
Neo4j로 노래와 가사 카탈로그를 만들고, 내장된 Gen AI 기능으로 내용 기반 노래 찾기!
여러분, 노래 제목이나 누가 불렀는지 기억은 안 나는데, 대략적인 내용만 어렴풋이 기억나는 노래를 찾고 싶었던 적 없으신가요? 딱 4줄의 코드로 이 문제를 해결하는 도구를 만들어 볼 거예요.

인터넷은 금방 지나갈 과대 광고일 뿐이에요. 장기적으로 봤을 때, 사람들이 인터넷 서핑에 그렇게 많은 시간을 쏟고 싶어 하진 않을 거라고 생각해요.
이 말은 1996년에 스웨덴 통신부 장관이었던 이네스 우스만(Ines Uusmann)이 했던 말인데요. 그녀의 말처럼 인터넷이 과대 광고였을 수도 있죠. 하지만 인터넷은 이미 20년 넘게 우리 곁에 있었고, 이제는 절대 사라지지 않을 존재에 대한 과대 광고였던 것 같아요. 인터넷 없는 현대 생활은 상상하기 힘들 정도니까요. 사실 90년대 초반에 과대광고를 불러일으킨 건 바로 월드 와이드 웹(World Wide Web)의 등장 때문이었죠.
마찬가지로 많은 사람들이 AI를 과대 광고라고 부르기도 해요. 물론 그럴 수도 있지만, 인터넷의 과대 광고와 굉장히 비슷하다고 생각해요. AI는 반세기가 넘는 역사를 가지고 있고, 오늘날의 인터넷처럼 우리 삶에 필수적인 존재로 계속 남아있을 거라고 믿어요. 인터넷에 WWW가 있다면, AI에는 LLM(Large Language Model)과 GenAI 같은 존재가 있는 거죠.
만약 제 예측이 맞다면, 특히 소프트웨어 개발자라면 ChatGPT와 대화하는 것뿐만 아니라, 이 기술을 직접 사용하는 방법을 배우면서 새로운 기술을 배우고 받아들이는 게 중요할 거예요. 그리고 그렇게 하기 위해 꼭 수학자일 필요도 없어요! AI를 쉽게 사용할 수 있도록 도와주는 훌륭한 도구들이 정말 많거든요. 그중 하나가 바로 Neo4j랍니다.
Neo4j와 AI
Vector Search가 뭔지 너무 깊게 들어가진 않을게요. 간단하게 설명하자면, 벡터는 화살표처럼 길이와 방향을 가진 것이라고 생각하면 돼요. 2차원에서는 아래 그림처럼 x와 y 두 숫자로 벡터를 표현할 수 있죠.
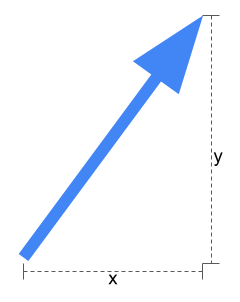
Vector Embedding은 LLM이 자연어 텍스트(또는 이미지나 음악)의 내용을 나타내는 단일 벡터를 생성하도록 하는 건데요. 예를 들어, 이 블로그 글 전체를 하나의 벡터로 표현하는 거죠. 그런데 위 그림처럼 2차원 벡터가 아니라, 1000차원이 넘는 벡터(OpenAI의 경우 1536차원)를 사용해요. 이렇게 텍스트를 숫자로 표현한 다음, 이걸 이용해서 GenAI와 Neo4j에 대한 다른 블로그 글(제가 쓴 글이 몇 개 있어요 😉)처럼 비슷한 텍스트를 검색할 수 있는 거예요. 이때 텍스트에 사용된 단어의 유사성이 아니라, 텍스트의 실제 의미(LLM이 이해하도록 설계된)를 기준으로 검색하는 거죠.
Neo4j를 사용하면 Vector Embedding을 Node의 Property로 저장한 다음, 특정 임베딩과 유사한 Node를 검색할 수 있어요. 검색 속도를 높이기 위해 이런 벡터들을 Indexing할 수도 있고요. 바로 이 기능을 이용해서 가사 검색기를 만들 거예요.
가사 검색기가 왜 필요할까요?
그런데 왜 이런 도구를 만들고 싶을까요? ChatGPT도 이 기능을 꽤 잘하거든요. 예를 들어, 제가 ChatGPT에게 이렇게 물어봤어요.
메탈리카 노래 중에 전쟁에서 심하게 다쳐서 감각을 잃은 남자에 대한 노래가 뭐였지?
그러자 ChatGPT는 이렇게 대답했어요.
당신이 언급한 메탈리카의 노래는 'One'입니다. "One"은 1988년 앨범 "...And Justice for All"의 트랙입니다. 이 곡은 제1차 세계대전 당시 부상을 입어 시각, 청각, 언어 등 모든 감각을 잃은 군인의 이야기를 담은 달튼 트럼보(Dalton Trumbo)의 소설 'Johnny Got His Gun'에서 영감을 받았다. 메탈리카는 이 노래에서 전쟁의 공포와 고통, 그리고 그러한 비극적인 상황에서 일어날 수 있는 개인의 정체성 상실을 전달한다.
음, 우리가 직접 이런 도구를 만들고 싶은 이유는 몇 가지가 있어요.
- ChatGPT는 Language Model이 훈련될 때 존재했던 정보만 알고 있어요. 그래서 만약 메탈리카의 최신 앨범 '72 Seasons'에 수록된 곡이었다면 찾지 못했을 거예요.
- ChatGPT는 훌륭하지만, 완전히 신뢰할 수는 없어요. 때로는 솔직한 거짓말을 하기도 하거든요.
- Spotify 같은 음악 서비스에 이 기능을 넣는다면, 모든 노래가 아니라 라이브러리에 있는 노래만 검색하면 되겠죠.
- 그리고 Spotify 같은 도구에 이런 기능을 통합하려면, 채팅 기능보다는 좀 더 명확하게 정의된 API를 통합하고 싶을 거예요.
우리가 만들 도구
시작하기 전에 OpenAI 계정을 만들어야 해요. Neo4j는 임베딩을 수행하기 위해 OpenAI, VertexAI, AWS Bedrock을 지원하지만, 이번에는 OpenAI를 사용할 거예요. OpenAI 계정은 유료 계정이라서 비용이 발생할 수 있지만, 제가 이 글을 쓰면서 테스트하는 데 사용한 비용은 2센트도 안 됐어요. OpenAI 계정에서 API Key를 생성해야 하고, 이 키는 아래 쿼리에서 $apiKey로 사용될 거예요.
GenAI 지원은 Neo4j 5.x 버전에서 점진적으로 이루어졌는데요. 여기서 사용할 가장 최신 기능인 임베딩 절차는 Neo4j 5.15에서 출시되었기 때문에, 이 버전을 사용할 거예요.
Neo4j 자체 인스턴스를 사용하고 있다면, neo4j-genai-plugin-5.XX.0.jar 파일을 복사해서 plugins 폴더에 넣어준 다음 Neo4j를 재시작해야 해요. AuraDB를 사용하고 있다면, 기본적으로 이 기능들을 바로 사용할 수 있답니다.
이 글의 내용을 테스트해보고 싶다면 AuraDB Free 인스턴스를 설정하는 것도 좋은 방법이에요. 여기서 무료 계정을 만들 수 있어요: 그리고 인스턴스를 만들어서 직접 테스트해볼 수 있죠. OpenAI 계정도 필요하다는 점, 잊지 마세요!
이번 글에서는 특정 기능을 구현하는 애플리케이션을 만들지는 않을 거예요. 대신 Neo4j Browser에서 Cypher 쿼리를 작성해볼 건데요, 실제 서비스를 개발한다면 당연히 이 쿼리들을 애플리케이션 코드에 통합해야겠죠?
세상 모든 노래에 대해 다 해보면 좋겠지만, 아쉽게도 그런 데이터를 구할 수가 없어서... 대신 St. Anger 앨범까지의 Metallica 노래 가사 라이브러리를 찾았어요. HTML 형식이었지만, 가사를 파싱해서 아티스트 (여기서는 Metallica 하나뿐!), 앨범, 노래로 이루어진 그래프를 만들었답니다. 노래 가사는 각 `Song` **node**의 문자열 **property**로 저장했어요.
직접 테스트해보고 싶다면, 아래 코드를 실행해서 똑같은 데이터셋을 가져올 수 있어요. 물론, 아래 `import` 구문에서 사용하는 것과 동일한 **스키마**를 따른다면, 좋아하는 아티스트와 노래를 사용해도 괜찮아요!
LOAD CSV WITH HEADERS FROM 'https://drive.google.com/uc?export=download&id=1uD3h7xYxr9EoZ0Ggoh99JtQXa3AxtxyU' AS line
CREATE (song:Song {name: line.Song, lyrics: line.Lyrics})
MERGE (album:Album {name: line.Album})
MERGE (artist:Artist {name: line.Artist})
MERGE (song)-[:IS_ON]->(album)
MERGE (album)-[:PERFORMED_BY]->(artist)자, 이제 **database**가 준비됐으니, 제일 먼저 할 일은 **vector**에 사용할 **property**에 대한 **vector index**를 만드는 거예요. 여기서는 `embedding`이라는 **property**를 사용할 거고, `Song` **node**에 저장할 거예요. `1536`은 **vector**의 차원인데 (OpenAI가 사용하는 차원과 같아요!), 마지막 **property**인 `'cosine'`은 사용할 유사도 알고리즘이에요. 일반적으로 `'cosine'`이 가장 많이 쓰인답니다.
CREATE VECTOR INDEX song_embeddings IF NOT EXISTS
FOR (s:Song) ON (s.embedding)
OPTIONS {
indexConfig: {
`vector.dimensions`: 1536,
`vector.similarity_function`: 'cosine'
}
}다음으로는 모든 노래 가사에 대한 **Vector Embedding**을 추가해야 해요. 간단한 `MATCH` **query**를 사용해서 노래를 찾은 다음, 가사 **property** 문자열을 **embedding** 함수에 전달하면 돼요.
MATCH (song:Song)
WITH song, genai.vector.encode(song.lyrics, "OpenAI", {token: $apiKey}) AS vector
CALL db.create.setNodeVectorProperty(song, "embedding", vector)`db.create.setNodeVectorProperty()` **procedure**는 `SET song.embedding = 임베딩`과 똑같은 역할을 하지만, **vector**를 더 효율적인 형식으로 저장해준다는 점이 다르답니다.
이 **query**는 **database**에 있는 모든 노래에 대해 OpenAI **API**를 한 번씩 호출하기 때문에, 실행하는 데 시간이 좀 걸릴 거예요. 위 함수 대신 **batch procedure**를 사용하는 방법도 있는데, 이 경우에는 (여기서는) 단 한 번의 **API** 호출만 발생해요.
MATCH (song:Song)
WITH collect(song.lyrics) AS lyrics, collect(song) AS songs
CALL genai.vector.encodeBatch(lyrics, "OpenAI", {token: $apiKey}) YIELD index, resource, vector
CALL db.create.setNodeVectorProperty(songs[index], "embedding", vector)여기서 주의할 점은 한 **batch**에 포함할 수 있는 항목 수에 제한이 있다는 거예요 (OpenAI의 경우 2048개). 따라서 **database**에 Metallica 말고 다른 아티스트의 노래도 있다면, 예를 들어 아티스트별로 또는 앨범별로 나눠서 처리해야 할 거예요.
자, 이제 모든 설정이 끝났으니 가사 **search**를 수행할 준비가 됐어요. 검색할 문구는 `phrase`라는 **parameter**로 설정하고, `apiKey`는 여전히 **parameter**로 유지할 거예요 (아래에는 표시하지 않았지만요).
:params
{
phrase: "A song about a guy who is so badly wounded in war so he no longer has any senses",
apiKey: "*****"
}**search**를 하려면, 먼저 똑같은 함수를 호출해서 검색 문구에 대한 **Vector Embedding**을 생성해야 해요. 그런 다음, 전용 **procedure**를 사용해서 **database**에서 가장 유사한 **embedding**을 가진 노래를 찾아주는 **vector search**를 수행하면 된답니다.
WITH genai.vector.encode($phrase, "OpenAI", {token: $apiKey}) AS embedding
CALL db.index.vector.queryNodes('song_embeddings', 1, embedding) YIELD node AS song, score
RETURN song.name이것이 우리에게 DISPOSABLE HEROES라는 답을 주네요. 글쎄요, 그건 우리가 기대했던 건 아니었어요. 우리는 ONE을 생각하고 있었거든요. DISPOSABLE HEROES 역시 고통에 대한 전쟁 노래이기 때문에 정답이긴 하지만, 우리가 원하는 건 아니죠. 이건 정확한 과학이 아니니까요. 그래서 일반적으로 최고의 일치 항목 수를 요청하는 게 가장 좋아요. 올바른 것은 일반적으로 상위 3~5개 결과에 있거든요. queryNodes의 두 번째 매개변수는 우리가 원하는 결과이니까, 이를 3으로 늘리면 돼요.
WITH genai.vector.encode($phrase, "OpenAI", {token: $apiKey}) AS embedding
CALL db.index.vector.queryNodes('song_embeddings', 3, embedding) YIELD node AS song, score
RETURN song.name이제 다시 실행해볼게요.
DISPOSABLE HEROES
ONE
ONE됐네요! 두 번째 일치로 올바른 것을 얻었어요. 그리고 세 번째 경기는…? 왜 우리는 그것을 두 번 얻을까요? 음, 두 개 이상의 앨범에 포함되어 있기 때문에 우리가 모델링한 대로 데이터베이스에 복제되는 거죠.
이것이 우리 솔루션을 뒷받침하는 Knowledge Graph를 갖는 것이 매우 좋은 점이에요. 가사를 기반으로 노래를 찾은 다음 그래프를 탐색하여 다른 모든 것을 찾을 수 있거든요.
WITH genai.vector.encode($phrase, "OpenAI", {token: $apiKey}) AS embedding
CALL db.index.vector.queryNodes('song_embeddings', 3, embedding) YIELD node AS song, score
MATCH (song)-[:IS_ON]->(album:Album)-[:PERFORMED_BY]->(artist:Artist)
RETURN song.name AS Song, album.name AS Album, artist.name AS Artist이제 결과는 이렇습니다.
Song Album Artist
DISPOSABLE HEROES MASTER OF PUPPETS Metallica
ONE S&M Metallica
ONE And Justice For All.. Metallica이제 제대로 작동하는지 확인하기 위해 한 번 더 테스트하면 돼요. 이번에는 다음을 검색해볼게요.
악몽을 꾸는 소년의 노래
결과는 다음과 같아요.
Song Album Artist
Enter Sandman Black Album Metallica
Enter Sandman S&M Metallica
The thing that should not be MASTER OF PUPPETS MetallicaEnter Sandman은 제가 의도한 것이므로 성공이라고 해야겠죠?
됐어요. 네 줄의 코드로 지능형 노래 시놉시스 찾기를 완료했어요!
참고 자료
Vector Search Index에 대한 문서는 다음과 같아요.
벡터 검색 인덱스 – Cypher 매뉴얼
여기에서 내장 함수/절차에 대한 문서를 찾을 수 있어요.
GenAI 통합 – Cypher 매뉴얼
- Vector Embedding 검색
- GenAI 도구
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'GraphRAG' 카테고리의 다른 글
| Neo4j GraphRAG Python 패키지 시작하기: 초보자 가이드 (0) | 2026.05.03 |
|---|---|
| GenAI 시작 키트: Java에서 Spring AI로 애플리케이션 구축에 필요한 모든 것 (0) | 2026.05.03 |
| GenAI 그래프 수집 2.0: GraphRAG의 진화 (0) | 2026.05.02 |
| 클라우드에서 완성하는 풀 스택 그래프: Neo4j로 GraphRAG 마스터하기 (0) | 2026.05.01 |
| 법률 문서에서 Knowledge Graph로: Neo4j와 GraphRAG 활용하기 (0) | 2026.05.01 |