
Neo4j 같은 Graph Database는 엔터티 해결 문제를 해결하는 데 아주 적합해요. 예를 들어, 그래프는 두 사용자 프로필이 이메일 주소와 같은 공통 식별자를 공유하는 위치를 보여주죠. 하지만 두 식별자가 비슷하긴 한데, 데이터 입력 오류 때문에 약간의 철자 차이가 있다면 그래프에서 식별하기 어려울 수 있어요.
Neo4j의 APOC(Awesome Procedures On Cypher) 라이브러리에는 Levenshtein, Jaro-Winkler, Sorensen-Dice를 포함해서 문자열 편집 거리를 계산하기 위한 다양한 텍스트 함수가 있어요. 개별 문자열 쌍을 비교하는 데는 효과적이지만, 무차별 대입 방식으로 대규모 데이터 세트의 가능한 모든 문자열 쌍에 이러한 기능을 적용하려면 시간이 꽤 걸릴 거예요.
그러다가 저는 우연히 편집 거리를 위한 컨벌루션 임베딩이라는 논문을 접하게 됐어요. Xinyan Dai, Xiao Yan, Kaiwen Zhou, Yuxuan Wang, Han Yang, James Cheng 님이 쓰신 논문인데요. 저자들은 CNN(Convolutional Neural Network)을 사용해서 문자열의 철자를 나타내는 Vector Embedding을 만들었어요. CNN은 편집 거리가 큰 문자열보다 작은 문자열을 Vector 공간에 더 가깝게 배치하도록 훈련되었죠. 철자 오류를 찾기 위해 가능한 모든 문자열 쌍을 검사할 필요 없이, K-최근접 이웃을 사용해서 비교해야 할 가능성이 가장 높은 문자열 쌍을 식별할 수 있게 된 거예요.
저자가 제공한 GitHub 저장소에서 코드를 복제했어요. 코드를 실행하고 Neo4j에서 결과 데이터로 작업하기 위해 몇몇 Jupyter 노트북을 추가했고요. 한번 확인해 보세요! 제 레포 포크와 이 블로그의 코드랍니다.
합성 이메일 데이터 생성
저는 Faker Python 라이브러리를 사용해서 150,000개의 합성 이메일 주소 목록을 만들었어요. 중복 항목을 제거하고 나니, 작업할 수 있는 고유 이메일이 141,286개라는 걸 알게 됐죠. 이메일을 생성하는 코드는 그래프_분석/Generate_data.ipynb 노트북에 있답니다.
임베딩을 생성하고 Neo4j로 보내기
다음으로, 작성자의 임베딩 코드를 실행했어요. 코드는 예제 데이터를 학습, 쿼리, 기본 세그먼트로 분할하고 각 문자열에 대한 임베딩을 생성하죠. 기본 임베딩 아키텍처를 2계층 CNN으로 만들기 위해 training.py 파일을 약간 수정했어요. 임베딩을 시작하는 데 사용한 코드는 그래프_분석/Send_to_Neo4j.ipynb 노트북에 있어요.
python main.py --dataset emails --nt 1000 --nq 1000 --epochs 20 --save-split --save-embed --save-model임베딩을 생성하는 데 약 93초가 걸렸어요. 다음은 결과의 예시랍니다.
Neo4j의 각 이메일 Node가 고유한 주소 값을 갖도록 하기 위해 Neo4j에 Node Key 제약 조건을 만들었어요.
CREATE CONSTRAINT email_node_key IF NOT EXISTS
FOR (e:Email) REQUIRE e.address IS NODE KEY그런 다음 Cypher 쿼리를 사용해서 임베딩이 포함된 이메일을 Neo4j에 보냈어요. 데이터를 로드하는 데 약 67초가 걸렸답니다.
UNWIND $data AS row
CALL {
WITH row
MERGE (e:Email {address:row['address']})
SET e.split = row['split']
WITH row, e
CALL db.create.setNodeVectorProperty(e, 'editEmbedding', row['embedding'])
} IN CONCURRENT TRANSACTIONS OF 10000 rowsK-최근접 이웃을 사용하여 가장 유사한 임베딩 찾기
Neo4j의 Graph Data Science 제품에는 K-최근접이웃 알고리즘이 포함되어 있어요. 그래프의 각 이메일 Node에 대해, 알고리즘은 코사인 유사성을 기반으로 가장 유사한 임베딩을 가진 다른 k개의 Node를 찾으려고 시도하죠. 이 부분을 실행하는 코드는 노트북 그래프_분석/Check_knn.ipynb에 있답니다.
먼저 Neo4j GDS Python 클라이언트를 사용해서 이메일 Node의 메모리 내 투영을 생성했어요. 아직 데이터베이스에 관계가 없기 때문에 관계 투영에 와일드카드("*")를 사용했죠.
g_email, result = gds.graph.project(
"emails",
{"Email": {"properties": "editEmbedding"}},
"*")top_10_df = gds.run_cypher("""
CALL gds.knn.stream("emails", {nodeProperties:"editEmbedding", topk:10})
YIELD node1, node2, similarity
WITH gds.util.asNode(node1) AS s,
gds.util.asNode(node2) AS t,
similarity
RETURN round(similarity, 2) AS similarity,
apoc.text.levenshteinDistance(s.address, t.address)
AS levenshteinDistance,
count(*) AS pairs
""")결과에 대한 히트맵을 만들어봤는데요. 코사인 유사성을 포함하는 것과 문자열 Levenshtein 거리 사이에 관계가 있다는 걸 알 수 있었어요. Levenshtein 거리가 2 이하인 문자열 쌍 중 `Embedding` 유사성이 0.84보다 큰 문자열 쌍은 없었답니다.
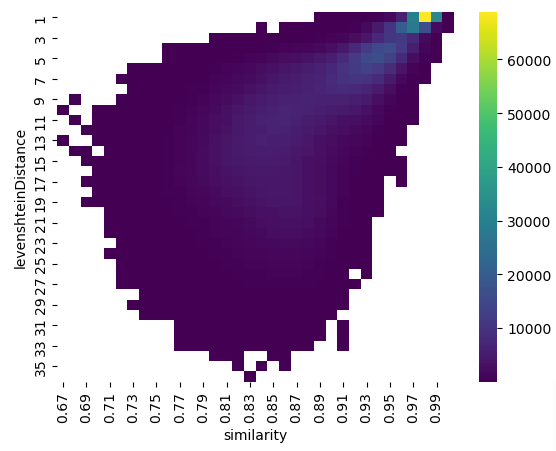
초기 탐색에서는 각 `Node`에 대해 가장 유사한 상위 10개의 `Embedding`을 살펴봤지만, 대규모 이메일 데이터 세트에서는 이메일에 작은 편집 거리 내에 10개 이상의 다른 이메일이 있을 수도 있잖아요. 이번에는 상위 K 매개변수를 80으로 설정하고 유사도 컷오프를 0.84로 설정해서 KNN을 다시 실행해봤어요. 결과를 스트리밍하는 대신 `HAS_SIMLAR_EMBEDDING`이라는 Neo4j에 대한 새로운 `Relationship`을 작성했죠. 이 결과를 계산하고 Neo4j에 쓰는 데 270초가 걸렸어요. `Embedding`을 생성하고 이를 Neo4j로 전송하고, `Graph` 투영을 생성하고 쓰기 모드에서 KNN을 실행하는 데 모두 431초가 걸렸는데, 이건 7분이 조금 넘는 시간이에요. 제가 실행한 `Cypher` `Query`는 다음과 같아요.
gds.run_cypher("""
CALL {
CALL gds.knn.stream("emails", {nodeProperties:"editEmbedding", topk:80, similarityCutoff:0.84})
YIELD node1, node2, similarity
WITH gds.util.asNode(node1) AS s,
gds.util.asNode(node2) AS t,
similarity
WITH s, t, similarity,
apoc.text.levenshteinDistance(s.address, t.address) AS levenshteinDistance
WHERE levenshteinDistance <= 2
MERGE (s)-[r:HAS_SIMILAR_EMBEDDING]->(t)
ON CREATE SET r.similarity = similarity,
r.levenshteinDistance = levenshteinDistance
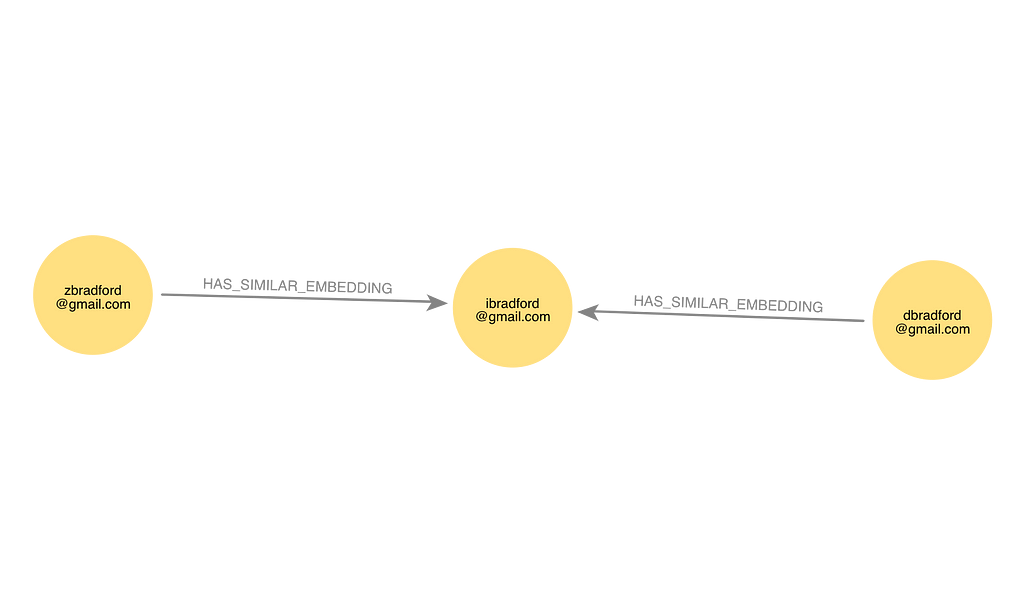
} IN TRANSACTIONS OF 10000 ROWS""")다음은 `HAS_SIMILAR_EMBEDDING` `Relationship`에 의해 다른 두 `Node`에 연결된 이메일 `Node`를 보여주는 Neo4j의 출력 예시랍니다.
KNN 결과를 레코드 연결 결과와 비교
저는 그 결과를 Python을 사용해서 얻을 수 있는 결과와 비교하고 싶었어요. 기록 연계 라이브러리를 사용했죠. 프로세스의 이 부분에 대한 코드는 그래프_분석/Try_record_linkage.ipynb 노트북에 있답니다. 전체 `Index`를 사용해서 가능한 모든 `Node` 쌍을 비교하는 건 제 환경에서 메모리를 너무 많이 사용하더라고요. 그래서 이메일을 Pandas 데이터 프레임에 로드하고 차단 열을 설정했어요.
먼저, 잠재적인 모든 일치 항목에 이메일의 첫 글자가 공통적으로 포함되도록 요구하려고 했어요. 이러한 후보 쌍을 생성하기 위해 레코드 연결 `Indexer`를 실행하면 환경에 메모리가 부족해졌죠.
잠재적인 일치 수를 줄이기 위해 후보 이메일 쌍에는 처음 두 문자와 최상위 도메인이 동일해야 하거나, 세 번째 문자부터 최상위 도메인까지 동일한 문자가 있어야 했어요. 저는 이것이 처음 두 문자 또는 최상위 도메인의 편집으로 인해 일부 쌍을 놓칠 것이라는 걸 알고 있었지만, 실제 데이터에서는 이러한 유형의 실수가 상대적으로 드물기를 바랐죠. 이렇게 해서 64,816,224개의 가능한 쌍을 검사할 수 있게 되었어요. `Index`를 생성하고 레코드 연계 비교를 실행하는 데 609초가 걸렸는데, 이는 CNN/Neo4j 접근 방식보다 29% 느린 속도였어요.
레코드 연결에서 Neo4j로 쌍을 로드해서 `Embedding` 비교의 쌍이 레코드 연결의 쌍과 얼마나 밀접하게 일치하는지 확인해봤어요. 저는 두 프로세스 모두에서 248,790쌍(전체의 92.8%)이 발견되었다는 걸 알게 되었죠. `Embedding` 비교에서는 15,237쌍(전체의 5.7%)이 발견되었지만 레코드 연결에서는 누락되었고요. 레코드 연계에서는 4,106쌍(전체의 1.5%)이 발견되었지만 삽입 비교에서는 누락되었답니다.
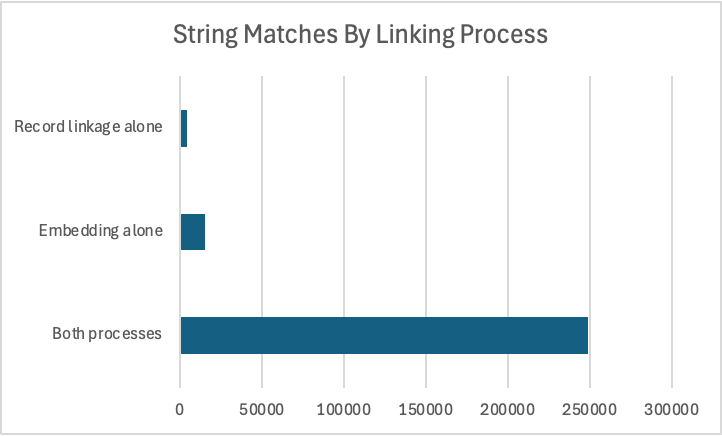
레코드 연결 시 유사성 발견 쌍이 누락되는 경우가 있었는데, 문자열의 처음 두 글자(예: amills@yahoo.com과 zmiles@yahoo.com) 내에서 편집이 발생했기 때문이었어요. 레코드 연결에서 이 문제를 방지하려면 다른 차단 방식을 시도해야 하는데, 더 많은 컴퓨팅 리소스가 필요하죠.
레코드 연결에서 임베딩 비교가 누락된 쌍을 발견했다면, 이는 CNN 임베딩이 Levenshtein 거리가 2 이하인 이메일보다 2보다 큰 Levenshtein 거리를 가진 주소를 대상 주소에 더 가깝게 배치했기 때문일 수 있어요. 이 문제를 해결하기 위해 2계층 CNN보다 더 복잡한 CNN 아키텍처를 탐색해볼 수도 있겠죠.
전반적으로 CNN을 사용하여 편집 거리가 낮은 문자열 쌍을 식별한 결과가 정말 인상적이었어요. 그래프 기반 엔터티 해결 파이프라인에 포함될 가능성이 충분하다고 생각해요.
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'GraphRAG' 카테고리의 다른 글
| 그래프 신경망으로 Word Embedding 성능 끌어올리기 (1) | 2026.04.29 |
|---|---|
| GraphRAG Python 패키지로 그래프 탐색을 활용하여 하이브리드 검색 성능 향상시키기 (0) | 2026.04.29 |
| Text2CypherRetriever로 Neo4j GraphRAG, 쉽게 시작하기 (0) | 2026.04.28 |
| BigQuery 데이터에서 Neo4j GraphRAG으로 풍부하고 강력한 인사이트 발견하기 (0) | 2026.04.28 |
| 파라다이스 페이퍼 심층 그래프 분석: Neo4j와 GraphRAG로 파헤치다 (0) | 2026.04.27 |