
최근 몇 년 동안 Natural Language Processing(NLP)은 정말 빠르게 발전하고 있어요. 그중에서도 중요한 부분은 임베딩인데요, 임베딩은 단어나 구절의 의미와 다른 단어들과의 관계를 숫자로 표현한 것이라고 할 수 있어요.
임베딩은 문서 분류, 기계 번역, 감정 분석, 개체명 인식 등 다양한 NLP 작업에 활용될 수 있죠. 게다가 GPT-3 같은 사전 훈련된 Large Language Model(LLM) 덕분에 여러 언어 작업과 분야에서 전이 학습을 하는 데 임베딩이 더욱 중요해졌어요. 임베딩이 NLP의 발전에 큰 영향을 주고 있다는 거, 정말 흥미롭죠?
한편, 그래프와 그래프 Neural Network의 발전으로 이미지 인식, 신약 개발, 추천 시스템 등 여러 분야에서 성능이 향상되었어요.
특히 그래프 Neural Network는 데이터 포인트 간의 관계가 Machine Learning 작업의 정확도를 높이는 데 중요한 역할을 하는 그래프 구조 데이터의 표현을 학습하는 데 엄청난 가능성을 보여주고 있어요.
이번 블로그에서는 그래프 Neural Network의 기능을 활용해서 데이터 포인트 간의 관계를 캡처하고 인코딩해서 문서 분류 정확도를 높이는 방법을 알아볼 거예요. 특히, Medium 기사의 태그를 예측하기 위해 두 가지 모델을 훈련해 볼 건데요.

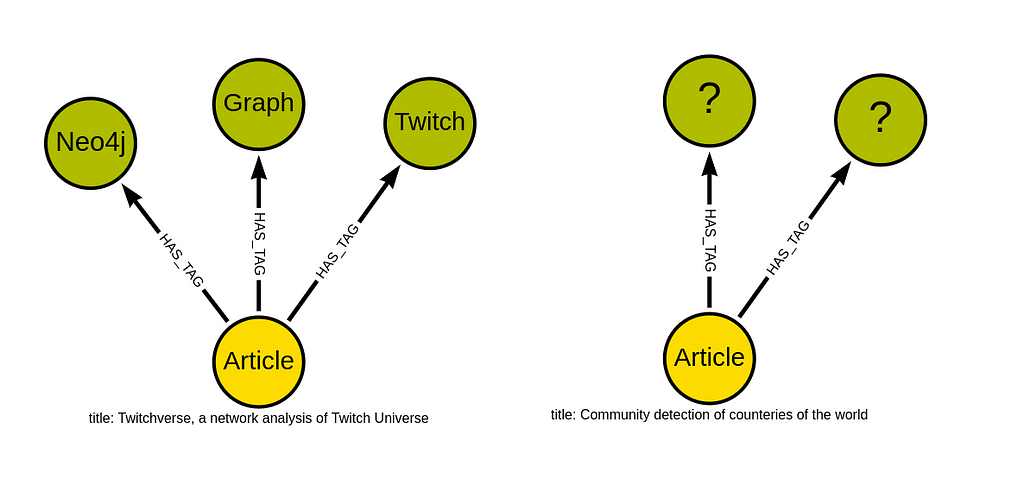
대부분의 Medium 기사에는 작성자가 더 쉽게 검색하고 검색 성능을 높이기 위해 관련 태그를 달아놓죠. 이러한 태그는 기사 분류라고도 생각할 수 있어요. 위 이미지처럼 각 기사에는 최대 5개까지 태그 또는 카테고리가 할당될 수 있어요. 그래서 두 가지 분류 모델을 훈련해서 다중 라벨 분류를 할 건데요, 각 기사에 하나 이상의 태그를 할당하는 방식이에요.
첫 번째 분류 모델은 기사 제목과 부제의 OpenAI 최신 임베딩(text-embedding-ada-002)을 입력 기능으로 사용할 거예요. 이 모델은 GraphSAGE라는 그래프 Neural Network 알고리즘을 사용해서 개선하려는 기준 정확도를 제공하죠. 흥미롭게도 이 예시에서는 단어 임베딩이 GraphSAGE에 대한 입력으로 사용될 수 있어요.
훈련하는 동안 GraphSAGE 알고리즘은 이러한 단어 임베딩을 활용해서 인접한 Node의 정보를 반복적으로 집계하고, 문서 분류와 같은 Machine Learning 작업의 정확성을 높일 수 있는 강력한 Node 수준 표현을 생성해요.
간단히 말해서, 이번 블로그에서는 데이터 포인트 간의 관계를 고려해서 단어 임베딩을 개선하기 위해 그래프 Neural Network를 사용하는 방법을 살펴볼 거예요.
데이터 포인트 간의 관계가 중요하고 예측 가능하다면 그래프 Neural Network는 텍스트 데이터의 더 의미 있고 정확한 표현을 학습할 수 있고, 결과적으로 Machine Learning 모델의 정확도를 높일 수 있어요.
Medium 데이터 세트
Kaggle에는 몇 가지 Medium 기사 데이터 세트가 있지만, 기사 간의 관계를 포함하는 데이터 세트는 없어요. 어떤 유형의 관계가 태그 예측에 도움이 될까요? Medium에는 사용자가 콘텐츠를 북마크하거나 읽고 싶을 때 목록을 만들어서 관리하는 기능이 있어요.
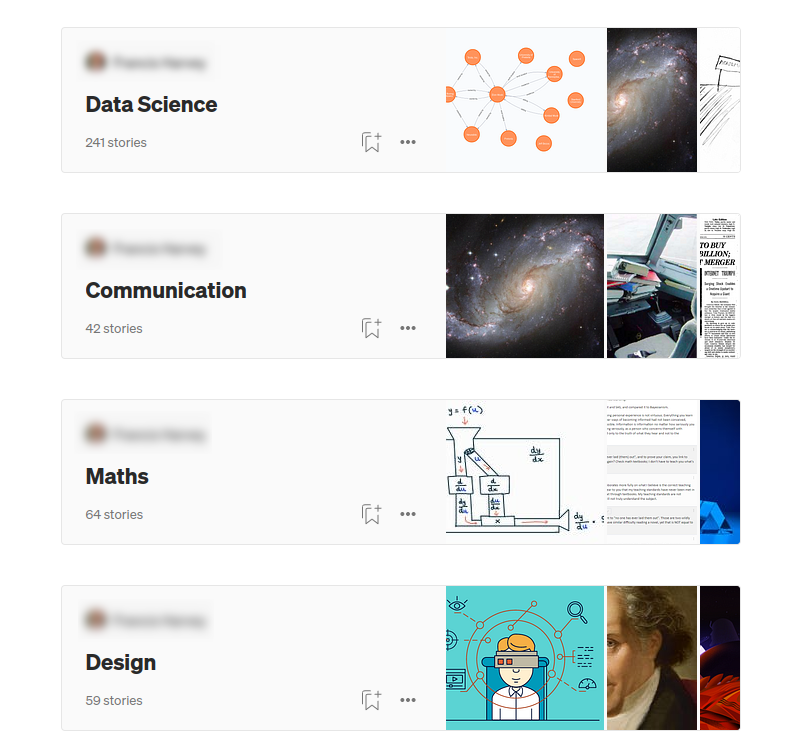
이 이미지는 사용자가 주제에 따라 4개의 기사 목록을 만든 예시를 보여주고 있어요. 예를 들어, 대부분의 기사는 목록에 있고, 다른 기사는 , , 그리고 목록에 추가되었죠. 두 기사가 동일한 목록에 있다면 공통 목록이 없는 경우보다 더 유사하다는 아이디어예요. Medium 목록은 유사한 기사를 찾고 추천하는 데 도움이 되는 기사 간의 관계라고 생각할 수 있어요.
물론 예외도 있어요. 일부 사용자는 온갖 종류의 기사가 포함된 엄청나게 큰 읽기 목록을 만들기도 하거든요.
재미있게도 이렇게 많은 기사가 포함된 목록의 대부분은 제목이 똑같아요. 바로 이죠. Medium의 기본 설정인 것 같아요.
아쉽게도 Medium 기사와 사용자가 만든 목록에 대한 정보가 포함된 공개 데이터 세트는 없어요.
그래서 저는 데이터를 분석하면서 시간을 좀 보내야 했어요. 4,000명의 사용자 목록에서 55,000개의 Medium 기사에 대한 정보를 가져왔답니다.
Neo4j 환경 준비
그래프 구성 및 GraphSAGE 훈련은 Neo4j에서 실행될 거예요. 저는 Cypher라는 멋진 그래프 쿼리 언어와 50개 이상의 그래프 알고리즘이 포함된 Graph Data Science(GDS) 플러그인을 제공하는 Neo4j를 정말 좋아해요. 덕분에 그래프를 생성하고 분석하기 위해 여러 도구를 사용할 필요가 없거든요.
Medium 데이터 세트의 그래프 스키마는 다음과 같아요:
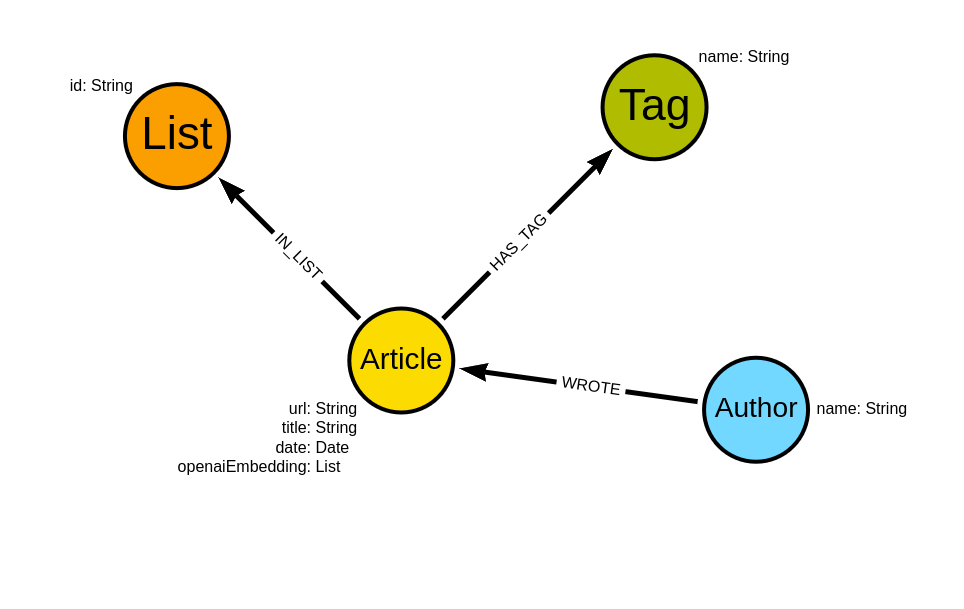
스키마는 중간 기사를 중심으로 진행돼요. 우리는 url, , 그리고 date 기사의 정보를 가지고 있죠. 또한 기사 제목과 부제를 기반으로 text-embedding-ada-002 모델을 사용하여 OpenAI의 임베딩을 계산하고 openai임베딩 속성으로 저장했어요. 기사를 작성한 사람, 해당 기사가 속한 사용자 목록 및 태그도 알고 있고요.
중간 규모 데이터 세트를 Neo4j 데이터베이스로 가져올 수 있는 두 가지 옵션을 준비했어요. 다음 Jupyter Notebook을 실행하고 Python에서 데이터 세트를 가져올 수 있어요. 이 옵션은 Neo4j 샌드박스 환경(빈 Graph Data Science 프로젝트 사용)에서도 작동한답니다.
마스터의 블로그/Import.ipynb · tomasonjo/blogs
다른 옵션은 제가 준비한 Neo4j 데이터베이스 덤프를 복원하는 거예요.
중간 덤프-v55.dump
덤프는 Neo4j 버전 5.5.0으로 생성되었으므로 해당 버전 이상을 사용해야 해요. 데이터베이스 덤프를 복원하는 가장 쉬운 방법은 Neo4j 데스크탑 환경을 사용하는 것이랍니다.
또한 다음을 설치해야 해요: APOC and GDS 라이브러리는 Neo4j Desktop 환경을 사용하는 경우 필요해요.
데이터베이스 가져오기가 완료된 후 Neo4j 브라우저에서 다음 Cypher 쿼리를 실행하여 가져오기가 성공했는지 확인할 수 있어요.
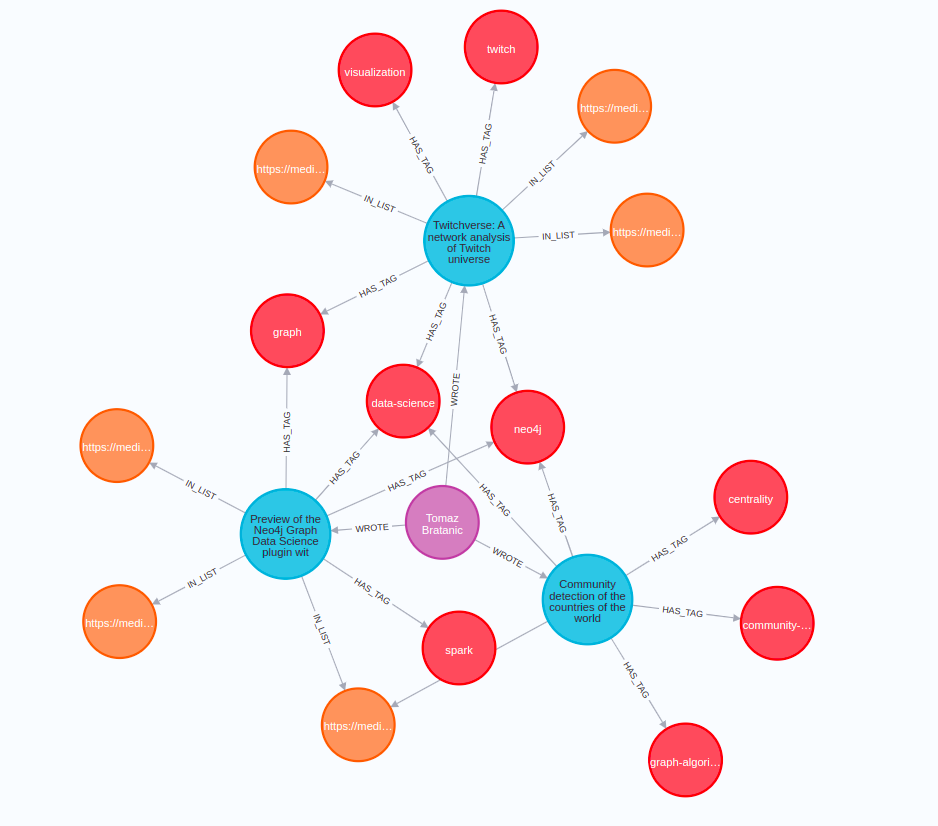
MATCH p=(n:Author)-[:WROTE]->(d)-[:IN_LIST]->(), p1=(d)-[:HAS_TAG]->()
WHERE n.name = "Tomaz Bratanic"
RETURN p,p1 LIMIT 25결과에는 목록 및 태그와 함께 제가 작성한 기사 몇 개가 포함될 거예요.
이제 이 블로그 게시물의 실제적인 부분을 살펴볼 시간이에요. 모든 분석 코드는 Jupyter Notebook으로 제공된답니다.
블로그/마스터에서 GraphSAGE.ipynb를 사용한 분류 · tomasonjo/blogs
탐색적 분석
우리는 Graph Data Science Python Client를 사용해서 Neo4j 및 Graph Data Science 플러그인과 인터페이스할 거예요. 이는 순수 Python 코드를 사용하여 그래프 알고리즘을 실행할 수 있게 해주는 Neo4j 생태계에 대한 탁월한 추가 기능이죠. 제 소개 블로그 게시물에서 자세한 내용을 확인해보세요.
먼저 매체 기사당 태그 분포를 평가해볼게요.
dist_df = gds.run_cypher("""
MATCH (a:Article)
RETURN count{(a)-[:HAS_TAG]->()} AS count
""")
sns.displot(dist_df['count'], height=6, aspect=1.5)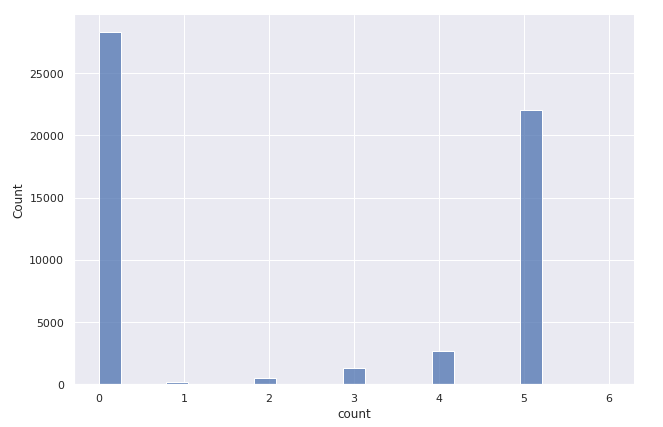
기사의 약 50%에는 태그가 없네요.
여기에는 두 가지 이유가 있어요. 작성자가 아무 것도 사용하지 않았거나 사용자 정의 HTML 구조를 가진 매체 출판물과 같은 다양한 이유로 스크랩 프로세스에서 해당 항목을 검색하지 못했을 수도 있죠. 그러나 태그가 있는 기사가 여전히 25,000개가 넘으므로 기사 태그의 다중 레이블 분류 모델을 훈련하고 평가할 수 있으므로 큰 문제는 아니에요. 대부분의 작성자는 기사당 5개의 태그를 사용하기로 선택하는데, 이는 Medium 플랫폼에서 허용하는 상한이기도 하답니다.
다음으로 사용자 목록에 포함되지 않은 기사가 있는지 평가해볼게요.
gds.run_cypher(
"""
MATCH (a:Article)
RETURN exists {(a)-[:IN_LIST]-()} AS in_list,
count(*) AS count
ORDER BY count DESC
"""
)결과는 모든 기사가 하나 이상의 목록에 속해 있음을 보여주네요. 격리된 Node(연결되지 않은 Node)를 식별하는 것은 모든 그래프 분석 워크플로에서 중요한 부분이에요. Node 임베딩을 계산하는 동안 이에 특별한 주의를 기울여야 하기 때문이죠. 다행히 이 데이터세트에는 격리된 Node가 없으므로 걱정할 필요가 없어요.
탐색적 분석의 마지막 부분에서는 가장 자주 사용되는 태그를 살펴볼게요. 여기서는 최소 100개 이상의 기사에 존재하는 태그의 단어 구름을 구성할 거예요.
tags = gds.run_cypher(
"""
MATCH (t:Tag)
WITH t, count {(t)<--()} AS size
WHERE size > 100
RETURN t.name AS tag, size
ORDER BY size DESC
"""
)
d = {}
for i, row in tags.iterrows():
d[row["tag"]] = row["size"]
wordcloud = WordCloud(
background_color="white", colormap="tab20c", min_font_size=1
).generate_from_frequencies(d)
plt.figure()
plt.imshow(wordcloud)
plt.axis("off")
plt.show()

가장 자주 사용되는 태그는 Data Science, 인공 지능, 프로그래밍, 그리고 Machine Learning이네요.
다중 라벨 분류
앞서 언급했듯이, 우리는 매체 기사의 태그를 예측하기 위해 다중 레이블 분류 모델을 훈련할 거예요. 이를 위해 scikit-multilearn 라이브러리를 사용할 건데요, 이 라이브러리가 데이터 분할 및 모델 훈련에 도움이 되거든요.
scikit-multilearn 라이브러리를 사용한 데이터세트 분할은 무작위 시드 파라미터를 제공하지 않아서 데이터세트 분할이 결정적이지 않다는 점을 확인했어요. OpenAI의 단어 임베딩으로 훈련된 기본 모델과 GraphSAGE 임베딩을 기반으로 한 모델을 제대로 비교하려면, 두 모델 버전 모두 동일한 훈련 및 테스트 예제를 사용하도록 단일 데이터 세트 분할을 수행해야 해요. 그렇지 않으면 데이터세트 분할에 따라서 모델의 정확도에 약간의 차이가 있을 수 있거든요.
단어 임베딩은 이미 그래프에 저장되어 있으니, 분류 모델을 훈련하기 전에 GraphSAGE 알고리즘을 사용해서 Node Embedding을 계산하기만 하면 돼요.
GraphSAGE
GraphSAGE는 컨볼루션 그래프 Neural Network 알고리즘이에요. 이 알고리즘의 핵심 아이디어는 Node의 로컬 이웃에서 특징 정보를 샘플링하고 집계해서 Node Embedding을 생성하는 함수를 학습하는 것이죠. GraphSAGE 알고리즘은 Node Embedding을 유도할 수 있는 함수를 학습하므로, 학습 단계에서 관찰되지 않은 새로운 Node의 Embedding을 유도하는 데에도 사용할 수 있어요. 이걸 귀납적 학습이라고 부른답니다.
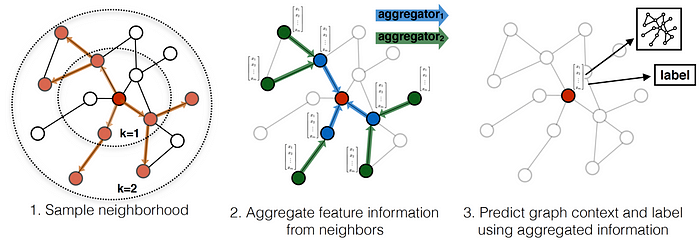
GraphSAGE에서 지역 탐색 및 정보 공유. [1]
GraphSAGE 알고리즘의 훈련 과정과 수학에 대해 더 자세히 알고 싶다면, GraphSAGE에 대한 직관적인 설명 (Rıza Özçelik의 블로그 게시물) 또는 공식 GraphSAGE 사이트를 살펴보는 걸 추천드려요.
Node Similarity 알고리즘을 사용한 단일 부분 투영
GraphSAGE는 여러 유형의 Node가 있는 그래프를 지원하는데, 각 Node 유형에는 이를 나타내는 다양한 기능이 있어요. 저희 예시에서는 Article과 List Node가 있죠. 하지만 저는 작업 흐름을 단순화하기 위해 단일 부분 투영을 수행하기로 결정했어요.
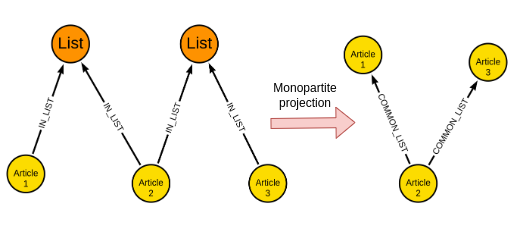
단일 부분 투영은 그래프 분석에서 자주 사용되는 단계인데요. 아이디어는 이분 그래프(두 개의 Node 유형이 있는 그래프)를 가져와서 단일 부분 그래프(단 하나의 Node 유형만 있는 그래프)를 출력하는 거예요. 이 특정 예시에서는 두 Article이 동일한 List의 일부인 경우 두 Article 간의 Relationship을 생성할 수 있어요. 또한 공유 List의 수 또는 Jaccard 계수와 같은 정규화된 값을 Relationship Property로 저장할 수도 있죠.
단일 부분 투영은 그래프 분석의 일반적인 단계이므로, Neo4j Graph Data Science 라이브러리는 Node Similarity 알고리즘을 제공해서 우리를 도와줄 수 있어요.
먼저, 메모리 내 그래프를 투영해야 해요. 우리는 Article과 List Node와 함께 IN_LIST Relationship을 사용할 거예요. 추가적으로, openaiEmbedding Node Property도 포함할 거고요.
G, metadata = gds.graph.project(
"articles",
["Article", "List"],
"IN_LIST",
nodeProperties=["openaiEmbedding"]
)이제 Node Similarity 알고리즘을 사용해서 단일 부분 투영을 수행할 수 있어요. 한 가지 주의할 점은 topK 파라미터가 10이라는 건데요. 이는 각 Node가 가장 유사한 10개의 Node에만 연결된다는 의미예요. 하지만 이 예시에서는 사용자 List의 모든 Article 간에 Relationship을 생성하려고 하니까, 상대적으로 높은 값을 사용해야겠죠. topK 파라미터에 말이에요.
gds.nodeSimilarity.mutate(
G, topK=2000, mutateProperty="score", mutateRelationshipType="SIMILAR"
)우리는 mutate 알고리즘 모드를 사용해서 결과를 메모리 내 투영 그래프에 다시 저장할 거예요. SIMILAR Relationship은 하나 이상의 사용자 List를 공유하는 모든 Article 쌍 간에 생성될 거예요.
GraphSAGE 모델 훈련
GraphSAGE 알고리즘
GraphSAGE 알고리즘은 귀납적이에요. 즉, 이전 훈련 중에 보지 못했던 `Node`에 대한 임베딩을 생성하는 데 사용할 수 있다는 거죠. 이런 귀납적 특성 덕분에 그래프의 일부에서만 GraphSAGE 모델을 훈련한 다음, 모든 `Node`에 대한 임베딩을 생성할 수 있어요.
그래프의 일부에 대해서만 GraphSAGE 모델을 훈련하면 시간과 컴퓨팅 성능을 절약할 수 있어서 큰 그래프를 처리할 때 유용해요. 그래프가 그렇게 크진 않지만, 이 예제를 통해 그래프의 훈련 하위 집합을 효율적으로 샘플링하는 방법을 보여드릴게요.
재시작 샘플링을 통한 랜덤 워크
재시작 샘플링을 통한 랜덤 워크 아이디어는 정말 간단해요. 알고리즘은 미리 정의된 시작 `Node` 집합에서 무작위로 이동하죠. 워크의 각 단계에서 현재 랜덤 워크가 중지되고 시작 `Node` 집합에서 새로운 랜덤 워크가 시작될 확률이 있어요. 사용자는 시작 `Node`를 정의할 수 있는데, 시작 `Node`가 정의되지 않은 경우 알고리즘은 이를 무작위로 균일하게 선택해요.
시작 `Node`를 수동으로 선택하는 예제를 보여드리는 게 흥미로울 것 같아서, 기사 그래프가 어떻게 연결되어 있는지 평가하기 위해 약하게 연결된 구성 요소 알고리즘을 실행하는 것부터 시작해볼게요. 약하게 연결된 구성 요소는 관계 방향을 무시할 경우, 집합의 모든 `Node` 사이에 경로가 존재하는 그래프 내의 `Node` 집합이에요.
약하게 연결된 구성 요소는 다른 구성 요소의 `Node`가 도달할 수 없는 섬으로 간주될 수 있어요. 알고리즘은 연결된 `Node` 집합을 식별하지만, 그 출력은 전체 그래프의 연결이 얼마나 끊어졌는지 평가하는 데 도움이 될 수 있죠.
wcc = gds.wcc.stream(G)
wcc_grouped = (
wcc.groupby("componentId")
.size()
.to_frame("componentSize")
.reset_index()
.sort_values("componentSize", ascending=False)
.reset_index()
)
print(wcc_grouped)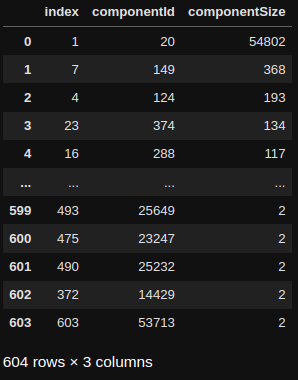
그래프에는 총 604개의 연결된 구성 요소가 있어요. 가장 큰 구성 요소는 모든 `Node`의 98%를 포함하고, 다른 구성 요소는 더 작으며 많은 구성 요소가 2개의 `Node`만 포함하고 있죠. 구성 요소에 `Node`가 두 개만 있다면, 기사가 두 개만 있는 중간 규모 사용자 목록이 있고 해당 두 기사는 다른 목록의 일부가 아니라는 의미예요.
우리는 Weakly Connected Component 알고리즘을 실행해서 큰 연결된 구성 요소에 속하는 `Node`를 식별하고, 따라서 샘플링 알고리즘의 시작 `Node`로 사용할 수 있어요. 예를 들어, 이웃이 하나만 있는 `Node`를 사용한 경우 샘플링 알고리즘은 그래프를 효율적으로 서브샘플링하기 위해 더 긴 탐색을 수행할 수 없겠죠.
다행히 샘플링 알고리즘은 랜덤 워크가 새 `Node`를 방문하지 않는 경우 시작 `Node` 세트를 자동으로 확장하도록 구현되어 있어요. 하지만 모든 `Node`의 98%를 차지하는 가장 큰 연결된 구성 요소의 시작 `Node`를 사용했기 때문에 알고리즘은 시작 `Node` 세트를 자동으로 확장할 필요가 없어요.
largest_component = wcc_grouped["componentId"][0]
start_node = wcc[wcc["componentId"] == largest_component]["nodeId"][0]
trainG, metadata = gds.alpha.graph.sample.rwr(
"trainGraph",
G,
samplingRatio=0.20,
startNodes=[int(start_node)],
nodeLabels=["Article"],
relationshipTypes=["SIMILAR"],
)샘플링 비율 매개변수는 샘플링할 원본 그래프의 `Node` 비율을 정의해요. 예를 들어 샘플링 비율로 0.20 값을 사용하면 샘플링된 하위 그래프는 원래 그래프 크기의 20%가 되죠. 추가적으로 우리는 랜덤 워크가 오직 방문만 할 수 있도록 정의해야 해요. `Node`를 통해 `Relationship`을 이용해서 Node Label and Relationship Type 매개변수.
GraphSAGE 훈련
마지막으로 샘플링된 하위 그래프에서 GraphSAGE 모델을 훈련할 수 있어요.
gds.beta.graphSage.train(
trainG,
modelName="articleModel",
embeddingDimension=256,
sampleSizes=[10, 10],
searchDepth=15,
epochs=20,
learningRate=0.0001,
activationFunction="RELU",
aggregator="MEAN",
featureProperties=["openaiEmbedding"],
batchSize=10,
)GraphSAGE 알고리즘은 openaiEmbedding `Node` 속성을 입력 기능으로 사용해요. GraphSAGE 임베딩의 차원은 256(벡터 크기)이죠. 이 블로그에서 하이퍼 파라미터 최적화를 시도해 보는 동안 학습률과 활성화 함수가 가장 영향력 있는 매개변수라는 것을 알게 되었어요.
임베딩 생성
GraphSAGE 모델이 훈련된 후에는 이를 사용해서 모든 `Node`에 대한 `Node` 임베딩을 계산할 수 있어요. 원래의 더 큰 투영 그래프의 `Node`를 고려하고 `Relationship`을 사용해서요.
gds.beta.graphSage.write(
G,
modelName="articleModel",
nodeLabels=["Article"],
writeProperty="graphSAGE",
relationshipTypes=["SIMILAR"],
)이번에는 GraphSAGE 임베딩을 데이터베이스의 `Node` 속성으로 저장하는 모드에요.
분류 모델
OpenAI 및 GraphSAGE 임베딩을 모두 준비했어요. 이제 남은 건 모델을 훈련하고 성능을 비교하는 것뿐이죠.
먼저 예측하려는 기사 태그에 라벨을 지정할게요. 저는 임의로 최소 100개 이상의 기사에 존재하는 태그만 포함하기로 결정했어요. 대상 태그에는 보조 태그가 지정됩니다. 상표.
gds.run_cypher(
"""
MATCH (t:Tag)
WHERE count{(t)<--()} > 100
SET t:Target
RETURN count(*) AS count
"""
)예측하려는 태그 161개에 라벨을 붙였어요. 위 단어 클라우드 시각화는 동일한 161개의 태그를 빈도에 따라 시각화한 것이라는 점, 기억하시죠?
scikit-multilearn 라이브러리를 사용할 거니까, Neo4j에서 관련 정보를 내보내야 해요.
data = gds.run_cypher(
"""
MATCH (a:Article)-[:HAS_TAG]->(tag:Target)
RETURN a.url AS article,
a.openaiEmbedding AS openai,
a.graphSAGE AS graphSAGE,
collect(tag.name) AS tags
"""
)다음으로, 특정 기사에 대한 태그의 존재를 나타내는 이진 행렬을 만들어야 해요. 기본적으로 기사당 태그를 one-hot encoding하는 거라고 생각하면 돼요. 이걸 위해 MultiLabelBinarizer 절차를 활용할 수 있어요.
mlb = MultiLabelBinarizer()
tags_mlb = mlb.fit_transform(data["tags"])
data["target"] = list(tags_mlb)scikit-multilearn 라이브러리는 다중 레이블 예측 작업을 위한 향상된 데이터 세트 분할을 제공해요. 하지만 무작위 시드 매개변수를 사용하는 결정론적 접근 방식은 허용되지 않으니까, Word Embedding과 GraphSAGE Embedding 모두에 대해 데이터 세트 분할을 한 번만 수행한 다음, 그에 따라 두 모델을 학습시킬 거예요.
다음 함수는 다중 레이블 분류 모델에 대한 입력 기능으로 별도로 사용해야 하는 데이터 프레임과 열을 가져와 가중치가 적용된 매크로와 가중치가 적용된 정밀도를 인쇄하는 동안 가장 성능이 좋은 모델을 반환해요. 여기서는 LabelPowerset 접근 방식을 사용한 다중 라벨 분류를 진행할 거예요.
def train_and_evaluate(df, input_columns):
max_weighted_precision = 0
best_input = ""
# Single split data
X = data[input_columns].values
y = np.array(data["target"].to_list())
x_train_all, y_train, x_test_all, y_test = iterative_train_test_split(
X, y, test_size=0.2
)
# Train a model for each input option
for i, input_column in enumerate(input_columns):
print(f"Training a model based on {input_column} column")
x_train = np.array([x[i] for x in x_train_all])
x_test = np.array([x[i] for x in x_test_all])
# train
classifier = LabelPowerset(LogisticRegression())
classifier.fit(x_train, y_train)
# predict
predictions = classifier.predict(x_test)
print("Test accuracy is {}".format(accuracy_score(y_test, predictions)))
print(
"Macro Precision: {:.2f}".format(
get_macro_precision(mlb.classes_, y_test, predictions)
)
)
weighted_precision = get_weighted_precision(mlb.classes_, y_test, predictions)
print("Weighted Precision: {:.2f}".format(weighted_precision))
if weighted_precision > max_weighted_precision:
max_weighted_precision = weighted_precision
best_classifier = classifier
best_input = input_column
return best_classifier, best_input자, 이제 모든 준비가 끝났으니 Word Embedding과 graphSAGE Embedding을 기반으로 모델을 훈련하고 성능을 비교해 볼까요?
추신. Google Colab을 사용하는 경우, openai Embedding을 사용하면 OOM 문제가 발생할 수 있다는 점 참고해주세요!
classifier, best_input = train_and_evaluate(data, ["openai", "graphSAGE"])결과는 다음과 같아요.
Training a model based on openai column
Test accuracy is 0.055443548387096774
Macro Precision: 0.20
Weighted Precision: 0.36
Training a model based on graphSAGE column
Test accuracy is 0.05584677419354839
Macro Precision: 0.30
Weighted Precision: 0.41제목과 부제의 임베딩이 해당 태그에 대한 정보를 제공하긴 하지만, 효율적이지 않을 수 있어요. 왜냐하면 콘텐츠를 정확하게 설명하기보다는 관심을 끄는 클릭베이트 스타일의 제목을 우선시하기 때문일 수 있죠. 또한 작성자마다 다양한 레이블을 사용해서 동일한 콘텐츠에 태그를 지정하는 것에 대한 선호도가 다를 수도 있고요. 이런 어려움에도 불구하고, 우리 모델은 161개의 레이블을 예측하는데, 그 중 다수에는 예시가 거의 없는데도 허용 가능한 결과를 얻을 수 있다는 점이 놀라워요. 정확성을 더 높이기 위해 전체 기사 텍스트를 삽입하고 성능을 평가해볼 수도 있겠죠.
흥미롭게도 GraphSAGE 임베딩을 사용하면 기사 간의 관계를 고려해서 분류 정확도가 향상돼요. 우리 모델의 매크로 정밀도는 10% 포인트나 향상되고, 가중 정밀도는 5% 향상되죠. 이런 결과는 GraphSAGE 임베딩이 자주 사용되지 않는 태그를 더 효과적으로 식별하는 데 도움이 된다는 것을 보여줘요. 표준 단어 임베딩 모델과 달리, 그래프 Neural Network를 사용하면 데이터 포인트 간의 추가 관계를 인코딩할 수 있어서 다운스트림 Machine Learning 모델 성능이 향상되는 거죠. 게다가 성능을 높이면서 차원 축소를 1536에서 256으로 수행했는데, 이건 정말 큰 성과라고 할 수 있어요.
테스트 예측
우리 데이터베이스에는 태그가 없는 기사가 거의 50%나 돼요. 여러 모델에서 모델을 테스트하고 결과를 직접 평가해볼 수 있어요.
example = gds.run_cypher(
"""
MATCH (a:Article)
WHERE NOT EXISTS {(a)-[:HAS_TAG]->()}
RETURN a.title AS title,
a.openaiEmbedding AS openai,
a.graphSAGE AS graphSAGE
LIMIT 15
"""
)
tags_predicted = classifier.predict(np.array(example[best_input].to_list()))
example["tags"] = [list(mlb.inverse_transform(x)[0]) for x in tags_predicted]
example[["title", "tags"]]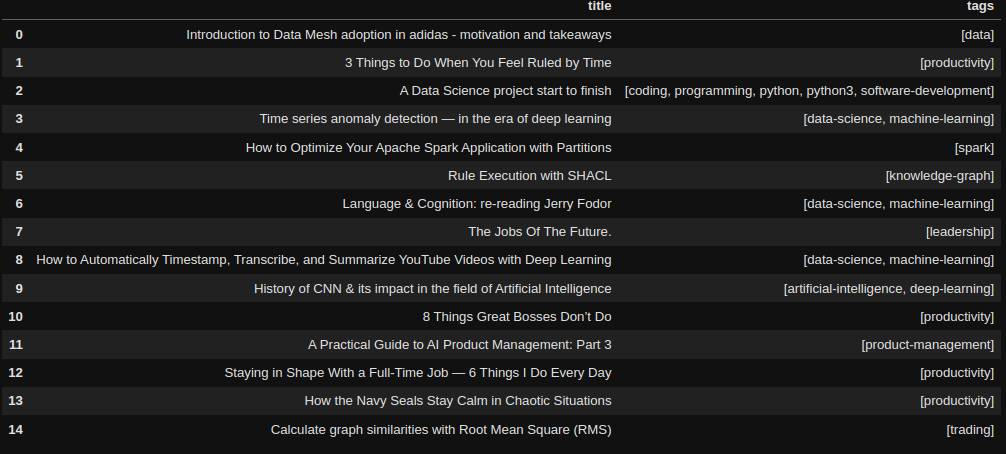
흥미롭게도 모델은 대부분의 실제 기사에 5개의 태그가 있는 반면, 기사당 하나 또는 두 개의 레이블만 할당해요. 아마도 이게 정밀도 점수 값의 원인 중 하나일 거예요. 그 외에는 이 작은 샘플로 판단했을 때 결과가 꽤 유망해 보이죠?
요약
word2vec과 같은 전통적인 단어 임베딩 모델은 단어의 동시 발생 통계를 인코딩하는 데 중점을 둬요. 하지만 데이터 포인트 간에 찾을 수 있는 다른 관계는 완전히 무시되죠. 예를 들어, 유사한 기사를 다양한 읽기 목록에 배치해서 사용자에게 주석을 달도록 하는 경우가 있어요. 다행히 그래프 Neural Network는 단어 임베딩을 기반으로 구축하고 데이터 포인트 간의 관계에서 파생된 추가 정보를 인코딩할 수 있어서 전통적인 단어 임베딩과 그래프 임베딩 사이에 다리를 제공해준답니다. 따라서 그래프 Neural Network는 처음부터 시작할 필요 없이 최첨단 단어 또는 문서 임베딩을 향상시키는 데 사용할 수 있어요.
참고 자료
[1] 해밀턴, 윌, Zhitao Ying, Jure Leskovec. “대형 그래프에서의 유도적 표현 학습.” 신경 정보 처리 시스템의 발전. 2017.
- 그래프 Neural Network
- GraphSAGE
- 다중 라벨 분류기
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'GraphRAG' 카테고리의 다른 글
| 지식 그래프와 LLM: Fine-Tuning vs. Retrieval-Augmented Generation (GraphRAG) 완벽 비교 (1) | 2026.04.30 |
|---|---|
| Databricks에서 Neo4j GraphRAG로 임팩트 있는 인사이트 찾기 (0) | 2026.04.29 |
| GraphRAG Python 패키지로 그래프 탐색을 활용하여 하이브리드 검색 성능 향상시키기 (0) | 2026.04.29 |
| Neo4j에서 임베딩으로 문자열 편집 거리 표현하기 (0) | 2026.04.28 |
| Text2CypherRetriever로 Neo4j GraphRAG, 쉽게 시작하기 (0) | 2026.04.28 |