

Neo4j GraphRAG Python 패키지에 대한 이전 포스팅에서는 패키지에서 제공하는 고급 검색기를 사용해서 단순한 벡터 검색을 넘어 GraphRAG 애플리케이션을 향상시키는 방법을 보여드렸어요. 벡터 검색에 그래프 순회 단계를 추가하면 벡터 검색만으로는 얻을 수 없는 귀중한 정보를 검색할 수 있다는 것을 설명했죠. 또한 전체 텍스트 검색과 벡터 검색을 결합하면 벡터 검색만으로는 놓칠 수 있는 Neo4j 데이터베이스의 데이터에 쿼리를 매칭할 수 있다는 것도 보여드렸어요. 이번 포스팅에서는 하이브리드 검색과 그래프 순회 기술을 결합해서 GraphRAG 애플리케이션의 검색 성능을 크게 향상시키는 HybridCypherRetriever를 살펴볼게요.
설정
먼저 GraphRAG Python 패키지, Neo4j Python 드라이버, OpenAI Python 패키지가 설치되어 있는지 확인해야 해요.
pip install neo4j neo4j-graphrag openai이전 포스팅에서 사용했던 것과 동일한 사전 구성된 Neo4j 데모 데이터베이스를 사용할 거예요.
- GraphRAG Python 패키지
- GraphRAG Python 패키지를 사용하여 그래프 탐색으로 벡터 검색 강화
- Python용 GraphRAG Python 패키지를 사용하는 GraphRAG 애플리케이션에 대한 하이브리드 검색
이 데이터베이스는 영화 추천 Knowledge Graph를 시뮬레이션하고 있어요. 데이터베이스에 대한 자세한 내용은 첫 번째 블로그의 설정 섹션을 참고해주세요: Neo4j GraphRAG Python 패키지 시작하기.
웹 브라우저를 통해 데이터베이스에 접속할 수 있어요. 에서 사용자 이름과 비밀번호로 "recommendations"를 사용하면 돼요. 다음 코드 조각을 사용해서 애플리케이션에서 데이터베이스에 연결해 보세요.
from neo4j import GraphDatabase
# Demo database credentials
URI = "neo4j+s://demo.neo4jlabs.com"
AUTH = ("recommendations", "recommendations")
# Connect to Neo4j database
driver = GraphDatabase.driver(URI, auth=AUTH)OpenAI API 키도 설정해야 해요.
import os
os.environ["OPENAI_API_KEY"] = "sk-…"하이브리드 검색 및 그래프 순회
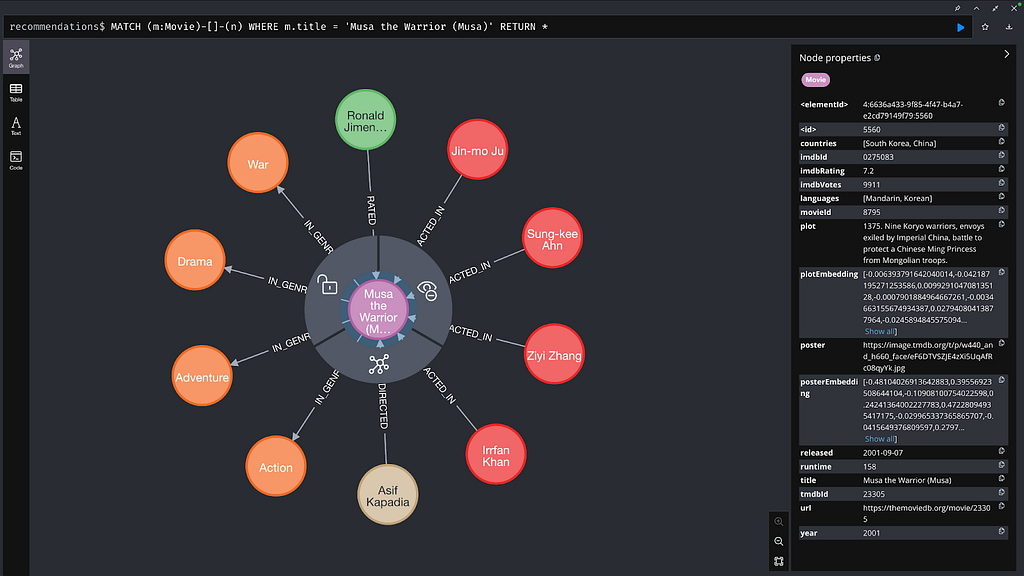
영화 '무사 무사'의 Node와 이에 직접 연결된 Node에요. 영화 자체에는 배우에 대한 정보가 포함되어 있지 않고, 배우 Node에 저장되어 있죠.
GraphRAG Python 패키지 시작하기에서는 Vector Index를 사용해서 영화 줄거리를 쿼리하는 방법을 보여드렸어요. 덕분에 Neo4j 데이터베이스에서 영화 Node를 검색해서 LLM이 사용자 쿼리에 응답할 수 있는 컨텍스트를 제공할 수 있었죠. 하지만 아쉽게도 영화 Node에는 각 영화에 출연한 배우 같은 세부 정보가 부족했어요. 그래서 다음과 같은 질문에는 답할 수 없었죠. “마법의 정글 보드 게임을 다룬 영화에 출연한 배우는 누구였나요?”
다행히 두 번째 블로그 GraphRAG Python 패키지를 사용하여 그래프 탐색으로 벡터 검색 강화에서는 Cypher 쿼리를 사용해서 초기 영화 Node에 연결된 추가 Node를 검색할 수 있는 VectorCypher 검색기에 대해 이야기했어요. 이 접근 방식을 통해 각 영화 Node에 연결된 배우 Node를 검색하고 반환할 수 있어서 특정 배우에 대한 질문에 답할 수 있게 되었죠.
세 번째 블로그 Neo4j GraphRAG Python 패키지를 사용하는 GraphRAG 애플리케이션에 대한 하이브리드 검색에서는 사용자 쿼리가 정확한 단어나 구문에 의존하는 경우, 특히 정확한 날짜가 필요한 경우 Vector Search의 한계에 대해 논의했어요. 이 문제를 해결하기 위해 Vector Search의 기본인 Semantic Search보다는 어휘적 유사성(즉, 정확한 단어)을 기반으로 텍스트를 일치시키는 전체 텍스트 검색을 검색 프로세스에 통합했죠. Vector Search와 전체 텍스트 검색의 결과를 결합하는 하이브리드 리트리버가 다음과 같은 쿼리에 대해 올바른 영화 Node를 찾고 반환할 수 있는 방법을 보여드렸어요. "1375년 중국 제국을 배경으로 한 영화 이름이 뭐예요?"
그런데 이런 접근 방식을 결합하고 싶다면 어떻게 해야 할까요? 하이브리드 검색과 그래프 순회를 함께 사용하면 두 가지 방법 중 하나만 처리할 수 있는 것보다 훨씬 더 복잡한 질문에 답할 수 있어요. 예를 들어 "1375년 중국 제국을 배경으로 한 영화에 나오는 배우들의 이름은 무엇인가요?" 같은 질문에요!
Vector Cypher 및 하이브리드 리트리버의 한계
시작하기 전에 VectorCypherRetriever와 HybridRetriever가 이 질문을 어떻게 처리하는지 살펴보고 새로운 검색기를 사용해야 하는지 한번 살펴볼까요?
먼저 VectorCypherRetriever부터 볼게요:
from neo4j_graphrag.embeddings.openai import OpenAIEmbeddings
from neo4j_graphrag.retrievers import VectorCypherRetriever
embedder = OpenAIEmbeddings(model="text-embedding-ada-002")
retrieval_query = """
MATCH
(actor:Actor)-[:ACTED_IN]->(node)
RETURN
node.title AS movie_title,
node.plot AS movie_plot,
collect(actor.name) AS actors;
"""
retriever = VectorCypherRetriever(
driver,
index_name="moviePlotsEmbedding",
embedder=embedder,
retrieval_query=retrieval_query,
)
query_text = "What are the names of the actors in the movie set in 1375 in Imperial China?"
retriever_result = retriever.search(query_text=query_text, top_k=3)
print(retriever_result)그러면 다음과 같은 결과가 반환돼요.
items = [
RetrieverResultItem(
content="",
메타데이터=None,
),
RetrieverResultItem(
content="",
메타데이터=None,
),
RetrieverResultItem(
content="",
메타데이터=None,
),
]
메타데이터 = {"__retriever": "VectorCypherRetriever"}불행히도 이 검색기는 올바른 영화("전사 무사")를 반환하지 않네요. 하지만 여기서는 full-text index를 사용하는 게 도움이 될 수 있어요. 영화 설명에 언급된 날짜(1375)를 정확하게 일치시킬 수 있으니까요.
이 검색기에 대한 자세한 설명과 위의 코드 조각에 대한 연습은 다음 링크를 참고해주세요: GraphRAG Python 패키지를 사용하여 그래프 탐색으로 Vector Search 강화.
이제 HybridRetriever를 사용해 볼까요?
from neo4j_graphrag.embeddings.openai import OpenAIEmbeddings
from neo4j_graphrag.retrievers import HybridRetriever
embedder = OpenAIEmbeddings(model="text-embedding-ada-002")
retriever = HybridRetriever(
driver=driver,
vector_index_name="moviePlotsEmbedding",
fulltext_index_name="movieFulltext",
embedder=embedder,
return_properties=["title", "plot"],
)
query_text = "What are the names of the actors in the movie set in 1375 in Imperial China?"
retriever_result = retriever.search(query_text=query_text, top_k=3)
print(retriever_result)그러면 다음과 같은 결과가 반환될 거예요.
items = [
RetrieverResultItem(
content="{'title': 'Musa the Warrior (Musa)', 'plot': '1375. Nine Koryo warriors, envoys exiled by Imperial China, battle to protect a Chinese Ming Princess from Mongolian troops.'}",
metadata={"score": 1.0},
),
RetrieverResultItem(
content="{'title': 'Once Upon a Time in China (Wong Fei Hung)', 'plot': "Set in late 19th century Canton this martial arts film depicts the stance taken by the legendary martial arts hero Wong Fei-Hung (1847-1924) against foreign forces' (English, French and ..."}",
metadata={"score": 1.0},
),
RetrieverResultItem(
content="{'title': 'Once Upon a Time in China III (Wong Fei-hung tsi sam: Siwong tsangba)', 'plot': "Master Wong and his disciples enroll in the 'Dancing Lion Competition' to stop an assassination plot and to battle an arrogant, deceitful opponent."}",
metadata={"score": 0.9975943434767434},
),
]
metadata = {"__retriever": "HybridRetriever"}이 검색기를 사용하면 올바른 영화("전사 무사")를 찾아내긴 하지만, 배우 정보를 반환하지는 않아요. 배우 정보는 별도의 `Actor` node에 저장되어 있고, 영화 node와 함께 이 node들을 검색하려면 추가적인 그래프 순회 과정이 필요하기 때문이죠.
이 검색기에 대한 자세한 설명과 위의 코드 조각에 대한 연습은 다음 링크를 참고해주세요: Python용 GraphRAG Python 패키지를 사용하는 GraphRAG 애플리케이션에 대한 하이브리드 검색.
HybridCypherRetriever
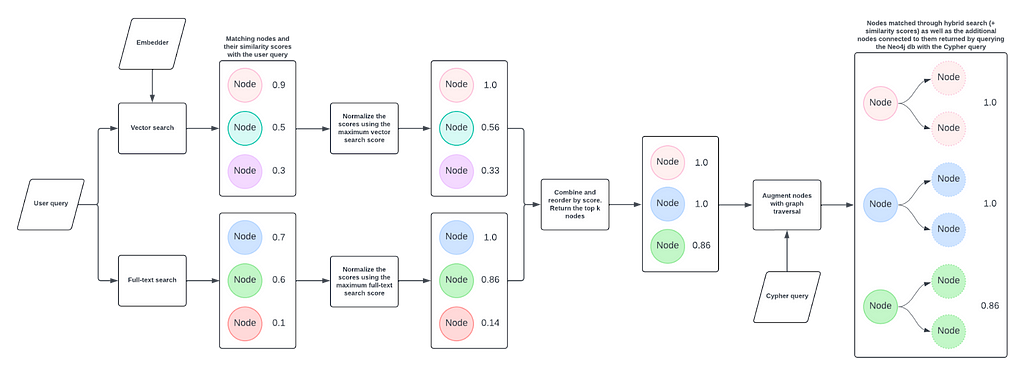
하이브리드 Cypher 검색 프로세스
HybridCypherRetriever는 그래프 순회 단계를 추가해서 하이브리드 검색 프로세스를 더 향상시켜요. Vector Search와 결합된 검색을 통해 초기 node 세트를 식별하는 것으로 시작해서, full-text index를 사용하고, 지정된 Cypher query를 사용해서 각 node에 대한 그래프에서 추가 정보를 검색하는 방식이죠.
이 검색기를 사용하려면 먼저 하이브리드 검색을 통해 검색된 각 node와 함께 가져올 추가 정보를 정확하게 지정하는 Cypher query를 작성해야 해요. 영화 속 배우에 대한 질문에 대답하고 싶다면, 다음과 같은 query를 사용할 수 있겠죠.
retrieval_query = """
MATCH
(actor:Actor)-[:ACTED_IN]->(node)
RETURN
node.title AS movie_title,
node.plot AS movie_plot,
collect(actor.name) AS actors;
"""그런 다음 검색하려는 Vector Search 이름 및 full-text index와 함께 이 query를 HybridCypherRetriever에 전달해요. 이 시리즈의 이전 블로그와 마찬가지로 영화 줄거리를 검색하고 `moviePlotsEmbedding` Vector index와 `movieFulltext` full-text index를 사용할 거예요.
마지막으로, embedding model도 검색자에게 전달해야 해요. 데모 데이터베이스의 영화 plot embedding은 원래 이걸 사용해서 생성되었기 때문에 `text-embedding-ada-002` model을 사용할게요.
from neo4j import GraphDatabase
from neo4j_graphrag.embeddings.openai import OpenAIEmbeddings
from neo4j_graphrag.retrievers import HybridCypherRetriever
driver = GraphDatabase.driver(URI, auth=AUTH)
embedder = OpenAIEmbeddings(model="text-embedding-ada-002")
retriever = HybridCypherRetriever(
driver=driver,
vector_index_name="moviePlotsEmbedding",
fulltext_index_name="movieFulltext",
retrieval_query=retrieval_query,
embedder=embedder,
)
query_text = "What are the names of the actors in the movie set in 1375 in Imperial China?"
retriever_result = retriever.search(query_text=query_text, top_k=3)
print(retriever_result)이 검색기를 사용해서 데이터베이스를 쿼리하면 배우와 함께 올바른 영화(전사 무사)가 반환되는 것을 확인할 수 있어요.
items = [
RetrieverResultItem(
content="",
메타데이터=없음,
),
검색자결과항목(
내용="",
메타데이터=없음,
),
검색자결과항목(
내용="",
메타데이터=없음,
),
]
메타데이터 = {"__retriever": "HybridCypherRetriever"}쿼리에 대한 정답은 다음과 같아요.
The names of the actors in the movie set in 1375 in Imperial China,
"Musa the Warrior (Musa)," are Irrfan Khan, Ziyi Zhang, Sung-kee Ahn, and Jin-mo Ju.요약
이번 블로그에서는 GraphRAG 애플리케이션에서 GraphRAG Python 패키지의 고급 HybridCypherRetriever를 사용하는 방법을 보여드렸어요. 하이브리드 검색과 그래프 순회를 통한 벡터 검색의 한계를 개별적으로 강조하고, 이러한 기술을 결합해서 어떻게 더 복잡하고 미묘한 질문에 답할 수 있는지 보여주었죠.
패키지 코드는 오픈 소스이며 다음 에서 찾을 수 있어요. 언제든지 이슈를 올려주세요!
GitHub – neo4j/neo4j-graphrag-python: Python용 Neo4j GraphRAG
- GraphRAG
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'GraphRAG' 카테고리의 다른 글
| Databricks에서 Neo4j GraphRAG로 임팩트 있는 인사이트 찾기 (0) | 2026.04.29 |
|---|---|
| 그래프 신경망으로 Word Embedding 성능 끌어올리기 (1) | 2026.04.29 |
| Neo4j에서 임베딩으로 문자열 편집 거리 표현하기 (0) | 2026.04.28 |
| Text2CypherRetriever로 Neo4j GraphRAG, 쉽게 시작하기 (0) | 2026.04.28 |
| BigQuery 데이터에서 Neo4j GraphRAG으로 풍부하고 강력한 인사이트 발견하기 (0) | 2026.04.28 |