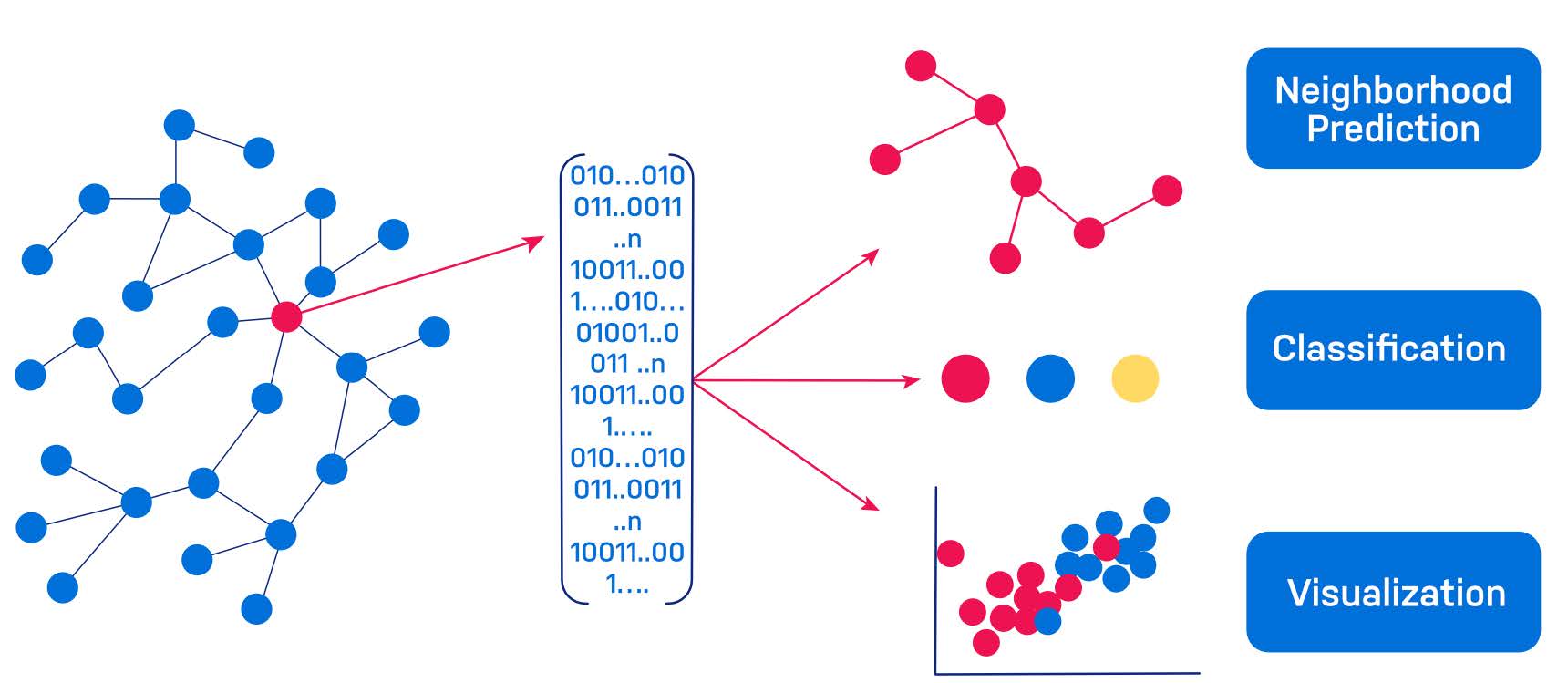
편집자 주: 이 프레젠테이션은 다음에서 제공되었습니다.실파 카케라 at 연결: 그래프를 통한 혁신 가속화.
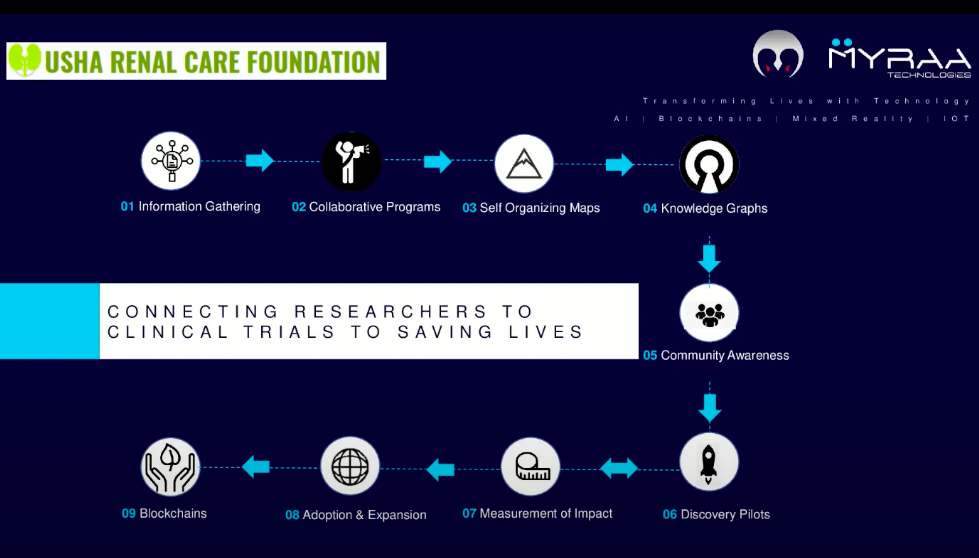
Usha Renal Care Foundation에서는 의료 데이터에 대한 풍부한 지식 저장소를 갖기 위해 자체 구성 맵에 넣을 정보를 수집하고 있다고 해요. 이 계획은 단계적으로 진행될 예정이고, 현재는 초기 단계에 있죠.
핵심 문제: 조각난 데이터
우리가 주목하는 핵심적인 문제는 의료 산업 데이터가 파편화되어 있다는 점이에요. 정보가 이렇게 흩어져 있으면 새로운 임상시험 기회를 찾기가 정말 어렵고, 환자분들이 고통을 겪게 되죠. 이 이니셔티브는 바로 이 점을 연결해서 긍정적인 영향을 주고, 환자분들에게 최고의 의료 서비스를 제공하는 데 목적이 있어요.
NephroBlocks 소개
저희는 데이터를 NephroBlocks와 연결했어요. 'Nephro'는 *신장학(Nephrology)*에서, 'Blocks'는 *블록체인(Blockchain)* 데이터에서 따왔어요. 신장학 데이터에 대한 Knowledge Graph를 만들고, 환자와 의료 기관에서 활용할 수 있도록 하는 거죠. 의료 전문가분들과 이야기를 나눠보면, 가장 큰 어려움 중 하나가 기술이 한 곳에서 다른 곳으로 이전되는 과정이라고 해요. 첨단 기술이 특정 위치에 있더라도, 규정 준수나 인식 문제 때문에 다른 곳에 적용되기까지 시간이 오래 걸릴 수 있다는 거죠. 그래서 NephroBlocks는 모든 사람이 동일한 플랫폼에서 현재 진행 중인 임상 시험과 성공률을 확인할 수 있도록 돕고 있어요.
안타깝게도 임상 시험은 매우 구체적인 모집 기준과 환자 프로필을 요구하기 때문에, 환자분들은 어떤 시험에 참여할 수 있는지 알기 어려워요. 게다가 일부 환자분들은 적절한 신장 전문의 네트워크에 속해 있지 않아서, 임상 시험에 대한 정보를 아예 접하지 못하는 경우도 있죠. 저희는 바로 이 정보 공유 문제를 해결하려고 노력하고 있어요.
NephroBlocks를 만든 이유
Neo4j의 그래프 플랫폼은 데이터 간의 연관성을 찾는 데 정말 유용해요. 덕분에 적절한 임상 시험에 맞는 환자 프로필을 제때 매칭할 수 있게 되었죠. 임상 연구자분들도 서로 협력해서 임상시험 프로필에 맞는 사례를 찾을 수 있고요. 이건 모두에게 좋은 일(win-win)이라고 생각해요.
우선 우샤신장관리재단을 설립하게 된 계기부터 말씀드리고 싶어요. 이 일을 하는 이유는 개인적인 경험과 깊이 관련되어 있어요. 이 이니셔티브는 어머니의 정신과 11년간의 신부전 투병에 대한 헌사로, 어머니의 이름을 따서 만들어졌어요. 어머니는 예상보다 훨씬 오래 생존하셨는데, 그건 기술 덕분이었죠. 저는 그 점이 정말 자랑스럽고, 기술자로서 이 계획을 위해 매일 노력하는 원동력이 되었어요. 어머니는 기술의 도움을 받아 저에게 당연한 어린 시절을 선물해주신 환자였어요.
저는 세상 모든 사람들이 그런 기회를 누릴 자격이 있다고 믿어요. 그래서 생명을 구할 수 있는 기술이 무엇인지 적극적으로 알리고 있는 거죠. Google에서 원하는 정보를 검색할 수 있지만, 모든 정보를 활용할 수 있는 건 아니잖아요. 어머니께서 투병하시던 마지막 단계에는 대부분의 의사들이 해결책이 없다고 말하는 신경병증 문제가 있었어요.
하지만 기술자인 저는 그걸 받아들일 수 없었어요. 분명 다른 방법이 있을 거라고 생각했죠. 어딘가에서 연구나 임상 시험이 진행 중일 수도 있잖아요. 해결책을 찾을 수 없다는 절망감이 NephroBlocks를 만들게 된 계기가 되었어요. 저희는 신장 치료부터 시작했지만, 이 계획은 확장 가능하고 다른 분야에서도 더 큰 성공을 거둘 수 있을 거라고 믿어요.
더 나은 환자 발견을 위한 임상시험과 연구의 연결
제 개인적인 여정과 동기를 말씀드렸으니, 이제 Graph Database를 어떻게 구현했고 앞으로 어떻게 발전시켜나갈지 공유할게요.
온라인에서 연구 논문을 읽고 신경병증에 대한 임상 시험을 검색하는 건 정말 수작업에 가까워요. 모든 사람이 삶의 중요한 순간마다 그렇게 할 수는 없죠. 그래서 이 플랫폼을 구축하면 사람들이 데이터를 더 쉽게 찾고, 연구 논문에서 임상 시험, 환자 프로필까지 한 번에 연결할 수 있게 되는 거예요.
현재 저희는 데이터베이스에 신장 치료와 관련된 5만 건 이상의 임상 시험 데이터를 가지고 있어요. 스크립트를 사용해서 지속적으로 데이터베이스를 업데이트하고, 다양한 신장 관련 연구를 후원하는 기관들과 협력하고 있기도 하고요.
연구에서 공통적인 사건이 발견되면 데이터베이스의 관계 강도가 높아져요. 데이터가 풍부해지면 Semantic Search 단계가 시작되는 거죠.
그래프 Discovery Engine
이제 기술과 Discovery Engine이 어떻게 작동하는지 좀 더 자세히 살펴볼까요? Discovery Engine은 더 나은 Query를 도출하는 데 도움을 줘요. 예를 들어, 10~25세 범위의 당뇨병 환자이면서 만성 신장 질환을 앓고 있는 환자 프로필을 가져올 수 있죠. 그리고 당시 이용 가능한 임상 시험을 기반으로 이들을 재편성하는 거예요. 지금은 신장 전문의분들이 이 데이터를 먼저 사용하는 데 집중하고 있지만, 시스템이 더 발전하면 환자분들에게도 큰 희망을 줄 수 있을 거라고 생각해요. 환자분들이 생존할 기회가 있다는 희망을 가질 수 있다고 상상해보세요!
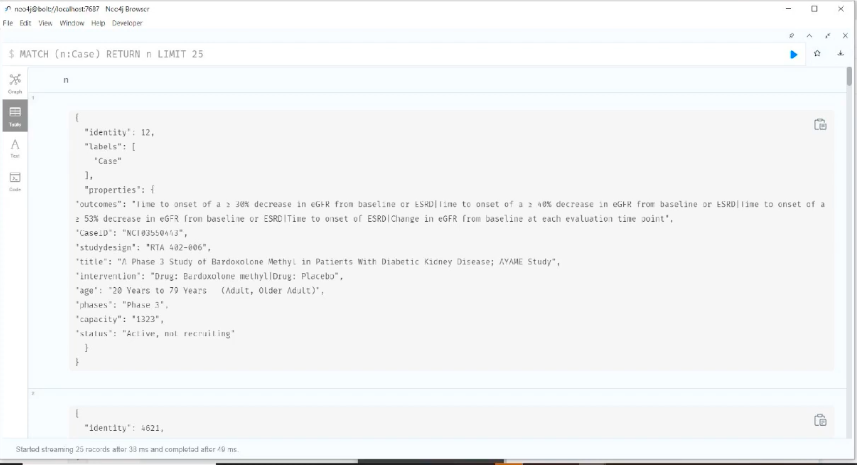
데이터베이스에서 가장 먼저 보여드리고 싶은 건 임상시험 사례에 대한 데이터예요.
임상 시험의 용량을 보여주는 곳에서 이런 질문들을 할 수 있겠죠. "임상 시험이 활성화되어 있나요?", "지금 모집 중인가요?", "요구 사항은 무엇인가요?", "연령대는 어떻게 되나요?", "어떤 단계에 있나요?" 같은 질문들이요.
다음은 우리가 채운 사례들이에요.
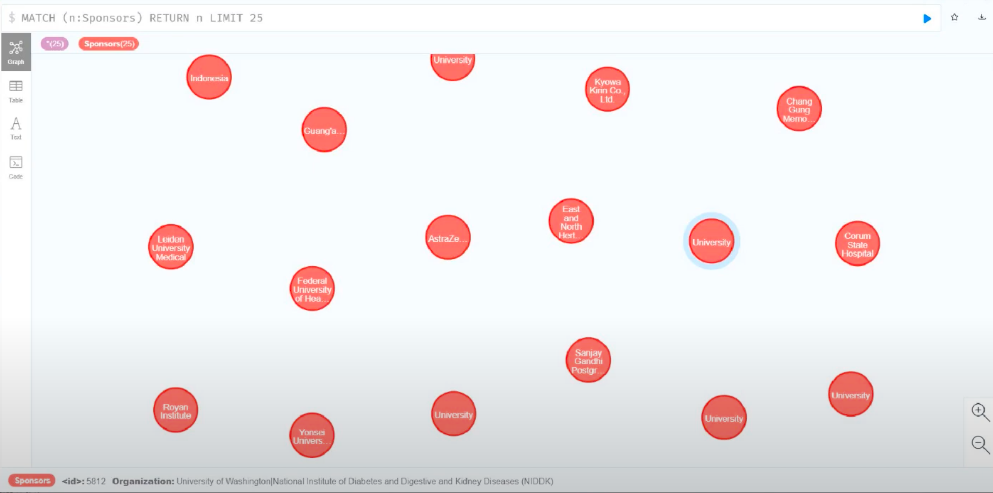
그리고 스폰서 정보도 있네요.
조직과 위치를 기반으로 협회, 후원자, 그리고 그들이 사용하는 자금 유형을 식별할 수 있어요. 이는 환자뿐만 아니라 연구자가 자신의 연구에 어떤 기관이 도움을 줄 수 있는지 식별하는 데도 도움이 되죠.
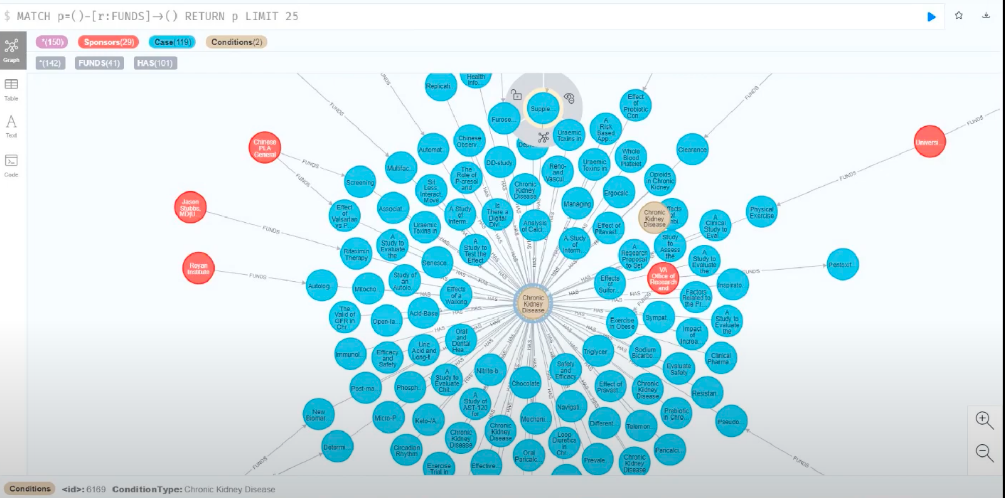
저장소에 조건을 저장하기도 해요. 예를 들어 만성 신장 질환을 동반한 제2형 당뇨병 같은 조건이죠. 이와 동일한 세부 사항을 가진 것들이 많이 있어요. 따라서 관계의 첫 번째 유형은 후원자와 우리가 채택한 조건의 유형이 되는 거죠.
환자 입장에서 이런 옵션들이 있다는 건 정말 흥미로운 일이죠! 조건과 스폰서 정보가 파란색으로 표시된 임상 시험을 보면, 현재 진행 중인 계획이라는 걸 한눈에 알 수 있어요.
블록체인: 우리 여정의 다음 단계
Neo4j 저장소의 다음 단계는 기부, 기부자, 그리고 기부자들의 분산 네트워크를 가능하게 하는 블록체인을 도입하는 거예요. 입원 환자뿐만 아니라, 이런 종류의 연구에 접근하고 싶어 하는 모든 사람들을 위해 투명한 모듈 형태로 제공하고 싶어요.
결론
저는 여러분이 강력하게 믿는 일을 받아들이시길 권장해요. NephroBlocks를 통해 우리는 모든 정보를 분산 원장에 저장해서, Graph Database와 통합 저장소에 대해 가능한 한 많은 사람들에게 알리기 위해 최선을 다하고 있답니다.
두 가지 미래 지향적인 기술 개념인 Graph Database와 블록체인을 결합하면 헬스케어 산업에서 정말 훌륭한 생태계를 만들 수 있어요. 우리는 세상을 더욱 안전하게 만들기 위해 노력하고 있고, 이 커뮤니티에 함께 가치를 구축하고 더할 수 있기를 기대해요. 저희가 하는 일을 확인해 보시고, 궁금한 점이 있다면 언제든지 문의해주세요! 혁신을 만들어 나가요!
7월 Connections에 등록하고 전문가들이 그래프를 사용하여 실제 문제를 해결하는 방법을 알아보세요.
우샤 신장 케어 파운데이션
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
LangChain 및 Neo4j를 사용하는 고급 그래프 기반 메타데이터 기술로 Vector Search를 최적화합니다.
In Retrieval-Augmented Generation(RAG) 애플리케이션, 텍스트 임베딩 및 Vector Search는 문서의 의미와 서로 얼마나 유사한지를 이해하여 문서를 찾는 데 도움이 돼요. 하지만 날짜나 카테고리와 같은 특정 기준에 따라 정보를 정렬할 때는 텍스트 임베딩이 효과적이지 않죠. 예를 들어, 특정 연도에 생성된 모든 문서를 찾거나 "공상 과학"과 같은 특정 카테고리에 태그가 지정된 문서를 찾아야 하는 경우에요.
메타데이터 필터링, 즉 필터링된 Vector Search가 중요한 역할을 하는 곳이죠! 구조화된 필터를 효과적으로 처리해서 사용자가 특정 속성에 따라 검색 결과를 좁힐 수 있거든요.
메타데이터 필터링에서는 먼저 관련 문서의 범위를 좁힌 다음 좁은 집합에 Vector Search를 적용하는 사전 필터링 접근 방식을 사용합니다. 작성자의 이미지입니다.
제공된 이미지에서 프로세스는 사용자가 2021년에 새로운 정책이 구현되었는지 묻는 것으로 시작돼요. 그런 다음 메타데이터 필터를 사용하여 지정된 연도(이 경우 2021년)를 기준으로 더 큰 인덱스 문서 풀을 정렬하죠. 결과적으로 해당 연도의 문서 하위 집합만 필터링되는 거예요.
가장 관련성이 높은 문서를 더욱 정밀하게 조사하기 위해 이 하위 집합 내에서 Vector Search가 수행됩니다. 이 방법을 사용하면 시스템은 2021년의 문맥상 관련된 문서 풀 내에서 관심 주제와 밀접하게 관련된 문서를 찾을 수 있어요. 이 2단계 프로세스인 메타데이터 필터링과 Vector Search는 검색 결과의 정확성과 관련성을 높여준답니다.
최근에 소개한 메타데이터 필터링을 위한 LangChain 지원은 Neo4j에서 Node 속성을 기반으로 해요. 하지만 같은 Graph Database는 구조화되지 않은 데이터와 함께 매우 복잡하고 연결된 구조화된 데이터를 저장할 수 있다는 점! 다음 예를 한번 살펴볼까요?
구조화되지 않은 데이터와 고도로 연결된 데이터를 그래프로 표현한 모습이에요. 작성자 이미지입니다.
데이터 세트에서 구조화되지 않은 부분은 시각화의 오른쪽 상단에 있는 기사와 텍스트 덩어리를 나타내요. 텍스트 청크 `Node`에는 텍스트와 해당 텍스트 `Embedding` 값이 들어있고, 날짜, 감정, 작성자 같은 기사에 대한 추가 정보가 있는 기사 `Node`에 연결되죠.
그런데 기사는 기사에서 언급한 조직과 추가로 연결돼요. 이 예시에서는 기사에 Neo4j가 언급되어 있네요. 게다가 우리 데이터 세트에는 투자자, 이사회 구성원, 공급업체 등 Neo4j에 대한 구조화된 정보가 풍부하게 들어있답니다.
그래서 이 광범위한 구조화된 정보를 활용해서 정교한 메타데이터 필터링을 실행할 수 있고, 다음과 같은 구조화된 기준을 사용해서 문서 선택을 정확하게 세분화할 수 있어요.
Rod Johnson이 이사회 구성원으로 있는 회사 중에 새로운 재택근무 정책을 시행한 회사가 있나요?
Neo4j가 투자한 회사에 대한 부정적인 소식이 있나요?
현대자동차에 납품하는 기업의 공급망 문제와 관련해서 주목할 만한 소식이 있었나요?
이런 예시 질문들을 보면 구조화된 그래프 기반 메타데이터 필터를 사용해서 관련 문서 하위 집합의 범위를 얼마나 좁힐 수 있는지 알 수 있죠.
이번 블로그 포스팅에서는 OpenAI 함수 호출 에이전트와 함께 LangChain을 사용해서 그래프 기반 메타데이터 필터링을 구현하는 방법을 보여드릴게요. 코드는 에서 확인할 수 있어요.
의제
소위 `Graph Database`를 사용할 건데요, Neo4j가 호스팅하는 공개 데모 서버에서 사용할 수 있어요. 다음 자격 증명을 사용해서 액세스할 수 있습니다.
이 글을 쓰는 시점에는 Vector Index를 사전 필터링 접근 방식과 함께 사용할 수 없어요. Vector Index와 함께 사후 필터링만 적용할 수 있죠. 하지만 사후 필터링에 대한 논의는 이 글의 범위를 벗어나요. 철저한 벡터 유사성 검색과 결합된 사전 필터링 접근 방식에 집중할 거니까요.
전체 블로그 게시물은 Cypher 쿼리를 동적으로 생성하고 관련 정보를 검색하는 다음 `get_organization_news` 함수로 요약돼요. 명확하게 보여드리기 위해 코드를 여러 부분으로 나눠서 설명할게요.
def get_organization_news(
topic: Optional[str] = None,
organization: Optional[str] = None,
country: Optional[str] = None,
sentiment: Optional[str] = None,
) -> str:
# If there is no prefiltering, we can use vector index
if topic and not organization and not country and not sentiment:
return vector_index.similarity_search(topic)
# Uses parallel runtime where available
base_query = (
"CYPHER runtime = parallel parallelRuntimeSupport=all "
"MATCH (c:Chunk)<-[:HAS_CHUNK]-(a:Article) WHERE "
)
where_queries = []
params = {"k": 5} # Define the number of text chunks to retrieve
입력 매개변수를 정의하는 것부터 시작해 볼게요. 보시다시피 모두 선택적 문자열이에요. `topic` 매개변수는 문서 내에서 특정 정보를 찾는 데 사용되죠. 실제로는 `topic` 매개변수의 값을 임베딩해서 벡터 유사성 검색을 위한 입력으로 사용하는 거예요. 다른 세 가지 매개변수는 사전 필터링 접근 방식을 보여주는 데 사용되고요.
사전 필터링 매개변수가 모두 비어 있으면 기존 Vector Index를 사용해서 해당 문서를 찾을 수 있어요. 그렇지 않다면 사전 필터링된 메타데이터 접근 방식에 사용될 기본 Cypher 쿼리 준비를 시작하는 거죠. `CYPHER Runtime = Parallel ParallelRuntimeSupport=all` 절은 Neo4j Database에 병렬 런타임을 사용하도록 지시하는 부분이에요. 다음으로 `Chunk` node와 해당 `Article` node를 선택하는 `match` 구문을 준비하고요.
이제 Cypher 쿼리에 메타데이터 필터를 동적으로 추가할 준비가 됐어요. 먼저 `Organization` 필터부터 시작해 볼게요.
if organization:
# Map to database
candidates = get_candidates(organization)
if len(candidates) > 1: # Ask for follow up if too many options
return (
"Ask a follow up question which of the available organizations "
f"did the user mean. Available options: {candidates}"
)
where_queries.append(
"EXISTS {(a)-[:MENTIONS]->(:Organization {name: $organization})}"
)
params["organization"] = candidates[0]
LLM이 사용자가 관심을 갖는 특정 조직을 식별하는 경우, 먼저 `get_candidates` 함수를 사용하여 값을 데이터베이스에 매핑해야 해요. 내부적으로 `get_candidates` 함수는 전체 텍스트 인덱스를 활용한 키워드 검색으로 후보 `Node`를 찾죠. 여러 후보자가 발견되면 LLM에게 사용자에게 후속 질문을 해서 정확히 어떤 조직을 의미하는지 명확히 하도록 지시합니다.
그렇지 않으면 우리는 실존 하위 쿼리를 사용해서 특정 조직을 언급하는 기사를 필터 목록으로 필터링해요. Cypher 삽입을 방지하기 위해 쿼리를 연결하는 대신 쿼리 매개변수를 사용하고요.
다음으로, 사용자가 언급된 조직의 국가를 기반으로 텍스트 청크를 사전 필터링하려는 상황을 처리해볼게요.
if country:
# No need to disambiguate
where_queries.append(
"EXISTS {(a)-[:MENTIONS]->(:Organization)-[:IN_CITY]->()-[:IN_COUNTRY]->(:Country {name: $country})}"
)
params["country"] = country
국가는 표준 명명 표준을 따르므로 LLM은 대부분의 국가 명명 표준에 익숙해서 값을 데이터베이스에 매핑할 필요가 없어요.
마찬가지로 감정 메타데이터 필터링도 처리해볼까요?
if sentiment:
if sentiment == "positive":
where_queries.append("a.sentiment > $sentiment")
params["sentiment"] = 0.5
else:
where_queries.append("a.sentiment < $sentiment")
params["sentiment"] = -0.5
감정 입력 값으로 긍정적이거나 부정적인 두 가지 값만 사용하도록 LLM에 지시합니다. 그런 다음 이 두 값을 적절한 필터 값에 매핑하는 거죠.
`topic` 매개변수는 사전 필터링에 사용되지 않고 벡터 유사성 검색에 사용되므로 약간 다르게 처리해요.
if topic: # Do vector comparison
vector_snippet = (
" WITH c, a, vector.similarity.cosine(c.embedding,$embedding) AS score "
"ORDER BY score DESC LIMIT toInteger($k) "
)
params["embedding"] = embeddings.embed_query(topic)
else: # Just return the latest data
vector_snippet = " WITH c, a ORDER BY a.date DESC LIMIT toInteger($k) "
LLM이 사용자가 뉴스의 특정 주제에 관심이 있음을 식별하면, `topic` 입력의 텍스트 임베딩을 사용하여 가장 관련성이 높은 문서를 찾아요. 반면에 특정 주제가 식별되지 않으면 최신 기사 몇 개만 반환하고 벡터 유사성 검색을 완전히 피합니다.
이제 Cypher 문을 함께 배치하고 이를 사용하여 데이터베이스에서 정보를 검색해야 해요.
return_snippet = "RETURN '#title ' + a.title + 'n#date ' + toString(a.date) + 'n#text ' + c.text AS output"
complete_query = (
base_query + " AND ".join(where_queries) + vector_snippet + return_snippet
)
# Retrieve information from the database
data = graph.query(complete_query, params)
print(f"Cypher: {complete_query}n")
# Safely remove embedding before printing
params.pop('embedding', None)
print(f"Parameters: {params}")
return "###Article: ".join([el["output"] for el in data])
모든 쿼리 조각을 결합하여 최종 `complete_query`를 구성합니다. 그런 다음 동적으로 생성된 Cypher 문을 사용하여 데이터베이스에서 정보를 검색하고 이를 LLM에 반환해요. 입력 예를 위해 생성된 Cypher 문을 한번 살펴볼까요?
get_organization_news(
organization='neo4j',
sentiment='positive',
topic='remote work'
)
# Cypher: CYPHER runtime = parallel parallelRuntimeSupport=all
# MATCH (c:Chunk)<-[:HAS_CHUNK]-(a:Article) WHERE
# EXISTS {(a)-[:MENTIONS]->(:Organization {name: $organization})} AND
# a.sentiment > $sentiment
# WITH c, a, vector.similarity.cosine(c.embedding,$embedding) AS score
# ORDER BY score DESC LIMIT toInteger($k)
# RETURN '#title ' + a.title + 'ndate ' + toString(a.date) + 'ntext ' + c.text AS output
# Parameters: {'k': 5, 'organization': 'Neo4j', 'sentiment': 0.5}
동적 쿼리 생성은 예상대로 작동하며 데이터베이스에서 관련 정보를 검색할 수 있다는 것을 알 수 있어요.
OpenAI 에이전트 정의
다음으로 함수를 에이전트 도구로 래핑해야 해요. 먼저 입력 매개변수 설명을 추가해볼게요.
fewshot_examples = """{Input:What are the health benefits for Google employees in the news? Query: Health benefits} {Input: What is the latest positive news about Google? Query: None} {Input: Are there any news about VertexAI regarding Google? Query: VertexAI} {Input: Are there any news about new products regarding Google? Query: new products} """
class NewsInput(BaseModel): topic: Optional[str] = Field( description="Any specific information or topic besides organization, country, and sentiment that the user is interested in. Here are some examples: " + fewshot_examples ) organization: Optional[str] = Field( description="Organization that the user wants to find information about" ) country: Optional[str] = Field( description="Country of organizations that the user is interested in. Use full names like United States of America and France." ) sentiment: Optional[str] = Field( description="Sentiment of articles", enum=["positive", "negative"] )
사전 필터링 매개변수는 설명하기 꽤 간단했지만, `topic` 매개변수가 예상대로 작동하게 만드는 데 약간의 어려움이 있었어요. 결국, LLM이 더 잘 이해할 수 있도록 몇 가지 예시를 추가하기로 결정했죠. 또한 국가 명명 형식에 대한 LLM 정보를 제공하고, 감정에 대한 열거형도 제공하는 것을 볼 수 있어요.
이제 LLM 사용 시기에 대한 지침이 포함된 설명과 이름을 지정해서 커스텀 툴을 정의할 수 있어요.
class NewsTool(BaseTool):
name = "NewsInformation"
description = (
"useful for when you need to find relevant information in the news"
)
args_schema: Type[BaseModel] = NewsInput
def _run(
self,
topic: Optional[str] = None,
organization: Optional[str] = None,
country: Optional[str] = None,
sentiment: Optional[str] = None,
run_manager: Optional[CallbackManagerForToolRun] = None,
) -> str:
"""Use the tool."""
return get_organization_news(topic, organization, country, sentiment)
마지막으로 `agent_executor`를 정의하는 거예요. 얼마 전에 구현했던 OpenAI 에이전트의 LCEL 구현을 그대로 재사용했어요.
llm = ChatOpenAI(temperature=0, model="gpt-4-turbo", streaming=True)
tools = [NewsTool()]
llm_with_tools = llm.bind(functions=[format_tool_to_openai_function(t) for t in tools])
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful assistant that finds information about movies "
" and recommends them. If tools require follow up questions, "
"make sure to ask the user for clarification. Make sure to include any "
"available options that need to be clarified in the follow up questions "
"Do only the things the user specifically requested. ",
),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)
agent = (
{
"input": lambda x: x["input"],
"chat_history": lambda x: _format_chat_history(x["chat_history"])
if x.get("chat_history")
else [],
"agent_scratchpad": lambda x: format_to_openai_function_messages(
x["intermediate_steps"]
),
}
| prompt
| llm_with_tools
| OpenAIFunctionsAgentOutputParser()
)
agent_executor = AgentExecutor(agent=agent, tools=tools)
이 에이전트는 뉴스 정보를 검색하는 데 사용할 수 있는 툴을 하나 가지고 있어요. 또한 `chat_history` 메시지 플레이스홀더를 추가해서 에이전트가 대화할 수 있도록 하고, 후속 질문과 답변이 가능하도록 만들었답니다.
구현 테스트
몇 가지 입력을 실행하고 생성된 Cypher 문과 파라미터를 살펴볼게요.
agent_executor.invoke(
{"input": "What are some positive news regarding neo4j?"}
)
# Cypher: CYPHER runtime = parallel parallelRuntimeSupport=all
# MATCH (c:Chunk)<-[:HAS_CHUNK]-(a:Article) WHERE
# EXISTS {(a)-[:MENTIONS]->(:Organization {name: $organization})} AND
# a.sentiment > $sentiment WITH c, a
# ORDER BY a.date DESC LIMIT toInteger($k)
# RETURN '#title ' + a.title + 'date ' + toString(a.date) + 'text ' + c.text AS output
# Parameters: {'k': 5, 'organization': 'Neo4j', 'sentiment': 0.5}
생성된 Cypher 문이 유효하네요. 특정 주제를 지정하지 않았으니 Neo4j를 언급하는 긍정적인 기사의 마지막 5개 텍스트 청크를 반환하는군요. 좀 더 복잡한 작업을 해볼까요?
agent_executor.invoke(
{"input": "What are some of the latest negative news about employee happiness for companies from France?"}
)
# Cypher: CYPHER runtime = parallel parallelRuntimeSupport=all
# MATCH (c:Chunk)<-[:HAS_CHUNK]-(a:Article) WHERE
# EXISTS {(a)-[:MENTIONS]->(:Organization)-[:IN_CITY]->()-[:IN_COUNTRY]->(:Country {name: $country})} AND
# a.sentiment < $sentiment
# WITH c, a, vector.similarity.cosine(c.embedding,$embedding) AS score
# ORDER BY score DESC LIMIT toInteger($k)
# RETURN '#title ' + a.title + 'date ' + toString(a.date) + 'text ' + c.text AS output
# Parameters: {'k': 5, 'country': 'France', 'sentiment': -0.5, 'topic': 'employee happiness'}
LLM 에이전트는 사전 필터링 파라미터를 올바르게 생성했지만 특정 항목도 식별했어요. 주제 말이죠. 이 주제는 Vector Embedding 유사성 검색에 대한 입력으로 사용되므로 검색 프로세스를 더욱 세분화할 수 있어요.
요약
이번 블로그 포스팅에서는 예제 그래프 기반 메타데이터 필터를 구현해서 Vector Embedding 검색 정확도를 향상시켰어요. 하지만 데이터 세트에는 훨씬 더 정교한 사전 필터링 쿼리를 허용하는 광범위하고 상호 연결된 옵션이 있답니다. Graph Database 표현을 통해 구조화된 필터의 가능성은 LLM 함수 호출 기능과 결합되어 Cypher 문을 동적으로 생성할 때 정말 무궁무진하죠.
또한 에이전트에는 이 블로그 포스팅에 표시된 것처럼 구조화되지 않은 텍스트를 검색하는 도구와 다음을 수행할 수 있는 기타 도구가 있을 수 있어요. 구조화된 정보 검색, Knowledge Graph를 많은 RAG 애플리케이션에 대한 탁월한 솔루션으로 만들어주죠.
코드는 다음에서 사용할 수 있습니다. .
rag
구조화되지 않은 데이터
벡터 유사성 검색
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
유행어를 좋아하든 싫어하든 '빅데이터'는 피할 수 없는 현실이에요. 비즈니스 인텔리전스든 생물정보학이든, 추천 엔진이든 위험 분석이든 상관없이, data는 계속 증가할 뿐이죠.
그래프는 빅데이터 작업을 위한 강력한 도구라는 건 의심할 여지가 없어요. 안타깝게도 그래프의 가장 큰 장점 중 하나인 직관적인 시각화는 기본적으로 고정된 리소스인 화면 크기로 인해 제한되죠. 아무리 큰 모니터라도 수백 개의 Node만 수용하면 그래프 구조를 분석하기 어려워져요.
너무 빽빽해요
2012년에 제가 처음 시작한 스타트업은 공유 경제를 위한 신뢰 기반으로 소셜 네트워크를 활용했어요. (이건 전문 용어 빙고 at 그래프커넥트 2018에서 훌륭한 연습이 되기도 했죠). 우리는 많은 실제 및 가짜 소셜 네트워크 계정의 그래프 서명을 살펴봤어요. 이러한 계정 간의 차이를 정량화하기는 어렵지만, 시각화하면 패턴의 차이가 명확하게 나타나요.
하지만 우리는 인기 있는 사람들 덕을 보지는 못했어요. 예를 들어 아래 그래프는 최대 2,000명의 친구를 보유한 사용자를 보여줘요. 별도의 커뮤니티를 나타내는 다양한 색상의 그래프 레이아웃은 Gephi를 사용하여 2D로 만들었어요.
이건 꽤 멋지고 몇 가지 뚜렷한 클러스터를 보여주지만, 이 접근 방식의 단점도 드러내죠. 가장 눈에 띄는 건 모든 것이 겹쳐 보이는 왼쪽의 거대한 Node 덩어리예요. 2D 레이아웃은 개별 클러스터를 효과적으로 분리하지만, 해당 클러스터가 서로 연결되어 있으면 답이 없어요.
이제 남은 건 그래프만 보여주는 그래프 시각화뿐이에요. 연결 수, 활동 수준, 위치 등과 같은 매개변수별로 클러스터링하려는 경우 색상이나 크기를 다시 할당하는 것 외에는 할 수 있는 일이 많지 않아요. Node를 시각적으로 정렬하고 분류하는 건 쉽지 않죠.
물론 데이터를 별도의 애플리케이션으로 가져와 해당 속성의 2D 산점도를 생성하거나 지도에 Node를 펼칠 수도 있어요. 하지만 우리는 그래프에 의해 직관적으로 포착된 차트와 관계 사이의 연결을 잃게 될 거예요.
게다가, 저는 그 사이를 쉽게 전환할 수 없어요.(u0:User)-[:friend_of]-(u1:User)위의 관점을 다음과 같이 표현합니다.
2년 후 저는 현재의 스타트업인 키네비즈를 설립했어요. 첫 번째 클라이언트인 Box는 파일 공유 플랫폼에서 협업을 시각화하기 위해 우리를 초대했죠. 이 "콜라보 그래프"는 BoxWorks 고객 컨퍼런스를 위해 만들어졌고, 참석자들은 제스처 컨트롤을 사용하여 대형 화면에서 그래프와 상호 작용했어요.
제스처 인터페이스를 최대한 활용하기 위해 우리는 레이아웃을 3D로 하기로 결정했어요. 우리를 놀라게 한 첫 번째 점은 3,000개 이상의 Node가 있는 이 3D 그래프가 300개 이상의 Node로 구성된 2D 그래프만큼 빽빽해 보이지 않는다는 것이었어요!
클러스터는 상호 연결을 잃지 않고 시각적으로 분리돼요. 직관적으로 고차원 정보는 고차원 시각화에서 이점을 얻는다는 것을 알 수 있었죠 (그래프의 각 연결이 차원으로 간주된다는 점을 고려하면). 2D에서 3D로의 선형적 증가는 편안하게 배치할 수 있는 데이터 양의 기하급수적인 증가를 의미해요.
VR을 이용한 소수자 신고
3D 데이터 시각화는 완전히 새로운 건 아니고 단점이 없는 것도 아니에요. 2D 화면에서는 깊이 정보가 손실되죠. 그리고 모든 화면 기반 시각화는 글로벌 컨텍스트를 유지하면서 로컬 구조를 조사하는 것 사이의 단절로 인해 어려움을 겪어요 (일명 Google 지도 문제: 거리를 확대하면 도시의 컨텍스트를 잃게 되잖아요).
2014년에 Oculus DK2 가상 현실 헤드셋이 막 출시되었을 때, 저희는 그걸 한번 시험해보고 싶었어요. 왜냐하면 WebGL에서 Collab Graphs를 개발하고 있었거든요. WebXR 표준 덕분에 큰 어려움 없이 VR로 가져올 수 있었죠. 멋질 것 같기도 했고, 2D 화면에서 3D의 단점을 해결할 수 있을 거라는 직감도 있었거든요.
결과는 정말 영감을 줬어요! 하이브리드 VR 및 2D 데이터 시각화 플랫폼인 GraphXR을 만들게 되었죠. VR을 사용해 보지 않았다면 물리적 공간의 경험을 얼마나 잘 반영하는지 전달하기 어려울 거예요. 지금 당장 뒤에 누군가가 서 있는지(야유!) 뒤돌아 볼 필요 없이 문이 어디에 있는지 아는 것처럼, VR은 지속적으로 확대/축소하거나 뷰 사이를 이동하지 않고도 복잡한 패턴에 대한 상황 인식을 제공하거든요.
VR 데이터 시각화의 효율성에 대한 확실한 주장을 하기 전에 많은 연구가 이루어져야 하겠지만, 초기 도구 사용자들은 데이터 분석 속도가 15배에서 150배(!) 향상되었다고 보고했어요.
확장 현실(XR은 VR과 증강 현실의 상위 집합)의 미래는 밝지만, VR 데이터 시각화의 이점이 AR로 이어지는 것을 아직 보지 못했다는 점을 언급할 가치가 있어요.
현재 세대의 AR 헤드셋은 시야가 좁아서 시야 영역이 화면으로 제한되거든요. 콘텐츠는 시청자의 주변 시야에 절대 들어가지 않기 때문에 VR에서 보는 것처럼 뇌의 공간 버퍼에 로드되지 않아요. 이러한 제한은 차세대 AR 헤드셋에서는 의심할 여지 없이 제거될 거예요.
큰 그림
특히 시각화가 작업에서 중요한 역할을 하는 경우, 데이터 전문가가 되기에는 정말 흥미로운 시기인 것 같아요. 저는 큰 그래프를 시각화하는 데 따른 몇 가지 과제와 솔루션만 다루었지만요.
Bloom and 의 데이터 시각화 파트너로 구성된 전체 생태계는 빅데이터 작업을 위한 다양한 전략을 제공해요. 급증하는 GPU 성능을 통해 Graphistry는 대규모 그래프 레이아웃 문제를 해결할 수 있고, 3Data 및 Virtualitics와 같은 회사는 VR 데이터 시각화의 가능성을 탐색하고 있죠. 빅데이터 및 그래프 채택과 마찬가지로 시각화 옵션도 계속 늘어날 거예요.
키네비즈GraphConnect 2018의 실버 스폰서입니다. 코드 사용KIN10컨퍼런스 및 교육 세션 티켓을 10% 할인받으실 수 있으며, 뉴욕에서 뵙겠습니다!
9월 20~21일에 열리는 GraphConnect 2018에 참가하여 이와 같은 프로젝트에 참여하는 전 세계의 그래프 전문가를 만나보세요. 오늘 위의 할인 코드를 받아 티켓을 받으세요.
내 (할인!) 티켓 받기
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
이번 글에서는 이전 블로그 게시물의 아이디어와 실험을 바탕으로 PDF 문서에서 RAG 애플리케이션을 구축하는 데 필요한 모든 단계를 안내해 드릴 거예요.
프로젝트 저장소: 깃허브.
GitHub – Joshua-Yu/graph-rag: 그래프 기반 검색 + GenAI = 프로덕션에서 더 나은 RAG
개요
더 나은 Retrieval-Augmented Generation(RAG) 솔루션을 구축하는 방법에 대한 글과 제품이 정말 많죠. 과거에는 Property Graph Database를 사용한 지식 저장, 인덱싱 및 검색을 중심으로 RAG의 주요 측면을 설명했어요. 비정형 데이터와 정형 데이터 모두.
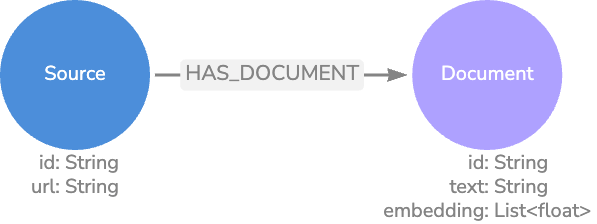
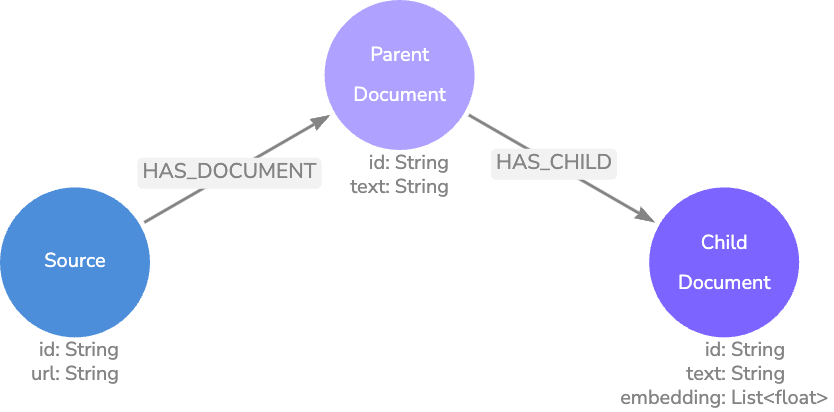
벡터를 Knowledge Graph와 함께 저장해야 하는 이유는 무엇일까요?
여기에서는 를 보여드리면서 모든 부분을 하나로 모아보려고 해요. PDF 문서 파싱 및 수집부터 Knowledge Graph 생성, 주어진 자연어 질문에 대한 그래프 검색에 이르기까지 엔드투엔드 파이프라인을 다루고 있답니다.
주요 솔루션 구성 요소
1. PDF 문서 파싱 및 콘텐츠 추출
LLM Sherpa(깃허브)는 계층적 레이아웃 정보(예: 문서, 섹션, 문장, 표 등)로 PDF 문서를 파싱하기 위한 Python 라이브러리이자 API에요.
일반적인 청킹 전략과 비교하면 (고정 길이 + 텍스트 겹침) 문서 구조를 보존할 수 있다면 보다 유연한 청킹이 가능해지기 때문에 생성을 위한 더 완전하고 관련성 높은 컨텍스트를 제공할 수 있어요.
2. 지식 저장소용 Neo4j AuraDB
AuraDB에는 기능을 실험하고 시험해 볼 수 있는 free 티어가 있어요. 자신만의 인스턴스를 생성하는 자세한 단계를 보려면 다음 온라인 문서 또는 이 기사를 참고하세요:
간단한 3단계로 Knowledge Graph에 Q&A 기능 추가하기
3. 데이터 수집을 위한 Python + Neo4j 드라이버
PDF 문서의 내용은 Cypher 쿼리 언어를 사용하는 Python 드라이버를 통해 Neo4j에 로드돼요.
4. Semantic Search를 위한 Neo4j Vector Index
Neo4j가 제공하는 표준 데이터 유형, 자유 형식 텍스트 및 텍스트 임베딩 절차에 의해 생성된 벡터에 대한 Index에요.
텍스트 임베딩과 벡터가 처음이라면 개념과 사용 샘플을 설명하는 게시물을 참조해 보세요.
텍스트 임베딩 — 무엇을, 왜, 어떻게?
5. 빠른 프로토타이핑을 위한 GenAI-Stack
The GenAI 스택은 Neo4j가 협력하여 만든 사전 구축된 개발 환경이에요. , 랭체인, 그리고 를 사용하죠. 이 스택은 특히 RAG를 통해 LLM(Large Language Models)에서 생성된 응답의 정확성, 관련성, 출처를 개선하는 데 중점을 두고 GenAI 애플리케이션을 생성하도록 설계되었답니다.
숙달을 위한 빠른 길: 효율적인 LLM 애플리케이션을 위한 Neo4j GenAI 스택
우리 프로젝트에서는 채팅 애플리케이션의 빠른 개발을 위해 LangChain 부분이 필요해요.
6. 임베딩 및 텍스트 생성을 위한 OpenAI 모델
OpenAI의 임베딩 모델인 *text-embedding-ada-002* 와 LLM *GPT-4* 가 사용되니까, OpenAI API 키가 필요해요.
프로젝트 연습
1. 준비
1.1 를 저장소에서 복제하세요: .
1.2 Neo4j AuraDB 무료 인스턴스를 생성하세요.
1.3 필요한 종속성을 설치해야 해요.
llmsherpa ()
Neo4j GenAI-stack (). 여기에는 LangChain과 Streamlit(프론트엔드)이 이미 포함되어 있어요.
Python용 Neo4j 드라이버
1.4 OpenAI API 키도 필요하겠죠?
2. PDF 문서 파싱 및 Neo4j로 로드
샘플 프로젝트 폴더 아래의 custom 폴더에서 LayoutPDFReader_KGLoader 노트북을 실행해 보세요. 다음 단계를 따르면 돼요:
ingestDocumentNeo4j()를 실행해서 문서의 모든 내용을 Graph Database에 로드하세요. 현재는 텍스트 chunk와 table이 지원된답니다.
3. 텍스트 및 테이블 이름에 대한 임베딩 생성 및 저장
KGEmbedding_Populate 노트북을 열고 실행해서 임베딩을 생성하고 저장하세요. OpenAI API 키와 Neo4j AuraDB 연결 정보를 입력한 후에 embedding node를 만들면 돼요.
# First parameter is the node label,
# second is the node property name which contains text to be embedded
LoadEmbedding("Chunk", "sentences")
LoadEmbedding("Table", "name")
이제 다음과 같은 스키마를 가진 가 만들어졌어요.
문서 그래프 스키마. 점선 화살표는 향후 생성될 예정입니다.
4. 채팅 애플리케이션 준비
복제된 프로젝트 위치로 이동해서GenAI Stack을 클릭하고 아래 파일과 하위 폴더를 복사하세요. GenAI Stack 폴더의를요. 간단하게 설명해 드릴게요.
chains.py: 구조 인식 검색기의 새로운 프로시저가 포함된 업데이트된 Python 파일이에요.
# from line 154
def configure_qa_structure_rag_chain(llm, embeddings, embeddings_store_url, username, password):
# RAG response based on vector search and retrieval of structured chunks
...
...
cs_bot_papers.py: Streamlit 및 새로운 검색기를 기반으로 한 채팅 프런트 엔드입니다.
이 구조 인식 검색기에 대한 자세한 설명은 제 다른 블로그 게시물을 확인해 보세요.
GenAI 스택에 구조 인식 검색 추가
5. 채팅 애플리케이션 실행
이제 실행할 준비가 되었어요! 다음을 입력해서 Streamlit 애플리케이션을 실행해 보세요 (Python 환경에 따라 약간 다른 명령줄을 사용할 수 있어요).
python -m streamlit run cs_bot_papers.py
기능을 보여드리기 위해 비교적 최신 논문을 넣어서 테스트해봤는데요,Natural Language Is All You Need for Graph(arXiv) 그리고 "instructGLM" 접근 방식에 대해 질문했어요.
만약 Retrieval-Augmented Generation (RAG)이 disabled 상태라면, GPT-4는 지식 마감일이 2023년 4월이기 때문에 정답을 제공할 수 없어요.
Retrieval-Augmented Generation (RAG)이 되면, 애플리케이션은
먼저 질문의 텍스트 Vector Embedding을 생성해요.
그런 다음 Neo4j AuraDB에서 벡터 검색에 사용되죠.
가장 많이 일치하는 chunk에 대해 관련 내용같은 section이 검색됩니다 (구조 인식 검색 부분).
답변을 생성하기 위해 사용자 질문과 함께 GPT-4로 전달돼요.
이것은 소위구조 인식 검색을 사용하는데요. 아래 스크린샷을 보면, 검색된 정보에서 답변뿐만 아니라 메타데이터로 전달된 참조 위치도 제공되는 것을 확인할 수 있어요.
추가 토론
위 단계를 따라 Graph Database로 구동되는 RAG 채팅 애플리케이션을 성공적으로 실행할 수 있기를 바라요.
Neo4j를 사용해서 지식을 저장하면 유연한 모델, 다양한 indexing 기능, 빠른 query 성능뿐만 아니라 Cypher query language로 복잡한 검색과 같은 더 많은 잠재력을 얻을 수 있어요.
GenAI
앞으로 이 샘플 프로젝트에 더 중요한 기능을 추가하는 여정을 계속할 거예요.
초보자를 위한 GraphRAG
연결된 데이터를 기반으로 복잡한 질문에 답할 수 있는 GraphRAG 애플리케이션을 구축해보세요. 세 가지 주요 검색 패턴을 알아볼까요?
Langchain
OpenAI
PDF 문서
RAG
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
"Allianz Benelux에서는 연결된 데이터 관점에서 데이터를 볼 수 있게 해주는 그래프를 정말 중요하게 생각해요. 데이터를 개별 정보 조각으로 보는 대신, 모든 조각이 어떻게 연결되어 있는지 이해하고 싶거든요." 라고 Allianz Benelux의 비즈니스 인텔리전스 책임자 Jan Doumen이 말했어요.
이번 주 5분 인터뷰에서는 비즈니스 인텔리전스 책임자인 Jan Doumen과 Aarthi Kumar (수석 데이터 과학자), Niels Holtrop (데이터 과학자) 님과 이야기를 나눠볼 거예요. 이 분들은 모두 Graphie Award 수상자이기도 한데요, Allianz Benelux에서 Neo4j를 사용해서 고객 프로필을 만들고 보험 업계의 사기를 어떻게 탐지하는지 한번 알아볼까요?
자기소개를 부탁드려요.
Jan: 안녕하세요! 이 글을 읽고 계신 시간이 언제든 좋은 아침, 좋은 오후, 좋은 저녁, 혹은 좋은 밤이에요.
저희는 Allianz Benelux, 그 중에서도 데이터 오피스라는 조직 내 사업 부서에 속해 있어요. Allianz는 세계에서 가장 큰 보험 회사 중 하나이고, Benelux는 벨기에, 네덜란드, 룩셈부르크 이렇게 세 나라를 아우르는 국경을 넘나드는 운영 기관이죠.
저희 사업은 소매, 중소기업(SMB), 중견 기업, 그리고 손해보험(재산 및 손해) 사업과 생명 보험 사업 모두에 집중하고 있어요. 주로 브로커가 중개하는 시장에서 보험을 판매하고 있답니다. 그래프로 어떤 일을 하는지 좀 더 자세히 알려드릴게요. 저는 고객 인사이트 및 인텔리전스, 관리 정보 및 인사이트 분야의 전문 분야 책임자이자 팀장인 Jan Doumen입니다.
Aarthi: 안녕하세요, 여러분! 저는 Aarthi Kumar이고요, 수석 데이터 과학자이자 고객 및 브로커 인사이트 및 인텔리전스 부문의 수석 리더입니다.
Niels: 만나서 반가워요. 제 이름은 Neils Holtrop이고, 사기 정보 팀의 데이터 과학자이자 주요 리더입니다. 저희는 사기 사업부와 함께 사기 퇴치에 고급 분석 및 Machine Learning 알고리즘을 통합하는 것을 목표로 하고 있어요.
Neo4j를 어떻게 사용하고 있나요?
Jan: Allianz Benelux에서는 연결된 데이터 관점에서 데이터를 볼 수 있게 해주는 그래프의 중요성을 굳게 믿고 있어요. 데이터를 개별 정보 조각으로 보는 대신, 이 모든 조각들이 어떻게 서로 연결되어 있는지 이해하고 싶거든요. 이런 관점을 통해 이미 큰 이익을 얻고 있는 두 가지 영역이 있어요.
하나는 고객 인텔리전스인데, 고객에 대한 진정한 360도 뷰를 만들 수 있었어요. 고객이 실제로 필요로 하는 것이 무엇인지 이해하기 시작했죠. 다른 하나는 사기 정보예요. 아시다시피 사기는 저희 비용의 상당 부분을 차지하고, 이는 정직하게 보험금을 청구하는 대다수 고객에게 부정적인 영향을 미치거든요.
Neo4j를 사용하기 전에는 이 문제를 어떻게 해결했나요?
Niels: 보험에서 사기 문제는 정말 큰 문제예요. 추정치에 따르면 지급된 청구 비용의 약 5~10%가 사기 때문에 발생한다고 해요. 여기에는 전문적인 사기꾼뿐만 아니라 자신의 주장을 과장하는 일반 소비자도 포함되죠. 보험 업계에서 그래프 기술을 사용하는 건 주로 단계적이거나 과장된 청구와 관련된 전문적인 사기에 초점을 맞추고 있어요. 이런 종류의 주장은 어떤 식으로든 서로를 아는 사람들 사이에서 발생하는 사회적 연결을 통해 주로 발견되거든요.
과거에는 이런 관계를 파악하는 과정이 수많은 수작업으로 이루어져서 시간이 엄청 오래 걸렸어요. 어떤 사건을 입증하려면 네트워크 전체를 그려서 누가 누구와 어떤 방식으로 관련되어 있는지 확인해야 했죠. 하지만 그래프를 사용하면 버튼 클릭 한 번으로 네트워크를 생성할 수 있어요. 그래서 당사자들의 초기 개요를 만드는 데 시간을 엄청나게 절약할 수 있게 되었죠.
Aarthi: 고객 데이터는 모든 조직의 금맥과 같아요. 그래프가 없었다면 고객 Golden Profile(중앙 고객 마스터 프로필) 대신 고객 Golden Record(고객에 대한 일치하는 단일 뷰)를 사용했을 거예요.
전통적인 관계형 데이터베이스는 사람이 이해하기 어려운 고객에 대한 사실 기록을 제공했죠. 데이터에 더 많은 차원을 추가할수록 영업 및 마케팅 팀이 데이터를 사용하는 게 점점 더 어려워졌어요. 주요 사용 사례 중 하나는 교차 판매 및 상향 판매 기회인데요, McKinsey 연구에 따르면 보험 회사의 교차 판매 및 상향 판매 기회는 매출을 최소 10~20% 증가시킬 수 있다고 해요. 이런 기회를 놓치고 싶지 않겠죠?
Neo4j를 선택하게 된 계기가 무엇인가요?
Jan: 저희는 여러 그래프 데이터베이스 제공업체를 살펴보고 있었어요. 결국 대부분은 기존 데이터베이스 위에 그래프를 제공하더라고요. 네이티브 그래프를 만드는 곳은 소수에 불과했고, Neo4j도 그 중 하나였죠. 그래서 다른 제품들과 비교하면서 Neo4j를 선택하게 되었어요. 저는 광범위한 구현에서 우리를 얼마나 지원할 의향이 있는지 회사 뒤에 있는 사람들과 이야기를 나눴어요.
그런 다음 저희에게 가장 적합하다고 생각되는 것을 선택했어요. 공평하게 말하자면, 그래프에는 박사 학위를 가진 데이터 과학자가 여러 명 있거든요. 그래서 저희는 시장과 다양한 도구 각각의 가치가 무엇인지 잘 알고 있었죠.
예전에는 할 수 없었지만 지금은 무엇을 할 수 있나요?
닐스: Graph Database를 사용하면 이제 데이터베이스 보기 대신 일반 사람이 보는 방식으로 청구의 관계를 볼 수 있어요. 링크가 존재하면 서로 다른 당사자 간의 관계를 즉시 시각적으로 확인할 수 있죠. 이를 두 개의 서로 다른 주장에 동일한 이름이 존재한다는 것을 기억하거나 인식하려는 전통적인 방법과 비교해 보세요. 저희는 청구 내에서 새로운 소셜 네트워크를 찾는 데 걸리는 시간이 크게 단축된다는 것을 깨달았어요.
아르티어: 고객을 모든 데이터 포인트가 포함된 그래프로 볼 수 있다면 비즈니스 팀이 더 빨리 이해하고 더 빠른 의사 결정을 내리는 데 도움이 돼요. 고객에 대한 가구적 관점을 통해 고객, 이상적인 고객 및 고객의 요구 사항을 더 잘 이해할 수 있었어요. 저희는 저희가 가지고 있는 것을 고객에게 판매하는 것이 아니라 고객의 필요에 맞는 올바른 보험 보호를 판매하고 싶거든요.
귀하의 프로젝트의 다음 단계는 무엇입니까?
닐스: Neo4j를 사용할 때 가장 좋은 점은 일단 초기 데이터베이스가 설정되면 권장 GRANDstack을 사용하거나 R 및 Python과 같은 오픈 소스 라이브러리 및 소프트웨어를 사용하여 그래프와 상호 작용할 수 있는 다양한 방법이 있다는 거예요. 이는 실제로 실험을 수행하고 무언가가 작동하는지 여부를 빠르게 확인할 수 있는 큰 유연성을 허용하죠.
닐스: Neo4j를 사용할 때 가장 좋은 점은 일단 초기 데이터베이스가 설정되면 권장 GRANDstack을 사용하거나 R 및 Python과 같은 오픈 소스 라이브러리 및 소프트웨어를 사용하여 그래프와 상호 작용할 수 있는 다양한 방법이 있다는 거예요. 이는 실제로 실험을 수행하고 무언가가 작동하는지 여부를 빠르게 확인할 수 있는 큰 유연성을 허용하죠.
Neo4j를 사용하면서 가장 좋은 점은 무엇입니까?
닐스: 저희에게 다음 단계는 그래프 데이터 과학 라이브러리가 저희에게 무엇을 가져다 줄 수 있는지 조사하는 것이에요. 네트워크 분석이 최우선 과제가 되겠지만, 청구서에 존재하는 데이터의 시간순으로 볼 때 정보 유출 측면에서 그 자체의 문제가 발생할 거예요. 여기에서는 Neo4j와 함께 옵션이 무엇인지, 그래프의 새로운 기능을 개발하는 데 도움이 될 수 있는 부분을 평가할 거예요.
그래프 기술의 미래는 어떻게 될 것이라고 생각하시나요?
Jan: 솔직히 저희는 그래프의 미래가 밝다고 생각해요. 관계형 데이터베이스는 단순히 연결된 관점에서 데이터를 볼 수 있는 컴퓨팅이 없었기 때문에 존재했죠. 지나치게 단순화하면 이는 우리의 뇌에 비유될 수 있어요. 우리는 뇌의 약 10%만 사용하잖아요. 그러니 우리가 100%를 사용할 수 있다고 상상해 보세요. 저희 친구 중 한 명은 최근 그래프 데이터 웨어하우스에 관한 박사 학위를 취득했어요. 따라서 탐색하고 활용할 수 있는 수많은 가능성이 있죠. 그리고 저희는 그래프를 사용하는 것이 시장의 주요 차별화 요소라고 믿어요.
향후 5분 인터뷰에서 Neo4j 프로젝트에 대해 공유하고 싶으신가요? 저희에게 연락해주세요. content@neo4j.com
5분 인터뷰
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
오늘날의 경제 환경에서는 깊고 신뢰할 수 있는 통찰력과 강력한 예측이 꼭 필요해요. 데이터는 정말 소중한 자산이지만, 데이터 내부와 데이터 간의 관계는 아직 제대로 활용되지 못하고 있는 경우가 많죠.
Graph Embedding은 연결된 데이터의 구조를 학습해서 가장 시급한 문제들을 해결하는 새로운 방법을 제시하고, 미처 보지 못했던 부분에 대한 가시성을 더해주는 새로운 기술이에요.
점점 더 많은 조직들이 데이터 내 연결의 가치를 알아보고 있고, 그만큼 그래프 분석이 현대적인 데이터 및 분석 전략의 기초로 널리 인정받고 있어요. 예를 들어 Gartner는 그래프가 2021년 10%에서 2025년까지 데이터 및 분석 혁신의 80%에 사용될 거라고 예측하고 있대요.
Knowledge Graph에 대한 강력한 심층 `Query`는 과거에는 조사하는 데 몇 주씩 걸렸을 비즈니스 질문에 빠르게 답변을 제공해줘요. 그래프 시각화 도구는 자유로운 탐색을 촉진하고 "아하!" 하는 순간을 만들어내죠.
그런데 전체 그래프를 분석하거나 예측하는 경우는 어떨까요? 아니면 이미 질문하는 방법을 알고 있는 질문을 뛰어넘어보는 건 어때요?
일반적인 첫 번째 단계는 비지도 Machine Learning 기술을 사용하는 거예요. 그래프 알고리즘을 사용해서 패턴, 이상 현상 등을 식별하는 거죠. 예를 들어, 데이터 과학자는 PageRank와 같은 중심성 알고리즘을 사용해서 회사에서 가장 중요한 사람을 식별하거나, Louvain과 같은 커뮤니티 탐지 알고리즘을 사용해서 자금 세탁을 찾아낼 수 있어요.
그래프 분석의 다음 개척지는 지도 Machine Learning을 적용하는 건데요. 즉, 다음에 일어날 일을 예측하고, 누락된 데이터를 채우고, 그래프 구조가 미래를 예측할 수 있는 방법을 이해하는 거예요. 바로 이럴 때 Graph Embedding이 필요한 거고, 연결된 데이터 내에서 통찰력을 얻기 위한 기본 기술이 되는 거죠.
이번 블로그 포스팅에서는 다음 내용을 살펴볼 거예요.
지금 Graph Embedding이 필요한 이유
Graph Embedding이란 무엇이고 어떻게 작동하나요?
Graph Embedding의 실제 사용 예시
지금 Graph Embedding이 필요한 이유
Graph Embedding은 연결된 데이터(Knowledge Graph, 고객 여정, 거래 네트워크)를 예측 신호로 변환하는 데 사용되는 기술이에요.
데이터 과학자는 보통 과거 데이터를 사용해서 예측 모델을 강화하죠. 하지만 최근 전 세계적으로 유행하는 전염병이나 자연 재해와 같은 '블랙 스완' 사건을 생각해보면, 이런 데이터는 예측 가능성이 훨씬 낮아져요. 과거 데이터 표의 행과 열을 살펴보는 대신, Graph Embedding을 사용하면 연결된 데이터에서 통찰력을 얻을 수 있어요.
그래프는 복잡한 공급망, 의료 연구, 고객 360, 사기 탐지 등 거의 모든 종류의 데이터를 나타낼 수 있다는 사실! 정말 흥미롭죠?
그래프의 모든 데이터에서 예측 가능한 것은 무엇일까요? 데이터 과학자는 패턴과 이상 현상을 찾아내기 위해 그래프를 탐색하고 다양한 그래프 알고리즘을 실행하는 것부터 시작하는 경우가 많아요. 하지만 이는 상당히 제한적인 접근 방식이죠. 각 특정 그래프 알고리즘은 항상 발견하도록 설계된 특정 패턴만 찾거든요. PageRank는 항상 PageRank이고, 이것이 알려줄 수 있는 유일한 것은 node가 얼마나 중요한지 뿐이에요.
그래프 임베딩은 좀 달라요. 그래프 임베딩은 그래프의 고유한 데이터를 보고 이를 통해 학습해서 문제를 해결하죠. 어떤 알고리즘이 유용한 정보를 알려줄지 추측하는 대신, 그래프 임베딩은 사용자가 찾지 못할 예측 패턴을 강조해요. 이런 의미에서 그래프 임베딩은 그래프에 대해 학습하기 위한 치트 코드와 약간 비슷하다고 할 수 있어요.
그래프 임베딩은 추측 없이 예측 가능한 내용을 보여주므로 시행착오를 거쳐 수동으로 특성을 엔지니어링하는 데 드는 시간을 절약할 수 있어요. 주요 보험 회사의 선임 데이터 과학자는 그래프 임베딩에 대한 그의 팀의 기대를 다음과 같이 표현했죠. "우리가 이 알고리즘과 저 알고리즘을 시험해 본 후 우리가 선택한 특징이 예측이 아닌 것으로 판명되는 특징 엔지니어링을 수행하려면 시간이 오래 걸립니다."
모든 것이 자연스럽게 연결됩니다.
임베딩은 수학이 아니라 마술이다
그래프가 그 자체에 대해 알려줄 수 있다는 생각은 마치 마술처럼 들리죠? 마치 클라크의 제3법칙 "충분히 발전한 기술은 마법과 구별할 수 없습니다." 와 같은 느낌이에요. 겉보기와는 다르게 그래프 임베딩은 마법이 아닌 최첨단 수학이랍니다.
그래프 임베딩은 그래프를 숫자로 변환해요. 그래프 임베딩은 그래프의 모든 정보를 가져와서 학습하여, 존재하지 않는 패턴과 표면 연결을 밝힐 수 있는 수치 표현을 도출하죠. 그래프 임베딩은 데이터의 정확한 수학적 표현이므로 그래프 임베딩이 표시하는 신호는 비즈니스를 발전시키는 데 신뢰할 수 있어요.
그래프 임베딩은 그래프의 중요한 기능을 모두 반영해요. 초상화가 3차원 사람을 2차원으로 인코딩하는 것처럼 임베딩은 그래프를 압축하여 더 간단하면서도 알아볼 수 있도록 만들어 줍니다.
그래프에서 데이터의 구조(데이터 포인트 간의 연결)는 node 및 해당 속성만큼 중요해요. The nodes are data. node를 연결하는 relationships는 데이터이고, 이러한 node와 relationship에 할당된 속성도 데이터죠. 각 node의 이웃 수를 세는 것과 같은 간단한 기술은 그래프에 인코딩된 구조적 맥락과 풍부함을 놓치기 쉬워요. 임베딩은 모든 정보를 가져와 node, 해당 속성, 이웃과의 relationship 및 전체 그래프의 컨텍스트를 인코딩하는 의미 있는 단일 vector로 변환할 수 있어요.
임베딩은 node(사물), relationship(연결) 또는 전체 그래프 등 그래프의 다양한 측면을 설명할 수 있어요. 임베딩을 사용하면 질문에 답하기 위해 고유하게 조정된 데이터로부터 수학적 표현을 만들 수 있죠.
그래프 임베딩은 특정 그래프 데이터의 수치 표현을 생성합니다.
임베딩 뒤의 수학
임베딩 생성과 임베딩 사용은 상호 연관되어 있어요. 선택한 기술은 보유한 데이터와 해결하려는 문제에 따라 결정되죠.
임베딩을 계산하려면 먼저 임베드하려는 node, 속성 및 relationship를 식별해야 해요. 기본적으로 그래프를 숫자로 변환할 때 고려해야 할 사항인 거죠.
데이터를 선택한 후 임베딩 기술을 선택하게 되는데요. Neo4j Graph Data Science는 현재 아래 표의 임베딩 기술을 지원하고 있어요. 임베딩을 선택한 후에는 다양한 구성 매개변수를 사용해서 임베딩을 사용자 정의하고 조정할 수 있어요. 이렇게 하면 임베딩이 정확한 표현을 제공하는지 확인할 수 있죠. 임베딩이 학습하는 내용, 실행 기간, 결과의 정확성 측정 방법, 다양한 기능이 인코딩되는 방식까지 제어할 수 있다는 점이 매력적이에요. 임베딩을 생성한 후에는 여러 가지 방법으로 활용할 수 있는데요. 한번 살펴볼까요? **유사성을 계산**할 수 있어요. 임베딩은 구조적 동등성, 유사한 속성, 유사한 `Node`를 찾기 위한 코사인 유사성과 같은 메트릭, 가장 가까운 이웃 그래프 구축 등 그래프 유사성을 인코딩해요. 예를 들어, 소매 그래프에서는 임베딩이 고객 행동을 포착하므로 유사한 임베딩을 가진 제품이 좋은 추천 대상이 되는 경우가 많죠. **그래프를 차트로 시각화**할 수도 있어요. PCA와 같은 기술을 사용해서 2차원 또는 3차원으로 t-SNE 플롯을 만들 수 있죠. 시각화를 통해 클러스터나 패턴을 식별할 수 있는데요. 아스트라제네카에서는 다양한 진단을 받은 환자를 시각화하고 구별하기 위해 환자 여정 임베딩을 사용했다고 해요 (그림 3). **특징으로는** `Node` 분류 및 링크 예측과 같은 작업을 수행하기 위해 지도형 Machine Learning 모델을 훈련할 수 있어요. 예를 들어 은행 거래 그래프에서 각 계정 소유자에 대한 `Node` 임베딩을 계산하고, 이러한 임베딩을 사용해서 행동을 기반으로 사기를 저지를 가능성이 있는 계정을 예측할 수 있죠.
탐색환자 여행3차원 t-SNE 플롯으로.
그래프 임베딩의 실제 사용
그래프 임베딩은 단순한 이론이 아니라 최첨단 기업이 AI를 더 잘 수행하는 방법이에요. 이제 오늘날의 조직이 고급 그래프 임베딩 수학을 활용해서 이점을 누리는 몇 가지 방법에 대해 이야기해 볼게요.
사기 찾기
는 비정상적인 거래 행위를 발견해서 식별되는 경우가 많죠. 임베딩은 정상 계정과 비정상 계정의 행위를 인코딩하고, 이를 구별하는 예측 모델을 훈련시켜서 정상적인 거래와 사기 행위를 구별할 수 있어요. 임베딩은 거래 상대방, 빈도, 연결 밀도 등 그래프 내의 풍부한 정보를 추출해서 정상적인 거래 행위에서 벗어나는 패턴을 나타내는 더 큰 네트워크를 통합하는 데 도움이 돼요.
엔터티 확인 및 명확성
마케팅부터 소매, 금융까지 사용자가 직면하는 일반적인 문제는 고유한 사용자 식별 및 중복 제거(또는 항목, 문서 등)인데요. 데이터의 바다에서 이 문제를 해결하는 데 그래프 임베딩이 큰 도움이 될 수 있어요. 더 큰 그래프에서 각 `Node`와 해당 컨텍스트(`Property`, 이웃, 이웃 등)를 인코딩하면 기본적인 수학을 사용해서 거의 동일한 임베딩을 식별할 수 있어요. `Node` 간의 유사성을 강조해서 여러 사람으로 보이는 것이 실제로는 한 사람인지 확인할 수 있는 거죠.
제품 추천 개선
과거에는 협업 필터링이 추천을 개선하기 위한 일반적인 접근 방식이었는데요. "이 항목을 구매한 사람들은 이러한 다른 항목도 구매했습니다"와 같은 방식이었죠. 임베딩은 을 한 단계 더 발전시켜요.
임베딩은 누군가가 무엇을 샀는지 뿐만 아니라 그 사람이 얼마나 많은 물건을 샀는지, 누가 그 물건을 샀는지, 그 사람들이 무엇을 샀는지 등을 전체 그래프에 걸쳐 인코딩할 수 있어요. 매우 큰 제품 카탈로그에서 그래프 임베딩은 밀접하게 관련된 항목을 거의 조회하지 않는 경우에도 수학적으로 강조 표시하므로 강력한 추천을 지원할 수 있답니다.
신약 발굴
Knowledge Graph는 많은 제약 R&D 팀의 기본이죠. 시스템 생물학은 자연스럽게 그래프 형태를 띠는데요. 유전자, 화학 물질, 질병 간의 연결은 수많은 조건의 원인과 치료법을 암호화하고 있어요. 그래프 임베딩은 각 유전자가 어떻게 연결되어 있는지, 얼마나 멀리 떨어져 있는지, 질병에 대한 중간 노드를 통해 또는 업스트림 경로와의 직접적인 상호 작용 또는 간섭을 통해 유전자를 수정할 수 있는 화학 물질이 무엇인지 등의 정보를 인코딩할 수 있어요. 이렇게 풍부하고 설명적인 임베딩은 링크 예측 모델의 입력으로 사용될 수 있죠. 이 모델은 기존 지식을 사용해서 유전자와 질병, 약물과 유전자 사이의 이전에 알려지지 않은 연관성을 밝혀 유망한 새로운 치료법을 식별한답니다.
이탈 예측
소매점부터 SaaS 플랫폼, 기존 유틸리티 제공업체에 이르기까지 많은 기업이 고객 이탈에 깊은 관심을 갖고 있어요. 사용자가 휴대폰 서비스 제공업체를 떠나기로 결정하는 통신사 이탈이 그 예시인데요. 이러한 고객 결정은 이전 구매, 매장 방문, 고객 서비스 통화 등 공급자와의 모든 상호 작용의 맥락에서 이루어져요. 컨텍스트에는 다른 고객과의 상호 작용(전화 통화, 문자)은 물론 다른 고객의 경험도 포함될 수 있죠. 풍부한 세부 정보를 Knowledge Graph에 담아 각 고객의 경험을 나타내기 위해 임베딩을 훈련한 다음, 해당 임베딩을 사용해서 서비스를 떠날 가능성이 있는 사람을 예측할 수 있으므로 조기 개입을 통해 비즈니스를 구할 수 있어요.
Neo4j Graph Data Science
그래프 임베딩은 데이터에서 예측 요소를 빠르고 안정적으로 학습할 수 있는 강력한 방법이라, 데이터에 숨겨진 모든 연결을 바탕으로 결정을 내릴 수 있게 도와주죠. 하지만 엔터프라이즈 팀의 주요 과제는 최첨단 과학 기술을 신속하고 안정적이며 규모에 맞게 프로덕션에 적용하는 것이에요.
이것이 바로 Neo4j가 도울 수 있는 부분인데요. 고객들은 그래프 임베딩에 대해 알고 있었지만, Neo4j Graph Data Science를 시작하기 전까지는 실제로 사용할 수 없었다고 말해요.
Neo4j는 그래프 분석 및 그래프 기반 ML 분야의 선두 주자로서 더 적은 노력으로 더 많은 데이터 과학을 지원하고 있어요. 저희 데이터 과학 플랫폼은 다음을 결합했답니다:
Neo4j Graph Database: 연결된 데이터를 저장, 유지 및 Query하기 위한 것이에요.
Neo4j Bloom: 연결된 데이터를 시각적으로 탐색하기 위한 것이죠.
Neo4j Graph Data Science, 또는 GDS - 그래프 Machine Learning을 대규모로 실행할 수 있어요.
Neo4j는 즉시 실행 가능한 60개 이상의 알고리즘 및 ML 모델과 항상 추가되는 새로운 모델을 포함해서 다른 어떤 공급업체보다 더 많은 그래프 데이터 과학 기술을 제공해요. Neo4j는 사용자에게 GDS 환경을 벗어나지 않고도 몇 가지 명령만으로 데이터를 변환하고, 예측 기능을 생성하고, 최고 성능의 모델을 훈련 및 선택할 수 있는 기능을 제공하죠.
고객들은 GDS를 사용하면 임베딩에 관한 학술 논문을 읽는 것에서 벗어나 실제로 작업에 적용할 수 있다고 말해요. Neo4j Graph Data Science에는 예측 모델 생성 작업을 크게 줄이고 데이터 유출과 같은 문제를 해결해서 데이터 과학자의 행복과 생산성을 높이는 강력한 기능이 포함되어 있답니다. 저희 구현은 수백억 개의 Node로 확장되도록 고도로 병렬화되어 있으므로 사용할 수 있는 의미 있는 결과를 신속하게 얻을 수 있어요. 저희는 훈련된 모델을 Neo4j에 저장할 수 있는 모델 카탈로그를 통해 MLOps를 지원하고 있답니다.
Neo4j Graph Data Science는 가장 널리 배포된 Graph Database에서 실행돼요. Neo4j Graph Database는 확장 및 재해 복구를 위한 읽기 복제본은 물론 데이터 버전 관리와 같은 엔터프라이즈 기능을 제공하죠.
데이터가 어디에 있든 Neo4j를 사용하면 지원을 통해 쉽게 시작할 수 있어요. Connector, Spark, Kafka, Tableau와 같은 BI 도구는 물론 Python, Java, Go 및 드라이버용 드라이버용 more도 지원한답니다.
Neo4j Bloom은 비즈니스 이해관계자와 데이터 과학자가 데이터와 모든 연결을 자유롭게 탐색해서 협업과 통찰력을 가속화할 수 있도록 지원하는 아름답고 표현력이 풍부한 데이터 시각화 도구에요. 임베딩의 경우 이는 계산에 포함된 모든 데이터의 맥락에서 결과(예측 및 새로 식별된 유사성)를 보는 것을 의미하죠.
Neo4j는 유연하고 클라우드 독립적인 배포를 제공해요. 선호하는 클라우드 플랫폼, 온프레미스에서 Neo4j를 직접 다운로드해서 배포하거나 Neo4j의 완전 관리형 클라우드 제품인 Neo4j AuraDS를 통해 주문형으로 시작해보세요.
주요 시사점
그래프 임베딩이 제공하는 기능을 보여주는 몇 가지 주요 내용은 다음과 같아요.
경쟁 우위를 확보하세요. 그래프 임베딩을 무시할 여유가 없어요. 그래프 임베딩은 신선한 통찰력과 아이디어로 이어지는 새로운 정보를 표면화하죠.
더 나은 예측을 해보세요. 그래프 임베딩은 기능 엔지니어링의 무거운 작업을 수행해서 ML 모델에 포함할 예측 요소를 식별해준답니다.
데이터 과학자의 최신 정보를 빠르게 얻으세요. 해당 분야의 전문가인 데이터 과학자를 찾는 것은 어렵죠. 그래프 임베딩은 데이터 자체에서 학습하기 때문에 전문가가 아닐 수도 있는 데이터 과학자도 효과적으로 데이터를 사용하고 빠르게 완전한 생산성을 발휘할 수 있어요.
데이터에서 전체 가치를 추출하세요. 일부 지역에서는 데이터가 고르지 않게 분포되거나 희박할 수 있어요. 그래프 임베딩은 데이터 상태에 관계없이 데이터를 최대한 활용하는 데 도움이 된답니다. 그래프 임베딩을 사용하면 자주 구매하지 않는 품목에도 추천이 관련돼요.
더 많이 알아보세요. 임베딩은 Knowledge Graph를 통해 학습해요. 이러한 학습 내용을 통합해서 Knowledge Graph를 더욱 풍부하게 만들어보세요.
반복하고 혁신하세요. 다양한 그래프 임베딩 기술을 사용해서 데이터에서 다양한 인사이트를 얻어보세요. 그래프 알고리즘, 쿼리, 시각화를 반복적으로 활용해서 목표한 혁신과 새로운 발견을 이끌어낼 수 있어요.
시작할 준비 되셨나요?
샌드박스의 샘플 프로젝트를 한번 사용해 보시거나, 완전 관리형 클라우드 제품인 Neo4j AuraDB를 시작해 보세요.
Graph Data Science에 대해 더 자세히 알고 싶으신가요? Meredith Corporation, AstraZeneca, NASA처럼 들이 Neo4j Graph Data Science를 어떻게 활용하는지 알아보세요.
GDS
Graph Data Science
Machine Learning
math
t-SNE
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
Wikimedia Commons에 따라 라이센스가 부여된 칠레 ESO Paranal Observatory의 레이저가 인공 참조 별을 생성하는 방법에 대한 표지 이미지.
11월 17일 목요일 1500 GMT/11:00 ET(ET)에 Neo4j의 NODES 2022 라이브 스트리밍 웹캐스트에서 저자 Tomaž Bratanič와 함께 진행된 "Node to Knowledge Graph Embeddings"를 참조하세요.24시간 진행되는 전세계 라이브 이벤트 등록은 무료입니다.
아직 정보 기술 분야에서 일반적으로 사용되는 문구는 아니에요. Graph Embedding은 현재로서는 수학자들의 플레이북에서 빌려온 데이터 과학 용어에 더 가깝죠. (스탠포드 대학교 교수들은 “표현 학습"이라고 부르기도 해요.) 기술 자체로는 엄청 혁신적인 건 아니고요. 기원전 5세기경 그리스 건축가 밀레투스의 이시도르가 아르키메데스 디자인의 이면에 있는 기하학적 매개변수를 발견하고 다른 곳의 다른 규모로 새로운 건물에서 이를 재창조한 순간, 어떤 형태로든 Graph Embedding이 탄생했다고 주장할 수도 있을 정도죠.
어떤 형태로든 솔루션을 그래프로 시각적으로 표현할 수 있다면, 해당 솔루션의 주요 기하학적 구성 요소를 정밀도를 크게 잃지 않고 더 작은 규모의 더 컴팩트한 행렬 또는 심지어 다른 그래프에 매핑할 수 있다는 아이디어인데요. 우리의 목적을 위해 Graph Embedding은 다음을 달성해요. 배열이 일부 구성되어 있는 매우 크고 조밀한 값 행렬을 사용하여 그래프로 플롯할 수 있으며 해당 값이 구성되는 구성 요소를 더 적은 수의 값에 매핑할 수 있어요. 바로 Vector를 사용해서요. 이렇게 하면 본질적으로 동일한 결과를 얻을 수 있죠.
달리 말하면, 우리는 Machine Learning 및 예측 분석과 같은 애플리케이션의 매트릭스를 투영하기 위해 막대한 양의 스토리지를 소비하는 데 많은 어려움을 겪고 있어요. 심지어 거대한 "데이터 레이크"를 구축하기도 하죠. 그 유입구는 우리가 그 뒤에 있는 패턴을 발견할 수 있는 수단(또는 시간)을 찾을 수 있기를 바라는 희망으로 단일 가상 볼륨으로 수집된 처리되지 않은 실시간 원시 데이터 스트림이에요.
처음부터 Graph Embedding을 사용했다면 이러한 모놀리식 데이터 저장소가 필요하지 않았을 수도 있어요. 대신, 우리는 여기저기에 몇 개의 연못을 건설하여 몇 가지 정확도 포인트(일부 애플리케이션의 경우 사용자가 눈치 채지 못할 수도 있음)를 교체하여 꽤 많은 시간을 되돌릴 수 있죠. 월별 S3 스토리지 비용으로 수천 달러를 절약하면서요.
Manning Publications의 저자인 Tomaž Bratanič는 "모든 사람은 수동 기능 엔지니어링을 피하고 싶어합니다."라고 말했어요.데이터 과학을 위한 그래프 알고리즘에서요. "많은 작업이 들어가야 해요. 매우 노동 집약적이죠. 대신 사람들은 이러한 Vector를 자동으로 마법처럼 구성하는 알고리즘을 설계해요. '그럼 두 홉 이웃의 수를 인코딩해야 할까요, 아니면 친구의 친구 수를 인코딩해야 할까요?'라고 생각하면서 많은 생각을 할 필요가 없어요. 클러스터링 계수?' 아니요. 별다른 입력 없이 '마법을 발휘하세요'라고만 말하는 거죠. 이는 비지도 알고리즘이에요.”
Graph Embedding에 대해 자세히 알아보기
Graph Embedding: 데이터를 학습하여 문제를 해결하는 AI by 알리시아 프레임
검사Node Embedding알고리즘 Neo4j 그래프 데이터 과학 라이브러리 매뉴얼에서
그래프 데이터 과학 기초에 대한 전체 무료 과정 Neo4j GraphAcademy에서
핵심 요약
"만약 고급 수학을 사용하여 1,000만 개의 숫자를 보다 관리하기 쉬운 숫자 목록, 예를 들어 2개로 압축할 수 있다면 어떨까요?" Neo4j의 개발자 관계 담당 수석 이사인 David Allen은 이렇게 말했어요. “그럼 우리는 어떤 Node든 (x, y) 줄거리를 조정하는 거죠! 이것이 그래프 시각화가 하는 일이에요. 시간이 걸리죠.n- 차원 그래프를 평면 그림으로 표시하는 데요. 이제 우리는 그것이 지저분해질 수 있다는 것을 알고 있으며 많은 그래프가 너무 풍부하여 2차원으로는 충분하지 않아요. 1,000만 개의 숫자를 우리가 선택한 길이의 Vector로 압축할 수 있는 방법이 있다면 어떨까요? 아마도 64개면 이러한 관계의 풍부함을 포착하기에 충분할 거예요. 그게 Graph Embedding이에요.”
가장 일반적인 수준에서 임베딩은 비록 근사치에 의해서라도 고차 함수를 표현하기 위해 저차 수학적 모델을 사용하는 방법이에요. Graph Embedding이 약속하는 것은 거대한 데이터 테이블을 최소화하고 결과를 신속하게 처리하는 방법이죠. 이는 조직이 데이터를 사용하여 큰 문제를 해결하고 일반적인 테이블이나 구조화되지 않은 데이터 풀에서 Graph Database로 전환하도록 설득할 수 있을 만큼 수익성이 좋은 방법이고요.
임베딩은 조직에게 패턴을 표현하는 데 훨씬 적은 숫자가 필요한 방대한 양의 정보를 통합하는 영리한 방법을 제공할 수 있어요. 기후 변화, 역학, 사회적 불안, 탄소 배출, 산호초 보호 등 인류가 직면한 모든 큰 문제를 해결하기 위해 슈퍼컴퓨터나 거대한 네트워크 데이터 센터의 대규모 스토리지 어레이에 계속 의존할 수는 없죠. 현재 사용 가능한 도구를 사용하는 방법에 대해 좀 더 영리해야 해요. 더 적은 비용으로 더 많은 작업을 수행하는 방법을 배우려면 Machine Learning 기술, 시뮬레이션 및 세계 모델링을 적용해서 처음부터 더 적은 비용으로 더 많은 작업을 수행할 수 있도록 해야 할 거예요.
Allen은 이렇게 말했어요. “좀 더 멋지게 표현하자면, 우리는 n차원 그래프를 더 낮은 차원 공간으로 표현하는 거예요. 엉뚱하게 표현하면 다음과 같아요. 1,000만 개의 숫자 행을 가져와서 64개의 숫자 행으로 바꾸는 거죠. 우리는 단순화라는 이름으로 일부 정보를 기꺼이 잃어버릴 거예요.”
그러한 기술이 언제 꼭 필요하게 되었을까요? Allen은 "64차원을 시각화할 수는 없지만 Machine Learning 알고리즘은 시각화할 수 있어요."라고 말해요.
Allen은 계속해서 “ML 파이프라인의 요점은 이러한 대규모 데이터 플롯을 취하는 거예요. x, y 플롯 — 그리고 그 안에서 패턴을 찾는 거죠. 컴퓨터는 64차원이나 128차원에 대해서는 걱정하지 않아요. 오늘날에는 10,000개의 데이터 포인트에서 패턴을 찾을 수 있어요. 그러나 그래프가 없으면 결코 볼 수 없는 특정 토폴로지 패턴이 있을 거예요. 그래프 임베딩은 ML 알고리즘이 이해할 수 있는 방식으로 토폴로지 패턴을 인코딩해요. 그래프의 복잡성을 훨씬 더 관리하기 쉬운 벡터로 요약하는 거죠.”
주머니 속의 은하계
그래프 삽입에 대해 생각하는 한 가지 방법은 다음과 같아요. 일종의 사고 실험이죠. 특정하고 정확한 순서로 거대한 두루마리에 수학 공식에 대한 가능한 모든 솔루션을 작성할 수 있다고 가정해 봐요. 그리고 벽지와 같은 솔루션을 속이 빈 구 내부에 붙여 넣을 수도 있죠. 다음으로, 천문대의 레이저 유도 망원경처럼 해당 구의 중심에 레이저가 있는 단일 솔루션을 가리킬 수 있다고 상상해 보십시오. 레이저가 가리키는 각도는 솔루션이 어디에 있는지 알려줘요. 레이저의 X 및 Y 각도가 원래 공식에 통합되면 다음과 같은 정보를 얻을 수 있을 뿐만 아니라 해결책은 다음과 같았어요. 그러나 일단 거꾸로 계산하면 what 해결책은 다음과 같아요.
따라서 속일 수 있어요. 실제로는 어느 구체에나 아무 것도 쓰거나 붙여넣을 필요가 없어요. X와 Y 각도는 , 해당 벡터를 인덱스로 사용할 수 있어요. 해당 인덱스를 거꾸로 작업하면 해결책이 있죠.
우리가 방금 설명한 것은 다소 초보적인 방식으로 공간의 2차원을 나타내는 두 개의 부동 소수점 값을 사용하여 알려진 공식에 대한 유한한 해 목록을 표현하는 방법이에요. 이제 이러한 X 및 Y 좌표 변수의 정밀도 수준이 차트에서 벗어나야 한다고 삽입하는 것이 옳을 거예요. 합리적으로 복잡한 수식의 경우 이를 풀려면 128자리보다 훨씬 많은 숫자가 필요하죠.
그러나 3차원보다 큰 공간에서 “레이저 포인터” 벡터를 상상한다면 — 이를 “n차원 공간” — 그런 다음 (n– 1) 수학적으로 해결하기는 더 쉽지만 몇 바이트만 더 소비하는 방식으로 동일한 인덱스를 달성하기 위해 정밀도가 다소 낮은 부동 소수점 값.
New Jersey Institute of Technology의 데이터 과학과 창립자인 David A. Bader 교수는 "그래프 임베딩은 일반적으로 사용돼요. 그래프 표현 학습을 수행하거나 그래프 내의 패턴을 학습하기 위해 Machine Learning 기술을 수행하려고 할 때죠. 패턴이 있는 경우 임베딩은 훌륭한 솔루션이에요. 저는 그래프 임베딩을 가속화하고 이를 그래프 내 기능 학습에 사용하는 여러 조직과 협력하고 있어요."라고 설명했어요.
그래프 임베딩 작업은 기하학적 패턴으로 더 많은 양의 정보를 표현하는 것과 관련이 있어요. Neo4j가 일반적으로 연결된 Nodes의 방대한 그래프로 나타내는 정보 유형은 더 작고 밀도가 높은 그래프로 캡슐화될 수 있죠.
왜 그럴까요? 오늘날 전통적인 데이터베이스 모델은 소위 빅 데이터 구성에 존재하는 모델이라 할지라도 과학적 목적을 위해 실제 시나리오를 정확하고 안정적으로 시뮬레이션하는 데 필요한 용량의 일부를 아직 확보하지 못했어요. 물론, 전통적인 데이터베이스를 사용하여 특정 경제 상황과 상황, 고도로 상호 연결된 물류 및 공급망, 인간 행동 패턴을 모델링하는 것이 가능해요. 하지만 허리케인의 기류 분자는요? 살아있는 유기체의 암세포는요? 인간의 뇌파 활동은요? 아직은 아니죠.
Neo4j의 Allen은 "그래프는 네트워크 형태로 복잡한 시스템 역학을 포착하기 때문에 강력해요. 그래프 임베딩은 모든 네트워크 복잡성을 긴 숫자 값 목록으로 다시 요약할 수 있는 일종의 게이트웨이예요. 그런 다음 이러한 임베딩을 모든 종류의 Machine Learning 알고리즘(그래프 기반이 아닌 알고리즘에도 적용 가능)에 적용할 수 있으므로 그래프 토폴로지의 핵심 부분을 보고 이해하고 교훈을 얻을 수 있어요. 소셜 네트워크에서 누가 누구와 가까이 있는지 같은 교훈을 얻는 거죠.”
그래프 임베딩에 대해 자세히 알아보기
Neo4j 및 Emblaze를 사용한 그래프 임베딩 이해Nathan Smith, 데이터 과학을 향하여
node2vec을 사용하여 기존 ML을 Neo4j Graph에 연결데이브 부틸라
GraphSAGE를 사용한 Neo4j의 그래프 임베딩작성자: Sefik Ilkin Serengil
스파링 시합
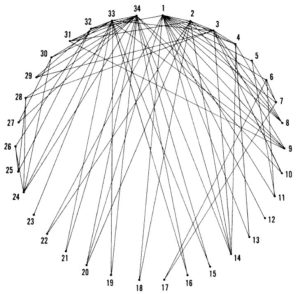
>문제가 1970년경에 처음으로 밝혀진 경위는 다음과 같아요. 당시 Wayne Zachary라는 친구는 처음으로 대학 가라데 클럽 회원들 사이에서 논쟁을 벌이는 두 파벌을 나타내는 수학적 모델을 만들 수 있는지 고려하기 시작했어요.
전쟁, 질병, 기근이 많은 인구의 생존을 위협하는 더 넓은 범위의 인간 사회에서와 마찬가지로 이 전투도 인플레이션을 중심으로 이루어졌어요. 한 파벌은 클럽 창립자에게 맹렬히 충성했으며, 회비를 인상하려는 그의 바람에도 불구하고 그의 봉사에 헌신했어요. 다른 파벌은 가격을 안정적으로 유지하겠다고 약속하고 포기할 의사가 없는 클럽 회장을 지지했어요. Zachary는 어떤 회원이 어떤 파벌에 합류할지 예측할 수 있는 공식을 통해 수년 동안 클럽 회원 간의 상호 작용을 그래프로 묘사할 수 있는지 궁금했어요.
다음 7년 동안 Zachary는 34개 클럽 회원 모두의 관계를 쉽게 관련시킬 수 있는 방식으로 표현하기 위해 후보 모델을 만들었는데, 일부는 못과 실을 사용한 것으로 보여요. 그의 첫 번째 반복이 아래에 나타나 있어요. 처음에는 그의 Mark I 그래프가 충분히 합리적으로 보였죠.
하지만 생각만큼 실용적이지 않았어요. 우선, 서클 내에서 회원의 위치는 완전히 임의적이었거든요. 결과적으로 연관성을 나타내는 선의 길이는 의미가 없게 된 거죠. 예를 들어, 회원 #31은 #2, #9와 연결되었는데, #9와 #31을 연결하려면 #2와 #31에 필요한 것보다 훨씬 더 많은 실이 필요했어요. 이러한 길이 값이나 그 사이의 거리는 정보를 제공하지 못했죠. Zachary가 회원을 원이 아닌 정사각형으로 배열했다면 그래프는 그만큼 많은 정보를 전달했을 테지만, 그의 연관성을 나타내는 데이터는 상당히 다르게 나타났을 거예요.
Zachary는 다양한 접근 방식을 시도했고, 마침내 컴퓨터 알고리즘으로 구현할 수 있는 시스템을 발견했는데, 그게 바로 이었어요.
여기서 이진수 표는 각 클럽 회원 쌍 간의 연관성 유무를 나타내요. 인접 행렬은 정보를 제공하고 인코딩할 수 있는 개념인 거죠.
Neo4j 시대보다 30년 전에 출판된 Daniel F. Stubbs와 Neil W. Webre의 1985년 교과서에는 인접 행렬에 대해 몇 마디 언급되어 있어요. 가라데 클럽 회원과 같은 데이터 세트의 회원이 Node로 선언되고 원자 데이터 유형을 사용하여 정의되었다고 가정해 볼게요 (Stubbs 및 Webre는 Pascal 언어를 사용했죠). 인접 행렬은 값이 부울로 선언될 수 있는 2차원 배열 변수 내에서 정의될 수 있어요. Webre와 Stubbs는 다음과 같이 썼어요.
이 접근 방식의 가장 큰 단점은 Node를 삽입하거나 삭제할 수 없다는 거예요. Node 집합을 탐색하는 것처럼 Node에 대한 설명 정보를 저장하는 것도 어렵죠. . . 배열 Node는 각 Node와 관련된 정보를 저장하는 데 사용돼요. 이 접근 방식을 사용하면 Node를 삭제하고 삽입할 수 있지만 (최대 []), 배열 그래프의 Index 값에 대응하려면 배열 Node에서 요소를 이동해야 해요.
따라서 내용을 원래 있던 위치로 다시 섞는 정교하고 지루한 방법 없이는 그래프를 발전시킬 수 없어요. 저자는 이것이 파스칼에서 어떻게 달성될 수 있는지를 보여주기 위해 다음 수십 페이지를 소비했어요. 그러나 그들의 그래프는 반임의적인 행과 열 내에 Node를 배치하는 데 국한되어 파스칼이 무엇을 언제 섞을지 알 수 있었죠.
소셜 네트워크 모델링에 관한 Zachary의 1977년 논문은 Node 간 연결을 나타내는 최선의 접근 방식으로 인접 행렬을 고수했어요. 최적의 솔루션, 즉 34명이 훨씬 넘는 소셜 네트워크에 더 적합한 접근 방식을 찾으려면 Zachary의 뒤를 이어(또는 아마도 이 경우에는 그의 카타 단계) 학술 연구자들의 노력이 필요할 거예요. 이는 Neo4j가 Graph Database를 나타내는 데 사용하는 것과 마찬가지로 네트워크 그래프 생성으로 시작되죠. 그런 다음 알고리즘을 사용하여 임베딩(다축 기하학적 공간에 정보가 더 간결하게 포함된 그래프)을 생성하는 거예요.
Wayne Zachary의 1977년 지역 가라테 클럽 소셜 네트워크 표현을 사용한 저수준 임베딩 시연이에요. 스탠포드 네트워크 분석 프로젝트에서 제작되었답니다.
가라테 클럽 그래프의 일반적인 시각화에서 Neo4j의 Allen은 이렇게 설명했어요. "그래프의 각 사람은 34개의 숫자로 구성된 행렬의 벡터로 표현되죠. 그런데 만약 34개의 node 대신 3,400만 개의 node가 있다면 어떨까요? 3,400만 x 3,400만 행렬은 감당하기 힘들 거예요."
Scott Fulton의 나이아가라 폭포 이미지 (2022년 10월)
캐스케이드 효과
Tomaž Bratanič는 이 점에 대해 더 자세히 설명했어요. "임베딩 알고리즘에 대한 입력을 인접 행렬로 생각해 보세요. 인접 행렬은 열과 행의 수가 그래프의 node 수와 동일한 정사각형 행렬이잖아요. 예를 들어, 백만 개의 행과 백만 개의 열이 있는 정사각 행렬로 작업한다고 가정해 볼게요. 이걸 가장 기본적인 Machine Learning 알고리즘에 입력하려고 한다면 – 예를 들어, Random Forest – 백만 개의 행은 큰 문제가 아닐 수 있어요. 하지만 백만 가지 기능을 갖춘 Machine Learning 모델을 구축하는 건 가장 효율적인 방법은 아닐 수도 있죠.”
백만 개의 node 인접 행렬에 한 행을 추가하거나 해당 행렬에서 한 행을 페어링하는 간단한 작업도 테이블 기반 데이터베이스의 경우 엄청난 작업이 될 수 있어요. Bratanič는 Machine Learning 모델의 경우 기록 유지 작업 외에도 전체 시스템을 재교육해야 할 수도 있다고 지적했답니다.
Bratanič는 데이터 과학자들 사이에 임베딩에 관해 두 가지 사고방식이 있다고 덧붙였어요. 한 그룹은 동일성 또는 동일성을 기반으로 그래프를 배열하는 데 가장 관심이 있죠. 동성애적으로— node 간 특성의 유사성이요. 예를 들어, 소셜 네트워크의 경우 node가 대표하는 사람들이 더 많은 수의 인지된 속성을 공유할 때 node가 클러스터링되거나 이웃될 수 있어요. 그런 그룹에 대한 임베딩은 코사인 유사성과 유클리드 거리 함수를 활용해서 동질성 수준을 인코딩하는 데 도움이 될 수 있다고 그는 설명했죠. 그래프에서 node의 위치가 가까울수록 더 작은 코사인 유사성 변수를 갖게 되는 거예요.
두 번째 그룹은 특정 다른 node 주변의 인접한 node 밀도에 더 관심이 있어요. 다른 사람과 더 큰 친화력을 갖는 것처럼 보이는 이러한 "슈퍼 node"는 이러한 슈퍼 node가 서로 팔로우하지 않는 경향이 있는 경우에도 따라야 하는 특성(예: 소셜 네트워크의 구성원인 유명인)을 나타낼 수 있죠. 또한 네트워크 내의 소규모 클러스터나 커뮤니티 사이에 "브리지"를 형성하는 경향이 있답니다. Bratanič는 "그들이 없었다면 네트워크의 일부 부분의 연결이 끊어졌을 거예요. 임베딩을 사용해서 임베딩 공간에서 해당 node를 코딩할 때 해당 브리지가 출력과 유사한 임베딩을 갖기를 원할 거예요."라고 말했어요.
Neo4j의 David Allen은 "여기에 문제가 있어요. 일반적으로 Machine Learning 알고리즘은 사용자가 제공하는 데이터에서 패턴을 찾죠."라고 말했어요. "고객의 우편번호, 생년월일, 지출 요약일 수도 있고요. 고객에게 패턴이 무엇인지 알려주지 않으면 ML 알고리즘은 고객의 토폴로지 패턴을 배울 수 없어요.
“Graph Embedding은 복잡한 시스템 역학에 대한 완전히 새로운 종류의 정보를 컴퓨터에 제공하는 방법이에요."라고 그는 계속 말했어요. "데이터베이스가 기존 패턴을 학습하고 새로운 패턴을 예측하는 방식은 이전과 크게 다르지 않아요. 하지만 더 나은 정보를 제공했기 때문에 개선된 거죠."
자금세탁 방지
자금세탁방지(AML) 탐지 시스템 사례를 한번 살펴볼까요? JPMorgan Chase에서 개발 중인 것처럼요. 관계형 트랜잭션 데이터베이스를 활용하는 일반적인 시스템은 트랜잭션 분석만 수행할 수 있어요. 자금 이체 규모, 계좌 소유자 ID, 이체가 시작된 시간 등 개인 기록의 특정 특성을 조사할 수 있죠. 이러한 거래에 적용되는 최고의 알고리즘조차도 우려되는 패턴을 격리하는 데 어려움을 겪어요. 그렇게 하더라도 그 우려 사항이 무엇인지, 무엇이어야 하는지가 항상 명확하지는 않고요. 본질적으로 거래 시스템에 대한 사기 패턴이 어떤 모습인지 확립하는 유일한 방법은 미리 확립된 "의심스러운 행동"의 인스턴스를 사용하여 모델을 훈련시키는 것이에요. 이는 오슬로 노르웨이 컴퓨팅 센터의 한 팀이 수행해 온 작업이죠. PDF]. 최근 논문에서 노르웨이 팀은 다음과 같이 썼어요.
지도 학습은 일반적으로 알려진 결과/레이블이 있는 데이터를 사용할 수 있는 경우에 선호돼요. AML의 경우 다른 유형의 금융사기와 달리 금융기관에서 자금세탁 용의자가 실제로 범죄를 저지른 것인지 알아내는 경우가 거의 없기 때문에 문제가 되죠. 그러나 실제 자금 세탁 대신 "의심스러운" 행동을 모델링하여 이 문제를 해결할 수 있어요.
이 맥락에서 "의심스럽다"는 것은 NCC 팀이 어떤 이유로든 이전에 위험 신호가 있었던 행동을 의미해요. 지도 학습을 위해서는 이러한 원칙과 패턴이 미리 확립되어 있어야 하죠. MedoidAI의 Christina Chrysouli와 Antonis Markou가 쓴 글처럼 2021년 10월 회사 블로그에 "대부분의 Machine Learning 알고리즘은 필요한 엔터티의 특성이 모두 제공되는 경우에만 작동할 수 있어요."
대조적으로 Graph Embedding을 사용하면 AML이 덜 감독되거나 감독되지 않는 접근 방식을 채택할 수 있어요. 알고리즘은 지금까지 누구도 본 적이 없는 패턴을 감지할 수 있는 거죠. 임베딩을 시도했다면 NCC 모델에 쉽게 나타날 수 있었을 거예요.
예를 들어, "5번의 이체로 인해 많은 돈이 여러 계좌 사이에서 큰 원으로 이동하게 되었나요? 이것이 임베딩이 제공할 수 있는 것이죠."라고 Allen은 말했어요.
체계적 위험
Graph Embedding을 통해 실현 가능성 영역에 추가된 또 다른 기능 클래스는 다음과 같아요.. Neo4j 영업 컨설턴트인 Joe Depeau가 설명했듯이 전염병이 최고조에 달했을 때 놀라울 정도로 많은 고객이 소위 "공급망 사용 사례"에 대한 통찰력을 얻기 위해 Neo4j를 찾았어요.
Depeau는 "그것을 자세히 조사해 보면 실제로 의미하는 바는 고객 네트워크의 시스템적 위험을 이해하고 싶어한다는 것이죠."라고 말했어요. "예를 들어 여행사, 즉 대형 패키지 여행사가 있다고 가정해 볼게요. 아무도 휴가를 보낼 수 없기 때문에 해당 회사가 코로나19 기간 동안 어려움을 겪을 것이라는 것을 모두가 알고 있었죠."
여행 및 레저 회사의 일반적인 위험 수준을 알면 역사적 최고치에 도달하여 회사의 존재 자체가 위험해질 수 있으며, 금융 및 물류 회사는 금융 거래를 판단합니다.from 그 회사들 to 다른 조직은 나중에 사라질 거예요. "음식 제공업체인가요? 청소 회사인가요? 법률 회사인가요? 부동산 중개인인가요? 그 사람들의 돈은 어디로 가나요?"
갑자기 가시성이 핵심 미덕이 되었어요. 그 동안, UN 세계관광기구가 예상한 세계 관광 산업은 정규 수입의 1/3을 잃을 수 있으며, 이로 인해 최소 15%의 관광 일자리가 즉시 해고될 위험에 처하게 돼요. 많은 조직에서 작업해야 하는 유일한 데이터는 관계형 프레임워크로 관리되는 트랜잭션 데이터였어요. 그러나 전 세계적으로 금융 고객이 이러한 위험으로부터 자신을 보호할 수 있도록 리소스를 재분배하는 데 충분한 시간을 두고 해당 데이터를 사용하여 예측 및 예측을 렌더링하려면 슈퍼컴퓨터가 필요하죠.
Depeau는 "그들은 이것이 네트워크에 어떤 영향을 미칠지에 대한 결정을 정말로 원했어요. 그리고 그들이 이러한 회사 중 일부를 도울 수 있는 리소스가 있다면 어디에 적용하는 것이 가장 좋을까요? 그 공간에서 데이터 과학 분야는 정말 흥미로웠어요. 모델 실행을 시작하고, 임베딩을 생성하고, 특정 회사가 위험에 처해 있는지, 주변 네트워크로 인해 얼마나 위험에 처해 있는지 예측하는 것이죠."라고 말했어요.
사회 전체로서, 그리고 우주에 떠 있는 푸른 바위처럼, 세계는 수많은 시스템적 위험에 직면해 있어요. 이러한 위기 중 하나만 발생했을 때 조직에서는 이 위험을 모델링하는 데 사용했던 도구가 위험 수준이 상대적으로 낮았던 상황(예: 17세기) 이외의 상황에는 부적절하다는 것을 깨달았죠. 이제 한 가지 위험은 가라앉고, 가라데 클럽에서의 논쟁보다 훨씬 복잡하지 않을 수도 있는 문제를 놓고 사회 집단과 사회가 분열되는 경향을 포함하여 다른 위험이 증가하고 있어요.
Graph Embedding은 솔직히 말하면 인공지능이 아니에요. 응용과학이죠. 그것을 적용하는 것은 이제 우리 지적인 사람들에게 달려 있어요.
Graph Embedding에 대해 자세히 알아보기
Deep Learning을 위한 Graph Embedding 작성자: Flawnson Tong, 데이터 과학을 향하여
단계 조심하기: 그래프 어텐션을 통해 노드 임베딩 학습 [PDF] Google AI와 협력하여 University of Southern California 연구원이 작성
프로세스 중심 사례 기반 추론에서 그래프 임베딩 기술 사용막시밀리안 호프만(Maximillian Hoffman)과 랄프 버그만(Ralph Bergmann), 독일 트리어대학교
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
Knowledge Graph로 구동되는 RAG 애플리케이션에서 부모-자식 관계, 질문 기반, 주제 요약과 같은 그래프 데이터 모델을 사용하는 경우를 알아볼까요?
Microsoft Designer에서 생성됨
Retrieval-Augmented Generation(RAG) 애플리케이션을 구축할 때 문서를 벡터 또는 Graph Database에 넣고, 임베딩을 생성하고, 코사인 유사성을 실행하고 싶은 유혹이 들 수 있어요.
이 글에서는 이러한 애플리케이션을 향상시키는 데 사용할 수 있는 몇 가지 대체 그래프 데이터 모델과 각 모델이 제공하는 고유한 이점에 대해 설명할게요. 이 글을 읽기 전에 여러분이 Graph Database와 RAG에 어느 정도 익숙하다고 가정할게요.
여기에는 GitHub 저장소가 포함되어 있고, 다음을 통해 이러한 데이터 모델을 생성하고 탐색하는 코드가 들어있어요. arrows.app 또는 Neo4j 브라우저를 사용하면 자신의 애플리케이션에 대한 데이터 모델을 수정할 수 있어요.
Neo4j
Neo4j는 벡터 검색을 수행할 수 있는 벡터 인덱싱 기능이 있는 Graph Database를 제공해요. 다음을 사용해서 로컬에서 Neo4j를 사용해 볼 수 있어요: 데스크톱 버전 또는 클라우드 호스팅 환경에서 Neo4j AuraDB를 무료로 사용할 수 있어요. 데이터베이스를 초기화할 때 Neo4j 버전 ≥ 5.13을 실행해서 벡터 인덱싱 기능이 있는지 확인하세요.
Vector Embedding
Vector Embedding은 미디어를 수학적으로 나타내는 일련의 숫자예요. 이는 전통적으로 단어와 문장으로 수행되었지만 이제는 오디오, 이미지 및 비디오를 Vector Embedding으로 인코딩하는 것도 가능해요. 벡터의 길이를 차원이라고 해요.
Neo4j는 최대 4096차원의 벡터를 지원하며 일반적인 값은 768 및 1536이에요.
[0.123, -0.423, 0.519, ..., -0.942]
컨텍스트 검색
반환된 컨텍스트는 사용자 질문 임베딩과 그래프에 있는 텍스트 임베딩 간의 계산된 유사성 점수에 따라 결정돼요.
일치하는 임베딩에서 검색된 텍스트를 분리하는 것이 좋아요. 이는 원시 청크에 삽입 시 인코딩된 정보를 희석시킬 수 있는 필러 단어와 추가/충돌 정보가 포함될 가능성이 높기 때문이에요.
더 작은 및/또는 처리된 텍스트 청크를 포함함으로써 유사성 일치를 더 정확하게 만들 수 있으며, 그래프 관계를 탐색하여 응답 생성을 위해 LLM에 반환되는 텍스트를 제어할 수 있어요.
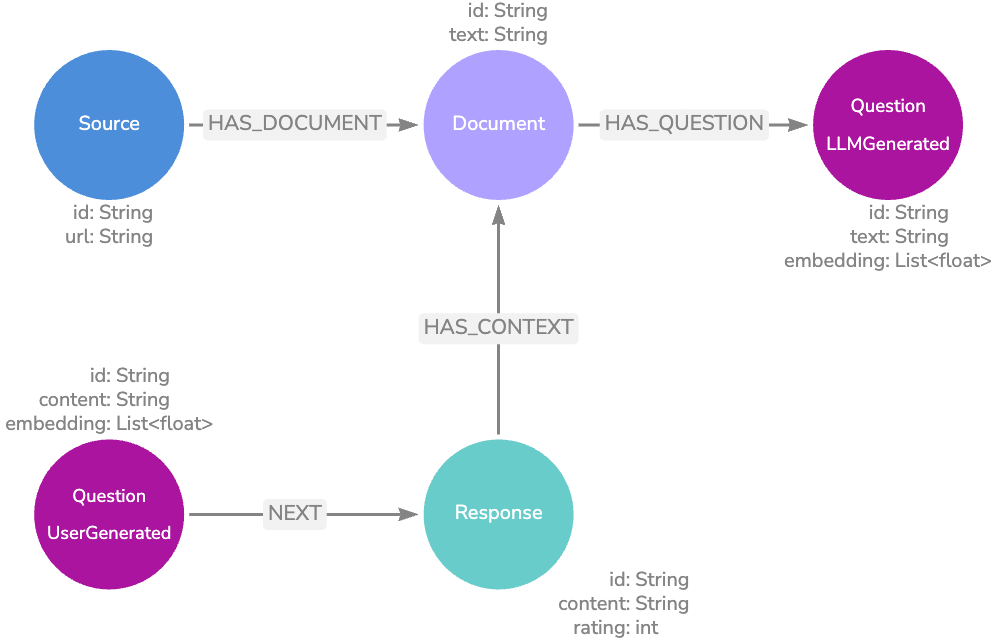
기본 그래프 데이터 모델
이 그래프 데이터 모델은 문서 `Node`에 텍스트 청크를 저장하고 반환된 텍스트에서 일치하는 임베딩을 분리하지 않아요. 문서 `Node`의 임베딩 속성에 대해 벡터 검색을 실행하여 LLM에 컨텍스트로 반환할 가장 관련성이 높은 텍스트를 찾을 수 있어요. 원한다면 `Relationship`을 탐색하여 각 텍스트 덩어리의 출처를 찾아 인용을 제공할 수도 있어요.
이 모델은 개념 증명에 적합하지만 크게 개선될 수 있으며 생산 애플리케이션에 더 나은 옵션이 있어요.
기본 그래프 데이터 모델
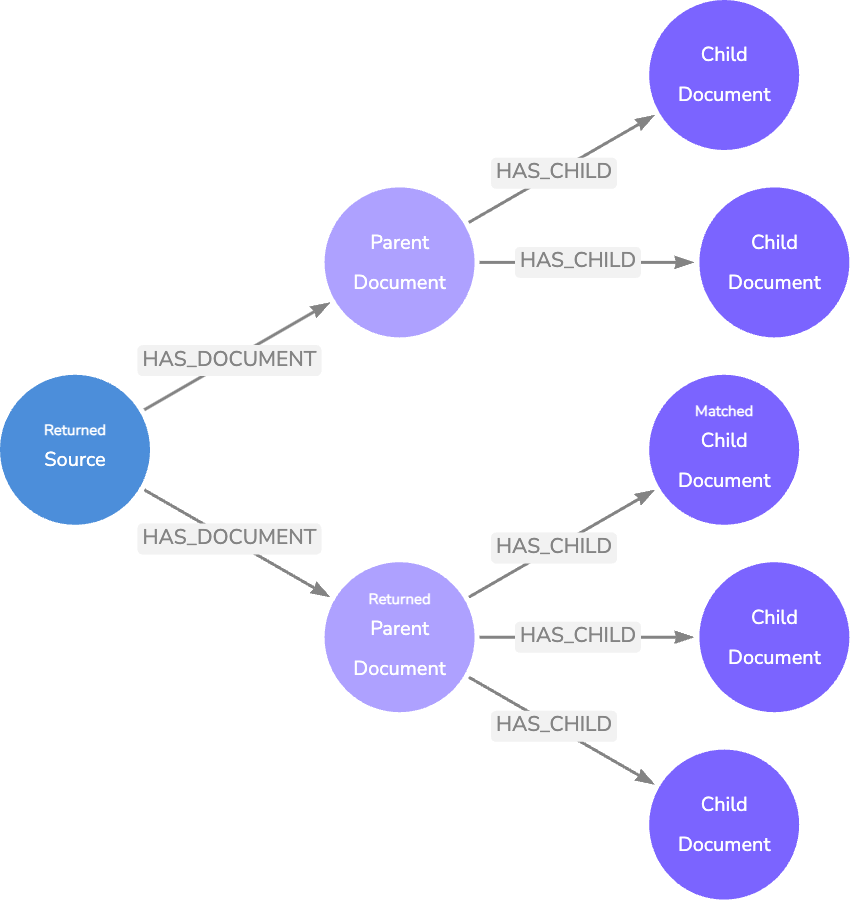
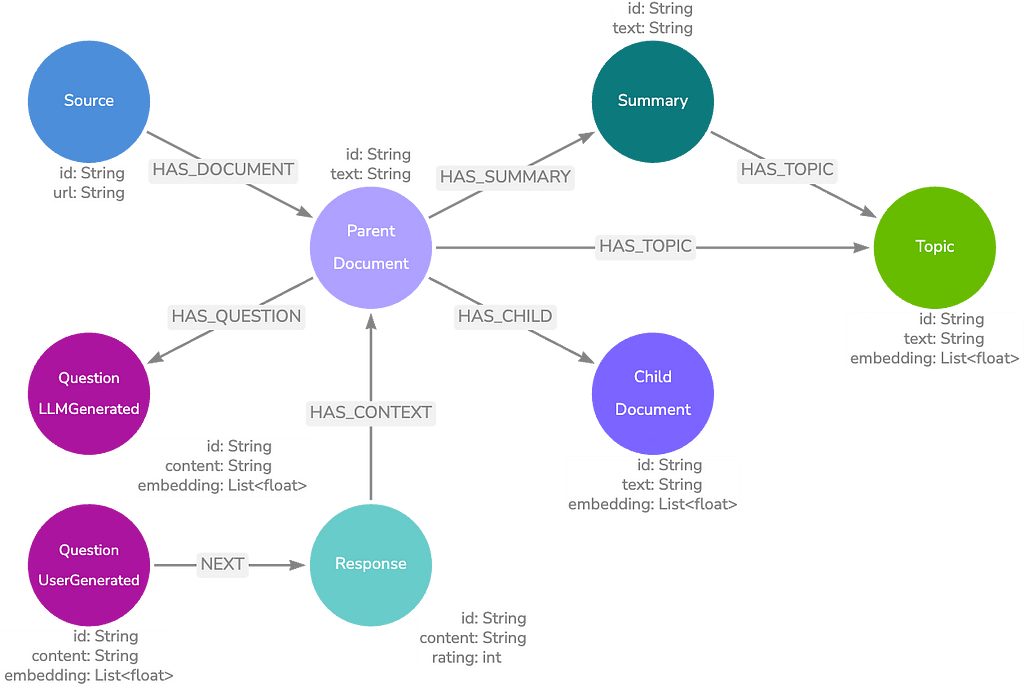
부모-자식
부모-자식 모델은 기본 모델과 유사하지만 텍스트 덩어리를 더 세분화하여 예상 질문에 더 가까운 길이를 만들어요. 이렇게 하면 질문과 일치하는 텍스트 간의 정보 세분성이 유지되므로 한 단락에 대해 몇 단어를 일치시키지 않아요.
하위 `Node` 포함 일치 항목이 있으면 `Relationship`을 탐색하여 하위 텍스트와 주변 텍스트가 포함된 상위 `Node` 텍스트를 검색할 수 있어요. 이 방법은 보다 정확한 벡터 검색 일치를 제공하는 동시에 컨텍스트가 풍부한 결과를 반환해요.
상위-하위 데이터 모델
애플리케이션에서 일반적인 질문의 길이를 찾으려면 실험이 필요하지만 문서 채팅 애플리케이션에서는 140자가 표준 길이인 것으로 나타났어요.
일치 및 반환된 `Node`의 예
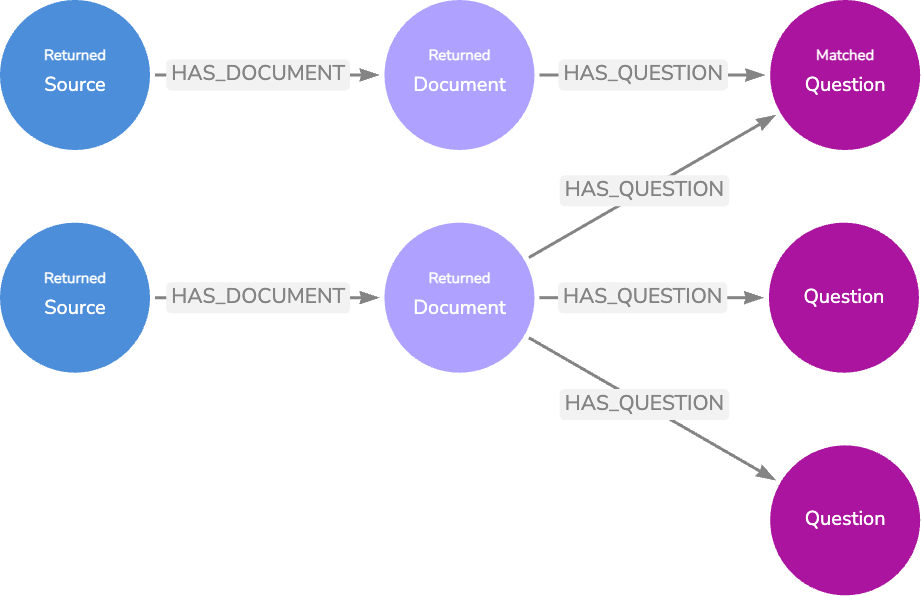
질문
이 다음 데이터 모델은 질문 `Node`를 답변에 대한 유용한 컨텍스트가 포함된 문서에 연결하여 기본 모델을 더욱 확장해요.
문서 텍스트를 LLM에 전달하고 텍스트가 답변할 수 있는 질문을 반환하도록 요청하여 질문을 생성할 수 있어요. `Knowledge Graph`에 애플리케이션 활동을 기록하여 실제 사용자 질문을 제공할 수도 있죠.
질문 데이터 모델
여기에는 두 가지 검색 옵션이 있어요.
첫 번째 옵션은 LLM에서 생성된 질문에 대해 `Vector Embedding` 검색을 수행하고 관련 문서 `Node` 텍스트를 응답 생성을 위한 컨텍스트로 반환하는 것이에요.
LLM 생성 질문에 대한 일치 및 반환 `Node`의 예
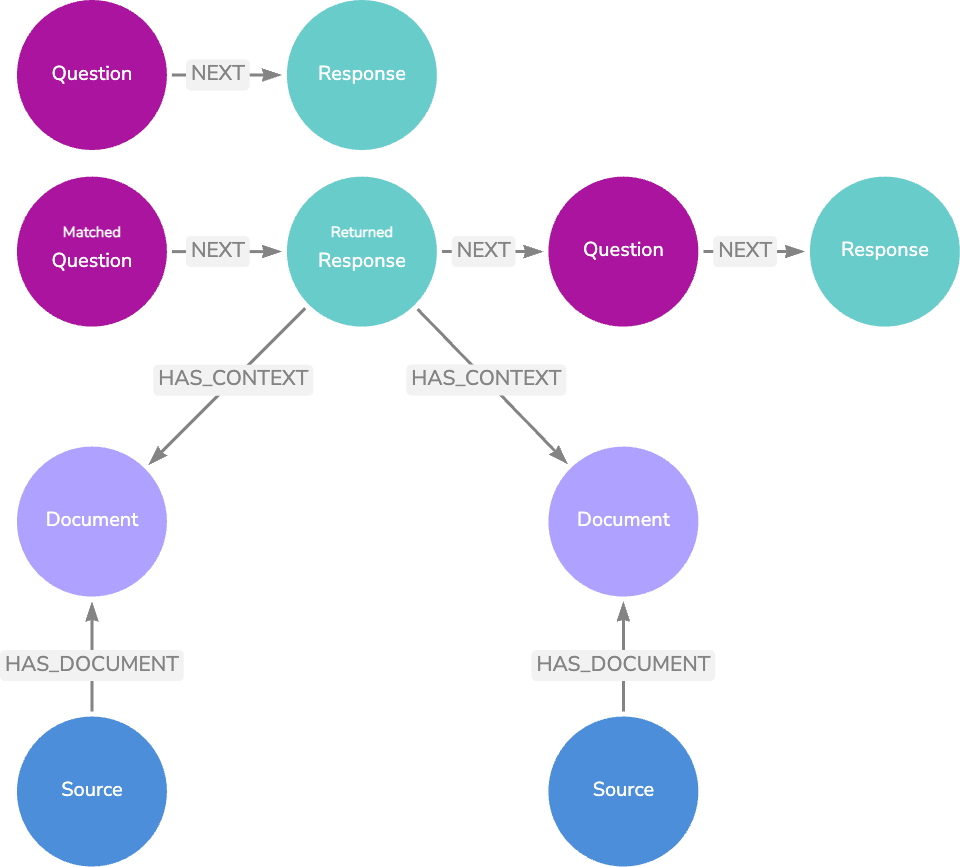
두 번째 옵션은 로깅의 실제 사용자 질문을 일치시키는 것이에요. 질문이 높은 평가를 받은 LLM 응답 `Node`와 관련이 있는 경우 LLM 응답 생성 단계를 완전히 우회하여 해당 `Node`의 텍스트를 반환할 수 있어요. 관련 문서 또는 소스 `Node`의 관련 정보가 이미 응답 텍스트에 있으므로 관련 문서 또는 소스 `Node`를 반환할 필요가 없죠.
사용자 생성 질문에 대한 일치 및 반환 `Node`의 예
주제 및 요약
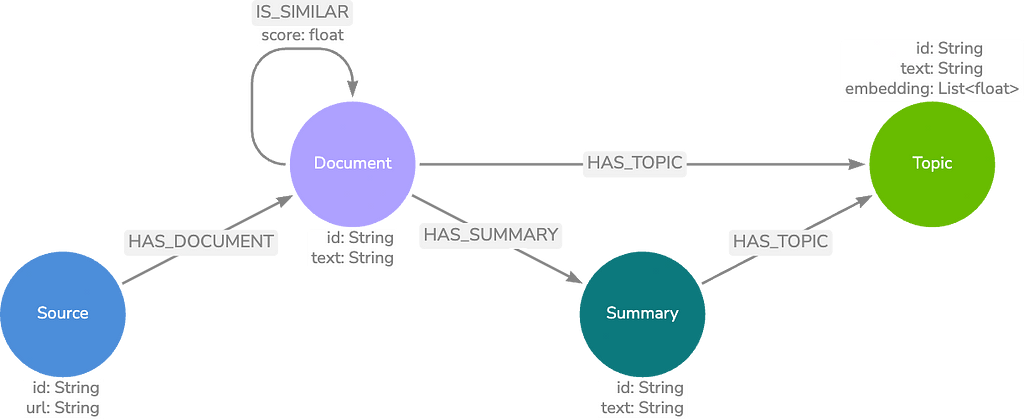
다음 모델 유형에는 Neo4j를 사용해야 해요. Graph Data Science(GDS) 라이브러리 말이죠. 우리는 GDS를 사용하여 문서 `Node`의 커뮤니티를 찾고 이러한 각 커뮤니티에 대한 요약을 생성하여 기본 데이터 모델을 구축해요.
커뮤니티는 `IS_SIMILAR` `Relationship`의 문서 `Node` 간 KNN 유사성 점수를 포함하는 텍스트를 기반으로 해요. 이러한 요약을 요약 `Node`에 저장하고 요약 텍스트에서 엔터티 추출을 수행하여 주제를 찾아요. 이러한 항목을 주제 `Node`에 저장하면 `Vector Embedding` 검색 외에도 키워드 검색을 수행할 수 있죠.
주제 및 요약 데이터 모델
가능한 검색 프로세스는 다음과 같아요.
주제 `Node` 텍스트 임베딩에 대한 `Vector Embedding` `Index` 검색,
발견된 상위 k개의 주제 `Node`에서 연결된 문서 `Node`까지의 그래프 순회,
발견된 문서 풀에서 `Vector Embedding` `Index` 검색 및
응답 생성을 위해 상위 k개 문서 `Node` 텍스트 및 관련 URL을 LLM에 반환합니다.
데이터 모델 결합
이러한 모델은 개별적으로 또는 조합하여 수행하여 애플리케이션의 기능을 향상시킬 수 있어요.
아마도 사용자가 생성한 질문을 일치시키고 싶지만 근접한 일치 항목이 없으면 상위-하위 아키텍처의 하위 `Node`를 일치시키세요.
주제 및 요약 `Node`는 검색 향상 이상의 귀중한 정보를 제공할 수도 있어요. `Knowledge Graph`가 특정 질문에 대한 답변을 제공할 수 있는지 검증하기 위해 메타 분석에 사용할 수 있죠.
부모-자녀 + 질문 + 주제 및 요약 데이터 모델
결론
`RAG` 애플리케이션을 위한 그래프 데이터 모델링은 지속적으로 개발되고 있으며 계속 발전하고 있어요. 위에서 논의한 모델은 필요에 따라 사용 사례에 맞게 수정될 수 있으며 여러분의 프로젝트에 영감을 줄 수 있기를 바라요. 여기에는 GitHub 저장소 다음을 통해 이러한 데이터 모델을 생성하고 탐색하는 코드가 포함되어 있어요. arrows.app 또는 Neo4j 브라우저.
일부 모델은 `Knowledge Graph`에 직접 애플리케이션 활동을 기록할 때 가장 잘 작동해요. Dan Bukowski와 저는 블로그 시리즈에서 `Knowledge Graph` 로깅 스타일의 이점을 자세히 설명합니다. 맥락이 전부다.
그래프 데이터 모델
RAG
Retrieval-Augmented Generation
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
오늘날 대부분의 대규모 조직에서는 데이터가 사일로에 갇혀 있다는 점을 인지하고 있을 거예요.
데이터 연결이 끊어지면, 보고서가 불완전해지고 제대로 활용하기 어려워지죠. 그래서 데이터 사일로를 통합해서 보여주는 보고서가 필요한 거예요. 그래야 조직 내에서 중요한 정보를 찾고, 비즈니스 성공에 도움이 되는 정확한 정보를 실행하고 제공하는 부서의 능력을 확신할 수 있거든요.
NoSQL: 데이터 사일로에 대한 해답
대부분의 조직은 데이터 사일로 문제를 야기했던 도구와 기술로는 그 문제를 해결할 수 없다는 걸 이미 알고 있어요. 그래서 지난 몇 년 동안 NoSQL 데이터베이스와 기술이 개발되고 배포되는 걸 볼 수 있었죠. NoSQL은 데이터를 더 빠르고, 더 큰 규모로, 더 민첩하게 통합하는 데 도움을 주거든요.
이 강력한 새 데이터베이스와 플랫폼은 기존 방식보다 데이터 통합 시간을 단축시켜 주지만, 개발자 중심이라는 또 다른 과제를 안겨주죠. 특히, 이러한 최신 기술을 개발하고 사용하는 데 필요한 새로운 기술을 습득해야 해요.
우리는 데이터베이스 르네상스라는 멋진 시대에 살고 있고, 멋진 새로운 기술들을 모두 가지고 있지만, NoSQL 전문 지식은 아직 상대적으로 새롭고 발전하고 있어요. 40년 넘게 사람들은 SQL 기반 기술을 사용해서 데이터 관리 및 통합 솔루션을 개발해 왔거든요. 마치 40년 동안 사람들이 오른손으로 데이터 관리를 연습해 온 것과 같은 거죠.
NoSQL의 최첨단에 있는 사람들은 와서 데이터로 무엇을 할 수 있는지 보여주면서 이렇게 말해요. "보세요, 우리는 귀하의 데이터를 사용해서 유연하고 안전하게 대규모로 결과를 제공하고, 현재 수행하는 시간의 1/4 만에 통찰력을 제공할 수 있도록 도와드릴 수 있습니다!" 개발자와 기업은 우리의 말을 듣고 기뻐하며 "좋아요, 한번 해봐요! 어떻게 하면 되죠?"라고 외치죠. 그러면 우리는 "쉬워요! 이 새로운 기술로 성공하기 위해 우리가 할 일은... 왼손을 사용하도록 요청하는 것뿐입니다."라고 대답하는 거예요.
모든 기술 뒤에는 사람이 있습니다
기술 사일로 위에는 사람들의 사일로가 존재하죠. 이러한 기술 통합을 구현할 때, 새로운 시스템을 활용해서 최적의 결과를 얻으려면 변경 관리와 비즈니스 프로세스를 업데이트해야 하는 어려움이 있어요.
At FactGem에서는 코드를 작성하지 않고도 데이터를 통합할 수 있는 방법을 제공하고 있어요. FactGem의 엔지니어링 팀은 비즈니스 사용자가 직접 하지 않아도 되도록 통합의 복잡성을 처리하는 부담을 덜어준답니다.
결과적으로 데이터 통합 논의가 반드시 IT 부서에서 시작될 필요는 없어요. FactGem의 Data Fabric 애플리케이션은 기술 지식이 없는 사용자도 서로 다른 데이터 사일로를 신속하게 통합하여, 이전에는 단절되었던 데이터에 대한 통합 보고서를 제공하는 데 사용할 수 있답니다.
만약 여러분이 화이트보드에 조직의 데이터에 대한 entity와 relationship을 그릴 수 있다면, FactGem을 사용해서 데이터를 통합할 수 있어요. 정말 간단하죠?
FactGem 소개
FactGem은 데이터 소스를 지정하고 필요한 소스만 로드할 수 있어요. 필요한 소스의 attribute만 필요에 따라 가져오는 거죠. WhiteboardR에서 관심 있는 소스에 대한 통합 모델을 만드는 것부터 시작한답니다.
다음으로, MappR을 사용해서 데이터 소스와 관심 있는 attribute를 WhiteboardR 모델에 매핑해요. 매핑이 완료되면 MonitR을 사용해서 데이터를 FactGem에 로드하여 통합 모델에서 즉시 액세스하고 query할 수 있어요. FactGem의 REST API, Tableau와 같은 BI 도구에 대한 웹 데이터 연결 또는 사용자 지정 추출을 통해 데이터에 액세스할 수 있답니다.
FactGem의 기업용 제공을 통해 그래프를 직접 활용할 수 있고, Cypher도 사용할 수 있어요.
FactGem: 그래프 초보자에게 적합
Neo4j 커뮤니티에 있는 우리는 Graph Database 기술의 가장 큰 장애물 중 하나는 사람들이 익숙하지 않고 그래프 기술이 무엇을 할 수 있는지 모른다는 점이라고 생각해요.
대부분의 경우 FactGem과 Neo4j가 해결하는 데 도움이 되는 데이터 통합 프로젝트 유형을 구현하는 대규모 조직에는 엄청난 양의 그래프 전문 지식이 없을 수 있어요. 하지만 우리는 그래프가 매우 중요하다고 믿기 때문에 그래프를 기업에 도입하는 데 도움을 주고 싶은 마음이 크답니다.
FactGem을 사용하면 드래그 앤 드롭 데이터 통합을 제공하고 이전 데이터 시스템에서는 사용할 수 없었던 데이터 통찰력에 대한 액세스를 제공해서 그래프가 수행할 수 있는 작업을 다른 사람에게 매우 빠르게, 그리고 쉽게 보여줄 수 있어요. 이를 통해 사람들은 그래프의 가치를 즉시 확인할 수 있고, 그래프 기술 채택에 더 많은 자원을 투자할 의향이 생기죠. 그리고 실제로 FactGem을 사용하는 사람들에게서 이런 패턴이 나타났어요.
기술적 지식이 없는 사용자도 FactGem을 사용해서 자신에게 적합한 웹 기반 인터페이스를 통해 즉각적인 결과와 통찰력을 얻을 수 있어요. 이 경험을 통해 그들은 그래프의 힘을 발견하고 궁극적으로 사람들이 왼손으로 연습하듯이 Neo4j 및 그래프 기술에 능숙해질 수 있도록 투자하게 된답니다. 여기에서 그래프에 대한 이점과 이해가 풍부해지는 거죠.
문의하기 자세히 알아보세요!
추가 리소스
FactGem과 Neo4j의 파트너십에 대한 자세한 내용을 확인해보세요. 여기에서 GraphConnect의 이전 블로그 게시물과 프리젠테이션을 확인할 수 있습니다.
엔터프라이즈 데이터 패브릭의 출현
좋은 것부터 그래프까지, 올바른 데이터베이스 선택
5분 인터뷰: FactGem CTO Clark Richey
5분 인터뷰: FactGem CEO Megan Kvamme
FactGem는 브론즈 스폰서입니다. GraphConnect New York에서 할인 코드FactGem30을 사용해서 티켓과 교육 비용을 30% 할인받으세요.
무엇을 기다리고 계신가요? GraphConnect New York 티켓을 구매하시고 10월 24일 맨해튼 Pier 36에서 만나요!
Cypher
FactGem
GraphConnect
NoSQL 데이터베이스
SQL
Tableau
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
기존 분석 방식으로는 대규모 데이터 세트 내의 복잡한 관계를 처리하기 어려워서, 많은 조직들이 연결된 데이터로부터 강력한 통찰력을 얻는 데 어려움을 겪고 있어요. 진정으로 정보에 기반한 의사 결정을 내리려면 사기 탐지, 추천 시스템 개선, 민감한 데이터 보호, 공급망 최적화 등 데이터 속 숨겨진 연결 고리를 이해하는 게 중요하죠.
그래프 분석은 데이터 엔터티 간의 관계를 분석해서 숨겨진 패턴, 추세, 이상 징후를 찾아내는 데 도움을 줘요. 기존 분석 방법으로는 놓칠 수 있는 예측을 가능하게 하고, 새로운 통찰력을 얻을 수 있게 해주죠.
이번 가이드에서는 그래프 분석이 어떻게 데이터 문제를 기회로 바꿔주는지 알아볼 거예요. 그래프 분석의 실제 적용 사례들을 살펴보고, 가 어떻게 복잡한 데이터 분석을 간소화하고 즉시 활용 가능한 통찰력을 제공하는지 배워볼게요.
사기 탐지 및 위험 분석: 복잡한 사기 계획 탐색
은행, 소매업체, 통신 회사, 전자 상거래 기업들은 모두 보안 위험에 노출되어 있죠. 예를 들어 합성 신원 사기, 계정 탈취, 정교한 교차 채널 공격 등이 있을 수 있어요. 조직은 공유 IP 주소, 장치 지문 일치, 조정된 거래 패턴 등 악의적인 행위자들과 그들의 활동 간의 연결 고리를 식별해서 사기 조직과 사이버 범죄 네트워크의 정체를 밝혀내고 피해를 예방하거나 최소화할 수 있어요. 하지만 안타깝게도, 이런 연결 고리들은 엄격한 테이블 구조를 강요하고 복잡한 관계를 표현하는 데 많은 비용이 드는 기존 관계형 데이터베이스 아키텍처에서는 잘 보이지 않는 경우가 많아요. 특히 JOIN 연산은 더욱 그렇죠. 악의적인 행위자들은 의심스러운 활동을 여러 계정과 채널에 분산시켜서 이러한 구조적 제약, 특히나 `Schema`의 경직성이나 JOIN 관련 성능 제약을 악용하곤 해요.
이러한 아키텍처 제약으로 인해 다음과 같은 시스템이 만들어지게 돼요.
사전 정의된 규칙에 의존하며, 진화하는 사기 전술에 제대로 적응하지 못해요.
충분한 맥락 정보 없이 연결 고리만 분석하기 때문에 잘못된 경고를 많이 발생시켜요.
다양한 플랫폼이나 서비스 전반에서 조직적으로 이루어지는 사기 활동을 제대로 탐지하지 못해요.
관계형 데이터베이스를 사용하는 기존 사기 탐지 시스템이 가진 핵심적인 기술적 문제들을 해결하는 데 도움을 줄 수 있는 Neo4j Aura Graph Analytics를 소개합니다! 아래 표에서 Neo4j Aura Graph Analytics가 사기 탐지에 어떤 영향을 미칠 수 있는지 한번 살펴볼까요?
Neo4j 그래프의 장점
고정된 스키마 요구 사항
새로운 사기 패턴에 대비해 비용이 많이 드는 데이터 모델 재설계 필요
새로운 위협 패턴에 적응하는 유연한 스키마
JOIN 집중 쿼리
연결된 데이터 분석으로 인한 기하급수적인 성능 저하
기본 관계 인덱싱으로 실시간 패턴 일치 가능
멀티홉 관계 분석
규모에 따라 계산이 불가능함
경로 깊이에 관계없이 일정한 시간 순회
사용 사례: 자금세탁 집단 식별
그래프 알고리즘은 계정 간의 거래 흐름을 추적해서 잠재적인 자금 세탁 활동을 찾아내요. 예를 들어, 여러 지역에 걸쳐 관련 없는 계정 간에 이체가 빠르게 연속적으로 발생하면 의심스러운 행동을 나타낼 수 있죠. Neo4j AuraDB 같은 Graph Database는 계정을 Node로, 트랜잭션을 Relationship으로 모델링해서 주기, 클러스터 및 "허브" 계정을 감지한답니다.
이 시각화는 전형적인 자금세탁 계획을 보여주네요.
여러 관할권에 걸친 국제 거래(미국, 중국, 러시아, 브라질, 인도, 케이맨 제도)
조세 피난처의 중앙 허브 계정(케이맨 제도)
결국 근원으로 돌아가는 순환적인 돈의 흐름
각 전송 시 약간의 양 감소(스트리핑)
신속한 연속 전송(모두 몇 시간 내에 발생)
Neo4j Aura 그래프 분석은 중복 제거 및 엔터티 해결을 합리화해서 유사한 엔터티와 그 Relationship을 식별해요. 데이터 엔터티(고객, 계정, 장치 등)를 속성(이름, 주소, 이메일 등)을 소유한 Node로 모델링한 다음 이러한 엔터티 간의 Relationship을 생성해서 상호 작용이나 연결을 나타낼 수 있죠. 이 접근 방식을 사용하면 데이터 생태계 전반에서 엔터티가 어떻게 연결되어 있는지 확인하고 기존 데이터베이스에서 종종 놓치는 패턴을 찾아낼 수 있어요. 예를 들어, 이름은 약간 다르지만 동일한 판매자 계정과 동일한 거래 패턴을 가진 두 개의 고객 레코드가 있는 경우 이를 잠재적인 중복으로 표시할 수 있답니다.
대규모 데이터 세트에서 JOIN 집약적인 작업으로 어려움을 겪는 기존 관계형 데이터베이스와 달리 Neo4j의 솔루션은 대규모 데이터 세트 내의 Relationship을 효율적으로 분석해서 성능 문제 없이 수백만 개의 엔터티로 확장돼요.
Neo4j Aura Graph Analytics는 확률적 커뮤니티 감지와 유사성 알고리즘을 결합해서 정교한 사기 감지도 가능하게 해요. 플랫폼의 약하게 연결된 구성요소 알고리즘은 의심스러운 속성을 공유하는 그룹 계정은 관련 없어 보이는 개체 간의 숨겨진 연결을 드러내죠.
다음과 같은 유사성 알고리즘 Jaccard, 코사인 및 오버랩은 여러 차원에서 서로 다른 엔터티가 얼마나 밀접하게 일치하는지 측정해서 합성 ID를 감지하는 데 도움이 돼요. 예를 들어 Jaccard 유사성은 합법적인 신원 구성 요소의 비정상적인 조합을 식별해서 도난당한 데이터 조각으로 구성된 잠재적인 합성 신원을 표시할 수 있죠. 이 접근 방식은 복잡한 JOIN 작업의 성능 저하 없이 실시간 사기 위험 점수를 생성하므로 금융 기관이 즉시 조치를 취할 수 있답니다.
Neo4j 그래프 기술을 사용해서 자금 세탁을 방지하는 방법에 대해 자세히 알아보려면 다음을 읽어보세요. 이 심층 가이드. Neo4j를 사용한 사기 탐지에 대해 더 자세히 살펴보고 싶다면 다음을 확인하세요. 이 블로그 시리즈.
추천 엔진: 관계를 통해 고객 참여 강화
전자상거래 및 스트리밍 서비스는 기존 추천 시스템으로 인해 어려움을 겪고 있어요. 대부분은 협업 필터링을 사용해서 사용자 유사성이나 과거 상호 작용을 기반으로 항목을 추천하죠. 이 접근 방식은 빈도나 기록 기반 패턴을 넘어 다양한 제품이나 사용자 행동이 어떻게 연결되어 있는지와 같은 복잡한 Relationship을 식별하지 못하는 경우가 많아요.
기존 시스템은 또한 "콜드 스타트" 문제로 어려움을 겪고, 정적인 과거 데이터에 의존해서 진정으로 개인화된 경험을 제한한답니다.
사용 사례: 개인화된 콘텐츠 추천
Netflix나 Spotify 같은 스트리밍 서비스들은 그래프 기반 추천 엔진이 얼마나 뛰어난 개인화 경험을 제공할 수 있는지 보여주는 좋은 예시죠. Netflix는 시청 기록뿐만 아니라 시청 시간, 시간대, 사용 기기 등 시청 방식까지 분석해서 서로 연결된 데이터 포인트를 활용해 복잡한 네트워크를 만들어요.
Spotify도 마찬가지로 음악 객체(노래, 아티스트, 앨범)와 이들의 관계(장르, 분위기, 아티스트)를 나타내는 Knowledge Graph를 사용해서 Discover Weekly 플레이리스트를 제공하고 있어요. 그래프 구조 안에서 콘텐츠 속성과 사용자 행동을 모두 분석함으로써, 기존의 테이블 형태 데이터베이스에서는 놓칠 수 있는 미묘한 음악적 선호도까지 연결할 수 있는 거죠.
스트리밍 플랫폼이 그래프 기반 방식으로 추천 시스템을 설계하는 방법을 한번 살펴볼까요?
이 다이어그램은 서로 연결된 사용자, 프로그램, 완료율, 그리고 기기를 보여주는 스트리밍 플랫폼 네트워크를 나타내요. 그래프 기반 접근 방식은 이러한 엔터티 간의 깊은 관계를 밝혀내서 플랫폼이 상황을 잘 파악한 추천 시스템을 구축할 수 있도록 도와주죠.
Neo4j Aura Graph Analytics는 65개 이상의 내장 그래프 알고리즘, 예를 들어 개인화된 PageRank나 K-최근접 이웃 같은 알고리즘을 통해 다양한 차원에서 관계를 분석해서 추천 정확도를 높여요. 이러한 알고리즘은 그래프 구조를 사용해서 근접성, 영향력, 유사성을 기준으로 항목 점수를 매기고, 1초 안에 개인화된 제안을 제공해서 참여 지표를 개선하는 데 도움을 줘요. Neo4j는 유연한 스키마와 확장 가능한 아키텍처를 통해 개발 주기를 단축시켜 주기도 하고요.
Neo4j는 사용자, 항목, 상호 작용을 Nodes와 Relationships로 모델링해서 복잡한 Queries를 단순화하고 실시간으로 적응하는 추천을 제공해요. 최신 추천 엔진을 위한 이상적인 솔루션이라고 할 수 있죠.
공급망 최적화: 복잡한 네트워크 관계 마스터하기
제조, 소매, 물류, 제약, 식품 회사들은 공급망 문제 때문에 어려움을 겪고 있어요. 공급망 단계 사이의 격차 때문에 가시성이 계속 문제가 되고, 기존 데이터베이스 시스템은 속도가 느리죠. 문제가 발생하면 기업들은 영향을 받는 제품을 빨리 찾아내거나 백업 공급 업체를 찾기가 어려울 때가 많아요. 기존 시스템은 현대 공급망의 고도로 연결된 특성을 처리하도록 만들어지지 않았거든요. 공급업체와 물류 데이터를 저장하기 위해 엄격한 스키마를 사용하기 때문에 상호 의존성을 분석하기가 어렵기 때문이에요.
그래프 분석 모델은 공급망을 서로 연결된 엔터티의 실제 네트워크로 표현해요. Neo4j Aura 데이터베이스를 사용하면 공급망 관리자는 네트워크 깊이에 상관없이 일관된 성능으로 여러 단계의 공급업체, 유통 센터, 운송 경로를 탐색할 수 있어요. 이를 통해 문제가 발생했을 때 실시간으로 영향 분석을 할 수 있을 뿐만 아니라, 기존 관계형 데이터베이스 시스템이 따라올 수 없는 사전 예방적 위험 관리도 가능해져요.
사용 사례: 위험 완화 및 경로 최적화
공장, 유통 센터, 항구, 운송 경로를 서로 연결된 그래프로 모델링함으로써 제조업체는 최적의 배송 경로를 식별하는 동시에 잠재적인 병목 현상을 빠르게 감지하고 예방할 수 있어요.
글로벌 제조업체가 Neo4j를 사용해서 어떻게 공급망을 최적화하는지 한번 살펴볼까요? 아래 시나리오는 다단계 공급망 전체에서 가시성 문제에 직면한 회사가 그래프 분석을 사용해서 전체 공급 네트워크를 그래프로 모델링하고 다음과 같은 통찰력을 얻는 방법을 보여줘요.
2차 및 3차 공급업체에 대한 의존도
구성 요소 전달을 위한 중요 경로
특정 지역의 위험 집중
문제 발생 시 대체 소싱 기회
Neo4j의 그래프 모델을 사용하면 신속하게 영향 평가를 하고 대체 공급업체를 활성화할 수 있어요. 최단 경로 알고리즘으로 밀리초 단위로 라우팅을 최적화하는 거죠. 그동안 매개 중심성은 단일 포트가 배송의 80%를 처리하는 것처럼 중요한 오류 지점을 정확히 찾아낸답니다.
Neo4j Aura는 재고 및 운송 시간부터 외부 위험까지 공급망 데이터를 효율적으로 분석해줘요.
사이버 보안 및 위협 탐지: 디지털 위협 환경 매핑
금융 서비스, 정부 기관 및 중요 인프라 부문이 직면한 문제는 정교한 위협인데요, 이들은 네트워크를 통해 측면으로 이동하면서 의도적으로 합법적인 동작을 모방해요. 이러한 위협은 알려진 공격 패턴에 의존하는 기존 탐지 임계값을 회피하죠.
그래프 분석은 보안 데이터를 격리된 경고나 로그가 아닌 상호 연결된 엔터티 및 이벤트로 모델링해요. 사용자, 장치, IP 주소 및 네트워크 활동을 Node와 Relationship으로 표시함으로써 Neo4j는 네트워크 전반에 걸쳐 시간이 지남에 따라 전개되는 공격 패턴을 추적할 수 있어요. 이러한 관계 중심 접근 방식을 통해 보안 팀은 기존 방식에서 볼 수 없었던 측면 이동, 권한 상승, 데이터 유출 시도를 탐지할 수 있는데, 이는 보안정보 및 이벤트 관리(SIEM) 시스템이 놓치는 부분이죠.
Neo4j Aura Graph Analytics 알고리즘은 겉으로는 관련이 없어 보이는 이벤트 사이의 미묘한 연결을 식별하여 매일 발생하는 수십억 건의 보안 이벤트 속에 숨겨져 있을 공동 공격을 밝혀낼 수 있답니다.
사용 사례: 피싱 캠페인에 대응
금융 기관은 공격자가 합법적인 기관을 사칭하여 중요한 시스템에 무단으로 액세스하는 정교한 피싱 캠페인에 직면해 있어요. 이러한 공격에는 일반적으로 스푸핑된 이메일, 가짜 웹사이트, 사회 공학적 전술 등 여러 접점이 포함되어 있어서 기존 보안 도구로는 탐지하기 어렵죠. 이러한 캠페인이 성공하면 자격 증명 도용, 계정 탈취, 그리고 궁극적으로 수천 명의 고객에게 영향을 미치는 데이터 침해로 이어질 수 있어요.
보안 팀의 과제는 여러 시스템과 기간에 걸쳐 서로 다른 지표를 연결하여 조정된 캠페인이 성공하기 전에 식별하는 거예요. 기존 SIEM 시스템은 새로운 공격 기술에 적응할 수 없는 사전 정의된 상관 관계 규칙에 의존하기 때문에 이러한 복잡한 공격 패턴을 식별하는 데 어려움을 겪죠.
보안 팀은 서로 다른 보안 데이터를 포괄적인 그래프 모델로 통합하여 이러한 문제를 극복할 수 있어요. 물리적 개체에 초점을 맞춘 공급망 모델링과 달리 사이버 보안 그래프는 계정, 장치, 애플리케이션 및 네트워크 리소스를 액세스 관계 및 상호 작용 이벤트와 통합합니다. 더욱이, Neo4j LLM 지식 그래프 빌더는 구조화되지 않은 보안 로그 및 위협 인텔리전스 보고서에서 엔터티와 관계를 추출할 수 있답니다.
보안 데이터에 대한 전체적인 뷰를 통해 금융 회사는 IP 주소, 장치 지문, 로그인 시도를 매핑해서 숨겨진 연결을 찾을 수 있어요.
예를 들어 공격자가 탐지를 피하려고 IP 주소를 바꿔도, 그래프 분석을 통해 단일 장치에서 접근하는 의심스러운 계정 클러스터가 드러날 수 있죠. 보안 팀은 그래프를 탐색하면서 네트워크를 통해 공격자의 측면 이동을 추적하고, 캠페인에서 잠재적으로 손상될 수 있는 모든 계정, 시스템, 데이터 세트를 식별할 수 있어요.
Neo4j의 중심성 알고리즘은 공격자가 표적으로 삼을 만한 중요한 리소스를 찾아낼 수 있어요. 예를 들어 PageRank는 과도한 권한을 가진 고도로 연결된 서버를 식별할 수 있고, Label Propagation은 유사한 행동 패턴을 보이는 손상된 사용자 계정 그룹을 탐지하는 데 도움이 되죠. 이런 알고리즘은 데이터베이스 크기에 상관없이 효율적으로 작동하기 때문에, 관계형 데이터베이스 쿼리를 손상시킬 수 있는 성능 저하 없이 페타바이트 규모의 보안 데이터에서 실시간 위협 검색이 가능해요.
콘텐츠 네트워크 및 미디어 인텔리전스: 정보 생태계 탐색
미디어 조직, 뉴스 매체, 콘텐츠 게시자는 콘텐츠, 주제, 객체, 청중 상호 작용 간의 복잡한 관계를 관리하는 데 어려움을 겪고 있어요. 기존 시스템은 키워드 매칭에 의존하기 때문에 콘텐츠 검색 및 인사이트 생성에 한계가 있죠.
그래프 분석은 정보 생태계의 자연스럽게 연결된 구조를 모델링해서 콘텐츠 관리를 혁신해요. Neo4j를 사용하면 조직이 Knowledge Graph를 만들 수 있어요. 기사, 주제, 사람, 장소, 이벤트는 복잡한 JOIN이 필요한 조각난 테이블이 아니라, 서로 연결된 네트워크로 존재하는 거죠. 이 접근 방식은 수백만 개의 문서에서도 일관된 쿼리 성능을 유지하면서, 기존 시스템이 감지할 수 없는 상황별 관계와 패턴을 드러내요.
사용 사례: 잘못된 정보 네트워크 식별
잘못된 정보 캠페인에는 생성된 콘텐츠를 개별적으로 분석할 때 합법적인 것처럼 보이는 조정된 계정 네트워크가 포함돼요. 격리된 콘텐츠에 초점을 맞추는 기존 조정 시스템은 이런 조직적인 노력을 제대로 감지하지 못하죠.
Neo4j는 구조화되지 않은 콘텐츠를 풍부한 Knowledge Graph로 변환해서 이런 문제를 해결해요. 여기서 엔티티와 그 관계가 눈에 보이게 되죠. 예를 들어 미디어 인텔리전스 회사는 사용자 계정, 콘텐츠, 해시태그, 참여 패턴을 상호 연결된 그래프로 모델링해서 정치적 행사 중에 수백만 개의 소셜 미디어 게시물을 분석할 수 있어요. 이렇게 표현하면 기존 분석에서는 보이지 않던 네트워크 구조가 바로 드러나죠.
사용자, 게시물, 관련 해시태그, 다양한 주제를 매핑해서 의심스러운 패턴을 찾아내는 샘플 그래프를 한번 살펴볼까요?
각 게시물은 개별적으로 보면 괜찮아 보일 수 있지만, 그래프에서는 조정된 콘텐츠 증폭, 공유 장치, 유사한 해시태그의 반복 사용을 나타내는 멀티홉 관계를 식별할 수 있어요.
Neo4j의 그래프 알고리즘은 사용자 참여를 분석하는 데 도움을 주는데요. 예를 들어, 학위 중심성 알고리즘(Degree Centrality Algorithm)을 통해 참여를 유도하는 영향력 있는 계정을 식별하고, 루뱅 알고리즘(Louvain Algorithm)으로 상호 작용 패턴을 기반으로 사용자를 의미 있는 커뮤니티로 분류할 수 있죠. 가장 중요한 점은 연결되지 않은 이데올로기 그룹을 연결하는 연결 중심성이 높은 계정이 잠재적인 잘못된 정보 슈퍼전파자로 식별될 수 있다는 거예요. 이러한 전략적 Node에 조정 노력을 집중함으로써 플랫폼은 광범위한 콘텐츠 검열 없이 허위 정보의 확산을 줄일 수 있답니다.
이러한 타겟 접근 방식은 잘못된 정보를 억제할 뿐만 아니라 사용자가 커뮤니티 내에서 그리고 네트워크 전반에서 상호 작용하는 방식을 밝혀 더 깊은 참여 통찰력을 제공해요.
의료 및 생의학 연구: 생명을 구하는 연관성 찾기
의료 서비스 제공자, 제약 회사, 연구 기관은 전자 건강 기록, 게놈 서열, 단백질 상호 작용, 임상 시험을 포괄하는 방대한 생물 의학 데이터 세트를 관리하고 있어요. 기존의 관계형 데이터베이스는 질병, 약물, 환자 간의 관계를 추적하기 어렵게 만드는 방식으로 데이터를 조각화하죠.
관계형 데이터베이스에서 생물학적 관계를 Query하는 작업은 경로 길이에 따라 기하급수적으로 느려지고, 다단계 분석에 많은 비용이 들어요. 다양한 생물 의학 데이터 형식과 온톨로지의 통합을 복잡하게 만드는 엄격한 Schema 요구 사항과 결합된 이러한 단편화는 약물 발견 노력과 포괄적인 환자 치료를 심각하게 방해한답니다.
그래프 분석은 생물학적 시스템을 단절된 데이터 사일로가 아닌 상호 연결된 네트워크로 표현함으로써 생의학 연구를 변화시키는데요. Neo4j의 Schema에 구애받지 않는 구조는 게놈 데이터, 단백질체학, 임상 기록, 연구 문헌을 통일된 Knowledge Graph로 원활하게 통합하여 의료 혁신을 주도하는 상황별 관계를 보존해요. 사전 정의된 JOIN 테이블이 필요한 관계형 데이터베이스와 달리 Neo4j는 관계 깊이에 대한 성능 저하 없이 3단계 약물-단백질-질병 상호 작용을 분석하든 10단계 대사 단계를 분석하든 상관없이 복잡한 경로를 지속적으로 탐색할 수 있어요. 이 기능은 전자 건강 기록(Electronic Health Record)과 CRISPR처럼 서로 다른 데이터 소스를 연결할 때 정말 중요하죠. 기존 시스템이 호환되지 않는 Schema와 지연된 Query 응답으로 어려움을 겪고 있는 심사 결과에요.
사용 사례: 약물 용도 변경
약물 용도 변경, 즉 기존 승인 약물에 대한 새로운 치료 응용 분야를 찾는 것은 일반적으로 10~15년과 수십억 달러가 소요되는 기존 약물 개발보다 더 빠르고 비용 효율적인 치료 경로를 제공해요. 하지만 유망한 용도 변경 후보를 식별하는 것은 쉽지 않아요. 단백질-단백질 상호 작용, 유전자 발현 패턴, 경로 분석, 임상 결과를 포함하여 서로 다른 데이터 세트에 걸쳐 복잡한 생물학적 상호 작용을 분석해야 하거든요. 기존의 데이터베이스 접근 방식은 이러한 다차원 관계 Query로 인해 어려움을 겪기 때문에 잠재적인 연결을 체계적으로 발견하는 것이 거의 불가능하답니다.
잠재적인 약물 용도 변경 기회를 식별하기 위해 약물, 질병, 유전자, 단백질 간의 관계를 명시적으로 모델링하는 샘플 그래프를 한번 살펴볼까요?
Neo4j는 질병, 약물, 유전자, 단백질, 경로 등 수많은 생물 의학 개체를 포괄적인 Knowledge Graph로 연결해줘요. 공개 데이터와 독점 데이터를 통합해서 기업은 생물학적 메커니즘, 약물 표적, 질병 경로에 대한 통합된 뷰를 만들 수 있죠.
게다가 Neo4j의 Text2Cypher 기능 덕분에, 해당 분야 전문가가 Natural Language Processing 쿼리를 사용해서 정교한 네트워크 분석을 수행할 수 있어요. 전문적인 프로그래밍 기술이 없어도 괜찮아요! 예를 들어 임상의가 "질병 Y에서 상향 조절되는 유전자 X와 동일한 경로를 표적으로 하는 승인된 약물은 무엇입니까?"라고 간단하게 질문할 수 있고, 잠재적인 용도 변경 기회를 시각적으로 매핑된 결과로 얻을 수 있는 거죠.
TensorFlow 같은 Machine Learning 프레임워크와 통합되면, Neo4j는 Graph Neural Network 기술을 통해 새로운 약물 상호작용과 부작용을 예측해서 약물 재활용을 향상시킬 수 있어요. 이런 모델은 Graph 표현 고유의 풍부한 관계 컨텍스트를 사용해서 기존 표 형식 데이터로는 불가능했던 예측 정확도를 달성하는 거죠.
IT 인프라 및 네트워크 관리: 디지털 생태계 매핑
복잡한 IT 인프라를 가진 대기업은 물리적 환경과 가상 환경 전체에서 컴포넌트 간의 관계를 모델링하고 분석하는 데 어려움을 겪고 있어요. 기존 도구는 현대 기술 생태계의 역동적이고 상호 연결된 특성을 제대로 포착하지 못하는 정적인 표현을 사용하기 때문에, 종속성을 이해하고 영향을 추적하며 중요한 경로를 식별하는 게 거의 불가능하죠.
Neo4j Aura Graph Analytics는 기술 환경을 자연스럽게 상호 연결된 시스템으로 모델링해서 IT 인프라 관리를 위한 이상적인 기반을 제공해요. Neo4j는 서버, 애플리케이션, 네트워크 장치, 서비스를 Nodes로 표현하고, 해당 종속성과 통신 경로를 Relationships로 표현해서 전체 생태계의 살아있는 지도를 만드는 거예요.
Neo4j는 다른 방법으로는 즉시 종속성을 매핑해요. 예를 들어 Configuration Management Database는 "이 서버에 장애가 발생하면 어떤 애플리케이션이 영향을 받나요?"와 같은 간단한 Query에 복잡한 JOIN이 필요한 관계형 데이터베이스를 기반으로 구축되었죠. 이는 컨테이너 오케스트레이션이 기존 인벤토리 시스템이 효과적으로 추적할 수 없는 지속적으로 변화하는 인프라를 생성하는 클라우드 네이티브 환경에서 특히 중요해요.
With Neo4j의 실시간 관계 모델링, IT 팀은 폭발 반경 계산을 즉시 시각화하고, 근본 원인 분석을 수행하고, 기존 모니터링 도구에 숨겨져 있던 단일 장애 지점을 식별할 수 있어요.
사용 사례: 클라우드 비용 최적화
환경이 점점 더 복잡해짐에 따라 클라우드 인프라를 최적화하는 건 점점 더 어려워지고 있어요. 일반적으로 조직은 사용되지 않는 Resources를 식별하고, 서비스 간의 종속성을 이해하고, 중요한 비즈니스 운영을 방해하지 않고 컴포넌트를 안전하게 폐기하는 데 어려움을 겪죠. 기존의 클라우드 관리 도구는 기본적인 사용량 지표를 제공하지만, Resources 간의 복잡한 관계 웹을 드러내는 데는 실패했어요. 이로 인해 고아 인스턴스, 과잉 프로비저닝된 서비스, 중복 컴포넌트에 대한 불필요한 지출이 발생해요. 이러한 종속성을 완전히 파악하지 못한 채 비용 절감 계획을 시도하면 기업은 예상치 못한 서비스 중단을 초래할 위험이 있어요.
예를 들어 아래 그래프는 데이터베이스 및 컴퓨팅 인스턴스와 같은 배포된 클라우드 애플리케이션에 대한 종속성을 보여줍니다.
클라우드 인프라에는 사용량 지표를 자세히 보지 않으면 찾기 힘든 고아 인스턴스가 있을 수 있어요.
SaaS 제공업체는 Neo4j를 사용해서 전체 클라우드 인프라를 연결된 그래프로 모델링해서 이런 문제를 해결할 수 있죠. 애플리케이션, 서비스, 데이터베이스, 컴퓨팅 리소스 간의 종속성을 매핑해서 직/간접적인 관계를 모두 보여주는 환경의 포괄적인 디지털 트윈을 만드는 거예요. Neo4j의 중심성 알고리즘을 사용하면 중요한 경로와 병목 현상을 식별하는 동시에, 여전히 비용이 발생하는 고아 리소스와 축소할 수 있는 활용도가 낮은 EC2 인스턴스를 찾을 수 있어요. 가장 중요한 점은, 그래프 시각화가 독립적으로 보이는 서비스 간의 숨겨진 종속성을 보여줘서 팀이 연속적인 오류 없이 중복 구성 요소를 안전하게 해제할 수 있다는 거죠.
Neo4j AuraDB의 실시간 `Query` 기능은 IT 팀이 인프라를 모니터링하고 문제를 해결하는 방식을 바꿔줘요. 제한된 컨텍스트로 미리 정의된 대시보드만 제공하는 기존 모니터링 도구와는 달리, Neo4j는 모든 시작점에서 전체 종속성 체인을 동적으로 탐색할 수 있어요. 사고가 발생하면 팀은 영향을 받는 모든 서비스, 데이터베이스, 애플리케이션 전반에 걸쳐 영향 경로를 즉시 추적할 수 있죠. 예를 들어, 깊이 우선 검색 경로 찾기 알고리즘을 사용하면 여러 서비스 계층에서 API 오류의 근본 원인을 빠르게 추적해서 평균 해결 시간을 크게 줄일 수 있어요. 이러한 실시간 관계 인식은 사전 비용 최적화와 사후 사고 관리 모두에 필요한 상황별 이해를 제공해요. 이건 플랫 파일 CMDB와 기존 모니터링 도구가 제공할 수 없는 기능이죠.
결론
그래프 분석은 기존 시스템이 효과적으로 해결할 수 없는 문제를 해결함으로써 연결된 데이터를 이해하는 새로운 방법을 조직에 제공해요. 그래프 기술은 데이터 포인트 간의 관계를 자연스럽게 모델링함으로써 사기 탐지에서 숨겨진 패턴과 관계를 찾아내고, 미묘한 추천을 제공하고, 복잡한 공급망을 최적화하고, 사이버 보안 방어를 강화하고, 콘텐츠 검색을 개선하고, 생물 의학 연구를 가속화하고, IT 인프라 관리를 단순화하죠.
Neo4j Aura 그래프 분석은 조직이 전문적인 인프라 전문 지식 없이도 그래프 솔루션을 빠르게 구축하고 확장할 수 있는 확장 가능하고 직관적인 플랫폼을 제공해요. 내장된 알고리즘, 직관적인 시각화 기능, 구조화된 데이터와 구조화되지 않은 데이터를 원활하게 결합하는 기능을 통해 팀은 데이터에서 실행 가능한 통찰력을 빠르게 얻을 수 있죠.
궁극적으로 Neo4j Aura Graph Analytics는 조직이 격리된 데이터 포인트를 넘어 비즈니스를 추진하는 관계에 대한 더 깊은 이해를 향해 나아가고 복잡한 과제를 성장과 혁신을 위한 명확한 기회로 전환하도록 도와요.
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.