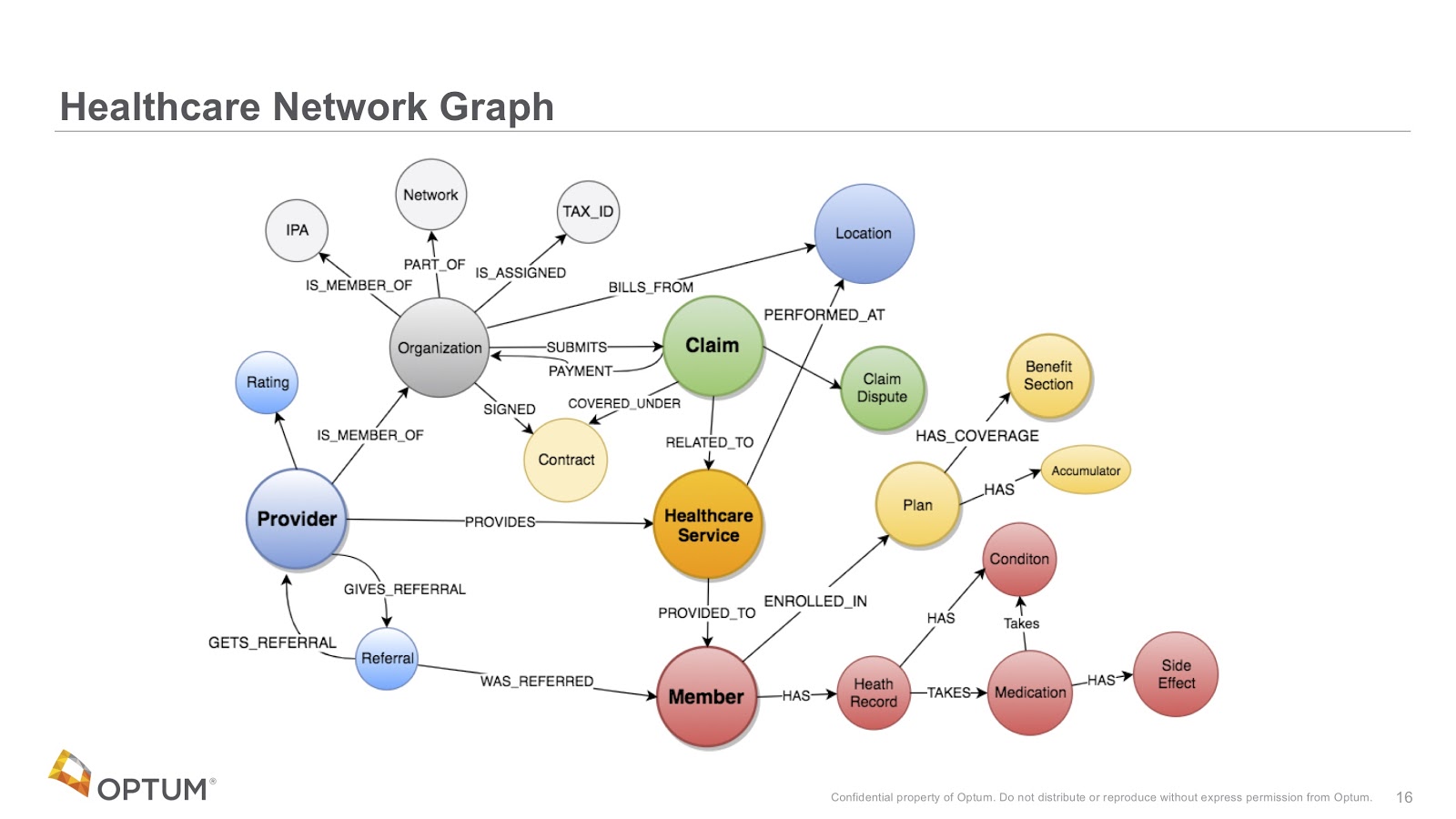
데이터에서 얼마나 효과적으로 통찰력을 뽑아내느냐에 따라 기업의 성패가 갈리는 시대가 왔어요. 기존 인프라에서 더 많은 가치를 얻는 방법은 여러 가지가 있죠. 더 많은 데이터를 수집하거나, 더 복잡한 모델을 구축하거나, 아니면 이미 가지고 있는 데이터를 재구성해서 이전에는 보지 못했던 패턴을 찾아낼 수도 있어요. 마지막 방법은 그래프 모델링과 그래프 알고리즘을 활용해서 연결된 데이터 전체에서 영향력, 중심성, 커뮤니티, 그리고 숨겨진 관계를 찾아내는 데 효과적이에요.
중요한 점은, 이렇게 풍부한 통찰력을 얻기 위해 BigQuery 외부에 별도의 인프라를 구축할 필요가 없다는 거예요. 데이터 세트가 커질수록 NetworkX 같은 기존 오픈 소스 도구는 단일 시스템 이상으로 확장하기 어려울 수 있지만, Aura Graph Analytics는 최소한의 운영 부담으로 확장 가능한 그래프 처리를 제공하거든요. 아래 예시에서는 Aura Graph Analytics가 BigQuery 워크플로우에 얼마나 자연스럽게 녹아드는지 보여드릴게요. 데이터를 `쿼리`하고, Pandas DataFrame에 로드하고, Python에서 직접 강력한 그래프 알고리즘을 실행하고, 원한다면 컴퓨팅과 스토리지를 분리하는 익숙한 종량제 환경 내에서 풍부한 결과를 다시 웨어하우스에 저장할 수 있어요.
그래프 분석 + BigQuery
Neo4j는 BigQuery를 포함해서 기업 데이터가 어디에 있든 유연하게 작업할 수 있도록 Aura Graph Analytics를 만들었어요. BigQuery 데이터에 연결하는 방법은 간단해요. 흐름을 한번 살펴볼까요?
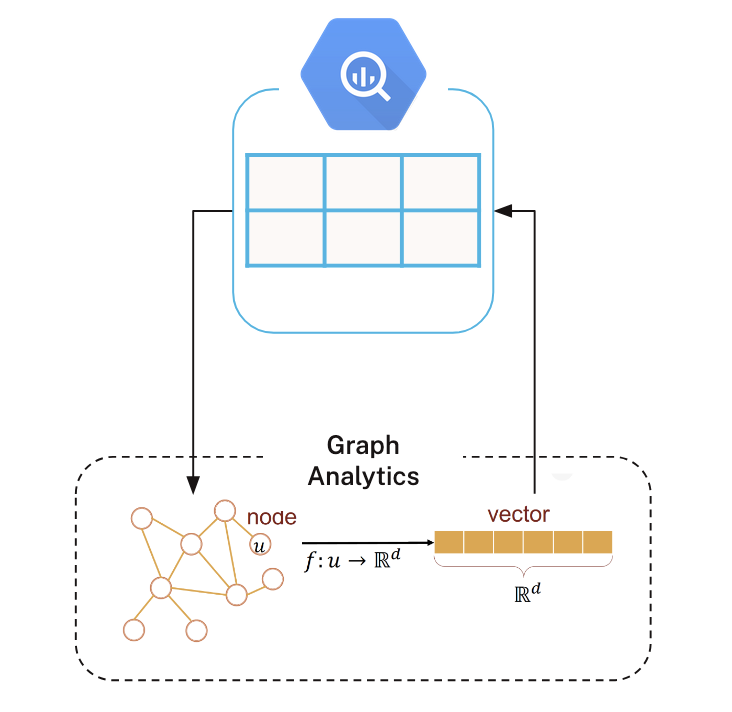
먼저 BigQuery에서 SQL `쿼리`를 작성해서 그래프로 모델링하고 싶은 데이터를 추출하고, 결과를 Python 데이터 프레임에 로드해요. 일반적으로 `노드`용 데이터프레임 하나와 `관계`용 데이터프레임(에지 목록)을 각각 만들게 되죠.
다음으로, Aura의 서버리스 인프라에서 세션을 시작하고 그래프를 메모리에 투영해요. 그래프 투영은 그래프 알고리즘 실행을 위해 특별히 최적화된 메모리 내 표현 방식이에요.
일단 투영이 끝나면 Aura의 컴퓨팅 환경에서 알고리즘을 실행할 수 있어요. 오른쪽에 보이는 다이어그램에서는 임베딩 알고리즘을 사용해서 `노드`의 `Vector Embedding`을 생성한 다음, Python 데이터 프레임에 다시 저장하는 과정을 보여주고 있어요.
여기에서 다운스트림 Machine Learning 워크플로우에서 이러한 그래프 기반 기능을 사용하거나, 더 광범위한 분석 및 운영을 위해 BigQuery에 다시 쓸 수도 있죠.
데이터 가져오기
BigQuery 공개 데이터 세트 중 하나의 데이터를 사용해서 관리하기 쉬운 Stack Overflow 댓글의 하위 그래프를 만들어 볼 거예요.
이 `쿼리`는 허브 역할을 할 많은 개별 댓글 작성자가 있는 매우 활동적인 게시물을 선택하는 것으로 시작돼요. 그런 다음 해당 허브(첫 번째 홉)에서 모든 댓글을 수집하고 바깥쪽으로 확장해서 동일한 사용자가 댓글을 남긴 다른 게시물을 캡처하죠(두 번째 홉). 마지막으로 두 번째 홉 게시물에 대한 모든 댓글을 포함시켜요.
이 접근 방식은 데모에서 WCC 또는 PageRank와 같은 그래프 알고리즘을 실행하는 데 이상적인, 컴팩트하고 대부분 연결된 사용자 게시물 하위 그래프를 생성하는 동시에 데이터 볼륨을 작고 작업하기 쉽게 유지해 준답니다.
%%bigquery df
WITH hub_post AS (
SELECT post_id
FROM `bigquery-public-data.stackoverflow.comments`
WHERE user_id IS NOT NULL
GROUP BY post_id
ORDER BY COUNT(DISTINCT user_id) DESC
LIMIT 1
),
-- 2) First hop: all comments on the hub post
h1_comments AS (
SELECT user_id, post_id
FROM `bigquery-public-data.stackoverflow.comments`
WHERE post_id IN (SELECT post_id FROM hub_post)
AND user_id IS NOT NULL
),
-- 3) Second hop: all other posts commented on by those users
h2_posts AS (
SELECT DISTINCT c.post_id
FROM `bigquery-public-data.stackoverflow.comments` c
JOIN h1_comments h1
ON c.user_id = h1.user_id
WHERE c.post_id != h1.post_id
),
-- 4) Bring in all comments on those second-hop posts
h2_comments AS (
SELECT user_id, post_id
FROM `bigquery-public-data.stackoverflow.comments`
WHERE post_id IN (SELECT post_id FROM h2_posts)
AND user_id IS NOT NULL
)
-- 5) 결정적인 connected slice: hub post + second-hop posts
SELECT user_id, post_id
FROM h1_comments
UNION ALL
SELECT user_id, post_id
FROM h2_comments코드 언어: PHP (php)결과는 다음과 같이 저장됩니다. df Neo4j Aura Graph Analytics와 함께 사용할 준비가 거의 완료되었어요.
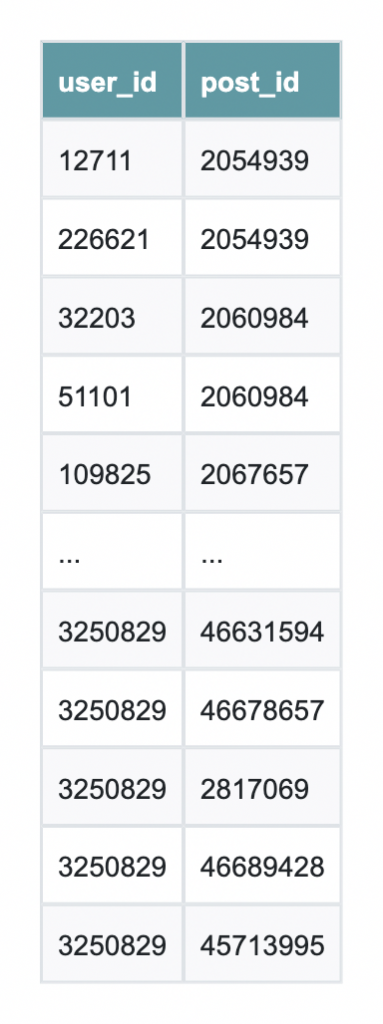
그래프 분석 설정
먼저 패키지를 다운로드해요.
!pip install graphdatascience그런 다음 필요한 모든 패키지를 가져옵니다.
from graphdatascience.session import DbmsConnectionInfo, AlgorithmCategory, CloudLocation, GdsSessions, AuraAPICredentials
from datetime import timedelta
import pandas as pd
import os
from google.colab import userdata코드 언어: 자바스크립트 (자바스크립트)이제 Aura 자격 증명을 사용해서 세션을 만들어볼게요. 이걸 하려면 Graph Analytics가 포함된 Aura 계정이 필요해요.
CLIENT_ID = 'your_client_id'
CLIENT_SECRET = 'your_client_secret'
TENANT_ID = 'your_tenent_id'코드 언어: 자바스크립트 (자바스크립트)from graphdatascience.session import GdsSessions, AuraAPICredentials, AlgorithmCategory, CloudLocation
from datetime import timedelta
sessions = GdsSessions(api_credentials=AuraAPICredentials(CLIENT_ID, CLIENT_SECRET, TENANT_ID))
name = "내-새 세션-SM"
memory = sessions.estimate(
node_count=20,
relationship_count=50,
algorithm_categories=[AlgorithmCategory.CENTRALITY, AlgorithmCategory.NODE_EMBEDDING],
)
cloud_location = CloudLocation(provider="gcp", region="유럽-서부1")
gds = sessions.get_or_create(
session_name=name,
memory=memory,
ttl=timedelta(hours=5),
cloud_location=cloud_location,
)
코드 언어: 자바스크립트 (자바스크립트)그 다음엔 데이터를 올바른 형식으로 만들기 위해 약간의 데이터 정리를 해줄 거예요.
# 음수 ID가 있는 행을 삭제합니다.
df = df[(df["사용자_ID"] >= 0) & (df["게시물_ID"] >= 0)]
# Node
users = pd.DataFrame({
"노드 ID": df["사용자_ID"].dropna().unique(),
})
users["라벨"] = [["사용자"]] * len(users)
posts = pd.DataFrame({
"노드 ID": df["게시물_ID"].dropna().unique(),
})
posts["라벨"] = [["우편"]] * len(posts)
nodes = pd.concat([users, posts], ignore_index=True)
# Relationship(이분할 에지: 사용자 -> 게시, 방향이 지정되지 않은 WCC의 경우 역)
rels_forward = pd.DataFrame({
"소스노드 ID": df["사용자_ID"],
"targetNodeId": df["게시물_ID"],
"관계 유형": "COMMENTED_ON"
})
rels_reverse = pd.DataFrame({
"소스노드 ID": df["게시물_ID"],
"targetNodeId": df["사용자_ID"],
"관계 유형": "COMMENTED_ON"
})
relationships = pd.concat([rels_forward, rels_reverse], ignore_index=True).drop_duplicates()
코드 언어: PHP (php)그래프 생성 및 알고리즘 실행
다음으로는 gds.graph.construct 메서드를 사용해서 그래프 투영을 만들어볼게요. 이렇게 하면 알고리즘을 실행하기 위한 인-메모리 그래프가 생성된답니다.
if gds.graph.exists("so_comments_bip")["존재한다"]:
gds.graph.drop("so_comments_bip")
G = gds.graph.construct("so_comments_bip", nodes, relationships)코드 언어: 자바스크립트 (자바스크립트)가장 먼저 Weakly Connected Components를 사용해서 모든 컴포넌트가 동일한 커뮤니티에 있는지 확인해볼까요? 만약 그렇다면 다른 Node에서 특정 Node에 도달할 수 있다는 뜻이니까, 그래프가 연결되어 있다는 의미가 되겠죠!
wcc = gds.wcc.stream(G) # nodeId, componentId, size(버전에 따라 다름) 열이 있는 pandas DataFrame을 반환합니다.코드 언어: PHP (php)왜냐하면 다들 똑같은 componenetId를 갖고 있으니까, 실제로는 동일한 커뮤니티에 속해 있어서 전체 그래프가 연결되어 있음을 추론할 수 있어요. 그리고 간단한 Python 호출을 통해 지루한 데이터 검증 작업을 수행할 수 있죠.
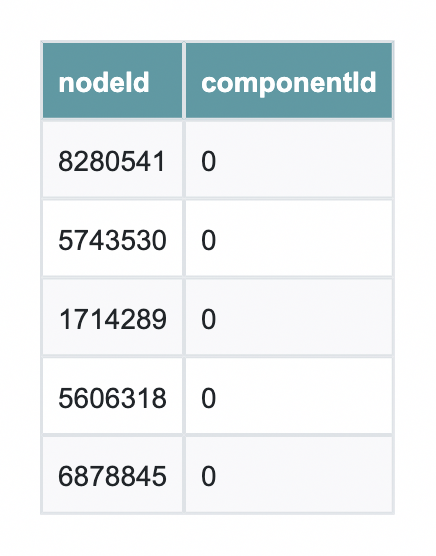
다음으로 연결된 하위 그래프에서 PageRank를 실행해서 가장 영향력 있는 Node를 식별해요.
PageRank는 연결만 계산하는 게 아니에요. 연결의 품질을 측정해서 토론의 중심에 있는 사용자나 게시물을 강조하죠. 상위 결과를 살펴보면 어떤 Node가 네트워크에서 구조적으로 중요하고 추가 조사에 가장 영향력이 있는지 빠르게 확인할 수 있어요.
재미있는 보너스 퀴즈로 PageRank는 원래 Google을 강화하기 위해 개발되었다는 사실!
# PageRank 실행(결과를 Pandas로 다시 스트리밍)
pr = gds.pageRank.stream(
G,
maxIterations=20,
dampingFactor=0.85
)
# 상위 결과를 정렬하고 검사합니다.
pr_sorted = pr.sort_values("점수", ascending=)
pr_sorted.head(10)코드 언어: PHP (php)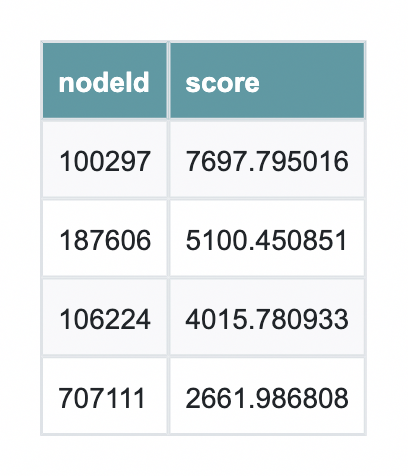
여기에서 강화된 DataFrame을 데이터베이스에 다시 쓰거나, 기능 엔지니어링, 순위 지정 또는 이상 탐지와 같은 작업을 위해 다운스트림 Machine Learning 워크플로에서 직접 사용할 수 있어요. 여기서 본 것은 하나의 예일 뿐이에요. 한번 살펴볼까요? 전체 그래프 알고리즘 제품군은 커뮤니티를 발견하고, 유사성을 감지하고, 영향력을 계산하고, 연결된 데이터에서 더 깊은 통찰력을 얻을 수 있는 임베딩을 생성할 수 있도록 도와줘요.
이 분석에서는 다음을 사용합니다. 스택 오버플로 BigQuery를 통해 사용할 수 있는 데이터 세트입니다. 원본 콘텐츠는 Stack Overflow 커뮤니티에서 제공하며 CC-BY-SA 3.0에 따라 라이선스가 부여됩니다. 블로그의 이 소스에서 생성된 모든 파생 데이터 테이블 또는 하위 그래프에는 동일한 라이선스가 적용됩니다.
- 그래프 데이터 과학
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'GraphRAG' 카테고리의 다른 글
| Neo4j에서 임베딩으로 문자열 편집 거리 표현하기 (0) | 2026.04.28 |
|---|---|
| Text2CypherRetriever로 Neo4j GraphRAG, 쉽게 시작하기 (0) | 2026.04.28 |
| 파라다이스 페이퍼 심층 그래프 분석: Neo4j와 GraphRAG로 파헤치다 (0) | 2026.04.27 |
| DeepWalk: 스티븐 스키에나 박사와의 5분 인터뷰 (1) | 2026.04.27 |
| Cypher 웨비나 후기: Neo4j, GraphRAG 활용 인사이트 (1) | 2026.04.27 |