
소개
GraphRAG용 Neo4j를 사용해 본 적이 있다면 이미 생성 모델의 출력 품질을 향상시킬 수 있는 잠재력을 알고 계실 거예요. 전통적으로 이를 위해서는 Neo4j와 Cypher에 대한 깊은 지식이 필요했죠. 이번 포스팅에서는 공식적으로 Neo4j GraphRAG Python 패키지(neo4j-graphrag)를 소개할게요. 이 패키지는 개발자를 위한 RAG(Retrieval-Augmented Generation) 애플리케이션에 Neo4j의 통합을 단순화하도록 설계되었답니다.
GraphRAG Python 패키지는 RAG 설정에서 검색 및 생성 프로세스를 효율적으로 관리할 수 있는 도구를 제공해요. 이 게시물이 끝나면 패키지를 사용하여 검색 작업을 실행하는 데 능숙해질 거예요. 다음 게시물에서는 전체 엔드투엔드 RAG 파이프라인을 구축할 수 있는 패키지 생성 기능에 대해 자세히 알아볼 거예요.
GraphRAG란 무엇입니까?
neo4j-graphrag 패키지는 GraphRAG(그래프 검색 증강 생성)를 용이하게 해줘요. Neo4j에서는 그래프 데이터베이스를 벡터 검색과 통합하는 것이 RAG의 다음 개척지를 대표한다고 믿고 있어요.
설정
영화 추천 Knowledge Graph를 시뮬레이션하는 사전 구성된 Neo4j 데모 데이터베이스에 연결하여 시작해 봐요. 다음에서 액세스하세요: 사용자 이름과 비밀번호로 "recommendations"를 사용하면 돼요. 이 설정은 Vector Embedding 데이터가 이미 사용할 준비가 된 Neo4j 데이터베이스의 일부인 현실적인 시나리오를 제공해 준답니다.
Cypher 명령어를 입력해서 데이터를 시각화해 보세요.
MATCH (n) RETURN n LIMIT 25;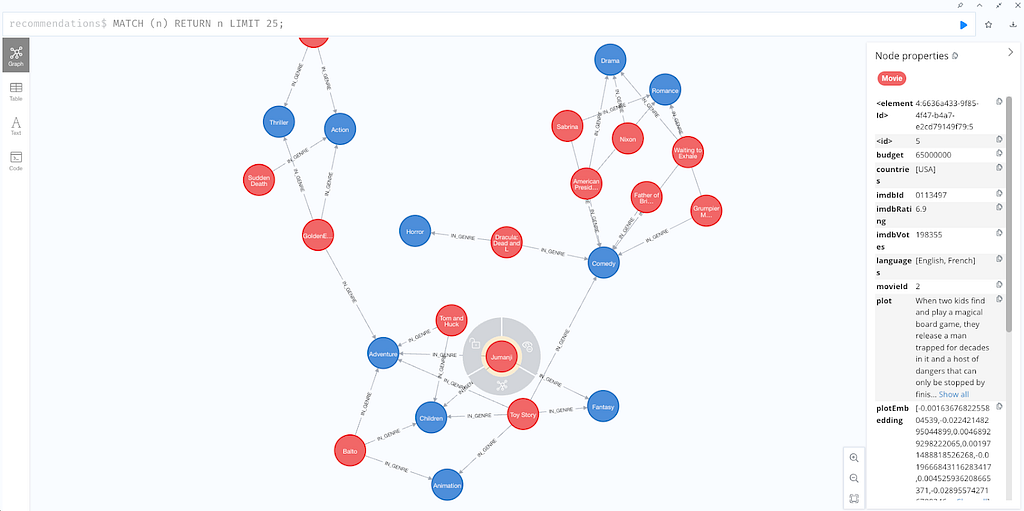
오른쪽의 각 Node 세부 정보에서 plotEmbedding 속성을 확인해 보세요. 데모 전반에 걸쳐 Vector Search를 수행하기 위해 이러한 임베딩을 사용할 거예요. moviePlotsEmbedding이 존재하는지 확인하기 위해 Cypher 명령을 입력해서 Vector Index를 생성해 봅시다.
SHOW INDEXES YIELD * WHERE type='VECTOR';Python 환경에서 다음 다른 패키지와 함께 neo4j-graphrag 패키지를 설치하세요.
pip install neo4j-graphrag neo4j openai계속해서 Neo4j Python 드라이버를 사용하여 Neo4j 데이터베이스에 대한 연결을 설정해 봐요.
from neo4j import GraphDatabase
# Demo database credentials
URI = "neo4j+s://demo.neo4jlabs.com"
AUTH = ("recommendations", "recommendations")
# Connect to Neo4j database
driver = GraphDatabase.driver(URI, auth=AUTH)이 데모를 위해서는 OpenAI API 키 세트가 있는지 확인해야 해요.
import os
os.environ["OPENAI_API_KEY"] = "sk-…"검색
우리 패키지는 다양한 검색 전략에 맞춰진 다양한 검색기를 제공해요 (전체 목록에 대한 문서). 적절한 것을 선택하는 것은 특정 요구 사항에 따라 달라지죠. 여기서는 VectorRetriever 클래스를 사용할게요.
from neo4j-graphrag.retrievers import VectorRetriever
from neo4j-graphrag.embeddings.openai import OpenAIEmbeddings
embedder = OpenAIEmbeddings(model="text-embedding-ada-002")
retriever = VectorRetriever(
driver,
index_name="moviePlotsEmbedding",
embedder=embedder,
return_properties=["title", "plot"],
)우리는 text-embedding-ada-002를 사용하는데, 데모 데이터베이스의 영화 플롯 임베딩이 이 모델을 사용하여 생성되어 보다 관련성 높은 검색 검색이 가능해졌기 때문이에요. 반환된 결과를 사용자 정의하는 방법이 있는데, 여기서는 Node 속성 title과 plot이 반환되도록 return_properties를 지정했어요.
검색어를 사용하여 Query와 밀접하게 일치하는 영화 줄거리를 검색하면 Approximate Nearest Neighbor Search를 실행하여 Query와 가장 잘 일치하는 상위 3개의 영화 줄거리를 식별해 준답니다.
query_text = "A movie about the famous sinking of the Titanic"
retriever_result = retriever.search(query_text=query_text, top_k=3)
print(retriever_result)
items=[
RetrieverResultItem(content="""
{'title': 'Titanic',
'plot': 'An unhappy married couple deal with their problems on board the ill-fated ship.'}""",
metadata={'score': 0.9450652599334717, 'nodeLabels': None, 'id': None}),
RetrieverResultItem(content="""
{'title': 'Night to Remember, A',
'plot': 'An account of the ill-fated maiden voyage of RMS Titanic in 1912.'}""",
metadata={'score': 0.9428615570068359, 'nodeLabels': None, 'id': None}),
RetrieverResultItem(content="""
{'title': 'Titanic',
'plot': 'A seventeen-year-old aristocrat falls in love with a kind, but poor artist aboard the luxurious, ill-fated R.M.S. Titanic.'}""",
metadata={'score': 0.9422949552536011, 'nodeLabels': None, 'id': None})]
metadata={'__retriever': 'VectorRetriever'}정규식을 사용해서 `retriever_result`를 더 자세하게 파싱할 수도 있어요.
import re
for k, item in enumerate(retriever_result.items):
plot = re.search(r"'plot':s*'([^']*)'", item.content).group(1)
title = re.search(r"'title':s*'([^']*)'", item.content).group(1)
score = item.metadata["score"]
print(f"Result {k}: {title} - {score} - {plot}")
Result 0: Titanic - 0.9450652599334717 - An unhappy married couple deal with their problems on board the ill-fated ship.
Result 1: Night to Remember, A - 0.9428615570068359 - An account of the ill-fated maiden voyage of RMS Titanic in 1912.
Result 2: Titanic - 0.9422949552536011 - A seventeen-year-old aristocrat falls in love with a kind, but poor artist aboard the luxurious, ill-fated R.M.S. Titanic.GraphRAG
이제 `Retriever`가 간단한 GraphRAG 파이프라인에 어떻게 적용되는지 한번 살펴볼까요? `neo4j-graphrag` 패키지를 사용해서 GraphRAG 쿼리를 실행하려면 몇 가지 구성 요소가 필요해요.
- Neo4j Driver — Neo4j 데이터베이스에 쿼리할 때 사용돼요.
- Retriever — `neo4j-graphrag` 패키지에서 몇 가지 구현체를 제공하고, 만약 제공되는 구현체 중에 여러분의 요구사항에 맞는 게 없다면 직접 만들 수도 있어요.
- LLM — 답변을 생성하려면 LLM을 호출해야겠죠? `neo4j-graphrag` 패키지는 현재 OpenAI LLM에 대한 구현체만 제공하지만, 인터페이스는 LangChain 채팅 모델과 호환되고 필요하다면 여러분만의 인터페이스를 만들 수도 있답니다.
실제로는 단 몇 줄의 코드만 있으면 돼요.
from neo4j-graphrag.llm import OpenAILLM
from neo4j-graphrag.generation import GraphRAG
# LLM
# Note: the OPENAI_API_KEY must be in the env vars
llm = OpenAILLM(model_name="gpt-4o", model_params={"temperature": 0})
# Initialize the RAG pipeline
rag = GraphRAG(retriever=retriever, llm=llm)
# Query the graph
query_text = "What movies are sad romances?"
response = rag.search(query_text=query_text, retriever_config={"top_k": 5})
print(response.answer)다양한 유형의 `Retriever`를 커스터마이징하는 방법은 다음 포스팅에서 자세히 알아볼게요.
요약
여러분을 초대해서 neo4j-graphrag 프로젝트에 패키지화하고, 댓글이나 GraphRAG를 통해 여러분의 통찰력을 공유해주시면 감사하겠습니다. 디스코드 채널을 통해서도 소통할 수 있어요.
패키지 코드는 오픈 소스이고 에서 찾을 수 있습니다. 언제든지 이슈를 올려주세요!
초보자를 위한 GraphRAG
연결된 데이터를 기반으로 복잡한 질문에 답할 수 있는 GraphRAG 애플리케이션을 구축해보세요. 세 가지 주요 검색 패턴을 알아볼 거예요.
- Python
- Retrieval-Augmented
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'GraphRAG' 카테고리의 다른 글
| 메타로의 여정: GraphRAG, 벡터, 그리고 Knowledge Graph 마무리 (0) | 2026.05.04 |
|---|---|
| Neo4j와 LangChain으로 구현하는 '로컬에서 글로벌로' GraphRAG: 그래프 구축하기 (0) | 2026.05.03 |
| GenAI 시작 키트: Java에서 Spring AI로 애플리케이션 구축에 필요한 모든 것 (0) | 2026.05.03 |
| 단 4줄 코드로 만드는 GenAI 기반 노래 찾기: Neo4j와 GraphRAG 활용 (0) | 2026.05.02 |
| GenAI 그래프 수집 2.0: GraphRAG의 진화 (0) | 2026.05.02 |