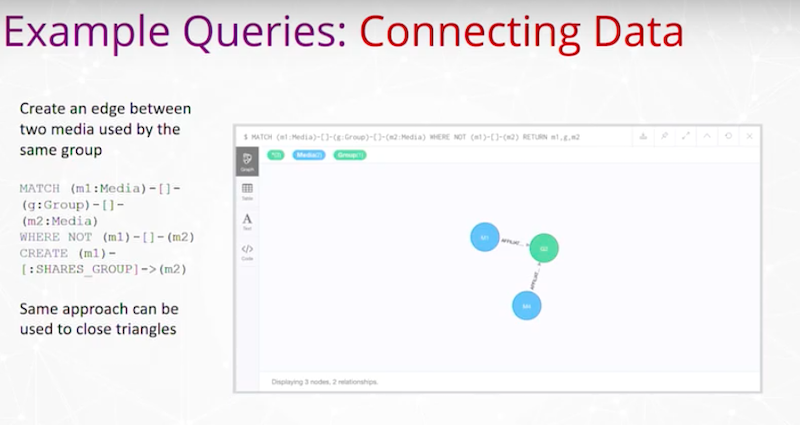
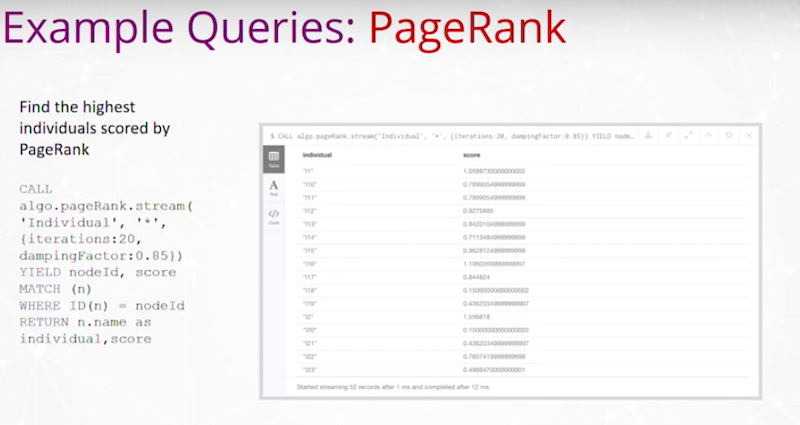
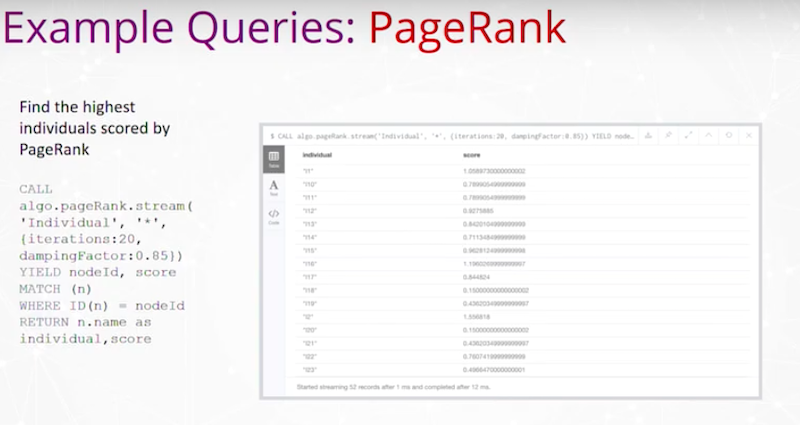
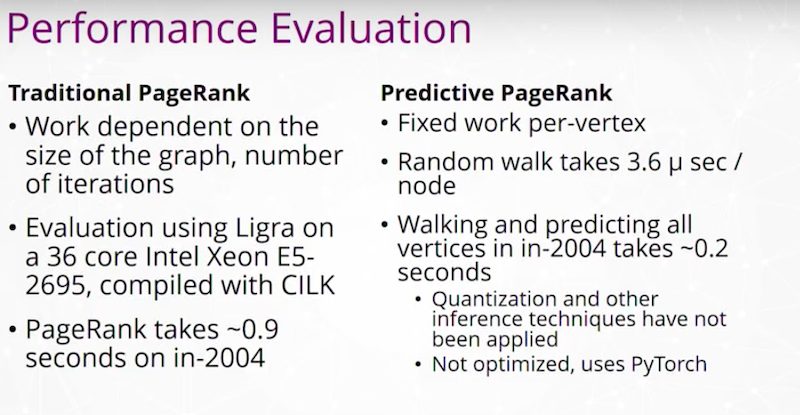
Knowledge Graph와 구조화된 도구를 사용해서 문제 해결하는 방법을 알아봐요.
텍스트 임베딩 모델, 다들 좋아하시죠? 구조화되지 않은 텍스트 인코딩에 아주 뛰어나서 의미상 유사한 콘텐츠를 더 쉽게 찾을 수 있게 해주니까요. 특히 문서나 다른 텍스트 리소스에서 관련 정보를 인코딩하고 검색하는 데 집중하는 요즘 대부분의 RAG 애플리케이션의 핵심이라는 점은 놀랍지 않아요. 하지만 RAG 애플리케이션에서 텍스트 임베딩 접근 방식이 부족하거나 잘못된 정보를 전달하는 경우를 생각해 볼 만한 명확한 예시들이 있답니다.
앞서 말씀드렸듯이 텍스트 임베딩은 구조화되지 않은 텍스트를 인코딩하는 데 탁월해요. 하지만 구조화된 정보, 예를 들어 , , 또는 같은 작업에는 그렇게 능숙하지 않죠. 간단한 질문을 하나 생각해 볼까요?
2024년에 개봉한 영화 중에서 가장 높은 평가를 받은 영화는 무엇인가요?
이 질문에 답하려면 먼저 출시 연도별로 필터링한 다음, 평점별로 정렬해야 해요. 텍스트 임베딩을 사용한 순진한 접근 방식이 어떻게 작동하는지 살펴보고, 이런 질문을 처리하는 방법을 보여드릴게요. 이번 블로그 포스팅에서는 구조화된 데이터 작업을 다룰 때 필터링, 정렬, 집계 등의 구조를 제공하는 다른 도구, 즉 Knowledge Graph를 사용해야 한다는 점을 강조할 거예요. 코드는 에서 확인하실 수 있습니다.
환경 설정
이번 블로그 포스팅에서는 Neo4j Sandbox의 추천 프로젝트를 사용할 거예요. 추천 프로젝트는 MovieLens 데이터 세트를 사용하는데, 여기에는 영화, 배우, 평점 등 다양한 정보가 담겨 있답니다.

다음 코드는 Neo4j 데이터베이스에 연결하기 위해 LangChain 래퍼를 인스턴스화해요.
os.environ["NEO4J_URI"] = "bolt://44.204.178.84:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "minimums-triangle-saving"
graph = Neo4jGraph(refresh_schema=False)
다음 코드에 전달할 OpenAI API 키도 필요해요.
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")데이터베이스에는 10,000개의 영화가 있지만, 아직 텍스트 임베딩이 저장되어 있지는 않아요. 모든 항목에 대한 임베딩 계산을 피하기 위해 최고 평점 영화 1,000개에 "Target"이라는 보조 라벨을 지정할 거예요.
graph.query("""
MATCH (m:Movie)
WHERE m.imdbRating IS NOT NULL
WITH m
ORDER BY m.imdbRating DESC
LIMIT 1000
SET m:Target
""")텍스트 임베딩 계산 및 저장
어떤 내용을 임베딩할지 결정하는 건 중요한 고려 사항이에요. 연도별 필터링과 평점별 정렬을 보여드릴 예정이니, 임베딩 텍스트에서 해당 세부 정보를 제외하는 건 공정하지 않겠죠? 그래서 각 영화의 개봉 연도, 평점, 제목, 설명을 모두 캡처하기로 했어요.
다음은 임베딩할 텍스트의 예시입니다. 영화 "더 울프 오브 월 스트리트"의 경우:
plot: Based on the true story of Jordan Belfort, from his rise to a wealthy
stock-broker living the high life to his fall involving crime, corruption
and the federal government.
title: Wolf of Wall Street, The
year: 2013
imdbRating: 8.2이게 구조화된 데이터를 임베딩하는 데 좋은 접근 방식이 아니라고 생각할 수도 있지만, 저는 최고의 접근 방식을 모르기 때문에 딱히 반박하진 않을게요. 키-값 항목 대신 텍스트 등으로 변환해야 할 수도 있겠죠. 더 나은 방법이 있다면 알려주세요!
LangChain의 Neo4j Vector 객체에는 from_existing_graph라는, 인코딩해야 하는 텍스트 속성을 선택할 수 있는 편리한 방법이 있어요.
embedding = OpenAIEmbeddings(model="text-embedding-3-small")
neo4j_vector = Neo4jVector.from_existing_graph(
embedding=embedding,
index_name="movies",
node_label="Target",
text_node_properties=["plot", "title", "year", "imdbRating"],
embedding_node_property="embedding",
)이 예시에서는 임베딩 생성을 위해 OpenAI의 text-embedding-3-small 모델을 사용하고 있어요. from_existing_graph 메서드를 사용해서 Neo4jVector 객체를 초기화하죠. node_label 매개변수는 인코딩할 노드를 필터링하는데, 특히 "Target" 라벨이 붙은 노드만 선택해요. text_node_properties 매개변수는 포함될 노드 속성을 정의하는데, 여기에는 plot, title, year, 그리고 imdbRating이 포함돼요. 마지막으로, embedding_node_property는 생성된 임베딩이 저장될 속성을 정의하는데, 여기서는 embedding을 사용하고 있어요.
순진한 접근 방식
줄거리나 설명을 기반으로 영화를 찾는 것부터 시작해 볼까요?
pretty_print(
neo4j_vector.similarity_search(
"What is a movie where a little boy meets his hero?"
)
)결과는 다음과 같아요:
plot: A young boy befriends a giant robot from outer space that a paranoid government agent wants to destroy.
title: Iron Giant, The
year: 1999
imdbRating: 8.0
plot: After the death of a friend, a writer recounts a boyhood journey to find the body of a missing boy.
title: Stand by Me
year: 1986
imdbRating: 8.1
plot: A young, naive boy sets out alone on the road to find his wayward mother. Soon he finds an unlikely protector in a crotchety man and the two have a series of unexpected adventures along the way.
title: Kikujiro (Kikujirô no natsu)
year: 1999
imdbRating: 7.9
plot: While home sick in bed, a young boy's grandfather reads him a story called The Princess Bride.
title: Princess Bride, The
year: 1987
imdbRating: 8.1결과는 전반적으로 꽤 괜찮은 것 같아요. 항상 어린 소년이 등장하지만, 그가 항상 영웅을 만나는지는 잘 모르겠네요. 그리고 데이터 세트에는 영화가 1,000개밖에 없어서 옵션이 다소 제한적이에요.
이제 몇 가지 기본적인 필터링이 필요한 쿼리를 시도해 볼게요.
pretty_print(
neo4j_vector.similarity_search(
"Which movies are from year 2016?"
)
)결과:
plot: Six short stories that explore the extremities of human behavior involving people in distress.
title: Wild Tales
year: 2014
imdbRating: 8.1
plot: A young man who survives a disaster at sea is hurtled into an epic journey of adventure and discovery. While cast away, he forms an unexpected connection with another survivor: a fearsome Bengal tiger.
title: Life of Pi
year: 2012
imdbRating: 8.0
plot: Based on the true story of Jordan Belfort, from his rise to a wealthy stock-broker living the high life to his fall involving crime, corruption and the federal government.
title: Wolf of Wall Street, The
year: 2013
imdbRating: 8.2
plot: After young Riley is uprooted from her Midwest life and moved to San Francisco, her emotions - Joy, Fear, Anger, Disgust and Sadness - conflict on how best to navigate a new city, house, and school.
title: Inside Out
year: 2015
imdbRating: 8.3웃기게도 2016년 영화는 하나도 선택되지 않았네요. 어쩌면 인코딩을 위해 텍스트 준비를 더 꼼꼼히 하면 더 나은 결과를 얻을 수도 있을 거예요. 하지만 여기서는 문서나 메타데이터 속성을 기반으로 영화를 필터링해야 하는 간단한 구조화된 데이터 작업을 다루고 있기 때문에 텍스트 임베딩을 적용하는 건 적절하지 않아요. 메타데이터 필터링은 RAG 시스템의 정확성을 높이기 위해 자주 사용되는 기술이랍니다.
다음으로 시도할 쿼리에는 약간의 정렬이 필요할 거예요.
pretty_print(
neo4j_vector.similarity_search("Which movie has the highest imdb score?")
)결과:
plot: A silent film production company and cast make a difficult transition to sound.
title: Singin' in the Rain
year: 1952
imdbRating: 8.3
plot: A film about the greatest pre-Woodstock rock music festival.
title: Monterey Pop
year: 1968
imdbRating: 8.1
plot: This movie documents the Apollo missions perhaps the most definitively of any movie under two hours. Al Reinert watched all the footage shot during the missions--over 6,000,000 feet of it, ...
title: For All Mankind
year: 1989
imdbRating: 8.2
plot: An unscrupulous movie producer uses an actress, a director and a writer to achieve success.
title: Bad and the Beautiful, The
year: 1952
imdbRating: 7.9IMDb 평점에 익숙하시다면 8.3점 이상의 영화가 많다는 걸 아실 거예요. 우리 데이터베이스에서 가장 높은 평가를 받은 타이틀은 사실 시리즈인 밴드 오브 브라더스인데, 무려 9.6점이라는 엄청난 점수를 받았답니다. 다시 말하지만, 결과를 정렬할 때 텍스트 임베딩 성능이 좋지 않다는 걸 알 수 있어요.
이번에는 일종의 집계가 필요한 질문도 한번 평가해 볼게요.
pretty_print(neo4j_vector.similarity_search("How many movies are there?"))결과:
plot: Ten television drama films, each one based on one of the Ten Commandments.
title: Decalogue, The (Dekalog)
year: 1989
imdbRating: 9.2
plot: A documentary which challenges former Indonesian death-squad leaders to reenact their mass-killings in whichever cinematic genres they wish, including classic Hollywood crime scenarios and lavish musical numbers.
title: Act of Killing, The
year: 2012
imdbRating: 8.2
plot: A meek Hobbit and eight companions set out on a journey to destroy the One Ring and the Dark Lord Sauron.
title: Lord of the Rings: The Fellowship of the Ring, The
year: 2001
imdbRating: 8.8
plot: While Frodo and Sam edge closer to Mordor with the help of the shifty Gollum, the divided fellowship makes a stand against Sauron's new ally, Saruman, and his hordes of Isengard.
title: Lord of the Rings: The Two Towers, The
year: 2002
imdbRating: 8.7결과가 4개의 무작위 영화를 반환하기 때문에 여기서 얻을 수 있는 정보는 딱히 없네요. 무작위로 선택된 4개의 영화에서 이 예시에 태깅하고 삽입한 영화가 총 1,000개라는 결론을 내리는 건 사실상 불가능하죠.
그렇다면 해결책은 뭘까요? 간단해요. 필터링, 정렬, 집계와 같은 구조화된 작업과 관련된 질문에는 구조화된 데이터를 사용하도록 설계된 도구가 필요하죠.
구조화된 데이터를 위한 도구
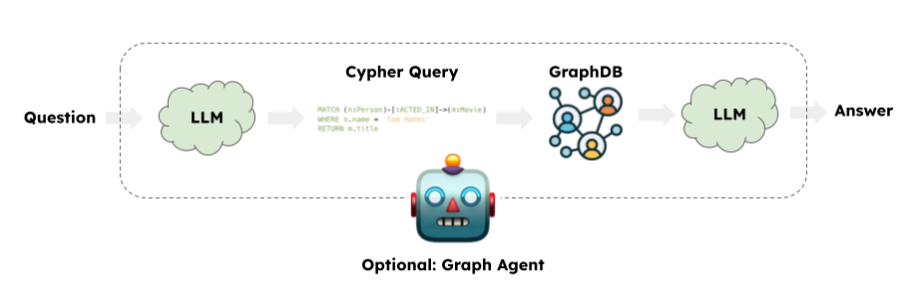
요즘 대부분의 사람들은 LLM이 제공된 질문과 스키마를 기반으로 데이터베이스와 상호 작용하기 위해 데이터베이스 쿼리를 생성하는 text2query 접근 방식을 떠올리는 것 같아요. Neo4j의 경우 text2cypher지만 SQL 데이터베이스용 text2sql도 있죠. 하지만 실제로는 안정적이지 않고 프로덕션 용도로 사용하기에 충분히 강력하지 않은 것 같아요.

몇 번의 예시, Fine-tuning과 같은 기술을 사용할 수도 있지만, 이 단계에서 높은 정확도를 달성하는 건 거의 불가능해요. text2query 접근 방식은 간단한 데이터베이스 스키마에 대한 간단한 질문에는 적합하지만, 프로덕션 환경의 현실과는 거리가 멀죠. 이 문제를 해결하기 위해 데이터베이스 쿼리 생성의 복잡성을 LLM에서 분리해서, 함수 입력을 기반으로 결정론적으로 데이터베이스 쿼리를 생성하는 코드 문제로 다루는 거예요. 유연성이 줄어드는 대신 견고성이 크게 향상된다는 장점이 있죠. 모든 것에 대답하려고 시도하다가 부정확하게 대답하는 것보다, RAG 애플리케이션의 범위를 좁혀서 해당 질문에 정확하게 대답하는 게 더 좋다고 생각해요.
함수 입력을 기반으로 데이터베이스 쿼리(이 경우 Cypher 문)를 생성하므로 LLM의 도구 기능을 활용할 수 있어요. 이 프로세스에서 LLM은 사용자 입력을 기반으로 관련 매개변수를 채우고, 함수는 필요한 정보 검색을 처리하는 거죠. 이 데모에서는 먼저 두 가지 도구(영화 개수를 계산하는 도구와 목록을 나열하는 도구)를 구현한 다음 LangGraph를 사용하여 LLM 에이전트를 만들 거예요.
영화 계산 도구
미리 정의된 필터를 기반으로 영화 개수를 계산하는 도구를 구현하는 것부터 시작해 볼게요. 먼저 이러한 필터가 무엇인지 정의하고, 이를 사용하는 시기와 방법을 LLM에 설명해야 해요.
class MovieCountInput(BaseModel):
min_year: Optional[int] = Field(
description="Minimum release year of the movies"
)
max_year: Optional[int] = Field(
description="Maximum release year of the movies"
)
min_rating: Optional[float] = Field(description="Minimum imdb rating")
grouping_key: Optional[str] = Field(
description="The key to group by the aggregation", enum=["year"]
)LangChain은 함수 입력을 정의하는 여러 가지 방법을 제공하지만, 저는 Pydantic 접근 방식을 선호해요. 이 예에는 영화 결과를 세분화하는 데 사용할 수 있는 세 가지 필터(min_year, max_year 및 min_rating)가 있어요. 이러한 필터는 구조화된 데이터를 기반으로 하며 선택 사항이에요. 사용자는 필터 중 일부를 포함하거나, 모두 포함하거나, 포함하지 않도록 선택할 수 있죠. 또한 특정 속성별로 개수를 그룹화할지 여부를 함수에 알려주는 grouping_key 입력을 도입했어요. 이 경우 지원되는 유일한 그룹화는 enum 섹션에 정의된 대로 연도별이에요.
이제 실제 함수를 정의해 볼게요.
@tool("movie-count", args_schema=MovieCountInput)
def movie_count(
min_year: Optional[int],
max_year: Optional[int],
min_rating: Optional[float],
grouping_key: Optional[str],
) -> List[Dict]:
"""Calculate the count of movies based on particular filters"""
filters = [
("t.year >= $min_year", min_year),
("t.year <= $max_year", max_year),
("t.imdbRating >= $min_rating", min_rating),
]
# Create the parameters dynamically from function inputs
params = {
extract_param_name(condition): value
for condition, value in filters
if value is not None
}
where_clause = " AND ".join(
[condition for condition, value in filters if value is not None]
)
cypher_statement = "MATCH (t:Target) "
if where_clause:
cypher_statement += f"WHERE {where_clause} "
return_clause = (
f"t.`{grouping_key}`, count(t) AS movie_count"
if grouping_key
else "count(t) AS movie_count"
)
cypher_statement += f"RETURN {return_clause}"
print(cypher_statement) # Debugging output
return graph.query(cypher_statement, params=params)movie_count 함수는 선택적 필터와 grouping key를 기반으로 영화 수를 계산하는 Cypher 쿼리를 생성해요. 인수로 제공되는 값을 사용해서 필터 목록을 정의하는 것으로 시작하죠. 필터는 값이 None이 아닌 조건만 포함하여 Cypher 문에 지정된 필터링 조건을 적용하는 WHERE 절을 동적으로 작성하는 데 사용돼요.
그런 다음 제공된 grouping_key를 기준으로 그룹화하거나, 단순히 총 영화 수를 계산해서 Cypher 쿼리의 RETURN 절이 구성돼요. 마지막으로 함수는 쿼리를 실행하고 결과를 반환하죠.
필요에 따라 더 많은 인수와 더 많은 관련 논리를 사용하여 함수를 확장할 수 있지만, LLM이 함수를 올바르고 정확하게 호출할 수 있도록 명확하게 유지하는 것이 중요해요.
영화 목록 도구
다시 한번, 함수의 인수를 정의하는 것부터 시작해야 해요.
class MovieListInput(BaseModel):
sort_by: str = Field(
description="How to sort movies, can be one of either latest, rating",
enum=["latest", "rating"],
)
k: Optional[int] = Field(description="Number of movies to return")
description: Optional[str] = Field(description="Description of the movies")
min_year: Optional[int] = Field(
description="Minimum release year of the movies"
)
max_year: Optional[int] = Field(
description="Maximum release year of the movies"
)
min_rating: Optional[float] = Field(description="Minimum imdb rating")영화 개수 함수와 동일한 세 개의 필터를 유지하지만, description 인수를 추가해요. 이 인수를 사용하면 Vector Embedding 유사성 검색을 사용하여 줄거리를 기반으로 영화를 검색하고 나열할 수 있죠. 구조화된 도구와 필터를 사용한다고 해서 텍스트 임베딩과 벡터 검색 방법을 통합할 수 없다는 의미는 아니에요. 대부분의 경우 모든 영화를 반환하고 싶지 않기 때문에 기본값과 함께 선택적 k 입력을 포함해요. 또한 목록을 작성하기 위해 가장 관련성이 높은 영화만 반환하도록 영화를 정렬하려고 하는데요. 이 경우 등급이나 출시 연도별로 정렬할 수 있어요.
함수를 구현해 볼까요?
@tool("movie-list", args_schema=MovieListInput)
def movie_list(
sort_by: str = "rating",
k : int = 4,
description: Optional[str] = None,
min_year: Optional[int] = None,
max_year: Optional[int] = None,
min_rating: Optional[float] = None,
) -> List[Dict]:
"""List movies based on particular filters"""
# Handle vector-only search when no prefiltering is applied
if description and not min_year and not max_year and not min_rating:
return neo4j_vector.similarity_search(description, k=k)
filters = [
("t.year >= $min_year", min_year),
("t.year <= $max_year", max_year),
("t.imdbRating >= $min_rating", min_rating),
]
# Create parameters dynamically from function arguments
params = {
key.split("$")[1]: value for key, value in filters if value is not None
}
where_clause = " AND ".join(
[condition for condition, value in filters if value is not None]
)
cypher_statement = "MATCH (t:Target) "
if where_clause:
cypher_statement += f"WHERE {where_clause} "
# Add the return clause with sorting
cypher_statement += " RETURN t.title AS title, t.year AS year, t.imdbRating AS rating ORDER BY "
# Handle sorting logic based on description or other criteria
if description:
cypher_statement += (
"vector.similarity.cosine(t.embedding, $embedding) DESC "
)
params["embedding"] = embedding.embed_query(description)
elif sort_by == "rating":
cypher_statement += "t.imdbRating DESC "
else: # sort by latest year
cypher_statement += "t.year DESC "
cypher_statement += " LIMIT toInteger($limit)"
params["limit"] = k or 4
print(cypher_statement) # Debugging output
data = graph.query(cypher_statement, params=params)
return data이 함수는 설명, 연도 범위, 최소 등급, 정렬 기본 설정 등 다양한 필터를 기반으로 영화 목록을 검색해줘요. 만약 다른 필터 없이 설명만 있다면, 벡터 인덱스 유사성 검색을 통해 관련 영화를 찾죠. 추가 필터가 있다면, 함수는 출시 연도나 IMDb 등급 같은 기준으로 영화를 매칭하는 Cypher 쿼리를 만들고, 이를 설명 기반 유사성과 결합해요. 결과는 유사성 점수, IMDb 등급, 또는 연도별로 정렬되고, k개의 영화로 제한된답니다.
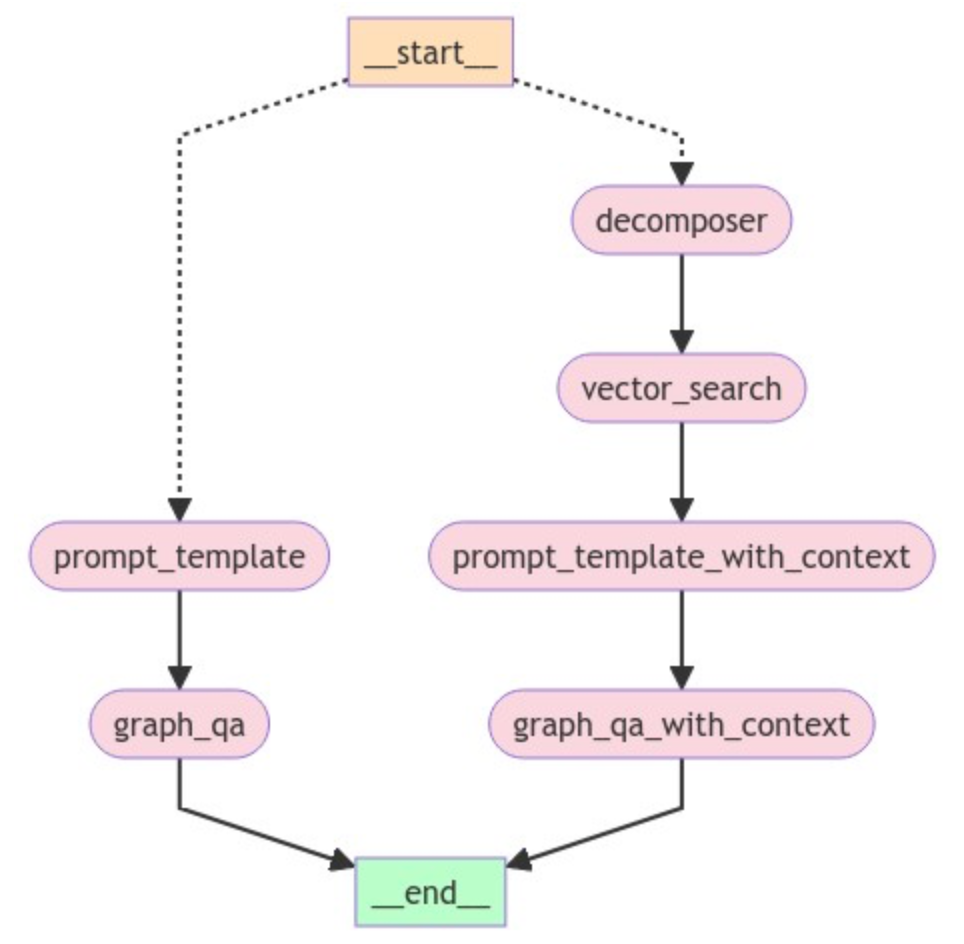
LangGraph 에이전트로 모든 것을 하나로 묶기
간단하게 React LangGraph를 사용하는 에이전트를 구현해 볼까요?

에이전트는 LLM과 도구 단계로 구성되어 있어요. 에이전트와 상호 작용할 때, 먼저 LLM에 전화해서 도구를 사용해야 하는지 결정하죠. 그런 다음 루프를 실행하게 될 거예요.
- 에이전트가 액션(예: 도구 호출)을 취하라고 하면, 도구를 실행하고 결과를 에이전트에게 다시 전달해요.
- 에이전트가 도구 실행을 요청하지 않으면 완료되고, 사용자에게 응답하는 거죠.
코드 구현은 정말 간단해요. 먼저 도구를 LLM에 바인딩하고 보조 단계를 정의해볼게요.
llm = ChatOpenAI(model='gpt-4-turbo')
tools = [movie_count, movie_list]
llm_with_tools = llm.bind_tools(tools)
# System message
sys_msg = SystemMessage(content="You are a helpful assistant tasked with finding and explaining relevant information about movies.")
# Node
def assistant(state: MessagesState):
return {"messages": [llm_with_tools.invoke([sys_msg] + state["messages"])]}다음으로 LangGraph 흐름을 정의해볼까요?
# Graph
builder = StateGraph(MessagesState)
# Define nodes: these do the work
builder.add_node("assistant", assistant)
builder.add_node("tools", ToolNode(tools))
# Define edges: these determine how the control flow moves
builder.add_edge(START, "assistant")
builder.add_conditional_edges(
"assistant",
# If the latest message (result) from assistant is a tool call -> tools_condition routes to tools
# If the latest message (result) from assistant is a not a tool call -> tools_condition routes to END
tools_condition,
)
builder.add_edge("tools", "assistant")
react_graph = builder.compile()LangGraph에서 두 개의 Node를 정의하고 이를 조건부 Edge와 연결했어요. 도구가 호출되면 흐름이 도구로 전달되고, 그렇지 않으면 결과가 사용자에게 다시 전송되는 구조에요.
이제 에이전트를 테스트해 볼게요.
messages = [
HumanMessage(
content="What are the some movies about a girl meeting her hero?"
)
]
messages = react_graph.invoke({"messages": messages})
for m in messages["messages"]:
m.pretty_print()결과:

첫 번째 단계에서 에이전트는 적절한 설명 변수와 함께 영화 목록 도구를 사용하도록 선택했어요. kvalue 5를 선택한 이유는 확실하지 않지만, 해당 숫자를 선호하는 것 같아요. 이 도구는 줄거리를 기반으로 가장 관련성이 높은 상위 5개 영화를 반환하고, LLM은 마지막에 사용자를 위해 간단히 요약해 준답니다.
ChatGPT에게 k 값 5를 좋아하는 이유를 묻는다면 다음과 같은 응답을 받을 거예요.

다음으로 메타데이터 필터링이 필요한 좀 더 복잡한 질문을 해볼게요.
messages = [
HumanMessage(
content="What are the movies from the 90s about a girl meeting her hero?"
)
]
messages = react_graph.invoke({"messages": messages})
for m in messages["messages"]:
m.pretty_print()결과:

이번에는 1990년대 영화만 필터링하기 위해 추가 인수가 사용되었어요. 이 예는 사전 필터링 방식을 사용한 메타데이터 필터링의 일반적인 예시인데요. 생성된 Cypher 문은 먼저 개봉 연도를 필터링해서 영화의 범위를 좁힌답니다. 다음 부분에서 Cypher 문은 텍스트 임베딩과 벡터 유사성 검색을 사용해서 어린 소녀가 자신의 영웅을 만나는 영화를 찾고 있어요.
다양한 조건에 따라 영화 수를 계산해 볼까요?
messages = [
HumanMessage(
content="How many movies are from the 90s have the rating higher than 9.1?"
)
]
messages = react_graph.invoke({"messages": messages})
for m in messages["messages"]:
m.pretty_print()결과:

계산을 위한 전용 도구를 사용하면 복잡성이 LLM에서 도구로 이동하고, LLM은 관련 기능 매개변수를 채우는 일만 담당하게 돼요. 이러한 작업 분리는 시스템을 더욱 효율적이고 강력하게 만들고 LLM 입력의 복잡성을 줄여주죠.
에이전트는 여러 도구를 순차적으로 또는 병렬로 호출할 수 있으니까, 좀 더 복잡한 것으로 테스트해 볼까요?
messages = [
HumanMessage(
content="How many were movies released per year made after the highest rated movie?"
)
]
messages = react_graph.invoke({"messages": messages})
for m in messages["messages"]:
m.pretty_print()결과:

앞서 언급한 대로 에이전트는 여러 도구를 호출해서 질문에 답하는 데 필요한 모든 정보를 수집할 수 있어요. 이 예에서는 최고 등급 영화가 개봉된 시기를 식별하기 위해 최고 등급 영화를 나열하는 것으로 시작하죠. 해당 데이터가 있으면 영화 개수 도구를 호출해서 질문에 정의된 그룹화 키를 사용하여 지정된 연도 이후 개봉된 영화 수를 수집합니다.
요약
텍스트 임베딩은 구조화되지 않은 데이터를 검색하는 데는 탁월하지만, , , 그리고 와 같은 구조화된 작업에서는 부족해요. 이러한 작업에는 이러한 작업을 처리하는 데 필요한 정확성과 유연성을 제공하는 구조화된 데이터용으로 설계된 도구가 필요하죠. 중요한 점은 시스템의 도구 세트를 확장하면 더 광범위한 사용자 쿼리를 처리할 수 있어 애플리케이션이 더욱 강력하고 다용도로 사용될 수 있다는 거예요. 구조화된 데이터 접근 방식과 구조화되지 않은 텍스트 검색 기술을 결합하면 보다 정확하고 관련성 높은 응답을 제공할 수 있으며, 궁극적으로 RAG 애플리케이션의 사용자 경험을 향상시킬 수 있어요.
언제나 그렇듯이 코드는 다음에서 사용할 수 있습니다. .
- rag
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'GraphRAG' 카테고리의 다른 글
| GraphQL API에 Retrieval-Augmented Generation (RAG)을 더하는 방법 (0) | 2026.05.31 |
|---|---|
| LlamaIndex에서 Property Graph Index를 내 입맛대로 커스터마이징하기 (0) | 2026.05.29 |
| 인공지능과 Machine Learning의 현재와 미래 (0) | 2026.05.29 |
| Neo4j 대규모 지식 그래프에서 예측 분석: GraphRAG와 Machine Learning 활용 (1) | 2026.05.28 |
| 2023년 그래프 기술 전망: Neo4j와 GraphRAG의 미래는? (1) | 2026.05.28 |