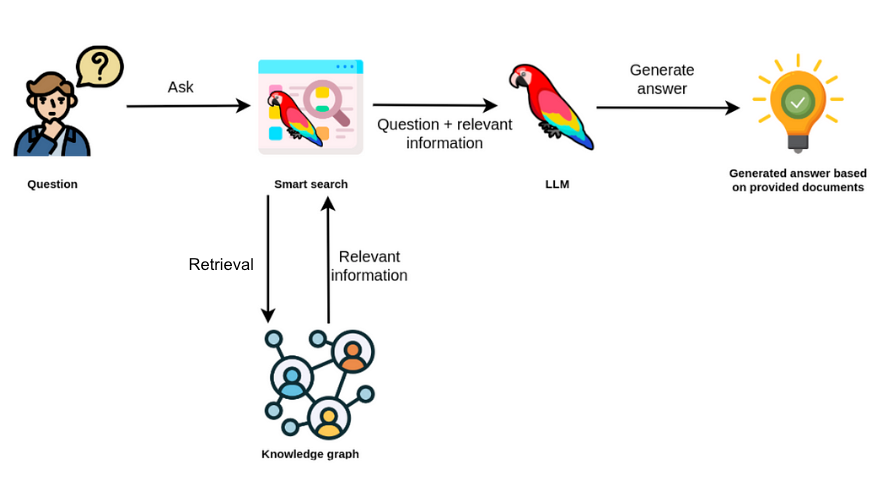
오늘날 대부분의 대규모 조직에서는 데이터가 사일로에 갇혀 있다는 점을 인지하고 있을 거예요.
데이터 연결이 끊어지면, 보고서가 불완전해지고 제대로 활용하기 어려워지죠. 그래서 데이터 사일로를 통합해서 보여주는 보고서가 필요한 거예요. 그래야 조직 내에서 중요한 정보를 찾고, 비즈니스 성공에 도움이 되는 정확한 정보를 실행하고 제공하는 부서의 능력을 확신할 수 있거든요.
NoSQL: 데이터 사일로에 대한 해답
대부분의 조직은 데이터 사일로 문제를 야기했던 도구와 기술로는 그 문제를 해결할 수 없다는 걸 이미 알고 있어요. 그래서 지난 몇 년 동안 NoSQL 데이터베이스와 기술이 개발되고 배포되는 걸 볼 수 있었죠. NoSQL은 데이터를 더 빠르고, 더 큰 규모로, 더 민첩하게 통합하는 데 도움을 주거든요.
이 강력한 새 데이터베이스와 플랫폼은 기존 방식보다 데이터 통합 시간을 단축시켜 주지만, 개발자 중심이라는 또 다른 과제를 안겨주죠. 특히, 이러한 최신 기술을 개발하고 사용하는 데 필요한 새로운 기술을 습득해야 해요.
우리는 데이터베이스 르네상스라는 멋진 시대에 살고 있고, 멋진 새로운 기술들을 모두 가지고 있지만, NoSQL 전문 지식은 아직 상대적으로 새롭고 발전하고 있어요. 40년 넘게 사람들은 SQL 기반 기술을 사용해서 데이터 관리 및 통합 솔루션을 개발해 왔거든요. 마치 40년 동안 사람들이 오른손으로 데이터 관리를 연습해 온 것과 같은 거죠.
NoSQL의 최첨단에 있는 사람들은 와서 데이터로 무엇을 할 수 있는지 보여주면서 이렇게 말해요. "보세요, 우리는 귀하의 데이터를 사용해서 유연하고 안전하게 대규모로 결과를 제공하고, 현재 수행하는 시간의 1/4 만에 통찰력을 제공할 수 있도록 도와드릴 수 있습니다!" 개발자와 기업은 우리의 말을 듣고 기뻐하며 "좋아요, 한번 해봐요! 어떻게 하면 되죠?"라고 외치죠. 그러면 우리는 "쉬워요! 이 새로운 기술로 성공하기 위해 우리가 할 일은... 왼손을 사용하도록 요청하는 것뿐입니다."라고 대답하는 거예요.
모든 기술 뒤에는 사람이 있습니다
기술 사일로 위에는 사람들의 사일로가 존재하죠. 이러한 기술 통합을 구현할 때, 새로운 시스템을 활용해서 최적의 결과를 얻으려면 변경 관리와 비즈니스 프로세스를 업데이트해야 하는 어려움이 있어요.
At FactGem에서는 코드를 작성하지 않고도 데이터를 통합할 수 있는 방법을 제공하고 있어요. FactGem의 엔지니어링 팀은 비즈니스 사용자가 직접 하지 않아도 되도록 통합의 복잡성을 처리하는 부담을 덜어준답니다.
결과적으로 데이터 통합 논의가 반드시 IT 부서에서 시작될 필요는 없어요. FactGem의 Data Fabric 애플리케이션은 기술 지식이 없는 사용자도 서로 다른 데이터 사일로를 신속하게 통합하여, 이전에는 단절되었던 데이터에 대한 통합 보고서를 제공하는 데 사용할 수 있답니다.
만약 여러분이 화이트보드에 조직의 데이터에 대한 entity와 relationship을 그릴 수 있다면, FactGem을 사용해서 데이터를 통합할 수 있어요. 정말 간단하죠?
FactGem 소개
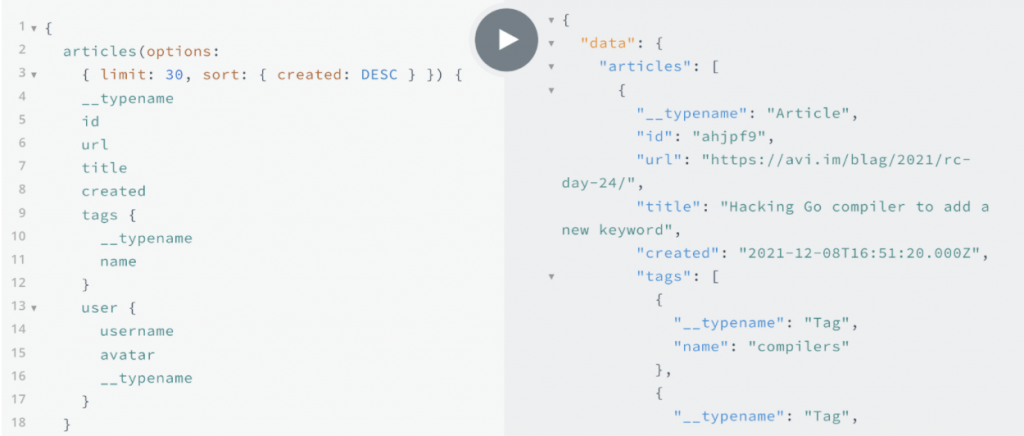
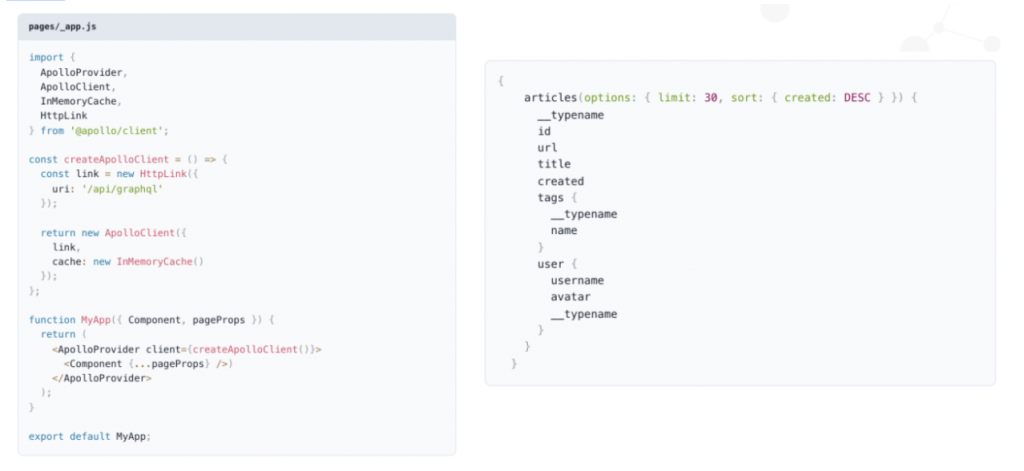
FactGem은 데이터 소스를 지정하고 필요한 소스만 로드할 수 있어요. 필요한 소스의 attribute만 필요에 따라 가져오는 거죠. WhiteboardR에서 관심 있는 소스에 대한 통합 모델을 만드는 것부터 시작한답니다.
다음으로, MappR을 사용해서 데이터 소스와 관심 있는 attribute를 WhiteboardR 모델에 매핑해요. 매핑이 완료되면 MonitR을 사용해서 데이터를 FactGem에 로드하여 통합 모델에서 즉시 액세스하고 query할 수 있어요. FactGem의 REST API, Tableau와 같은 BI 도구에 대한 웹 데이터 연결 또는 사용자 지정 추출을 통해 데이터에 액세스할 수 있답니다.
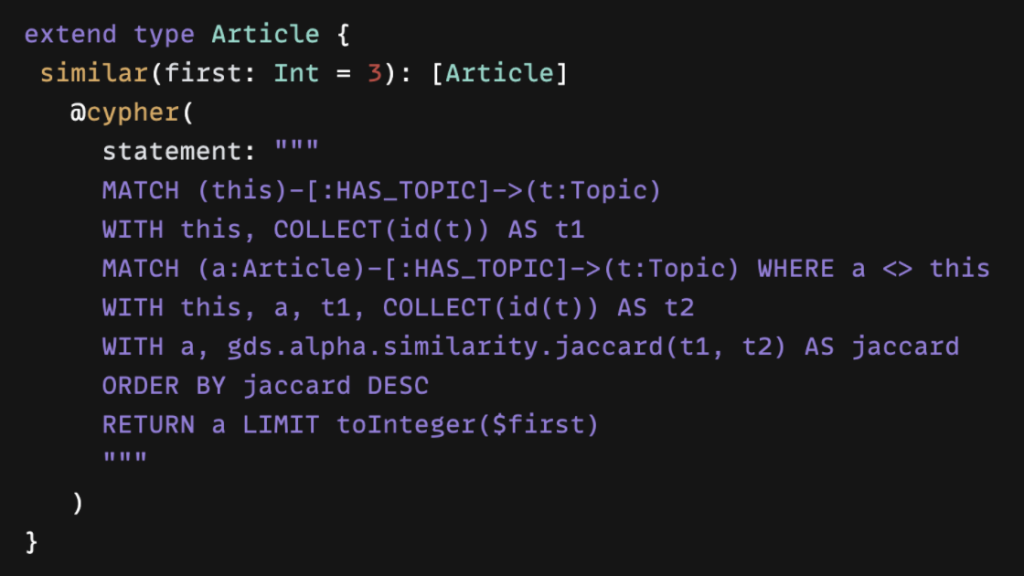
FactGem의 기업용 제공을 통해 그래프를 직접 활용할 수 있고, Cypher도 사용할 수 있어요.
FactGem: 그래프 초보자에게 적합
Neo4j 커뮤니티에 있는 우리는 Graph Database 기술의 가장 큰 장애물 중 하나는 사람들이 익숙하지 않고 그래프 기술이 무엇을 할 수 있는지 모른다는 점이라고 생각해요.
대부분의 경우 FactGem과 Neo4j가 해결하는 데 도움이 되는 데이터 통합 프로젝트 유형을 구현하는 대규모 조직에는 엄청난 양의 그래프 전문 지식이 없을 수 있어요. 하지만 우리는 그래프가 매우 중요하다고 믿기 때문에 그래프를 기업에 도입하는 데 도움을 주고 싶은 마음이 크답니다.
FactGem을 사용하면 드래그 앤 드롭 데이터 통합을 제공하고 이전 데이터 시스템에서는 사용할 수 없었던 데이터 통찰력에 대한 액세스를 제공해서 그래프가 수행할 수 있는 작업을 다른 사람에게 매우 빠르게, 그리고 쉽게 보여줄 수 있어요. 이를 통해 사람들은 그래프의 가치를 즉시 확인할 수 있고, 그래프 기술 채택에 더 많은 자원을 투자할 의향이 생기죠. 그리고 실제로 FactGem을 사용하는 사람들에게서 이런 패턴이 나타났어요.
기술적 지식이 없는 사용자도 FactGem을 사용해서 자신에게 적합한 웹 기반 인터페이스를 통해 즉각적인 결과와 통찰력을 얻을 수 있어요. 이 경험을 통해 그들은 그래프의 힘을 발견하고 궁극적으로 사람들이 왼손으로 연습하듯이 Neo4j 및 그래프 기술에 능숙해질 수 있도록 투자하게 된답니다. 여기에서 그래프에 대한 이점과 이해가 풍부해지는 거죠.
문의하기 자세히 알아보세요!
추가 리소스
FactGem과 Neo4j의 파트너십에 대한 자세한 내용을 확인해보세요. 여기에서 GraphConnect의 이전 블로그 게시물과 프리젠테이션을 확인할 수 있습니다.
엔터프라이즈 데이터 패브릭의 출현
좋은 것부터 그래프까지, 올바른 데이터베이스 선택
5분 인터뷰: FactGem CTO Clark Richey
5분 인터뷰: FactGem CEO Megan Kvamme
FactGem는 브론즈 스폰서입니다. GraphConnect New York에서 할인 코드FactGem30을 사용해서 티켓과 교육 비용을 30% 할인받으세요.
무엇을 기다리고 계신가요? GraphConnect New York 티켓을 구매하시고 10월 24일 맨해튼 Pier 36에서 만나요!
Cypher
FactGem
GraphConnect
NoSQL 데이터베이스
SQL
Tableau
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
기존 분석 방식으로는 대규모 데이터 세트 내의 복잡한 관계를 처리하기 어려워서, 많은 조직들이 연결된 데이터로부터 강력한 통찰력을 얻는 데 어려움을 겪고 있어요. 진정으로 정보에 기반한 의사 결정을 내리려면 사기 탐지, 추천 시스템 개선, 민감한 데이터 보호, 공급망 최적화 등 데이터 속 숨겨진 연결 고리를 이해하는 게 중요하죠.
그래프 분석은 데이터 엔터티 간의 관계를 분석해서 숨겨진 패턴, 추세, 이상 징후를 찾아내는 데 도움을 줘요. 기존 분석 방법으로는 놓칠 수 있는 예측을 가능하게 하고, 새로운 통찰력을 얻을 수 있게 해주죠.
이번 가이드에서는 그래프 분석이 어떻게 데이터 문제를 기회로 바꿔주는지 알아볼 거예요. 그래프 분석의 실제 적용 사례들을 살펴보고, 가 어떻게 복잡한 데이터 분석을 간소화하고 즉시 활용 가능한 통찰력을 제공하는지 배워볼게요.
사기 탐지 및 위험 분석: 복잡한 사기 계획 탐색
은행, 소매업체, 통신 회사, 전자 상거래 기업들은 모두 보안 위험에 노출되어 있죠. 예를 들어 합성 신원 사기, 계정 탈취, 정교한 교차 채널 공격 등이 있을 수 있어요. 조직은 공유 IP 주소, 장치 지문 일치, 조정된 거래 패턴 등 악의적인 행위자들과 그들의 활동 간의 연결 고리를 식별해서 사기 조직과 사이버 범죄 네트워크의 정체를 밝혀내고 피해를 예방하거나 최소화할 수 있어요. 하지만 안타깝게도, 이런 연결 고리들은 엄격한 테이블 구조를 강요하고 복잡한 관계를 표현하는 데 많은 비용이 드는 기존 관계형 데이터베이스 아키텍처에서는 잘 보이지 않는 경우가 많아요. 특히 JOIN 연산은 더욱 그렇죠. 악의적인 행위자들은 의심스러운 활동을 여러 계정과 채널에 분산시켜서 이러한 구조적 제약, 특히나 `Schema`의 경직성이나 JOIN 관련 성능 제약을 악용하곤 해요.
이러한 아키텍처 제약으로 인해 다음과 같은 시스템이 만들어지게 돼요.
사전 정의된 규칙에 의존하며, 진화하는 사기 전술에 제대로 적응하지 못해요.
충분한 맥락 정보 없이 연결 고리만 분석하기 때문에 잘못된 경고를 많이 발생시켜요.
다양한 플랫폼이나 서비스 전반에서 조직적으로 이루어지는 사기 활동을 제대로 탐지하지 못해요.
관계형 데이터베이스를 사용하는 기존 사기 탐지 시스템이 가진 핵심적인 기술적 문제들을 해결하는 데 도움을 줄 수 있는 Neo4j Aura Graph Analytics를 소개합니다! 아래 표에서 Neo4j Aura Graph Analytics가 사기 탐지에 어떤 영향을 미칠 수 있는지 한번 살펴볼까요?
Neo4j 그래프의 장점
고정된 스키마 요구 사항
새로운 사기 패턴에 대비해 비용이 많이 드는 데이터 모델 재설계 필요
새로운 위협 패턴에 적응하는 유연한 스키마
JOIN 집중 쿼리
연결된 데이터 분석으로 인한 기하급수적인 성능 저하
기본 관계 인덱싱으로 실시간 패턴 일치 가능
멀티홉 관계 분석
규모에 따라 계산이 불가능함
경로 깊이에 관계없이 일정한 시간 순회
사용 사례: 자금세탁 집단 식별
그래프 알고리즘은 계정 간의 거래 흐름을 추적해서 잠재적인 자금 세탁 활동을 찾아내요. 예를 들어, 여러 지역에 걸쳐 관련 없는 계정 간에 이체가 빠르게 연속적으로 발생하면 의심스러운 행동을 나타낼 수 있죠. Neo4j AuraDB 같은 Graph Database는 계정을 Node로, 트랜잭션을 Relationship으로 모델링해서 주기, 클러스터 및 "허브" 계정을 감지한답니다.
이 시각화는 전형적인 자금세탁 계획을 보여주네요.
여러 관할권에 걸친 국제 거래(미국, 중국, 러시아, 브라질, 인도, 케이맨 제도)
조세 피난처의 중앙 허브 계정(케이맨 제도)
결국 근원으로 돌아가는 순환적인 돈의 흐름
각 전송 시 약간의 양 감소(스트리핑)
신속한 연속 전송(모두 몇 시간 내에 발생)
Neo4j Aura 그래프 분석은 중복 제거 및 엔터티 해결을 합리화해서 유사한 엔터티와 그 Relationship을 식별해요. 데이터 엔터티(고객, 계정, 장치 등)를 속성(이름, 주소, 이메일 등)을 소유한 Node로 모델링한 다음 이러한 엔터티 간의 Relationship을 생성해서 상호 작용이나 연결을 나타낼 수 있죠. 이 접근 방식을 사용하면 데이터 생태계 전반에서 엔터티가 어떻게 연결되어 있는지 확인하고 기존 데이터베이스에서 종종 놓치는 패턴을 찾아낼 수 있어요. 예를 들어, 이름은 약간 다르지만 동일한 판매자 계정과 동일한 거래 패턴을 가진 두 개의 고객 레코드가 있는 경우 이를 잠재적인 중복으로 표시할 수 있답니다.
대규모 데이터 세트에서 JOIN 집약적인 작업으로 어려움을 겪는 기존 관계형 데이터베이스와 달리 Neo4j의 솔루션은 대규모 데이터 세트 내의 Relationship을 효율적으로 분석해서 성능 문제 없이 수백만 개의 엔터티로 확장돼요.
Neo4j Aura Graph Analytics는 확률적 커뮤니티 감지와 유사성 알고리즘을 결합해서 정교한 사기 감지도 가능하게 해요. 플랫폼의 약하게 연결된 구성요소 알고리즘은 의심스러운 속성을 공유하는 그룹 계정은 관련 없어 보이는 개체 간의 숨겨진 연결을 드러내죠.
다음과 같은 유사성 알고리즘 Jaccard, 코사인 및 오버랩은 여러 차원에서 서로 다른 엔터티가 얼마나 밀접하게 일치하는지 측정해서 합성 ID를 감지하는 데 도움이 돼요. 예를 들어 Jaccard 유사성은 합법적인 신원 구성 요소의 비정상적인 조합을 식별해서 도난당한 데이터 조각으로 구성된 잠재적인 합성 신원을 표시할 수 있죠. 이 접근 방식은 복잡한 JOIN 작업의 성능 저하 없이 실시간 사기 위험 점수를 생성하므로 금융 기관이 즉시 조치를 취할 수 있답니다.
Neo4j 그래프 기술을 사용해서 자금 세탁을 방지하는 방법에 대해 자세히 알아보려면 다음을 읽어보세요. 이 심층 가이드. Neo4j를 사용한 사기 탐지에 대해 더 자세히 살펴보고 싶다면 다음을 확인하세요. 이 블로그 시리즈.
추천 엔진: 관계를 통해 고객 참여 강화
전자상거래 및 스트리밍 서비스는 기존 추천 시스템으로 인해 어려움을 겪고 있어요. 대부분은 협업 필터링을 사용해서 사용자 유사성이나 과거 상호 작용을 기반으로 항목을 추천하죠. 이 접근 방식은 빈도나 기록 기반 패턴을 넘어 다양한 제품이나 사용자 행동이 어떻게 연결되어 있는지와 같은 복잡한 Relationship을 식별하지 못하는 경우가 많아요.
기존 시스템은 또한 "콜드 스타트" 문제로 어려움을 겪고, 정적인 과거 데이터에 의존해서 진정으로 개인화된 경험을 제한한답니다.
사용 사례: 개인화된 콘텐츠 추천
Netflix나 Spotify 같은 스트리밍 서비스들은 그래프 기반 추천 엔진이 얼마나 뛰어난 개인화 경험을 제공할 수 있는지 보여주는 좋은 예시죠. Netflix는 시청 기록뿐만 아니라 시청 시간, 시간대, 사용 기기 등 시청 방식까지 분석해서 서로 연결된 데이터 포인트를 활용해 복잡한 네트워크를 만들어요.
Spotify도 마찬가지로 음악 객체(노래, 아티스트, 앨범)와 이들의 관계(장르, 분위기, 아티스트)를 나타내는 Knowledge Graph를 사용해서 Discover Weekly 플레이리스트를 제공하고 있어요. 그래프 구조 안에서 콘텐츠 속성과 사용자 행동을 모두 분석함으로써, 기존의 테이블 형태 데이터베이스에서는 놓칠 수 있는 미묘한 음악적 선호도까지 연결할 수 있는 거죠.
스트리밍 플랫폼이 그래프 기반 방식으로 추천 시스템을 설계하는 방법을 한번 살펴볼까요?
이 다이어그램은 서로 연결된 사용자, 프로그램, 완료율, 그리고 기기를 보여주는 스트리밍 플랫폼 네트워크를 나타내요. 그래프 기반 접근 방식은 이러한 엔터티 간의 깊은 관계를 밝혀내서 플랫폼이 상황을 잘 파악한 추천 시스템을 구축할 수 있도록 도와주죠.
Neo4j Aura Graph Analytics는 65개 이상의 내장 그래프 알고리즘, 예를 들어 개인화된 PageRank나 K-최근접 이웃 같은 알고리즘을 통해 다양한 차원에서 관계를 분석해서 추천 정확도를 높여요. 이러한 알고리즘은 그래프 구조를 사용해서 근접성, 영향력, 유사성을 기준으로 항목 점수를 매기고, 1초 안에 개인화된 제안을 제공해서 참여 지표를 개선하는 데 도움을 줘요. Neo4j는 유연한 스키마와 확장 가능한 아키텍처를 통해 개발 주기를 단축시켜 주기도 하고요.
Neo4j는 사용자, 항목, 상호 작용을 Nodes와 Relationships로 모델링해서 복잡한 Queries를 단순화하고 실시간으로 적응하는 추천을 제공해요. 최신 추천 엔진을 위한 이상적인 솔루션이라고 할 수 있죠.
공급망 최적화: 복잡한 네트워크 관계 마스터하기
제조, 소매, 물류, 제약, 식품 회사들은 공급망 문제 때문에 어려움을 겪고 있어요. 공급망 단계 사이의 격차 때문에 가시성이 계속 문제가 되고, 기존 데이터베이스 시스템은 속도가 느리죠. 문제가 발생하면 기업들은 영향을 받는 제품을 빨리 찾아내거나 백업 공급 업체를 찾기가 어려울 때가 많아요. 기존 시스템은 현대 공급망의 고도로 연결된 특성을 처리하도록 만들어지지 않았거든요. 공급업체와 물류 데이터를 저장하기 위해 엄격한 스키마를 사용하기 때문에 상호 의존성을 분석하기가 어렵기 때문이에요.
그래프 분석 모델은 공급망을 서로 연결된 엔터티의 실제 네트워크로 표현해요. Neo4j Aura 데이터베이스를 사용하면 공급망 관리자는 네트워크 깊이에 상관없이 일관된 성능으로 여러 단계의 공급업체, 유통 센터, 운송 경로를 탐색할 수 있어요. 이를 통해 문제가 발생했을 때 실시간으로 영향 분석을 할 수 있을 뿐만 아니라, 기존 관계형 데이터베이스 시스템이 따라올 수 없는 사전 예방적 위험 관리도 가능해져요.
사용 사례: 위험 완화 및 경로 최적화
공장, 유통 센터, 항구, 운송 경로를 서로 연결된 그래프로 모델링함으로써 제조업체는 최적의 배송 경로를 식별하는 동시에 잠재적인 병목 현상을 빠르게 감지하고 예방할 수 있어요.
글로벌 제조업체가 Neo4j를 사용해서 어떻게 공급망을 최적화하는지 한번 살펴볼까요? 아래 시나리오는 다단계 공급망 전체에서 가시성 문제에 직면한 회사가 그래프 분석을 사용해서 전체 공급 네트워크를 그래프로 모델링하고 다음과 같은 통찰력을 얻는 방법을 보여줘요.
2차 및 3차 공급업체에 대한 의존도
구성 요소 전달을 위한 중요 경로
특정 지역의 위험 집중
문제 발생 시 대체 소싱 기회
Neo4j의 그래프 모델을 사용하면 신속하게 영향 평가를 하고 대체 공급업체를 활성화할 수 있어요. 최단 경로 알고리즘으로 밀리초 단위로 라우팅을 최적화하는 거죠. 그동안 매개 중심성은 단일 포트가 배송의 80%를 처리하는 것처럼 중요한 오류 지점을 정확히 찾아낸답니다.
Neo4j Aura는 재고 및 운송 시간부터 외부 위험까지 공급망 데이터를 효율적으로 분석해줘요.
사이버 보안 및 위협 탐지: 디지털 위협 환경 매핑
금융 서비스, 정부 기관 및 중요 인프라 부문이 직면한 문제는 정교한 위협인데요, 이들은 네트워크를 통해 측면으로 이동하면서 의도적으로 합법적인 동작을 모방해요. 이러한 위협은 알려진 공격 패턴에 의존하는 기존 탐지 임계값을 회피하죠.
그래프 분석은 보안 데이터를 격리된 경고나 로그가 아닌 상호 연결된 엔터티 및 이벤트로 모델링해요. 사용자, 장치, IP 주소 및 네트워크 활동을 Node와 Relationship으로 표시함으로써 Neo4j는 네트워크 전반에 걸쳐 시간이 지남에 따라 전개되는 공격 패턴을 추적할 수 있어요. 이러한 관계 중심 접근 방식을 통해 보안 팀은 기존 방식에서 볼 수 없었던 측면 이동, 권한 상승, 데이터 유출 시도를 탐지할 수 있는데, 이는 보안정보 및 이벤트 관리(SIEM) 시스템이 놓치는 부분이죠.
Neo4j Aura Graph Analytics 알고리즘은 겉으로는 관련이 없어 보이는 이벤트 사이의 미묘한 연결을 식별하여 매일 발생하는 수십억 건의 보안 이벤트 속에 숨겨져 있을 공동 공격을 밝혀낼 수 있답니다.
사용 사례: 피싱 캠페인에 대응
금융 기관은 공격자가 합법적인 기관을 사칭하여 중요한 시스템에 무단으로 액세스하는 정교한 피싱 캠페인에 직면해 있어요. 이러한 공격에는 일반적으로 스푸핑된 이메일, 가짜 웹사이트, 사회 공학적 전술 등 여러 접점이 포함되어 있어서 기존 보안 도구로는 탐지하기 어렵죠. 이러한 캠페인이 성공하면 자격 증명 도용, 계정 탈취, 그리고 궁극적으로 수천 명의 고객에게 영향을 미치는 데이터 침해로 이어질 수 있어요.
보안 팀의 과제는 여러 시스템과 기간에 걸쳐 서로 다른 지표를 연결하여 조정된 캠페인이 성공하기 전에 식별하는 거예요. 기존 SIEM 시스템은 새로운 공격 기술에 적응할 수 없는 사전 정의된 상관 관계 규칙에 의존하기 때문에 이러한 복잡한 공격 패턴을 식별하는 데 어려움을 겪죠.
보안 팀은 서로 다른 보안 데이터를 포괄적인 그래프 모델로 통합하여 이러한 문제를 극복할 수 있어요. 물리적 개체에 초점을 맞춘 공급망 모델링과 달리 사이버 보안 그래프는 계정, 장치, 애플리케이션 및 네트워크 리소스를 액세스 관계 및 상호 작용 이벤트와 통합합니다. 더욱이, Neo4j LLM 지식 그래프 빌더는 구조화되지 않은 보안 로그 및 위협 인텔리전스 보고서에서 엔터티와 관계를 추출할 수 있답니다.
보안 데이터에 대한 전체적인 뷰를 통해 금융 회사는 IP 주소, 장치 지문, 로그인 시도를 매핑해서 숨겨진 연결을 찾을 수 있어요.
예를 들어 공격자가 탐지를 피하려고 IP 주소를 바꿔도, 그래프 분석을 통해 단일 장치에서 접근하는 의심스러운 계정 클러스터가 드러날 수 있죠. 보안 팀은 그래프를 탐색하면서 네트워크를 통해 공격자의 측면 이동을 추적하고, 캠페인에서 잠재적으로 손상될 수 있는 모든 계정, 시스템, 데이터 세트를 식별할 수 있어요.
Neo4j의 중심성 알고리즘은 공격자가 표적으로 삼을 만한 중요한 리소스를 찾아낼 수 있어요. 예를 들어 PageRank는 과도한 권한을 가진 고도로 연결된 서버를 식별할 수 있고, Label Propagation은 유사한 행동 패턴을 보이는 손상된 사용자 계정 그룹을 탐지하는 데 도움이 되죠. 이런 알고리즘은 데이터베이스 크기에 상관없이 효율적으로 작동하기 때문에, 관계형 데이터베이스 쿼리를 손상시킬 수 있는 성능 저하 없이 페타바이트 규모의 보안 데이터에서 실시간 위협 검색이 가능해요.
콘텐츠 네트워크 및 미디어 인텔리전스: 정보 생태계 탐색
미디어 조직, 뉴스 매체, 콘텐츠 게시자는 콘텐츠, 주제, 객체, 청중 상호 작용 간의 복잡한 관계를 관리하는 데 어려움을 겪고 있어요. 기존 시스템은 키워드 매칭에 의존하기 때문에 콘텐츠 검색 및 인사이트 생성에 한계가 있죠.
그래프 분석은 정보 생태계의 자연스럽게 연결된 구조를 모델링해서 콘텐츠 관리를 혁신해요. Neo4j를 사용하면 조직이 Knowledge Graph를 만들 수 있어요. 기사, 주제, 사람, 장소, 이벤트는 복잡한 JOIN이 필요한 조각난 테이블이 아니라, 서로 연결된 네트워크로 존재하는 거죠. 이 접근 방식은 수백만 개의 문서에서도 일관된 쿼리 성능을 유지하면서, 기존 시스템이 감지할 수 없는 상황별 관계와 패턴을 드러내요.
사용 사례: 잘못된 정보 네트워크 식별
잘못된 정보 캠페인에는 생성된 콘텐츠를 개별적으로 분석할 때 합법적인 것처럼 보이는 조정된 계정 네트워크가 포함돼요. 격리된 콘텐츠에 초점을 맞추는 기존 조정 시스템은 이런 조직적인 노력을 제대로 감지하지 못하죠.
Neo4j는 구조화되지 않은 콘텐츠를 풍부한 Knowledge Graph로 변환해서 이런 문제를 해결해요. 여기서 엔티티와 그 관계가 눈에 보이게 되죠. 예를 들어 미디어 인텔리전스 회사는 사용자 계정, 콘텐츠, 해시태그, 참여 패턴을 상호 연결된 그래프로 모델링해서 정치적 행사 중에 수백만 개의 소셜 미디어 게시물을 분석할 수 있어요. 이렇게 표현하면 기존 분석에서는 보이지 않던 네트워크 구조가 바로 드러나죠.
사용자, 게시물, 관련 해시태그, 다양한 주제를 매핑해서 의심스러운 패턴을 찾아내는 샘플 그래프를 한번 살펴볼까요?
각 게시물은 개별적으로 보면 괜찮아 보일 수 있지만, 그래프에서는 조정된 콘텐츠 증폭, 공유 장치, 유사한 해시태그의 반복 사용을 나타내는 멀티홉 관계를 식별할 수 있어요.
Neo4j의 그래프 알고리즘은 사용자 참여를 분석하는 데 도움을 주는데요. 예를 들어, 학위 중심성 알고리즘(Degree Centrality Algorithm)을 통해 참여를 유도하는 영향력 있는 계정을 식별하고, 루뱅 알고리즘(Louvain Algorithm)으로 상호 작용 패턴을 기반으로 사용자를 의미 있는 커뮤니티로 분류할 수 있죠. 가장 중요한 점은 연결되지 않은 이데올로기 그룹을 연결하는 연결 중심성이 높은 계정이 잠재적인 잘못된 정보 슈퍼전파자로 식별될 수 있다는 거예요. 이러한 전략적 Node에 조정 노력을 집중함으로써 플랫폼은 광범위한 콘텐츠 검열 없이 허위 정보의 확산을 줄일 수 있답니다.
이러한 타겟 접근 방식은 잘못된 정보를 억제할 뿐만 아니라 사용자가 커뮤니티 내에서 그리고 네트워크 전반에서 상호 작용하는 방식을 밝혀 더 깊은 참여 통찰력을 제공해요.
의료 및 생의학 연구: 생명을 구하는 연관성 찾기
의료 서비스 제공자, 제약 회사, 연구 기관은 전자 건강 기록, 게놈 서열, 단백질 상호 작용, 임상 시험을 포괄하는 방대한 생물 의학 데이터 세트를 관리하고 있어요. 기존의 관계형 데이터베이스는 질병, 약물, 환자 간의 관계를 추적하기 어렵게 만드는 방식으로 데이터를 조각화하죠.
관계형 데이터베이스에서 생물학적 관계를 Query하는 작업은 경로 길이에 따라 기하급수적으로 느려지고, 다단계 분석에 많은 비용이 들어요. 다양한 생물 의학 데이터 형식과 온톨로지의 통합을 복잡하게 만드는 엄격한 Schema 요구 사항과 결합된 이러한 단편화는 약물 발견 노력과 포괄적인 환자 치료를 심각하게 방해한답니다.
그래프 분석은 생물학적 시스템을 단절된 데이터 사일로가 아닌 상호 연결된 네트워크로 표현함으로써 생의학 연구를 변화시키는데요. Neo4j의 Schema에 구애받지 않는 구조는 게놈 데이터, 단백질체학, 임상 기록, 연구 문헌을 통일된 Knowledge Graph로 원활하게 통합하여 의료 혁신을 주도하는 상황별 관계를 보존해요. 사전 정의된 JOIN 테이블이 필요한 관계형 데이터베이스와 달리 Neo4j는 관계 깊이에 대한 성능 저하 없이 3단계 약물-단백질-질병 상호 작용을 분석하든 10단계 대사 단계를 분석하든 상관없이 복잡한 경로를 지속적으로 탐색할 수 있어요. 이 기능은 전자 건강 기록(Electronic Health Record)과 CRISPR처럼 서로 다른 데이터 소스를 연결할 때 정말 중요하죠. 기존 시스템이 호환되지 않는 Schema와 지연된 Query 응답으로 어려움을 겪고 있는 심사 결과에요.
사용 사례: 약물 용도 변경
약물 용도 변경, 즉 기존 승인 약물에 대한 새로운 치료 응용 분야를 찾는 것은 일반적으로 10~15년과 수십억 달러가 소요되는 기존 약물 개발보다 더 빠르고 비용 효율적인 치료 경로를 제공해요. 하지만 유망한 용도 변경 후보를 식별하는 것은 쉽지 않아요. 단백질-단백질 상호 작용, 유전자 발현 패턴, 경로 분석, 임상 결과를 포함하여 서로 다른 데이터 세트에 걸쳐 복잡한 생물학적 상호 작용을 분석해야 하거든요. 기존의 데이터베이스 접근 방식은 이러한 다차원 관계 Query로 인해 어려움을 겪기 때문에 잠재적인 연결을 체계적으로 발견하는 것이 거의 불가능하답니다.
잠재적인 약물 용도 변경 기회를 식별하기 위해 약물, 질병, 유전자, 단백질 간의 관계를 명시적으로 모델링하는 샘플 그래프를 한번 살펴볼까요?
Neo4j는 질병, 약물, 유전자, 단백질, 경로 등 수많은 생물 의학 개체를 포괄적인 Knowledge Graph로 연결해줘요. 공개 데이터와 독점 데이터를 통합해서 기업은 생물학적 메커니즘, 약물 표적, 질병 경로에 대한 통합된 뷰를 만들 수 있죠.
게다가 Neo4j의 Text2Cypher 기능 덕분에, 해당 분야 전문가가 Natural Language Processing 쿼리를 사용해서 정교한 네트워크 분석을 수행할 수 있어요. 전문적인 프로그래밍 기술이 없어도 괜찮아요! 예를 들어 임상의가 "질병 Y에서 상향 조절되는 유전자 X와 동일한 경로를 표적으로 하는 승인된 약물은 무엇입니까?"라고 간단하게 질문할 수 있고, 잠재적인 용도 변경 기회를 시각적으로 매핑된 결과로 얻을 수 있는 거죠.
TensorFlow 같은 Machine Learning 프레임워크와 통합되면, Neo4j는 Graph Neural Network 기술을 통해 새로운 약물 상호작용과 부작용을 예측해서 약물 재활용을 향상시킬 수 있어요. 이런 모델은 Graph 표현 고유의 풍부한 관계 컨텍스트를 사용해서 기존 표 형식 데이터로는 불가능했던 예측 정확도를 달성하는 거죠.
IT 인프라 및 네트워크 관리: 디지털 생태계 매핑
복잡한 IT 인프라를 가진 대기업은 물리적 환경과 가상 환경 전체에서 컴포넌트 간의 관계를 모델링하고 분석하는 데 어려움을 겪고 있어요. 기존 도구는 현대 기술 생태계의 역동적이고 상호 연결된 특성을 제대로 포착하지 못하는 정적인 표현을 사용하기 때문에, 종속성을 이해하고 영향을 추적하며 중요한 경로를 식별하는 게 거의 불가능하죠.
Neo4j Aura Graph Analytics는 기술 환경을 자연스럽게 상호 연결된 시스템으로 모델링해서 IT 인프라 관리를 위한 이상적인 기반을 제공해요. Neo4j는 서버, 애플리케이션, 네트워크 장치, 서비스를 Nodes로 표현하고, 해당 종속성과 통신 경로를 Relationships로 표현해서 전체 생태계의 살아있는 지도를 만드는 거예요.
Neo4j는 다른 방법으로는 즉시 종속성을 매핑해요. 예를 들어 Configuration Management Database는 "이 서버에 장애가 발생하면 어떤 애플리케이션이 영향을 받나요?"와 같은 간단한 Query에 복잡한 JOIN이 필요한 관계형 데이터베이스를 기반으로 구축되었죠. 이는 컨테이너 오케스트레이션이 기존 인벤토리 시스템이 효과적으로 추적할 수 없는 지속적으로 변화하는 인프라를 생성하는 클라우드 네이티브 환경에서 특히 중요해요.
With Neo4j의 실시간 관계 모델링, IT 팀은 폭발 반경 계산을 즉시 시각화하고, 근본 원인 분석을 수행하고, 기존 모니터링 도구에 숨겨져 있던 단일 장애 지점을 식별할 수 있어요.
사용 사례: 클라우드 비용 최적화
환경이 점점 더 복잡해짐에 따라 클라우드 인프라를 최적화하는 건 점점 더 어려워지고 있어요. 일반적으로 조직은 사용되지 않는 Resources를 식별하고, 서비스 간의 종속성을 이해하고, 중요한 비즈니스 운영을 방해하지 않고 컴포넌트를 안전하게 폐기하는 데 어려움을 겪죠. 기존의 클라우드 관리 도구는 기본적인 사용량 지표를 제공하지만, Resources 간의 복잡한 관계 웹을 드러내는 데는 실패했어요. 이로 인해 고아 인스턴스, 과잉 프로비저닝된 서비스, 중복 컴포넌트에 대한 불필요한 지출이 발생해요. 이러한 종속성을 완전히 파악하지 못한 채 비용 절감 계획을 시도하면 기업은 예상치 못한 서비스 중단을 초래할 위험이 있어요.
예를 들어 아래 그래프는 데이터베이스 및 컴퓨팅 인스턴스와 같은 배포된 클라우드 애플리케이션에 대한 종속성을 보여줍니다.
클라우드 인프라에는 사용량 지표를 자세히 보지 않으면 찾기 힘든 고아 인스턴스가 있을 수 있어요.
SaaS 제공업체는 Neo4j를 사용해서 전체 클라우드 인프라를 연결된 그래프로 모델링해서 이런 문제를 해결할 수 있죠. 애플리케이션, 서비스, 데이터베이스, 컴퓨팅 리소스 간의 종속성을 매핑해서 직/간접적인 관계를 모두 보여주는 환경의 포괄적인 디지털 트윈을 만드는 거예요. Neo4j의 중심성 알고리즘을 사용하면 중요한 경로와 병목 현상을 식별하는 동시에, 여전히 비용이 발생하는 고아 리소스와 축소할 수 있는 활용도가 낮은 EC2 인스턴스를 찾을 수 있어요. 가장 중요한 점은, 그래프 시각화가 독립적으로 보이는 서비스 간의 숨겨진 종속성을 보여줘서 팀이 연속적인 오류 없이 중복 구성 요소를 안전하게 해제할 수 있다는 거죠.
Neo4j AuraDB의 실시간 `Query` 기능은 IT 팀이 인프라를 모니터링하고 문제를 해결하는 방식을 바꿔줘요. 제한된 컨텍스트로 미리 정의된 대시보드만 제공하는 기존 모니터링 도구와는 달리, Neo4j는 모든 시작점에서 전체 종속성 체인을 동적으로 탐색할 수 있어요. 사고가 발생하면 팀은 영향을 받는 모든 서비스, 데이터베이스, 애플리케이션 전반에 걸쳐 영향 경로를 즉시 추적할 수 있죠. 예를 들어, 깊이 우선 검색 경로 찾기 알고리즘을 사용하면 여러 서비스 계층에서 API 오류의 근본 원인을 빠르게 추적해서 평균 해결 시간을 크게 줄일 수 있어요. 이러한 실시간 관계 인식은 사전 비용 최적화와 사후 사고 관리 모두에 필요한 상황별 이해를 제공해요. 이건 플랫 파일 CMDB와 기존 모니터링 도구가 제공할 수 없는 기능이죠.
결론
그래프 분석은 기존 시스템이 효과적으로 해결할 수 없는 문제를 해결함으로써 연결된 데이터를 이해하는 새로운 방법을 조직에 제공해요. 그래프 기술은 데이터 포인트 간의 관계를 자연스럽게 모델링함으로써 사기 탐지에서 숨겨진 패턴과 관계를 찾아내고, 미묘한 추천을 제공하고, 복잡한 공급망을 최적화하고, 사이버 보안 방어를 강화하고, 콘텐츠 검색을 개선하고, 생물 의학 연구를 가속화하고, IT 인프라 관리를 단순화하죠.
Neo4j Aura 그래프 분석은 조직이 전문적인 인프라 전문 지식 없이도 그래프 솔루션을 빠르게 구축하고 확장할 수 있는 확장 가능하고 직관적인 플랫폼을 제공해요. 내장된 알고리즘, 직관적인 시각화 기능, 구조화된 데이터와 구조화되지 않은 데이터를 원활하게 결합하는 기능을 통해 팀은 데이터에서 실행 가능한 통찰력을 빠르게 얻을 수 있죠.
궁극적으로 Neo4j Aura Graph Analytics는 조직이 격리된 데이터 포인트를 넘어 비즈니스를 추진하는 관계에 대한 더 깊은 이해를 향해 나아가고 복잡한 과제를 성장과 혁신을 위한 명확한 기회로 전환하도록 도와요.
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
많은 오픈 소스 커뮤니티에서는 사람들이 가입하고 탈퇴하지만, 우리 곁을 떠나는 경우는 드물죠.
정말 안타깝게도, 저희의 친구이자 동료인 Anders Nawroth가 지난 주말 세상을 떠났다는 소식을 전하게 되었어요.
그의 아내와 아들, 그리고 모든 가족들에게 깊은 위로를 전합니다. 사랑하는 친구이자 오랜 동반자를 잃은 슬픔에 함께 마음 아파하고 있어요. Anders가 힘든 암 투병을 하는 동안 보여준 용기와 의지에 정말 감탄했어요. 모두가 희망을 놓지 않았지만, 결국 역부족이었고 그는 우리 곁을 떠나게 되었네요.
Neo4j를 처음 사용한 분들은 Anders가 작성한 문서와 예제들을 보면서 감동받았을 거예요. 눈에 잘 띄진 않지만, Anders의 작업은 Neo4j를 시작하고 사용하는 많은 사람들에게 큰 도움이 되었죠.
Anders는 조용하고 내성적인 사람이었지만, 사람들과 가르치는 것, 글쓰는 것에 큰 열정을 가지고 있었어요. 뛰어난 기술 작가이자 음악가였지만, 훌륭한 스토리텔러이자 작가이기도 했답니다.
Anders는 Neo Technology의 직원 #4였기 때문에 (현재는 120명이 넘어요!) 그가 없는 시간은 상상하기 어려워요. 그는 사람들이 데이터를 더 잘 이해하도록 돕는 우리의 미션에 깊은 관심을 가지고 있었죠.
조용하고 겸손한 성격 때문에 많은 사람들이 그를 과소평가했지만, 그의 생각과 유머, 지혜를 알아본 사람들은 그와 함께 즐거운 시간을 보냈을 거예요. Anders는 정말 좋은 친구였으니까요.
Anders는 자신의 몸 상태가 좋지 않아서 농담으로 자신의 몸을 '월요일의 농산물'이라고 부르기도 했어요. 하지만 그는 불평하는 대신, 주어진 상황에서 최선을 다하려고 노력했죠. 몸이 아플 때에도 다른 사람들을 돕고, 생각을 나누고, 피드백과 아이디어를 제공하기 위해 대화를 나누는 것을 멈추지 않았어요.
Michaela는 가족 외에 누구보다 Anders를 많이 챙겼어요. 우리 회사의 진정한 심장인 Michaela는 거의 매일 집과 병원을 방문했죠. Anders의 마지막 시간을 더 좋게 만들어준 Mica에게 정말 감사해요.
Anders는 모든 사람이 지식을 공유하고 아이디어와 콘텐츠에 대해 협력하도록 장려했어요. 그는 GraphGists와 DocGists를 오픈 소스 커뮤니티에 기여함으로써 이를 가능하게 했죠.
우리가 Neo4j 문서를 보거나 GraphGist를 사용하거나 그의 음악을 들을 때마다, 그의 유산은 우리 일상 속에 살아 숨 쉬고 있을 거예요.
AsciiDoctor의 창시자인 Dan Allen은 이렇게 말했어요.
앤더스는 제 삶에 큰 영향을 미쳤고, 놀라운 유산을 남겼습니다. 그는 항상 AsciiDoc 및 Asciidoctor의 영웅으로 기억될 거예요. DocGist를 사용할 때마다, 또는 문장 끝에 줄 바꿈을 추가할 때마다 그를 생각할 겁니다.
어쩌면 그의 음악을 통해 그가 어떤 사람이었는지 보여주는 것이 가장 좋을 것 같아요.
사랑하는 친구 Anders, 당신을 우리의 마음과 생각 속에 영원히 간직할게요. 우리 모두에게 영감을 줘서 정말 고마워요.
Farewell.
P.S. 많은 기사를 썼지만, 이렇게 어렵고도 쉬운 기사는 처음이었어요. Anders에 대해 좋은 말을 너무 많이 할 수 있지만, 그가 영원히 우리 곁을 떠났다는 사실을 깨닫는 것은 정말 마음 아픈 일이에요.
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
Going Meta 라이브 스트리밍 시리즈의 27개 에피소드에서는헤수스 바라사님이 semantics, 온톨로지, Knowledge Graph의 다양한 측면을 탐구했어요.
자, 이제 Going Meta 시즌 1을 마무리할 시간이에요.
정말 엄청난 성공이었죠! 매달 함께 해주신 여러분께 진심으로 감사드려요! Going Meta의 27개 에피소드가 모두 담긴 YouTube 재생 목록은 여기에서 확인하실 수 있어요.
이 글을 쓰고 있는 지금, YouTube 총 조회수는 79,000회를 훌쩍 넘었고, GitHub 저장소도 인기가 많았는데요. 여기에는 각 에피소드와 관련된 모든 자료(코드, 쿼리, 데이터 세트, 온톨로지, 노트북 등)가 모여 있답니다.
이제 새로운 시즌을 시작할 때가 된 것 같아요. 이전 시즌의 핵심 주제에서 완전히 벗어나진 않겠지만, GraphRAG와 Knowledge Graph에 좀 더 집중해보려고 해요.
시즌 1에서는 Graph Database, semantics, 온톨로지의 몇 가지 기본 원칙을 다뤘어요. 특히 Knowledge Graph를 깊이 있게 조사하면서 그 안에 숨겨진 무한한 가능성을 발견했고, 인공지능부터 데이터 관리까지 다양한 분야에 적용할 수 있다는 것을 알게 되었죠.
에피소드 20은 이미 그동안 다뤘던 내용을 요약하는 역할을 했는데요. 첫 번째 에피소드에서는 데이터 엔지니어링, 지식 관리, 개발자/데이터 통합, 고급 semantics라는 몇 가지 주제를 다루기도 했어요.
저희 웹사이트에서 모든 내용을 읽고 시청하실 수 있어요. 도 준비되어 있답니다. 이 글에서는 Going Meta 첫 번째 시즌을 마무리하는 추가 7개의 에피소드를 다룰 거예요.
Going Meta 20개 에피소드 요약
에피소드 21-27: GenAI, RAG 및 Knowledge Graph
21화부터는 AI 트렌드를 따라갔어요. 에피소드 전반에 걸쳐 다양한 주제를 섞는 대신, Knowledge Graph를 사용해서 GenAI 및 (Graph)RAG에 집중했죠. 각 에피소드에서는 새로운 측면을 다루고, Knowledge Graph와 온톨로지가 데이터 작업의 새로운 방식에 특히 어떻게 유용한지 보여줄 거예요.
(Graph)RAG
Retrieval-Augmented Generation은 2023년 말에 떠오르는 주제였으니, 자세히 살펴보는 건 당연하겠죠? 특히 Large Language Model(LLM)과 결합해서 Knowledge Graph 및 온톨로지를 통해 GenAI 결과를 더 정확하고, 상황에 맞게, 이해하기 쉽게 만드는 방법을 탐구했어요.
RAG 패턴이 어떻게 LLM의 창의력/환각 문제를 해결하고, 데이터 세트에서 AI 에이전트가 지원하는 그래프 모델로 이동하는 반사 에이전트를 구축하는 데 도움이 되는지도 살펴봤답니다.
에피소드:
Ep 22 — Knowledge Graph가 포함된 RAG Ep 23 — Knowledge Graph를 사용한 고급 RAG 패턴 Ep 24 — KG+LLM: 온톨로지 기반 RAG 패턴 Ep 27 — LangGraph로 반사 에이전트 구축
도메인별 정보에 대해 벡터와 그래프를 사용하는 접근 방식, 또는 Knowledge Graph와 결합해서 사용하는 접근 방식을 비교해봤어요.
에피소드:
21 — 벡터 기반 Semantic Search 및 그래프 기반 Semantic Search 23 — Knowledge Graph를 사용한 고급 RAG 패턴
정확성과 특이성을 높이기 위해 Knowledge Graph와 LLM을 결합하는 경우가 많아서, 이 세그먼트의 모든 에피소드의 거의 일부가 됐죠. LLM을 사용해서 CSV 파일에서 Knowledge Graph를 만드는 방법도 살펴봤어요.
data.world 벤치마크를 자세히 살펴보면, 온톨로지가 포함된 Knowledge Graph가 LLM 결과를 크게 향상시키는 것으로 나타났어요.
에피소드:
Ep 25 — 자동화된 KG 구축을 위한 LLM Ep 25 — LLM QA에서 KG의 역할에 대한 data.world 벤치마크 추출
시즌 2
하지만 여기서 멈추지 않을 거예요! 시즌 2가 곧 시작될 예정이거든요. 새 시즌을 통해 에피소드 27에서 시작한 작업을 이어가면서, Knowledge Graph와 GraphRAG의 병치 및 다양한 개념을 보여줌으로써 GenAI 지원 애플리케이션을 구축하는 방법에 대해 더 깊이 알아보고 싶어요.
Going Meta – Ep 27: LangGraph를 사용하여 반사 에이전트 구축
이렇게 하면 여러분이 따라가면서 아이디어를 훨씬 더 빠르게 실제 생활로 전환할 수 있는 기회를 얻게 될 거예요.
물론, 의미론과 존재론을 완전히 배제하지는 않을 거고요. 언제나 그렇듯이 여러분의 제안도 기다리고 있어요. 에피소드에 좋을 것 같다고 생각되는 내용이 있으면 핑(YouTube 댓글, Discord 등)을 보내주세요!
Going Meta가 2024년 6월부터 시즌 2 ( 에피소드 1)으로 돌아올 예정이에요. 앞으로의 여정에 계속 함께 해주시면 좋겠어요!
자원
GraphRAG
Ontology
RAG
Semantic Search
Semantics
Vector
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
RAG 정확도 향상을 위해 텍스트 추출, 네트워크 분석, LLM 프롬프트 및 요약을 결합합니다.
저는 종종 GraphRAG라고 불리는 그래프를 통한 Retrieval-Augmented Generation(RAG) 구현에 대한 새로운 접근 방식에 항상 흥미를 느껴요. 하지만 GraphRAG라는 용어를 들으면 모든 사람이 서로 다른 구현을 염두에 두는 것 같아요. 이번 블로그 게시물에서는 '로컬에서 글로벌로 GraphRAG' Microsoft 연구원의 기사 및 구현을 살펴볼게요. Knowledge Graph 구성 및 요약 부분을 다루고 검색기는 다음 블로그 게시물에 남겨 두겠습니다. 연구원들이 코드 저장소를 제공해줘서 정말 고마워요. 프로젝트 페이지도 있답니다.
위에서 언급한 기사에서 취한 접근 방식은 정말 흥미로워요. 제가 알기로는, 여러 소스의 정보를 압축하고 결합하기 위한 파이프라인의 한 단계로 Knowledge Graph를 사용하는 것이 포함되는데요. 텍스트에서 entity와 relationship을 추출하는 것은 새로운 것은 아니죠. 하지만 저자들은 압축된 그래프 구조와 정보를 다시 자연어 텍스트로 요약하는 참신한(적어도 저에게는) 아이디어를 소개해요. 파이프라인은 그래프를 생성하기 위해 처리되는 문서의 입력 텍스트로 시작돼요. 그런 다음 그래프는 다시 자연어 텍스트로 변환되죠. 생성된 텍스트에는 이전에 여러 문서에 분산된 특정 entity 또는 그래프 커뮤니티에 대한 요약 정보가 포함되어 있어요.
Microsoft 의 GraphRAG 논문에 구현된 높은 수준의 인덱싱 파이프라인
정말 간단하게 말하면, GraphRAG 파이프라인에 대한 입력은 다양한 정보가 포함된 소스 문서예요. 문서는 LLM을 사용하여 처리되어 해당 relationship과 함께 문서에 나타나는 entity에 대한 구조화된 정보를 추출하죠. 이렇게 추출된 구조화된 정보는 Knowledge Graph를 구성하는 데 사용돼요.
Knowledge Graph 데이터 표현을 사용하면 특정 entity에 대한 여러 문서나 데이터 소스의 정보를 빠르고 직접적으로 결합할 수 있다는 장점이 있어요. 앞서 언급했듯이 Knowledge Graph가 유일한 데이터 표현은 아니에요. Knowledge Graph가 구성된 후 그래프 알고리즘과 LLM 프롬프트의 조합을 사용하여 Knowledge Graph에서 발견된 entity 커뮤니티의 자연어 요약을 생성해요.
이러한 요약에는 특정 entity 및 커뮤니티에 대한 여러 데이터 소스와 문서에 분산된 요약 정보가 포함되어 있답니다.
파이프라인을 더 자세히 이해하려면 원본 문서에 제공된 단계별 설명을 참조하세요.
파이프라인 단계 — 이미지 출처:GraphRAG 종이, CC BY 4.0에 따라 라이선스가 부여됨
Neo4j와 LangChain을 사용해서 이 접근 방식을 재현하는 데 사용할 파이프라인을 간단하게 요약해볼게요.
Indexing - 그래프 생성
소스 문서를 텍스트 덩어리로: 소스 문서를 처리하기 쉽도록 더 작은 텍스트 덩어리로 나눠요.
요소 인스턴스에 대한 텍스트 청크: 각 텍스트 청크를 분석해서 엔터티와 관계를 추출하고, 이 요소들을 나타내는 튜플 목록을 만들어요.
요소 인스턴스에서 요소 요약까지: 추출된 항목과 관계는 LLM을 사용해서 각 요소에 대한 설명 텍스트 블록으로 요약돼요.
그래프 커뮤니티에 대한 요소 요약: 이 엔터티 요약들은 그래프를 형성하고, Leiden 같은 알고리즘을 사용해서 커뮤니티로 분할되죠.
커뮤니티를 커뮤니티 요약으로 그래프 표시: 데이터 세트의 전체적인 주제 구조와 의미를 이해하기 위해 LLM을 통해 각 커뮤니티의 요약이 생성돼요.
Retrieval - 응답
글로벌 답변에 대한 커뮤니티 요약: 커뮤니티 요약은 중간 답변을 생성해서 사용자 쿼리에 응답하는 데 사용되고, 이 답변은 최종 글로벌 답변으로 합쳐져요.
코드를 바로 사용할 수는 없지만, 구현이 완료되었으니 사용되는 기본적인 접근 방식이나 LLM 프롬프트에 약간의 차이가 있을 수 있어요. 진행하면서 이런 차이점을 설명해 드릴게요.
코드는 에서 확인할 수 있어요.
Neo4j 환경 설정
Neo4j를 기본 그래프 저장소로 사용할 거예요. 시작하는 가장 쉬운 방법은 무료 인스턴스를 사용하는 건데요, Neo4j 샌드박스는 Graph Data Science 플러그인이 설치된 Neo4j 데이터베이스의 클라우드 인스턴스를 제공해줘요. 아니면 Neo4j 데스크탑 애플리케이션을 다운로드해서 Neo4j 데이터베이스의 로컬 인스턴스를 설정할 수도 있어요. 로컬 버전을 사용하는 경우에는 APOC 및 GDS 플러그인을 모두 설치해야 해요. 프로덕션 환경에서는 GDS 플러그인을 제공하는 유료 관리형 AuraDS(데이터 과학) 인스턴스를 사용할 수 있죠.
저희는 Neo4j그래프를 사용할 건데요, 이건 LangChain에 추가한 편리한 래퍼예요.
이번에는 제가 얼마 전에 만든 뉴스 기사 데이터 세트를 사용할 거예요. Diffbot의 API를 이용했죠. 재사용하기 편하도록 GitHub에 올려놨어요.
news = pd.read_csv(
"https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/news_articles.csv"
)
news["tokens"] = [
num_tokens_from_string(f"{row['title']} {row['text']}")
for i, row in news.iterrows()
]
news.head()
데이터세트의 처음 몇 줄을 한번 살펴볼까요?
데이터세트의 샘플 행
여기에는 tiktoken 라이브러리를 사용해서 계산한 토큰 수와 함께, 게시 날짜와 기사 제목, 텍스트가 들어있어요.
텍스트 청킹
텍스트 청킹 단계는 정말 중요하고, 다운스트림 결과에 큰 영향을 미친답니다. 논문 저자들은 텍스트 덩어리를 작게 만들수록 더 많은 항목을 추출할 수 있다는 걸 발견했어요.
텍스트 청크 크기에 따른 추출된 엔티티 수 — 이미지 출처: GraphRAG paper, CC BY 4.0에 따라 라이선스가 부여됨
보시다시피, 2,400개 토큰의 텍스트 청크를 사용하면 600개 토큰을 사용할 때보다 추출되는 엔티티 수가 줄어들어요. 또한 LLM이 첫 번째 실행에서 모든 엔티티를 추출하지 못할 수도 있다는 점도 확인했죠. 이 경우 추출을 여러 번 수행하는 휴리스틱을 도입할 거예요. 이에 대해서는 다음 섹션에서 자세히 알아볼게요.
하지만 항상 절충점이 있기 마련이죠. 더 작은 텍스트 청크를 사용하면 문서 전체에 분산된 특정 엔티티의 컨텍스트와 상호 참조가 손실될 수 있어요. 예를 들어 문서에서 "John"과 "he"가 별도의 문장으로 언급된 경우, 텍스트를 더 작은 덩어리로 나누면 "he"가 John을 가리키는지 명확하지 않을 수 있죠. 일부 상호 참조 문제는 중첩 텍스트 청킹 전략을 사용하여 해결할 수 있지만, 모든 문제가 해결되는 건 아니에요.
기사 텍스트의 크기를 한번 살펴볼까요?
sns.histplot(news["tokens"], kde=False)
plt.title('Distribution of chunk sizes')
plt.xlabel('Token count')
plt.ylabel('Frequency')
plt.show()
기사 토큰 수 분포를 보니 거의 정규 분포를 따르고 최댓값이 약 400개 토큰 정도 되네요. 청크 빈도는 이 최고점까지 점점 증가하다가 대칭적으로 감소하는 걸 확인할 수 있어요. 이는 대부분의 텍스트 청크가 400 토큰 근처에 있다는 걸 보여주죠.
이 분포 때문에 상호 참조 문제를 피하려고 여기서는 텍스트 청크를 따로 진행하지 않았어요. 기본적으로 GraphRAG 프로젝트는 청크 크기를 300개 토큰으로 설정하고 100개 토큰을 겹치게 설정해 뒀답니다.
Nodes 및 Relationships 추출
다음 단계는 텍스트 청크에서 지식을 구성하는 거예요. 이번 사용 사례에서는 LLM을 사용해서 텍스트에서 Nodes 및 Relationships 형태로 구조화된 정보를 추출할 건데요. 여러분은 LLM 프롬프트를 논문에 사용된 저자와 같이 사용할 수 있어요. 필요한 경우, Node 레이블을 미리 정의할 수 있는 LLM 프롬프트도 있지만 기본적으로는 선택 사항이에요. 또한 원본 문서에서 추출된 Relationships에는 유형이 없고 설명만 있더라고요. 제 생각에는 LLM이 Relationship으로서 더 풍부하고 미묘한 정보를 추출하고 유지할 수 있도록 하기 위한 선택인 것 같아요. 하지만 Relationship 유형 지정(설명은 속성에 넣을 수 있겠죠!) 없이 깔끔한 Knowledge Graph를 갖기는 어렵겠죠?
저희 구현에서는 LLMGraphTransformer를 사용했어요. LangChain 라이브러리에서 사용할 수 있는 기능이죠. 기사 문서 구현처럼 순수한 Prompt Engineering을 사용하는 대신, LLMGraphTransformer는 지원을 호출하는 내장 함수를 사용해서 구조화된 정보(LangChain의 구조화된 출력 LLM)를 추출해요. 시스템 프롬프트를 한번 살펴보세요:
이 예시에서는 그래프 추출에 GPT-4o를 사용하고 있어요. 작성자는 LLM에게 구체적으로 엔터티, 관계, 설명 추출을 지시하죠. LangChain 구현을 통해 node_properties와 relationship_properties를 사용해서 LLM이 추출할 node 또는 relationship 속성을 지정할 수 있어요.
LLMGraphTransformer 구현과의 차이점은 모든 node 또는 relationship 속성이 선택 사항이라는 점이에요. 그래서 모든 node가 description property를 가지는 건 아니죠. 원한다면 필수 추출을 포함하도록 사용자 정의 추출을 정의해서 description 속성을 필수로 만들 수도 있지만, 이 구현에서는 건너뛸게요.
그래프 추출 속도를 높이고 결과를 Neo4j에 저장하기 위해 요청을 병렬화하고 있어요.
MAX_WORKERS = 10
NUM_ARTICLES = 2000
graph_documents = []
with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor:
# Submitting all tasks and creating a list of future objects
futures = [
executor.submit(process_text, f"{row['title']} {row['text']}")
for i, row in news.head(NUM_ARTICLES).iterrows()
]
for future in tqdm(
as_completed(futures), total=len(futures), desc="Processing documents"
):
graph_document = future.result()
graph_documents.extend(graph_document)
graph.add_graph_documents(
graph_documents,
baseEntityLabel=True,
include_source=True
)
이 예시에서는 2,000개의 기사에서 그래프 정보를 추출하고 결과를 Neo4j에 저장하고 있어요. 약 13,000개의 엔터티와 16,000개의 관계를 추출했죠. 다음은 그래프에서 추출된 문서의 예시입니다.
문서(파란색)는 추출된 엔터티 및 관계를 가리킵니다.
추출을 완료하는 데 약 35(+/- 5)분이 걸리고, GPT-4o를 사용하는 경우 비용은 약 $30 정도 들어요.
이 단계에서 작성자는 두 번 이상의 패스에서 그래프 정보를 추출할지 여부를 결정하기 위해 휴리스틱을 도입하고 있어요. 단순화를 위해 한 번의 패스만 수행할게요. 하지만 여러 패스를 수행하려는 경우 첫 번째 추출 결과를 대화 기록으로 두고 간단히 많은 엔터티가 누락된 LLM에게 더 많은 것을 추출해야 한다고 지시할 수 있어요. GraphRAG 작성자처럼요.
이전에는 텍스트 청크 크기가 얼마나 중요한지, 그리고 이것이 추출된 엔터티 수에 어떤 영향을 미치는지 언급했었죠. 추가 텍스트 청크를 수행하지 않았으므로 텍스트 청크 크기를 기준으로 추출된 항목의 분포를 평가해 볼 수 있어요.
entity_dist = graph.query(
"""
MATCH (d:Document)
RETURN d.text AS text,
count {(d)-[:MENTIONS]->()} AS entity_count
"""
)
entity_dist_df = pd.DataFrame.from_records(entity_dist)
entity_dist_df["token_count"] = [
num_tokens_from_string(str(el)) for el in entity_dist_df["text"]
]
# Scatter plot with regression line
sns.lmplot(
x="token_count",
y="entity_count",
data=entity_dist_df,
line_kws={"color": "red"}
)
plt.title("Entity Count vs Token Count Distribution")
plt.xlabel("Token Count")
plt.ylabel("Entity Count")
plt.show()
산점도를 보면 빨간색 선으로 표시된 양의 추세가 보이긴 하지만, 관계가 하위 선형이라는 걸 알 수 있어요. 토큰 수가 증가해도 대부분의 데이터 포인트는 더 낮은 엔티티 수로 몰려있죠. 이는 추출된 엔티티 수가 텍스트 청크 크기에 비례해서 늘어나지 않는다는 걸 나타내요. 일부 이상값이 있긴 하지만, 일반적으로 토큰 수가 많다고 해서 엔티티 수가 계속 늘어나진 않아요. 텍스트 청크 크기가 작을수록 더 많은 정보를 추출한다는 저자의 발견을 뒷받침하는 내용이죠.
구성된 그래프의 `Node` 차수 분포를 살펴보는 것도 흥미로울 것 같아요. 다음 코드는 `Node` 차수 분포를 검색하고 시각화하는 코드예요.
degree_dist = graph.query(
"""
MATCH (e:__Entity__)
RETURN count {(e)-[:!MENTIONS]-()} AS node_degree
"""
)
degree_dist_df = pd.DataFrame.from_records(degree_dist)
# Calculate mean and median
mean_degree = np.mean(degree_dist_df['node_degree'])
percentiles = np.percentile(degree_dist_df['node_degree'], [25, 50, 75, 90])
# Create a histogram with a logarithmic scale
plt.figure(figsize=(12, 6))
sns.histplot(degree_dist_df['node_degree'], bins=50, kde=False, color='blue')
# Use a logarithmic scale for the x-axis
plt.yscale('log')
# Adding labels and title
plt.xlabel('Node Degree')
plt.ylabel('Count (log scale)')
plt.title('Node Degree Distribution')
# Add mean, median, and percentile lines
plt.axvline(mean_degree, color='red', linestyle='dashed', linewidth=1, label=f'Mean: {mean_degree:.2f}')
plt.axvline(percentiles[0], color='purple', linestyle='dashed', linewidth=1, label=f'25th Percentile: {percentiles[0]:.2f}')
plt.axvline(percentiles[1], color='orange', linestyle='dashed', linewidth=1, label=f'50th Percentile: {percentiles[1]:.2f}')
plt.axvline(percentiles[2], color='yellow', linestyle='dashed', linewidth=1, label=f'75th Percentile: {percentiles[2]:.2f}')
plt.axvline(percentiles[3], color='brown', linestyle='dashed', linewidth=1, label=f'90th Percentile: {percentiles[3]:.2f}')
# Add legend
plt.legend()
# Show the plot
plt.show()
Node 차수 분포는 멱함수 패턴을 따르는데, 이는 대부분의 Node가 연결 수가 매우 적은 반면 일부 Node는 연결 정도가 높다는 것을 나타내요. 평균 차수는 2.45, 중앙값은 1.00으로 절반 이상의 Node에 연결이 하나만 있다는 것을 나타내죠. 대부분의 Node(75%)에는 2개 이하의 연결이 있고 90%는 5개 이하의 연결이 있어요. 이러한 분포는 소수의 허브에 많은 연결이 있고 대부분의 Node에는 연결이 거의 없는 실제 네트워크의 일반적인 현상이에요.
Node와 Relationship 설명은 모두 필수 속성이 아니니까, 추출된 개수도 한번 살펴볼까요?
graph.query("""
MATCH (n:`__Entity__`)
RETURN "node" AS type,
count(*) AS total_count,
count(n.description) AS non_null_descriptions
UNION ALL
MATCH (n)-[r:!MENTIONS]->()
RETURN "relationship" AS type,
count(*) AS total_count,
count(r.description) AS non_null_descriptions
""")
결과는 12,994개 Node 중 5,926개(45.6%) Node에 description 속성이 있는 것으로 나타났어요. 반면에 15,921개 Relationship 중 5,569개(35%)만이 그러한 속성을 가지고 있네요.
LLM의 확률적 특성으로 인해 숫자는 실행 및 소스 데이터, LLM, 프롬프트에 따라 달라질 수 있다는 점 참고해주세요.
Entity Resolution
Entity Resolution(중복 제거)은 Knowledge Graph를 구성할 때 각 Entity가 고유하고 정확하게 표현되도록 보장하고 중복을 방지하고 동일한 실제 Entity를 참조하는 레코드를 병합하므로 중요해요. 이 프로세스는 그래프 내에서 데이터 무결성과 일관성을 유지하는 데 필수적이죠. Entity Resolution이 없으면 Knowledge Graph는 조각화되고 일관되지 않은 데이터로 인해 오류가 발생하고 신뢰할 수 없는 통찰력을 얻게 될 거예요.
잠재적인 엔티티 중복
이 이미지는 하나의 실제 엔티티가 여러 문서에서, 그리고 결과적으로 그래프에서 약간 다른 이름으로 표현될 수 있는 상황을 보여주고 있어요.
게다가 희소 데이터는 엔티티 해결 없이는 정말 큰 문제가 될 수 있어요. 다양한 소스의 불완전하거나 부분적인 데이터 때문에 정보가 여기저기 흩어지고 연결이 끊겨서, 각 엔티티에 대한 일관성 있고 포괄적인 이해를 하기가 어렵게 되죠. 정확한 엔티티 식별은 데이터를 통합하고, 빈 곳을 채우고, 각 엔티티에 대한 통합된 뷰를 생성해서 이 문제를 해결해 준답니다.
사용 전/후 연결을 위한 엔터티 해결 국제탐사보도언론인협회(ICIJ) 해외 유출 데이터 — 이미지 출처: 파코 네이선
시각화의 왼쪽 부분은 희박하고 연결되지 않은 그래프를 나타내요. 하지만 오른쪽에서 볼 수 있듯이, 이러한 그래프는 효율적인 엔터티 해결과 잘 연결될 수 있죠.
전반적으로 엔터티 확인은 데이터 검색 및 통합의 효율성을 향상시켜 다양한 소스에 걸쳐 정보에 대한 응집력 있는 보기를 제공해요. 궁극적으로 신뢰할 수 있고 완전한 Knowledge Graph를 기반으로 보다 효과적인 질의응답을 가능하게 합니다.
안타깝게도 GraphRAG 논문의 저자는 논문에서 언급은 했지만, 저장소에 엔터티 확인 코드를 포함하지 않았어요. 이 코드를 생략한 이유는 특정 도메인에 대해 강력하고 성능이 좋은 엔터티 확인을 구현하기가 어렵기 때문일 수 있어요. 사전 정의된 유형의 Node를 처리할 때 다양한 Node에 대한 사용자 정의 휴리스틱을 구현할 수 있죠 (사전 정의되지 않은 경우 회사, 조직, 비즈니스 등과 같이 일관성이 충분하지 않아요). 하지만 우리의 경우처럼 Node Label이나 유형을 미리 알 수 없다면 이는 더욱 어려운 문제가 돼요. 그럼에도 불구하고 우리는 텍스트 임베딩 및 그래프 알고리즘을 단어 거리 및 LLM과 결합하여 프로젝트에서 엔터티 해결 버전을 구현할 거예요.
엔터티 해결 흐름
법인 해결 프로세스에는 다음 단계가 포함돼요.
Graph의 항목 — Graph 내의 모든 항목부터 시작해요.
K-최근접 Graph — 텍스트 임베딩을 기반으로 유사한 엔터티를 연결하는 k-최근접 이웃 Graph를 구성합니다.
약하게 연결된 구성 요소 — k-가장 가까운 Graph에서 약하게 연결된 구성 요소를 식별하여 유사할 가능성이 있는 엔터티를 그룹화합니다. 이러한 구성 요소가 식별된 후 단어 거리 필터링 단계를 추가합니다.
LLM 평가 — LLM을 사용하여 이러한 구성 요소를 평가하고 각 구성 요소 내의 엔터티를 병합해야 하는지 여부를 결정하여 엔터티 해결에 대한 최종 결정을 내립니다(예: 'Silicon Valley Bank'와 'Silicon_Valley_Bank'를 병합하고 '2023년 9월 16일' 및 '2023년 9월 2일'과 같은 다른 날짜에 대한 병합을 거부).
먼저 엔터티의 이름 및 설명 속성에 대한 텍스트 임베딩을 계산합니다. 우리는 from_existing_graph의 방법Neo4jVector이를 달성하기 위해 LangChain에 통합합니다.
이러한 임베딩을 사용하여 이러한 임베딩의 코사인 거리를 기반으로 유사한 잠재적 후보를 찾을 수 있어요. 우리는 다음에서 사용 가능한 그래프 알고리즘을 사용할 거예요.Graph Data Science(GDS) 라이브러리; 그러므로 우리는GDS Python 클라이언트Python 방식으로 쉽게 사용할 수 있도록 다음을 수행합니다.
GDS 라이브러리에 익숙하지 않은 경우 Graph 알고리즘을 실행하기 전에 먼저 메모리 내 Graph를 투영해야 합니다.
Graph Data Science 알고리즘 실행 워크플로
첫째, Neo4j에 저장된 그래프는 더 빠른 처리 및 분석을 위해 인메모리 그래프에 투영됩니다. 다음으로, 메모리 내 그래프에 그래프 알고리즘이 실행되는 거죠. 선택적으로 알고리즘 결과를 Neo4j 데이터베이스에 다시 저장할 수도 있어요. 이에 대한 자세한 내용은 선적 서류 비치에서 확인해보세요.
k-최근접 이웃 그래프를 생성하기 위해 텍스트 Vector Embedding과 함께 모든 엔터티를 투영합니다.
이제 그래프가 아래에 투영되었으므로 entities 이름으로 그래프 알고리즘을 실행할 수 있어요. 우리는 k-Nearest Neighbor 그래프를 사용할 거예요. k-Nearest Neighbor 그래프의 희소성 또는 밀도에 영향을 미치는 가장 중요한 두 가지 매개변수는 similarityCutoff and topK입니다. topK는 각 Node에 대해 찾을 이웃의 수이며 최소값은 1이에요. similarityCutoff는 이 임계값 미만의 유사성을 갖는 Relationship을 필터링하죠. 여기서는 기본값을 사용해볼게요. topK는 10이고 similarity cutoff가 0.95로 상대적으로 높습니다. 0.95와 같은 높은 similarity cutoff를 사용하면 매우 유사한 쌍만 일치 항목으로 간주되어 거짓 긍정을 최소화하고 정확도를 향상시킵니다.
k-최근접 그래프 구성 및 프로젝트 그래프에 새 관계 저장
우리는 Knowledge Graph 대신에 투영된 인 메모리 그래프에 결과를 다시 저장하고 싶기 때문에 mutate 알고리즘 모드를 사용할 거예요:
다음 단계는 새로 추론된 유사성 관계와 연결된 엔터티 그룹을 식별하는 것이에요. 연결된 Node 그룹을 식별하는 것은 네트워크 분석에서 흔히 수행되는 프로세스인데, 이걸 또는 클러스터링이라고 부르죠. 조밀하게 연결된 Node의 하위 그룹을 찾는 것과 관련이 있어요. 이 예에서는 약하게 연결된 구성요소 알고리즘을 사용하는데, 연결 방향을 무시하더라도 그래프에서 모든 Node가 연결된 부분을 찾는 데 도움이 된답니다.
WCC 결과를 데이터베이스에 다시 쓰기
결과를 다시 데이터베이스에 저장하기 위해 write 모드의 알고리즘을 사용할 거예요 (저장된 그래프):
텍스트 포함 비교는 잠재적인 중복 항목을 찾는 데 도움이 되지만, 엔터티 해결 프로세스의 일부일 뿐이에요. 예를 들어 Google과 Apple은 임베딩 공간에서 매우 가깝죠 (0.96 코사인 유사도 사용, ada-002 임베딩 모델). BMW와 Mercedes Benz도 마찬가지고요 (코사인 유사도 0.97). 높은 텍스트 임베딩 유사성은 좋은 시작이지만, 이를 개선할 수 있어요. 따라서 텍스트 거리가 3 이하인 단어 쌍만 허용하는 추가 필터를 추가할 거예요 (문자만 변경할 수 있다는 의미).
word_edit_distance = 3
potential_duplicate_candidates = graph.query(
"""MATCH (e:`__Entity__`)
WHERE size(e.id) > 3 // longer than 3 characters
WITH e.wcc AS community, collect(e) AS nodes, count(*) AS count
WHERE count > 1
UNWIND nodes AS node
// Add text distance
WITH distinct
[n IN nodes WHERE apoc.text.distance(toLower(node.id), toLower(n.id)) < $distance
OR node.id CONTAINS n.id | n.id] AS intermediate_results
WHERE size(intermediate_results) > 1
WITH collect(intermediate_results) AS results
// combine groups together if they share elements
UNWIND range(0, size(results)-1, 1) as index
WITH results, index, results[index] as result
WITH apoc.coll.sort(reduce(acc = result, index2 IN range(0, size(results)-1, 1) |
CASE WHEN index <> index2 AND
size(apoc.coll.intersection(acc, results[index2])) > 0
THEN apoc.coll.union(acc, results[index2])
ELSE acc
END
)) as combinedResult
WITH distinct(combinedResult) as combinedResult
// extra filtering
WITH collect(combinedResult) as allCombinedResults
UNWIND range(0, size(allCombinedResults)-1, 1) as combinedResultIndex
WITH allCombinedResults[combinedResultIndex] as combinedResult, combinedResultIndex, allCombinedResults
WHERE NOT any(x IN range(0,size(allCombinedResults)-1,1)
WHERE x <> combinedResultIndex
AND apoc.coll.containsAll(allCombinedResults[x], combinedResult)
)
RETURN combinedResult
""", params={'distance': word_edit_distance})
이 Cypher 설명은 조금 복잡해서 이 블로그 게시물에서 자세히 다루기는 어려울 것 같아요. 언제든지 LLM에게 설명을 요청할 수 있다는 점 참고해주세요.
Anthropic Claude Sonnet 3.5 — 중복 개체 판정 설명
단어 거리 컷오프는 단순한 숫자가 아니라 단어 길이의 함수로 설정하면 구현이 더 확장 가능해질 수 있어요.
중요한 점은, 이제 병합하려는 잠재적인 엔터티 그룹이 출력된다는 거예요. 다음은 병합할 수 있는 `node` 목록입니다.
보시다시피, 우리의 접근 방식이 모든 종류의 `Node`에 다 잘 작동하는 건 아니에요. 잠깐 살펴보면 사람이나 조직에는 더 잘 맞는 것 같고, 날짜에는 꽤 안 좋은 것 같죠? 미리 정의된 `Node` 유형을 사용하면 다양한 `Node` 유형에 대해 서로 다른 경험적 방법을 준비할 수 있어요. 이 예에서는 미리 정의된 `Node` 라벨이 없으므로 `Large Language Model`을 통해 항목 병합 여부에 대한 최종 결정을 내릴 거예요.
자, 그럼 `Node` 병합에 관한 최종 결정을 효과적으로 안내하고 알리기 위해 `Large Language Model` `Prompt`를 만들어봐야겠죠?
system_prompt = """You are a data processing assistant. Your task is to identify duplicate entities in a list and decide which of them should be merged.
The entities might be slightly different in format or content, but essentially refer to the same thing. Use your analytical skills to determine duplicates.
Here are the rules for identifying duplicates:
1. Entities with minor typographical differences should be considered duplicates.
2. Entities with different formats but the same content should be considered duplicates.
3. Entities that refer to the same real-world object or concept, even if described differently, should be considered duplicates.
4. If it refers to different numbers, dates, or products, do not merge results
"""
user_template = """
Here is the list of entities to process:
{entities}
Please identify duplicates, merge them, and provide the merged list.
"""
저는 항상 with_structured_output을 사용하는 걸 좋아해요. 출력을 수동으로 파싱할 필요가 없도록 구조화된 데이터 출력을 기대할 때 LangChain의 메서드죠.
여기서는 출력을 다음과 같은 list of lists로 정의할게요. 여기서 각 내부 목록에는 병합해야 하는 엔터티가 포함되어 있어요. 이 구조는 예를 들어 입력이 다음과 같은 시나리오를 처리하는 데 사용돼요. [Sony, Sony Inc, Google, Google Inc]. 이러한 경우 'Google' 및 'Google Inc'와 별도로 'Sony'와 'Sony Inc'를 병합하는 게 좋겠죠.
class DuplicateEntities(BaseModel):
entities: List[str] = Field(
description="Entities that represent the same object or real-world entity and should be merged"
)
class Disambiguate(BaseModel):
merge_entities: Optional[List[DuplicateEntities]] = Field(
description="Lists of entities that represent the same object or real-world entity and should be merged"
)
extraction_llm = ChatOpenAI(model_name="gpt-4o").with_structured_output(
Disambiguate
)
다음으로 `Large Language Model` `Prompt`를 구조화된 출력과 통합해서 LCEL(LangChain Expression Language) 구문을 사용해서 체인을 생성하고, 이를 disambiguate 기능으로 캡슐화할 거예요.
extraction_chain = extraction_prompt | extraction_llm
def entity_resolution(entities: List[str]) -> Optional[List[List[str]]]:
return [
el.entities
for el in extraction_chain.invoke({"entities": entities}).merge_entities
]
우리는 모든 잠재적 후보 `Node`를 entity_resolution 기능을 통해 실행해서 병합할지 여부를 결정해야 해요. 프로세스 속도를 높이기 위해 `Large Language Model` 호출을 다시 병렬화할게요.
merged_entities = []
with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor:
# Submitting all tasks and creating a list of future objects
futures = [
executor.submit(entity_resolution, el['combinedResult'])
for el in potential_duplicate_candidates
]
for future in tqdm(
as_completed(futures), total=len(futures), desc="Processing documents"
):
to_merge = future.result()
if to_merge:
merged_entities.extend(to_merge)
엔터티 해결의 마지막 단계는 entity_resolution LLM의 결과를 가져와서, 지정된 nodes를 병합해서 Graph Database에 다시 쓰는 거예요.
graph.query("""
UNWIND $data AS candidates
CALL {
WITH candidates
MATCH (e:__Entity__) WHERE e.id IN candidates
RETURN collect(e) AS nodes
}
CALL apoc.refactor.mergeNodes(nodes, {properties: {
description:'combine',
`.*`: 'discard'
}})
YIELD node
RETURN count(*)
""", params={"data": merged_entities})
이 엔터티 해결 방법이 완벽하진 않지만, 개선할 수 있는 출발점을 제공한다는 점이 중요해요. 어떤 엔터티를 유지해야 할지 결정하는 로직을 개선하는 것도 좋겠죠?
요소 요약
다음 단계에서 작성자는 요소 요약 단계를 수행하는데요. 기본적으로 모든 node와 relationship은 엔터티 요약 프롬프트를 사용해요. 저자는 이 접근 방식이 참신하고 흥미롭다고 언급하고 있어요.
"전반적으로, 잠재적으로 잡음이 많은 그래프 구조에서 동질적인 nodes에 대한 풍부한 설명 텍스트를 사용하는 것은 LLM의 기능과 전역 쿼리 중심 요약의 요구 사항 모두에 부합합니다. 이러한 특성은 또한 다운스트림 추론 작업을 위해 간결하고 일관된 지식 트리플(주제, 술어, 객체)에 의존하는 일반적인 Knowledge Graph와 그래프 인덱스를 차별화합니다."
아이디어가 정말 흥미롭죠? 우리는 여전히 텍스트에서 주체 및 개체 ID 또는 이름을 추출하기 때문에, 엔터티가 여러 텍스트 덩어리에 걸쳐 나타나는 경우에도 올바른 엔터티에 relationship을 연결할 수 있어요. 하지만 relationship은 단일 유형으로 축소되지 않아요. 대신 relationship 유형은 실제로 더 풍부하고 미묘한 정보를 유지할 수 있는 자유 형식 텍스트가 될 수 있다는 점!
게다가 엔터티 정보는 LLM을 사용해서 요약되기 때문에, 더 정확한 검색을 위해 이 정보와 엔터티를 보다 효율적으로 포함하고 인덱싱할 수 있어요.
임의의 node 및 relationship 속성을 추가해서 이러한 더 풍부하고 미묘한 정보를 유지할 수도 있다고 주장할 수도 있겠죠. 하지만 임의 node 및 relationship 속성의 한 가지 문제는 LLM이 다른 속성 이름을 사용하거나 모든 실행에서 다양한 세부 정보에 집중할 수 있기 때문에 정보를 일관되게 추출하기 어려울 수 있다는 점이에요.
이러한 문제 중 일부는 추가 유형 및 설명 정보와 함께 미리 정의된 속성 이름을 사용해서 해결될 수 있어요. 이 경우 해당 속성을 정의하는 데 도움을 줄 해당 분야 전문가가 필요하므로 LLM이 사전 정의된 설명 이외의 중요한 정보를 추출할 여지가 거의 없어요.
Knowledge Graph에 더욱 풍부한 정보를 표시하는 것은 정말 흥미로운 접근 방식인 것 같아요.
요소 요약 단계의 한 가지 잠재적인 문제는 그래프의 모든 엔터티와 relationship에 대해 LLM 호출이 필요하기 때문에 확장이 잘 되지 않는다는 거예요. 우리의 그래프는 13,000개의 nodes와 16,000개의 relationships로 비교적 작은 편인데요. 이런 작은 그래프의 경우에도 29,000개의 LLM 호출이 필요하고, 각 호출에는 몇 백 개의 토큰이 사용되므로 상당히 비용이 많이 들고 시간이 오래 걸려요. 따라서 여기서는 이 단계를 생략하고, 초기 텍스트 처리 중에 추출된 설명 속성을 계속 사용할 수 있어요.
커뮤니티 구성 및 요약
그래프 구성 및 인덱스 프로세스의 마지막 단계에는 그래프 내에서 커뮤니티를 식별하는 작업이 포함돼요. 여기서 커뮤니티는 그래프의 나머지 부분보다 서로 더 촘촘하게 연결된 nodes 그룹으로, 더 높은 수준의 상호 작용 또는 유사성을 나타내죠. 다음 시각화는 커뮤니티 감지 결과의 예를 보여줍니다.
국가는 해당 국가가 속한 커뮤니티에 따라 색상이 지정됩니다.
이러한 엔터티 커뮤니티가 클러스터링 알고리즘으로 식별되면 LLM은 각 커뮤니티에 대한 요약을 생성해서 개별 특성과 관계에 대한 통찰력을 제공해요.
이번에도 Graph Data Science 라이브러리를 사용하는데요. 먼저 인메모리 그래프를 투영하는 것부터 시작해볼게요. 원본 기사를 정확하게 따르기 위해 엔터티 그래프를 무방향 가중치 네트워크로 투영할 거예요. 여기서 네트워크는 두 엔터티 간의 연결 수를 나타내죠.
저자들은 Leiden algorithm, 즉 그래프 내에서 커뮤니티를 식별하기 위한 계층적 클러스터링 방법을 사용했어요. 계층적 커뮤니티 검색 알고리즘을 사용하면 여러 수준의 세분성에서 커뮤니티를 검사할 수 있다는 장점이 있죠. 저자는 각 수준의 모든 커뮤니티를 요약해서 그래프 구조에 대한 포괄적인 이해를 제공할 것을 제안하고 있어요.
먼저 WCC(Weakly Connected Components) 알고리즘을 사용해서 그래프의 연결성을 평가해볼게요. 이 알고리즘은 그래프 내에서 격리된 섹션을 식별하는데요. 즉, 그래프의 나머지 부분에는 연결되어 있지 않지만 서로 연결되어 있는 Node 또는 구성 요소의 하위 집합을 감지하는 거죠. 이러한 구성 요소는 네트워크 내의 단편화를 이해하고 다른 Node와 독립적인 Node 그룹을 식별하는 데 도움이 돼요. WCC는 그래프의 전체 구조와 연결성을 분석하는 데 필수적이에요.
WCC 알고리즘 결과는 1,119개의 개별 구성 요소를 식별했어요. 특히 가장 큰 구성 요소는 9,109개의 Node로 구성되는데, 이는 단일 슈퍼 구성 요소가 수많은 작은 격리 구성 요소와 공존하는 실제 네트워크에서 흔히 볼 수 있는 모습이에요. 가장 작은 구성 요소에는 Node가 1개 있으며 평균 구성 요소 크기는 약 11.3 Node입니다.
다음으로 GDS 라이브러리에서도 사용할 수 있는 Leiden 알고리즘을 실행하고 includeIntermediateCommunities 파라미터로 모든 레벨의 커뮤니티를 반환하고 저장할 거예요. 또한 relationshipWeightProperty 파라미터로 Leiden 알고리즘의 가중치 변형을 실행할 거고요. write 알고리즘 모드를 사용해서 결과를 node property로 저장할게요.
알고리즘은 5가지 레벨의 커뮤니티를 식별했는데, 가장 높은 레벨(커뮤니티가 가장 큰 최소 세부 레벨)에는 1,188개의 커뮤니티(1,119개 컴포넌트와 반대)가 있어요. 다음은 Gephi를 사용해서 마지막 레벨의 커뮤니티를 시각화한 결과예요.
Gephi의 커뮤니티 구조 시각화
1,000개가 넘는 커뮤니티를 시각화하는 건 쉽지 않죠. 각각의 색상을 고르는 것조차 사실상 불가능해요. 하지만 멋진 예술 작품처럼 보이긴 하네요!
이제 각 커뮤니티에 대해 고유한 node를 만들고, 계층 구조를 상호 연결된 그래프로 표현해볼게요. 나중에 커뮤니티 요약 및 기타 속성도 node property로 저장할 거예요.
graph.query("""
MATCH (e:`__Entity__`)
UNWIND range(0, size(e.communities) - 1 , 1) AS index
CALL {
WITH e, index
WITH e, index
WHERE index = 0
MERGE (c:`__Community__` {id: toString(index) + '-' + toString(e.communities[index])})
ON CREATE SET c.level = index
MERGE (e)-[:IN_COMMUNITY]->(c)
RETURN count(*) AS count_0
}
CALL {
WITH e, index
WITH e, index
WHERE index > 0
MERGE (current:`__Community__` {id: toString(index) + '-' + toString(e.communities[index])})
ON CREATE SET current.level = index
MERGE (previous:`__Community__` {id: toString(index - 1) + '-' + toString(e.communities[index - 1])})
ON CREATE SET previous.level = index - 1
MERGE (previous)-[:IN_COMMUNITY]->(current)
RETURN count(*) AS count_1
}
RETURN count(*)
""")
저자는 또한 community rank라는 개념을 소개하는데요, 이는 커뮤니티 내의 엔터티가 나타나는 고유한 텍스트 청크 수를 나타낸다고 해요.
graph.query("""
MATCH (c:__Community__)<-[:IN_COMMUNITY*]-(:__Entity__)<-[:MENTIONS]-(d:Document)
WITH c, count(distinct d) AS rank
SET c.community_rank = rank;
""")
이제 더 높은 수준에서 병합되는 많은 중간 커뮤니티가 있는 샘플 계층 구조를 살펴볼게요. 커뮤니티는 서로 겹치지 않아요. 즉, 각 항목은 각 수준에서 정확히 단일 커뮤니티에 속하죠.
계층적 커뮤니티 구조. 커뮤니티는 주황색이고 법인은 보라색입니다.
이미지는 Leiden 커뮤니티 감지 알고리즘으로 인한 계층 구조를 나타내요. 보라색 노드는 개별 엔터티를 나타내고 주황색 노드는 계층적 커뮤니티를 나타내죠.
계층 구조는 이러한 개체의 조직을 다양한 커뮤니티로 보여주며, 더 작은 커뮤니티는 더 높은 수준에서 더 큰 커뮤니티로 병합돼요.
이제 소규모 커뮤니티가 더 높은 수준에서 어떻게 병합되는지 살펴볼까요?
계층적 커뮤니티 구조
이 이미지는 연결성이 낮은 엔터티와 결과적으로 소규모 커뮤니티가 수준 전반에 걸쳐 최소한의 변화를 경험한다는 것을 보여주고 있어요. 예를 들어 여기의 커뮤니티 구조는 처음 두 수준에서만 변경되지만 마지막 세 수준에서는 동일하게 유지되죠. 결과적으로 전체 조직이 서로 다른 계층에서 크게 변경되지 않기 때문에 이러한 엔터티에 대해 계층적 수준이 중복되는 경우가 많아요.
커뮤니티 수와 규모, 다양한 수준을 더 자세히 살펴볼까요?
community_size = graph.query(
"""
MATCH (c:__Community__)<-[:IN_COMMUNITY*]-(e:__Entity__)
WITH c, count(distinct e) AS entities
RETURN split(c.id, '-')[0] AS level, entities
"""
)
community_size_df = pd.DataFrame.from_records(community_size)
percentiles_data = []
for level in community_size_df["level"].unique():
subset = community_size_df[community_size_df["level"] == level]["entities"]
num_communities = len(subset)
percentiles = np.percentile(subset, [25, 50, 75, 90, 99])
percentiles_data.append(
[
level,
num_communities,
percentiles[0],
percentiles[1],
percentiles[2],
percentiles[3],
percentiles[4],
max(subset)
]
)
# Create a DataFrame with the percentiles
percentiles_df = pd.DataFrame(
percentiles_data,
columns=[
"Level",
"Number of communities",
"25th Percentile",
"50th Percentile",
"75th Percentile",
"90th Percentile",
"99th Percentile",
"Max"
],
)
percentiles_df
수준별 커뮤니티 규모 분포
원래 구현에서는 모든 수준의 커뮤니티를 요약했어요. 우리 경우에는 8,590개의 커뮤니티가 있고, 결과적으로 8,590개의 LLM 호출이 발생하죠. 저는 계층적 커뮤니티 구조에 따라 모든 수준을 요약할 필요는 없다고 생각해요. 예를 들어, 마지막 수준과 마지막에서 다음 수준의 차이는 커뮤니티가 4개뿐이에요 (1,192 대 1,188). 따라서 우리는 중복된 요약을 많이 만들게 되는 거죠. 한 가지 해결책은 변경되지 않는 다양한 수준의 커뮤니티에 대한 단일 요약을 만들 수 있는 구현을 만드는 거예요. 또 다른 방법은 변경되지 않는 커뮤니티 계층을 축소하는 거고요.
또한 많은 가치나 정보를 제공하지 않을 수 있으므로 구성원이 한 명으로 구성된 커뮤니티를 요약하고 싶은지 잘 모르겠어요. 여기서는 레벨 0, 1, 4의 커뮤니티를 요약하는데, 먼저 데이터베이스에서 해당 정보를 검색해야 해요.
community_info = graph.query("""
MATCH (c:`__Community__`)<-[:IN_COMMUNITY*]-(e:__Entity__)
WHERE c.level IN [0,1,4]
WITH c, collect(e ) AS nodes
WHERE size(nodes) > 1
CALL apoc.path.subgraphAll(nodes[0], {
whitelistNodes:nodes
})
YIELD relationships
RETURN c.id AS communityId,
[n in nodes | {id: n.id, description: n.description, type: [el in labels(n) WHERE el <> '__Entity__'][0]}] AS nodes,
[r in relationships | {start: startNode(r).id, type: type(r), end: endNode(r).id, description: r.description}] AS rels
""")
이제 커뮤니티 요소에서 제공하는 정보를 기반으로 Natural Language 요약을 생성하는 LLM 프롬프트를 준비해야 해요. 다음에서 영감을 얻을 수 있어요. 연구자들이 사용한 프롬프트.
저자는 커뮤니티를 요약했을 뿐만 아니라 각 커뮤니티에 대한 결과도 생성했어요. 결과는 특정 이벤트 또는 정보에 관한 간결한 정보로 정의할 수 있는데, 예를 들면 이런 거죠.
"summary": "Abila City Park as the central location",
"explanation": "Abila City Park is the central entity in this community, serving as the location for the POK rally. This park is the common link between all other
entities, suggesting its significance in the community. The park's association with the rally could potentially lead to issues such as public disorder or conflict, depending on the
nature of the rally and the reactions it provokes. [records: Entities (5), Relationships (37, 38, 39, 40)]"
제 생각에는 단 한 번의 패스로 결과를 추출하는 것은 엔터티 및 관계를 추출하는 것만큼 포괄적이지 않을 수 있어요.
또한 로컬 또는 전역 검색 검색기의 코드에서 해당 사용에 대한 참조나 예를 찾지 못했어요. 따라서 이 경우에는 결과 추출을 하지 않으려고 해요. 아니면, 학자들이 자주 말하듯이 이 연습은 독자 여러분의 몫으로 남겨두겠습니다. 게다가, 다음 단계도 건너뛰었어요. 주장 또는 공변량 정보 추출인데, 얼핏 보면 결과와 비슷해 보이죠.
커뮤니티 요약을 생성하는 데 사용할 프롬프트는 매우 간단해요.
community_template = """Based on the provided nodes and relationships that belong to the same graph community,
generate a natural language summary of the provided information:
{community_info}
Summary:""" # noqa: E501
community_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Given an input triples, generate the information summary. No pre-amble.",
),
("human", community_template),
]
)
community_chain = community_prompt | llm | StrOutputParser()
이제 남은 일은 커뮤니티 표현을 문자열로 변환해서 JSON 토큰 오버헤드를 피하고, 체인을 함수로 래핑해서 토큰 수를 줄이는 거예요.
def prepare_string(data):
nodes_str = "Nodes are:n"
for node in data['nodes']:
node_id = node['id']
node_type = node['type']
if 'description' in node and node['description']:
node_description = f", description: {node['description']}"
else:
node_description = ""
nodes_str += f"id: {node_id}, type: {node_type}{node_description}n"
rels_str = "Relationships are:n"
for rel in data['rels']:
start = rel['start']
end = rel['end']
rel_type = rel['type']
if 'description' in rel and rel['description']:
description = f", description: {rel['description']}"
else:
description = ""
rels_str += f"({start})-[:{rel_type}]->({end}){description}n"
return nodes_str + "n" + rels_str
def process_community(community):
stringify_info = prepare_string(community)
summary = community_chain.invoke({'community_info': stringify_info})
return {"community": community['communityId'], "summary": summary}
이제 선택한 레벨에 대한 커뮤니티 요약을 생성할 수 있어요. 다시 한 번 더 빠른 실행을 위해 호출을 병렬화할게요.
summaries = []
with ThreadPoolExecutor() as executor:
futures = {executor.submit(process_community, community): community for community in community_info}
for future in tqdm(as_completed(futures), total=len(futures), desc="Processing communities"):
summaries.append(future.result())
제가 언급하지 않은 한 가지 측면은 저자가 커뮤니티 정보를 입력할 때 컨텍스트 크기를 초과하는 잠재적인 문제도 다루고 있다는 점이에요. 그래프가 확장됨에 따라 커뮤니티도 크게 성장할 수 있죠. 우리의 경우 가장 큰 커뮤니티는 545명의 회원으로 구성되었어요. GPT-4o의 컨텍스트 크기가 토큰 100,000개를 초과한다는 점을 고려해서 이 단계를 건너뛰기로 결정했어요.
마지막 단계로 커뮤니티 요약을 데이터베이스에 다시 저장할 거예요.
graph.query("""
UNWIND $data AS row
MERGE (c:__Community__ {id:row.community})
SET c.summary = row.summary
""", params={"data": summaries})
최종 그래프 구조는 이렇게 생겼어요:
이제 그래프에는 원본 문서, 추출된 엔터티 및 관계는 물론 계층적 커뮤니티 구조와 요약까지 모두 포함되어 있어요.
요약
The 의 "From Local to Global" 논문은 GraphRAG에 대한 새로운 접근 방식을 보여주는 데 정말 큰 도움이 되었어요. 다양한 문서의 정보를 계층적인 Knowledge Graph 구조로 결합하고 요약하는 방법을 보여주죠.
한 가지 명시적으로 언급되지 않은 점은 구조화된 데이터 소스를 그래프에 통합할 수도 있다는 거예요. 입력이 구조화되지 않은 텍스트로만 제한될 필요는 없다는 거죠.
추출 방식에서 특히 좋았던 점은 `노드`와 `관계` 모두에 대한 설명을 캡처한다는 점이에요. 설명을 통해 LLM은 모든 것을 `노드` ID 및 `관계` 유형으로 축소하는 것보다 훨씬 더 많은 정보를 유지할 수 있거든요.
또한 텍스트에 대한 단일 추출 패스로는 모든 관련 정보를 캡처하지 못할 수도 있고, 필요한 경우 여러 패스를 수행하는 로직을 도입할 수 있다는 점을 보여줘요. 게다가 저자는 그래프 커뮤니티에 대한 요약을 수행하여 여러 데이터 소스에 압축된 주제 정보를 삽입하고 인덱싱할 수 있다는 흥미로운 아이디어를 제시하기도 했어요.
다음 블로그 게시물에서는 로컬 및 글로벌 검색 검색기 구현을 살펴보고, 주어진 그래프 구조를 기반으로 구현할 수 있는 다른 접근 방식에 대해 이야기해볼게요.
언제나 그렇듯이 코드는 에서 확인할 수 있어요.
이번에도 데이터베이스 덤프를 올려놨으니, 결과를 탐색하고 다양한 검색기 옵션을 실험해 볼 수 있을 거예요.
이 덤프를 영원히 무료인 Neo4j AuraDB 인스턴스로 가져올 수도 있어요. 검색 탐색에는 그래프 데이터 과학 알고리즘이 필요하지 않으니까, 그래프 패턴 일치, `벡터` 및 전체 텍스트 `인덱스`만 있으면 검색을 탐색할 수 있답니다.
자세한 내용은 모든 GenAI 프레임워크와 Neo4j 통합에서 확인해보세요. 제 책 "데이터 과학을 위한 그래프 알고리즘"“Graph Algorithms for Data Science”도 참고해주세요.
필수 GraphRAG
Knowledge Graph를 활용해서 Retrieval-Augmented Generation의 잠재력을 최대로 끌어올려 보세요! 지금 바로 Manning에서 제공하는 가이드를 무료로 받아보실 수 있어요.
ChatGPT
GraphRAG
Langchain
RAG
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
GraphRAG용 Neo4j를 사용해 본 적이 있다면 이미 생성 모델의 출력 품질을 향상시킬 수 있는 잠재력을 알고 계실 거예요. 전통적으로 이를 위해서는 Neo4j와 Cypher에 대한 깊은 지식이 필요했죠. 이번 포스팅에서는 공식적으로 Neo4j GraphRAG Python 패키지(neo4j-graphrag)를 소개할게요. 이 패키지는 개발자를 위한 RAG(Retrieval-Augmented Generation) 애플리케이션에 Neo4j의 통합을 단순화하도록 설계되었답니다.
GraphRAG Python 패키지는 RAG 설정에서 검색 및 생성 프로세스를 효율적으로 관리할 수 있는 도구를 제공해요. 이 게시물이 끝나면 패키지를 사용하여 검색 작업을 실행하는 데 능숙해질 거예요. 다음 게시물에서는 전체 엔드투엔드 RAG 파이프라인을 구축할 수 있는 패키지 생성 기능에 대해 자세히 알아볼 거예요.
GraphRAG란 무엇입니까?
neo4j-graphrag 패키지는 GraphRAG(그래프 검색 증강 생성)를 용이하게 해줘요. Neo4j에서는 그래프 데이터베이스를 벡터 검색과 통합하는 것이 RAG의 다음 개척지를 대표한다고 믿고 있어요.
설정
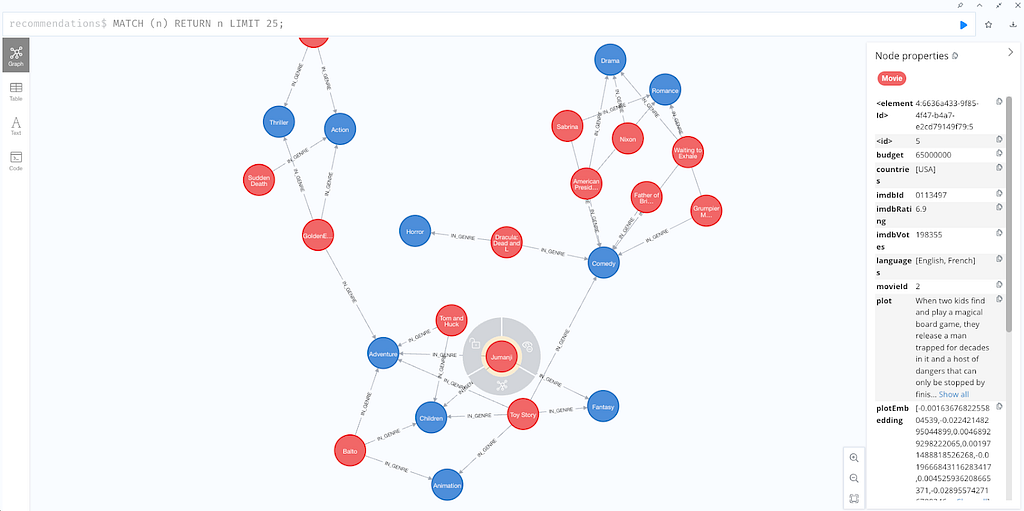
영화 추천 Knowledge Graph를 시뮬레이션하는 사전 구성된 Neo4j 데모 데이터베이스에 연결하여 시작해 봐요. 다음에서 액세스하세요: 사용자 이름과 비밀번호로 "recommendations"를 사용하면 돼요. 이 설정은 Vector Embedding 데이터가 이미 사용할 준비가 된 Neo4j 데이터베이스의 일부인 현실적인 시나리오를 제공해 준답니다.
Cypher 명령어를 입력해서 데이터를 시각화해 보세요.
MATCH (n) RETURN n LIMIT 25;
오른쪽의 각 Node 세부 정보에서 plotEmbedding 속성을 확인해 보세요. 데모 전반에 걸쳐 Vector Search를 수행하기 위해 이러한 임베딩을 사용할 거예요. moviePlotsEmbedding이 존재하는지 확인하기 위해 Cypher 명령을 입력해서 Vector Index를 생성해 봅시다.
SHOW INDEXES YIELD * WHERE type='VECTOR';
Python 환경에서 다음 다른 패키지와 함께 neo4j-graphrag 패키지를 설치하세요.
pip install neo4j-graphrag neo4j openai
계속해서 Neo4j Python 드라이버를 사용하여 Neo4j 데이터베이스에 대한 연결을 설정해 봐요.
from neo4j import GraphDatabase
# Demo database credentials
URI = "neo4j+s://demo.neo4jlabs.com"
AUTH = ("recommendations", "recommendations")
# Connect to Neo4j database
driver = GraphDatabase.driver(URI, auth=AUTH)
이 데모를 위해서는 OpenAI API 키 세트가 있는지 확인해야 해요.
import os
os.environ["OPENAI_API_KEY"] = "sk-…"
검색
우리 패키지는 다양한 검색 전략에 맞춰진 다양한 검색기를 제공해요 (전체 목록에 대한 문서). 적절한 것을 선택하는 것은 특정 요구 사항에 따라 달라지죠. 여기서는 VectorRetriever 클래스를 사용할게요.
from neo4j-graphrag.retrievers import VectorRetriever
from neo4j-graphrag.embeddings.openai import OpenAIEmbeddings
embedder = OpenAIEmbeddings(model="text-embedding-ada-002")
retriever = VectorRetriever(
driver,
index_name="moviePlotsEmbedding",
embedder=embedder,
return_properties=["title", "plot"],
)
우리는 text-embedding-ada-002를 사용하는데, 데모 데이터베이스의 영화 플롯 임베딩이 이 모델을 사용하여 생성되어 보다 관련성 높은 검색 검색이 가능해졌기 때문이에요. 반환된 결과를 사용자 정의하는 방법이 있는데, 여기서는 Node 속성 title과 plot이 반환되도록 return_properties를 지정했어요.
검색어를 사용하여 Query와 밀접하게 일치하는 영화 줄거리를 검색하면 Approximate Nearest Neighbor Search를 실행하여 Query와 가장 잘 일치하는 상위 3개의 영화 줄거리를 식별해 준답니다.
query_text = "A movie about the famous sinking of the Titanic"
retriever_result = retriever.search(query_text=query_text, top_k=3)
print(retriever_result)
items=[
RetrieverResultItem(content="""
{'title': 'Titanic',
'plot': 'An unhappy married couple deal with their problems on board the ill-fated ship.'}""",
metadata={'score': 0.9450652599334717, 'nodeLabels': None, 'id': None}),
RetrieverResultItem(content="""
{'title': 'Night to Remember, A',
'plot': 'An account of the ill-fated maiden voyage of RMS Titanic in 1912.'}""",
metadata={'score': 0.9428615570068359, 'nodeLabels': None, 'id': None}),
RetrieverResultItem(content="""
{'title': 'Titanic',
'plot': 'A seventeen-year-old aristocrat falls in love with a kind, but poor artist aboard the luxurious, ill-fated R.M.S. Titanic.'}""",
metadata={'score': 0.9422949552536011, 'nodeLabels': None, 'id': None})]
metadata={'__retriever': 'VectorRetriever'}
정규식을 사용해서 `retriever_result`를 더 자세하게 파싱할 수도 있어요.
import re
for k, item in enumerate(retriever_result.items):
plot = re.search(r"'plot':s*'([^']*)'", item.content).group(1)
title = re.search(r"'title':s*'([^']*)'", item.content).group(1)
score = item.metadata["score"]
print(f"Result {k}: {title} - {score} - {plot}")
Result 0: Titanic - 0.9450652599334717 - An unhappy married couple deal with their problems on board the ill-fated ship.
Result 1: Night to Remember, A - 0.9428615570068359 - An account of the ill-fated maiden voyage of RMS Titanic in 1912.
Result 2: Titanic - 0.9422949552536011 - A seventeen-year-old aristocrat falls in love with a kind, but poor artist aboard the luxurious, ill-fated R.M.S. Titanic.
GraphRAG
이제 `Retriever`가 간단한 GraphRAG 파이프라인에 어떻게 적용되는지 한번 살펴볼까요? `neo4j-graphrag` 패키지를 사용해서 GraphRAG 쿼리를 실행하려면 몇 가지 구성 요소가 필요해요.
Neo4j Driver — Neo4j 데이터베이스에 쿼리할 때 사용돼요.
Retriever — `neo4j-graphrag` 패키지에서 몇 가지 구현체를 제공하고, 만약 제공되는 구현체 중에 여러분의 요구사항에 맞는 게 없다면 직접 만들 수도 있어요.
LLM — 답변을 생성하려면 LLM을 호출해야겠죠? `neo4j-graphrag` 패키지는 현재 OpenAI LLM에 대한 구현체만 제공하지만, 인터페이스는 LangChain 채팅 모델과 호환되고 필요하다면 여러분만의 인터페이스를 만들 수도 있답니다.
실제로는 단 몇 줄의 코드만 있으면 돼요.
from neo4j-graphrag.llm import OpenAILLM
from neo4j-graphrag.generation import GraphRAG
# LLM
# Note: the OPENAI_API_KEY must be in the env vars
llm = OpenAILLM(model_name="gpt-4o", model_params={"temperature": 0})
# Initialize the RAG pipeline
rag = GraphRAG(retriever=retriever, llm=llm)
# Query the graph
query_text = "What movies are sad romances?"
response = rag.search(query_text=query_text, retriever_config={"top_k": 5})
print(response.answer)
다양한 유형의 `Retriever`를 커스터마이징하는 방법은 다음 포스팅에서 자세히 알아볼게요.
요약
여러분을 초대해서 neo4j-graphrag 프로젝트에 패키지화하고, 댓글이나 GraphRAG를 통해 여러분의 통찰력을 공유해주시면 감사하겠습니다. 디스코드 채널을 통해서도 소통할 수 있어요.
패키지 코드는 오픈 소스이고 에서 찾을 수 있습니다. 언제든지 이슈를 올려주세요!
초보자를 위한 GraphRAG
연결된 데이터를 기반으로 복잡한 질문에 답할 수 있는 GraphRAG 애플리케이션을 구축해보세요. 세 가지 주요 검색 패턴을 알아볼 거예요.
Python
Retrieval-Augmented
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
GenAI(생성 AI) 애플리케이션을 구축하기 위한 언어, 프레임워크, 도구 옵션이 정말 많죠? 이제 막 시작하는 단계라면 이런 결정을 내리고 모든 것을 통합하는 방법을 알아내는 게 부담스러울 수 있어요.
우리 팀은 몇 가지 핵심 기술이 포함된 스타터 키트 프로젝트를 제공해서 이 프로세스를 단순화하려고 사전 패키지된 솔루션을 개발해 왔어요. 그 중 하나가 바로 오늘 포스팅 주제인 Java에서 Spring AI를 사용해서 GenAI 애플리케이션을 구축하는 방법이에요.
Spring AI란 무엇인가요?
Spring AI는 GenAI 애플리케이션을 구축하기 위한 프레임워크예요. LLM(Large Language Model) 및 RAG(Retrieval-Augmented Generation)와 같은 GenAI 모델 및 아키텍처 작업을 위한 도구와 유틸리티를 제공하죠. Java에는 GenAI를 위한 다른 옵션도 있지만 Spring AI는 다양한 커뮤니티에 걸친 소수의 Neo4j 초기 통합 중 하나랍니다.
이 프로젝트에는 무엇이 포함되어 있나요?
모든 코드와 배경 정보는 spring-ai-starter-kit GitHub 저장소에 있어요. 여기서 일부 코드를 살펴볼 거지만, 언제든지 저장소를 다시 참조할 수 있어요.
Neo4j를 사용해서 구조화된 데이터(예: entity 및 relationship)는 물론 관련 Vector Embedding이 포함된 구조화되지 않은 텍스트 데이터를 저장해요. 벡터에 대한 유사성 검색을 실행한 다음, 검색 `query`를 실행해서 추가 관련 entity를 가져올 수 있죠. 오늘은 OpenAI 모델을 선택할게요. 하지만 다른 모델로 교체할 수도 있어요. Spring AI 지원 LLM를 참고하세요.
프로젝트의 pom.xml 파일을 살펴보면 이 프로젝트에 포함된 네 가지 종속성을 확인할 수 있어요.
Spring Web(REST API 생성용)
OpenAI(또는 Mistral AI, Ollama 등과 같은 기타 LLM 모델)
Neo4j 벡터 데이터베이스(벡터 저장 및 `query`용)
Spring Data Neo4j(Spring 애플리케이션에서 Neo4j 작업용)
우리가 사용하는 데이터 세트는 EDGAR에서 제공한 SEC 서류예요. 여기에는 회사 및 개인 서류 제출을 위한 문서 모음이 포함되어 있죠. 문서는 일반 텍스트로 되어 있고, 다양한 회사에 대한 재무 정보가 포함되어 있어요. 우리 팀은 이 데이터를 회사, 재무 형태 및 관리자에 대한 정보가 포함된 Knowledge Graph로 정리했어요. 여기에는 다음이 포함돼요.
양식 10-K — 상장 회사가 SEC에 제출해야 하는 연례 보고서. 회사의 재무 성과에 대한 포괄적인 요약을 제공해요.
양식 13 — 1억 달러 이상의 자산을 관리하는 기관 관리자가 제출함
스타터 키트 애플리케이션은 기본적으로 공개 데이터베이스에 미리 로드된 데이터 세트 버전을 사용해요. Neo4j Aura 클라우드 데이터베이스 덕분이죠. 덕분에 데이터 가져오기 및 형식 지정으로 인한 번거로움이 사라진답니다. 또는 처음부터 자신만의 Knowledge Graph를 로드하거나, sec-edgar-notebooks 저장소에서 데이터 세트에 대해 자세히 알아볼 수도 있어요.
배경 정보를 살펴보고 코드를 확인해 볼까요?
프로젝트 저장소를 복제한 다음, 즐겨 사용하는 IDE에서 열어보세요. pom.xml 파일을 보면 이전의 네 가지 종속성과 함께 마일스톤 저장소가 포함되어 있음을 알 수 있을 거예요. Spring AI는 아직 일반 출시 버전이 아니기 때문에 마일스톤 저장소가 포함되어 있답니다.
OpenAI의 LLM을 사용하려면 OpenAI에 가입해서 API 키를 요청해야 해요. 해당 데이터베이스(직접 생성한 경우 데이터베이스 포함)가 있다면 application.properties 파일에서 구성을 설정할 수 있어요. 다음은 그 예시입니다.
spring.ai.openai.api-key=<YOUR API KEY HERE>
spring.neo4j.uri=neo4j+s://9fcf58c6.databases.neo4j.io
spring.neo4j.authentication.username=public
spring.neo4j.authentication.password=read_only
spring.data.neo4j.database=neo4j
데이터베이스 자격 증명은 미리 로드된 기본 인스턴스에 대한 것이에요. 따라서 자체 데이터베이스를 사용하는 경우 .uri, .username 및 .password 속성을 해당 속성과 일치하도록 업데이트해야 합니다.
애플리케이션의 코드를 한번 검토해 볼까요?
Vector Embedding 및 벡터 저장소 설정
SpringAiApplication 클래스에서는 OpenAI 클라이언트용 Spring Bean 두 개와 애플리케이션에서 필요할 때마다 필요한 구성 요소에 액세스할 수 있는 Neo4j 벡터 저장소를 설정해야 해요.
@Bean
public EmbeddingClient embeddingClient() {
return new OpenAiEmbeddingClient(new OpenAiApi(System.getenv("SPRING_AI_OPENAI_API_KEY")));
}
@Bean
public Neo4jVectorStore vectorStore(Driver driver, EmbeddingClient embeddingClient) {
return new Neo4jVectorStore(driver, embeddingClient,
Neo4jVectorStore.Neo4jVectorStoreConfig.builder()
.withIndexName("form_10k_chunks")
.withLabel("Chunk")
.withEmbeddingProperty("textEmbedding")
.build());
}
EmbeddingClient 빈은 OpenAI API용 클라이언트를 생성하고 속성 파일에서 API 키를 전달해요. 그런 다음 Neo4jVectorStore 빈은 Neo4j를 임베딩(벡터)용 저장소로 구성하죠. 이는 데이터베이스 자격 증명과 내장 클라이언트에서 자동 구성된 Driver를 가져와요. 벡터 Index 이름(Spring AI 기본값은 spring-ai-document-index), 임베딩을 저장할 Node의 Label(기본값은 Document 엔터티 검색), 임베딩을 포함하는 Property 이름을 지정하려면 벡터 저장소 구성을 사용자 정의해야 해요.
애플리케이션 모델
다음으로 애플리케이션 엔터티를 데이터베이스 모델에 매핑하는 몇 가지 표준 도메인 클래스가 있어요. Document Chunk Node를 나타내는 Chunk 클래스와 데이터베이스의 해당 엔터티를 나타내는 Form, Company 및 Manager에 대한 클래스도 있죠. Chunk 엔터티에는 유사성 검색에 사용할 임베딩(벡터)이 연결되어 있답니다.
이러한 엔터티는 표준 Spring Data Neo4j 코드이므로 여기에 코드를 표시하지는 않을게요. 하지만 각 클래스의 전체 코드는 프로젝트의 GitHub 저장소에서 확인할 수 있어요.
프로젝트의 저장소 인터페이스는 애플리케이션이 데이터베이스와 상호 작용할 수 있도록 도와줘요. 유사한 Chunk에 대한 관련 엔터티(Form, Company, Manager)를 찾는 정의된 Query 방법이 하나 있답니다.
다음으로 컨트롤러 클래스는 사용자 요청을 처리하고 응답을 생성하기 위해 모든 부분이 함께 모이는 곳이에요. 이 클래스에는 사용자로부터 질문을 받고 Neo4jVectorStore를 호출하여 가장 유사한 문서를 계산하고 반환하는 로직이 포함되어 있죠. 그런 다음 유사한 Chunk를 Neo4j Query에 전달해서 연결된 엔터티를 검색하고 LLM 프롬프트에 추가 컨텍스트를 제공할 수 있어요. 제공된 모든 정보를 사용해서 더욱 정확하게 답변하는 거죠.
제어 장치
컨트롤러 클래스는 유사성 검색을 실행하고, LLM을 호출하고, 데이터베이스를 Query하기 위해 Neo4jVectorStore 빈, OpenAiChatClient 빈 및 ChunkRepository 인터페이스를 삽입해야 해요.
@RestController
@RequestMapping("/api")
public class ChunkController {
private final OpenAiChatClient client;
private final Neo4jVectorStore vectorStore;
private final ChunkRepository repo;
@GetMapping("/chat")
String getGeneratedResponse(@RequestParam String question) {
List<Document> results = vectorStore.similaritySearch(SearchRequest.query(question));
List<Chunk> docList = repo.getRelatedEntitiesForSimilarChunks(results.stream()
.map(Document::getId)
.collect(Collectors.toList()));
var template = new PromptTemplate("""
You are a helpful question-answering agent. Your task is to analyze
and synthesize information from the top result from a similarity search
and relevant data from a graph database.
Given the user's query: {question}, provide a meaningful and efficient answer based
on the insights derived from the following data:
{graph_result}
""",
Map.of("question", question,
"graph_result", docList.stream().map(chunk -> chunk.toString()).collect(Collectors.joining("n"))));
System.out.println(" - - - PROMPT - - -");
System.out.println(template.render());
return client.call(template.create().getContents());
}
}
마지막 부분은 사용자가 /chat 엔드포인트에 GET 요청을 보낼 때 호출되는 메서드를 정의하는 부분이에요. 이 메서드는 질문을 query 파라미터로 받아서, vectorStore의 similaritySearch() 메서드에 전달해서 유사한 문서 덩어리(chunks)를 찾죠.
Spring AI는 일반적인 Document 타입을 예상하기 때문에, 유사한 Chunk 노드가 Document 엔티티에 매핑돼요. Neo4jVectorStore 클래스에는 Document를 사용자 정의 레코드로 변환하는 메서드와, 반대로 레코드를 Document로 변환하는 메서드가 포함되어 있답니다.
컨트롤러 메서드로 다시 돌아와서, 이제 유사한 문서 청크가 있지만, 텍스트 청크만으로는 유용한 답변을 제공하기에 충분한 정보가 없을 수도 있어요. 이제 Neo4j에서 query를 실행해서 해당 청크와 관련된 양식, 회사, 관리자를 검색해야 해요. 바로 이 부분이 애플리케이션의 Retrieval-Augmented Generation (RAG) 부분이에요.
유사성 검색이 유사한 문서 청크를 반환한 후, 저장소의 getRelatedEntitiesForSimilarChunks() 메서드를 호출해서 (유사한 문서 ID 목록을 전달해서) 해당 청크에 대한 관련 항목을 찾아요.
다음 코드 블록은 관련 엔터티가 포함된 사용자의 질문과 그래프 결과를 함께 Large Language Model (LLM)으로 보낼 텍스트가 포함된 프롬프트 템플릿이에요. 마지막으로 템플릿의 create() 메서드를 호출해서 LLM에서 응답을 생성하고 응답 문자열에 대한 content 키를 반환하죠.
한번 시험해 볼까요!
애플리케이션 실행
스타터 키트 애플리케이션을 실행하려면 터미널에서 ./mvnw spring-boot:run 명령을 사용하면 돼요. 애플리케이션이 실행되면 EDGAR 데이터에 대한 질문을 query 파라미터로 사용해서 /api/chat 엔드포인트에 GET 요청을 보낼 수 있어요. 몇 가지 예시를 보여드릴게요.
SEC 관련 질문을 자유롭게 던져보거나, 애플리케이션이나 코드를 조정해서 어떻게 반응하는지 확인해보세요. 콘솔 출력을 확인해서 애플리케이션과 LLM 간에 데이터가 잘 주고받는지 확인할 수도 있답니다.
마무리
이번 포스팅에서는 Java로 GenAI 애플리케이션 구축을 시작하는 데 도움이 되는 Spring AI Neo4j 스타터 키트를 살펴봤어요. Spring AI를 사용해서 이미 잘 구축된 Spring 생태계의 풍부함을 확장해서 JVM 언어(이번 포스팅에서는 Java)로 GenAI 앱을 작성할 수 있었죠.
Spring AI는 다양한 LLM 모델과 Vector Store를 지원하지만, 저희는 OpenAI 모델과 Neo4j 데이터베이스를 선택했어요. Neo4j는 구조화되지 않은 텍스트 데이터 및 Vector Embedding과 함께 관계 및 표준 구조화된 데이터를 저장하는 기능을 제공하거든요. OpenAI 모델을 사용해서 데이터베이스의 유사성 검색 결과 및 관련 엔터티를 기반으로 사용자 질문에 대한 응답을 생성했답니다.
이 포스팅이 GenAI와 그 이상을 시작하는 데 도움이 되었기를 바라요! 즐거운 코딩 되세요!
자원
코드(GitHub 저장소):Spring AI 스타터 키트
무료 온라인 강좌:GraphAcademy를 통해 Neo4j 및 LLM에 대해 알아보세요
선적 서류 비치:스프링 AI
웹페이지:Spring AI 프로젝트
java
rag
spring
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
Neo4j로 노래와 가사 카탈로그를 만들고, 내장된 Gen AI 기능으로 내용 기반 노래 찾기!
여러분, 노래 제목이나 누가 불렀는지 기억은 안 나는데, 대략적인 내용만 어렴풋이 기억나는 노래를 찾고 싶었던 적 없으신가요? 딱 4줄의 코드로 이 문제를 해결하는 도구를 만들어 볼 거예요.
제 아들 Noah Bergman(13세)의 작품
인터넷은 금방 지나갈 과대 광고일 뿐이에요. 장기적으로 봤을 때, 사람들이 인터넷 서핑에 그렇게 많은 시간을 쏟고 싶어 하진 않을 거라고 생각해요.
이 말은 1996년에 스웨덴 통신부 장관이었던 이네스 우스만(Ines Uusmann)이 했던 말인데요. 그녀의 말처럼 인터넷이 과대 광고였을 수도 있죠. 하지만 인터넷은 이미 20년 넘게 우리 곁에 있었고, 이제는 절대 사라지지 않을 존재에 대한 과대 광고였던 것 같아요. 인터넷 없는 현대 생활은 상상하기 힘들 정도니까요. 사실 90년대 초반에 과대광고를 불러일으킨 건 바로 월드 와이드 웹(World Wide Web)의 등장 때문이었죠.
마찬가지로 많은 사람들이 AI를 과대 광고라고 부르기도 해요. 물론 그럴 수도 있지만, 인터넷의 과대 광고와 굉장히 비슷하다고 생각해요. AI는 반세기가 넘는 역사를 가지고 있고, 오늘날의 인터넷처럼 우리 삶에 필수적인 존재로 계속 남아있을 거라고 믿어요. 인터넷에 WWW가 있다면, AI에는 LLM(Large Language Model)과 GenAI 같은 존재가 있는 거죠.
만약 제 예측이 맞다면, 특히 소프트웨어 개발자라면 ChatGPT와 대화하는 것뿐만 아니라, 이 기술을 직접 사용하는 방법을 배우면서 새로운 기술을 배우고 받아들이는 게 중요할 거예요. 그리고 그렇게 하기 위해 꼭 수학자일 필요도 없어요! AI를 쉽게 사용할 수 있도록 도와주는 훌륭한 도구들이 정말 많거든요. 그중 하나가 바로 Neo4j랍니다.
Neo4j와 AI
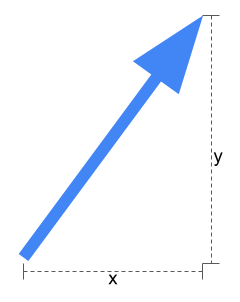
Vector Search가 뭔지 너무 깊게 들어가진 않을게요. 간단하게 설명하자면, 벡터는 화살표처럼 길이와 방향을 가진 것이라고 생각하면 돼요. 2차원에서는 아래 그림처럼 x와 y 두 숫자로 벡터를 표현할 수 있죠.
2차원 벡터
Vector Embedding은 LLM이 자연어 텍스트(또는 이미지나 음악)의 내용을 나타내는 단일 벡터를 생성하도록 하는 건데요. 예를 들어, 이 블로그 글 전체를 하나의 벡터로 표현하는 거죠. 그런데 위 그림처럼 2차원 벡터가 아니라, 1000차원이 넘는 벡터(OpenAI의 경우 1536차원)를 사용해요. 이렇게 텍스트를 숫자로 표현한 다음, 이걸 이용해서 GenAI와 Neo4j에 대한 다른 블로그 글(제가 쓴 글이 몇 개 있어요 😉)처럼 비슷한 텍스트를 검색할 수 있는 거예요. 이때 텍스트에 사용된 단어의 유사성이 아니라, 텍스트의 실제 의미(LLM이 이해하도록 설계된)를 기준으로 검색하는 거죠.
Neo4j를 사용하면 Vector Embedding을 Node의 Property로 저장한 다음, 특정 임베딩과 유사한 Node를 검색할 수 있어요. 검색 속도를 높이기 위해 이런 벡터들을 Indexing할 수도 있고요. 바로 이 기능을 이용해서 가사 검색기를 만들 거예요.
가사 검색기가 왜 필요할까요?
그런데 왜 이런 도구를 만들고 싶을까요? ChatGPT도 이 기능을 꽤 잘하거든요. 예를 들어, 제가 ChatGPT에게 이렇게 물어봤어요.
메탈리카 노래 중에 전쟁에서 심하게 다쳐서 감각을 잃은 남자에 대한 노래가 뭐였지?
그러자 ChatGPT는 이렇게 대답했어요.
당신이 언급한 메탈리카의 노래는 'One'입니다. "One"은 1988년 앨범 "...And Justice for All"의 트랙입니다. 이 곡은 제1차 세계대전 당시 부상을 입어 시각, 청각, 언어 등 모든 감각을 잃은 군인의 이야기를 담은 달튼 트럼보(Dalton Trumbo)의 소설 'Johnny Got His Gun'에서 영감을 받았다. 메탈리카는 이 노래에서 전쟁의 공포와 고통, 그리고 그러한 비극적인 상황에서 일어날 수 있는 개인의 정체성 상실을 전달한다.
음, 우리가 직접 이런 도구를 만들고 싶은 이유는 몇 가지가 있어요.
ChatGPT는 Language Model이 훈련될 때 존재했던 정보만 알고 있어요. 그래서 만약 메탈리카의 최신 앨범 '72 Seasons'에 수록된 곡이었다면 찾지 못했을 거예요.
ChatGPT는 훌륭하지만, 완전히 신뢰할 수는 없어요. 때로는 솔직한 거짓말을 하기도 하거든요.
Spotify 같은 음악 서비스에 이 기능을 넣는다면, 모든 노래가 아니라 라이브러리에 있는 노래만 검색하면 되겠죠.
그리고 Spotify 같은 도구에 이런 기능을 통합하려면, 채팅 기능보다는 좀 더 명확하게 정의된 API를 통합하고 싶을 거예요.
우리가 만들 도구
시작하기 전에 OpenAI 계정을 만들어야 해요. Neo4j는 임베딩을 수행하기 위해 OpenAI, VertexAI, AWS Bedrock을 지원하지만, 이번에는 OpenAI를 사용할 거예요. OpenAI 계정은 유료 계정이라서 비용이 발생할 수 있지만, 제가 이 글을 쓰면서 테스트하는 데 사용한 비용은 2센트도 안 됐어요. OpenAI 계정에서 API Key를 생성해야 하고, 이 키는 아래 쿼리에서 $apiKey로 사용될 거예요.
GenAI 지원은 Neo4j 5.x 버전에서 점진적으로 이루어졌는데요. 여기서 사용할 가장 최신 기능인 임베딩 절차는 Neo4j 5.15에서 출시되었기 때문에, 이 버전을 사용할 거예요.
Neo4j 자체 인스턴스를 사용하고 있다면, neo4j-genai-plugin-5.XX.0.jar 파일을 복사해서 plugins 폴더에 넣어준 다음 Neo4j를 재시작해야 해요. AuraDB를 사용하고 있다면, 기본적으로 이 기능들을 바로 사용할 수 있답니다.
이 글의 내용을 테스트해보고 싶다면 AuraDB Free 인스턴스를 설정하는 것도 좋은 방법이에요. 여기서 무료 계정을 만들 수 있어요: 그리고 인스턴스를 만들어서 직접 테스트해볼 수 있죠. OpenAI 계정도 필요하다는 점, 잊지 마세요!
이번 글에서는 특정 기능을 구현하는 애플리케이션을 만들지는 않을 거예요. 대신 Neo4j Browser에서 Cypher 쿼리를 작성해볼 건데요, 실제 서비스를 개발한다면 당연히 이 쿼리들을 애플리케이션 코드에 통합해야겠죠?
세상 모든 노래에 대해 다 해보면 좋겠지만, 아쉽게도 그런 데이터를 구할 수가 없어서... 대신 St. Anger 앨범까지의 Metallica 노래 가사 라이브러리를 찾았어요. HTML 형식이었지만, 가사를 파싱해서 아티스트 (여기서는 Metallica 하나뿐!), 앨범, 노래로 이루어진 그래프를 만들었답니다. 노래 가사는 각 `Song` **node**의 문자열 **property**로 저장했어요.
아티스트는 빨간색, 앨범은 파란색, 노래는 녹색
직접 테스트해보고 싶다면, 아래 코드를 실행해서 똑같은 데이터셋을 가져올 수 있어요. 물론, 아래 `import` 구문에서 사용하는 것과 동일한 **스키마**를 따른다면, 좋아하는 아티스트와 노래를 사용해도 괜찮아요!
LOAD CSV WITH HEADERS FROM 'https://drive.google.com/uc?export=download&id=1uD3h7xYxr9EoZ0Ggoh99JtQXa3AxtxyU' AS line
CREATE (song:Song {name: line.Song, lyrics: line.Lyrics})
MERGE (album:Album {name: line.Album})
MERGE (artist:Artist {name: line.Artist})
MERGE (song)-[:IS_ON]->(album)
MERGE (album)-[:PERFORMED_BY]->(artist)
자, 이제 **database**가 준비됐으니, 제일 먼저 할 일은 **vector**에 사용할 **property**에 대한 **vector index**를 만드는 거예요. 여기서는 `embedding`이라는 **property**를 사용할 거고, `Song` **node**에 저장할 거예요. `1536`은 **vector**의 차원인데 (OpenAI가 사용하는 차원과 같아요!), 마지막 **property**인 `'cosine'`은 사용할 유사도 알고리즘이에요. 일반적으로 `'cosine'`이 가장 많이 쓰인답니다.
CREATE VECTOR INDEX song_embeddings IF NOT EXISTS
FOR (s:Song) ON (s.embedding)
OPTIONS {
indexConfig: {
`vector.dimensions`: 1536,
`vector.similarity_function`: 'cosine'
}
}
다음으로는 모든 노래 가사에 대한 **Vector Embedding**을 추가해야 해요. 간단한 `MATCH` **query**를 사용해서 노래를 찾은 다음, 가사 **property** 문자열을 **embedding** 함수에 전달하면 돼요.
MATCH (song:Song)
WITH song, genai.vector.encode(song.lyrics, "OpenAI", {token: $apiKey}) AS vector
CALL db.create.setNodeVectorProperty(song, "embedding", vector)
`db.create.setNodeVectorProperty()` **procedure**는 `SET song.embedding = 임베딩`과 똑같은 역할을 하지만, **vector**를 더 효율적인 형식으로 저장해준다는 점이 다르답니다.
이 **query**는 **database**에 있는 모든 노래에 대해 OpenAI **API**를 한 번씩 호출하기 때문에, 실행하는 데 시간이 좀 걸릴 거예요. 위 함수 대신 **batch procedure**를 사용하는 방법도 있는데, 이 경우에는 (여기서는) 단 한 번의 **API** 호출만 발생해요.
MATCH (song:Song)
WITH collect(song.lyrics) AS lyrics, collect(song) AS songs
CALL genai.vector.encodeBatch(lyrics, "OpenAI", {token: $apiKey}) YIELD index, resource, vector
CALL db.create.setNodeVectorProperty(songs[index], "embedding", vector)
여기서 주의할 점은 한 **batch**에 포함할 수 있는 항목 수에 제한이 있다는 거예요 (OpenAI의 경우 2048개). 따라서 **database**에 Metallica 말고 다른 아티스트의 노래도 있다면, 예를 들어 아티스트별로 또는 앨범별로 나눠서 처리해야 할 거예요.
자, 이제 모든 설정이 끝났으니 가사 **search**를 수행할 준비가 됐어요. 검색할 문구는 `phrase`라는 **parameter**로 설정하고, `apiKey`는 여전히 **parameter**로 유지할 거예요 (아래에는 표시하지 않았지만요).
:params
{
phrase: "A song about a guy who is so badly wounded in war so he no longer has any senses",
apiKey: "*****"
}
**search**를 하려면, 먼저 똑같은 함수를 호출해서 검색 문구에 대한 **Vector Embedding**을 생성해야 해요. 그런 다음, 전용 **procedure**를 사용해서 **database**에서 가장 유사한 **embedding**을 가진 노래를 찾아주는 **vector search**를 수행하면 된답니다.
WITH genai.vector.encode($phrase, "OpenAI", {token: $apiKey}) AS embedding
CALL db.index.vector.queryNodes('song_embeddings', 1, embedding) YIELD node AS song, score
RETURN song.name
이것이 우리에게 DISPOSABLE HEROES라는 답을 주네요. 글쎄요, 그건 우리가 기대했던 건 아니었어요. 우리는 ONE을 생각하고 있었거든요. DISPOSABLE HEROES 역시 고통에 대한 전쟁 노래이기 때문에 정답이긴 하지만, 우리가 원하는 건 아니죠. 이건 정확한 과학이 아니니까요. 그래서 일반적으로 최고의 일치 항목 수를 요청하는 게 가장 좋아요. 올바른 것은 일반적으로 상위 3~5개 결과에 있거든요. queryNodes의 두 번째 매개변수는 우리가 원하는 결과이니까, 이를 3으로 늘리면 돼요.
WITH genai.vector.encode($phrase, "OpenAI", {token: $apiKey}) AS embedding
CALL db.index.vector.queryNodes('song_embeddings', 3, embedding) YIELD node AS song, score
RETURN song.name
이제 다시 실행해볼게요.
DISPOSABLE HEROES
ONE
ONE
됐네요! 두 번째 일치로 올바른 것을 얻었어요. 그리고 세 번째 경기는…? 왜 우리는 그것을 두 번 얻을까요? 음, 두 개 이상의 앨범에 포함되어 있기 때문에 우리가 모델링한 대로 데이터베이스에 복제되는 거죠.
이것이 우리 솔루션을 뒷받침하는 Knowledge Graph를 갖는 것이 매우 좋은 점이에요. 가사를 기반으로 노래를 찾은 다음 그래프를 탐색하여 다른 모든 것을 찾을 수 있거든요.
WITH genai.vector.encode($phrase, "OpenAI", {token: $apiKey}) AS embedding
CALL db.index.vector.queryNodes('song_embeddings', 3, embedding) YIELD node AS song, score
MATCH (song)-[:IS_ON]->(album:Album)-[:PERFORMED_BY]->(artist:Artist)
RETURN song.name AS Song, album.name AS Album, artist.name AS Artist
이제 결과는 이렇습니다.
Song Album Artist
DISPOSABLE HEROES MASTER OF PUPPETS Metallica
ONE S&M Metallica
ONE And Justice For All.. Metallica
이제 제대로 작동하는지 확인하기 위해 한 번 더 테스트하면 돼요. 이번에는 다음을 검색해볼게요.
악몽을 꾸는 소년의 노래
결과는 다음과 같아요.
Song Album Artist
Enter Sandman Black Album Metallica
Enter Sandman S&M Metallica
The thing that should not be MASTER OF PUPPETS Metallica
Enter Sandman은 제가 의도한 것이므로 성공이라고 해야겠죠?
됐어요. 네 줄의 코드로 지능형 노래 시놉시스 찾기를 완료했어요!
참고 자료
Vector Search Index에 대한 문서는 다음과 같아요.
벡터 검색 인덱스 – Cypher 매뉴얼
여기에서 내장 함수/절차에 대한 문서를 찾을 수 있어요.
GenAI 통합 – Cypher 매뉴얼
Vector Embedding 검색
GenAI 도구
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
확장 법칙은 정체될 수 있지만 GenAI는 줄어들지 않았어요. 엔지니어들은 어디에서나 무엇이 작동하고 어떻게 유용하게 만들 수 있는지 알아내느라 바빴죠. GraphRAG, 즉 Knowledge Graph와 Retrieval-Augmented Generation (RAG)이 결합된 기술은 다양한 기술로 발전해 왔고, 연구 논문과 소프트웨어 통합도 활발하게 이루어지고 있어요.
이 점을 염두에 두고 두 번째 GenAI 그래프 모임을 준비했고, 그래프와 LLM의 교차점에서 일하는 뛰어난 분들을 초대했어요. 목표는 GraphRAG 주변에서 일어나는 많은 일에 대한 메모를 파악하고 비교하는 것이었답니다.
회고전: 5월부터 지금까지
5월 첫 번째 GenAI 그래프 모임 이후 GraphRAG의 타임라인이에요 (완전하진 않지만요!).
처음에 GenAI 그래프 모임에서 GenAI 애플리케이션이 세 가지 주요 버킷의 소스 데이터를 사용하는 것을 관찰하면서 검색을 위해 Knowledge Graph를 사용하는 방법을 탐색했었죠.
텍스트 파일 또는 PDF의 구조화되지 않은 데이터
기존 데이터베이스의 구조화된 데이터
두 가지가 결합된 혼합 데이터
여름 동안 개발자와 기업의 관심이 엄청나게 증가했어요. 프로젝트는 "PDF로 채팅" 또는 "CSV로 채팅"과 같이 구조화되지 않았거나 구조화된 데이터로 시작하는 경향이 있었죠. 하지만 첨단 기술이 앞으로 나아갈 길을 제시했음에도 불구하고 많은 사람들이 파일럿 단계에서 정체되었어요.
개념 증명 이상의 일을 할 수 있었던 사람들의 공통점은 무엇이었을까요? 저희 경험에 따르면 비정형 데이터와 정형 데이터 사이에 더 강력한 연결이 있어서 혼합 데이터의 최적 지점에 도달하는 것 같았어요.
GenAI 개념 증명 노력 중 71%는 구조화되지 않은 데이터만 사용할 때 멈춘다고 해요. PoC를 통과한 3분의 1은 더 구조화된 비즈니스 데이터로 시작하거나 통합했대요.
학문적 이론을 실제 실무로 전환하는 건 정말 어려운 일이죠. 그래서 저희는 몇 가지 일을 하기로 결정했어요:
패턴 카탈로그를 큐레이팅해서 연구 논문에서 정보를 추출하는 거예요.
검증된 접근 방식을 와 라이브러리로 구현하는 거죠.
동료들과 만나서 도움이 될 만한 다른 게 뭐가 있는지 알아보는 거예요.
Gathering 행사에서 저희는 Knowledge Graph 구성, GraphRAG 기술, 그리고 실제 경험에 중점을 두고 그룹 토론을 진행했어요.
GraphRAG 시작하기
여러분 모두 Vector Embedding이 뭔지 이미 알고 있고, RAG 약어가 뭔지도 설명할 수 있는 AI 엔지니어라고 가정해 볼게요. 그럼 가장 좋은 시작 방법은 뭘까요?
공유 노트 내용을 한번 살펴볼까요:
기술 전반에 걸친 병렬 비교
연결된 데이터와 결과 프롬프트를 포함해서 답변을 생성하는 데 사용된 전체 컨텍스트를 공개하는 것
그래프 시각화는 데이터와 스키마에 대한 "아하!" 모먼트에 정말 중요해요.
Knowledge Graph 구성, 자동 마법과 손으로 직접 선별하는 것 사이의 균형을 맞추는 데 도움을 주는 것
세 가지 방향: 1) 모든 소스에 대한 일반적인 도구 기반 워크플로, 2) 잘 알려진 심층적인 예시로서 구체적인 "Northwind" Knowledge Graph, 3) 다양한 예시를 위한 독립 실행형 노트북
시작에 대한 대화를 확장한 또 다른 세션에서는 개발자 경험이라는 더 넓은 주제를 고려했어요.
공유 노트에서:
대부분의 사람들은 비정형 데이터로 시작하는 반면, GraphRAG는 정형 또는 혼합 데이터로 시작한다는 점
일반적인 RAG는 도메인에 구애받지 않지만, GraphRAG는 도메인에 따라 달라진다는 점
"고급 RAG"는 GraphRAG의 첫 번째 단계로 이해될 수 있으며, 도메인에 대해 상대적으로 독립적이라는 점
템플릿으로 해결할 수 있는 "콜드 스타트" 또는 "빈 캔버스" 문제가 있다는 점
올바른 GraphRAG 접근 방식은 도메인별로 다르다는 점. 지침과 예시가 필요하다는 점
광범위한 일반 비즈니스 문제를 다루는 "7개의 그래프"(자세한 내용은 추후 제공)
고전적인 객체 지향 디자인 패턴과 같은 공통 참조로 사용되는 GraphRAG 패턴 카탈로그
Knowledge Graph 엔지니어링
Knowledge Graph는 요약이 포함된 덩어리진 텍스트만큼 단순할 수도 있고, 전체 기업에 대한 통합 뷰만큼 포괄적일 수도 있는 전체 정보 아키텍처에요. 데이터 엔지니어링과 마찬가지로 Knowledge Graph에도 데이터 준비, 변환, 모델링 및 평가가 모두 필요하죠.
그룹은 Knowledge Graph의 혼합을 고려했어요.
CSV 또는 JSON과 같은 구조화된 데이터에서 매핑된 도메인 그래프
구조화된 데이터에서 매핑된 긴 형식의 텍스트가 포함된 도메인 그래프
제품 카탈로그나 매뉴얼과 같은 잘 알려진 문서 컬렉션에서 파생된 알려진 구조의 어휘 그래프
알려진 용어에 따라 명명된 개체 인식(NER)을 사용하여 검색된 구조가 포함된 어휘 그래프
NER과 구조화된 데이터를 결합하여 알려진 구조와 발견된 구조를 모두 포함하는 어휘 그래프
개방형 NER를 사용하여 완전히 발견된 구조를 갖는 어휘 그래프
온톨로지: 계획은 무엇인가요?
온톨로지는 단순히 해당 속성과 이들 간의 관계를 보여주는 주제 영역의 개념 및 범주 집합이에요. 원한다면 이걸 그래프 스키마라고 불러도 괜찮아요.
공유 노트에서:
스키마는 상호 운용성, 설명 가능성, 접지에 도움이 된다는 점
엔터티 추출 및 비정형 데이터와 정형 데이터 간의 정렬에 유용하다는 점
완전하고 형식적인 온톨로지는 부담스러울 수 있다는 점. GraphRAG에 대한 더 간단한 형식이 있을까요?
비정형 데이터와 일치하도록 카탈로그의 기존 스키마를 자동으로 선택할 수 있다는 점
엄격하게 정확하고 사용하기 쉬운 균형을 맞추는 게 중요하다는 점
스키마는 상호 운용성, 설명 가능성, 접지에 도움이 된다는 점
정보 검색을 위해 그래프를 사용하는 다양한 기술을 탐구하는 연구가 정말 활발하게 진행되고 있어요.
공유 노트 내용을 한번 살펴볼까요:
연구에는 상황별 검색, 쿼리 중심 요약, 텍스트-암호화, 계층형 메모리, 그래프 기반 재순위 지정, 하이브리드 index, GNN 등이 포함돼요.
GNN과 그래프 데이터 과학은 정확성을 강화하고 개선하는 데 도움을 줄 수 있어요.
그래프는 소스 정보, 메모리, 보안 제약 조건, 정보 검색을 위한 안내 경로를 나타낼 수 있어요.
가장 큰 과제는 "올바른" 일이 사용 사례에 따라 다르다는 점이에요.
GenAI 그래프 수집은 조직 간 협업을 위한 특별한 기회였어요. 당장의 목표는 P2P 연결이었지만, 장기적으로는 각 참여자가 자신의 길에서 성공하고 궁극적으로 모든 사람이 GraphRAG의 혜택을 받는 것이죠.
RAG의 'R'에 그래프를 사용하는 GraphRAG는 정말 다양한 접근 방식과 기술로 계속 발전하고 있어요. 다행히 모든 것을 다 알 필요도 없고, 한 번에 모든 걸 다 할 필요도 없다는 거죠. 그래프는 보기 좋게 구성되어 있잖아요. 그래프로 생각하는 방식, 즉 멘탈 모델에는 준비된 범위까지 확장되는 몇 가지 개념이 있어요. ML 모델부터 애플리케이션 워크플로, 디스크의 데이터 스토리지까지 그래프가 될 수 있죠. 아니면 단순히 텍스트 덩어리들을 서로 연결하고, 문서들을 연결하는 것만큼 간단할 수도 있고요.
최소 실행 가능한 그래프로 시작해보세요. 데이터를 더 추가하고, 풍부하게 만들고, 연결하고, 계속 반복하는 거예요!
그래프RAG
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
편집자 주: 이 강연은윌 리옹 at 클라우드 개발자를 위한 Neo4j의 Connections 이벤트 그래프.
풀스택 개발자의 관점에서 Neo4j가 현대 클라우드 생태계에 어떻게 적응하는지 공유할게요. 저는 Neo4j의 개발자 관계 팀에서 일하고 있고, Neo4j와 다양한 기술을 통합하고 고객이 이미 이 작업을 수행하는 방법을 살펴보는 데 많은 시간을 보내고 있어요.
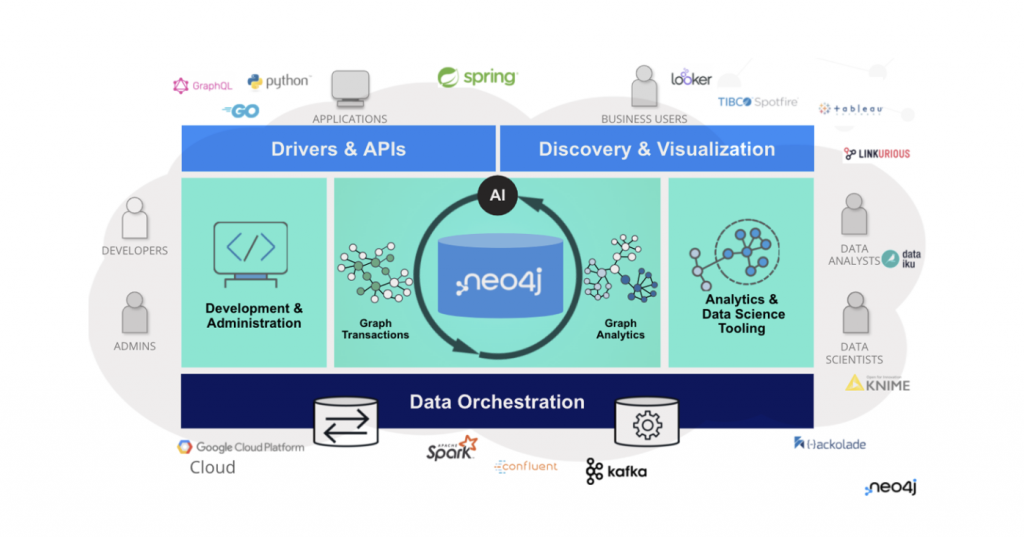
Neo4j 그래프 플랫폼
데이터베이스로서 Neo4j는 우리 애플리케이션의 아키텍처 핵심에 딱 맞는 것 같아요. 우리가 생각해야 할 것은 Neo4j가 다른 기술과 어떻게 작동하는지인데, 이는 우리가 달성하려는 목표에 따라 달라지죠. 위 다이어그램에서 오른쪽의 데이터 과학 및 분석 사용 사례부터 왼쪽의 더 많은 트랜잭션 운영 애플리케이션 구축에 이르는 스펙트럼을 볼 수 있어요. 이 블로그를 통해 저는 스펙트럼의 왼쪽 측면에 더 집중하고, 예를 들어 클라이언트와 데이터베이스 사이에 있는 API 계층을 구축하여 Neo4j로 운영 워크로드를 처리하는 방법을 공유할 거예요.
랍스터 그래프 애플리케이션
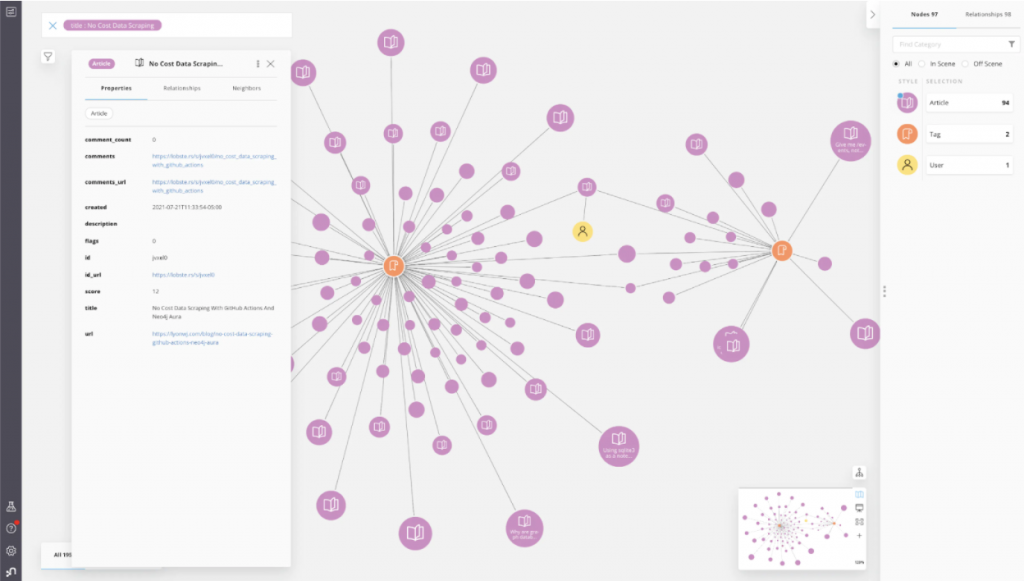
Lobsters는 Hacker News와 비슷한 뉴스 애그리게이터 사이트인데, 댓글을 보면 좀 더 친근한 느낌이 들 수도 있어요. 기술 커뮤니티에서 무슨 일이 일어나고 있는지 살펴보기 좋은 사이트죠. 그래서 Lobsters 사이트의 그래프 버전을 만들어보면 재미있을 것 같아서, "Lobsters Graph"라는 이름으로 만들어봤어요. 기본적으로 Lobsters에서 데이터를 가져오는 그래프 시각화 애플리케이션이에요. 여전히 인기 있는 기사와 관련 주제를 볼 수 있지만, 정보를 좀 더 시각적인 방식으로 볼 수 있다는 게 장점이죠. 기사의 태그와 주제를 기반으로 내가 관심 있는 내용을 더 빠르게 확인할 수 있고요. Lobsters Graph가 어떻게 생겼는지 간단하게 보여주는 데모 영상이에요.
애플리케이션 아키텍처
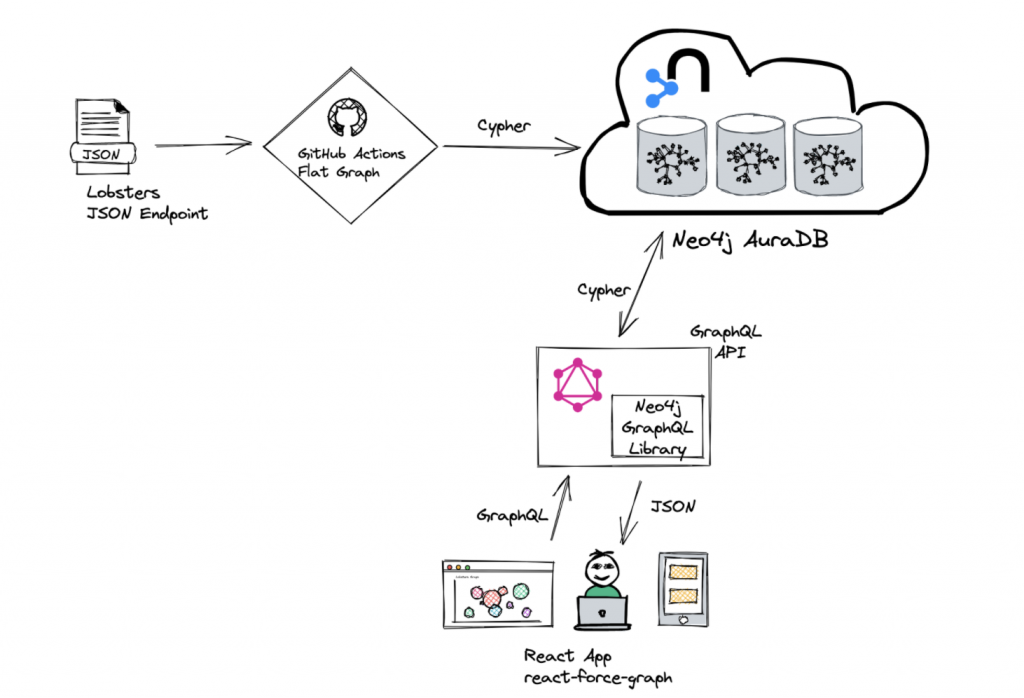
데모에서 보셨듯이, 아주 간단한 그래프 시각화 애플리케이션이에요. 이제 이 애플리케이션을 어떻게 구축했는지, 좀 더 구체적으로 아키텍처가 어떤 모습인지 자세히 살펴볼게요. 풀 스택 개발자로서 우리가 다루는 문제들을 보여주는 몇 가지 흥미로운 부분들이 있거든요. Lobsters의 JSON endpoint에서 데이터를 가져와 Neo4j에 로드하는 방법, 그리고 Neo4j에 데이터가 있으면 해당 데이터를 애플리케이션 계층에 노출하는 방법을 공유할게요.
Neo4j로 데이터를 가져오는 방법
가장 먼저 Neo4j AuraDB 인스턴스를 실행해야 해요. 저는 AuraDB 무료 인스턴스를 사용했는데, 이런 취미 프로젝트를 시작하기에 딱 좋은 방법이죠. 다행히 Lobsters는 데이터를 몇 가지 JSON 피드에 게시하고 있어요. 예를 들어, hottest.JSON endpoint는 순위가 가장 높은 기사를 기준으로 정렬된 리더보드 역할을 해요. 최신 endpoint도 있어서 Lobsters에 게시된 최신 기사를 추적할 수도 있고요.
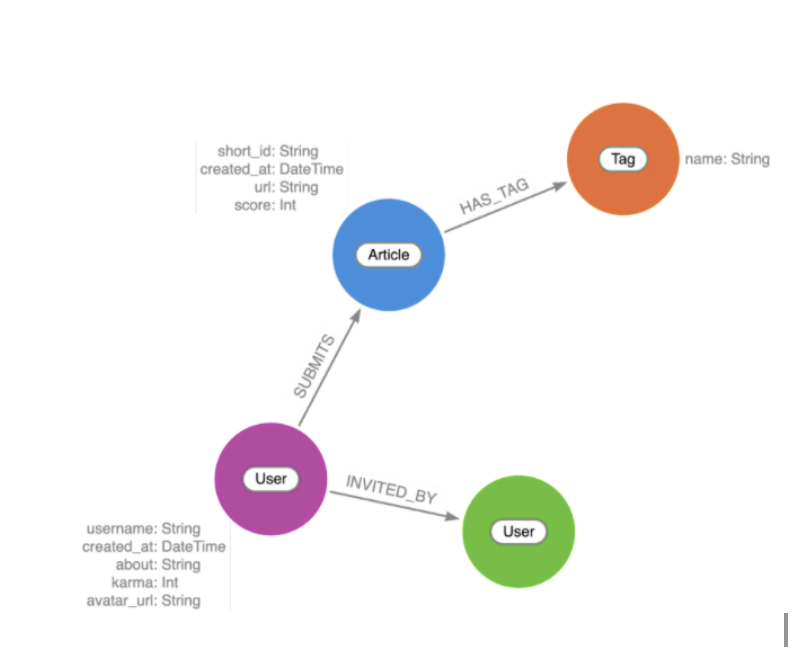
그래프 데이터 모델링
다음 단계는 반복적인 과정인 그래프 데이터 모델링이에요. 제 소스 데이터는 JSON이고요. 이걸 그래프로 표현하기 위해, 먼저 Node가 될 엔터티를 식별하는 것부터 시작해요. 이 경우에는 Node는 기사, 기사를 게시한 사용자, 그리고 기사와 연결되는 태그가 되겠죠.
그 다음에는 이러한 개체들이 어떻게 연결되어 있는지 생각해요. 이게 바로 Relationship이 되는 거죠. 마지막으로, 제가 가지고 있는 Property들을 살펴보죠. 예를 들어 기사에는 ID, URL, 관련 점수가 있어요. 이러한 Property들은 Node나 Relationship에 저장되는 속성이 되는 거예요. 이 반복적인 프로세스의 마지막 단계는 애플리케이션과 데이터 모델의 비즈니스 요구 사항을 살펴보고, 비즈니스 요구 사항에 대한 질문에 답하는 이 그래프를 통한 순회가 있는지 확인하는 거예요.
이 경우에는 매우 간단해요. 상위권 기사도 보고 싶고, 태그도 보고 싶어요. 그리고 동일한 태그가 있는 다른 기사를 볼 수 있기를 원하죠. 따라서 기사 Node를 ID나 점수별로 정렬하고, 해당 태그 Relationship을 순회해야 한다고 생각하게 돼요. 이 데이터 모델링 프로세스를 진행하면서 다음과 같은 훌륭한 도구를 사용할 수 있어요. Arrows는 다이어그램을 그리는 데 유용하죠. Arrows에서 다이어그램을 그린 후에는 이미지로 내보낼 수도 있고, 데이터 모델을 설명하는 JSON을 내보낼 수도 있어요. JSON 데이터를 버전 제어로 관리하고 프로젝트에 참여하는 다른 사람들과 모델을 공유할 수 있다는 점이 정말 좋죠.
Cypher에서 JSON 데이터 작업
이제 데이터 모델과 JSON 데이터가 준비되었어요. 여기서부터는 Cypher를 사용해서 해당 JSON 데이터를 가져와 Neo4j에 로드할 거예요. 다행히 Neo4j에는 APOC Load JSON procedure가 있답니다.
이건 APOC 절차 라이브러리의 일부인데요, APOC를 표준 라이브러리처럼 생각하면 돼요. 몇몇 프로시저와 기능으로 Cypher를 확장해주고, JSON 데이터 작업을 가능하게 해주거든요. apoc.load.json과 함께라면, JSON 엔드포인트로 가서 Cypher를 사용해 데이터를 다시 가져올 수 있어요. 들어오는 JSON 객체(여기선 객체 배열)를 반환하는 것뿐이지만, Cypher를 사용해서 그래프에서 만들고 싶은 데이터 모델을 설명하고 Cypher로 풀어낼 수 있죠. 각 기사에 대해 Cypher를 써서 기사 `Node`, 사용자 `Node`, 태그, 그리고 `Relationship`을 그래프에 생성하는 거예요.
이렇게 Cypher 구문 하나로 데이터를 로드했어요. 이제 Neo4j Browser나 Bloom을 사용해서 쿼리할 수 있죠. 랍스터 데이터를 특정 시점에 표현하는 데는 괜찮지만, 인터넷 검색을 할 때 매일 아침 사이트에 가서 그날의 블로그를 읽고 싶을 수도 있잖아요? 그럼 데이터는 계속 새로고침되어야 하고, 이 스크립트를 제 컴퓨터에서만 실행할 수는 없겠죠. 클라우드에 지속적으로 실행되면서 랍스터 데이터를 가져오는 무언가가 필요할 거예요.
Github 작업 – 플랫 데이터 크론 작업
바로 이럴 때 GitHub Actions가 등장하는 거죠! GitHub 이벤트에 응답하는 맥락에서 GitHub Actions를 많이 보셨을 텐데요. 예를 들어 코드를 체크인하거나 GitHub에 Pull Request가 들어오면 GitHub Actions를 사용해서 테스트를 실행하거나 배포를 트리거할 수 있어요. GitHub Actions를 cron 작업처럼 사용해서 매시간, 매일 실행할 수도 있고요.
GitHub 팀에서 플랫 데이터라는 GitHub Action을 출시했는데, 정말 깔끔하더라고요. 이걸 사용하면 JSON이나 CSV 같은 플랫 파일 엔드포인트로 가는 GitHub 작업을 만들거나, 주기적으로 데이터베이스 `Query`를 실행한 다음 해당 데이터를 GitHub에 커밋할 수 있어요. 데이터에 대한 기록도 남길 수 있고, 데이터를 데이터베이스에 로드하는 등의 후처리 단계도 정의할 수 있죠.
위에서 보시는 것처럼 GitHub 리포지토리에서는 이 플랫 데이터 GitHub 작업을 사용해서 Lobsters JSON 엔드포인트로 이동하고, 최신 .json 파일을 가져와 GitHub에 체크인하는 YAML 파일을 생성해요. 이 데이터는 자주 바뀌는 데이터가 아니라서 cron에서 매시간 실행되도록 설정해뒀어요.
Github 작업: 데이터 로드를 위한 평면 그래프
해당 데이터를 Neo4j Aura에 로드하기 위한 후처리 작업으로, 저는 평면 그래프라는 간단한 GitHub Action을 만들었어요. 이걸 사용하면 JSON 데이터로 작업하는 방법(여기서는 Cypher를 사용하겠죠?)을 정의할 수 있답니다.
전체 YAML 파일은 다음과 같아요.
먼저 Flat Data GitHub Action을 사용해서 최신 .json 파일을 가져와요. 그리고 Flat Graph GitHub Action을 사용하면 되죠. GitHub에는 비밀로 체크인된 Neo4j Aura 인스턴스에 대한 자격 증명이 있답니다. 다음은 JSON 배열을 반복하는 방법을 알려주는 Cypher 쿼리에요. apoc.load.json을 사용해서 이 쿼리와 매우 유사하게 만들 수 있지만, 이번에는 해당 JSON을 Cypher 파라미터로 전달할 거예요. 이렇게 하면 데이터가 Neo4j Aura에서 매 시간마다 계속 업데이트될 거예요.
Neo4j Bloom을 사용한 시각적 탐색
데이터를 시각적으로 탐색하는 방법 중 하나는 Neo4j Bloom을 사용하는 거예요.
Bloom은 Neo4j에 데이터만 있다면 그래프 UI를 만들 수 있는 아주 훌륭한 노코드 솔루션이에요. 하지만 이번 경우에는 Bloom이 딱 맞는 선택은 아니에요. 좀 더 간단한 걸 원하고, Bloom의 모든 기능을 다 보여주고 싶지도 않거든요. 웹 애플리케이션을 만들고 싶어요.
Neo4j GraphQL 라이브러리를 사용하여 API 계층 구축
데이터베이스를 프론트엔드 애플리케이션에 바로 노출하는 대신, 클라이언트와 데이터베이스 사이에 API 계층을 두고 싶어요. 여기에는 몇 가지 커스텀 로직이 들어가고, 보통 인증도 여기서 처리하죠. 이 프로젝트에서는 다양한 도구를 사용해서 이 문제를 해결할 수 있는 여러 방법이 있는데, 이번에는 Neo4j GraphQL 라이브러리를 사용해서 GraphQL API를 만들어볼게요.
Neo4j GraphQL 라이브러리는 JavaScript GraphQL API를 만들기 위한 JS 라이브러리가 아니에요. 다시 말하지만, 클라이언트와 데이터베이스 사이에 있는 이 레이어의 경우 GraphQL을 사용해서 데이터베이스에 직접 쿼리하지 않아요. 그럼에도 불구하고 Neo4j GraphQL 라이브러리는 시작할 때 여러 가지 장점을 제공해준답니다. 혹시 GraphQL에 익숙하지 않다면, 이건 기본적으로 API 쿼리 언어이자 API 요청을 처리하기 위한 런타임이라고 생각하면 돼요.
GraphQL을 사용하면 작업 중인 데이터 형태를 정확하게 정의하고 API에서 사용할 수 있는 엄격한 유형 시스템을 갖게 돼요. 클라이언트에서 해당 데이터를 쿼리하는 방법을 정의하는 거죠. 여기서 그래프 부분이 중요한데, 이러한 유형들이 어떻게 연결되는지를 설명해주거든요. GraphQL의 그래프는 다른 유형을 참조하는 유형의 관계 필드에 대한 아이디어를 가지고 있어요.
쿼리할 때 클라이언트는 GraphQL 유형 정의에 설명된 이 데이터 그래프를 자유롭게 탐색해서 클라이언트가 관심 있는 데이터, 또는 클라이언트가 렌더링해야 하는 데이터(예: 애플리케이션의 뷰)를 가져올 수 있어요. 다시 가져오려는 데이터를 지정하는 클라이언트와 결합된 이 유형 시스템은 우리가 돌아오는 데이터의 모양과 유형을 정확히 알고 있다는 걸 의미하고, 이는 클라이언트를 위해 유형이 안전한 데이터로 작업할 수 있는 정말 좋은 방법이에요.
언급했듯이 Neo4j GraphQL 라이브러리는 JS 그래픽 API를 구축하기 위한 JavaScript 라이브러리예요. API 레이어를 구축할 때 작성해야 하는 상용구 코드를 줄이는 데 정말 도움이 될 거예요. 새로운 GraphQL 라이브러리를 사용해서 GraphQL 유형 정의를 정의하고 이를 라이브러리에 전달하면, GraphQL API를 생성하는 데 필요한 많은 작업을 대신 처리해줘요. 따라서 Neo4j GraphQL 라이브러리의 주요 목표 중 하나는 GraphQL 최초 개발 아이디어를 지원하는 것이죠.
이건 GraphQL API뿐만 아니라 데이터베이스에 대한 데이터 모델을 정의하는 GraphQL 유형 정의가 있다는 걸 의미해요. GraphQL 정의는 실제로 데이터베이스의 데이터 모델을 구동할 수 있답니다. API에서 이는 Neo4j와 GraphQL 레이어로 작업할 때 두 개의 별도 스키마를 유지할 필요가 없다는 걸 의미하죠.
앞서 언급한 도구인 Arrows의 좋은 점 중 하나는 그래프 다이어그램을 만들 때 내보내기 옵션 중 하나가 GraphQL 유형 정의라는 거예요. 이러한 유형 정의는 Neo4j GraphQL 라이브러리에서 작동하고요. 그래프 모델을 시각적으로 정의하면 Arrows에서 직접 GraphQL 유형 정의를 내보낼 수 있어요.
GraphQL CRUD API 자동 생성
유형 정의가 있으면 이를 Neo4j GraphQL 라이브러리에 넘겨주세요. 그러면 모든 CRUD 작업(Create, Read, Update, Delete)이 생성될 거예요. 기본적으로 유형 정의에 정의된 모든 유형에 대한 작업이죠.
이건 순서 지정, 페이지 매김, 복잡한 필터링을 추가하고 데이터베이스가 지원하는 공간 및 시간 기본 유형에 대한 지원을 추가해서 Node 유형을 검색하기 위한 API의 진입점이에요.
GraphQL에서 Cypher 생성
쿼리 시 임의의 GraphQL 요청은 Cypher로 변환돼요. 개발자 입장에서 데이터 계층에서 데이터를 가져오는 방법을 설명하기 위해 많은 상용구 코드를 작성할 필요가 없다는 걸 의미하죠. 이는 개발자 생산성에 좋지만, 여기에는 또 다른 엄청난 성능 이점이 있어요. 단일 데이터베이스 쿼리를 생성하고 있고, 이는 데이터베이스에 대한 단일 왕복 여행이며 데이터베이스는 해당 쿼리를 최적화할 수 있거든요.
일반적으로 GraphQL을 사용하면 여러 데이터베이스 요청이 발생하죠. 이걸 캐싱하고 일괄 처리하는 방법을 고민해야 하지만, Neo4j GraphQL 라이브러리를 사용하면 기본적으로 생성되는 단일 데이터베이스 `쿼리`를 사용해서 루트에서 전체 요청을 자동으로 해결해줘요.
Cypher로 GraphQL 확장하기
이제 Neo4j 그래프 라이브러리를 사용해서 타입 정의 없이 무료로 생성되는 기본 CRUD 기능을 넘어서 볼 거예요. 정의하고 싶은 사용자 정의 로직이 있다면, Cypher GraphQL `스키마` 지시문을 사용할 수 있어요.
`스키마` 지시문은 서버 측에서 발생하는 사용자 정의 작업이 있다는 걸 나타내는 GraphQL에 내장된 확장 메커니즘이에요. Neo4j GraphQL 라이브러리에는 꽤 많은 지시문이 있는데요. 개발자가 지시문을 통해 API를 구성하는 주요 방법이죠. Cypher 지시문은 Neo4j GraphQL 라이브러리에서 제가 제일 좋아하는 기능이자, 아마도 가장 강력한 기능일 거예요. 이걸 사용하면 Cypher `쿼리`를 작성하고, Cypher `쿼리`에 매핑되는 타입 정의의 필드에 주석을 달 수 있어요.
즉, Cypher에서 사용자 지정 복잡한 로직을 작성하고 `스키마`에 주석을 달기만 하면 해당 기능을 추가할 수 있다는 거죠. 드라이버 연결 생성에 대해 걱정할 필요도 없어요. GraphQL 요청에서 생성된 단일 생성 데이터베이스 `쿼리`와 계속 작동하니까요. 하위 `쿼리`로 연결되므로 주소 지정, 데이터 계층으로 여러 번 왕복하지 않고 데이터베이스가 `쿼리`를 최적화하도록 하는 것의 성능 이점을 계속 활용할 수 있어요.
프론트엔드에서 그래프로 작업하는 방법: Next.js
이제 GraphQL API가 있고 타입 정의가 정의되었고, Neo4j GraphQL 라이브러리를 사용하고 있고, 클라이언트에서 GraphQL 요청을 작성해서 애플리케이션에서 렌더링하려는 데이터를 정확하게 가져올 수 있어요. 다음 단계는 프론트 엔드에서 그래프 데이터와 GraphQL을 사용해서 작업하는 방법에 대해 생각하는 거예요.
저는 Next.js를 사용하는 걸 좋아해요. React를 기반으로 구축된 프레임워크죠. SEO에 매우 유용한 서버 측 렌더링이나 파일 기반 라우팅과 같은 일부 기능을 추가하는 메타 프레임워크라고도 해요. 새로운 JavaScript 파일이나 구성 요소를 생성하고 성능을 위해 이미지 압축 및 코드 분할을 처리하기 위한 경로를 자동으로 확보할 수 있어요.
특히 우리와 관련된 기능은 서버 측 API 경로인데요. Next.js를 사용하면 그래프 시각화가 될 프런트엔드 React 코드를 만들 수 있어요. GraphQL 엔드포인트를 API 경로로 구축하고 배포할 수도 있고요. 이는 서버리스 기능으로 배포되죠. 이제 하나의 프레임워크를 사용하는 하나의 코드베이스에 프런트엔드와 백엔드 코드가 모두 있는 거예요.
아폴로 클라이언트
React 애플리케이션으로서 우리는 일반적으로 아폴로 클라이언트 GraphQL 데이터로 작업해요.
여기서는 Apollo Client 인스턴스를 생성한 다음 이를 React 컴포넌트 계층 구조에 주입해요. 애플리케이션의 모든 React 컴포넌트는 React의 훅에 액세스할 수 있어서 GraphQL `쿼리`를 작성할 수 있죠. 그러면 Apollo Client가 데이터 가져오기를 처리하는데요. 동일한 데이터를 요청하는 경우 Apollo Client는 API 계층으로 이동하는 대신 로컬에 캐시할 수 있어요. Apollo Client는 또한 이 데이터를 React 컴포넌트의 상태 데이터로 관리한답니다.
우리가 해야 할 일은 애플리케이션을 처음 로드할 때 가져오려는 모든 데이터를 정의하는 GraphQL `쿼리`를 작성하는 거예요. 이 경우에는 점수별로 정렬된 기사가 될 텐데, 현재 시점에서 가장 높은 기사를 제공하겠죠. 또한 사용자 상호 작용을 처리해서 해당 주제 중 하나를 클릭하면 API로 돌아가 해당 특정 태그에 연결된 더 많은 기사를 가져올 수 있기를 원해요.
React Force Graph를 사용한 그래프 데이터 시각화
이제 프론트 엔드에 데이터가 있고 그래프 시각화를 구축하려고 해요.
대부분의 그래프 시각화의 중요한 특징은 강제 지향 레이아웃이라는 아이디어인데요. 이는 시각화의 `노드`가 서로 밀어내는 반발 자성을 가지며 `관계`가 스프링 역할을 하여 `노드`를 끌어당기는 물리 시뮬레이션이 브라우저에서 진행되고 있음을 의미해요.
이 물리 시뮬레이션을 실행하고 시각화가 안정화되면 특정 `노드`가 다른 `노드`에 연결되는 위치와 그래프에서 `노드` 그룹이 존재하는 위치를 해석할 수 있는 클러스터와 커뮤니티가 형성되는 위치를 확인할 수 있죠. 기본적으로 거의 모든 `노드` 차트 시각화에서 강제 방향 레이아웃에 대한 아이디어를 볼 수 있어요. 물론 사용할 수 있는 다른 레이아웃 알고리즘이 있지만 Neo4j Bloom 및 Neo4j Browser에서 볼 수 있듯이 강제 지정이 매우 일반적이랍니다.
우리는 React를 사용하고 있으므로 다음과 같은 React 라이브러리를 사용해 볼게요. React Force Graph. 이는 Force Graph라는 라이브러리 위에 구축되었어요. 3D 그래프 구현을 구축할 수 있는 3D 버전도 있는데, 이는 본질적으로 React Force Graph에 대한 React 바인딩이에요.
이 경우 GraphQL `쿼리`는 JSON JavaScript의 객체로 다시 제공되므로 이를 React Force Graph 라이브러리에 쉽게 전달할 수 있어요. `노드` 대신 텍스트를 시각화하고 싶기 때문에 약간의 구성을 수행해야 하지만 그래프 시각화를 구축하기 위해 몇 가지 사소한 구성 외에 수행해야 할 작업은 많지 않아요.
이제 프론트 엔드에 그래프 시각화가 있고 Neo4j에서 데이터를 가져오는 GraphQL API를 통해 데이터를 가져오고 있어요. 이 데이터는 GitHub 작업을 사용하여 지속적으로 업데이트되고 있답니다.
Vercel을 사용한 배포
이제 프런트엔드 React 앱과 GraphQL을 모두 사용하여 애플리케이션을 배포할 차례인데요. 바로 Vercel을 사용해 볼 거예요. Vercel은 개발자에게 최적화된 배포 플랫폼이죠. Vercel에서는 Lobsters Graph용 GitHub 저장소를 연결할 수 있어요.
제 GraphQL API가 Vercel에 의해 서버리스 기능으로 배포될 예정이고 Neo4j Aura 인스턴스에 연결할 수 있어야 하기 때문에 환경 변수와 Neo4j Aura 인스턴스에 대한 연결 자격 증명을 입력하여 약간의 구성을 수행해야 해요.
GitHub 저장소를 처음 연결할 때 Vercel은 애플리케이션을 빌드한 다음 정적 React 코드를 Vercel CDN에 배포한답니다.
기본적으로 두 개의 도메인이 제공되는데요. 위에 보이는 것처럼 사용자 지정 도메인을 추가해서 특정 배포 미리보기 URL을 얻을 수도 있어요. Pull Request가 있거나 GitHub에 새로운 코드를 Push할 때마다 Vercel은 이 GitHub 저장소에 업데이트가 있다는 알림을 받게 돼요.
Vercel은 앱을 빌드하고 특정 미리보기 URL을 만들어 팀원들이나 클라이언트와 공유할 수 있게 해주죠. 이 미리보기 빌드를 사용하면 라이브 애플리케이션에 배포된 것과 똑같이 애플리케이션과 상호 작용할 수 있지만, 프로덕션 도메인으로 꼭 승격할 필요는 없어요. 팀에서 확인하고 검토한 후에 해당 Pull Request를 병합할 준비가 되면 앱의 프로덕션 URL로 승격되는 거죠. Vercel은 미리보기 빌드 아이디어를 관리하고 팀과 공유할 미리보기 URL을 제공하는 데 정말 유용한 것 같아요.
이제 앱이 활성화되었어요! 최신 Lobsters 뉴스와 함께 그래프 시각화를 볼 수 있을 뿐만 아니라, /API/GraphQL에서 GraphQL API에도 접근할 수 있어요. React 앱은 CDN에 배포되었고, GraphQL API는 Vercel에 의해 서버리스 기능으로 배포되었답니다. Next.js의 API 경로 기능을 활용하기만 하면 돼요.
애플리케이션 구축 방법
방금 구축한 애플리케이션의 아키텍처를 다시 한번 살펴볼까요? GitHub Actions를 사용해서 백그라운드에서 크론 작업을 설정해서 Lobsters JSON 엔드포인트에서 지속적으로 데이터를 가져왔어요. 그리고 Cypher를 사용해서 해당 데이터를 Neo4j Aura 인스턴스에 로드하고 GraphQL API를 구축했죠.
Neo4j GraphQL 라이브러리를 사용해서 애플리케이션 데이터를 프론트엔드 애플리케이션에 노출했어요. 프론트엔드 애플리케이션은 그래프 시각화를 생성하기 위해 반응형 그래프 컴포넌트를 사용하는 React 앱이고요. 관련된 모든 코드는 GitHub에서 확인할 수 있어요. . 더 자세한 내용이 궁금하신 분들을 위해 3부작 블로그 튜토리얼 시리즈도 준비했어요. 오늘 이야기한 다양한 단계를 좀 더 자세히 살펴볼 수 있도록 말이죠. 이 링크도 참고해주세요!
이 애플리케이션을 Neo4j 라이브 스트림에서 만들었는데, 여기서는 Neo4j의 많은 사람들과 커뮤니티의 다른 분들이 애플리케이션을 구축하고, 데이터로 작업하고, 그래프 데이터 과학을 수행하는 방법을 보여준답니다. 라이브 코딩을 좋아하신다면 라이브 스트림이 딱일 거예요. 질문도 하고, 관심 있는 부분에 대해 더 깊이 파고들 수도 있으니까요. 녹화된 영상은 Neo4j 유튜브 채널이나 Neo4j 트위치 채널에서 찾아볼 수 있어요.
리소스
흥미로운 자료 몇 가지를 더 소개해 드릴게요. 먼저 Neo4j AuraDB 무료 버전이 있어요. Neo4j Aura는 무료 등급을 제공해서 "무료"라고 부르는데요, 취미 프로젝트나 개발에 사용할 수 있도록 아주 쉽게 시작할 수 있는 Neo4j AuraDB 인스턴스를 만들 수 있답니다. GitHub Actions, Vercel, 그리고 Neo4j AuraDB 모두 무료 버전을 제공한다는 점도 기억해두면 좋을 것 같아요. 신용카드 정보 없이도 이 앱을 구축하는 데 필요한 모든 서비스를 무료로 이용할 수 있다는 거죠. 물론, 실제 서비스를 배포하고 확장할 준비가 되면 각 서비스의 유료 플랜을 이용할 수도 있고요.
더 자세한 정보가 필요하신 분들을 위해 Neo4j GraphQL 라이브러리 랜딩 페이지를 방문해 보세요. 다양한 기능에 대한 정보와 문서, 예제 링크를 찾아볼 수 있을 거예요. Neo4j의 GraphAcademy에는 Neo4j GraphQL 라이브러리를 사용해서 GraphQL API를 구축하는 방법을 자세히 알려주는 교육 과정도 준비되어 있답니다. Neo4j GraphQL 팀은 유럽에서 소프트웨어 엔지니어를 채용하고 있다고 해요. 채용 공고는 에서 확인하거나, GraphQL@neo4j.com으로 직접 문의하셔도 돼요. 궁금한 점이 있다면 언제든지 연락 주세요! 이 튜토리얼이 여러분께 도움이 되었기를 바라며, 유용한 자료들을 잘 활용하시길 응원할게요!
Bloom
Cypher
풀스택 GraphQL
GraphQL
GraphQL API
Neo4j GraphQL 라이브러리
Vercel
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.