, 법률 문서에 대한 훨씬 더 심층적이고 안정적인 분석을 가능하게 해줘요.
그래프 구성
저희는 Large Language Model(LLM)을 활용해서 법률 문서에서 구조화된 정보를 추출하는데요. 이때 계약 이해 Atticus 데이터세트(CUAD)를 사용해요. CUAD는 CC BY 4.0에 따라 라이센스가 부여된 계약 분석을 위해 널리 사용되는 벤치마크 데이터 세트예요. CUAD 데이터세트에는 500개가 넘는 계약이 포함되어 있어서 구조화된 추출 파이프라인을 평가하는 데 아주 이상적이죠.
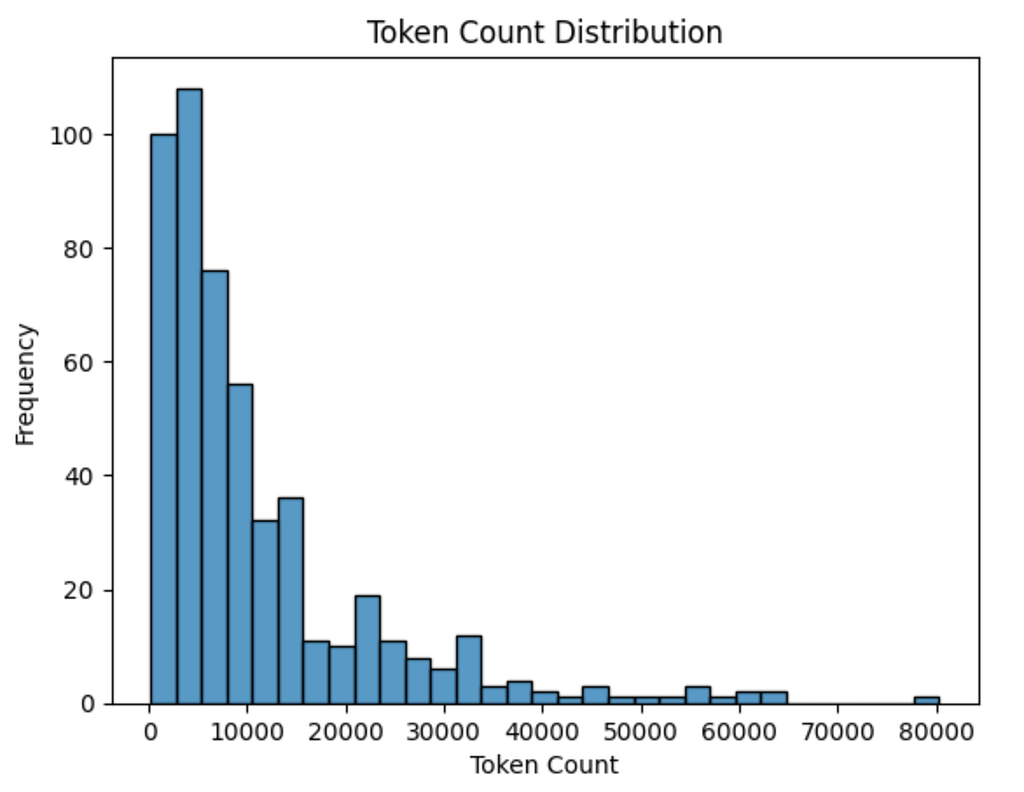
계약의 토큰 수 분포는 아래 그림에서 확인할 수 있어요.
CUAD 계약의 토큰 수 분포
이 데이터 세트에 있는 대부분의 계약은 토큰 수가 10,000개 미만으로 비교적 짧은 편이에요. 하지만 훨씬 긴 계약도 있어서, 80,000개 토큰에 달하는 경우도 있죠. 이런 긴 계약은 흔하진 않지만, 짧은 계약이 대부분을 차지하고 있어요. 분포를 보면 가파르게 감소하는 걸 알 수 있는데, 이는 장기 계약이 예외라는 걸 의미하죠.
저희는 추출을 위해 Gemini 2.0 Flash를 사용하고 있고, 토큰 입력 제한이 100만 개이기 때문에 이런 계약을 처리하는 건 문제가 되지 않아요. 저희 데이터 세트에서 가장 긴 계약(약 80,000개 토큰)도 모델 용량 안에 충분히 들어오거든요. 대부분의 계약이 훨씬 짧기 때문에, 처리를 위해 문서가 잘리거나 작은 덩어리로 나뉘는 것에 대해 걱정할 필요도 없답니다.
구조화된 데이터 추출
대부분의 상용 LLM에는 Pydantic 객체를 사용하여 출력 스키마를 정의하는 옵션이 있어요. Location 예시를 한번 살펴볼까요?
class Location(BaseModel):
"""
Represents a physical location including address, city, state, and country.
"""
address: Optional[str] = Field(
..., description="The street address of the location.Use None if not provided"
)
city: Optional[str] = Field(
..., description="The city of the location.Use None if not provided"
)
state: Optional[str] = Field(
..., description="The state or region of the location.Use None if not provided"
)
country: str = Field(
...,
description="The country of the location. Use the two-letter ISO standard.",
)
구조화된 출력을 위해 LLM을 사용할 때, Pydantic은 속성 유형을 지정하고 모델의 응답을 안내하는 설명을 제공해서 명확한 스키마를 정의하는 데 도움을 줘요. 각 field에는 str 또는 Optional[str]과 같은 유형과, LLM에 출력 형식 지정 방법을 정확하게 알려주는 설명이 있죠.
예를 들어 Location 모델에서는 다음과 같은 주요 속성을 정의해요. address, city, state, 그리고 country! 어떤 데이터가 예상되고 어떻게 구성되어야 하는지 지정하는 거죠. 예를 들어 country field는 "US", "FR", or "JP"와 같은 두 글자 국가 코드 표준을 따르도록 되어있어요. 'United States' 또는 'USA'와 같이 일관되지 않은 변형 대신에요. 이 원칙은 다른 구조화된 데이터에도 적용되는데, ISO 8601은 날짜를 표준 형식(YYYY-MM-DD)으로 유지하는 것과 같아요.
Pydantic으로 구조화된 출력을 정의함으로써 LLM 응답을 더욱 안정적이고 기계 판독 가능하게 만들 수 있고, 데이터베이스나 API에 쉽게 통합할 수도 있어요. 명확한 field 설명은 모델이 올바른 형식의 데이터를 생성하는 데 도움이 되기 때문에, 사후 처리의 필요성이 줄어든답니다.
Pydantic 스키마 모델은 더 정교해질 수도 있어요. 모델을 예로 들어볼게요. 법적 계약의 주요 세부 사항을 포착해서 추출된 데이터가 표준화된 구조를 따르도록 보장하는 거죠.
class Contract(BaseModel):
"""
Represents the key details of the contract.
"""
summary: str = Field(
...,
description=("High level summary of the contract with relevant facts and details. Include all relevant information to provide full picture."
"Do no use any pronouns"),
)
contract_type: str = Field(
...,
description="The type of contract being entered into.",
enum=CONTRACT_TYPES,
)
parties: List[Organization] = Field(
...,
description="List of parties involved in the contract, with details of each party's role.",
)
effective_date: str = Field(
...,
description=(
"Enter the date when the contract becomes effective in yyyy-MM-dd format."
"If only the year (e.g., 2015) is known, use 2015-01-01 as the default date."
"Always fill in full date"
),
)
contract_scope: str = Field(
...,
description="Description of the scope of the contract, including rights, duties, and any limitations.",
)
duration: Optional[str] = Field(
None,
description=(
"The duration of the agreement, including provisions for renewal or termination."
"Use ISO 8601 durations standard"
),
)
end_date: Optional[str] = Field(
None,
description=(
"The date when the contract expires. Use yyyy-MM-dd format."
"If only the year (e.g., 2015) is known, use 2015-01-01 as the default date."
"Always fill in full date"
),
)
total_amount: Optional[float] = Field(
None, description="Total value of the contract."
)
governing_law: Optional[Location] = Field(
None, description="The jurisdiction's laws governing the contract."
)
clauses: Optional[List[Clause]] = Field(
None, description=f"""Relevant summaries of clause types. Allowed clause types are {CLAUSE_TYPES}"""
)
이 계약 스키마는 법적 계약의 주요 세부 사항을 구조화된 방식으로 구성해서, LLM을 통해 더 쉽게 분석할 수 있게 해줘요. 여기에는 기밀 유지 또는 해고와 같은 다양한 유형의 clause가 포함되고, 각 clause에는 간략한 summary가 들어가죠. 관련 parties는 이름, 위치, role과 함께 나열되고, 계약 세부 정보에는 시작일과 종료일, 총 가치, 준거법 등이 포함돼요. 준거법과 같은 일부 attributes는 중첩 model을 사용해서 정의할 수 있어서, 더 자세하고 복잡한 output이 가능하답니다.
중첩된 object 접근 방식은 복잡한 data relationships을 처리하는 일부 AI model에서 잘 작동하는 반면, 다른 AI model에서는 깊이 중첩된 세부 정보로 인해 어려움을 겪을 수도 있어요.
다음 예제를 사용해서 접근 방식을 테스트해 볼 수 있어요. 우리는 LLM을 Fine-tuning하기 위해 LangChain framework를 사용하고 있어요.
llm = ChatGoogleGenerativeAI(model="gemini-2.0-flash")
llm.with_structured_output(Contract).invoke(
"Tomaz works with Neo4j since 2017 and will make a billion dollar until 2030."
"The contract was signed in Las Vegas"
)
이는 다음을 output해요:
Contract(
summary="Tomaz works with Neo4j since 2017 and will make a billion dollar until 2030.",
contract_type="Service",
parties=[
Organization(
name="Tomaz",
location=Location(
address=None,
city="Las Vegas",
state=None,
country="US"
),
role="employee"
),
Organization(
name="Neo4j",
location=Location(
address=None,
city=None,
state=None,
country="US"
),
role="employer"
)
],
effective_date="2017-01-01",
contract_scope="Tomaz will work with Neo4j",
duration=None,
end_date="2030-01-01",
total_amount=1_000_000_000.0,
governing_law=None,
clauses=None
)
자, 이제 계약 데이터가 구조화된 형식이 되었으니, 이걸 Neo4j로 가져오기 위한 Cypher 쿼리를 정의하고 엔터티, 관계, 그리고 주요 Clause들을 그래프 구조로 매핑해볼까요? 이 단계를 통해 추출된 원시 데이터는 쿼리 가능한 Knowledge Graph로 변환되어 계약 관련 인사이트를 효율적으로 탐색하고 검색할 수 있게 돼요.
UNWIND $data AS row
MERGE (c:Contract {file_id: row.file_id})
SET c.summary = row.summary,
c.contract_type = row.contract_type,
c.effective_date = date(row.effective_date),
c.contract_scope = row.contract_scope,
c.duration = row.duration,
c.end_date = CASE WHEN row.end_date IS NOT NULL THEN date(row.end_date) ELSE NULL END,
c.total_amount = row.total_amount
WITH c, row
CALL (c, row) {
WITH c, row
WHERE row.governing_law IS NOT NULL
MERGE (c)-[:HAS_GOVERNING_LAW]->(l:Location)
SET l += row.governing_law
}
FOREACH (party IN row.parties |
MERGE (p:Party {name: party.name})
MERGE (p)-[:HAS_LOCATION]->(pl:Location)
SET pl += party.location
MERGE (p)-[pr:PARTY_TO]->(c)
SET pr.role = party.role
)
FOREACH (clause IN row.clauses |
MERGE (c)-[:HAS_CLAUSE]->(cl:Clause {type: clause.clause_type})
SET cl.summary = clause.summary
)
이 Cypher 쿼리는 다음과 같은 속성을 가진 계약 Node를 생성해서 구조화된 계약 데이터를 Neo4j로 가져오죠. summary, contract_type, effective_date, duration, 그리고 total_amount. 준거법이 지정되면 계약은 Location Node에 연결돼요. 계약에 관련된 당사자는 Party Node로 저장되고, 각 당사자는 Location에 연결되며 계약과 관련된 역할이 할당되죠. 또한, 쿼리는 Clause를 처리해서 Clause Node를 생성하고 해당 유형과 요약을 저장하는 동시에 이를 계약에 연결합니다.
계약을 처리하고 가져온 후, 결과 그래프는 다음 그래프 스키마를 따르게 됩니다.
가져온 법적 그래프 스키마
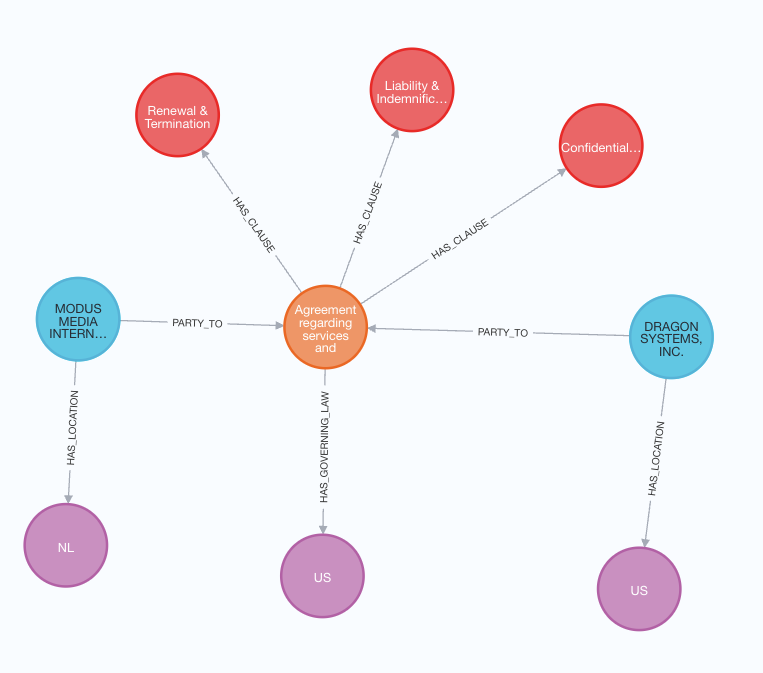
단일 계약에 대해서도 한번 살펴볼까요?
단일 계약 그래프
이 그래프는 계약(주황색 Node)이 다양한 Clause(빨간색 Node), Party(파란색 Node), Location(보라색 Node)으로 연결되는 계약 구조를 나타내요. 계약에는 갱신 및 종료, 책임 및 면책, 기밀 유지 및 비공개라는 세 가지 Clause가 있네요. Modus Media International과 Dragon Systems, Inc.라는 두 Party가 관련되어 있으며, 각각 해당 Location인 네덜란드(NL)와 미국(US)에 연결되어 있어요. 본 계약은 미국법의 적용을 받습니다. 계약 Node에는 날짜 및 기타 관련 세부 정보가 포함된 추가 메타데이터도 포함되어 있답니다.
CUAD 법적 계약이 포함된 공개 읽기 전용 인스턴스는 다음 자격 증명으로 사용할 수 있어요.
회사, 개인 및 Location이 참조되는 방식이 다양하기 때문에 법적 계약의 Entity Resolution은 꽤 까다로운 작업이에요. 예를 들어, 회사가 "Acme Inc."로 표시될 수 있는데, 어떤 계약에서는 'Acme Corporation'을, 또 다른 계약에서는 'Acme Corporation'을 사용할 수도 있거든요. 따라서 동일한 Entity를 지칭하는지 확인하는 프로세스가 필요하죠.
한 가지 방법은 텍스트 임베딩이나 Levenshtein 거리 같은 문자열 거리 측정법을 써서 후보 일치 항목을 만들어보는 거예요. 임베딩은 의미론적 유사성을 잡아내고, 문자열 거리는 문자 수준의 차이를 측정하죠. 후보가 식별되면 주소나 세금 ID 같은 메타데이터를 비교하고, 그래프에서 공유 관계를 분석하거나, 중요한 경우 사람이 직접 검토하는 등의 추가 평가가 필요할 수 있어요.
대규모 엔터티를 해결하려면 다음과 같은 오픈 소스 솔루션이 필요해요. Dedupe 같은 솔루션이나, Senzing 같은 상용 도구가 자동화된 방법을 제공하죠. 어떤 접근 방식을 선택할지는 데이터 품질, 정확성 요구 사항, 그리고 수동으로 감독할 수 있는지에 따라 달라져요.
일단 합법적인 그래프가 만들어지면, Agentic GraphRAG 구현으로 넘어갈 수 있어요.
Agentic GraphRAG
에이전트 아키텍처는 복잡성, 모듈성, 추론 기능이 정말 다양해요. 이런 아키텍처의 핵심에는 도구, 메모리, 오케스트레이션 메커니즘으로 보완되는 중앙 추론 엔진 역할을 하는 LLM이 있죠. 가장 큰 차이점은 LLM이 의사 결정을 내릴 때 얼마나 많은 자율성을 가지는지, 그리고 외부 시스템과의 상호 작용이 어떻게 구성되어 있는지예요.
특히 챗봇 같은 구현을 위한 가장 간단하고 효과적인 설계 중 하나는 도구를 사용한 직접적인 LLM 접근 방식이에요. 이 설정에서 LLM은 의사 결정자 역할을 하면서 호출할 도구(있다면)를 동적으로 선택하고, 필요할 때 작업을 다시 시도하고, 복잡한 요청을 처리하기 위해 여러 도구를 순차적으로 실행하죠.
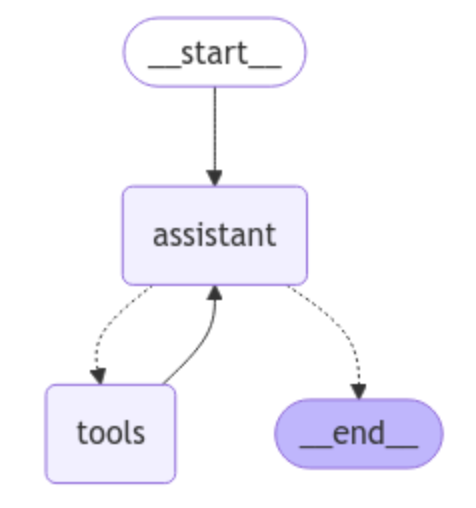
LangGraph 에이전트 아키텍처
이 다이어그램은 간단한 LangGraph 에이전트 워크플로우를 보여줘요. 시작 지점은 __start__이고, LLM이 사용자 입력을 처리하는 보조 노드로 이동하죠. 여기서 어시스턴트는 도구를 호출해서 관련 정보를 가져오거나, 바로 __end__로 넘어가서 상호작용을 끝낼 수 있어요. 도구를 사용하는 경우, 보조자는 다른 도구를 호출할지 아니면 세션을 종료할지 결정하기 전에 응답을 처리해요. 이런 구조 덕분에 에이전트는 응답하기 전에 외부 정보가 필요한 시점을 자율적으로 판단할 수 있죠.
이 접근 방식은 특히 추론 및 자기 수정 기능이 뛰어난 Gemini나 GPT-4o 같은 강력한 상용 모델에 잘 맞아요.
도구
LLM은 강력한 추론 엔진이지만, 그 효과는 외부 도구를 얼마나 잘 활용하느냐에 달려 있는 경우가 많아요. 데이터베이스 쿼리, API, 검색 기능 등 이런 도구들은 사실 검색, 계산 수행, 구조화된 데이터와 상호 작용하는 LLM의 기능을 확장해 주죠.
LLM 도구
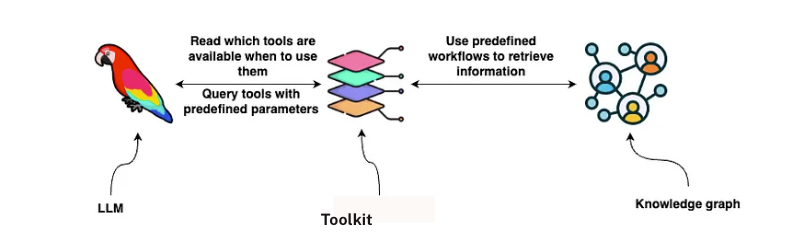
다양한 쿼리를 처리할 수 있을 만큼 일반적이면서도 의미 있는 결과를 반환할 수 있을 만큼 정밀한 도구를 설계하는 건 과학이라기보다는 예술에 가까워요. 우리가 실제로 구축하고 있는 건 LLM과 기본 데이터 사이의 의미 계층인 셈이죠. LLM이 Neo4j Knowledge Graph나 데이터베이스 스키마의 정확한 구조를 이해하도록 요구하는 대신, 이런 복잡성을 추상화하는 도구를 정의하는 거예요.
이런 접근 방식을 쓰면 LLM은 계약 정보가 그래프의 Node와 Relationship으로 저장되어 있는지, 아니면 문서 저장소의 원시 텍스트로 저장되어 있는지 알 필요가 없어요. 사용자의 질문에 따라 관련 데이터를 가져오기 위해 올바른 도구를 호출하기만 하면 되죠.
우리의 경우, 계약 검색 도구가 이런 의미 인터페이스 역할을 해요. 사용자가 계약 조건, 의무, 당사자에 대해 질문하면 LLM은 요청을 데이터베이스 쿼리로 변환하고, 관련 정보를 검색해서 LLM이 해석하고 요약할 수 있는 형식으로 표시하는 구조화된 쿼리 도구를 호출하죠. 이렇게 하면 다양한 LLM이 저장 구조에 대한 직접적인 지식이 없어도 계약 데이터와 상호 작용할 수 있는 유연하고 모델에 구애받지 않는 시스템이 만들어져요.
최적의 도구 세트를 설계하기 위한 만능 표준은 없어요. 어떤 모델에서는 잘 작동하는 게 다른 모델에서는 실패할 수도 있죠. 어떤 모델은 모호한 도구 지침을 적절하게 처리하는 반면, 다른 모델은 복잡한 매개변수 때문에 어려움을 겪거나 명시적인 프롬프트가 필요하기도 해요. 일반성과 작업별 효율성 사이의 절충안은 도구 설계에 사용 중인 LLM에 대한 반복, 테스트, Fine-tuning이 필요하다는 걸 의미해요.
계약 분석의 경우, 효과적인 도구는 사용자가 쿼리를 엄격하게 표현하지 않아도 계약을 검색하고 주요 용어를 요약해야 해요. 이런 유연성을 얻으려면 신중한 Prompt Engineering, 강력한 스키마 설계, 그리고 다양한 LLM 기능에 대한 적응이 필요하죠. 모델이 발전함에 따라 도구를 더욱 직관적이고 효과적으로 만들기 위한 전략도 발전할 거예요.
이 섹션에서는 도구 구현에 대한 다양한 접근 방식을 살펴보고, 유연성, 효율성, 다양한 LLM과의 호환성을 비교해 볼 거예요.
제가 선호하는 접근 방식은 동적이고 결정론적으로 Cypher 쿼리를 구성해서 데이터베이스에 대해 실행하는 거예요. 이 방법은 구현 유연성을 유지하면서 일관되고 예측 가능한 쿼리 생성을 보장하죠. 이런 방식으로 쿼리를 구성함으로써 의미 계층을 강화해서 사용자 입력이 데이터베이스 검색으로 원활하게 변환될 수 있도록 하는 거예요. 이렇게 하면 LLM은 기본 데이터 모델을 이해하기보다는 관련 정보를 검색하는 데 집중할 수 있어요.
우리 도구는 관련 계약을 식별하기 위한 것이기 때문에, 다양한 속성을 기반으로 계약을 검색할 수 있는 옵션을 LLM에 제공해야 해요. 입력 설명은 다시 Pydantic 객체로 제공되죠.
class ContractInput(BaseModel):
min_effective_date: Optional[str] = Field(
None, description="Earliest contract effective date (YYYY-MM-DD)"
)
max_effective_date: Optional[str] = Field(
None, description="Latest contract effective date (YYYY-MM-DD)"
)
min_end_date: Optional[str] = Field(
None, description="Earliest contract end date (YYYY-MM-DD)"
)
max_end_date: Optional[str] = Field(
None, description="Latest contract end date (YYYY-MM-DD)"
)
contract_type: Optional[str] = Field(
None, description=f"Contract type; valid types: {CONTRACT_TYPES}"
)
parties: Optional[List[str]] = Field(
None, description="List of parties involved in the contract"
)
summary_search: Optional[str] = Field(
None, description="Inspect summary of the contract"
)
country: Optional[str] = Field(
None, description="Country where the contract applies. Use the two-letter ISO standard."
)
active: Optional[bool] = Field(None, description="Whether the contract is active")
monetary_value: Optional[MonetaryValue] = Field(
None, description="The total amount or value of a contract"
)
LLM 도구를 사용하면 속성은 목적에 따라 다양한 형태를 취할 수 있어요. 일부 필드는 contract_type, country처럼 간단한 문자열로, 단일 값을 저장하죠. 다른 필드인 parties는 계약에 관련된 여러 엔터티처럼 여러 항목을 허용하는 문자열 목록이에요.
기본 데이터 유형 외에도 속성은 복잡한 객체를 나타낼 수도 있어요. 예를 들어 monetary_value는 통화 유형, 연산자 등 구조화된 데이터가 포함된 MonetaryValue 객체를 사용하죠. 중첩된 객체가 있는 속성은 데이터를 명확하고 구조적으로 표현하지만, 모델은 이를 효과적으로 처리하는 데 어려움을 겪는 경향이 있어서 단순하게 유지해야 해요.
이 프로젝트의 일환으로 우리는 추가 기능인 cypher_aggregation 속성을 실험하고 있어요. 특정 필터링이나 집계가 필요한 시나리오에 대해 LLM에 더 큰 유연성을 제공하죠.
cypher_aggregation: Optional[str] = Field(
None,
description="""Custom Cypher statement for advanced aggregations and analytics.
This will be appended to the base query:
```
MATCH (c:Contract)
<filtering based on other parameters>
WITH c, summary, contract_type, contract_scope, effective_date, end_date, parties, active, monetary_value, contract_id, countries
<your cypher goes here>
```
Examples:
1. Count contracts by type:
```
RETURN contract_type, count(*) AS count ORDER BY count DESC
```
2. Calculate average contract duration by type:
```
WITH contract_type, effective_date, end_date
WHERE effective_date IS NOT NULL AND end_date IS NOT NULL
WITH contract_type, duration.between(effective_date, end_date).days AS duration
RETURN contract_type, avg(duration) AS avg_duration ORDER BY avg_duration DESC
```
3. Calculate contracts per effective date year:
```
RETURN effective_date.year AS year, count(*) AS count ORDER BY year
```
4. Counts the party with the highest number of active contracts:
```
UNWIND parties AS party
WITH party.name AS party_name, active, count(*) AS contract_count
WHERE active = true
RETURN party_name, contract_count
ORDER BY contract_count DESC
LIMIT 1
```
"""
cypher_aggregation 속성을 사용하면 LLM이 고급 집계 및 분석을 위한 사용자 정의 Cypher 문을 정의할 수 있어요. 질문별 집계 논리를 추가하여 기본 쿼리를 확장해서 유연한 필터링 및 계산이 가능하게 하는 거죠.
이 기능은 유형별 계약 계산, 평균 계약 기간 계산, 시간 경과에 따른 계약 분포 분석, 계약 활동을 기반으로 주요 당사자 식별과 같은 사용 사례를 지원해요. LLM은 이 속성을 활용해서 사전 정의된 쿼리 구조 없이도 특정 분석 요구 사항에 맞는 통찰력을 동적으로 생성할 수 있죠.
이러한 유연성은 가치가 있지만, 적응성이 향상되면 작업의 복잡성이 추가되어 일관성과 견고성이 감소하므로 신중하게 평가해야 해요.
LLM에 함수를 제시할 때 함수의 이름과 설명을 명확하게 정의해야 해요. 잘 구조화된 설명은 모델이 함수를 올바르게 사용하도록 안내해서, 모델이 해당 목적, 예상 입력 및 출력을 이해하도록 돕죠. 이렇게 하면 모호함이 줄어들고 의미 있고 신뢰할 수 있는 쿼리를 생성하는 LLM의 기능이 향상돼요.
class ContractSearchTool(BaseTool):
name: str = "ContractSearch"
description: str = (
"useful for when you need to answer questions related to any contracts"
)
args_schema: Type[BaseModel] = ContractInput
마지막으로, 주어진 입력을 처리하고 해당 Cypher 문을 구성하고 효율적으로 실행하는 함수를 구현해야 해요.
함수의 핵심 논리는 Cypher 문을 구성하는 데 초점을 맞춰요. 쿼리의 기초로 계약을 일치시키는 것부터 시작하죠.
cypher_statement = "MATCH (c:Contract) "
다음으로 입력 매개변수를 처리하는 함수를 구현해야 해요. 이 예에서는 주로 속성을 사용하여 지정된 기준에 따라 계약을 필터링하죠.
예를 들어, contract_type 속성은 간단한 node 속성 필터링을 수행하는 데 사용돼요.
if contract_type:
filters.append("c.contract_type = $contract_type")
params["contract_type"] = contract_type
이 코드는 다음에 대한 Cypher 필터를 추가합니다. contract_type 값에 쿼리 매개변수를 사용하는 동안 쿼리 삽입 보안 문제를 방지하기 위해서죠.
LLM이 이를 처리하므로 입력 값을 유효한 계약 유형으로 매핑하는 것에 대해 걱정할 필요가 없어요.
우리는 LLM이 Knowledge Graph와 상호 작용할 수 있는 도구를 구축하고 있어요. 여기서 도구는 구조화된 쿼리에 대한 추상화 계층 역할을 하죠. 핵심 기능은 온톨로지와 유사하지만 동적으로 계산되는 추론된 속성을 런타임에 사용하는 기능이에요.
if active is not None:
operator = ">=" if active else "<"
filters.append(f"c.end_date {operator} date()")
여기서, active 계약이 진행 중인지 여부를 결정하는 런타임 분류 역할을 해요 (>= date()) 또는 만료됨 (< date()). 이 논리는 필요한 경우에만 속성을 계산하여 구조화된 쿼리를 확장하므로 보다 유연한 LLM 추론이 가능하죠. 도구 내에서 이와 같은 논리를 처리함으로써 LLM이 단순화되고 직관적인 작업과 상호 작용하여 쿼리 공식화보다는 추론에 집중할 수 있도록 해요.
필터링은 특정 당사자가 관련된 계약으로 결과를 제한하는 등 인접 node에 따라 달라지는 경우도 있어요. 그만큼 parties 속성은 선택적 목록이며 제공되면 해당 엔터티에 연결된 계약만 고려되도록 하죠.
if parties:
parties_filter = []
for i, party in enumerate(parties):
party_param_name = f"party_{i}"
parties_filter.append(
f"""EXISTS {{
MATCH (c)<-[:PARTY_TO]-(party)
WHERE toLower(party.name) CONTAINS ${party_param_name}
}}"""
)
params[party_param_name] = party.lower()
이 코드는 관련 당사자를 기준으로 계약을 필터링하여 논리를 다음과 같이 처리합니다. AND, 즉 계약이 포함되려면 지정된 모든 조건이 충족되어야 함을 의미하죠. 제공된 당사자 목록을 반복하고 각 당사자 조건이 유지되어야 하는 쿼리를 구성해요.
충돌을 방지하기 위해 각 당사자에 대해 고유한 매개변수 이름이 생성돼요. 그만큼 EXISTS 조항은 계약이 PARTY_TO 이름에 지정된 값이 포함된 당사자와의 관계. 대소문자를 구분하지 않는 일치를 허용하기 위해 이름은 소문자로 변환돼요. 각 당사자 조건은 별도로 추가되어 암시적 조건을 적용합니다. AND 그들 사이에.
지원과 같이 더 복잡한 로직이 필요한 경우 OR 조건이 있거나 다른 일치 기준을 허용하는 경우 입력을 변경해야 해요. 단순한 당사자 이름 목록 대신 연산자를 지정하는 구조화된 입력 형식이 필요하죠.
또한 사소한 오타를 허용하는 파티 매칭 방법을 구현하여 철자와 형식의 변형을 처리함으로써 사용자 경험을 향상시킬 수 있어요.
더 많은 유연성을 추가하기 위해 연산자 개체를 중첩된 속성으로 도입하여 필터링 논리를 더 많이 제어할 수 있어요. 하드코딩 비교 대신 연산자에 대한 열거형을 정의하고 이를 동적으로 사용하죠.
예를 들어, 금전적 가치가 있는 경우 총 금액이 지정된 값보다 큰지, 작은지 또는 정확히 같은지를 기준으로 계약을 필터링해야 할 수 있어요. 고정된 비교 논리를 가정하는 대신 가능한 연산자를 나타내는 열거형을 정의합니다.
class NumberOperator(str, Enum):
EQUALS = "="
GREATER_THAN = ">"
LESS_THAN = "<"
class MonetaryValue(BaseModel):
"""The total amount or value of a contract"""
value: float
operator: NumberOperator
if monetary_value:
filters.append(f"c.total_amount {monetary_value.operator.value} $total_value")
params["total_value"] = monetary_value.value
이 접근 방식은 시스템의 표현력을 훨씬 높여줘요. 빡빡한 필터링 규칙 대신 도구 인터페이스를 사용하면 LLM이 값뿐만 아니라 비교 방법까지 지정할 수 있거든요. 이렇게 하면 LLM의 상호 작용을 간단하고 선언적으로 유지하면서도 더 넓은 범위의 쿼리를 쉽게 처리할 수 있죠.
일부 LLM은 중첩된 객체를 입력으로 사용하는 데 어려움을 겪기 때문에 구조화된 연산자 기반 필터링을 처리하기가 쉽지 않아요. 추가로 between 연산자는 두 개의 별도 값이 필요하므로 구문 분석 및 입력 유효성 검사가 더 복잡해질 수 있죠.
최소 및 최대 속성
저는 보통 간단하게 하려고 min과 max 날짜 속성을 사용하곤 해요. 이렇게 하면 자연스럽게 범위 필터링을 지원하고 between 로직도 간단해지거든요.
if min_effective_date:
filters.append("c.effective_date >= date($min_effective_date)")
params["min_effective_date"] = min_effective_date
if max_effective_date:
filters.append("c.effective_date <= date($max_effective_date)")
params["max_effective_date"] = max_effective_date
이 기능은 선택적인 하한 및 상한 조건을 추가해서 유효 날짜 범위를 기준으로 계약을 필터링해줘요. min_effective_date와 max_effective_date가 제공되면 지정된 날짜 범위 내의 계약만 포함되는 거죠.
속성은 Semantic Search에도 사용할 수 있어요. 여기서는 Vector Embedding을 미리 사용하는 대신 메타데이터 필터링에 사후 필터링 방식을 사용하는 거죠. 먼저 날짜 범위, 금전적 가치, 정당과 같은 구조화된 필터를 적용해서 후보 집합의 범위를 좁혀요. 그런 다음 필터링된 하위 집합에 대해 벡터 검색을 수행해서 의미적 유사성을 기준으로 결과의 순위를 매기는 거예요.
if summary_search:
cypher_statement += (
"WITH c, vector.similarity.cosine(c.embedding, $embedding) "
"AS score ORDER BY score DESC WITH c, score WHERE score > 0.9 "
) # Define a threshold limit
params["embedding"] = embeddings.embed_query(summary_search)
else: # Else we sort by latest
cypher_statement += "WITH c ORDER BY c.effective_date DESC "
이 코드는 summary_search가 제공되는 경우 Semantic Search를 적용해요. 계약 임베딩과 쿼리 임베딩 사이의 코사인 유사성을 계산하고, 관련성에 따라 결과를 정렬하고, 임계값 0.9로 점수가 낮은 일치 항목을 필터링하는 거죠. 그렇지 않으면 기본적으로 가장 최근의 계약을 기준으로 정렬돼요 (effective_date 기준).
Cypher 집계 속성은 LLM에 어느 정도 부분적인 Text2Cypher 기능을 제공해서 초기 구조화된 필터링 후 집계를 동적으로 생성할 수 있도록 테스트하고 싶었던 실험이었어요. 가능한 모든 집계를 미리 정의하는 대신 이 접근 방식을 사용하면 LLM이 필요에 따라 개수, 평균 또는 그룹화된 요약과 같은 계산을 지정해서 쿼리를 더욱 유연하고 표현력 있게 만들 수 있죠. 하지만 이렇게 하면 더 많은 쿼리 로직이 LLM으로 이동하므로 생성된 모든 쿼리가 올바르게 작동하는지 확인하는 것이 중요해요. 형식이 잘못되었거나 호환되지 않는 Cypher 문으로 인해 실행이 중단될 수 있기 때문이죠. 유연성과 안정성 사이의 이러한 절충은 시스템 설계 시 주요 고려 사항이에요.
if cypher_aggregation:
cypher_statement += """WITH c, c.summary AS summary, c.contract_type AS contract_type,
c.contract_scope AS contract_scope, c.effective_date AS effective_date, c.end_date AS end_date,
[(c)<-[r:PARTY_TO]-(party) | {party: party.name, role: r.role}] AS parties, c.end_date >= date() AS active, c.total_amount as monetary_value, c.file_id AS contract_id,
apoc.coll.toSet([(c)<-[:PARTY_TO]-(party)-[:LOCATED_IN]->(country) | country.name]) AS countries """
cypher_statement += cypher_aggregation
암호 집계가 제공되지 않는 경우 프롬프트가 너무 복잡해지지 않도록 5개의 예시 계약과 함께 식별된 계약의 총 개수를 반환해요. 대규모 결과 세트로 어려움을 겪는 LLM은 별로 쓸모가 없기 때문에 과도한 행을 처리하는 것이 중요하죠. 또한 LLM이 100개의 계약 제목으로 답변을 생성하는 것도 좋은 사용자 경험은 아니에요.
이 Cypher statement는 일치하는 모든 계약을 목록으로 수집해서, 총 개수와 요약, 유형, 범위, 날짜, 금전적 가치, 역할이 있는 관련 당사자, 고유한 국가 위치 등 주요 속성이 포함된 최대 5개의 예제 계약을 반환해요.
이제 계약 검색 도구가 구축되었으니, 이걸 LLM에 전달해서 Agent GraphRAG를 구현해볼게요.
에이전트 벤치마크
Agent GraphRAG 구현을 진지하게 고려하고 있다면, 벤치마크뿐만 아니라 전체 프로젝트의 기초로서 평가 데이터 세트가 필요해요. 잘 구성된 데이터 세트는 시스템이 처리해야 하는 범위를 정의하는 데 도움이 되고, 초기 개발이 실제 사용 사례에 부합하도록 보장하죠. 게다가 성능 평가를 위한 유용한 도구가 되어서, LLM이 그래프와 얼마나 잘 상호 작용하고, 정보를 검색하고, 추론을 적용하는지 측정할 수 있어요. 또한 추측이 아닌 명확한 피드백을 통해 쿼리, 도구 사용 및 응답 형식을 반복적으로 구체화할 수 있으므로, 신속한 엔지니어링 최적화에도 필수적이에요. 구조화된 데이터 세트가 없으면 맹목적으로 개선 사항을 정량화하기 어렵고 불일치를 포착하기가 더 어려워져요.
벤치마크 코드는 에서 확인할 수 있어요.
저는 시스템을 평가하는 데 사용할 22개의 질문 목록을 작성했어요. 또한 다음과 같은 새로운 측정항목을 도입할 예정이에요. answer_satisfaction 맞춤 프롬프트가 제공되죠.
answer_satisfaction = AspectCritic(
name="answer_satisfaction",
definition="""You will evaluate an ANSWER to a legal QUESTION based on a provided SOLUTION.
Rate the answer on a scale from 0 to 1, where:
- 0 = incorrect, substantially incomplete, or misleading
- 1 = correct and sufficiently complete
Consider these evaluation criteria:
1. Factual correctness is paramount - the answer must not contradict the solution
2. The answer must address the core elements of the solution
3. Additional relevant information beyond the solution is acceptable and may enhance the answer
4. Technical legal terminology should be used appropriately if present in the solution
5. For quantitative legal analyses, accurate figures must be provided
+ fewshots
"""
많은 질문은 많은 양의 정보를 반환할 수 있어요. 예를 들어, 2020년 이전에 서명된 계약을 요청하면 수백 개의 결과가 나올 수 있죠. LLM은 총 개수와 몇 가지 예시 항목을 모두 수신하므로, LLM이 표시하기로 선택한 특정 예시보다는 총 개수에 중점을 두고 평가해야 해요.
벤치마크 결과
제공된 결과는 평가된 모든 모델(Gemini 1.5 Pro, Gemini 2.0 Flash 및 GPT-4o)이 대부분의 도구 호출에서 유사하게 성능이 뛰어나며, GPT-4o가 Gemini 모델(0.82 대 0.77)보다 약간 더 뛰어난 성능을 나타낸다는 것을 보여줘요. 눈에 띄는 차이점은 주로 부분적인 Text2Cypher가 사용될 때, 특히 다양한 집계 작업에서 나타나요.
이는 매우 간단한 22개의 질문에 불과하므로, LLM의 추론 기능을 실제로 탐색하지 못했어요.
또한 LLM은 일반적으로 복잡한 Cypher 쿼리를 직접 생성하는 것보다 Python 코드 생성 및 실행을 더 잘 처리하므로, 집계에 Python을 활용하여 정확성을 크게 향상시킬 수 있는 프로젝트를 봤어요.
웹 애플리케이션
저는 응답을 프런트 엔드로 직접 스트리밍하는 FastAPI에서 호스팅되는 LangGraph를 기반으로 하는 간단한 React 웹 애플리케이션도 구축했어요. 웹 앱을 만드는 데 도움을 준 Anei Gorcic에게 특별한 감사를 드립니다.
다음 명령을 사용하여 전체 스택을 시작할 수 있어요.
docker compose up
그리고 localhost:5173으로 이동하면 돼요.
웹 애플리케이션
요약
LLM은 점점 더 강력한 추론 능력을 갖추게 되면서, 적절한 도구와 함께 사용하면 법적 계약처럼 복잡한 영역을 탐색하는 데 아주 유용한 도우미가 될 수 있어요. 여기서는 실제 계약에서 흔히 볼 수 있는 다양한 조항을 깊이 다루지는 않고, 핵심적인 계약 속성에만 집중해서 겉핥기 식으로 살펴봤어요. 앞으로 조항 적용 범위를 넓히거나 도구 설계 및 상호 작용 전략을 개선하는 등 발전할 여지가 정말 많답니다.
코드는 에서 확인하실 수 있어요.
이미지
이 게시글에 사용된 모든 이미지는 작성자가 직접 만들었어요.
필수 GraphRAG
Knowledge Graph를 통해 RAG의 잠재력을 최대한 활용해보세요! Manning에서 제공하는 최종 가이드를 지금 바로 무료로 받아보세요.
LangChain
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
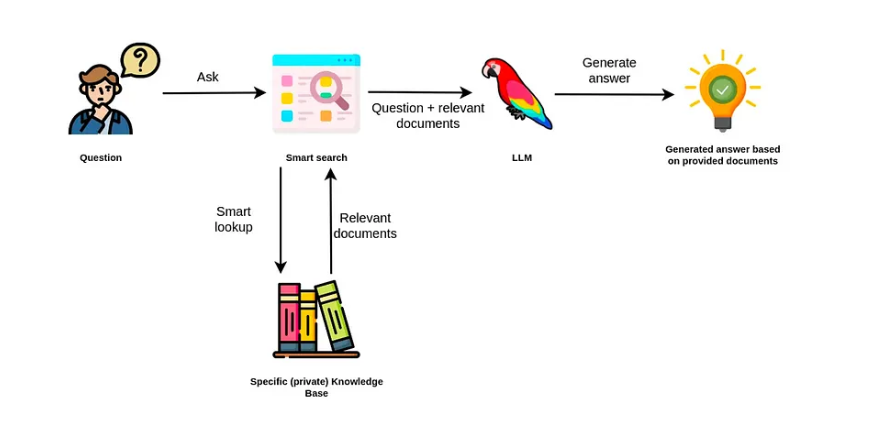
RAG (Retrieval-Augmented Generation)는 사전 훈련에만 의존하는 대신 검색과 생성을 결합하여 자체 데이터의 기본 출력을 결합, 즉 LLM (Large Language Model)을 향상하는 기술이에요. RAG 시스템은 지식 소스에서 관련 정보를 검색하고 이를 프롬프트에 통합해서 더 정확하고 상황에 맞으며 신뢰할 수 있는 응답을 가능하게 하죠.
RAG는 이제 LLM 애플리케이션에 널리 사용되는 아키텍처인데요, 웹 검색을 활용하는 질문 답변 서비스부터 기업 콘텐츠를 색인화하는 내부 채팅 도구, 복잡한 QA 파이프라인에 이르기까지 모든 것을 지원해요. 그 매력은 간단하죠. 검색을 통해 생성을 강화함으로써 팀은 관련성과 신뢰성에 대한 오늘날의 기대를 충족하는 LLM 경험을 제공할 수 있다는 점!
하지만 RAG 시스템을 출시하는 게 끝이 아니라는 거, 다들 아실 거예요. 프로토타입을 넘어선 사람이라면 누구나 그 증상을 알고 있을 텐데요. 환각이 다시 나타나거나, 긴 쿼리가 성능을 저하시키거나, 올바른 문서를 검색했음에도 불구하고 답변이 엉뚱하게 나오는 경우가 있죠. 바로 이럴 때 고급 RAG 기술이 필요한 거예요. 이 가이드는 팀이 관련성, 정확성 및 효율성을 향상시켜 시스템이 제대로 작동할 뿐만 아니라 대규모로도 잘 작동하도록 돕는 전략을 안내할 거예요.
이 가이드에서 다룰 내용은요:
RAG 파이프라인이 하는 일
일반적인 실패 모드
기본 RAG가 제대로 작동하지 않는 이유와 고급 RAG 기술이 어떻게 도움이 되는지
향상된 검색 품질 및 관련성
문서 검색 및 사용을 더욱 쉽게 만들기
Agentic Planning을 통해 복잡한 다단계 질문 처리
정확한 답변과 환각 감소
복잡한 질문에 Agentic Planning 사용
고급 RAG 전술을 평가하세요
고급 RAG 기술을 사용한 실제 계획
여기에서 어디로 가야합니까?
필수 GraphRAG
고급 RAG: FAQ
RAG 아키텍처
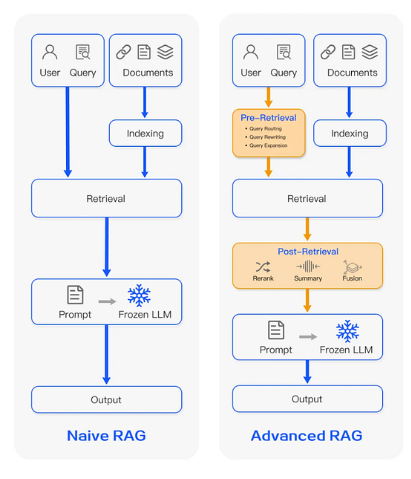
일반적인 RAG 파이프라인은 설명은 간단하지만, 프로덕션 환경을 위해 제대로 구축하기가 쉽지 않아요. RAG 아키텍처 기준과 기본 설정이 어려운 이유를 이해하면, 올바른 상황에서 고급 RAG 기술로 전환하는 데 도움이 될 거예요.
RAG 파이프라인이 하는 일
표준 RAG 시스템은 다음 네 가지 작업을 수행해요.
콘텐츠를 수집합니다.: 문서를 청크로 분할하고, 메타데이터를 추가하고, Vector Embedding을 생성합니다.
Index: 효율적인 검색을 위한 저장소(종종 벡터 Index, 때로는 키워드 Index 포함)를 구축합니다.
: Query에 대한 상위 k 컨텍스트를 가져옵니다.
: 검색된 컨텍스트와 함께 Query를 사용하여 모델을 Prompt하고 답변을 반환합니다.
런타임 시 시스템은 수집 중에 문서를 삽입하는 데 사용된 것과 동일한 모델로 사용자 Query를 인코딩하고, 가장 가까운 벡터에 대한 Index를 검색하고, 상위 k 청크를 검색하고, Prompt에 Query와 함께 해당 청크를 포함합니다.
기본 RAG 프로세스
일반적인 실패 모드
단순한 파이프라인은 데모에서는 잘 작동하지만, 프로덕션 환경에서는 문제가 생기는 경우가 많아요.
이거 완전 공감될 거예요. 팀을 위해 빠른 RAG 도우미를 만들었는데, 간단한 사실 조회는 잘 되거든요. 그런데 PM이 "지난 분기에 갱신했고 SSO에 대한 지원 티켓도 개설한 기업 고객은 누구죠?"라고 물어보면, 봇이 일부만 대답하고 몇몇 중요한 계정을 놓치거나 관련 없는 고객을 추가하는 거예요.
이런 증상, 겪어보셨을 텐데요.
Top-k 결과가 거의 중복되거나 너무 뻔한 내용이라 프롬프트에 다양성이 부족해요.
고유명사, ID, 약어(SKU-123, SSO, SOC 2)처럼 흔하지 않은 단어는 검색에서 잘 누락돼요.
답변에서 엉뚱한 내용을 인용하거나 비슷한 계정의 정보를 섞어서 말하기도 해요.
k 값을 늘리거나 청크를 더 길게 하거나, 후속 작업 후에 검색을 다시 실행하면 레이턴시가 늘어나요.
표나 PDF를 제대로 분할하지 못해서 중요한 헤더나 각주가 삭제되어 의미가 바뀌기도 해요.
다단계 채팅에서 제약 조건('EMEA만', '지난 분기')을 잊어버려서, 후속 질문에서 이전 필터를 무시하고 엉뚱한 답변을 하기도 해요.
검색 결과가 너무 뻔하면 모델이 있지도 않은 정보를 추측해서 채워 넣으려고 해요.
기본 RAG가 왜 문제일까요? (그리고 고급 RAG 기술이 어떻게 도움이 될까요?)
RAG는 확률적인 생성 방식과 작은 컨텍스트 창을 사용해서 대략적인 검색 결과를 결합하기 때문에, 프로덕션 환경에서 몇 가지 반복적인 실패 패턴이 나타나곤 해요. 이런 문제는 보통 로그나 추적을 통해 알게 되죠.
벡터 전용 검색은 Semantic Search에 강하지만, 정확한 토큰이나 희귀한 문자열을 놓칠 수 있어요. 하이브리드 검색을 사용하지 않으면 이름이나 코드가 빠져나갈 수 있죠.
가 구조를 어설프게 잘라버리면, 모델은 올바른 컨텍스트 없이 조각난 정보만 보게 돼요.
은 코사인 유사도가 유용성이 아니라 근접성을 기준으로 점수를 매긴다는 뜻이에요.
(시간, 소스, 지역) 때문에 범위에 맞지 않는 문서가 프롬프트에 나타날 수 있어요.
제한된 쿼리 이해(확장 또는 분해 없음)는 여러 단계를 거쳐야 하는 질문에 대한 검색 능력이 부족하다는 의미예요.
제한된 컨텍스트 창 때문에 중요한 구절을 놓치거나, 세부 정보가 부족한 요약에 의존하게 될 수 있어요.
피드백 루프 없음은, 예를 들어 간단한 CRAG 스타일 검사처럼, 생성 전에 약한 컨텍스트를 감지하지 못한다는 뜻이에요.
그래프 컨텍스트 없음은 엔터티와 이벤트를 연결하지 못해서 문서 간 추론이 실패한다는 의미예요.
오래된 임베딩 또는 인덱스는 검색되는 데이터가 어제의 상태를 반영한다는 뜻이에요.
고급 RAG 아키텍처는 모델이 보고 추론하는 방식을 개선해줘요. 더 나은 증거를 찾고, 중요한 정보만 유지하고, 소스 전체를 연결하고, 인용을 통해 결과를 확인하기 때문에 답변이 정확하고 설명 가능하며, 대규모 환경에서도 반복적으로 사용할 수 있게 되는 거죠.
순진한 RAG와 고급 RAG를 비교하는 인포그래픽
이를 실현하는 데 도움이 되는 고급 RAG의 장점 및 기술
고급 RAG는 보통 더 나은 검색, 더 나은 컨텍스트 관리, 더 나은 답변 생성을 의미해요. 아래에는 고급 RAG 아키텍처와 고급 기술의 주요 장점이 나와 있어요.
향상된 검색 품질 및 관련성
검색은 모델이 무엇을 볼지 결정하죠. 대부분의 프로덕션 RAG는 Semantic Search에는 강하지만, 희귀한 용어, ID, 약어는 놓칠 수 있는 조밀한 검색(임베딩)으로 시작해요. 고급 검색은 정밀도, 적용 범위, 구조를 계층화하는 기술을 통해 이 기준을 훨씬 뛰어넘어요.
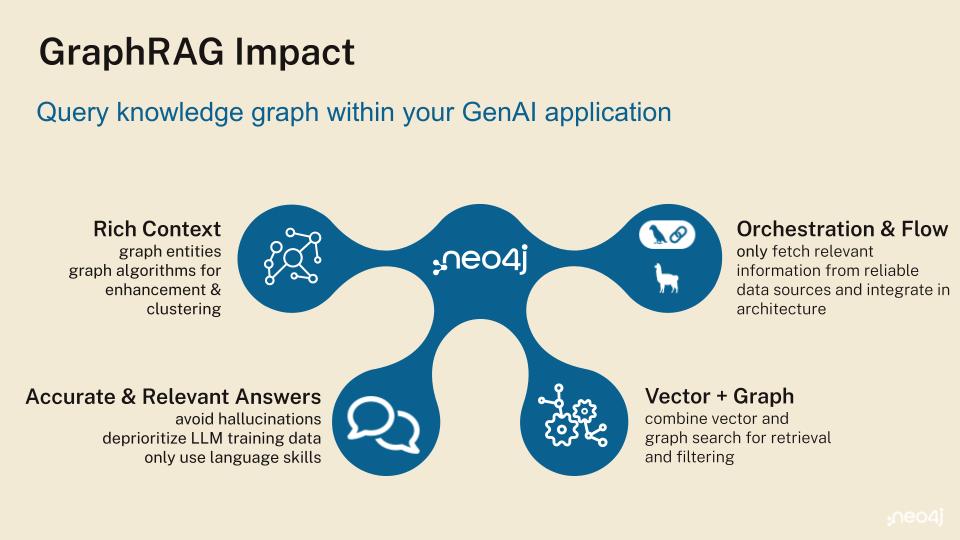
Knowledge Graph 검색(GraphRAG)
콘텐츠에 풍부한 엔터티와 관계(예: 사람, 제품, 사례, 인용)가 있다면, Knowledge Graph를 사용해서을 파악할 수 있어요. 단순히 비슷한 텍스트가 아니라요. 그래프 순회와 벡터 검색을 섞어서 프롬프트에 대한 정확하고 연결된 컨텍스트를 만들 수 있죠.
그래프가 왜 중요할까요? 벡터/Semantic Search는 로컬 조회에 강하지만, 글로벌한 질문이나 문서 간 질문, 여러 단계를 거치는 관계에서는 어려움을 겪어요. 소스를 엔터티와 관계로 모델링한 다음, 두 가지 방법으로 검색하는 거예요. 첫째, 로컬 순회를 실행해서 초기 검색 결과 주변의 관련 엔터티와 경로를 가져오고, 둘째, 큰 그림에 대한 질문에는 글로벌 커뮤니티 요약을 사용하는 거죠. 이구조화된 접근 방식을 사용하면 특정 정보를 훨씬 쉽게 검색하고 사용할 수 있어서, 더 정확하게 답변할 수 있는 질문의 유형이 훨씬 더 많아져요.
하이브리드 검색(Semantic + 어휘적)
Semantic Search는 쿼리와 문서를 의미에 따라 일치하도록 Vector Embedding으로 인코딩해요. 어휘 검색(예: BM25 또는 SPLADE)은 정확한 용어와 일치시키죠. Semantic Search는 의미를 이해하는 데 뛰어나지만 ID, 코드, 고유 명사와 같은 희귀한 용어를 놓칠 수 있어요. 하이브리드 검색은 이 두 가지를 모두 포함하는데요. 키워드 기반 검색기와 조밀한 임베딩을 결합한 다음, 상호 순위 융합(RRF, Reciprocal Rank Fusion)을 사용해서 결과를 합쳐요. RRF는 순위 목록을 병합하는 표준 방법인데, 모델이 올바른 의미와 올바른 토큰을 모두 포함하는 구절을 볼 수 있도록 해준답니다.
필터링
원시 문서에서 해당 필드를 추출하거나 강화한 후 메타데이터 규칙(소스, 날짜, 작성자, 문서 유형) 및 의미론적 임계값을 적용해요. 이렇게 하면 순위 재지정 전이나 도중에 품질이 낮거나 관련 없는 히트를 제거해서 즉각적인 팽창을 줄이고 접지를 향상시킬 수 있어요.
순위 재지정
첫 번째 통과 후 크로스 인코더 또는 재순위 서비스를 통해 순위를 다시 매기면 LLM에 보내는 상위 k개가 정말 최고가 될 거예요. 순위 재지정은 일반적으로 첫 번째 통과 검색 후에 사용될 때 상위 k 순서를 향상시켜 준답니다.
문서 검색 및 사용을 더욱 쉽게 만들어요
원시 문서는 Prompt에 깔끔하게 들어맞는 경우가 거의 없죠. 분할 방법, 구조 유지 방법, 메타데이터 추가 방법, 컨텍스트 압축 방법에 따라 검색되는 항목과 빠듯한 토큰 예산에서 해당 항목이 얼마나 유용한지가 결정돼요.
신호를 유지하고, 노이즈를 줄이고, 모델에 중요한 부분을 보내는 방법은 다음과 같아요.
청킹
청크 크기와 경계는 검색 품질에 큰 영향을 미쳐요. 기본적으로 고정 크기 또는 문장 인식 분할, 경계가 지저분한 경우 의미론적 청크의 레이어, 구조가 중요한 경우(테이블, 헤더, 코드) 문서 인식/적응형 청커에 도달하게 되죠. 배선할 준비가 되면, LangChain 텍스트 분할 문서에 드롭인 예시가 있으니 참고해보세요.
부모 리트리버
더 작은 "하위" 청크를 검색하고 동일한 섹션의 많은 하위가 나타날 때 "상위" 블록을 교체해서 문서 구조를 그대로 유지해서 컨텍스트를 유지하고 조각난 Prompt를 줄여줘요.
텍스트 요약/컨텍스트 증류
더 많은 관련 정보가 창에 들어가고 모델이 올바른 사실에 초점을 맞출 수 있도록 조회수를 요약해요. 대부분의 스택은 GraphRAG는 쿼리 중심 요약을 사용하고, LangChain에는 ContextualCompressionRetriever가 있고 LlamaIndex는 트리/정제 합성기를 제공하고 있어요.
대화를 위한 기억력 강화
다중 턴 채팅의 경우 대화 기록을 추적하고 검색 기반 메모리를 사용해서 시스템이 전체 대화 내용을 삽입하는 대신 과거 턴을 선택적으로 호출하도록 해요. 이를 동적 컨텍스트 창과 결합하면 후속 조치가 Prompt를 부풀리지 않고 올바른 컨텍스트를 상속받을 수 있게 된답니다.
쿼리 이해도 향상
때로는 질문을 작성하는 방식이 문서를 작성하는 방식과 일치하지 않는 경우가 있죠. 질문을 다시 작성하거나 확장할 수 있도록 작은 쿼리 이해 레이어를 추가하고, 오버페치 없이 올바른 구절을 찾는 데 더 나은 검색 기회를 제공할 수 있어요. 이 단계를 간단하고 검사 가능하게 유지하는 게 중요해요.
검색 변형으로서의 가상 질문
대표적인 질문(또는 HyDE 스타일 접근 방식에서는 가설적인 질문, 즉 )을 생성해서 각 청크에서 이를 인덱싱해요. 쿼리 시 사용자 질문을 사전 생성된 항목과 일치시켜 Semantic 정렬을 개선하는 거죠.
쿼리 확장
동의어 및 관련 용어를 추가하거나 몇 가지 쿼리 변형을 생성해서 질문과 문서 사이의 표현 격차를 해소하세요. 이는 종종 정밀도를 희생하지 않고 재현율을 향상시킨답니다 (필터링/순위 재지정과 결합된 경우).
Agentic Planning을 통해 복잡한 다단계 질문 처리
다단계 질문에는 Agentic Planning이 필요한 경우가 많아요. 에이전트 루프라고도 하는 이 접근 방식은 에이전트가 문제를 하위 질문으로 나누고, 각 질문에 적합한 도구(Graph 쿼리, 하이브리드 검색, 계산기)를 선택하고, 루프를 조정하는 작업(계획 → 경로 → 실행 → 확인 → 중지)을 포함해요. 이렇게 하면 적용 범위, 출처, 추측을 줄일 수 있죠. 고급 Agentic Planning이 실제로 어떻게 수행되는지 한번 살펴볼까요?
다단계 추론 또는 다중 홉 QA
어떤 질문들은 사람, 사건, 시간에 걸쳐 사실들을 연결해야 해요. 단일 top-k 풀로는 링크가 누락되는 경우가 많죠. 복잡한 질문을 더 작은 하위 질문으로 나누고, 에이전트가 각각을 최상의 검색자(관계/조인의 경우 Graph/Cypher, 사실 및 날짜의 경우 하이브리드/Semantic + 어휘)로 라우팅한 다음, 청구별 인용으로 합성하는 거예요. 홉이 약한 증거를 반환하는 경우 검색을 확장하거나 마무리하기 전에 명확한 질문을 해야 해요.
Agentic Planning 워크플로
추적 가능한 소스로 이어지는 충분한 고품질 증거가 있는 홉의 비율을 높이려면 Agentic Planning을 사용하여 단계를 계획하고, 각 단계를 올바른 도구로 라우팅하고, 증거를 확인하고, 답변이 지원되면 중지하는 거예요. 이는 출처를 보존하고 환각을 줄여주죠. 다단계 질문에 대한 간단한 체크리스트로 아래 사항을 사용해 보세요.
질문을 구체적인 작업(찾을 엔터티, 기간, 조인/경로)으로 나누세요.
작업별로 가장 적합한 도구를 선택하세요(관계 및 조인을 위한 Graph/Cypher, 사실/날짜를 위한 하이브리드 검색, 필요한 경우 계산기/코드).
쿼리 또는 검색을 실행하고 출처와 함께 증거를 수집해요.
적용 범위(각 하위 목표에 강력한 증거가 있나요?)와 충돌(소스가 일치하지 않나요?)을 확인하세요. 약하다면 다시 시도하거나 접근 방식을 넓히거나 도구를 전환하세요.
모든 하위 목표가 충족되거나 예산(최대 홉/도구 호출/토큰)에 도달하면 종료해요. 청구별로 인용하여 답변을 제공하거나 누락된 증거를 명시하세요.
CoT(Chain of Thought Prompting)
일부 작업은 모델이 성급하게 답을 찾는 대신 단계별로 계획하거나 추론할 때 이점을 얻어요. CoT를 에이전트의 개인 스크래치 패드로 사용하여 홉의 개요를 설명하고 중간 결과를 추적한 다음 인용문과 함께 간결하고 소스 기반 답변을 반환하는 거죠. CoT는 다단계 추론을 개선하지만 엄격한 기본 규칙이 필요해요(예: "검색된 소스에서만 답변하고 지원되지 않는 경우 '모름'이라고 말함"). 더 높은 정확도를 위해 여러 계획/체인 후보를 샘플링하고 가장 잘 지원되는 합성을 선택할 수 있어요. 단순한 조회나 대기 시간에 민감한 작업이 아닌 추론이 많은 쿼리에 CoT를 사용하세요.
확실한 답변과 환각 감소
검색이 잘 되더라도 모델은 뒷받침하는 구절이 얇거나 주제에서 벗어난 경우 여전히 추측할 수 있어요. 다음 수정 사항을 사용하여 데이터의 증거와 연결된 답변을 유지하고 검색이 충분히 강력하지 않은 경우 간단한 안전 확인을 추가해 보세요.
Grounding
검색된 소스에서만 응답하도록 모델에 지시하세요. 프롬프트에 다음을 추가하십시오: "아래에 나열된 검색된 출처에서만 답변하십시오. 답변이 지원되지 않으면 '모르겠습니다'라고 말하십시오. 주장 옆에 출처/인용 ID를 포함하십시오."
엄격한 프롬프트를 참조 태그 또는 인용 ID와 결합하고 지원되지 않는 텍스트를 차단하세요. (이는 프롬프트 템플릿과 평가 기준표에 속해요.)
교정 RAG(CRAG)
강력한 검색 파이프라인이 불완전하거나 관련 없는 컨텍스트를 반환하는 경우 CRAG는 가벼운 피드백 루프를 추가해요. 생성하기 전에 시스템은 검색된 세트가 충분한지 확인하죠. 약한 것으로 보이면 시스템은 또 다른 검색 패스를 트리거하거나 더 엄격한 필터를 적용한 다음 진행해요. 이 자체 점검 단계는 환각을 줄이는 데 도움이 되며 더 강력한 증거와 연결된 답변을 유지해 줘요.
고급 RAG 파이프라인을 구축하는 방법
먼저 데이터를 Knowledge Graph로 구성한 다음 그래프 인식 검색 및 에이전트 계획-경로-작업-검증-중지 루프를 계층화하여 고급 RAG 시스템을 구축하세요. LangChain/LangGraph 또는 LlamaIndex와 같은 프레임워크 경로를 선택하고 검색, 답변 품질 및 운영 지표를 통해 영향을 측정하세요.
소스 구조화
PDF/웹/텍스트의 엔터티, 관계 및 주요 속성을 Property Graph(Node, Edge, 속성)로 추출합니다. 출처(소스 ID, 범위, 타임스탬프)와 청크 또는 Node당 선택적 Vector Embedding을 유지하여 Graph 홉을 어휘/Semantic 검색과 혼합할 수 있어요. 경량 스키마를 조기에 정의합니다(엔티티/Edge 유형, 필수 속성). 추출된 필드에 신뢰도 점수를 저장하고 쿼리 시 신뢰도가 낮은 메타데이터의 가중치를 낮추거나 무시하세요.
복잡한 질문에 에이전트 계획 사용
다중 홉/글로벌 질문의 경우 간단한 루프를 실행하세요.
하위 목표(엔터티, 조인/경로, 기간)를 계획합니다.
각 하위 목표를 최상의 도구로 라우팅합니다. 관계 및 조인을 위해 Graph 쿼리 언어(예: Property Graph의 Cypher)를 통한 Graph 순회. 사실, 이름, 날짜에 대한 하이브리드 검색(어휘 + Semantic) 변환을 위한 선택적 계산기/코드.
실행 및 확인: 실행, 적용 범위/충돌 확인, 글로벌 질문 및 경로 제한 순회(유형/시간 제약이 있는 k-hop)에 대한 커뮤니티/클러스터 요약을 사용하여 컨텍스트를 정확하고 감사 가능하게 유지합니다. 증거가 약한 경우 도구를 확대하거나 전환합니다. 개방형 도구 사용을 방지하기 위해 종료 기준 및 예산(최대 홉/도구 호출/토큰)을 적용합니다. 모든 하위 목표가 충족되거나 예산에 도달하면 중지합니다.
고급 RAG 전술을 평가하세요
평가를 인색하게 하지 마세요. 다음을 측정하여 견고한 평가 기준선을 만들 수 있어요.
검색된 컨텍스트 관련성. 문맥이 실제로 질문에 유용한가요?
기초/신뢰성. 답변이 검색된 소스에 얼마나 충실한가요?
관련성 응답. 사용자의 질문에 제대로 답변하고 있나요?
검색을 위한 순위 측정 항목. 예를 들어, End-to-End UX에 대한 MRR/Recall@k 및 대기 시간을 추적하세요.
그래프를 소개할 때 간단한 설명을 덧붙여 보세요. 예를 들어 어떤 Node/Edge와 구절이 답변을 뒷받침하는지 보여주는 거죠. 이렇게 하면 신뢰도가 높아지고 디버깅도 더 쉬워질 거예요.
고급 RAG 기술을 사용한 실제 계획
연습만이 살길이죠! 다음 순서를 따라 개선 사항을 안전하게 추가하고, 실제로 어떤 부분이 효과적인지 확인해 보세요. 하나를 변경하고 측정한 다음, 다음 단계로 넘어가는 거예요.
기본 검색 안정화: 좋은 Embedding, 합리적인 청크, 깔끔한 메타데이터로 시작하세요. 상위 k개의 결과가 더 강력해지도록 순위 조정기를 추가한 다음, 기준선을 설정하기 위해 측정하는 거예요.
하이브리드 검색 추가: BM25를 벡터와 결합(Reciprocal Rank Fusion 또는 RRF를 통해)하여 정확한 토큰과 Semantic Search를 모두 잡아내세요. 정밀도@k, Recall@k 및 접지도를 추적하여 개선 효과를 확인하는 거죠.
쿼리 이해 도입: 쿼리 확장 및 HyDE(가설 질문/문서)를 사용하여 구문 격차를 해소하고, 과도하게 가져오지 않으면서 Recall을 개선해 보세요.
컨텍스트 공급 최적화: 더 많은 내용을 담을 수 있도록 상위 문서 논리와 요약/컨텍스트 증류를 활용하세요. 콘텐츠를 창 안에 넣어두는 거죠.
데이터를 엔터티 및 관계로 구성: 주요 엔터티(사람, 조직, 제품, ID) 및 출처와의 관계를 추출하고 정규화한 다음, 이를 경량 Knowledge Graph에 로드하세요. 검색 시 구절뿐만 아니라 경로도 가져올 수 있도록 텍스트와 함께 Node/Edge를 인덱싱하는 거예요.
상담원의 다단계 Q&A 활성화: 에이전트를 사용하여 다중 홉 질문을 처리하세요. 하위 목표를 계획하고, 각 목표를 올바른 도구로 라우팅하고, 실행하고, 적용 범위를 확인하고, 충돌을 해결하고, 예산 내에서 중지하고, 청구별 인용 및 감사 가능한 경로로 답변을 반환하는 거죠.
접지 강화: 엄격한 Prompt, CRAG 스타일 검색 확인 및 환각을 줄이기 위한 인용 태그를 사용하여 검색된 소스에 대한 답변을 고정하세요.
고급 RAG 연습 시작
데모에서 실제로 신뢰할 수 있는 시스템으로 만들고 싶으신가요? 테스트 쿼리의 작은 기준과 몇 가지 측정 항목으로 프로세스를 시작해 보세요. 그런 다음 한 번에 하나씩 변경하고 그 영향을 측정하는 거죠.
한 번에 하나의 개선 사항을 선택하세요. 순위 재지정 또는 하이브리드 검색으로 시작하는 게 좋아요. 둘 다 위험은 낮고 효과는 크거든요. 고정된 평가 세트에서 변경 사항을 측정하세요.
파이프라인을 추적하세요. 각 답변에 대해 검색된 청크, 점수, 그래프 경로 및 인용을 기록해 두세요.
선택한 프레임워크와 통합하세요. LangChain, LangGraph 또는 LlamaIndex와 같은 프레임워크는 고급 RAG 파이프라인을 조율하는 데 도움이 될 수 있지만, 그래프 인식 부분은 Neo4j의 생태계에서 나온답니다.
LangChain / LangGraph: 오케스트레이션에 사용하세요 (예: 하위 질문을 올바른 도구로 라우팅, 에이전트 관리 및 처리 계획 → 라우팅 → 조치 → 확인 → 루프 중지). 다음과 같은 Neo4j의 GenAI 생태계 구성 요소와 결합하세요. LLM Graph Builder (Knowledge Graph 생성) 및 Model Context Protocol (에이전트와 LLM을 그래프 쿼리에 연결하기 위해). 다음 블로그 게시물을 읽고 neo4j-advanced-rag 템플릿을 LangServe를 사용하여 호스팅하는 방법을 배워보세요.
LlamaIndex: 경로 경계 순회 및 하위 질문 분해를 위해 그래프 인덱스/쿼리 엔진을 사용하세요. 문서 검색기와 그래프 검색을 결합하고 사후 프로세서(중복 제거, 압축)를 적용하고 생성 전에 순위를 다시 지정하는 거죠. 상위-하위 검색 또는 Embedding 하이브리드는 구조 또는 다중 홉 추론이 중요한 경우 특히 유용해요.
CRAG 패턴을 채택하세요. 법률, 규정 준수 또는 엄격한 SLA에 따른 지원 편향과 같은 고위험 영역에서는 필수적이에요.
규모를 계획합니다. 하이브리드 Index, ANN(Approximate Nearest Neighbor) 및 일반 Query 캐싱을 사용해서 품질 저하 없이 대기 시간을 줄여보세요. 최적화하면서 평가를 계속 실행하는 것도 중요해요.
여기에서 어디로 가야합니까?
Advanced RAG는 검색, 컨텍스트 관리 및 생성 전반에 걸쳐 꾸준하고 점진적인 개선을 제공해요(단일 트릭이 아니라는 점!).
RAG 출시 준비를 완료하려면 순위 재지정 및 하이브리드 검색으로 시작해서 Query 이해 및 컨텍스트 증류를 추가하고 Knowledge Graph를 통해 다단계 추론을 도입해보세요. 고급 RAG 패턴은 향상된 관련성과 설명 가능성을 통해 그래프 기반 검색의 이점을 얻을 수 있어요. LLM과 결합된 Neo4j Knowledge Graph는 다음을 제공한답니다.
관련성: 단순한 Vector Embedding 검색에 비해 더 관련성이 높은 답변을 얻을 수 있어요.
문맥: 해당 주제에 대한 도메인별, 사실적, 구조화된 지식을 포함하고 있죠.
설명 가능성: 사용자에게 결과를 얻은 방법에 대한 추가 추론을 제공해요.
보안: Label, Relationship 및 속성에 대한 세분화된 권한을 갖춘 역할 기반 액세스 제어(RBAC)를 제공합니다.
지금 무료 가이드를 통해 첫 번째 GraphRAG 애플리케이션을 구축하는 방법을 알아보세요.
필수 GraphRAG
Knowledge Graph를 통해 RAG의 잠재력을 최대한 활용하세요. 한정된 기간 동안 Manning으로부터 최종 가이드를 무료로 받아보세요.
고급 RAG: FAQ
고급 RAG 기술에는 어떤 것이 있나요?
기본 파이프라인이 여전히 정확한 식별자를 놓치거나 환각을 느끼는 경우에는 보다 정확한 결과를 얻고, 구조를 유지하고, 근거 있는 답변을 유지하는 기술이 필요해요.
하이브리드 검색(벡터 + 키워드), 메타데이터 필터링, 순위 재지정, 구조 인식 청크/상위 문서로 시작해 보세요. 그런 다음 필요에 따라 레이어 요약, 쿼리 확장/HyDE, 다단계 추론, 접지/CRAG 및 검색 기반 메모리를 수행합니다.
고급 RAG 기술은 어떻게 복잡한 쿼리의 정확성을 향상합니까?
검색에 적용 범위가 부족하고 모델이 추측하는 경우 복잡한 질문은 실패할 수 있어요. 이러한 방법은 접지를 유지하면서 재현성과 정밀도를 높여주죠. 하이브리드 + 확장은 올바른 문서를 찾고, 순위 재지정 및 상위 문서/요약은 올바른 구절을 표면화하며, CRAG는 여러분이 답변하기 전에 약한 증거를 포착합니다.
RAG 시스템을 향상시키는 데 Knowledge Graph는 어떤 역할을 합니까?
Knowledge Graph는 흩어져 있는 문서, 표, API를 연결된 데이터 그림으로 통합합니다. 매핑된 엔터티와 관계를 통해 GraphRAG는 해당 연결을 검색하여 명확성을 개선하고 다중 홉 답변을 지원하며 소스를 추적 가능하게 유지합니다.
rag
지식 그래프와 대규모 언어 모델: GenAI의 잠재력 활용
여러분, 안녕하세요! 🎉 오늘은 Knowledge Graph와 Large Language Model (LLM)을 결합하여 GenAI의 잠재력을 극대화하는 방법에 대해 이야기해볼 거예요. 정말 흥미롭겠죠?
최근 몇 년 동안 GenAI 분야는 엄청난 발전을 이루었어요. 특히 LLM은 텍스트 생성, 번역, 요약 등 다양한 작업에서 뛰어난 성능을 보여주고 있죠. 하지만 LLM은 세상에 대한 명확한 이해 없이 방대한 양의 텍스트 데이터를 기반으로 작동하기 때문에 때로는 부정확하거나 일관성 없는 결과를 내놓기도 해요.
바로 이 지점에서 Knowledge Graph가 등장합니다! Knowledge Graph는 엔터티 간의 관계를 구조화된 방식으로 표현하여 LLM에 필요한 컨텍스트와 의미를 제공할 수 있어요. Knowledge Graph와 LLM을 함께 사용하면 GenAI 애플리케이션의 정확성, 신뢰성, 효율성을 크게 향상시킬 수 있답니다.
Knowledge Graph란 무엇일까요?
Knowledge Graph는 엔터티(예: 사람, 장소, 사물, 개념)와 그 관계를 그래프 형태로 표현한 것이에요. 각 엔터티는 Node로 표현되고, 관계는 Edge로 표현되죠. Property Graph는 Node와 Edge에 속성을 추가하여 더 풍부한 정보를 담을 수 있도록 해줘요.
Knowledge Graph는 다음과 같은 장점을 가지고 있어요:
구조화된 지식: 세상에 대한 정보를 체계적으로 정리하여 LLM이 더 쉽게 이해할 수 있도록 도와줘요.
추론 능력: 명시적으로 표현되지 않은 새로운 사실을 추론할 수 있어요.
컨텍스트 인식: 질문에 대한 답변에 필요한 컨텍스트를 제공하여 정확도를 높여줘요.
설명 가능성: 추론 과정을 추적하여 결과에 대한 설명이 가능하게 해줘요.
LLM이란 무엇일까요?
LLM은 방대한 양의 텍스트 데이터로 학습된 Deep Learning 모델이에요. 텍스트 생성, 번역, 요약, 질문 응답 등 다양한 Natural Language Processing (NLP) 작업을 수행할 수 있어요. LLM은 문맥을 이해하고 인간과 유사한 텍스트를 생성하는 데 매우 뛰어나지만, 세상에 대한 실제 지식이 부족하다는 단점이 있죠.
Knowledge Graph와 LLM의 결합
Knowledge Graph와 LLM을 결합하는 방법은 여러 가지가 있어요. 몇 가지 일반적인 방법을 한번 살펴볼까요?
Retrieval-Augmented Generation (RAG): LLM이 답변을 생성하기 전에 Knowledge Graph에서 관련 정보를 검색하여 활용하는 방식이에요.
Fine-tuning: Knowledge Graph의 정보를 사용하여 LLM을 Fine-tuning하는 방식이에요.
Knowledge Graph와 LLM을 결합하면 다양한 GenAI 애플리케이션을 개발할 수 있어요. 몇 가지 예를 들어볼게요.
Semantic Search: Knowledge Graph를 사용하여 검색어의 의미를 이해하고, 관련성 높은 결과를 제공하는 Semantic Search 엔진을 만들 수 있어요.
질문 응답 시스템: Knowledge Graph를 기반으로 질문에 대한 정확하고 맥락에 맞는 답변을 제공하는 질문 응답 시스템을 구축할 수 있어요.
챗봇: Knowledge Graph를 활용하여 더 자연스럽고 유용한 대화를 제공하는 챗봇을 개발할 수 있어요.
콘텐츠 생성: Knowledge Graph의 정보를 바탕으로 고품질의 콘텐츠를 자동으로 생성할 수 있어요.
Neo4j: Knowledge Graph를 위한 최고의 Graph Database
Neo4j는 Knowledge Graph를 구축하고 관리하기 위한 최고의 Graph Database 중 하나예요. Neo4j는 Property Graph 모델을 지원하며, 강력한 쿼리 언어인 Cypher를 제공하여 Graph 데이터를 쉽게 쿼리하고 분석할 수 있도록 도와줘요. 또한 APOC와 GDS 같은 다양한 플러그인을 통해 Neo4j의 기능을 확장할 수 있죠. 클라우드 기반의 AuraDB를 사용하면 더욱 편리하게 Knowledge Graph를 구축하고 운영할 수 있답니다.
결론
Knowledge Graph와 LLM은 GenAI의 잠재력을 최대한 활용하기 위한 강력한 조합이에요. Knowledge Graph는 LLM에 필요한 구조화된 지식과 컨텍스트를 제공하고, LLM은 Knowledge Graph의 정보를 활용하여 더욱 정확하고 유용한 결과를 생성할 수 있어요. Neo4j와 같은 Graph Database를 사용하면 Knowledge Graph를 쉽게 구축하고 관리할 수 있으며, 이를 통해 다양한 GenAI 애플리케이션을 개발할 수 있답니다.
여러분도 Knowledge Graph와 LLM을 활용하여 GenAI의 세계를 탐험해보세요! 정말 멋진 경험이 될 거예요! 😊
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
지난 365일 동안 Neo4j와 함께 하면서 회사 문화에 대한 지식과 통찰력, 스웨덴 '라곰'의 "딱 맞는 양"이라는 이념과 실천, 그리고 동료 `Node`들로부터 배우는 점들을 검색 없이도 발견할 수 있었어요. 심지어 저 자신과의 관계도 편안해졌답니다.
입사하기 전에는 일에만 집중하는 경향이 있었고, 일과 삶의 균형을 중요하게 생각하지 않았어요.
조화와 균형을 지지하고 기념하는 '라곰'은 Neo4j 정신에 깊이 뿌리내려 있어요. 분기별 글로벌 웰니스 데이와 같은 기업 이니셔티브, 그리고 사회적 책임을 위한 시간과 공간을 장려하는 것만 봐도 알 수 있죠.
'라곰'을 실천하면서 가족, 친구들과의 관계도 훨씬 더 좋아졌어요.
맥락상 회사 문화를 정의하는 Neo4j의 가치 중 하나는 "긍정적인 의도"인데요. 이는 비록 당신이 그들이나 그들의 결정에 동의하지 않을지라도 다른 사람들이 공동의 이익을 위해 일하고 있다는 심오하고 논리적인 가정이에요. 의사소통에서 긍정적인 의도를 가정함으로써 우리는 신뢰를 구축하고 감정이 아닌 인내와 차분하고 논리적인 사고가 필요한 상황에서 팀이 성공할 수 있도록 돕죠.
단순히 서로를 먼저 이해하려고 노력함으로써 불일치와 갈등이 최소화되고, 사내 정치가 위축되며, 강화된 협력을 통해 우리 모두의 집단적, 개인적 목표를 달성할 수 있어요.
제가 확립한 또 다른 관계는 동료 `Nodes`들과의 관계인데요. 매우 긍정적인 태도를 지닌 똑똑한 사람들과 함께 일하는 것은 일과 삶의 조화를 유지하는 데 엄청난 도움이 되었어요. 그들은 심지어 제가 쉬어야 할 때 쉬도록 하기도 해요.
APAC 지역의 우리 팀은 10배 이상 성장했고, 마케팅 팀의 규모는 3배나 늘어났어요. 팬데믹 기간 동안 지역 전역의 15개 이상의 도시에 기반을 둔 팀과 함께 협력하고 결속하는 것이 어려운 일이 되었죠. 시간대, 다양한 문화, 유행성 스트레스는 모든 사람에게 부담이 될 수 있으며, 특히 아주 어린 팀의 경우 더욱 그렇고요.
고립감을 극복하기 위해 우리는 세션 중에 비즈니스 대화를 하지 않는다는 규칙에 따라 가상 점심 세션을 설정했는데요. 이는 우리가 서로를 더 잘 이해하는 데 도움이 되었어요.
또한, 내 삶의 큰 부분이 공식적으로 인정되고 평등의 혜택을 받게 되면서 나와 나 자신의 관계는 지난 1년 동안 더욱 현실적이고 가시적으로 변했어요.
Neo4j에 오기 전에 관계는 제가 알고 있었지만 집중하지 않았던 것이었는데요. 연결과 관계를 이해하고 기술이 삶을 모방하는 것처럼 데이터 포인트 간의 경로가 인간의 삶으로 확장된다는 점을 인식함으로써 관계를 더 잘 이해하기 시작해요. 이를 실천하면 관계가 깊어지고 개선되며 상승 순환이 시작되죠.
그래프 데이터 플랫폼과의 관계를 강화하고 기술보다 더 광범위한 영향력과 구현을 통해 그 가치를 증폭시키고 크고 작은 기업에 헤아릴 수 없는 이점을 제공해요.
APAC 마케팅 팀 내의 관계는 다른 기능의 다른 팀 구성원으로 확장된 다음 Neo4j 외부의 다른 국가, 지역 및 커뮤니티로 확장되는데요. 관계망은 파트너, 개발자, 정부, 고객 및 잠재 고객으로 확장돼요. 모든 것이 연결되어 있는 거죠.
전체적으로 이러한 관계는 2021년을 저에게 멋진 한 해로 만드는 데 도움이 되었어요. 그리고 이 관계는 이제 막 시작되었는데요. 우리는 2022년에도 APAC에서 관리형 성장 전략을 계속하여 팀원들과 양질의 관계를 발전시키는 데 집중할 거예요. 뉴노멀을 통해 우리가 서로 직접 만날 수 있게 되기를 바라며, 이를 통해 지금까지의 가상 관계가 더 높은 수준의 상호 연결된 평면으로 발전할 거예요.
나는 더 많은 것을 기대하고 그 이하도 기대하지 않아요.
Neo4j에서의 생활에 대해 더 자세히 알고 싶으신가요? 우리를 팔로우하세요지저귀다, 페이스북, 그리고링크드인, 채용 페이지를 확인해 보세요.
APAC
Neo4j의 노드
Neo4j의 사람들
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
편집자 주: 이 프레젠테이션은 Tatiana Hartinger가 GraphConnect New York 2018년 9월에 진행했어요.
프레젠테이션 요약
Tatiana Hartinger는 수학자이자 그래프 이론을 전문으로 하는 인지 솔루션 컨설턴트예요. Cognitiva는 그래프를 사용해서 가상 비서를 향상시키고 있다고 해요.
Cognitva는 IBM의 Watson Assistant와 Neo4j 기반의 Graph Database를 결합했대요. 문제는 가상 비서가 고객의 요청과 관심사에 맞춰 빠른 추천을 제공해야 한다는 점이죠.
Watson Assistant는 Intents와 Entities를 사용하는데요. Intent는 사용자 입력의 목적을 나타내고, Entity는 Intent와 관련된 용어나 개체를 의미해요.
그래프에서 가상 비서에 사용되는 `정점(vertex)`에는 다양한 유형이 있어요. `정점(vertex)`은 색상으로 구분되어 있고, 각 `정점(vertex)`에는 `유형(type)` 값이 있는데, 이 `유형(type)` 값은 `정점(vertex)`의 질문에 대한 가능한 답변이 되는 거죠.
가상 비서와 Neo4j를 결합하기 위해 Cognitiva는 둘 사이를 오가는 Python 스크립트를 사용하고 있어요.
코드는 크게 세 부분으로 나눌 수 있어요.
Neo4j에서 그래프 생성
`정점(vertex)`과 `엣지(edge)`를 생성하는 데 사용되는 함수는 `엣지(edge)`의 가중치를 계산하는 데 사용돼요.
코드의 일부를 사용하면 Neo4j에서 `쿼리(query)`를 작성하는 동안 Watson Assistant의 대화 상자를 연결할 수 있어요.
솔루션이 어떻게 작동하는지 설명하기 위해 Hartinger는 영화 추천 예시를 사용해서 이 솔루션의 이점과 잠재력을 요약하고 있어요.
이 기술은 언젠가 특정 제품 판매, 예비 의료 진단, 환자 지원 및 상호 작용이 문제 해결의 핵심 단계인 기타 분야로 확장될 수 있을 거예요.
전체 프레젠테이션
저는 수학자이고 박사 과정에서 Graph Theory를 전공하고 있는 타티아나 하팅거에요. 현재 아르헨티나 부에노스아이레스의 Cognitiva에서 인공지능 관련 솔루션을 구현하는 기술 분야의 인지 솔루션 전문가로 일하고 있습니다.
저희가 구현하는 솔루션 중 하나는 다양한 회사를 위한 가상 비서 솔루션인데요, 통신 회사, 금융 서비스, 헬스케어 산업 분야에서 활용되고 있어요.
이번 내용은 페데리코 코스타, 하비에르 포르틸로와 함께 작업한 내용을 바탕으로 하고 있습니다.
저희 팀 리더가 그래프를 사용해서 가상 비서를 향상시키자는 아이디어를 냈을 때, 솔루션 개발에 착수하게 되었어요. 그때부터 어떻게 구현할 수 있을지 조사하기 시작했고, 마침내 해결책을 찾았죠.
소개
저희는 IBM의 AI Watson Assistant 기술과 IBM이 지원하는 Graph Database를 결합했어요. 고객의 선호도나 니즈에 따라 추천을 제공하고 싶었고, 가능한 한 빠르게 결과를 얻고 싶었거든요.
여기서 공유하는 예시는 영화 추천이지만, 사실 모든 유형의 추천이나 검색에 적용할 수 있어요. Graph Database에는 추천에 필요한 모든 정보가 담겨 있답니다.
중요한 점은, 저희가 선택한 지표를 사용해서 계산한 특정 연령대에 대한 가중치가 그래프에 있다는 거예요. 이 엣지 가중치는 가장 빠른 방법으로 추천 프로세스를 수행할 수 있게 해주는 핵심 요소랍니다.
해결하고 싶었던 문제
저희 목표는 가상 비서 환경에서 요청이나 관심사를 기반으로 고객에게 빠른 추천을 제공하는 것이었어요.
이것이 고객과의 첫 번째 소통이라고 가정해볼 수 있어요. 고객의 선호도나 좋아하는 것에 대한 사전 지식이 없는 상태죠. 그래서 정보를 수집해야 하는데, 여기서 가상 비서가 활약하게 돼요.
저희는 사용자의 선호도를 파악하기 위해 어시스턴트가 질문을 던지도록 설계했어요. 좋은 사용자 경험을 제공하고 싶었거든요. Watson Assistant 덕분에 자연어로 대화하는 부분은 물론, 전체 프로세스에 걸리는 시간을 최소화하고 싶었어요.
바로 이 지점에서 Neo4j를 사용한 그래프가 등장하는 거죠!
Watson Assistant Tool
IBM Watson Tool에 대해 조금 이야기해볼게요. 여기서 저희는 가상 비서를 개발했답니다.
IBM Watson Assistant를 사용하면 자연어로 입력된 내용을 이해한 다음, Query에 대한 답변을 제공할 수 있습니다.
Watson Assistant는 구조화되지 않은 데이터를 분석하고 자연어를 처리해요. 문법과 맥락을 이해하기 위해 복잡한 질문을 이해하고 각 경우에 가능한 모든 의미를 평가하는 솔루션을 교육했죠.
Watson 가상 어시스턴트는 학습 기술을 적용해서 문장이나 구문에 대해 미리 정의된 최상의 클래스를 예측한답니다.
가상 비서가 수행하는 이 "사고" 서비스는 텍스트 뒤에 숨겨진 의도를 해석하고 특정 신뢰 수준에 해당하는 분류를 반환해줘요.
선택된 값은 해당 작업을 트리거하는 데 사용되는데요. 해당 작업은 애플리케이션을 리디렉션하거나 질문에 답변하는 것일 수 있어요.
우리 봇은 각 경우에 Cognitiva의 AI 트레이너와 이 가상 비서를 위해 우리를 고용한 회사인 도메인 전문가의 특정 지식에 따라 특정 도메인에서 교육을 받아요.
Intents and Entities
Watson Assistant는 Intents 및 Entities와 함께 작동해요.
Intent란 뭘까요? 사용자 입력의 목적을 나타내요. 예를 들어, 영화 추천 요청이나 필요에 가장 적합한 제품 요청 등 무엇이든 될 수 있죠.
Entity는 Intent와 관련된 용어 또는 개체를 나타내요. 이는 우리가 사용자로부터 얻는 정보인데요. 우리 경우에는 Entity의 값으로 발생할 수 있는 다양한 질문에 대한 가능한 모든 답변을 정의해요.
Entity를 생각해보면 Genre 영화 추천의 경우 다음과 같은 값을 갖죠. drama, sci-fi, comedy, romance, 등.
오른쪽 아래에는 Watson Assistant의 대화 상자가 어떻게 보이는지 보여주는 이미지가 있어요. 보시다시피 트리와 같은 구조를 가지고 있죠. 항상 welcome Node에서 시작해서 anything-else Node로 끝나는데, 다른 모든 Node의 조건과 일치하지 않는 모든 항목이 이동하는 Node에요.
사용자가 입력을 입력할 때마다 Watson Assistant는 이 입력이 Node의 조건 중 하나에 해당하는지, Node의 이 조건이 충족되는지 확인해요. 그렇다면 해당 Node에 설정한 모든 작업이 계속 진행되죠. 우리는 답변을 제공하고 다른 특정 Node나 우리가 원하는 다른 것으로 이동할 수도 있어요.
그래프 디자인
Neo4j를 이용한 그래프 디자인에 대해 말씀드릴게요.
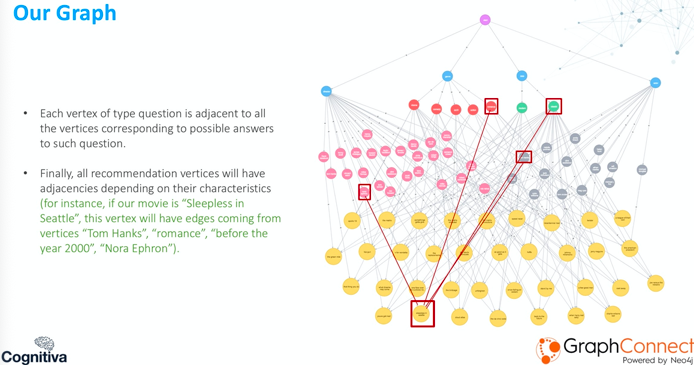
이 그래프에는 다양한 유형의 Node가 포함되어 있어요. 우리는 질문 유형별로 이러한 Node를 정의하는데요. 아래 두 번째 레이어에서 파란색으로 표시되는 Node가 바로 그거에요.
예를 들어 영화 추천을 생각해 본다면, genre, favorite actor, favorite director, 그리고 release date 정도가 있겠죠. 이런 것들이 사용자에게 물어볼 질문들이 될 거예요.
그 아래에는 type value 형태의 정점들이 있어요. 각 값은 질문에 대한 가능한 답변이 되는 거죠.
분홍색 부분에는 가능한 모든 directors가 있는데, 이들은 type question director 정점에 인접해 있어요. 빨간색은 영화의 가능한 모든 genres를 가지고 있고요. 초록색에는 다양한 dates 유형의 영화들이 있을 수 있겠죠.
우리의 경우, modern과 classic으로 나뉘어 있어요. 그리고 회색으로는 모든 type actor 정점이 있고, 이들은 당연히 actor 정점에 인접해 있답니다.
노란색 하단에는 추천 정점이 있는데, 이는 데이터베이스의 모든 영화들이에요. 결과는 상위권에 있죠. 우리가 이름을 붙인 더미 정점인 Start가 보이는데, 이 정점은 question type의 모든 정점에 인접하게 돼요.
앞서 말씀드렸듯이 각 type question은 해당 질문에 대한 가능한 답변에 해당하는 모든 정점에 인접하게 됩니다.
마지막으로 하단에 추천 정점이 있고, 이러한 유형의 정점에 대한 인접성은 정점의 특성에 해당해요.
영화를 본다고 해볼까요? 시애틀의 잠 못 이루는 밤을 빨간색으로 표시했어요.
그러면 Tom Hanks 엣지가 생기겠죠. 왜냐하면 그는 영화에 출연하는 배우이기 때문이에요. 그리고 Classic으로부터 오는 우위를 갖게 될 텐데, 왜냐하면 2000년 이전 영화이기 때문이죠. 또한 Romance라는 이점도 있는데, 그건 영화의 장르니까요. 마지막으로 Nora Ephron이라는 이점도 얻게 되는데, 그녀는 영화의 감독이니까요!
물론 이 예에서는 아주 작은 그래프를 보여드리고 있어요. 간단하게 유지하기 위해 배우 한 명, 감독 한 명, 장르 하나에만 인접한 영화를 만들기로 결정했죠. 물론, 실제로는 훨씬 더 많은 인접성을 가질 수 있을 거예요.
Start 정점과 vertices of type question 사이의 엣지는 엣지 가중치를 갖게 될 거예요. 이러한 가중치는 사용자에게 해당 질문을 요청할 경우 제외될 잠재적 추천의 최소 수에 해당하죠.
우리의 목표는 해당 엣지에 최대 가중치가 있는지 질문하는 거예요. 이렇게 하면 최악의 시나리오에서도 추천 정점에 더 빠르게 도달할 수 있답니다.
이 부분에 대해 좀 더 자세히 설명해 볼게요.
우리가 하는 일은 먼저 가능한 각 대답 B에 대해 질문 Q을 던져서, 질문 Q에 사용자가 응답했을 때 제외될 영화의 수를 계산하는 거예요.
그런 다음 그 답변 중 최소값을 취해서 질문 B을 던질 질문 Q, 더미 node 사이의 edge의 무게로 둬요. Start 질문 유형 node Q 사이에 말이죠.
마지막으로 우리는 어느 edge에 최대 가중치가 있는지 질문하죠. 이게 바로 우리가 물어볼 가장 좋은 질문으로 선택할 질문이 될 거예요.
이제 사용자에게 질문을 하고 답변을 얻으면 그래프가 업데이트돼요. 그런 다음 더 이상 관련이 없는 모든 vertex와 edge를 삭제하고, edge 가중치를 계산하는 거죠.
두 가지를 결합하는 방법
이제 우리 솔루션의 두 가지 측면을 어떻게 결합하는지 알려드릴게요. Watson Assistant의 가상 비서와 Neo4j의 그래프 말이죠.
이를 위해 우리는 Watson Assistant와 Neo4j 사이를 오가는 Python 스크립트를 작성했어요. JSON, Watson Developer Cloud 및 Py2neo 라이브러리를 사용했죠.
코드는 세 가지 주요 부분으로 구성돼요.
첫 번째는 Neo4j에서 그래프를 생성하는 부분이에요. 이전에 설명했듯이 몇 가지 기능을 사용해서 vertex와 edge를 만들었죠.
그런 다음 제가 언급한 edge의 가중치를 계산하는 데 필요한 몇 가지 기능이 있어요. Start와 질문 사이에요. 우리는 이전에 본 이 측정항목을 정의하고 솔루션의 각 단계에서 물어볼 가장 좋은 질문을 결정하는 함수를 만들어요. 또한 다음과 같이 그래프를 수정할 수 있는 몇 가지 기능도 있죠. Cypher, Neo4j의 쿼리 언어에요.
마지막으로 Neo4j에서 쿼리를 작성하는 동안 Watson Assistant의 대화 사이를 연결할 수 있게 해주는 코드 부분이 있어요.
우리는 이 작업에 필요한 모든 인텐트, 엔터티 및 컨텍스트 변수를 포함하는 Watson Assistant에서 이 대화 상자를 만들었어요. 의도가 감지되면 Watson은 가능한 한 최단 시간 내에 사용자를 위한 추천을 얻기 위해 필요한 질문을 계속 던지죠.
각 질문 후에 사용자의 응답은 컨텍스트 변수에 저장되고 그래프를 수정하는 데 사용돼요. 주목해야 할 중요한 점은 사용자가 하나 이상의 질문에 대해 명확한 대답을 갖고 있지 않은 경우도 고려한다는 것이에요.
이 경우 그에 따라 그래프를 수정할 거예요.
여기에 우리 솔루션의 작은 다이어그램이 있어요.
한편으로는 Watson Assistant가 있어요. 사용자와 대화를 나눈 다음 두 부분을 연결하는 코드를 작성하죠.
반면에 Neo4j에는 사용자에게 추천하는 데 필요한 모든 정보가 포함된 Graph Database가 있어요.
의도를 감지할 때마다 대화가 시작돼요. 사용자가 무언가를 입력하면 Watson이 의도를 감지하죠. 이를 통해 어떤 그래프를 봐야 하는지 알 수 있어요. 그런 다음 이 단계에서 물어볼 가장 좋은 질문을 계산하는 작업을 진행해요.
이 정보는 Watson Assistant로 다시 전달돼요. 어시스턴트는 사용자에게 해당 질문을 하고 답변을 얻은 다음, 해당 답변을 사용하여 그래프를 수정해요. 우리는 동일한 절차를 계속할 거예요.
영화 추천 예시
이 솔루션이 어떻게 작동하는지 영화 추천 예시를 보여드릴게요.
첫째, 우리는 Start vertex가 상단에 있어요. 그럼 우리는 네 가지 vertices of type 질문을 가지고 있어요. 이 예에서 고려한 질문은 director, genre, date 그리고 actor (영화의) 이에요.
그 다음 분홍색으로 표시된 유형 값의 vertex를 가지고 있어요. 모든 directors는 빨간색으로 표시되어 있고, 모든 genres 영화는 녹색으로 표시되어 있어요. 우리는 release dates를 2000년을 기준으로 classic과 modern으로 구분했어요. 그리고 회색으로는 모든 possible actors를 가지고 있어요.
마지막으로 하단에는 추천 vertex가 있어요. 추천 vertex는 우리 데이터베이스에 있는 영화들이에요. 우리는 사용자 추천으로 이러한 영화 중 하나를 찾으려고 노력하고 있어요.
이 부분의 해결방법에서 현재 그래프의 상태가 어떤지 먼저 확인해볼게요.
우리는 14개의 vertex를 가지고 있는데, type actor, 두 개의 vertex는 type date, 26개의 directors 그리고 다섯 개의 genres를 가지고 있어요. 데이터베이스에 있는 46개의 영화로 시작하죠. 사용자에게 물어볼 수 있는 질문은 네 가지에요. 우리는 더미 vertex의 이름을 Start라고 지었어요.
질문할 수 있는 네 가지 질문이 있으므로 더미 node 사이의 edge에 가중치를 부여해요. Start와 그 질문 vertex 사이에요. 제가 언급한 측정항목을 사용하여 이를 계산할 거예요.
우리는 사용자에게 영화의 배우에 대해 묻는 경우 제외될 수 있는 가능한 영화 추천 수를 계산하고, 거기에서 두 영화 사이의 edge 가중치를 얻어요. Start 와 actor 사이는 27이에요.
우리는 다른 세 가지 질문에 대해서도 동일한 작업을 수행하여 두 질문 사이의 edge 가중치를 얻어요. Start와 date 사이는 9, Start와 director 사이는 32, 그리고 Start와 genre 사이는 23이에요.
우리는 최대값을 찾고 있으므로 이 첫 번째 단계에서 선택할 가장 좋은 질문은 director에요. 이는 Watson이 사용자에게 물어볼 가상 비서죠. 여기서는 첫 번째 단계에서 그래프가 어떻게 보이는지 확인하고, 사이에 해당하는 모든 edge 가중치를 갖습니다. Start와 모든 질문 유형 vertex 사이에요.
이런 식으로 대화가 진행될 수 있어요. 먼저 비서가 "안녕하세요. 무엇을 도와드릴까요?"라고 물어보죠. 사용자는 "이번 주말에 볼 만한 영화 추천해 주실 수 있나요?"와 같이 대답할 수 있을 거예요.
이 경우 Watson Assistant는 의도, 즉 영화 추천을 감지하고 "물론입니다. 도와드리러 왔습니다."라는 응답을 시작하죠.
그때 우리는 이전에 가지고 있던 그래프를 살펴보고, 그래프에서 이 경우에 물어볼 가장 좋은 질문을 얻어내요.
우리는 이 질문이 영화 감독에 관한 것이라고 판단하고, "좋아하는 감독이 있나요?"라고 물어보죠. 이에 대해 사용자는 "별로 그렇지 않습니다."라고 대답할 수 있어요. 선호하는 감독이 없을 수도 있지만 괜찮아요.
이 경우 Watson Assistant는 엔터티를 감지하고 Director의 값은 "모르겠어요"가 되죠. 그러면 응답이 시작돼요.
"알겠습니다. 문제 없어요. 그러면 제가 선택할게요." 그리고 사용자로부터 얻은 이 정보를 디렉터라는 컨텍스트 변수에 저장하죠.
그래프를 수정하기 위해 이 컨텍스트 변수를 사용하는데요. 이제 이 단계에서 그래프가 어떻게 보이는지 한번 살펴볼까요?
그래프의 현재 상태를 보면 14개의 vertex 유형이 있어요. Director, 두 가지 유형의 Date, 다섯 개의 Genres, 그리고 여러 Movies가 있죠. 이 경우에는 여전히 36개네요. 사용자로부터 어떠한 정보도 얻지 못했기 때문에 그 어느 것도 배제할 수 없었지만, 질문 수는 3개로 줄었어요.
이제 우리는 세 가지 가능한 질문을 갖게 되었어요. 우리는 사이의 간선 가중치를 계산해야 해요. Start와 남은 세 가지 질문 사이의 가중치요.
이렇게 해서 Start와 Actor 사이의 간선에 대해 27의 가중치를 얻고, Start와 Date 사이에서 9의 가중치를 얻고, Start와 Genre 사이의 가중치는 23이 돼요.
우리는 최대값을 찾고 있으므로 이 단계에서는 영화의 배우에 대해 묻는 것이 가장 좋은 질문이라고 선택할 수 있겠죠.
이제 이 단계에서 그래프가 어떻게 보이는지 한번 살펴볼까요?
Director 타입의 vertex는 더 이상 관련 정보가 아니기 때문에 사라졌어요. 이미 사용자에게 물어봤으니 다시 물어볼 필요는 없겠죠? 그래서 가능한 질문 vertex는 세 개가 남았네요.
대화는 계속 진행될 거예요. 배우에 대해 물어봐야 한다는 걸 알고 있으니, 어시스턴트는 "가장 좋아하는 배우는 누구인가요?"라고 물어볼 거예요. 그러면 사용자는 "저는 톰 행크스의 열렬한 팬입니다!"라고 대답할 수 있겠죠.
여기서 우리는 정보를 얻고, actor 엔티티를 감지하는데, 이번에는 값이 Tom Hanks네요.
이 정보는 그래프를 수정하는 데 사용될 context variable에 저장돼요. 이제 그래프가 어떻게 보이는지 한번 살펴볼까요?
두 개의 Date 타입 vertex와 다섯 개의 Genre 타입 vertex가 있네요. 이 단계에서는 가능한 추천 영화 수가 확 줄었어요. 남은 영화는 9편이고, 남은 질문 수는 2개입니다.
이 단계에서는 두 edge의 edge weight를 계산해야 해요. Start와 이 두 가지 가능한 질문이 있네요.
Start와 Date 사이의 edge weight를 계산하면 3이 돼요. 그리고 Start와 Genre 사이의 edge weight를 계산하면 4가 되죠. 우리는 최대값에 관심이 있으니 영화의 장르를 선택할 거예요.
이제 그래프를 한번 살펴볼까요?
이 단계에서는 그래프가 훨씬 작아졌어요. 더 이상 Actor 타입의 vertex는 없고, Actor 질문 vertex 역시 사라졌죠. 이들은 더 이상 우리와 관련이 없으니까요. 우리에게는 Genre와 Date, 이렇게 두 가지 질문이 남아있고, 우리는 가장 좋은 질문은 영화의 Genre에 관한 것이라는 사실을 확인했어요.
그렇게 대화가 진행되는 거예요. 어시스턴트는 "어떤 장르를 선호하시나요?"라고 물어보죠. 사용자는 "로맨스 영화를 보는 것 같아요."라고 말할 수 있고요. 이 단계에서 엔터티를 감지하는데, genre의 값은 Romance가 되는 거죠.
다시 한번 이 정보를 컨텍스트 변수 genre에 저장하고, 그래프를 다시 수정하는 데 사용할 거예요.
이 단계에서 그래프의 현재 상태를 살펴보면 Date 타입의 Node가 두 개, Movie 타입의 Node가 한 개 있는 것을 확인할 수 있어요.
이제 사용자에게 추천을 해줄 수 있는 단계에 왔어요. 아직 한 가지 질문이 남아있지만, 기존 방식대로 했다면 모든 질문을 다 해야 했을 거예요. 하지만 이 솔루션을 사용하면 질문 하나를 아낄 수 있었죠.
이것은 아주 작은 예시라서 솔루션을 쉽게 볼 수 있도록 단순하게 유지하고 싶었어요. 데이터 양이 엄청나게 많은 경우에 가장 큰 이점을 얻을 수 있고, 가능한 많은 추천을 배제할 수 있답니다.
이것이 현재 그래프의 모습이에요.
다음과 같은 Node 타입이 하나 남아있네요. 바로 Recommendation! 추천해 드릴 영화라는 뜻이죠. 두 개 이상의 추천을 원할 수도 있어요. 사용자에게 제공하는 추천 목록을 3개, 5개, 또는 원하는 만큼 가질 수 있고, 순위대로 정렬될 수도 있답니다.
어시스턴트가 이 영화를 추천해 줄 거예요.
영화는 바로 시애틀의 잠 못 이루는 밤이에요. 이 영화는 1993년에 나온 클래식 로맨스 영화라는 것을 알고 있죠. 톰 행크스와 멕 라이언이 출연하고 노라 에프론이 감독을 맡았고요.
결국 추천을 받았습니다!
요약
우리의 주요 목표는 고객의 관심사나 요청에 따라 고객에게 빠른 추천을 제공하기 위해 가상 비서를 사용하는 것이었어요. 이 문제를 해결하는 데 필요한 모든 정보를 Neo4j Graph Database 형태로 모델링했답니다.
대화를 가능하게 해주는 Watson Assistant 인스턴스를 만들어 볼게요. 저희는 솔루션의 두 가지 측면을 결합하는데요. 어시스턴트가 특정 의도를 감지할 때마다 edge 가중치를 통해 그래프에 의해 결정되는 순서대로 사용자 선호도를 알아보기 위해 사용자에게 질문을 시작하는 거죠.
사용자로부터 답변을 얻으면 그래프를 수정하기 위해 이 정보를 저장하고, 추천을 작성하는 데 필요한 모든 정보를 얻을 때까지 동일한 방식으로 대화를 계속해요.
이 솔루션을 요약하면, 저희가 얻은 것은 인간 간의 대화를 시뮬레이션하는 프로세스와 가능한 가장 짧은 시간에 솔루션에 도달할 수 있도록 도와주는 Neo4j 모델을 사용한 추천 시스템이라고 할 수 있어요.
솔루션의 이점/잠재력
일반적인 가상 비서는 사용자의 질문에 답변하기 위해 훈련을 받지만, 그 능력에는 한계가 있죠. 일반적으로 반응적인 형태이고, 대화는 단방향적인 경향이 있어요. 또, 지능은 사용자의 요청을 해석하고 이에 대한 답변을 제공하는 것에만 집중되어 있고요.
저희가 생각하는 이러한 유형 기술의 다음 단계는 가상 비서가 특정 도메인의 전문가가 되어, 가장 관련성이 높은 질문을 먼저 제시하여 사용자에게 유용한 지침을 제공하는 대화형 및 양방향 대화를 구축하는 것이에요. 궁극적으로 목표는 사용자가 가능한 한 빠르고 효율적으로 최상의 답변을 얻을 수 있도록 돕는 것이죠.
해당 분야 전문가가 가질 수 있는 모든 정보가 포함된 하나 이상의 그래프를 통해 가상 비서에 또 다른 지능 계층을 추가한 셈이에요.
이러한 유형의 솔루션에 대한 몇 가지 가능한 응용 분야는 특정 제품에 대한 판매 고문이나 전문 판매원이 될 수 있다는 점이에요.
다양한 유형의 제품에 해당하는 그래프를 가질 수 있어요. 냉장고 추천에 대한 그래프, 전자레인지용 그래프, TV용 그래프 등을 가질 수 있는 거죠. 이러한 경우 추천 node는 저희가 사용할 수 있는 제품이 되고요. 그런 다음 질문은 해당 제품의 크기, 가격 또는 모든 유형의 특성에 해당할 수 있겠죠.
그런 다음 예비 의료 진단이나 환자 지원에도 적용될 수 있어요. 저희의 node는 가능한 모든 질병이 될 수 있으며, 환자가 가지고 있는 다양한 증상에 대해 질문할 수 있고요.
마지막으로, 기술 지원을 위한 문제 해결을 위해 보조자가 사용자에게 질문하여, 저희가 돕고 싶은 장치의 특정 오작동에 도달할 수 있는 최선의 방향을 안내하기를 원할 수도 있겠죠.
또한 이 동일한 솔루션에는 다양한 테마나 주제에 대한 그래프가 있을 수 있으므로, 어시스턴트는 한 번에 두 개 이상의 주제에 대해 사용자에게 지침을 제공할 수 있으며, 여기에서 다양한 유형의 의도를 모두 감지할 수 있다는 점도 언급하고 싶네요.
Cognitiva에서는 Neo4j 그래프 데이터베이스를 사용하여 가상 비서를 반응형으로 만들고 각 단계에서 최고의 질문을 할 수 있도록 함으로써 강화했어요. 이 프로세스는 사용자 선호도를 파악하는 데 도움이 되며, 이를 가능한 가장 빠른 방법으로 수행하여 사용자에게 귀중한 조언을 제공할 수 있게 되는 거죠.
Cypher
GraphConnect
JSON
Machine Learning
py2neo
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
편집자 주: 지난 10월 GraphConnect 샌프란시스코에서 InfoAdvisors의 수석 프로젝트 관리자인 Karen Lopez는 데이터가 Graph Database에 의해 가장 잘 제공될 시기를 알려주는 방법에 대한 프레젠테이션을 했어요.
GraphConnect SF의 더 많은 비디오를 보고 GraphConnect Europe에 등록하려면 다음을 확인하세요. graphconnect.com.
제 역할은 데이터(데이터뿐만 아니라 데이터 스토리)가 그래프가 필요하다고 알려주는 징후가 있다고 생각하는 이유를 설명하는 것이에요. 그리고 그래프는 어디에나 있을 뿐만 아니라, 세상을 먹고 있으며, 여러분의 데이터는 그걸 알고 있죠.
저는 트윗을 많이 해요. 그리고 데이터 병아리로서 제가 옹호하는 것 중 하나는 모든 사람이 자신의 데이터를 좋아하는지 확인하는 것이기 때문에 소셜 미디어에서 다른 일을 해요. 우리가 데이터를 사랑하는 방법 중 하나는 데이터에 적합한 집을 제공하고 데이터에 적합한 도구와 기술을 제공하는 것이라고 생각해요.
방금 Wi-Fi 없이 비행기에서 내리셨다면(즉, 에어캐나다에 Wi-Fi가 없기 때문에 에어캐나다를 이용하신 경우) 오늘이 무슨 날인지 아시나요? 바로 미래의 날로 돌아가기!
그 중 하나는 Emil이 이미 다루었어요. 현재 Graph Database와 처리 방식과 관계형 데이터베이스가 새로워지고 있는 시점 사이의 유사점이었죠.
몬산토에서 사람들에게 먹이를 주고 서로를 돌보는 것과 관련된 중요한 문제들과 함께 유전자형과 관련된 새로운 삶의 순환, 그리고 그게 세상을 어떻게 변화시킬지에 대해 이야기했어요.
그 다음엔 데이터 간의 연결을 어떻게 발견하고, 도출하고, 시각적으로 볼 수 있는지에 대해 들었는데요. 탐사보도 기자들이 데이터를 더 효과적으로 공유할 수 있는 방법에 대한 이야기였어요. 왜냐하면 기자들은 데이터를 이해하기 쉬운 형식으로 제공할 수 있거든요. 엄격한 형식의 스프레드시트보다 훨씬 쉽죠. 덕분에 기술 지식이 없는 사람들도 데이터를 더 쉽게 이해할 수 있게 돼요.
이런 기술들이 세상을 직접적으로 변화시킬 수도 있고, 여러분과 여러분의 조직이 세상을 변화시킬 수 있는 도구를 제공해 줄 수도 있을 거예요.
현실 세계의 계층은 사실 그래프 구조!
그렇다면 왜 그래프일까요?
저는 그래프에 대해 생각하는 것이 왜 중요한지를 설명하는, 조금 짓궂고 논쟁적인 의견을 가지고 있어요.
수십 년 동안 데이터를 다뤄온 경험을 바탕으로 말씀드리자면, 계층적 분류나 세상에 구조를 적용하는 걸 좋아하는 사람이 아무리 많아도, 진짜 계층은 많지 않다고 생각해요.
여기서 '진짜 계층'이란 정확히 하나의 부모를 갖는 트리 구조를 의미해요. 그런 구조는 현실에 잘 없죠. 우리는 데이터가 계층 구조인 척하도록 시스템을 개발하거나 데이터베이스를 설계하는 데 너무 많은 시간을 쏟고 있어요.
HR 조직도나 제품 카탈로그가 계층 구조라고 생각하지만, 데이터에 억지로 계층적인 세계관을 적용하려고 하면 오히려 더 힘들어져요.
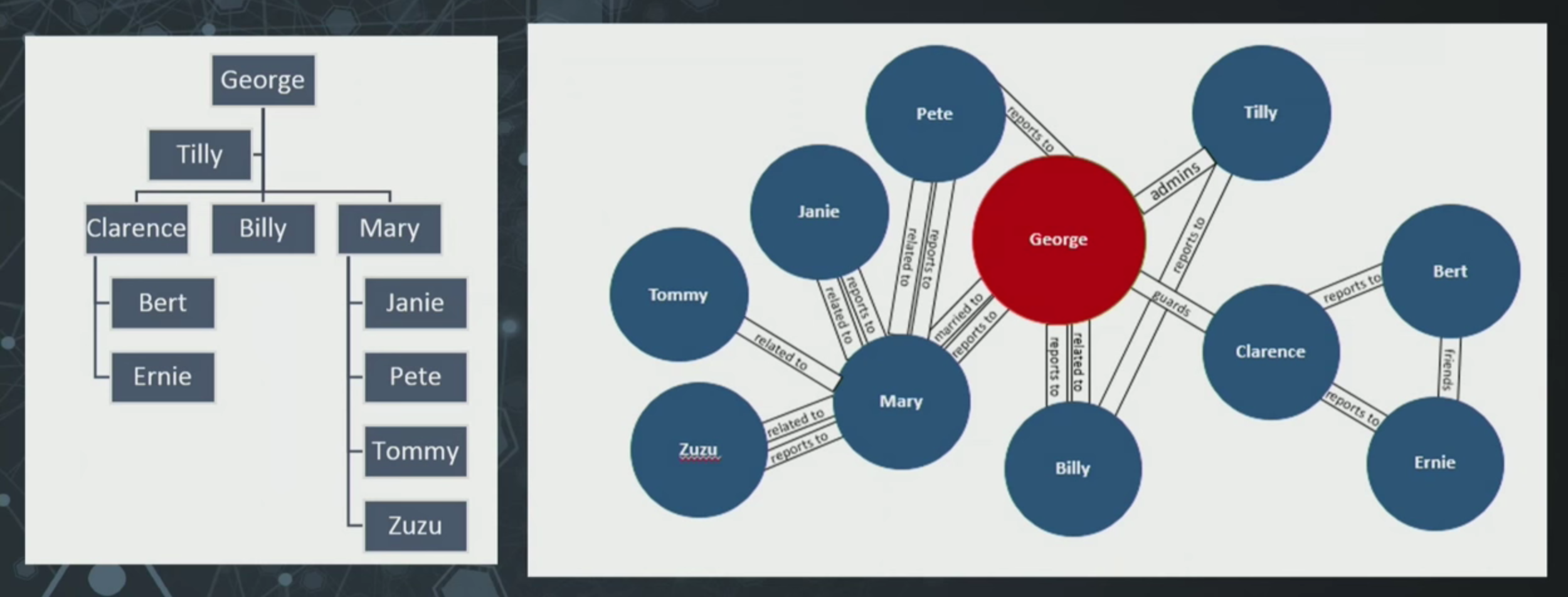
다음은 일반적인 계층 구조의 예시예요.
Bedford Falls에 우호적인 은행이 있고, 저축 대부 조합(S&L)을 소유하고 있으며, 사람들이 당신에게 보고한다고 가정해 볼게요. 당신에게 보고하는 사람들이 당신과 다른 관계도 맺고 있다는 사실을 깨닫기 전까지는 괜찮고 멋지죠.
왼쪽에는 계층 구조가 있고, 오른쪽에는 사람들이 서로 보고할 뿐만 아니라, 서로 결혼했거나 관련되어 있거나, 직접 보고하거나 감독자 역할을 한다는 것을 보여주는 더 큰 구조가 있어요.
우리는 사람에 대한 모든 데이터를 계층 구조로 정리하려고 노력하지만, 사람들은 그렇게 움직이지 않죠. 아마 여러분의 데이터도 마찬가지일 거예요.
품목, 제품, 부서, 부품, 설비도 마찬가지예요. 우리는 세상에 구조를 넣으려고 노력하고, 솔루션의 데이터를 통해 그렇게 하려고 하죠. 그리고 보고 구조에는 항상 '점선'이 있기 때문에 우리는 어려움을 겪게 되는 거예요.
사람들은 "한 번에 하나의 직책만 맡을 수 있습니다"와 같은 비즈니스 규칙을 제시하지만, 결국 사람들이 다른 사람을 따라다니거나 다른 사람과 겹치게 되죠. 이런 일은 항상 발생한다니까요.
그리고 ERP나 패키지 공급업체에 돌아가서 "실제로는 이 자리를 채울 사람이 5명이 필요해요. 두 사람은 기본이고 나머지는 보조인데 다른 사람을 뭐라고 불러야 할지 모르겠어요."라고 말하죠. 그러면 그들은 “그런 식으로는 안 돼요. 한 자리에 한 명만 있을 수 있으니까요.”라고 말할 거예요.
관계형 데이터베이스를 사용한 데이터 계층 모델링
관계형 세계에서는 이러한 개념으로 어려움을 겪어요. 저는 관계형 데이터베이스와 트랜잭션 시스템을 사용해서 작업하고 있거든요.
지금 당장 플래그 풋볼 팀을 구성한다면 저는 Team Relational에 속할 거예요. 그게 제가 인생의 대부분을 하는 일이니까요. 저는 SQL Server MVP이고, 데이터 모델러예요. 하루 종일 ERD를 만들죠.
제가 말씀드리고 싶은 건, 저는 고도로 관계형인 데이터 모델을 꿈꾼다는 거예요. 그렇다고 관계형 데이터베이스 시스템이 모든 것에 대한 솔루션이라고 생각하는 건 아니고요.
다음은 누군가가 테이블에 순전히 계층적 보고 구조를 설정할 수 있는 일반적인 방법이에요.
한 부모를 가리키는 직원, 직원 이름 및 직원 직위가 있어요. 이렇게 가르쳤는데, 그러면 사람들이 여러 사람에게 보고할 수 있다는 문제가 생기고, 맨 위에 있는 사람은 어떻게 해야 할까요? 이에 대한 해결 방법이 있긴 해요.
더미 레코드를 만들 수도 있고 CEO가 CEO에게 보고하도록 할 수도 있죠. 데이터가 계층적이라고 생각할 때에도 우리는 데이터를 사용해서 이러한 트릭을 수행해요.
순전히 계층적 구현에도 문제가 있어요. 관계형 세계에서는 직원이 직원에게 보고한다고 말하는 것은 재귀적인 관계죠. 직원들이 서로 여러 관계를 갖고 있다는 사실을 방금 배웠다는 점만 빼면요.
직원과 다른 사람 사이에는 아마도 수백 가지의 다른 관계가 있을 거예요. 따라서 우리는 관계형 데이터베이스에서와 마찬가지로 고도로 재귀적이고 자기 참조적인 조인(이런 단어는 절대 금지!)으로 끝나게 돼요.
부서 계층의 경우 또 다른 문제가 존재해요.
새로운 수준의 중간 관리자를 추가하거나, 관리자 한 명을 제거하거나, 직원의 절반을 한 관리자에서 다른 관리자로 이동해야 하면 어떻게 될까요? 우리는 관계형 데이터베이스에서 이 모든 것을 할 수 있어요. 이를 수행하는 방법에 대한 블로그 게시물, 스크립트 및 도구가 있지만, 이런 방식으로 수행하려고 하면 지저분해지죠.
관계형 데이터베이스 속이기
우리는 관계 세계의 트릭을 사용해서 실제로는 존재하지 않는다고 이미 말씀드린 계층 구조와 동일한 엔터티와 다른 엔터티 간의 관계를 모두 처리하려고 해요. 특별한 데이터 유형이 있을 수도 있고요.
SQL Server에는 서로 관련된 엔터티에 대한 모든 계층의 경로를 저장하도록 설계된 계층 ID라는 실제 데이터 유형이 있어요. 가지고 놀기 정말 재미있고 계층적 데이터를 사용하여 이러한 모든 트릭을 수행하죠.
유일한 문제는 실제 규모가 아닌 매우 단순한 구조에서만 작동한다는 거예요. 관계형 데이터베이스에서 트릭을 수행하고 있기 때문이죠.
인접 목록을 설정하고, 경로 열거를 수행하는 열에 넣고, 경로 분석 및 중첩 세트를 수행하는 클로저 테이블을 생성할 수 있어요. 관계형 세계에서 이러한 트릭을 구현한 적이 있다면 아마도 작동 방식을 설명하기 위해 긴 문서를 작성해야 했을 거예요.
작동은 하지만, 이걸 구현해야 하는 이유는 관계형 데이터베이스의 기본 가정 때문인데요. 데이터가 쓰기에 최적화되어 있고, 데이터가 매우 엄격한 구조를 따른다는 가정이요.
그건 실패가 아니에요. NoSQL 컨퍼런스에 가면 사람들은 그게 하나의 기능이고 우리가 관계형 데이터베이스를 구축하는 이유라고 말할 거예요. 잘 맞는 데이터에 대한 데이터 스토리는 관계형 데이터베이스에 포함될 가치가 있죠.
관계형 데이터베이스의 데이터 관계 문제
그럼에도 불구하고 우리는 매우 유연하고 매우 중요한 데이터 관계를 다루는 또 다른 문제가 있어요. 외래 키 제약 조건뿐만 아니라, 제가 말했듯이 이러한 것들을 관계형 데이터베이스로 구현하죠. 하지만 우리는 이 계층 구조가 실제로 계층 구조가 아니라는 걸 알게 돼요.
정말 네트워크나 물질형 구조에 가깝거든요. 이는 우리가 관계형 데이터베이스에서 특별한 관계를 구축하지 않는다는 것을 의미해요. 대신 직원 간의 다대다 관계를 관리하기 위해 연관 엔터티인 또 다른 테이블을 만들죠. 우리는 데이터를 가득 채워서 모두 괜찮아요.
지금은 다대다 관계를 처리하기 위한 완전히 다른 문제 세트를 소개했어요. 여기서는 그 모든 문제를 다루지는 않을 거예요. 그들은 단지 절충안일 뿐이죠. 그러나 이는 실제로 관계였던 어떤 것을 테이블, 즉 데이터 항목으로 변환하고 이를 다른 데이터 항목과 마찬가지로 취급한다는 의미에요.
이 때문에 우리는 모든 종류의 특수 처리 및 쿼리를 수행해야 하며, 특정 해결 방법을 구현하여 실수로 발생할 수 있는 여러 가지 이상 현상을 해결해야 해요.
모든 데이터가 고통받고 있습니다
부처님께 사과드리며 제가 관찰한 주요 내용 중 하나는 모든 데이터가 고통을 받고 있다는 거예요.
그게 무슨 뜻일까요? 저는 이 분야의 전문가는 아니지만, 이 고귀한 진리에 대한 저의 일반적인 이해는 우리가 고통을 겪는다는 거예요. 고통은 단지 문제를 다루거나, 스트레스를 받거나, 고통을 겪는 것을 의미하죠.
보다 일반적으로, 우리는 세상에 있는 것들을 실제로 적용되지 않고 우리가 통제할 수 없는 신념 체계나 구조에 맞추려고 할 때 고통을 겪어요. 그건 진실을 조금 확장한 것이지만, 기본적으로 우리는 원래 의도하지 않은 세상에 일부 데이터 쿼리를 강제하려고 하기 때문에 우리, 데이터 및 비즈니스 사용자가 어려움을 겪는 거예요.
그래프와 그래프 데이터를 다룰 때 중요한 점 중 하나는 관계형 세계에서 외래 키 관계는 전혀 관계가 아니라는 거예요. 관계형 데이터베이스라는 이름은 그래프 다이어그램의 상자나 원 사이의 선이 아니라 테이블이 관계이기 때문에 붙여진 이름이에요.
테이블은 제약 조건이에요. 그건 실제로 데이터가 통제를 벗어나지 않도록 하기 위해 착용하는 안전벨트죠. 이는 비즈니스 사용자가 이야기하거나 우리 삶에서 생각하는 관계가 아니에요. 그렇기 때문에 관계형 세계에서는 이를 생성하여 테이블에 넣어야 하는 거죠.
관계형 데이터베이스의 또 다른 단점은 속성, 태그 또는 레이블을 관계에 할당할 수 없다는 거예요. 데이터베이스에 이름을 부여할 수 있지만 아무도 그 이름을 볼 수 없죠.
그래프에서 중요한 점은 그래프 데이터베이스의 `Node`보다 관계에 우선 순위를 두었다는 거예요. 또한 관계형 데이터베이스는 이러한 관계형 `Query`나 이해를 수행할 때 확장이 잘 되지 않아요.
관계형 데이터베이스는 관계에 관한 것이 아니에요. 데이터 무결성을 위해 그들 사이에 제약이 있는 것들에 관한 것이죠.
저는 이것이 특정 데이터, 또는 더 중요하게는 특정 질문이 그래프에 더 적합하다고 말하는 이유 사이에서 가장 오해되는 차이점이라고 생각해요. 사람들은 "둘 중 하나" 접근 방식을 사용하고 싶어해요. 그래프 데이터베이스와 관계형 데이터베이스 중 어느 것이 더 좋다고 생각하시나요?
그건 제가 대답할 수 있는 질문이 아니에요. 효과적으로 대답하려면 우리가 대답하려는 질문이 무엇인지 알아야 하기 때문이죠.
관계형 데이터베이스는 테이블에 중점을 두고, 그래프 데이터베이스는 관계에 중점을 둬요. 특정 비즈니스 질문은 관계를 발견하든 문서화하든 실제로 관계에 관한 것이죠. 그건 고전적인 절충안이에요.
데이터가 그래프임을 알려주는 7가지 방법
그렇다면 데이터가 그래프라고 말하는 이유는 무엇일까요?
#7. 그 이름
네트워크, 나무, 분류, 조상, 구조 - 사람들이 조직도나 보고 구조에 관해 이야기하기 위해 이러한 단어를 사용한다면, 그들은 데이터와
#6. 그래프 같은 느낌을 주기 위해 트릭을 사용하고 있습니다.
개발자가 관계형 데이터베이스에 데이터를 구현한 다음 그 위에 레이어를 배치하여 그래픽처럼 보이거나 느껴지도록 한다는 이야기를 들어본 적이 있을 거예요. 이것이 바로 우리 모두가 관계 구조를 통해 해왔던 일이죠.
실제로는 관계형 구조뿐만 아니라 계층 구조도 있어요. 저는 관계 이전에 충분히 경험이 있다는 것을 기억하세요. 우리는 계층적 데이터베이스를 갖고 있었어요. XML, JSON 등과 같은 다른 데이터베이스 형식의 계층 구조가 있죠.
#5. 소프트웨어 공급업체가 불가능하다고 할 때
그 이유는 보통 그래프 기반이 아닌 데이터베이스나 그래프 처리 방식을 전제로 설계했기 때문일 거예요. 이제 와서 레이어를 덧붙이거나 상용 제품에 추가하려니 쉽지 않은 거죠.
#4. 질문이 엉뚱하게 느껴질 때
데이터 자체가 그래프 형태라서, 즉 구조적인 부분이 중요해서 Graph Database와 처리가 필요하다고 말하는 게 더 일반적이에요. 데이터가 그래프 형태일 *수도* 있지만, 중요한 건 데이터에 어떤 질문을 던지고 싶은가 하는 점이죠.
일반적으로 쿼리 언어를 배울 때 데모나 프레젠테이션에서 "모든 주문과 해당 주문 라인을 보여주세요" 같은 간단한 관계형 쿼리를 보게 되죠. Structured Query Language나 관계형 데이터베이스를 배우기엔 좋지만, 요즘 데이터에 대해 던지는 어려운 질문은 아니에요.
요즘은 법의학이나 사기 방지 담당자에게 "이 사람을 3단계 이상으로 아는 사람이 이 우체국을 방문해서 이 위치에서 이 나라로 상자를 배송한 적이 몇 번이나 있었나요?" 같은 질문을 던지곤 해요. 물론 그래프가 아닌 데이터베이스에서도 해당 데이터를 추적하고 응답할 수 있지만, 비용이 많이 들고 실행하는 데 오래 걸릴 거예요.
게다가, 이런 질문에 답하기 위해 완전히 별도의 솔루션을 찾아야 할 가능성도 높죠. 이는 보통 예산 문제나 추가적인 기술적인 문제로 이어지는데, 답변을 최적화하기 위해 해당 질문에 맞춰 특별히 설계된 솔루션이 필요하기 때문이에요.
분석가와 설계자로서 비즈니스 사용자에게 "더 심오한 질문은 무엇인가요?"라고 묻는 건 별로 좋은 방법이 아니라고 생각해요. 거래 시스템을 구축할 때 그런 질문을 하지 않는 이유는, 첫째는 대답이 두렵기 때문이고, 둘째는 그들이 필요로 하는 것을 제공하지 못할 수도 있기 때문이죠.
데이터가 엉망진창이 될 수 있거든요. 관계형 데이터베이스만으로는 감당하기 힘들죠. 데이터의 단순한 8단계 경로가 아니라, 수백, 수천 개가 넘는 경로 또는 Node가 있을 수 있으니까요.
#3. IT 팀에서 "느려질 거예요"라고 말할 때
혹은 "다른 시스템에 영향을 미칠 거예요", "데이터 웨어하우스를 구축해야 해요", "그 질문에는 답할 수 없을 것 같아요"라고 말할 수도 있겠죠. 이런 징조가 보인다면 정말 필요한 건 올바른 도구일지도 몰라요.
#2. 데이터에 특정 질문을 던지면 안 된다고 할 때
#1. Neo4j로 Proof of Concept를 만들었더니 잘 작동할 때
이게 최고죠!
"Proof of Concept를 구축했는데, 그건 그냥 빠른 프로토타입을 만들고 .NET에서 코딩을 좀 한 구식 Proof of Concept가 아니었어요. 실제로 Neo4j의 기본 데이터 모델과 시각화를 활용해서 Proof of Concept를 구축한 거죠."
Proof of Concept를 수행하는 것만으로도 데이터나 Query가 그래프 형태라는 걸 증명할 수 있어요.
Graph Database를 사용해야 하는 경우
우리 모두 Graph Database가 가장 잘 작동하는 상황을 강조하는 수많은 사례 연구를 들어봤을 거예요. 몇 가지 예를 살펴볼까요?
재귀 (Recursion):
재귀적인 질문이 있을 때마다 Graph Database를 사용해야 해요. 재귀는 어떤 것들이 무한한 수의 관계로 이어져서 매우 불규칙한 답변 세트를 생성하는 경우를 말해요.
예를 들어, Graph Database는 소셜 미디어에서 잘 작동해요. 한 사람은 3명의 팔로워를 가질 수 있지만, 다른 사람은 1억 명의 팔로워를 가질 수도 있잖아요. 그리고 '케빈 베이컨' 문제나 조직과 관련된 조직에도 잘 작동하죠.
마스터 데이터 관리 (Master Data Management):
많은 사람들이 마스터 데이터 관리를 그래프 문제라고 생각하지 않지만, 사실은 그렇답니다. 제품 라인, 제품 구성, 고객은 항상 그래프 형태의 질문이니까요.
네트워크 및 IT 운영 (Network and IT Operations):
궁극적인 그래프는 IT 시스템이라고 생각해요. 저는 매일 이와 관련된 작업을 하고 있죠. 여기에는 자산, 신원, BOM, 누가 무엇을 사용하는지, 어디에 있는지 등 모든 것이 포함돼요.
실시간 추천 (Real-time Recommendation):
추천 엔진뿐만 아니라, 우리가 연결되어 있다는 사실을 알게 되지만 미처 깨닫지 못하는 경우도 많죠. 경쟁 우위에 대한 많은 이야기가 있는데, 데이터에 대한 질문을 던질 수 있고 Graph Database가 이러한 질문에 답할 수 있다는 걸 알게 되는 위치에 대한 내용이에요.
법의학 및 사기 (Forensics and Fraud):
이건 행동 패턴을 추적할 수 있기 때문에 정말 흥미로워요. 사람들은 어떻게 행동하고, 언제 평소와 다르게 행동할까요? 행동의 변화는 사기적인 행위를 나타낼 수도 있고, 그냥 상점을 지나가는 사람일 수도 있겠죠.
리소스 최적화 (Resource Optimization):
이 부분에서 IT 전문가들은 다음과 같은 질문을 통해 조직에 금전적인 절감과 위험 완화를 제공할 수 있어요. "거기에 도달하는 가장 빠른 경로는 무엇인가?", "물건은 어디에 있는가?", "핫스팟, 활용도가 낮은 서버, 일정이 초과된 사람들은 어디에 있는가?"
프로모션 구축 (Promotion Building):
Graph Database는 더 많은 구매와 갱신을 유도하는 소매 프로모션을 구축하는 데에도 사용될 수 있어요. 또는 타겟 제안이나 제공할 생각조차 못 했던 항목에 사용될 수도 있겠죠.
데이터 모델링과 그래프
제가 데이터 모델러라고 말씀드렸죠? 제가 그래프에서 제일 좋아하는 점 중 하나는 논리적인 모델과 물리적인 모델이 분리되어 있지 않다는 거예요. 기본적인 데이터 모델이 곧 작성하는 물리적인 그래프 그 자체가 데이터 모델이자 데이터베이스가 되는 거죠.
화이트보드에 명사를 동그라미로 그리고, 그 사이에 관계를 추가하는 데이터 모델링을 할 수 있어요. 그러면 비즈니스 담당자, 최고 경영진, 관리자, 다른 IT 담당자 등 모든 레벨의 사람들이 쉽게 이해할 수 있죠.
또 다른 의견이 분분할 수 있는 아이디어가 있는데요. 기존의 엔터티-관계 데이터 모델도 여전히 중요한 역할을 한다는 거예요. 그렇다고 해서 반드시 Graph Database를 만들어야 한다는 의미는 아니지만, 어떤 회사들은 현재 데이터(데이터의 모양, 예외, 속성, 레이블)에 대해 수십 년 동안 쌓아온 이해를 가지고 있고, 이걸 그래프 구현에 활용할 수 있다는 거죠.
데이터 관계가 더 나은 통찰력을 얻는 방법
거의 제한 없이 그래프 처리를 하고 쿼리를 실행할 수 있는 핵심은 고객 레벨에서 시작해서 계속 확장해 나갈 수 있다는 점이에요.
전통적인 관계형 프로젝트에서는 범위가 명확하게 정의되어 있어야 하죠. 정말 비용이 많이 들고 민첩하게 개발해야 한다면, 무기한 대기열에서 끝날 가능성이 높아요.
사례 연구: Polyvore
Polyvore를 사용하면 젊은 패셔니스타들이 웹사이트에서 사진을 스크랩하고, 기본적인 메타데이터와 함께 하나의 이미지로 합쳐서 공유하고, 다른 사람들이 '좋아요'를 누를 수 있어요.
이건 본질적으로 메타데이터와 함께 의상과 특별한 기능들을 수집하는 크라우드소싱 방식이에요. 이걸 통해서 최종 사용자들이 제품을 어떻게 사용하고, 구매하고, 조합하는지를 제품 공급업체나 제조업체에 알려줄 수 있죠.
게다가 '좋아요'와 댓글을 통해 소셜 참여도 가능하게 만들어요. 본질적으로 누군가가 마치 세상의 모든 상점을 소유한 것처럼 사람들의 제품으로 구성된 가상 웹 상점을 구성하는 것과 같아요.
하지만 제품, 메타데이터, 사람들이 사용하는 제품, 제품이 함께 사용되는 방식, 새로운 조합에 대한 사람들의 생각 등 근본적인 관계는 제조업체와 공급업체가 이 공간에서 사용자와 상호 작용하고 자체 콘테스트를 만들 수 있는 기회를 제공해요. 정말 흥미롭죠? 게다가 후속 데이터를 마이닝할 수 있다는 점은 엄청난 힘을 가지고 있어요.
마스터 데이터 관리에 대한 참고 사항
마스터 데이터도 그래프인 이유는 고객에 대해 중요한 질문을 할 수 있을 뿐만 아니라, 이름 철자, 해당 이름과 연결된 전화번호와 같은 구문뿐만 아니라 상호 작용 횟수 및 유형과 같은 다른 패턴을 사용해서 고객 데이터의 중복을 제거할 수도 있기 때문이에요.
데이터에 대한 360도 뷰를 가지고 있기 때문에 이전에는 물어볼 수 없었던 질문을 할 수 있게 되는 거죠. 하지만 그건 단순한 데이터 그 이상이에요.
GraphGist를 탐색하면서 재미있게 보내세요 (제가 두 번째로 좋아하는 GraphGist가 벨기에 맥주에 관한 것이라는 사실에 너무 놀라지는 마세요).
제 마스터 데이터가 그래프인 이유에 대한 백서를 읽어보세요 (약간 편향적이지만 그래도 추천해요).
특정 조직에서 그래프의 세계로 뛰어드는 또 다른 좋은 방법은 주요 데이터 중심 비즈니스 담당자에게 데이터에 대해 묻고 싶지만 할 수 없었던 질문이 있는지 물어보는 거예요.
그런 다음 현재 관계형 데이터베이스에 문서화되지 않은 데이터의 관계가 있을 수 있다는 점을 비즈니스 사용자가 이해하도록 도와주세요. 과거에는 다른 데이터베이스나 다른 테이블에 있는 데이터가 여전히 필수적인 관계를 가질 수 있다는 점을 상기시키는 대신 관계는 단지 제약일 뿐이라고 말했었죠.
자신의 데이터에 대한 새로운 통찰력을 발견하면 조직은 기존 데이터의 데이터 관계를 기반으로 경쟁 우위를 확보할 수 있어요.
기존 데이터로 얻을 수 있는 통찰력을 정량화할 수 있다는 건 조직이 새로운 데이터, 외부 데이터 또는 새로운 질문을 통해 더 많은 통찰력을 얻는 방법을 이해하도록 돕는 첫 번째 단계가 될 거예요.
Karen의 강연에서 영감을 받으셨나요? GraphConnect Europe 2016년 4월 26일에 등록해서 진화하는 그래프 데이터베이스 기술 세계에 대한 업계 최고의 프레젠테이션과 워크숍을 만나보세요.
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
"항상 이유를 물어보세요" 라고 Stephen O'Grady, Redmonk의 공동 창립자가 말했어요.
어떤 프로젝트를 진행할지 결정할 때, 개발자는 빌드 요청받은 항목의 의미와 더 넓은 맥락을 고려해야 해요. Redmonk는 개발자 중심의 산업 분석 회사로, 상위 20개 프로그래밍 언어를 꾸준히 추적하고 있죠. Stephen O'Grady의 말입니다.
이번 주 GraphConnect 2018 (뉴욕)에서 진행된 5분 인터뷰에서 Stephen O'Grady는 그래프 기술의 사용 사례와 미래에 대한 생각을 공유했어요.
더 넓은 기술 생태계에서 그래프는 어떤 역할을 할까요?
O'Grady: 제 생각에 그래프 기술의 흥미로운 점은 지난 10년 정도에 걸쳐 등장한 다양한 비관계형 기술 중 하나라는 거예요. 수십 년 동안 관계형 데이터베이스를 사용하다가 이제는 분리되었죠. 지금은 모든 종류의 전문화된 데이터 저장소를 가지고 있어요.
이건 다양한 작업에 맞는 다양한 도구를 사용하는 접근 방식이라서 의미가 있죠. 특히 그래프는 그래프를 횡단하고 이전의 관계형 기술보다 훨씬 더 빠르게 작업을 수행할 수 있다는 점에서 다양한 문제에 대해 다양한 작업을 가능하게 해주기 때문에 가치가 있어요.
사용 사례를 보면 그래프는 꽤 다양해요. 오늘 여러분은 배달 라우팅부터 소셜 그래프 순회, 사물 인터넷(IoT) 사용 사례에 이르기까지 모든 것에 대한 이야기를 들어보셨을 거예요. 실제로 어디든 엔터티가 있고, 어떤 목적으로든 분석해야 하는 엔터티 간의 관계가 있다면 Graph Database가 꽤 잘 맞을 거예요.
그래프와 다른 기술 사이에 공생 관계가 있다고 생각하시나요?
O'Grady: 네, 떠오르는 것 중 하나가 인공지능이죠. Hillary Mason이 오늘 기조 연설에서 말했듯이, Machine Learning, Deep Learning 등의 작업을 수행하고 이러한 종류의 기술과 접근 방식을 다양한 데이터 문제에 적용하고 있어요.
제 생각에는 이러한 Machine Learning 시스템에 공급할 데이터 세트 중 일부가 본질적으로 그래프가 될 것이라는 점에서 자연스러운 적합성이 있어요. 따라서 이를 탐색하고 처리할 수 있고 두 시스템 간의 통합 지점을 가질 수 있다는 점은 정말 멋질 거예요.
그래프 기술의 미래는 어디로 향할 거라고 보시나요?
O'Grady: 제 관점에서는 그래프 기술이 주류로 자리 잡아야 한다고 생각해요. 왜냐하면 지금은 꽤 오랫동안 매우 유용한 도구였지만, 여전히 전문화되어 있고 많은 경우 틈새 시장에 머물러 있거든요. 우리가 궁극적으로 원하는 것은 그래프가 실질적이고 중요한 기술이며, 오늘날 관계형 데이터베이스처럼 사람들이 많은 것을 선택하고 분석할 수 있는 기술이라는 것을 모두가 이해하는 시점에 도달하는 것이죠.
GraphConnect 기조연설에서 가장 큰 시사점은 무엇이었나요?
O'Grady: 제 기조연설에서 얻은 가장 큰 교훈은 개발자, 실무자, 데이터 과학자 모두가 한 발 물러서서 우리가 무엇을 구축하고 있는지, 그리고 더 중요하게는 왜 그것을 구축하는지에 대해 생각해봐야 한다는 거예요.
이 업계에는 사람들이 흥미를 느꼈거나 지시를 받았기 때문에 무언가를 만들어 온 역사가 있죠. 그런데 우리가 만든 것 중 일부는 때때로 해를 입히고 심지어 잠재적으로 위험하기까지 했어요.
그래서 개발자들이 윤리적인 이유뿐만 아니라 자신의 경력이나 수익 잠재력과 같이 훨씬 더 중요한 목적을 위해서라도, 자신이 무엇을 만들고 있고, 무엇을 만들도록 요청받고 있는지 더 넓은 맥락에서 의식하도록 노력해야 한다는 아이디어인 거죠. 딱 하나만 가져갔으면 하는 게 있다면, 항상 "왜?"라는 질문을 던지는 거예요.
앞으로 5분 인터뷰에서 Neo4j 프로젝트에 대해 공유하고 싶으신가요? content@neo4j.com으로 연락 주세요!
여러분의 비즈니스에서 그래프를 어떻게 활용할 수 있을지 궁금하신가요? Graph Database의 상위 5가지 사용 사례 백서를 다운로드하고, 연결된 기업을 위해 그래프의 힘을 활용하는 방법을 알아보세요.
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.