
Knowledge Graph로 구동되는 RAG 애플리케이션에서 부모-자식 관계, 질문 기반, 주제 요약과 같은 그래프 데이터 모델을 사용하는 경우를 알아볼까요?

Retrieval-Augmented Generation(RAG) 애플리케이션을 구축할 때 문서를 벡터 또는 Graph Database에 넣고, 임베딩을 생성하고, 코사인 유사성을 실행하고 싶은 유혹이 들 수 있어요.
이 글에서는 이러한 애플리케이션을 향상시키는 데 사용할 수 있는 몇 가지 대체 그래프 데이터 모델과 각 모델이 제공하는 고유한 이점에 대해 설명할게요. 이 글을 읽기 전에 여러분이 Graph Database와 RAG에 어느 정도 익숙하다고 가정할게요.
여기에는 GitHub 저장소가 포함되어 있고, 다음을 통해 이러한 데이터 모델을 생성하고 탐색하는 코드가 들어있어요. arrows.app 또는 Neo4j 브라우저를 사용하면 자신의 애플리케이션에 대한 데이터 모델을 수정할 수 있어요.
Neo4j

Neo4j는 벡터 검색을 수행할 수 있는 벡터 인덱싱 기능이 있는 Graph Database를 제공해요. 다음을 사용해서 로컬에서 Neo4j를 사용해 볼 수 있어요: 데스크톱 버전 또는 클라우드 호스팅 환경에서 Neo4j AuraDB를 무료로 사용할 수 있어요. 데이터베이스를 초기화할 때 Neo4j 버전 ≥ 5.13을 실행해서 벡터 인덱싱 기능이 있는지 확인하세요.
Vector Embedding
Vector Embedding은 미디어를 수학적으로 나타내는 일련의 숫자예요. 이는 전통적으로 단어와 문장으로 수행되었지만 이제는 오디오, 이미지 및 비디오를 Vector Embedding으로 인코딩하는 것도 가능해요. 벡터의 길이를 차원이라고 해요.
Neo4j는 최대 4096차원의 벡터를 지원하며 일반적인 값은 768 및 1536이에요.
[0.123, -0.423, 0.519, ..., -0.942]컨텍스트 검색
반환된 컨텍스트는 사용자 질문 임베딩과 그래프에 있는 텍스트 임베딩 간의 계산된 유사성 점수에 따라 결정돼요.
일치하는 임베딩에서 검색된 텍스트를 분리하는 것이 좋아요. 이는 원시 청크에 삽입 시 인코딩된 정보를 희석시킬 수 있는 필러 단어와 추가/충돌 정보가 포함될 가능성이 높기 때문이에요.
더 작은 및/또는 처리된 텍스트 청크를 포함함으로써 유사성 일치를 더 정확하게 만들 수 있으며, 그래프 관계를 탐색하여 응답 생성을 위해 LLM에 반환되는 텍스트를 제어할 수 있어요.
기본 그래프 데이터 모델
이 그래프 데이터 모델은 문서 `Node`에 텍스트 청크를 저장하고 반환된 텍스트에서 일치하는 임베딩을 분리하지 않아요. 문서 `Node`의 임베딩 속성에 대해 벡터 검색을 실행하여 LLM에 컨텍스트로 반환할 가장 관련성이 높은 텍스트를 찾을 수 있어요. 원한다면 `Relationship`을 탐색하여 각 텍스트 덩어리의 출처를 찾아 인용을 제공할 수도 있어요.
이 모델은 개념 증명에 적합하지만 크게 개선될 수 있으며 생산 애플리케이션에 더 나은 옵션이 있어요.
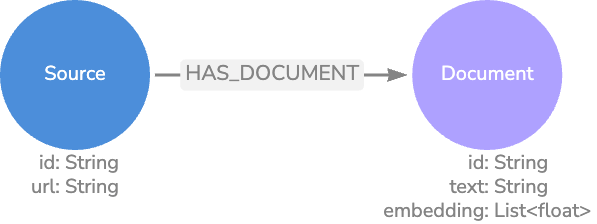
부모-자식
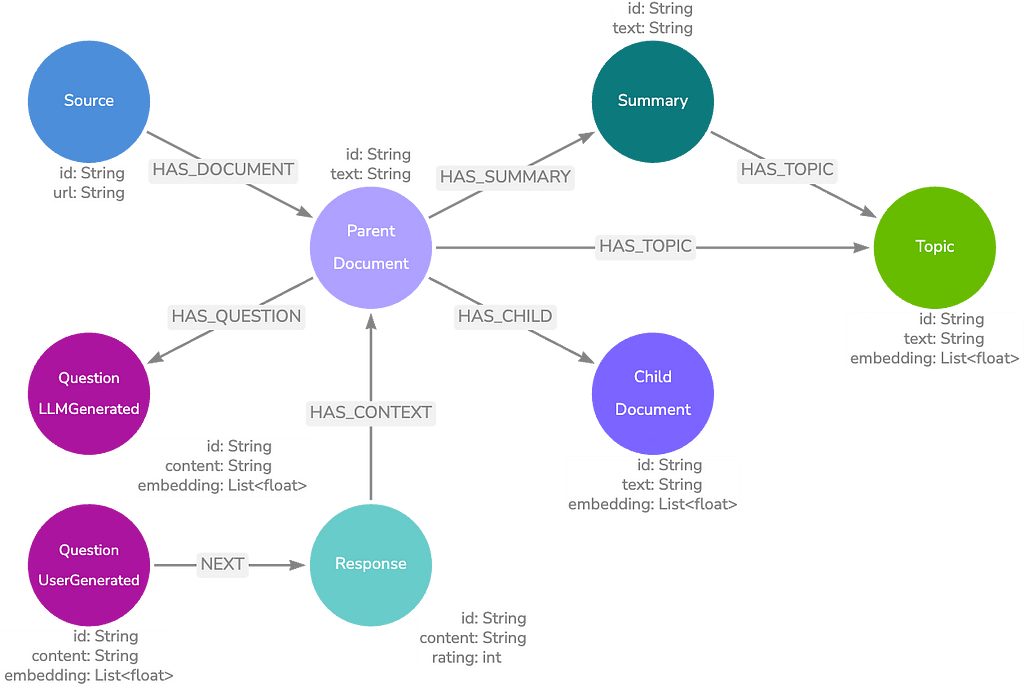
부모-자식 모델은 기본 모델과 유사하지만 텍스트 덩어리를 더 세분화하여 예상 질문에 더 가까운 길이를 만들어요. 이렇게 하면 질문과 일치하는 텍스트 간의 정보 세분성이 유지되므로 한 단락에 대해 몇 단어를 일치시키지 않아요.
하위 `Node` 포함 일치 항목이 있으면 `Relationship`을 탐색하여 하위 텍스트와 주변 텍스트가 포함된 상위 `Node` 텍스트를 검색할 수 있어요. 이 방법은 보다 정확한 벡터 검색 일치를 제공하는 동시에 컨텍스트가 풍부한 결과를 반환해요.
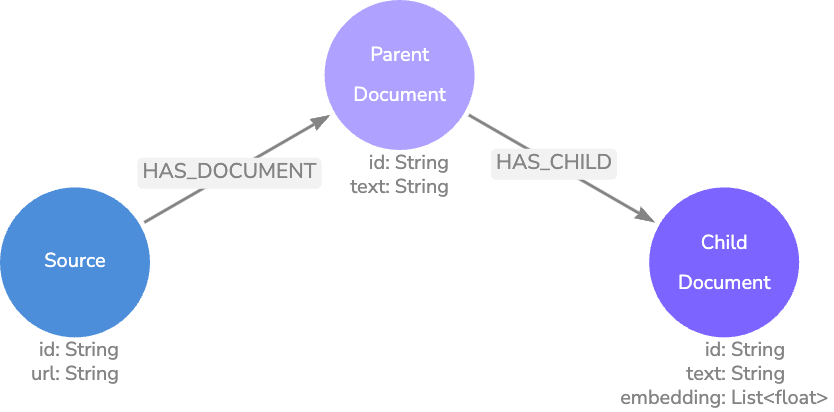
애플리케이션에서 일반적인 질문의 길이를 찾으려면 실험이 필요하지만 문서 채팅 애플리케이션에서는 140자가 표준 길이인 것으로 나타났어요.
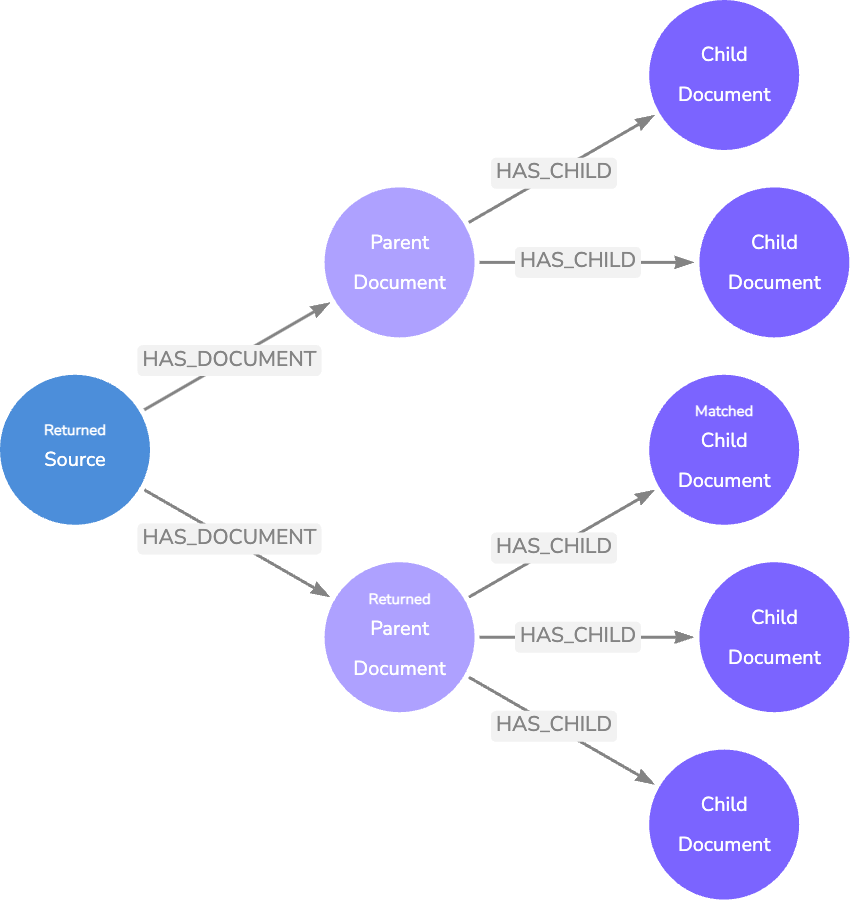
질문
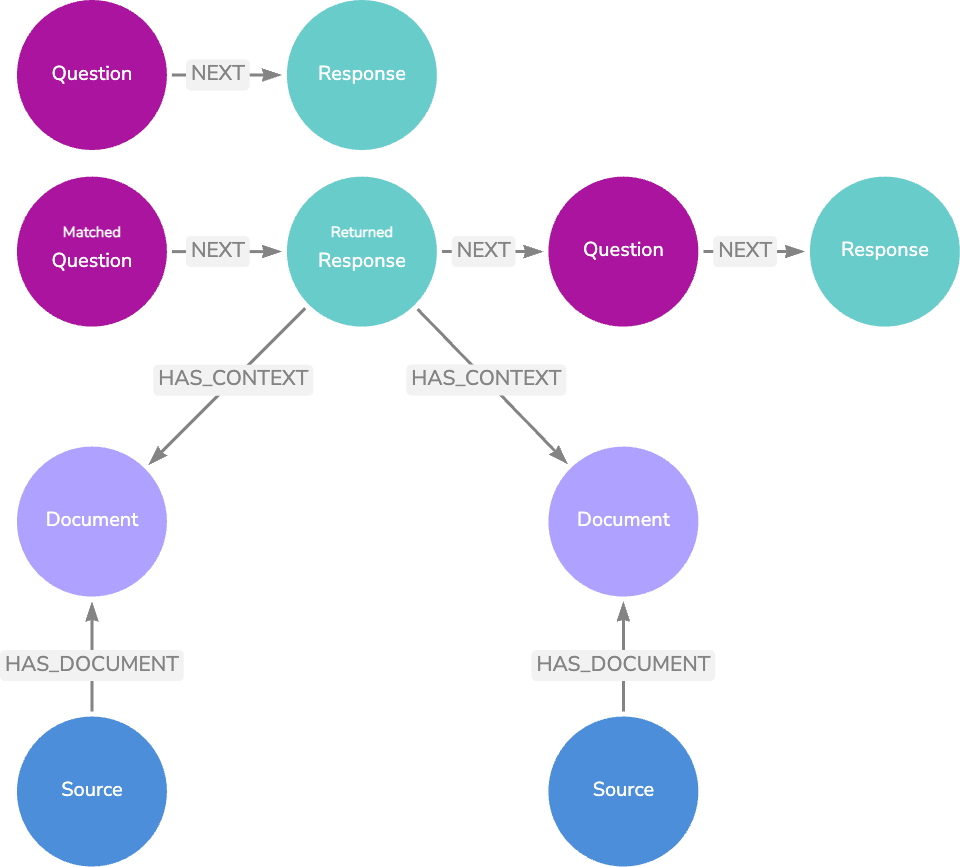
이 다음 데이터 모델은 질문 `Node`를 답변에 대한 유용한 컨텍스트가 포함된 문서에 연결하여 기본 모델을 더욱 확장해요.
문서 텍스트를 LLM에 전달하고 텍스트가 답변할 수 있는 질문을 반환하도록 요청하여 질문을 생성할 수 있어요. `Knowledge Graph`에 애플리케이션 활동을 기록하여 실제 사용자 질문을 제공할 수도 있죠.
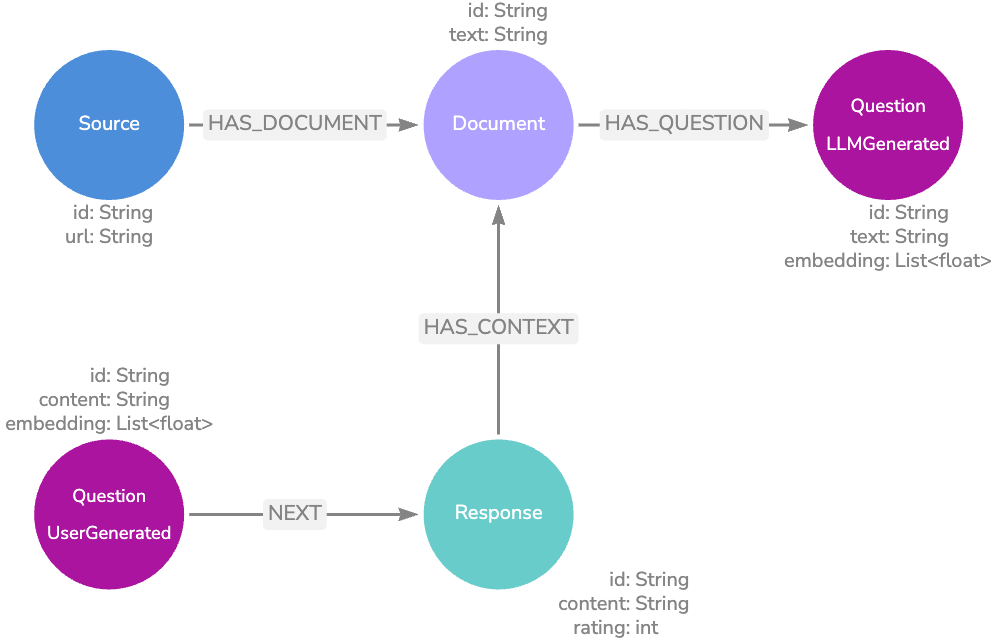
여기에는 두 가지 검색 옵션이 있어요.
첫 번째 옵션은 LLM에서 생성된 질문에 대해 `Vector Embedding` 검색을 수행하고 관련 문서 `Node` 텍스트를 응답 생성을 위한 컨텍스트로 반환하는 것이에요.
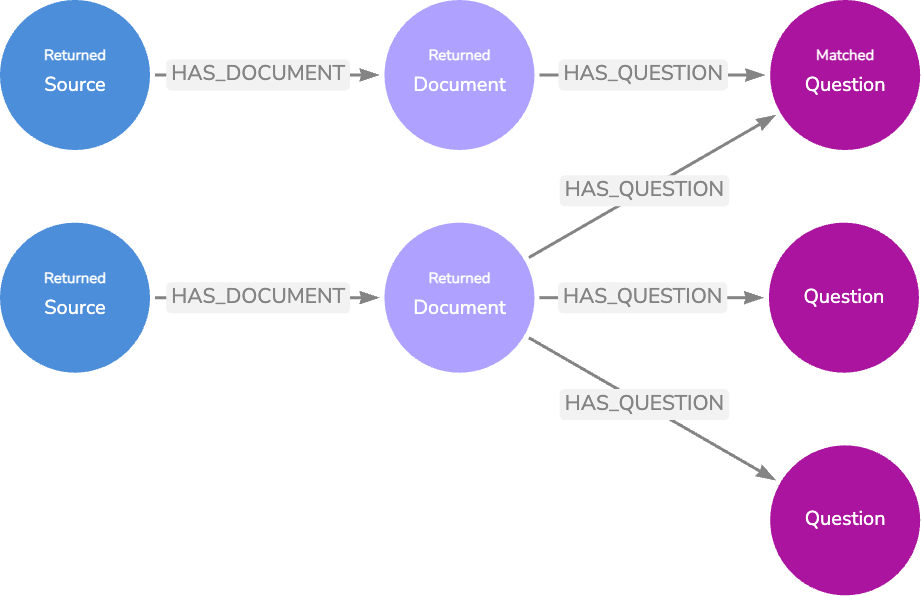
두 번째 옵션은 로깅의 실제 사용자 질문을 일치시키는 것이에요. 질문이 높은 평가를 받은 LLM 응답 `Node`와 관련이 있는 경우 LLM 응답 생성 단계를 완전히 우회하여 해당 `Node`의 텍스트를 반환할 수 있어요. 관련 문서 또는 소스 `Node`의 관련 정보가 이미 응답 텍스트에 있으므로 관련 문서 또는 소스 `Node`를 반환할 필요가 없죠.
주제 및 요약
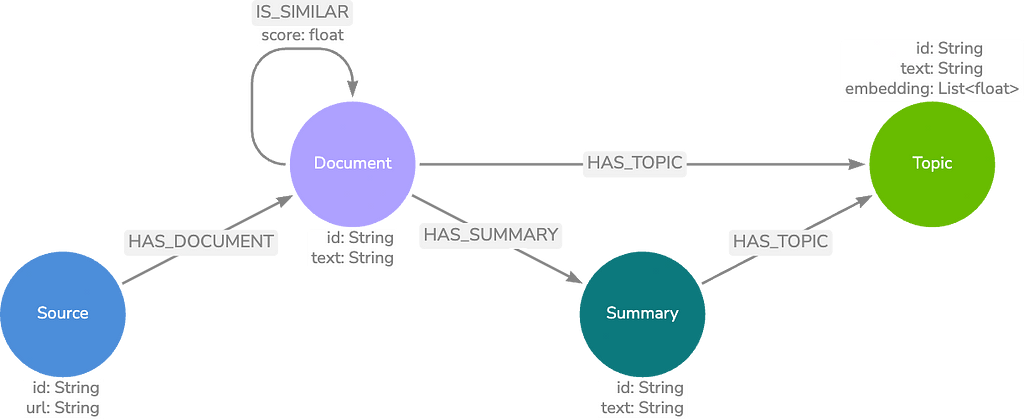
다음 모델 유형에는 Neo4j를 사용해야 해요. Graph Data Science(GDS) 라이브러리 말이죠. 우리는 GDS를 사용하여 문서 `Node`의 커뮤니티를 찾고 이러한 각 커뮤니티에 대한 요약을 생성하여 기본 데이터 모델을 구축해요.
커뮤니티는 `IS_SIMILAR` `Relationship`의 문서 `Node` 간 KNN 유사성 점수를 포함하는 텍스트를 기반으로 해요. 이러한 요약을 요약 `Node`에 저장하고 요약 텍스트에서 엔터티 추출을 수행하여 주제를 찾아요. 이러한 항목을 주제 `Node`에 저장하면 `Vector Embedding` 검색 외에도 키워드 검색을 수행할 수 있죠.
가능한 검색 프로세스는 다음과 같아요.
- 주제 `Node` 텍스트 임베딩에 대한 `Vector Embedding` `Index` 검색,
- 발견된 상위 k개의 주제 `Node`에서 연결된 문서 `Node`까지의 그래프 순회,
- 발견된 문서 풀에서 `Vector Embedding` `Index` 검색 및
- 응답 생성을 위해 상위 k개 문서 `Node` 텍스트 및 관련 URL을 LLM에 반환합니다.
데이터 모델 결합
이러한 모델은 개별적으로 또는 조합하여 수행하여 애플리케이션의 기능을 향상시킬 수 있어요.
아마도 사용자가 생성한 질문을 일치시키고 싶지만 근접한 일치 항목이 없으면 상위-하위 아키텍처의 하위 `Node`를 일치시키세요.
주제 및 요약 `Node`는 검색 향상 이상의 귀중한 정보를 제공할 수도 있어요. `Knowledge Graph`가 특정 질문에 대한 답변을 제공할 수 있는지 검증하기 위해 메타 분석에 사용할 수 있죠.
결론
`RAG` 애플리케이션을 위한 그래프 데이터 모델링은 지속적으로 개발되고 있으며 계속 발전하고 있어요. 위에서 논의한 모델은 필요에 따라 사용 사례에 맞게 수정될 수 있으며 여러분의 프로젝트에 영감을 줄 수 있기를 바라요. 여기에는 GitHub 저장소 다음을 통해 이러한 데이터 모델을 생성하고 탐색하는 코드가 포함되어 있어요. arrows.app 또는 Neo4j 브라우저.
일부 모델은 `Knowledge Graph`에 직접 애플리케이션 활동을 기록할 때 가장 잘 작동해요. Dan Bukowski와 저는 블로그 시리즈에서 `Knowledge Graph` 로깅 스타일의 이점을 자세히 설명합니다. 맥락이 전부다.
- 그래프 데이터 모델
- RAG
- Retrieval-Augmented Generation
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'GraphRAG' 카테고리의 다른 글
| 그래프 임베딩: 데이터로부터 학습하여 문제를 해결하는 AI (0) | 2026.05.06 |
|---|---|
| 그래프 임베딩이란 무엇일까요? 더 큰 문제를 규모에 맞게 해결하는 방법 (1) | 2026.05.05 |
| 그래프로 가는 길: 코드 한 줄 없이 시작하는 데이터 통합 (Neo4j, GraphRAG, Machine Learning, API 적용 가능) (0) | 2026.05.05 |
| 그래프 분석 활용 사례: Neo4j, GraphRAG, 그리고 더 많은 이야기 (0) | 2026.05.04 |
| 안녕 Anders, 그리고 Hello Neo4j GraphRAG! (0) | 2026.05.04 |