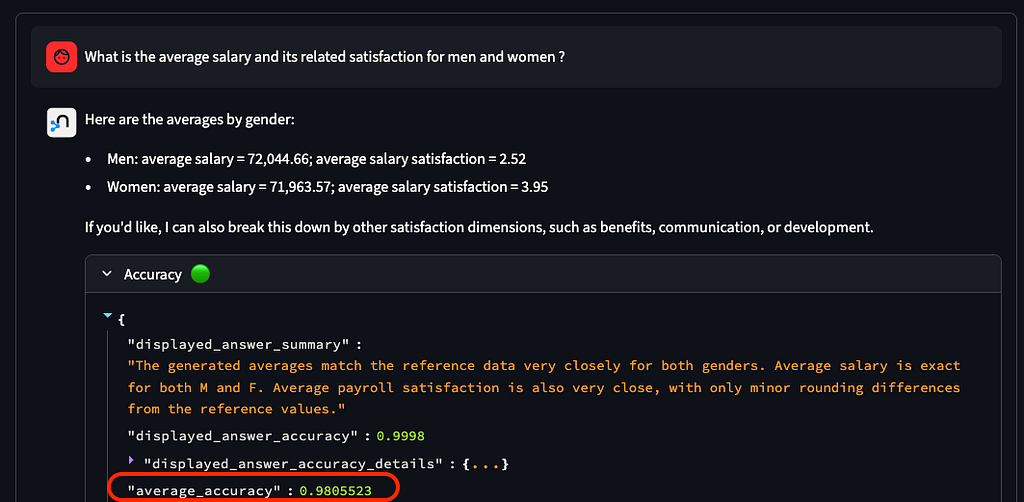
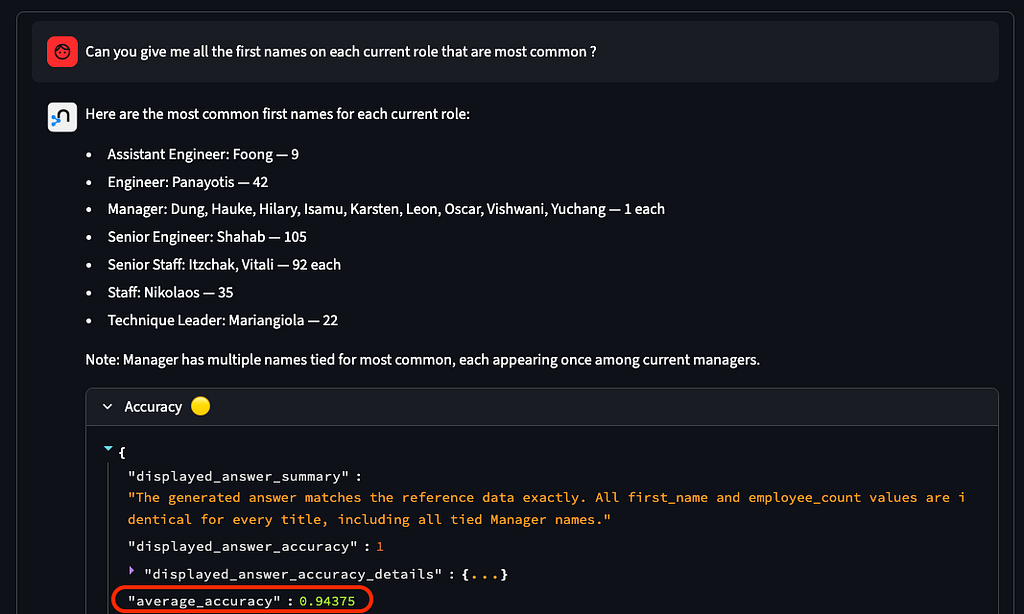
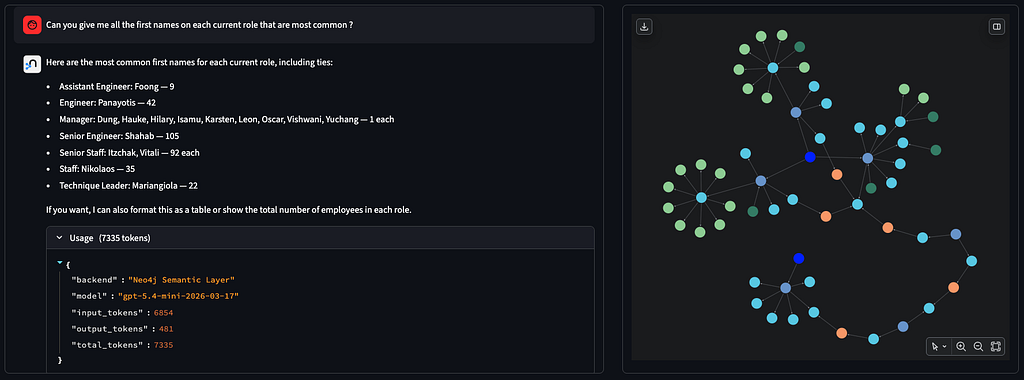
저희는 이걸 GDS의 정말 멋진 기능이라고 생각하고 싶어요. 알고리즘 *말고* GDS 전문가가 알아야 할 팁과 요령 같은 것들이요.
이 블로그 시리즈에서는 메모리 관리부터 그래프 변환에 이르기까지 다양한 주제를 다룰 거예요. 트랜잭션 데이터베이스를 알고리즘을 실행하려는 올바른 데이터 하위 집합으로 재구성할 수 있는 그래프 카탈로그의 내용도 다룰 거고요. GDS 1.3에서 방금 출시한 세분화된 보안을 위한 RBAC 통합, 알고리즘 조정 및 그래프 내보내기를 사용한 그래프 버전 관리에 대해 이야기해볼게요.
또한 그래프 알고리즘의 계층과 새로운 기능에 대한 조기 액세스를 위한 알파 계층에 대해 설명하고 일부 그래프 임베딩을 살짝 엿볼 수 있도록 보여드릴게요.
마지막으로, 자체 알고리즘을 실행하고 Java에서 Pregel API를 사용하여 자체 알고리즘을 작성하는 방법을 설명할 거예요.
이번 포스팅에서는 Graph Data Science™ 라이브러리, 데이터 과학 여정을 지원하는 Neo4j의 제품, 그리고 지난 몇 번의 릴리스 동안 알고리즘에 적용한 일부 업데이트 및 변경 사항에 대한 간략한 개요를 제공할게요.
Graph Data Science 라이브러리의 배경
GDS 라이브러리 전문가 팁을 살펴보기 전에 Graph Data Science에 대한 몇 가지 배경 지식을 제공하고 싶어요.
애초에 분석을 위해 Machine Learning(ML)이 포함된 그래프를 사용하는 이유가 궁금하다면, 아주 간단하게 이미 가지고 있는 데이터로 더 나은 예측을 얻을 수 있기 때문이에요.
데이터 과학자들이 "데이터가 많을수록 예측 성능이 좋아진다"라고 말하는 걸 종종 듣잖아요? 하지만 문제는 이미 데이터가 충분히 많다는 거죠. 그걸 관계라고 부르고, 이미 데이터 세트 안에 숨어있다는 사실!
현재 많은 데이터 과학 접근 방식은 데이터 포인트 간의 연결, 그리고 그 네트워크의 확장된 토폴로지를 무시하는 경향이 있어요. 이게 정말 예측에 중요한 요소가 될 수 있는데 말이죠.
관계를 명시적으로 통합하고 구조적 정보를 데이터에 추가하면 결과를 훨씬 좋게 만들 수 있어요. Machine Learning 모델에 예측 "그래프" 기능을 넣거나, 어떤 예측을 하든 관계를 실제로 사용하지 않으면 답할 수 없는 질문에 답하는 데 도움이 되거든요.
중요한 건, 지금 하고 있는 일을 버리라는 이야기가 아니라는 점이에요.
그래프, 특히 그래프 기반 Feature Engineering의 장점은 현재 분석 및 ML 파이프라인에 추가할 수 있다는 거예요. 그러니까 지금 하는 일을 계속하면서, 관계도 함께 활용해보세요!
Neo4j는 그래프 데이터 과학을 수행하는 데 어떻게 도움이 될까요?
Neo4j는 최고의 엔터프라이즈 Graph Database예요. 연결된 데이터를 저장하기 위한 확장 가능하고 안전하며 성능이 뛰어난 시스템이죠. 하지만 Neo4j는 업계 최대 규모의 그래프 전용 투자이기도 해요. 이게 여러분에게 뭘 의미하냐고요? 저희는 실무자에게 데이터베이스뿐만 아니라 Graph Data Science를 위한 다른 전용 제품도 제공하고 있다는 거죠.
Neo4j Graph Database 연결된 데이터를 영구적인 Graph Database에 저장하고, 데이터 과학 결과를 쉽게 저장하고 검색할 수 있어요.
분석 작업 공간과 50개 이상의 알고리즘을 제공하는 플러그인이에요.
Neo4j Bloom Neo4j의 데이터 시각화 및 탐색 도구랍니다.
Graph Data Science를 할 때는 알고리즘'만' 필요한 게 아니에요. 그래프 데이터를 올바른 형태로 저장할 공간(데이터베이스)이 필요하고, 데이터 과학자는 자신이 발견한 내용을 시각적으로 탐색하고 비즈니스 라인이나 해당 분야 전문가에게 설명할 수 있어야 해요. 그래서 Bloom과 같은 시각화 도구가 중요한 거죠.
Neo4j는 Graph Data Science를 수행하는 데 필요한 완벽한 도구 세트를 제공한답니다.
Graph Data Science 라이브러리에는 무엇이 있나요?
GDS 라이브러리는 인메모리 그래프(분석 작업 공간)를 만들기 위한 인프라와 50개 이상의 그래프 알고리즘을 제공하고 있어요.
이러한 알고리즘은 경로 찾기 및 중심성부터 커뮤니티 감지 및 링크 예측에 이르기까지 정말 다양하죠. 그래프의 토폴로지 및 계산 지표를 이해하는 데 도움이 되는 많은 알고리즘이 있답니다. 이러한 알고리즘은 매우 병렬화되어 있어서 수천억 개의 `Node`를 처리하고 확장할 수 있어요.
저희는 GDS를 가능한 한 확장 가능하게 만들기 위해 Neo4j 엔지니어링 팀이 수행한 모든 작업에 깊은 인상을 받았어요. Neo4j 데이터베이스에는 매우 컴팩트한 기본 그래프 스토리지가 있고 데이터 스토리지 및 트랜잭션 워크로드에 아주 적합하거든요.
저희 엔지니어링 팀은 트랜잭션 그래프를 대규모 글로벌 집계 및 순회에 최적화된 계산 그래프로 자동 변환하는 분석 작업 공간을 만들었어요.
인메모리 작업 공간을 사용하면 그래프의 모양을 변경하거나 그래프의 하위 집합을 지정하고 결과를 다시 쓰기 전에 다른 그래프 알고리즘을 계층화하는 등의 작업을 수행할 수 있어요. 그런 다음 준비가 되면 기본 데이터베이스를 업데이트하거나 결과를 완전히 새로운 데이터베이스로 내보낼 수 있죠.
최신 GDS 라이브러리로 업그레이드하지 않았다면 확실히 새로운 기능을 살펴보고 싶을 거예요. GDS 라이브러리에 최근 추가된 기능에는 새롭고 향상된 알고리즘, 표현력이 뛰어난 인메모리 그래프, 고급 기능 지원이 포함되어 있답니다.
새로운 GDS 라이브러리 추가
이제 배경 정보를 다뤘으니... 새로운 소식은 무엇일까요?
1.0 릴리스 이후 완전히 새로운 카테고리인 그래프 임베딩을 포함하여 7개의 새로운 알고리즘을 추가했어요. 또한 일관성을 위한 시딩, 배포 통계, 연속 커뮤니티 ID 등 기존 알고리즘에 새로운 기능을 추가했답니다.
더욱 표현력이 풍부한 인메모리 그래프 기능 인메모리 그래프를 통해 더 나은 성능과 표현성을 가능하게 하는 보다 표현력이 풍부한 기능을 추가했어요. 여기에는 가변성(인 메모리 그래프 업데이트), `Property` 결합 및 변환을 위한 고급 기능, 인메모리 그래프의 데이터를 `Query`하고 상호 작용하는 새로운 방법이 포함돼요.
또한 그래프 로더에 성능 최적화(데이터 변환 속도 향상)를 추가하고 압축을 개선하여 분석 작업 공간의 메모리 공간을 최소화했어요.
고급 기능 및 데이터베이스 통합 마지막으로 GDS 라이브러리가 핵심 데이터베이스와 작동하는 방식을 개선하기 위해 추가한 몇 가지 일반적인 고급 기능이 있어요. 여기에는 보안에 대한 역할 기반 액세스 지원과 Neo4j 지원이 포함되죠.
또한 사용자가 데이터베이스를 올바르게 구성하지 않았을 때 실수로 데이터베이스가 충돌하는 것을 방지하기 위해 향상된 메모리 관리 기능을 추가했어요. 자체 알고리즘을 구현하기 위한 Pregel API도 추가했답니다.
결론
이것은 최근에 추가된 내용을 아주 빠르게 요약한 거예요. 이 시리즈의 향후 블로그에서 더 자세히 설명할 예정이에요.
Graph Data Science에 관한 이 블로그 시리즈의 두 번째 기사에서는 추정 기능을 사용하여 메모리 요구 사항 확인, 그래프 로더를 사용하여 그래프 변환 및 재구성, RBAC를 사용하여 세분화된 보안 적용과 같은 내부 팁과 요령에 대해 논의할 거예요.
Graph Data Science의 더 깊은 측면을 알아볼 준비가 되셨나요? 아래를 클릭하시면GDS 개발자 문서에 액세스.
GDS 문서 받기
그래프 데이터 과학
Graph Export
In-Memory Graph
Machine Learning
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
요즘 많은 GenAI 솔루션(예: RAG)에서 텍스트, 이미지, 다른 데이터 임베딩에 대한 유사성 검색을 수행하는 게 점점 더 흔해지고 있죠. 임베딩 모델 Fine-tuning, Prompt Engineering, 순위 재지정을 위한 크로스 인코더 같은 기술로 임베딩 검색을 개선하려는 시도도 많고요.
이번 글에서는 위에서 언급한 방법들을 전혀 쓰지 않고도 유사성 검색을 확 끌어올리는 아주 간단하면서도 효과적인 방법을 보여드릴게요. 샘플도 준비되어 있고, Neo4j APOC ML 절차를 써서 Azure OpenAI, Google VertexAI, AWS Bedrock, 이렇게 3대 클라우드 제공업체에서 임베딩 테스트를 해본 결과도 보여드릴 예정이에요.
텍스트 임베딩에 대해 더 자세히 알고 싶다면, 예전에 썼던 글을 참고해주세요.
텍스트 임베딩 — 무엇을, 왜, 어떻게?
목표
일반적인 RAG(Retrieval Augmented Generation) 솔루션에서 검색 과정은 주로 이런 식으로 진행돼요. (텍스트) 임베딩에 대한 유사성 검색을 하는 거죠. 여기서 임베딩은 라는 데이터 타입으로 표현되고, Knowledge Base에 저장된 콘텐츠의 텍스트 임베딩에 대한 질문(자연어 질문)을 던지는 방식이에요.
RAG 애플리케이션의 벡터 유사성 검색. 출처:
효과적인 벡터 검색을 위해서는 가 중요한데요, 이 점수가:
관련 있는 벡터와 관련 없는 벡터 사이에 이 있어야 하고,
결과에서 관련 없는 벡터를 걸러내는 데 쓰이는 이 있어야 해요.
샘플
은행 상품에 대해 몇 가지 질문이 있다고 가정해 볼게요.
1. 'tell the differences bwteen standard home loan and fixed loan'
2. 'compare standard home loan, line of credit and fixed loan'
3. 'how to calculate interest?'
4. 'what is fixed rate loan?'
5. 'can I make more replayment?'
그리고 내용을 요약하면 이 되겠죠:
문제는 은행 상품의 특징을 비교하고 차이점을 요약하는 것입니다.
자, 테스트를 시작해볼까요?
Embedding API 호출하기
Neo4j를 사용해서 Knowledge Graph에 텍스트 데이터와 벡터 데이터를 모두 저장할 거라서, 빠르게 시작하기 위해 Neo4j APOC 라이브러리의 Machine Learning 절차를 사용할 거예요. 텍스트 임베딩을 얻기 위해 세 군데 클라우드 제공업체 모두 사용해볼 겁니다.
1. AWS Bedrock
AWS에서는 텍스트 임베딩 작업을 위해 Titan Embedding G1을 제공하고 있어요. 요청에 따라 특정 지역에서 사용할 수 있다네요. AWS 액세스 키와 keyID가 필요하고요. IAM에서 사용자 계정에 AmazonBedrockFullAccess 권한을 주는 것도 잊지 마세요.
Neo4j에는 Graph Data Science 라이브러리에 Cosine 유사도 기능이 있어요. 혹시 설치되어 있지 않다면, Cypher에서 직접 만들어서 사용할 수도 있답니다.
CALL apoc.custom.declareFunction(
"cosineSimilarity(vector1::LIST OF FLOAT, vector2::LIST OF FLOAT)::FLOAT",
"WITH
reduce(s = 0.0, i IN range(0, size($vector1)-1) | s + $vector1[i] * $vector2[i]) AS dotProduct,
sqrt(reduce(s = 0.0, i IN range(0, size($vector1)-1) | s + $vector1[i]^2)) AS magnitude1,
sqrt(reduce(s = 0.0, i IN range(0, size($vector2)-1) | s + $vector2[i]^2)) AS magnitude2
RETURN
toFloat(dotProduct / (magnitude1 * magnitude2)) AS score;"
);
기준선
유사도를 계산하기 위해 아래 Cypher 구문을 사용해서 Azure OpenAI 임베딩 모델부터 시작해 볼까요?
CALL apoc.ml.openai.embedding(['The question is about comparing banking products features and summarising differences'],NULL , {})
YIELD index, text, embedding
WITH text AS text1, embedding AS emb1
CALL apoc.ml.openai.embedding(['tell the differences bwteen standard home loan and fixed loan',
'compare standard home loan, line of credit and fixed loan',
'how to calculate interest?',
'what is fixed rate loan?',
'can I make more replayment?'
],NULL , {})
YIELD index, text, embedding
WITH text AS text2, embedding AS emb2, emb1, text1
RETURN text1, text2, custom.cosineSimilarity(emb1, emb2) AS score;
결과는 다음과 같아요.
╒══════════════════════════════════════════════════════════════════════╤═══════════════════════════════════════════════════════════════╤══════════════════╕
│text1 │text2 │score │
╞══════════════════════════════════════════════════════════════════════╪═══════════════════════════════════════════════════════════════╪══════════════════╡
│"The question is about comparing banking products features and summari│"tell the differences bwteen standard home loan and fixed loan"│0.786548104272935 │
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼───────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"compare standard home loan, line of credit and fixed loan" │0.8082209952027013│
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼───────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"how to calculate interest?" │0.7799410426972614│
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼───────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"what is fixed rate loan?" │0.7562771823612668│
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼───────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"can I make more replayment?" │0.7278839096948918│
│sing differences" │ │ │
└──────────────────────────────────────────────────────────────────────┴───────────────────────────────────────────────────────────────┴──────────────────┘
초기 결과는 예상했던 대로 나왔어요. 질문 #2의 점수가 가장 높고, 그 다음이 #1, #3 순서죠. 4번과 5번은 상대적으로 점수가 낮고요. 하지만 이건 기사 시작 부분에서 정의한 목표만큼 좋진 않아요.
질문 1~3번은 유사성 점수가 서로 너무 가까워요.
사이의 거리max and min유사성 점수는 겨우0.08이에요.
질문 #1은 관련성은 있지만,0.8을 합리적인 기준으로 본다면 상대적으로 점수가 낮은 편이죠.
비교할 벡터의 양이 많아지면 이런 문제 때문에 검색하고 필터링하기가 더 어려워질 수 있어요.
모델의 Fine-tuning이나 정교한 Prompt Engineering 없이 간단한 기술로 이걸 개선할 방법이 있을까요?
아주 간단한 방법
OpenAI 임베딩
물론 질문에 몇 가지 키워드를 추가할 수도 있어요. 예를 들어 '질문:'을 모든 질문 앞에 추가하면 아래와 같이 약간 더 나은 결과를 얻을 수 있죠.
╒══════════════════════════════════════════════════════════════════════╤══════════════════════════════════════════════════════════════════════╤══════════════════╕
│text1 │text2 │score │
╞══════════════════════════════════════════════════════════════════════╪══════════════════════════════════════════════════════════════════════╪══════════════════╡
│"The question is about comparing banking products features and summari│"question: tell the differences bwteen standard home loan and fixed lo│0.8076027901384112│
│sing differences" │an" │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"question: compare standard home loan, line of credit and fixed loan" │0.8209218883771804│
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"question: how to calculate interest?" │0.7897457504166066│
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"question: what is fixed rate loan?" │0.7752367420838878│
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"question: can I make more replayment?" │0.7434177316292667│
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
이제 #1과 #2는 모두 0.8 이상이고, #3을 제외한 모든 질문에 대해 점수가 높아진 걸 알 수 있어요. 실제로는 감소했네요.
더 일반적이고, 매우 간단하면서 효과적인 방법은 바로 를 좀 추가하는 거예요.
예를 들어 ### 를 질문이 시작될 때마다 추가하면 점수가 더 높아진답니다.
╒══════════════════════════════════════════════════════════════════════╤══════════════════════════════════════════════════════════════════════╤══════════════════╕
│text1 │text2 │score │
╞══════════════════════════════════════════════════════════════════════╪══════════════════════════════════════════════════════════════════════╪══════════════════╡
│"The question is about comparing banking products features and summari│"###question: tell the differences bwteen standard home loan and fixed│0.8153785384022421│
│sing differences" │ loan" │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"###question: compare standard home loan, line of credit and fixed loa│0.8396923324014403│
│sing differences" │n" │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"###question: how to calculate interest?" │0.8033634786411539│
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"###question: what is fixed rate loan?" │0.7924533227169328│
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"###question: can I make more replayment?" │0.7517756135667428│
│sing differences" │ │ │
그래서 다양한 패턴을 테스트한 결과, 아래와 같은 요약을 생각해냈어요.
OpenAI 임베딩 모델의 경우, 질문 양쪽에 ###을 추가하면 꽤 괜찮은 결과를 얻을 수 있는 것 같아요. 이렇게 하면 관련성이 낮은 질문보다 관련 질문이 더 많아지고, 거리가 13% 이상 늘어난다니 정말 흥미롭죠?
다른 임베딩 모델은 어떨까요?
AWS Bedrock
기본 테스트에서는 Bedrock/Titan 모델이 질문 #1과 2를 OpenAI보다 더 잘 구별하는 것으로 나타났어요. 유사성 점수의 거리가 훨씬 더 크지만, 절대값도 훨씬 낮기 때문이에요.
╒══════════════════════════════════════════════════════════════════════╤══════════════════════════════════════════════════════════════════════╤═══════════════════╕
│text1 │text2 │score │
╞══════════════════════════════════════════════════════════════════════╪══════════════════════════════════════════════════════════════════════╪═══════════════════╡
│"The question is about comparing banking products features and summari│"question: tell the differences bwteen standard home loan and fixed lo│0.48950020909002845│
│sing differences" │an" │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────────────────┤
│"The question is about comparing banking products features and summari│"question: compare standard home loan, line of credit and fixed loan" │0.49591356152310995│
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────────────────┤
│"The question is about comparing banking products features and summari│"question: how to calculate interest?" │0.3239678489106068 │
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────────────────┤
│"The question is about comparing banking products features and summari│"question: what is fixed rate loan?" │0.32782421303093584│
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼───────────────────┤
│"The question is about comparing banking products features and summari│"question: can I make more replayment?" │0.10463201924339886│
│sing differences" │ │ │
└──────────────────────────────────────────────────────────────────────┴──────────────────────────────────────────────────────────────────────┴───────────────────┘
다양한 패턴을 적용한 결과는 다음과 같아요.
다시###텍스트 임베딩에 더 많은 영향을 미치고 있네요.
Google VertexAI
VertexAI는 OpenAI에 비해 거리는 비슷하지만 점수가 낮아요.
══════════════════════════════════════════════════════════════════════╤══════════════════════════════════════════════════════════════════════╤══════════════════╕
│text1 │text2 │score │
╞══════════════════════════════════════════════════════════════════════╪══════════════════════════════════════════════════════════════════════╪══════════════════╡
│"The question is about comparing banking products features and summari│"question: tell the differences bwteen standard home loan and fixed lo│0.7222057116992117│
│sing differences" │an" │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"question: compare standard home loan, line of credit and fixed loan" │0.7196310737891332│
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"question: how to calculate interest?" │0.6515748673785347│
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"question: what is fixed rate loan?" │0.618704888535842 │
│sing differences" │ │ │
├──────────────────────────────────────────────────────────────────────┼──────────────────────────────────────────────────────────────────────┼──────────────────┤
│"The question is about comparing banking products features and summari│"question: can I make more replayment?" │0.5397404750178617│
│sing differences" │ │ │
└──────────────────────────────────────────────────────────────────────┴──────────────────────────────────────────────────────────────────────┴──────────────────┘
일부 패턴을 적용한 후의 결과는 다음과 같아요.
VertexAI 임베딩 모델이 &&& over ### 를 선호하는 것 같네요.
요약
임베딩은 AI에 대한 지식이라고 할 수 있죠. 하지만 의미론적으로 동일한 텍스트라도 임베딩은 언어 모델의 토큰화 및 사전 학습 프로세스에 따라 결과가 크게 달라질 수 있어요. 심지어 포함된 특수 문자/기호와 같은 사소한 것들도 결과에 상당한 영향을 미칠 수 있다는 점!
일부 모델, 특히 BERT와 같은 하위 단어 기반 모델은 기호를 별도의 토큰 또는 토큰의 일부(예: BERT의 "##")로 처리해서 후속 임베딩에 영향을 줘요.
상황에 맞는 임베딩을 생성할 수 있는 모델(예: Transformer)에서 기호의 존재는 주변 단어의 맥락을 바꿔서 임베딩을 변경하게 돼요. 하지만 비공개 LLM의 경우 이에 대한 명확한 설명이 없어서, 이는 알려지지 않은 기회와 위험을 초래할 수 있다는 점을 기억해야 해요.
임베딩 및 검색 평가에 대한 보다 실용적인 지침을 얻고 싶다면, 다음 글도 도움이 될 거예요.
RAG 솔루션에서 Vector Search가 작동하지 않는 이유는 무엇일까요?
AWS
GCP
OpenAI
Search
Semantic Search
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
GenAI(Generative AI) 사용은 산업과 사용 사례 전반에 걸쳐 계속 확산되고 있어요. 기업들은 혁신과 경쟁력 유지를 위해 필요한 인프라 구축에 투자를 늘리고 있죠.
현재 GenAI는 전체 AI 투자에서 일부를 차지하지만, AI 시장 내 점유율은 점점 커지고 있어요. IDC에 따르면, "GenAI 투자 성장이 가속화되면서, 이 분야는 5년 연평균 성장률 59.2%로 전체 AI 시장을 앞지를 것으로 예상돼요." 2024년부터 2028년까지의 예측 기간이 끝나면 "IDC는 GenAI 지출이 전체 AI 지출의 32%인 2,020억 달러에 이를 것으로 보고 있어요."
똑똑한 챗봇과 코드 생성부터 대화형 분석, 개인 맞춤형 고객 경험까지, 잠재력은 정말 어마어마하죠. 하지만 Amazon의 포괄적인 인프라 지원만으로는 충분하지 않아요. 원하는 결과를 얻으려면 Amazon Web Services(AWS)에 GenAI를 배포하는 것 이상의 노력이 필요하거든요. 기업들이 어려움을 겪는 주요 원인 중 하나는, 기반이 되는 데이터베이스 기술을 충분히 고려하지 않기 때문이에요.
데이터베이스 선택이 중요한 이유
AWS는 GenAI 애플리케이션을 구축하고 확장할 수 있는 강력한 도구를 제공하지만, 기업들은 여전히 해결해야 할 문제들이 있어요. 예를 들어 환각(사실과 다른 정보를 제공하는 것), 추적성 부족(출처 자료로 연결할 수 없는 문제), 지적 재산(IP) 문제 등이 있죠. 이런 문제들은 브랜드 평판을 떨어뜨리고 재정적인 손실을 초래할 수 있기 때문에, 정확성과 설명 가능성을 높이고 IP를 보호하는 전략과 기술을 도입하는 것이 중요해요.
이러한 문제들은 특히 Graph Database를 통해 해결할 수 있어요. 산업 및 사용 사례별로 특화된 문제 해결에 도움이 되죠. 왜냐하면 Graph Database는 복잡한 다단계 데이터 계층을 처리하고, 단일 Query에서 여러 연결을 탐색할 때 뛰어난 성능을 보이도록 설계되었기 때문이에요. 가장 중요한 점은 "데이터 이면의 데이터", 즉 더 깊은 이해와 정확한 AI 해석을 가능하게 하는 맥락적 관계를 제공한다는 거죠.
반면에 GenAI 애플리케이션 배포에 자주 사용되는 기존 관계형 데이터베이스와 Vector Database는 데이터 포인트 간의 풍부한 연결을 수용하고, AI 모델이 접근할 수 있는 도메인별 관계를 만드는 데 근본적인 한계가 있어요.
전체 인포그래픽 보기
GraphRAG 입력: 판도를 바꾸는 접근 방식
Graph Retrieval-Augmented Generation(GraphRAG)은 GenAI 결과를 개선하기 위한 가장 유망한 기술 중 하나에요. GraphRAG는 Large Language Model(LLM)의 강력한 기능과 Graph Database를 결합해서, AI 시스템이 기존 RAG 방식으로는 놓칠 수 있는 관계와 맥락을 유지하면서 내부 Knowledge Graph의 실시간 데이터에 접근할 수 있도록 도와주죠.
이 접근 방식은 다음과 같은 산업 전반의 AI 애플리케이션을 혁신하고 있어요.
금융 서비스: GraphRAG는 거래 데이터에서 숨겨진 관계를 찾아내서 더 효과적인 사기 탐지를 가능하게 해주고, 만족도와 충성도를 높이는 초개인화된 고객 경험을 제공해요.
운영: 복잡한 공급망 관계를 대규모로 분석할 수 있어서 기업은 중단을 예측하고 생산 프로세스를 최적화하며 제품 개발 주기를 가속화하는 동시에 비용을 절감할 수 있죠.
벡터 전용 RAG 시스템과는 달리, GraphRAG를 사용하면 Knowledge Graph에서 어떤 정보가 사용되었는지, 어떻게, 왜 선택되었는지에 대한 가시성을 확보할 수 있어요. 이는 많은 GenAI 배포에서 문제가 되는 추적성 문제를 해결하는 데 핵심적이죠.
앞으로 나아가기: 더 강력한 GenAI, 더 나은 결과
GenAI가 계속 발전하고 성숙해짐에 따라, AI 시스템의 기능과 신뢰성, 투명성 및 설명 가능성을 다루는 조직이 성공할 가능성이 높을 거예요. 그래프 기술과 GraphRAG는 이러한 목표를 달성하기 위한 필수 도구라고 할 수 있죠.
전체 인포그래픽 보기
AWS와 Neo4j가 파트너십을 맺었어요. 일반적인 GenAI 문제를 해결하기 위해 Neo4j AuraDB 프로가 Amazon Bedrock과 원활하게 통합되죠. 이 조합은 정확성과 설명 가능성을 유지하면서 기초 모델을 사용하여 GenAI 애플리케이션을 구축하고 확장하는 가장 간단한 방법 중 하나를 제공해요. 또한 이 파트너십은 Amazon SageMaker, Amazon EMR, Amazon Redshift, AWS Glue 및 Amazon MSK와의 통합을 포함하여 전체 AWS 생태계로 확장되므로 기업은 GraphRAG를 기존 AWS 환경에 원활하게 통합하고 AWS에서 GenAI 이니셔티브의 모든 잠재력을 실현할 수 있답니다.
AWS
AWS Bedrock
GraphRAG
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
이번 포스팅에서는 새로운 `REPEATABLE ELEMENTS` 매치 모드를 사용해서, 이전에는 불가능했던 **쿼리**를 해결하는 방법을 보여드릴게요. 예를 들어, **Node** 중 하나에 들어오고 나가는 **Relationship**이 하나만 있는 원형 패턴을 찾는 것 같은 **쿼리** 말이죠.
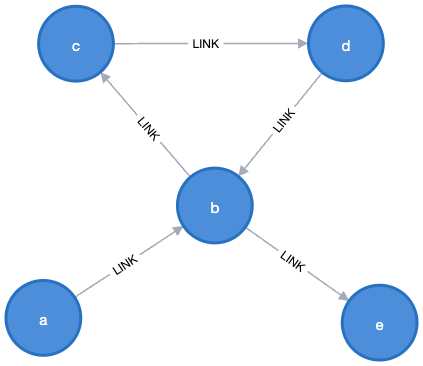
이 **Graph**를 한번 살펴볼까요?
여기서 `a`에서 `e`로 가는 방법이 몇 가지나 될까요? (**Relationship**의 방향을 따라가면서요!) 제 생각에 여러분 대부분은 두 가지라고 답할 거예요. `b`를 통해서 가거나, 아니면 `c`와 `d`를 거쳐서 우회하는 경우죠.
Cypher로 한번 시도해 볼게요.
MATCH p=(a {name: "a"})-->+(b {name: "e"}) RETURN p
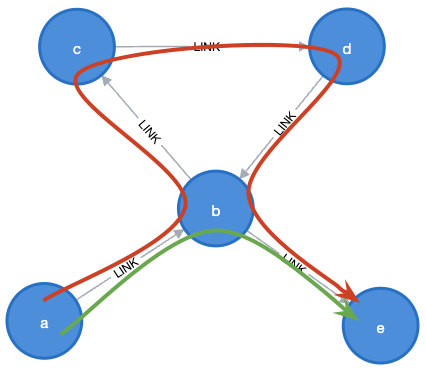
결과가 어떨 것 같나요? 당연히 여러분이 맞았어요! 다음 두 가지 결과를 얻을 수 있어요.
왜냐하면 같은 **Relationship**을 두 번 횡단할 수 없기 때문이에요. 우리는 딱 한 번의 루프만 수행할 수 있어요. `c`와 `d` 말이죠. 그런데 왜 그럴까요? 우리는 같은 `b` **Node**를 두 번 방문할 수 있었는데, 왜 **Relationship**은 안 되는 걸까요?
Cypher에서는 전통적으로 **Graph**를 탐색할 때 **Node**를 다시 방문하는 것은 허용되었지만, **Relationship**은 다시 방문할 수 없었어요. 이걸 `DIFFERENT RELATIONSHIPS` 매치 모드라고 불러요. 하지만 이게 지원되는 유일한 모드였기 때문에, 굳이 이걸 깊게 생각할 필요가 없었죠.
`DIFFERENT RELATIONSHIPS`가 기본값인 데에는 몇 가지 이유가 있어요. 우리 인간이 기대하는 것과 비슷하기도 하고 (위의 예시를 생각해보세요!), 무한 루프가 발생할 가능성이 적고, 계산 비용도 더 저렴하거든요.
하지만 새로운 Cypher 25 버전, 즉 Neo4j의 최신 릴리스인 2025.06.0에는 `REPEATABLE ELEMENTS`라는 새로운 매치 모드가 추가되어서, 이제 **Relationship**도 다시 방문할 수 있게 되었어요! `DIFFERENT RELATIONSHIPS`는 여전히 기본값이지만, `MATCH` 다음에 `REPEATABLE ELEMENTS`라는 키워드를 추가할 수 있어요.
MATCH REPEATABLE ELEMENTS <PATH PATTERN>, <PATH PATTERN>...
그런데, 도대체 왜 이런 걸 하고 싶을까요? 언제 유용할까요? 다양한 사용 사례를 한번 살펴볼게요.
데이터 세트
이걸 위해서, 전 세계 모든 공항과 공항 연결 방식이 담긴 데이터 세트가 필요했어요. 정규 항공편으로 해당 노선을 운항하는 항공사가 하나 이상 있다면, 하나의 공항이 다른 공항과 연결된 것으로 간주하는 거죠. 두 공항 사이에는 기껏해야 하나의 연결만 있을 거고, 방향은 신경 쓰지 않기로 했어요. (항공사가 한 방향으로 비행하면, 다른 방향으로도 비행한다고 가정하는 거예요. 항상 그런 건 아니지만, 적어도 대부분의 경우엔 단순화할 수 있거든요.)
저는 Jonty Wareing인데, 대부분의 공항 및 노선 데이터 세트를 GitHub에서 위에서 설명한 형식으로 Neo4j 데이터베이스로 직접 가져오는 Cypher 쿼리를 작성했어요. 이 쿼리는 AuraDB Free에서도 작동하도록 설계되었답니다:
MATCH (n) DETACH DELETE n;
CREATE INDEX iata IF NOT EXISTS FOR (a:Airport) ON (a.iata);
CALL apoc.load.json("https://raw.githubusercontent.com/Jonty/airline-route-data/refs/heads/main/airline_routes.json", null, {failOnError:false}) YIELD value
UNWIND keys(value) AS iata
WITH value[iata] AS iata
CALL(iata) {
MERGE (airport:Airport {iata: iata['iata']})
SET airport.location = point({latitude: toFloat(iata['latitude']), longitude: toFloat(iata['longitude'])})
WITH iata, airport
CALL(iata, airport) {
UNWIND keys(iata) AS prop
FILTER prop <> 'routes' AND prop <> 'iata' AND prop <> 'latitude' AND prop <> 'longitude'
SET airport[prop] = iata[prop]
}
CALL(iata, airport) {
UNWIND iata['routes'] AS route
UNWIND route['carriers'] AS carrier
WITH route, collect(carrier['name']) AS carriers
MERGE (destination:Airport {iata: route['iata']})
MERGE (airport)-[c:CONNECTION]-(destination)
ON CREATE
SET c += { km: route['km'], carriers: carriers }
}
} IN TRANSACTIONS OF 1000 ROWS;
참고로 FILTER는 위 쿼리에서 사용된 키워드인데요. Cypher 25의 또 다른 새로운 기능이랍니다. WITH 다음에 WHERE를 사용하는 것과 같아요.
Aura를 사용하고 있다면 쿼리 도구에서 바로 실행할 수 있어요. 시각화를 위해 도구 모음에서 탐색 도구로 전환하면 되는데요. 설정이 4,000개 이상의 nodes를 허용하는지 확인하고, 모든 nodes를 가져오는 쿼리를 실행해 보세요.
MATCH (n) RETURN n
이제 으로 바꿔볼까요? 화면 오른쪽 하단에 있는 선택기에서 (아직 설정되어 있지 않다면) 를 좌표에 사용할 속성으로 설정하면 돼요. 전체 그래프를 볼 수 있도록 축소하고, 그래프를 보려면 슬라이더를 당겨 보세요. X 와 Y 축을 조정하면 모든 공항에서 친숙한 모양이 보이기 시작할 거예요.
자, 이제 Command+A 또는 Ctrl+A를 눌러 모든 nodes를 선택해 주세요. nodes 위에서 마우스 오른쪽 버튼을 클릭하고 확장 > 모두를 선택하면 모든 경로도 볼 수 있답니다.
날짜 변경선을 통과하는 경로는 전 세계 반대 방향으로 이동하는 것으로 렌더링됩니다.
이것으로 끝이에요. 이제 REPEATABLE ELEMENTS의 사용 사례에 필요한 데이터가 준비되었네요!
사용 사례
다음은 위의 공항 데이터를 사용하는 REPEATABLE ELEMENTS의 몇 가지 다양한 사용 사례랍니다.
이사피외르뒤르(Ísafjörður)의 고립
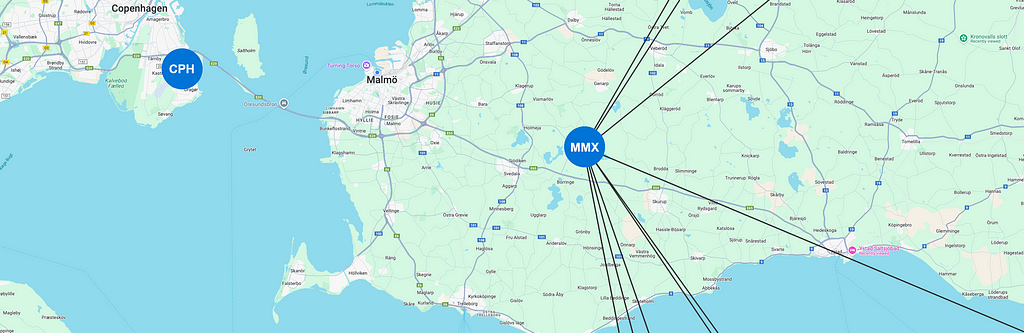
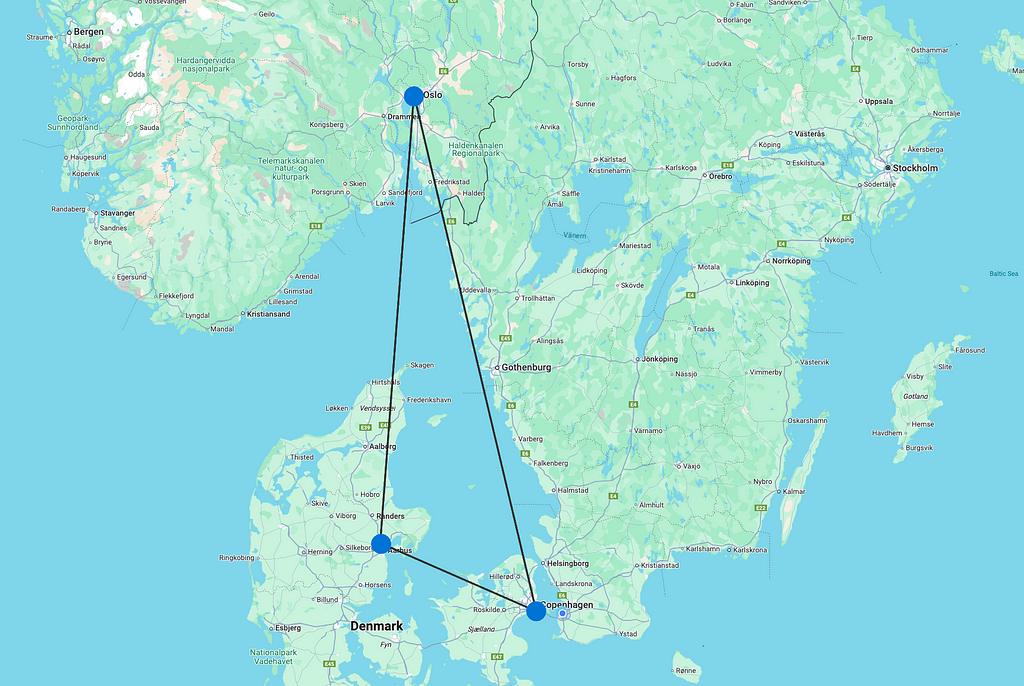
저는 스웨덴 말뫼에 살고 있어요. 여기에는 "Sturup"(IATA 코드 MMX)라는 별명을 가진 말뫼 공항이라는 공항이 있죠. 훨씬 더 큰 덴마크 코펜하겐 공항에 가는 것이 더 빠르고 쉽기 때문에 이 공항에서 비행기를 타는 일은 거의 없어요. 하지만 이 사용 사례에서는 말뫼 공항에서 비행기를 타고 싶다고 가정해 볼게요 (강풍으로 인해 코펜하겐으로 가는 다리가 폐쇄되었을 수도 있겠죠!).
모든 직항 노선이 있는 말뫼 공항(코펜하겐 공항도 포함되지만 노선은 없음)
이제 저는 지금 당장 어딘가로 날아가고 싶은 충동을 느껴요 (이 날 다리가 폐쇄되어 타이밍이 좋지 않네요!). 그냥 비행기를 타고 어디론가 가고 싶은 게 아니라, 적어도 세 번은 비행기를 타고 가고 싶어요. 하지만 보안 검색대에서 보내고 싶은 시간에는 제한이 있으므로 비행 횟수는 5회를 넘지 않아야 해요. 말뫼에서 시작한다면 얼마나 많은 가능성이 있을까요? 다음을 한번 살펴볼까요?
MATCH (mmx:Airport {iata: "MMX"})
MATCH p=(mmx)(()-[:CONNECTION]-()){3,5}(mmx)
RETURN p
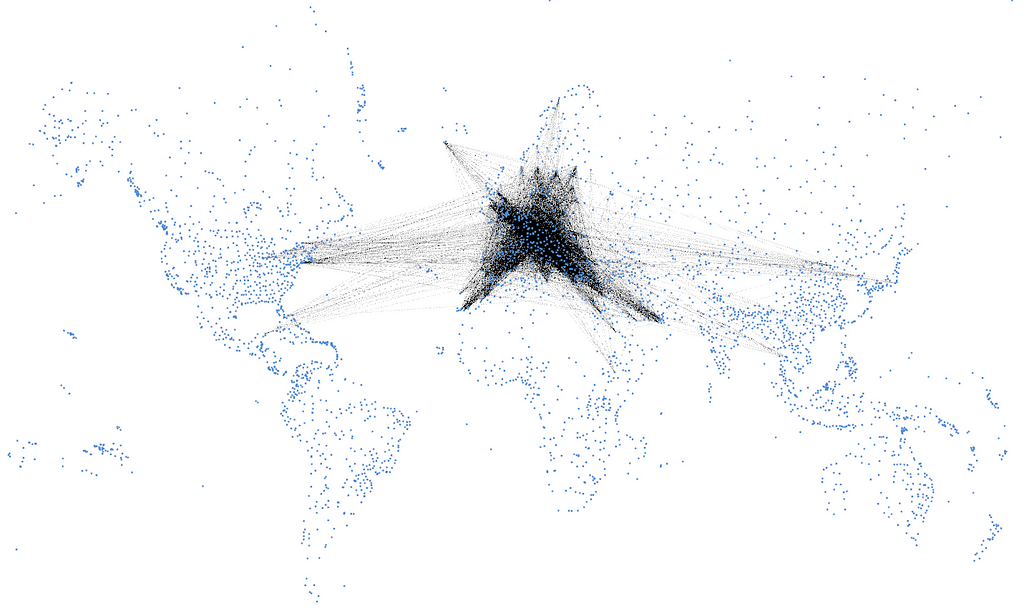
이를 통해 우리는 181,630가지의 다양한 여행 옵션을 선택할 수 있고, 서쪽 시카고, 북쪽 트롬쇠, 동쪽 도쿄, 남쪽 아디스아바바에서 전 세계 공항의 6.4%(242개)에 도달할 수 있답니다.
말뫼 공항에서 3~5개 홉으로 이동할 수 있는 경로
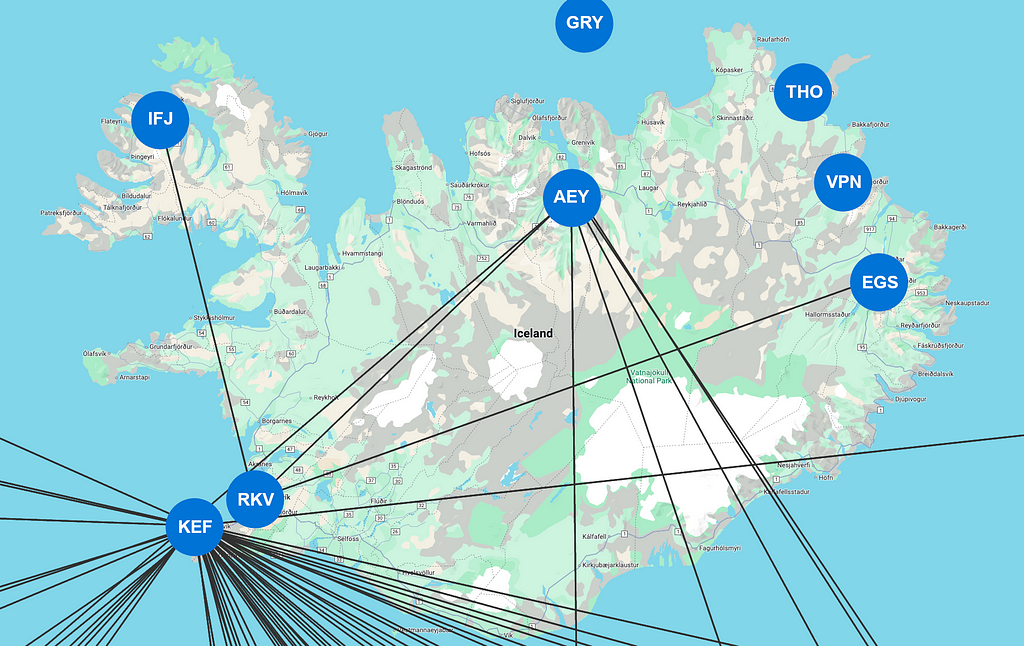
제겐 아이슬란드 북서부의 이사피외르뒤르(Ísafjörður)에 사는 친구가 있는데(아, 물론 실제로 그렇진 않지만 그렇다고 쳐봐요!) 트롬쇠에서 제가 겪었던 놀라운 경험에 대해 듣고 자기도 똑같이 해보고 싶어해요. 자, 이제 Ísafjörður(IATA 코드 IFJ)에 대한 쿼리를 업데이트해볼까요?
MATCH (ifj:Airport {iata: "IFJ"})
MATCH p=(ifj)(()-[:CONNECTION]-()){3,5}(ifj)
RETURN p
결과가 0이에요! 왜 그럴까요? Icelandair에서 이 공항을 오가는 항공편을 운항하고 있는데 말이죠. 그 이유는 레이캬비크로 가는 연결편이 단 하나뿐이고, 출국 항공편에서 이걸 사용해야 하기 때문에 다시 돌아올 때 이 연결편을 사용할 수 없기 때문이에요(같은 relationship을 두 번 횡단할 수 없다는 점을 기억하세요!).
아이슬란드 공항의 정기 노선
해결책은 새로운 REPEATABLE ELEMENTS를 사용하는 거예요. 연결을 다시 방문할 수 있도록 해주죠. 이렇게요!
MATCH (ifj:Airport {iata: "IFJ"})
MATCH REPEATABLE ELEMENTS p=(ifj)(()-[:CONNECTION]-()){3,5}(ifj)
RETURN p
이제 결과를 얻었네요. 아쉽게도 제 친구는 경기가 3번밖에 안 되어서 아이슬란드를 떠나지 못해요. 왜냐면 레이캬비크가 국내 공항이기 때문에 다른 노선이 두 개뿐이거든요(국제 공항은 레이캬비크에서 30마일 떨어진 케플라비크!). 따라서 네 단계를 거치면 Akureyri 또는 Egilsstadir에 도착하고 돌아오게 돼요(아니면 Reykjavik에 갔다가 두 번 돌아오거나). 다섯 번째 홉을 사용하면 Ísafjörður로 돌아오지 않아요. 하지만 적어도 REPEATABLE ELEMENTS 덕분에 Ísafjörður의 고립을 완전히 해결하진 못하더라도 쿼리는 해결할 수 있게 되었어요.
나는 500마일을 날고 싶다
이번에는 The Proclaimers의 "I'm Gonna Be(500 Miles)"의 정신으로 공항 그래프를 사용해서 또 다른 사용 사례를 살펴볼게요. 500마일을 걷는 건 너무 힘들 것 같으니, 대신 비행기를 타보자구요!
마일리지 추적하시는 분 계신가요? 우리가 절대 잃고 싶지 않은 항공사 자격을 유지하는 데 500마일이 부족하다고 상상해 보세요. 그럼 이전 섹션과 마찬가지로 500 상태 포인트를 획득하는 것을 목표로 한번 둘러볼까요? 거리와 티켓 가격 사이에는 약간의 상관관계가 있다고 가정하고(실제로는 좀 약하지만!), 우리는 검소하니까 거리를 최대한 낮게 유지하면서도 500 이상을 유지하려고 하는 거죠.
이번에는 항공편 상태 때문에 Scandinavian Airlines만 이용하고 싶어요(당분간 항공사 제휴는 무시할게요). 이 항공사의 세 가지 주요 허브는 코펜하겐, 스톡홀름, 오슬로에요. 그래서 이번에는 다리에 바람이 잘 통해서 Malmö 대신 코펜하겐으로 넘어갈 수 있기를 바라봅니다.
스칸디나비아 항공이 운항하는 노선
연결 시의 거리는 킬로미터(km) 단위이고, 500마일은 805km와 같아요. 우리의 질문은 코펜하겐에서 출발해서 2~6번의 점프를 하고 다시 코펜하겐에 도착하는 여정이에요. 목표는 가능한 한 805km에 가깝게 유지하는 거죠(물론 넘어야 하고요!). 한도를 6개로 설정한 이유는 150km 미만의 비행편이 거의 없기 때문이에요.
MATCH (cph:Airport {iata: "CPH"})
MATCH p=(cph)(()-[c:CONNECTION]-() WHERE "Scandinavian Airlines" IN c.carriers){2,6}(cph)
WITH p, reduce(d = 0, c IN relationships(p) | d + c.km) AS distance
WHERE distance >= 805
ORDER BY distance LIMIT 1
RETURN p, distance
우리가 받은 제안은 코펜하겐에서 오슬로까지(516km), 오슬로에서 오르후스까지(433km), 다시 코펜하겐까지(147km) 비행하는 여정이에요. 총 거리는 1,096km(681마일)네요.
코펜하겐 > 오슬로 > 오르후스 > 코펜하겐
음, 꽤 많이 초과됐네요. 제가 돈이 엄청 많다고 생각하는 걸까요? 좀 더 최적의 변형을 찾아봐야겠어요. 다시 한번 REPEATABLE ELEMENTS 구조를 활용해볼게요. 우리는 오슬로까지 왕복하는 시간이 더 짧으면서도 여전히 500마일 이상이 될 거라는 걸 알고 있으니, 연결 재사용을 허용하면 확실히 도움이 될 거예요. 다음은 REPEATABLE ELEMENTS를 사용한 쿼리에요(548km보다 짧은 항공편만 고려하도록 필터를 추가했어요. 이미 그 두 배에 달하는 솔루션이 있으니까요!).
MATCH (cph:Airport {iata: "CPH"})
MATCH REPEATABLE ELEMENTS p=(cph)(()-[c:CONNECTION]-() WHERE c.km < 548 AND "Scandinavian Airlines" IN c.carriers){2,6}(cph)
WITH p, reduce(d = 0, c IN relationships(p) | d + c.km) AS distance
WHERE distance >= 805
ORDER BY distance LIMIT 1
RETURN p, distance
같은 공항 사이를 두 번 이상 비행하는 게 허용되면 더 짧은 옵션이 제공되기도 해요. Torp는 코펜하겐에서 420km 떨어진 오슬로 남쪽 노르웨이 해안 공항인데, 그래서 총 여행은 840km(522마일)로 끝났어요. 덕분에 항공편 상태를 1년 더 확보하게 되었죠.
두 번째로 좋은 대안은 오르후스를 세 번 왕복하는 거였는데, 그건 너무 단조로웠을 것 같아서 Torp가 있어서 다행이었어요.
상상의 친구를 방문하다
Cypher에는 "keyword"라고 불리는 키워드가 있는데, SHORTEST 이걸 통해 그래프에서 최단 경로(홉의 무게가 아닌 홉 수로)를 찾을 수 있어요. 이건 이제 REPEATABLE ELEMENTS를 지원한답니다.
잠깐만요, 최단 경로의 경우 관계를 반복할 필요가 전혀 없다고 말할 수도 있겠네요! 음, 두 지점 사이의 절대 최단 경로를 원한다면 그렇지 않죠. 하지만 홉 제한이 더 낮거나 경로에 대한 다른 특별한 규칙이 있는 경우 그럴 수도 있어요. 또 다른 예를 살펴볼까요?
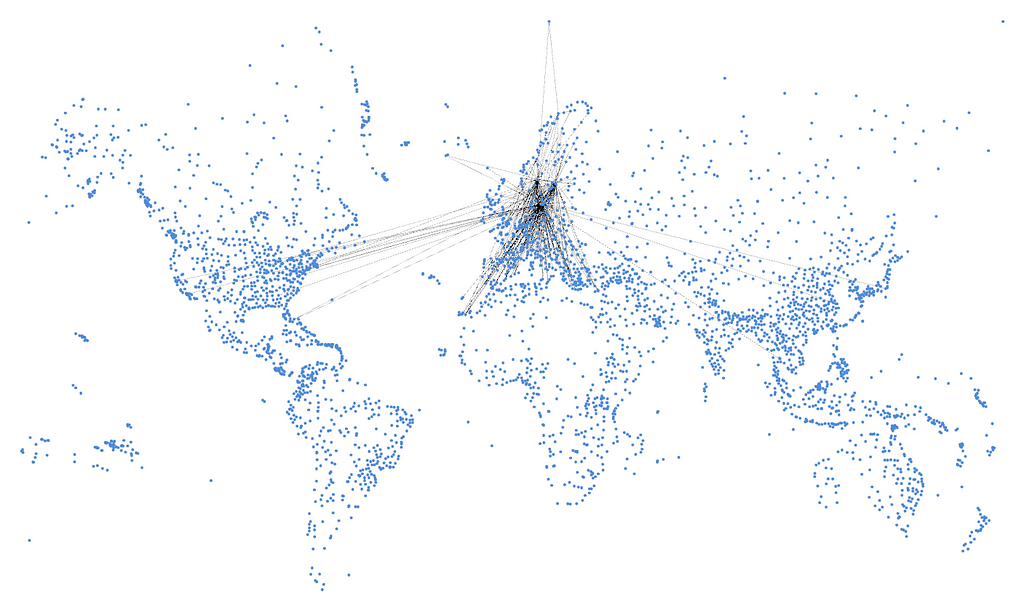
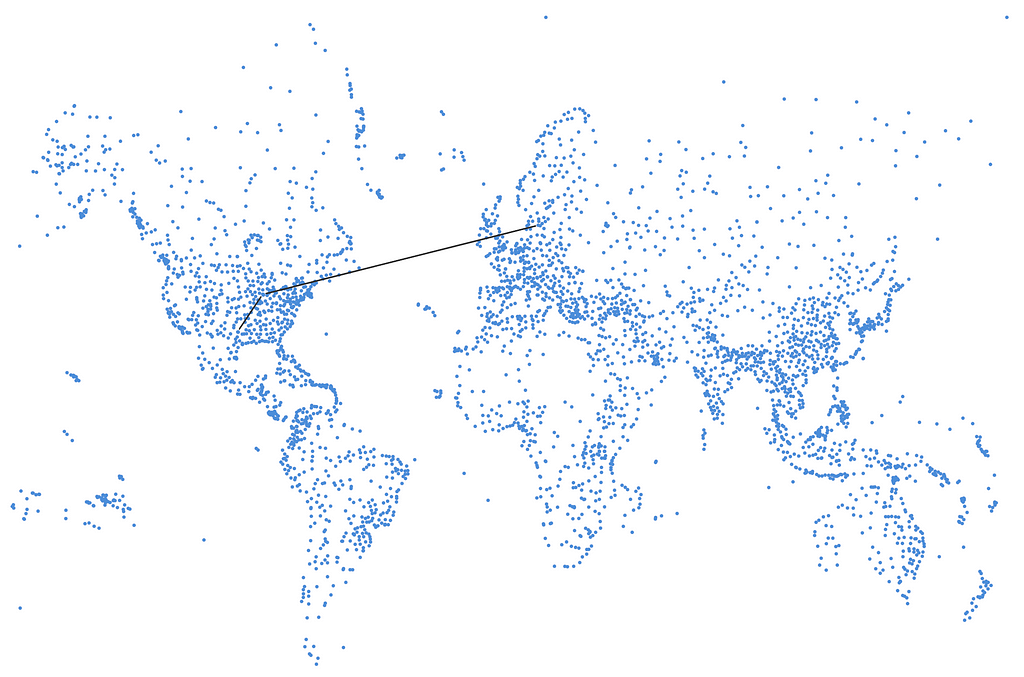
저는 코펜하겐에서 댈러스로 비행기를 타고 친구들(이번에는 진짜 친구들!)을 방문하고 싶고, 가능한 한 적은 비행 시간으로 여행하고 싶어요. 이렇게 할 수 있겠죠.
MATCH p = ALL SHORTEST (:Airport {iata:"CPH"})--+(:Airport {iata:"DFW"})
WITH p, reduce(d = 0, c IN relationships(p) | d + c.km) AS distance
ORDER BY distance LIMIT 1
RETURN p
첫 번째 명령문은 (최소 비행 횟수에서) 최단 경로를 찾는 명령문이에요. 우리는 ALL SHORTEST (대신 SHORTEST 1)를 사용해서 단 하나의 경로가 아닌 모든 최단 경로를 반환해요. 그런 다음 총 거리를 기준으로 순서를 지정하고 거리 기준으로 가장 짧은 것을 선택하는 거죠. 총 거리가 더 짧고 홉 수가 더 많은 항공편이 여전히 있을 수 있지만, 우리는 항공편 환승 횟수를 줄이는 걸 목표로 하고 있고, 이걸 통해 시카고에서 한 번의 환승 옵션을 제공해 줘요.
코펜하겐에서 시카고를 거쳐 댈러스까지
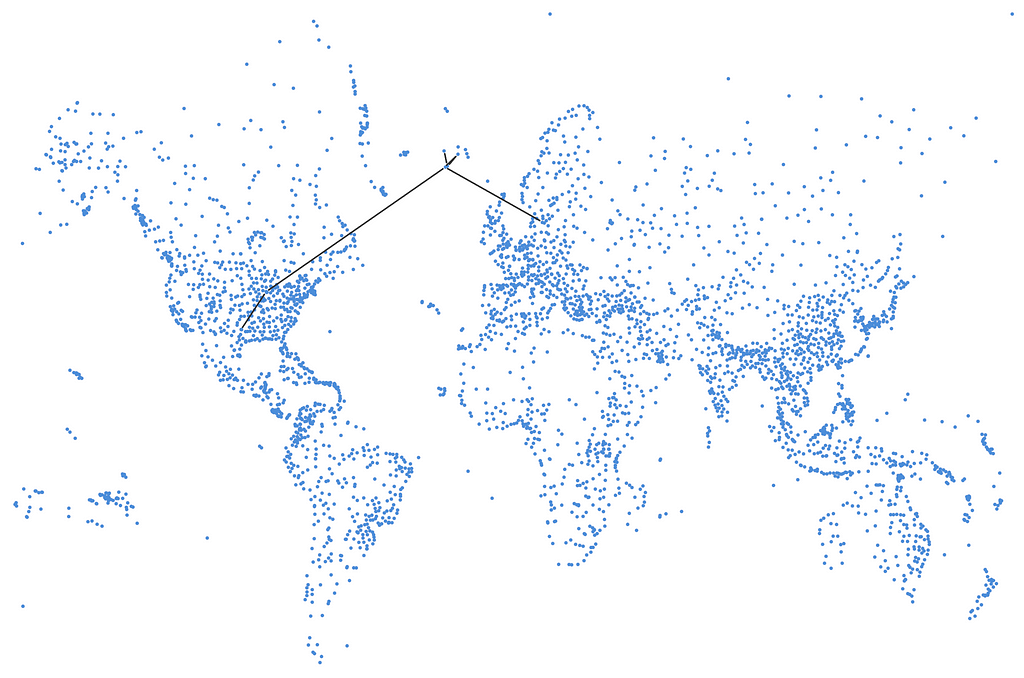
여기에 또 다른 조건을 추가해 볼게요. 이사피외르뒤르(Ísafjörður)에 있는 제 상상의 친구를 기억하시나요? 지구의 곡률 때문에 북유럽에서 북미로 가는 항공편은 대개 아이슬란드 상공을 비행한다는 걸 알고 있으니, 그를 방문하는 것도 괜찮겠죠? 다음과 같은 쿼리가 될 거예요.
MATCH p = ALL SHORTEST (:Airport {iata:"CPH"})--+(:Airport {iata:"IFJ"})--+(:Airport {iata: "DFW"})
WITH p, reduce(d = 0, c IN relationships(p) | d + c.km) AS distance
ORDER BY distance LIMIT 1
RETURN p
하지만 우리는 어떤 결과도 얻지 못했고, 그 이유를 이미 알고 있어요. 이사피외르뒤르(Ísafjörður)에 가려면 여행을 계속할 때 재사용할 경로를 사용해야 해요. 그래서 다시, 우리는 다음으로 전환해야 해요. REPEATABLE ELEMENTS 문제를 해결하려면 다음 단계를 따르세요.
MATCH REPEATABLE ELEMENTS p = ALL SHORTEST (:Airport {iata:"CPH"})--{,10}(:Airport {iata:"IFJ"})--{,10}(:Airport {iata: "DFW"})
WITH p, reduce(d = 0, c IN relationships(p) | d + c.km) AS distance
ORDER BY distance LIMIT 1
RETURN p;
+는 {,10}으로 대체돼요. 이는 다음을 사용할 때 무한 수량자를 가질 수 없기 때문이에요. REPEATABLE ELEMENTS. 조금만 생각해 보면 이해될 거예요.
이를 통해 우리는 케플라비크(레이캬비크 국제 공항)를 통과하는 9홉 경로를 얻게 되지만, 레이캬비크 국내 공항을 거쳐 이사피요르뒤르까지 이동하려면 아쿠레이리까지 비행기를 타고 가야 해요. 그런 다음 케플라비크(Keflavík)로 다시 같은 길을 횡단해야 하며, 거기에서 시카고를 거쳐 댈러스로 계속 이동해야 하죠.
이사피외르뒤르(Ísafjörður)를 거쳐 코펜하겐에서 댈러스까지
이걸 보고 내린 결론은 케플라비크와 레이캬비크 사이 50km 정도는 택시를 타는 게 더 나았을 거라는 거예요. 그렇게 하면 9번의 비행 중 4번의 비행과 총 1,066km의 비행 시간을 절약할 수 있거든요. 하지만 택시에서는 공짜 땅콩을 얻을 수 없잖아요!
요약
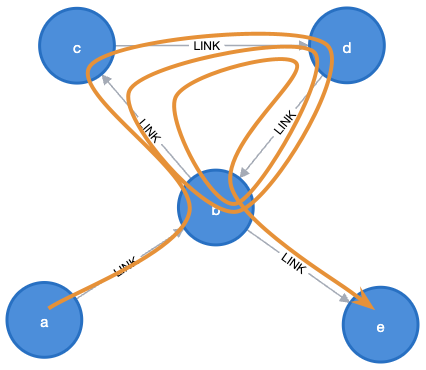
여기서 살펴본 예를 보면 REPEATABLE ELEMENTS는 동일한 관계를 양방향으로 탐색하려는 경우에만 유용하다는 걸 알 수 있어요. 하지만 우리는 같은 방향으로 관계를 재검토하고 싶을 수도 있죠. 이 기사의 첫 번째 예제 그래프로 돌아가서 최단 경로를 원한다고 말하면 a to e, 그러나 6번 이상의 점프에서는 다음을 사용하지 않으면 결과를 얻을 수 없어요. REPEATABLE ELEMENTS:
MATCH REPEATABLE ELEMENTS p = SHORTEST 1 (a {name: "a"})-->{6,10}(b {name: "e"})
RETURN p
이는 두 개의 루프를 통해 결과를 제공해요. c and d.
Neo4j 및 Cypher의 대부분의 전통적인 사용에서는 다른 관계의 기본 일치 모드가 아마도 여러분이 원하는 방식일 거예요. 하지만 앞서 살펴봤듯이 관계를 여러 번 탐색할 수 있다면 유익한 경우가 분명히 있겠죠?
다음에 대해 더 자세히 읽어볼 수 있어요. 매치 모드(Match Modes) 와 반복 가능한 요소(Repeatable Elements)는 Cypher 문서에서 확인해보세요. 궁금한 사항은 게시판에 올려주시면 됩니다. Neo4j 커뮤니티 포럼에 질문해주세요.
Cypher
GQL
Relationships
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
Neo4j GraphRAG Python 패키지 시리즈의 세 번째 기사에서는 전체 텍스트 인덱스를 사용하여 GraphRAG 애플리케이션을 향상시키는 방법을 살펴볼 거예요. 전체 텍스트 인덱스와 벡터 인덱스를 결합하면 벡터 검색만으로는 놓칠 수 있는 정보를 검색해서 검색 프로세스의 성능을 어떻게 향상시킬 수 있는지 보여드릴게요. 또한 Neo4j GraphRAG Python 라이브러리를 사용하여 전체 텍스트 인덱스와 벡터 인덱스를 모두 활용하는 GraphRAG 애플리케이션을 구축하는 방법을 살펴볼게요.
이전 블로그에서 사용된 사전 구성된 Neo4j 데모 데이터베이스 중 일부를 사용할 건데요 (GraphRAG Python 패키지 and GraphRAG Python 패키지를 사용하여 그래프 탐색으로 벡터 검색 강화 참고). 이 데이터베이스는 영화 추천 Knowledge Graph를 시뮬레이션해요. 데이터베이스에 대한 자세한 내용은 설정 섹션을 참조하세요. GraphRAG Python 패키지.
웹 브라우저를 통해 데이터베이스에 액세스할 수 있어요. 사용자 이름과 비밀번호로 "추천"을 사용하면 돼요. 다음 코드 조각을 사용하여 애플리케이션의 데이터베이스에 연결하세요.
from neo4j import GraphDatabase
# Demo database credentials
URI = "neo4j+s://demo.neo4jlabs.com"
AUTH = ("recommendations", "recommendations")
# Connect to Neo4j database
driver = GraphDatabase.driver(URI, auth=AUTH)
또한 OpenAI 키를 내보내야 해요.
import os
os.environ["OPENAI_API_KEY"] = "sk-…"
벡터 검색의 한계
Vector Search는 RAG 애플리케이션의 기본 구성 요소인 경우가 많아요. 이걸 통해 애플리케이션은 데이터베이스에서 사용자의 쿼리와 의미상 유사한 정보를 찾고, LLM이 응답을 생성할 수 있도록 해당 정보를 관련 컨텍스트로 제공할 수 있죠. 이전 시리즈 게시물에서는 GraphRAG 애플리케이션에서 Vector Search를 사용해서 의미 면에서 사용자 쿼리와 밀접하게 일치하는 플롯이 포함된 영화를 반환하고 영화에 대한 질문에 답했는데요. 예를 들어, 사용자가 "공룡 테마파크를 소재로 한 영화 제목이 뭐죠?"라고 물으면 Vector Search는 영화 Jurassic Park를 검색할 거예요. '미리보기 투어 중에 테마파크의 전력이 크게 중단되어 복제된 공룡 전시물이 날뛰게 됩니다'라는 줄거리가 사용자 쿼리와 의미가 유사하기 때문이죠.
하지만 의미론적 유사성이 항상 모든 쿼리에 대해 가장 관련성이 높은 정보를 검색하는 최고의 척도는 아닐 수 있어요. 예를 들어, 광범위한 의미가 부족하거나 더 넓은 맥락에서 다른 의미를 갖는 도메인별 용어를 검색할 때 Vector Search는 관련 정보를 검색하지 못하거나 관련 없는 정보를 반환할 수 있죠. 이는 이러한 용어가 Vector Search에 사용되는 임베딩 모델의 훈련 데이터에서 잘 표현되지 않을 수 있기 때문에 발생해요. 정확한 결과를 위해 정확히 일치해야 하는 이름이나 날짜와 같은 문자열이 사용자 쿼리에 포함된 경우에도 의미론적 유사성은 신뢰할 수 있는 측정이 아니에요. 이에 대한 예로, VectorRetriever를 사용해서 중국 제국의 1375년 영화 세트와 같이 특정 장소와 날짜를 배경으로 한 영화 세트의 이름을 묻는 경우를 들 수 있어요.
from neo4j import GraphDatabase
from neo4j-graphrag.embeddings.openai import OpenAIEmbeddings
from neo4j-graphrag.retrievers import VectorRetriever
driver = GraphDatabase.driver(URI, auth=AUTH)
embedder = OpenAIEmbeddings(model="text-embedding-ada-002")
retriever = VectorRetriever(
driver,
index_name="moviePlotsEmbedding",
embedder=embedder,
return_properties=["title", "plot"],
)
query_text = "What is the name of the movie set in 1375 in Imperial China?"
retriever_result = retriever.search(query_text=query_text, top_k=3)
print(retriever_result)
이걸 정확하게 일치시키려면 VectorRetriever 일치 알고리즘은 영화의 줄거리 설명 내에서 1375에 대한 정확한 날짜 참조를 찾아야 하지만, 현실적으로 불가능하죠. 결과적으로 VectorRetriever는 이 쿼리에 대한 올바른 영화(전사 무사)를 반환하지 못해요. 대신 중국을 배경으로 하거나 중국과 관련된 영화를 검색하지만, 1375년을 배경으로 한 영화는 없어요.
items = [
RetrieverResultItem(
content="{'title': 'Once Upon a Time in China (Wong Fei Hung)', 'plot': "Set in late 19th century Canton this martial arts film depicts the stance taken by the legendary martial arts hero Wong Fei-Hung (1847-1924) against foreign forces' (English, French and ..."}",
metadata={"score": 0.9209008812904358, "nodeLabels": None, "id": None},
),
RetrieverResultItem(
content="{'title': 'Once Upon a Time in China II (Wong Fei-hung Ji Yi: Naam yi dong ji keung)', 'plot': 'In the sequel to the Tsui Hark classic, Wong Fei-Hung faces The White Lotus society, a fanatical cult seeking to drive the Europeans out of China through violence, even attacking Chinese ...'}",
metadata={"score": 0.9179003834724426, "nodeLabels": None, "id": None},
),
RetrieverResultItem(
content="{'title': 'Red Cliff Part II (Chi Bi Xia: Jue Zhan Tian Xia)', 'plot': 'In this sequel to Red Cliff, Chancellor Cao Cao convinces Emperor Xian of the Han to initiate a battle against the two Kingdoms of Shu and Wu, who have become allied forces, against all ...'}",
metadata={"score": 0.91493159532547, "nodeLabels": None, "id": None},
),
]
metadata = {"__retriever": "VectorRetriever"}
Full-Text Indexes
다행히 이 문제에 대한 해결책이 있어요. 바로 Full-Text Indexes죠. 의미론적 유사성을 기준으로 문자열을 일치시키는 벡터 인덱스와 달리, Full-Text Indexes는 어휘 유사성을 기준으로 텍스트 조각을 일치시켜요. 즉, 정확한 단어 또는 텍스트 구조를 비교하는 거죠. 예를 들어, "The bat fly"와 "The bat broken"이라는 문장을 생각해 볼까요? 이 문장들은 단어 하나만 다르기 때문에 어휘적으로는 유사하지만 의미상으로는 달라요. 첫 번째는 날아다니는 동물을 묘사하고, 두 번째는 물체가 부서지는 것을 묘사하죠. Full-Text Index를 사용하면 날짜, 이름 등의 문자열을 정확하게 일치시킬 수 있어요.
하이브리드 리트리버
하이브리드 검색 프로세스
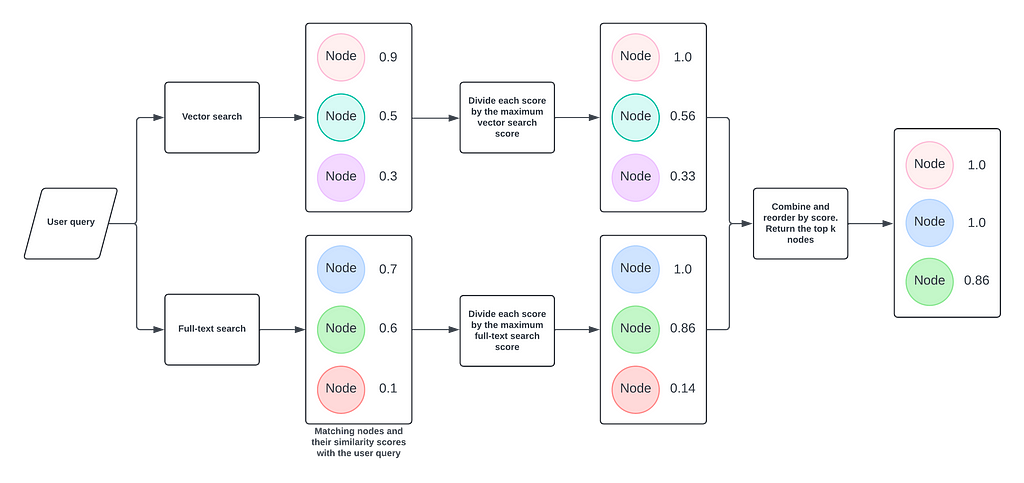
Neo4j GraphRAG Python 라이브러리의 HybridRetriever 클래스를 사용해서 GraphRAG 애플리케이션에 전체 텍스트 인덱스를 활용하는 방법을 알아볼게요. 이 Retriever는 하이브리드 검색이라는 방식으로 Vector Index와 전체 텍스트 인덱스를 모두 사용해요. 사용자 쿼리를 받아서 두 인덱스를 검색하고, `Node`와 점수를 얻어내죠. 각 결과 세트의 점수를 정규화한 다음 합쳐서 점수별로 순위를 매긴 후, 가장 적합한 결과를 반환해준답니다.
from neo4j import GraphDatabase
from neo4j-graphrag.embeddings.openai import OpenAIEmbeddings
from neo4j-graphrag.retrievers import HybridRetriever
driver = GraphDatabase.driver(URI, auth=AUTH)
embedder = OpenAIEmbeddings(model="text-embedding-ada-002")
retriever = HybridRetriever(
driver=driver,
vector_index_name="moviePlotsEmbedding",
fulltext_index_name="movieFulltext",
embedder=embedder,
return_properties=["title", "plot"],
)
query_text = "What is the name of the movie set in 1375 in Imperial China?"
retriever_result = retriever.search(query_text=query_text, top_k=3)
print(retriever_result)
여기서는 영화 줄거리용 Vector Index (moviePlotsEmbedding)와 각 영화의 제목과 줄거리가 합쳐진 전체 텍스트 인덱스 (movieFulltext)를 다시 사용하고 있어요. 이 Retriever를 사용하면 원하는 영화를 정확히 찾아낼 수 있죠!
items = [
RetrieverResultItem(
content="{'title': 'Musa the Warrior (Musa)', 'plot': '1375. Nine Koryo warriors, envoys exiled by Imperial China, battle to protect a Chinese Ming Princess from Mongolian troops.'}",
metadata={"score": 1.0},
),
RetrieverResultItem(
content="{'title': 'Once Upon a Time in China (Wong Fei Hung)', 'plot': "Set in late 19th century Canton this martial arts film depicts the stance taken by the legendary martial arts hero Wong Fei-Hung (1847-1924) against foreign forces' (English, French and ..."}",
metadata={"score": 1.0},
),
RetrieverResultItem(
content="{'title': 'Once Upon a Time in China II (Wong Fei-hung Ji Yi: Naam yi dong ji keung)', 'plot': 'In the sequel to the Tsui Hark classic, Wong Fei-Hung faces The White Lotus society, a fanatical cult seeking to drive the Europeans out of China through violence, even attacking Chinese ...'}",
metadata={"score": 0.9967417798386851},
),
]
metadata = {"__retriever": "HybridRetriever"}
이걸 전체 GraphRAG 파이프라인으로 만들려면, 다음 코드를 추가하기만 하면 돼요.
from neo4j-graphrag.llm import OpenAILLM
from neo4j-graphrag.generation import GraphRAG
# LLM
# Note: the OPENAI_API_KEY must be in the env vars
llm = OpenAILLM(model_name="gpt-4o", model_params={"temperature": 0})
# Initialize the RAG pipeline
rag = GraphRAG(retriever=retriever, llm=llm)
# Query the graph
query_text = "What is the name of the movie set in 1375 in Imperial China?"
response = rag.search(query_text=query_text, retriever_config={"top_k": 3})
print(response.answer)
우리가 기대하는 답변은 바로 이거죠!
The name of the movie set in 1375 in Imperial China is "Musa the Warrior (Musa)."
요약
neo4j-graphrag 패키지의 HybridRetriever 클래스를 사용해서 GraphRAG 애플리케이션을 구축하는 방법을 보여드렸어요. 이 클래스가 Vector Search와 전체 텍스트 검색을 결합해서, Vector Search만으로는 찾기 어려울 수 있는 사용자 쿼리에 대한 정확한 컨텍스트를 찾아내는 과정을 살펴봤죠.
패키지 코드는 오픈 소스이고 에서 확인할 수 있어요. 언제든지 이슈를 올려주세요.
GraphRAG
Python
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
이 기사에서는 정적 YAML 스키마 파일을 Neo4j 지식 그래프로 대체하여 토큰 사용량을 평균 20~30%(간단한 쿼리의 경우 최대 10배) 줄이는 동시에 복잡한 다중 테이블 질문의 정확도를 ~10% 포인트 향상시키는 방법을 보여 드리겠습니다. 모두 3분 안에 실행할 수 있는 라이브 데모에서 벤치마킹되었습니다.
중요한 이유
비즈니스 컨텍스트
데이터 기반 기업의 경우 데이터를 기반으로 주요 결정을 내려야 하므로 데이터에 대한 보편적인 액세스(정책 및 거버넌스 측면에서)는 선도하기 위한 필수 이니셔티브입니다.
그러나 대부분의 데이터는 데이터베이스에 상주하며 조직은 이 데이터를 지속적으로 대시보드로 전송하기 위해 IT 팀에 상당한 시간과 리소스를 투자합니다. 이러한 대시보드는 회사의 KPI를 기반으로 한 결정을 안내하는 중요한 자산이며 앞으로도 그럴 것입니다. 이제 비즈니스 사용자는 더 많은 것을 기대합니다. 그들은 숫자만 보고 싶어하는 것이 아닙니다. 그들은 조직 가치 사슬 전반에 걸쳐 데이터에 직접 액세스하여 '이유'를 이해하고 싶어합니다.
이러한 비즈니스 사용자에게 가장 쉬운 방법은 자연어를 사용하여 해당 산업에 특정한 뉘앙스와 기술 전문 용어를 사용하여 풍부한 맥락에 대한 생각을 전달하고 제공하는 것입니다. 이것이 사용자가 여러 데이터베이스의 데이터와 대화하고 탐색할 수 있도록 AI 에이전트가 개발되는 이유입니다.
오늘날 Text-to-SQL 에이전트의 문제점
데이터베이스와 대화한다는 것은 에이전트가 자연어 질문을 번역하고 PostgreSQL, Oracle, Snowflake, Databricks, BigQuery, Azure Fabric 등을 통해 SQL을 사용하여 데이터를 쿼리한다는 의미입니다.
표준 접근 방식: LLM에 모든 테이블/열 메타데이터가 포함된 포괄적인 YAML(또는 Markdown) 파일을 제공하거나 의미론적 유사성에 대한 벡터 기반의 동등한 파일, SKILL 및 쿼리를 안내하는 추가 비즈니스 설명을 제공합니다.
기본적인 질문에 효과가 있고 데모를 통해 쉽게 '와우' 효과를 제공할 수 있지만 몇 가지 문제점이 있습니다.
높은 토큰 비용: 요청마다 큰 부분 또는 전체 스키마가 전송됩니다.
상황에 따른 소음:관련 없는 테이블은 정확성을 저하시키고 환각을 유발합니다.
정적 제한사항:플랫 파일은 사용 패턴, 사전 또는 비즈니스 의미가 발전함에 따라 유지 관리하기가 어렵습니다. 지속적인 유지가 없으면 시간이 지남에 따라 에이전트의 성능이 저하됩니다.
Neo4j 의미 계층 접근 방식
Neo4j 의미 계층은 다음을 사용하여 GraphRAG 접근 방식을 도입합니다.동적 의미 계층으로서의 Neo4j. 선형 텍스트 파일에서 지식 그래프로 이동하면 에이전트는 모든 메타데이터 '읽기'를 중지하고 데이터 아키텍처를 지능적으로 '탐색'하기 시작합니다.
의미 계층의 스마트 그래프 모델
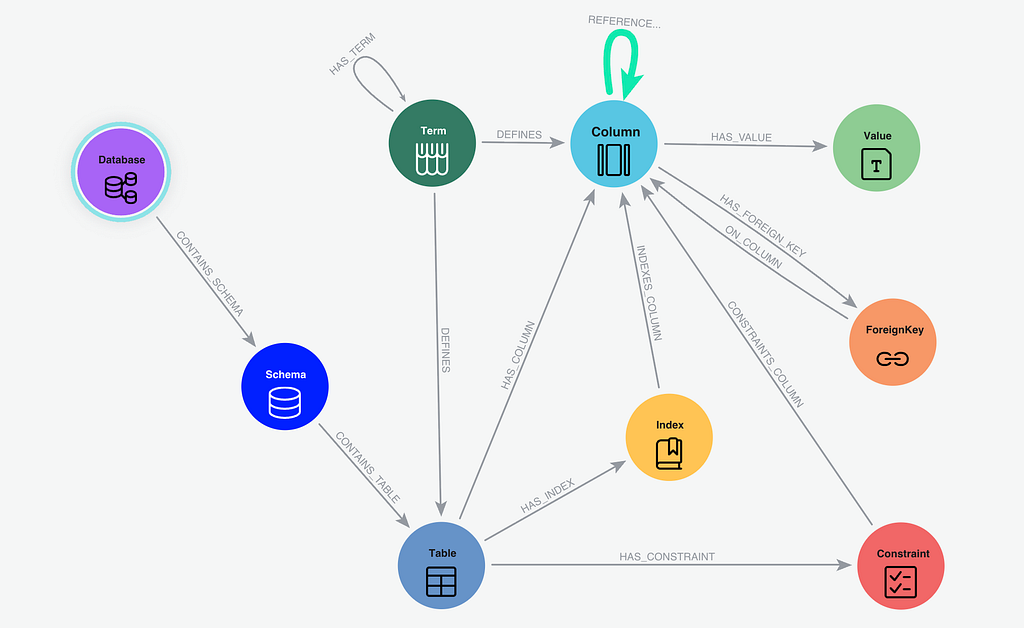
의미 계층에는 무엇이 저장되나요? 외과적 정밀도로 LLM을 기반으로 하고 유효한 SQL을 생성하기 위해 Neo4j 의미 계층은 다음을 저장합니다.
: 스키마, 테이블, 열, 유형.
: 외래 키 및 색인.
: 열의 특정 값 또는 몇 가지 예입니다.
: 도메인별 용어 및 정의와 기본 분류 구조
: 데이터베이스에서 외래 키로 지정되지 않은 RDBMS 트랜잭션 로그에서 조인합니다.
그리고 에이전트가 데이터베이스를 쿼리해야 할 때 에이전트는질문과 관련된 그래프 부분만, 의미 검색 + 그래프 순회(최단 경로)를 사용합니다.
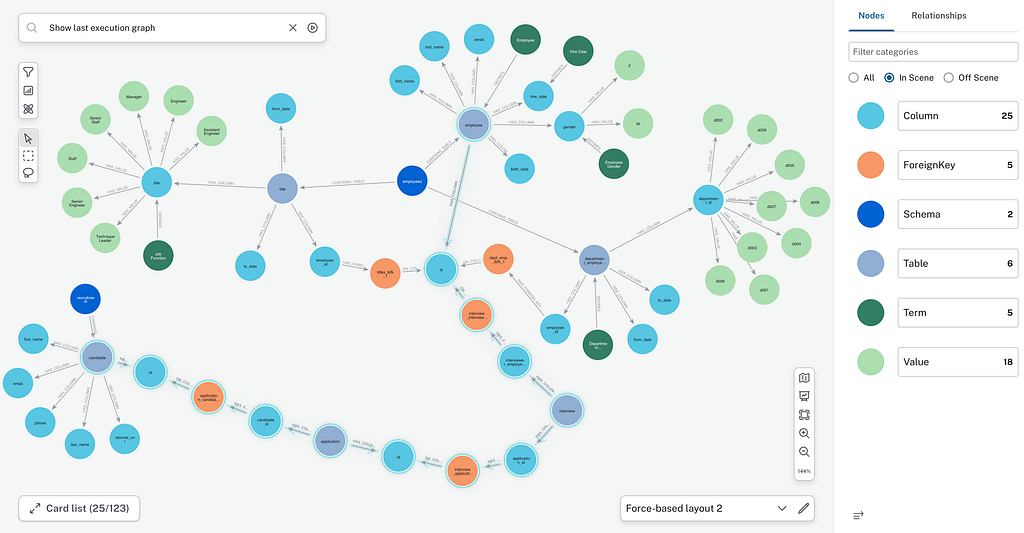
구체적인 예
벤치마크 애플리케이션
인사(HR) 샘플 데이터가 포함된 Text2SQL 벤치마크 애플리케이션
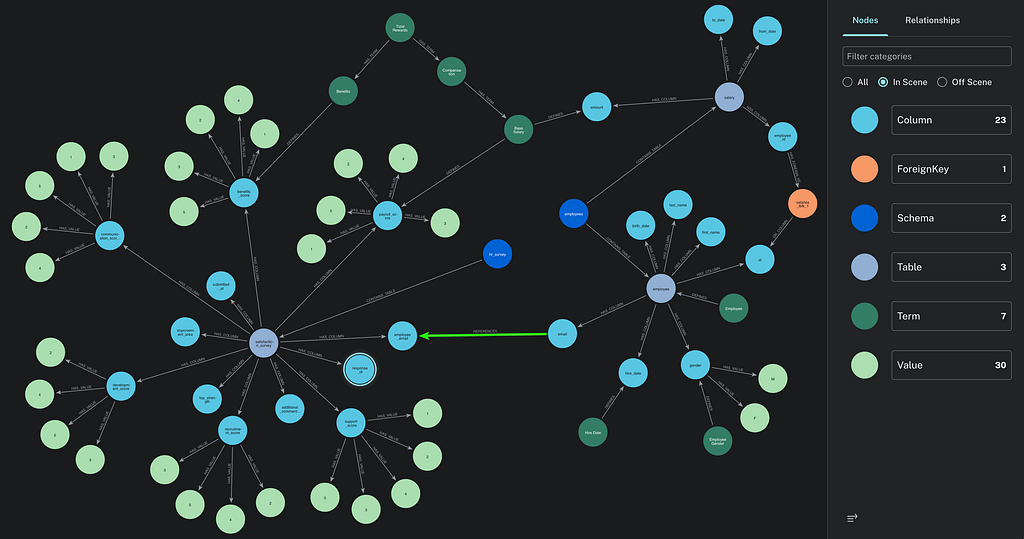
In 이 응용 프로그램, 동일한 Streamlit 애플리케이션에서 두 에이전트를 나란히 사용하여 두 가지 접근 방식을 검토하고 시험해 볼 수 있습니다.
YAML 에이전트: 호출할 때마다 전체 Database_schema.yaml(44KB, 테이블 ~50개)을 읽습니다.
Neo4j 의미 계층 에이전트: 그래프를 쿼리하여 관련 컨텍스트만 검색합니다.
2개의 에이전트는 스키마 검색 도구의 유일한 차이점을 제외하고 완전히 동일한 LangChain 에이전트 체인 및 도구 세트를 사용하고 있습니다. 불공정한 비교를 피하기 위해 yaml 파일에는 사용자 행동을 기반으로 한 중요한 조인(아래 그래프에서 볼 수 있는 이메일 간의 "REFERENCES" 녹색 관계)과 같이 의미 계층에 저장된 모든 주요 정보가 포함되어 있습니다. 상담사에게 대화 내역이 전송되지 않으므로 세션을 삭제하지 않고도 쉽게 결과를 비교할 수 있습니다.
직원 급여 및 관련 만족도에 대한 질문에 대해 상담원에게 제공되는 컨텍스트 그래프
이 애플리케이션은 Neo4j 및 에이전트 로직에 저장된 의미 계층의 의미 유사성 검색을 위해 OpenAI GPT(gpt-5.4-mini + text-embedding-3-small)를 사용하여 PostgreSQL 데이터베이스에 저장된 인사 데이터(가짜 공개 데이터 세트)를 쿼리합니다.
상담원에게 질문하기
애플리케이션에는 예상되는 SQL 쿼리를 기반으로 답변의 정확성을 확인하고 증가하는 복잡성을 다룰 수 있도록 HR 데이터에 대한 3가지 질문이 사전 연결되어 있습니다.
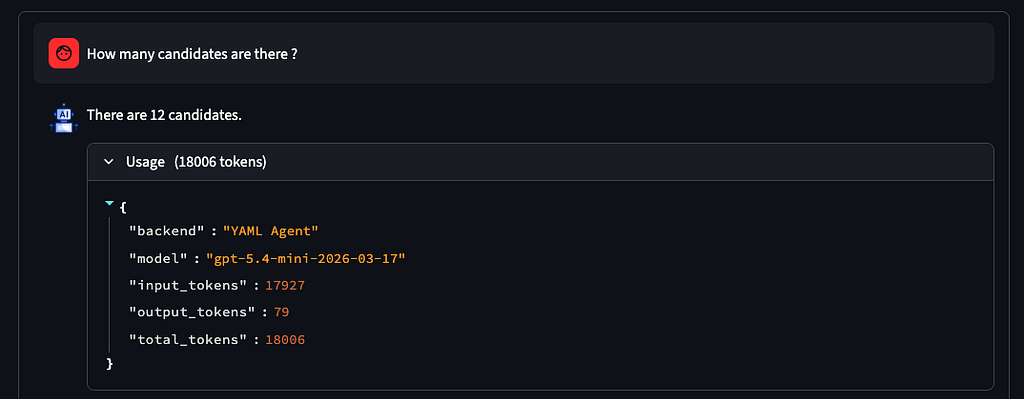
단순 카운트, 단일 테이블(“후보자는 몇 명이에요?”)
다중 테이블 조인 및 집계(“남성과 여성의 평균 급여와 만족도는 얼마입니까?”)
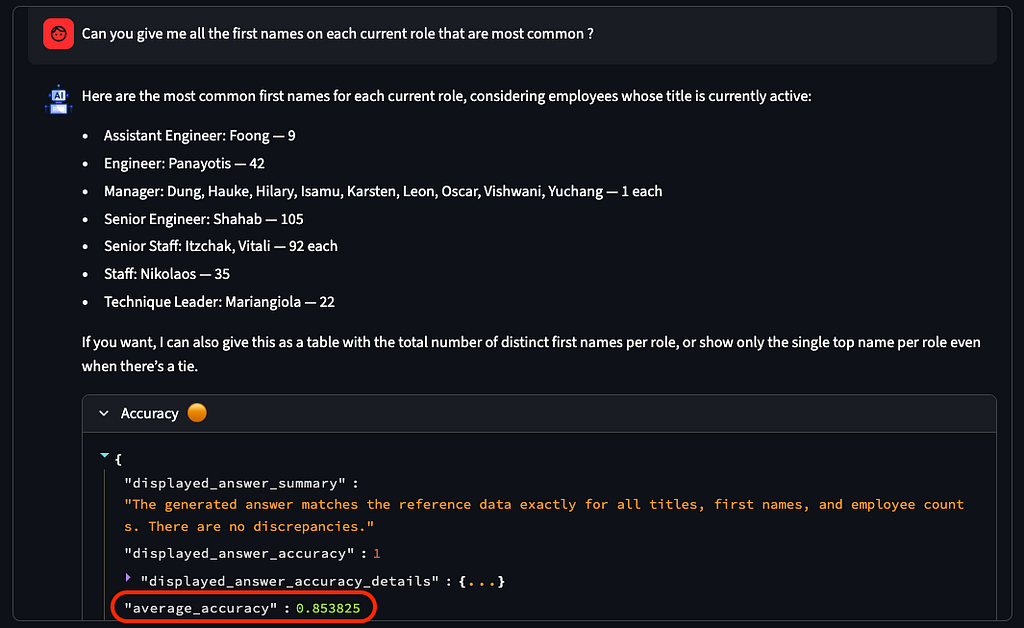
공통 테이블 표현식(CTE) + 창 함수(ROW_NUMBER()), 그룹화(“현재 각 역할에서 가장 흔한 이름은 무엇입니까?”)
YAML 에이전트의 정확성 및 비용
데모 애플리케이션(아래 스크린샷 참조)에서 에이전트의 기본 구성을 사용하면YAML 설명 사용, 일반적인 결과는 다음과 같습니다.
간단한 질문에 대한 100% 완벽한 정확성
다중 조인을 사용한 질문의 정확도 ~90%
중간 보기(CTE)가 필요한 질문에 대한 정확도 ~85%
YAML 에이전트의 평균 정확도(각각 10회 실행)
복잡한 질문에 대한 YAML 에이전트의 평균 정확도(각각 10회 실행)
비용과 관련하여 컨텍스트로 제공된 YAML 파일의 크기를 반영하는 안정적인 토큰 사용량(18,000개 토큰)을 볼 수 있습니다. 에이전트가 환각을 느끼는 상황에서 질문을 하면 비용이 급격히 증가할 수 있습니다. 컨텍스트를 너무 많이 추가하면 잘못된 SQL 쿼리가 생성될 위험이 높아지고 에이전트가 오류를 수정하기 위해 루프를 반복하고 토큰 소비가 늘어날 위험이 있습니다.
YAML 에이전트에서 사용하는 토큰
Neo4j 의미 계층 에이전트의 정확성 및 비용
데모 애플리케이션을 유지하면서 설정에서 Neo4j 의미 계층 에이전트로 전환하면 일반적으로 정확도가 향상됩니다.
간단한 질문의 경우 100% 정확도
다중 조인을 사용한 질문의 정확도 ~98%
중간 보기(CTE)가 필요한 질문에 대한 정확도 ~94%
의미 계층의 평균 정확도(각각 10회 실행)
비용과 관련하여 YAML 에이전트는 환각이 아닌 답변에 대해 거의 일정한 수의 토큰을 사용하는 반면 Neo4j 의미 계층은 질문의 복잡성에 따라 달라집니다.
간단한 질문에 토큰 최대 1,800개
다중 조인 관련 질문에 최대 5,000개의 토큰
중간 보기(CTE)가 필요한 질문에 대한 토큰 최대 7,300개
최단 경로를 사용하여 긴 테이블 조인 체인을 보여주는 컨텍스트 그래프
결과 분석 및 그래프가 복잡한 질문에 적합한 이유
간단한 질문의 경우 두 에이전트 모두 비슷한 성능을 발휘하지만 사용되는 토큰은 확실히 줄어듭니다. 평균적으로, 그리고 이 접근 방식을 사용하는 프로젝트 현장에서 수집한 내용을 통해 우리는 최소한의 결과를 확인했습니다.토큰 20~30% 감소YAML 파일(또는 다중 에이전트로 분산된 여러 YAML 파일)을 사용하는 정적 접근 방식과 비교됩니다.
복잡한 다중 테이블 쿼리의 경우Neo4j 에이전트는 훨씬 더 높은 정확도를 보여줍니다(이 데모에서는 +10% 포인트).컨텍스트 그래프의 관련 부분에만 초점을 맞추기 때문입니다. 이 이점은 더 큰 스키마(50~100개 이상의 테이블)와 쿼리에 여러 테이블 간의 조인이 포함될 때 증가합니다. 비즈니스 용어집, 관련 분류 및 예제 값을 사용하면 특히 업계의 특정 용어 및 비즈니스 복잡성을 정의할 때 의미 계층 신뢰성이 향상됩니다.
제공된 정보에는 조인 경로가 포함됩니다. 이러한 조인 경로는 데이터베이스(외래 키)의 기술 메타데이터를 사용합니다.또한 데이터 엔지니어/분석가의 행동에서 지속적으로 업데이트될 수 있는 외래 키로 선언되지 않은 사용 추론 조인도 있습니다.. 관계형 데이터베이스 트랜잭션 로그에서 추출된 이러한 행동 정보는 다음에서 가중치로 사용될 수 있습니다.경로 찾기 알고리즘가장 많이 사용되는 항목만 제안합니다.
이 조인("REFERENCES")은 PostgreSQL 트랜잭션 로그에서 2번 확인되었습니다.
Neo4j 의미 계층에 대한 심층 분석
토큰 감소와 정확성 향상은 LLM이 완벽한 SQL 쿼리를 생성하는 데 필요한 메타데이터를 찾는 것을 기반으로 합니다. 이는 3단계로 이루어집니다.
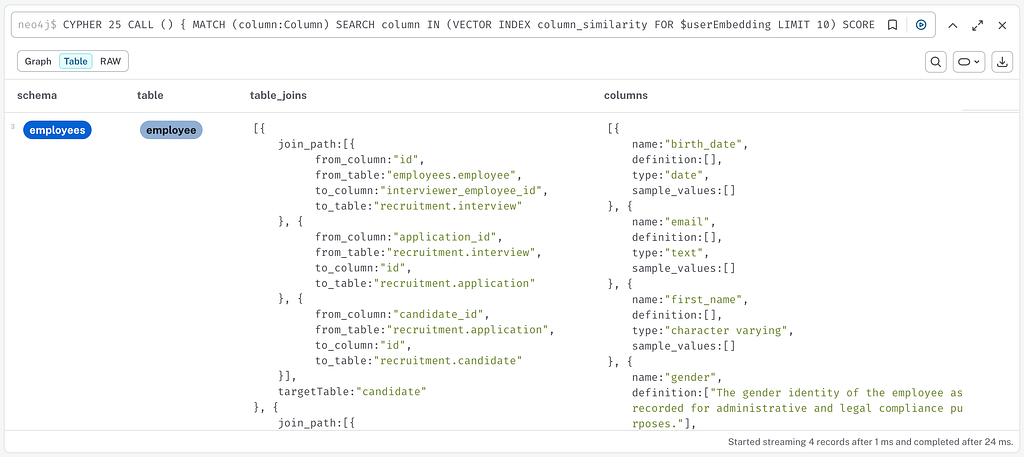
의미적 유사성을 사용하여 가장 유사한 용어와 열 및 관련 테이블을 찾습니다.
MATCH (column:Column)
SEARCH column IN (VECTOR INDEX column_similarity
FOR $userEmbedding LIMIT 10) SCORE as score
WHERE score>$threshold
RETURN DISTINCT column
UNION
MATCH (entryTerm:Term)
SEARCH entryTerm IN (VECTOR INDEX term_similarity FOR $userEmbedding LIMIT 10) SCORE as score
WHERE score>$threshold-0.1
MATCH (entryTerm)-[:HAS_TERM*0..]->(:Term)-[:DEFINES|HAS_COLUMN*1..2]->(column:Column)
RETURN DISTINCT column
2. 식별된 테이블 사이에서 가능한 모든 조인을 찾습니다.
WITH collect(DISTINCT column) as columns
UNWIND columns as sourceColumn
UNWIND columns as targetColumn
WITH sourceColumn, targetColumn
OPTIONAL MATCH links = SHORTEST 1
(sourceTable:Table {name:sourceColumn.tableName})
(()-[:HAS_COLUMN|HAS_FOREIGN_KEY|ON_COLUMN|REFERENCES]-(x)){0,16}
(targetTable:Table {name:targetColumn.tableName})
3. 추가 컨텍스트 수집
WITH DISTINCT sourceColumn as columnSimilarity, links
MATCH (table:Table)-[:HAS_COLUMN]->(columnSimilarity:Column)
MATCH p=(:Schema)-[:CONTAINS_TABLE]->(table)-[:HAS_COLUMN]->(column:Column)
OPTIONAL MATCH termCol = (:Term)-[:HAS_TERM*0..]->(:Term)-[:DEFINES]->(column)
OPTIONAL MATCH termTable = (:Term)-[:HAS_TERM*0..]->(:Term)-[:DEFINES]->(table)
OPTIONAL MATCH values = (column)-[:HAS_VALUE]->(:Value)
그러면 테이블 정보와 테이블 간의 가능한 조인이 포함된 결과가 JSON 형식으로 단 몇 ms 만에 상담사에게 제공될 수 있습니다.
코딩 에이전트(커서, VS Code…)에서 데모 코드 폴더를 열고 모든 작업을 수행하도록 요청합니다. Init는 인터넷에서 HR 데이터세트를 다운로드하고 PostgreSQL 및 Neo4j에 데이터를 로드합니다.
Can you look at the README.md and run this application in a virtual python 3.13.3 environment ?
The application must reach openAI api on the internet, so don't configure proxy blocking internet access.
* I have installed locally PostgreSQL with database postgres and no password
* I have installed locally Neo4j with password text2sql
* You should have the openAI key in your env context
내장된 예시를 뛰어넘으세요
미리 연결된 세 가지 질문은 증가하는 SQL 복잡성을 다루지만 이에 국한되지는 않습니다. 설정 옆에 있는 버튼을 사용하여 다음을 입력할 수 있는 대화상자를 열어 자신만의 테스트 사례를 정의할 수 있습니다.
자연어 관련 질문
예상되는 정답을 나타내는 참조 SQL
비교 지침(검사기가 결과를 확인하기 위해 사용하는 열)
귀하의 질문이 목록에 나타나고 정확성 검사가 자동으로 실행됩니다. 이를 통해 자신의 시나리오에서 나온 질문에 대해 두 상담원을 모두 벤치마킹할 수 있습니다.
더 나아가기: 그래프 데이터 과학, 플러그 앤 플레이 MCP
Neo4j 의미 계층의 주요 장점 중 하나는 기본 설정으로도 견고한 결과를 제공하는 동시에 특히 그래프 데이터 과학(GDS)을 통해 상당한 개선 여지를 남겨둔다는 것입니다.
가중치를 사용한 경로 찾기: 트랜잭션 로그에서 조인이 실행된 횟수를 'REFERENCES' 에지에 대한 가중치로 사용하여 트래픽이 많은 조인을 선호합니다.경로 찾기 알고리즘
엔터티 해결: use 약하게 연결된 구성요소(WCC) and K-최근접이웃(KNN)구조화되지 않은 비즈니스 문서에서 추출된 항목에 대해 동의어를 비즈니스 용어집 용어에 자동 연결합니다.
: 각 비즈니스 사용자가 액세스할 수 있는 데이터만 그래프 컨텍스트에 반영되도록 사용자 그룹 액세스 제어를 포함합니다.
비즈니스 프로세스 강화: 데이터 흐름을 그래프 경로로 모델링하여 프로세스 수준 질문에 답합니다.
: 에이전트는 의미 계층에서 대화 기록과 사용자 피드백을 캡처하여 시간이 지남에 따라 더 높은 품질의 SQL 쿼리를 생성할 수 있습니다. (에이전트 지속적인 개선)
가속기로서 의미 체계 계층은 플러그 앤 플레이 MCP 서버를 갖춘 프로젝트 Neocarta에서 사용할 수 있습니다.
관계형 데이터베이스에 대한 자연어 쿼리는 이제 주요 플랫폼 전반에 걸쳐 표준이 되었습니다. 데모와 프로덕션 시스템을 구분하는 것은 제공하는 컨텍스트입니다.
전통적인 플랫 파일 또는 벡터 기반 접근 방식은 스키마 문서를 컨텍스트 창에 덤프할 텍스트 덩어리로 취급합니다. 이로 인해 프롬프트가 지나치게 커지고, API 비용이 높아지며, 의미 있는 추론이 시작되기도 전에 관련 없는 테이블 정의로 인해 LLM의 부담이 커집니다.
Neo4j 의미 계층은 접근 방식을 근본적으로 바꿉니다. 에이전트에게 모든 것을 제공하고 에이전트가 알아낼 것이라고 기대하는 대신, 질문에 답하는 데 필요한 것, 즉 관련 테이블, 열, 조인 경로 및 비즈니스 용어에 대한 정확한 실시간 하위 그래프만 제공합니다. 결과는 분명합니다. 특히 구조적 맥락과 비즈니스 맥락이 모두 필요한 복잡한 다중 테이블 질문의 경우 모든 쿼리에서 토큰 사용량이 낮아지고 정확도가 훨씬 높아졌습니다.
그래프는 또한 YAML 파일이 근본적으로 포착할 수 없는 것, 즉 데이터가 실제로 사용되는 방식을 포착합니다. 트랜잭션 로그에서 채굴된 패턴, 모호한 언어를 해결하는 비즈니스 용어집, 이론적인 경로보다 검증된 경로를 선호하는 사용량 가중치 관계 등을 조인하세요. 이는 데이터 생태계의 역동적이고 살아 있는 속성이며, 지식 그래프는 이를 모델링하는 데 적합한 도구입니다.
LLM에는 더 큰 컨텍스트 창이 필요하지 않습니다. 더 나은 지도, 즉 그래프 기반 지도가 필요합니다.
그래프RAG
텍스트-SQL
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
몇 년 동안 글로벌 제약 및 생명 과학 커뮤니티를 모아서 그래프 기술이 데이터 문제를 해결하는 데 어떻게 도움이 되는지 논의했는데요. 올해 행사는 실용화에 중점을 두었어요. Knowledge Graph, GraphRAG, 그리고 GenAI를 생명 과학 및 의료 분야에 적용하는 방법에 대해서 말이죠.
이번 행사에는 제약 및 생명공학 분야의 기술 리더, 개발자, 데이터 과학자들이 한자리에 모였답니다. 참석자들은 아이디어를 교환하고, 생산 가능한 그래프 아키텍처를 탐색하고, Neo4j를 사용해서 R&D 지식 관리부터 정밀 의학 및 신약 개발에 이르기까지 업계에서 가장 시급한 데이터 문제들을 해결하는 방법을 공유했어요.
혹시 이벤트를 놓치셨나요? 모든 세션을 지금 바로 보실 수 있어요.
실제 그래프 통찰의 하루
하루 종일 발표자들은 그래프 기반 접근 방식이 어떻게 복잡한 생물의학 데이터에 대한 구조화되고 설명 가능하며 확장 가능한 솔루션을 가능하게 하는지 강조했는데요. 볼만한 가치가 있는 4개의 뛰어난 세션이 있답니다.
Synaptix — 그래프 및 GenAI를 사용하여 R&D 지식 관리
Merck Group의 Natalie Romanov 님이 Synaptix 플랫폼이 전임상 연구, 임상 개발, 규제 운영 전반에 걸쳐 단편화된 지식을 연결하는 방법을 공유했어요. Neo4j를 사용해서 약물 용도 변경부터 경쟁력 있는 인텔리전스까지 분석 및 에이전트 GenAI 워크플로를 모두 지원하는 그래프 생태계를 구축했다고 해요. 구조화된 그래프 모델과 생성 인터페이스를 결합해서 상황에 맞는 AI 증강 통찰력을 제공하는 이중 플랫폼 전략의 대표적인 예시라고 할 수 있죠.
밤을 통해 빛으로: Noctis로 화학 반응 데이터 탐색
Syngenta의 Nataliya Lopanitsyna 님이 발표를 맡았는데요. 이 세션에서 Syngenta는 단 3줄의 Python 코드로 문헌, 특허, 고처리량 스크린의 데이터를 쿼리 가능한 Knowledge Graph로 바꾸는 오픈 소스 툴킷인 NOCTIS를 소개했어요. 실험실 벤치부터 데이터 레이크, 그래프까지 전체 파이프라인을 살펴보면서 그래프 기반 표현이 어떻게 합성 경로 계획을 가속화하고 기존 시스템이 종종 놓치는 패턴을 찾아내는지 보여주었답니다.
프로젝트 AMIGO: 유전적 발견을 표적 치료법으로 전환
LMU Klinikum의 Nicola Götzenberger 님과 Daniel Weiss 님이 발표를 맡았어요. 프로젝트 AMIGO는 희귀 질환을 앓고 있는 어린이의 진단 및 치료를 가속화하기 위한 야심 찬 연합 데이터 이니셔티브라고 해요. Care-for-Rare 재단은 소아과 진료소 전반의 Knowledge Graph와 보안 데이터 협업을 통해 어떻게 진단 일정을 단축하고 표적 치료를 활성화하며 질병 진행에 대한 실시간 통찰력을 지원할 수 있는지 보여주었는데요. 정밀 의학을 통해 삶을 개선하는 그래프 기술의 강력한 사용 사례라고 할 수 있겠죠?
그래프 접근법을 사용한 개인 수준 데이터 통합
바이엘 AG의 Mahmoud Ibrahim님이 발표자로 참여하여, 그래프 모델을 활용한 환자 중심 데이터 통합 접근 방식에 대해 이야기했어요. "환자 지도"를 구축해서 다양한 임상 및 분자 데이터 세트를 연결하고, 질병 메커니즘을 더 깊이 이해하고 새로운 치료 가설을 찾아내서 임상 시험 성공률을 높이는 거죠. R&D에서 더 현명한 의사 결정을 지원하기 위해 그래프 임베딩과 증거 체인을 사용하는 방법도 살펴봤다고 해요.
요약
RDF에서 LPG로의 마이그레이션, GraphRAG 인프라에 대한 논의, 그리고 제약 공급망 및 생물의학 발견 데모까지! GraphTalk 2025에서는 통합 그래프 기술이 생명과학 분야에서 어떻게 AI 기반 혁신으로 발전했는지 제대로 보여줬어요.
더 자세한 내용이 궁금하다면 필수 GraphRAG를 확인해보세요. GraphRAG 시스템을 처음부터 구축하는 방법에 대한 Manning의 종합 가이드랍니다.
GraphRAG
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
2021년 6월 24일, Gothamist의 George Joseph은 다음과 같은 제목의 작품을 발표했어요. "반복적으로 위법 행위로 기소된 뉴욕 경찰국(NYPD) 경찰관 집단을 매핑합니다."
독립 데이터 저널리스트인 EJ Fox와 함께 Joseph은 논란의 여지가 있는 경찰 행위가 집단 행동인 경우가 많다는 사실을 자세히 설명했는데요. 이 기사는 2010년 이후 불만 사항과 관련된 경찰관의 탐색 가능한 시각화 및 지도를 보여줬습니다.
전 75경찰서 로버트 마르티네즈 상사와 연결된 일부 officer `Node`의 클로즈업 이미지
이 글은 복잡한 사회 현상을 인사이트로 이끌어내고, 현실 세계에서 계속해서 일어나고 있는 숨겨진 패턴을 지적했다는 점에서 주목할 만해요. 위법 행위에 대해 불만을 제기하는 패턴이 있는 것으로 보이는 특정 주요 경찰관을 조사하면서 Joseph은 체포 시 금지된 목을 조르는 방법을 사용하는 것이 카메라에 포착된 후 최근 은퇴한 한 경찰관과 같은 많은 두드러진 사례를 발견했습니다.
여기서 그래프가 효과적인 이유
이 시점에서 이 분석에 Neo4j가 많이 사용되었다는 것은 놀라운 일이 아니죠? `Relationship`에서 패턴을 찾는 것은 그래프의 장점 중 하나이니까요. 그래프는 진정으로 "관계에 관한 모든 것"이며 이와 같은 사례는 경찰관, 불만 사항, 시민 등 간의 `Relationship`이 개별 불만 사항이나 경찰관 기록보다 더 중요한 상황이에요.
데이터의 연결은 데이터 자체만큼 가치가 있어요.
이 팀이 어떻게 작업을 수행했는지 궁금하시다면 EJ Fox가 분석에 대한 훌륭한 기술 분석을 작성했으니 한번 살펴볼까요? 여기에서 Fox는 다음과 같이 설명합니다.
그의 데이터는 무엇이었나요?
Cypher의 LOAD CSV 접근 방식을 사용하여 데이터를 가져오는 방법
그가 입증된 시민 불만을 경찰관과 연결한 방법
그가 officer들 사이의 `Relationship`을 구축한 방법.
기술적인 설명은 EJ의 탁월한 기술 분석에 맡기겠지만, 여기서 실제로 모든 것을 하나로 묶어주는 "비밀 소스"는 Neo4j의 Graph Data Science 라이브러리, 특히 EigenVector Centrality의 사용이었어요. 이 특정 알고리즘은 그래프에서 특정 Node의 영향을 측정하는데, EJ의 경우, 반복적으로 불만을 제기하는 경찰관과 밀접하게 관련된(또는 함께 협력하는) 반복적으로 불만을 제기하는 경찰관을 찾는 데 도움이 되죠.
Neo4j 그래프 데이터 과학은 요즘 그래프 작업에 대한 가장 흥미로운 것 중 하나인데요. EigenVector Centrality는 데이터 과학자, 분석가, 심지어 데이터 저널리스트가 데이터에서 통찰력을 끌어낼 수 있는 50개 이상의 "도구 상자에 포함된 도구" 중 하나일 뿐이에요. 이는 데이터 과학에 대한 "그래프 작성"을 주도하고 있으며 이미 많은 고객이 독일 당뇨병 연구 센터의 연구 데이터베이스를 연결하고 금융 사기를 적발하는 데 사용하고 있답니다.
Graphs4Good
Gothamist의 기사는 Neo4j가 이런 종류의 프로젝트에 사용된 것이 처음이 아니라는 것을 보여주죠. 몇 년 전 우리는 데이터로 작업하는 사람들을 연결하고 활성화하여 더 효과적으로 작업할 수 있도록 Graphs4Good 프로젝트를 시작했어요. 데이터 저널리즘 분야에서 Neo4j는 이전에 숨겨진 조세 피난처를 찾아내고, 소셜 미디어에서 선거 조작의 패턴을 탐지하고, NASA가 과거 임무에 대한 집단적 지식을 학습하도록 도움으로써 납세자의 세금을 절약하는 데 사용되었답니다.
Neo4j는 핑크 프로그래밍을 후원하고 커뮤니티에 참여하여 여성이 기술 부문에서 크게 소외된 그룹으로 발전할 수 있도록 돕습니다.
그리고 우리는 실제 데이터에서 연결을 발견하는 데 도움이 되는 프로젝트에 대해 열려 있어요. Neo4j 데이터 저널리즘 액셀러레이터 프로그램을 통해 EJ와 같은 데이터 저널리스트는 우리 주변에서 발견되는 실제 네트워크를 푸는 데 도움을 받을 수 있죠.
다음은 무엇일까요?
기술 전문가로서 저는 이 분석에 포함된 모든 사항과 이것이 기본 Graph Database인 Neo4j가 갖는 기술 강점과 어떻게 연결되는지 설명하고 싶어요. EJ Fox의 기사가 이 내용을 너무 잘 다루고 있기 때문에 이 게시물에서는 맛보기만 했을 뿐이죠.
그리고 기술 심층 분석에서는 나무 대신 숲을 잃을 위험이 항상 존재해요. 그래프 데이터 사이언스로 할 수 있는 강력하고 멋진 일이 많이 있지만, 이 게시물에서는 큰 그림에 주목하고 싶었어요. 그래프 기술은 근본적으로 저널리스트가 현실 세계에 대한 통찰력을 발견할 수 있도록 하며, 그래프 유틸리티는 우리가 세상을 더 잘 이해하는 데 기여하죠. 사람들이 이를 개선하기 위한 조치를 취하는 방법을 이해하는 데 도움이 될 수도 있고요.
그래프에 대해 궁금하신 점이 있으시면 알려주세요. 신용 카드 없이 클라우드에서 Neo4j AuraDB를 무료로 사용할 수 있어요. 또는 Neo4j 커뮤니티 사이트를 확인해 보세요. Cypher, GDS 및 모든 종류의 기타 기술을 사용하여 모든 산업 및 사용 사례에 걸쳐 여기에서 볼 수 있는 것과 동일한 작업을 수행하는 사람들로 구성된 크고 활발한 커뮤니티를 찾을 수 있을 거예요.
즐거운 그래프 해킹을 즐겨보세요!
EJ폭스
GraphsforGood
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
2000년에 저는 뭄바이행 비행기를 타고 있었어요. Peter, Johan과 저는 엔터프라이즈 콘텐츠 관리 시스템(ECM)을 구축하고 있었는데, 연결된 데이터를 `Query`하기 위해 RDBMS를 사용하는 문제에 계속 부딪혔죠.
그때 번뜩이는 아이디어가 떠올랐어요! 냅킨을 꺼내서 첫 번째 `Property Graph` 모델을 빠르게 스케치했죠. 저희는 함께 냅킨에 그린 아이디어를 바탕으로 세계 최초의 `Graph Database`인 Neo4j를 만들었어요.
제가 상상도 못 했던 건 냅킨 뒷면에 끄적거린 작은 스케치가 전 세계에 미칠 엄청난 영향력이었어요. 물론 비즈니스적으로도 큰 영향을 줬지만, 수익을 떠나 꾸준히 성장해 왔고, 지금도 조용히 영향력을 행사하고 있죠.
Neo4j 커뮤니티 전체적으로 보면, `Graph` 기술을 활용해서 기후 변화, 암 치료, 여성 역량 강화, 돈세탁 방지, 그리고 인간 지식의 한계를 넓히는 등 사회의 가장 시급한 문제들을 해결해 왔어요.
비영리 단체, 정부 기관, 뉴스룸, 연구소 등 어떤 곳에서 일하든, 세상을 더 나은 곳으로 만들기 위해 엄청난 시간을 쏟는 분들이 계세요. 때로는 개인이기도 하고, 서로 다른 글로벌 팀이기도 하지만, 모두 제한된 리소스와 빠듯한 예산 때문에 힘든 싸움을 하고 있죠.
그럼에도 불구하고, 그들은 그림자 속에 숨겨진 연결고리를 조사하고, 복잡하게 얽힌 불법 행위의 그물을 풀고, 인체에 큰 피해를 주는 분자를 모델링하고 (치료하는 분자와 함께!), 별까지의 경로를 매핑하는 등의 놀라운 일들을 계속 해내고 있어요.
여기저기서 그들의 프로젝트에 대한 이야기를 들어보셨을 수도 있지만, 전체적으로는 잘 알려지지 않았죠. 하지만 이제 변화가 있을 거예요.
Graphs4Good 소개
Neo4j의 회사 비전은 "세상이 데이터를 이해할 수 있도록 돕는 것"이에요. 하지만 `Graph Database` (및 기타 `Graph` 기술 제품)를 구축하는 건 그 비전을 현실로 만드는 과정의 일부일 뿐이죠.
저는 그 비전의 핵심은 데이터를 다루는 사람들을 연결하고 활성화해서 더 효과적으로 일할 수 있도록 돕는 거라고 믿어요. 그래서 저희가 그래프4굿 프로그램을 만들었어요.
이 새로운 프로그램의 목표는 긍정적인 사회 변화에 영향을 미치고, 민주주의 원칙을 지키며, 세계에서 가장 어려운 과제를 해결하는 그래프 기반 프로젝트를 소개하고, 다른 사람들을 지원하고 격려하며 연결하는 것이에요.
오늘 Graphs4Good을 공식적으로 출시하면서(GraphConnect 2018에서), 이러한 프로젝트의 성공과 Neo4j가 제공한 지원은 이미 수년 동안 진행되어 왔다는 것을 알 수 있었어요. 그들의 이야기를 한번 들어볼까요?
데이터 저널리즘의 Graphs4Good
이 모든 것은 국제탐사보도언론인협회(ICIJ)에서 시작돼요. 2015년에 그들은 Neo4j와 그래프 시각화 도구인 Linkurious를 사용하여 획기적인 작업을 시작했죠. 바로 스위스 누출 이야기인데요, 스위스 프라이빗 뱅킹의 비밀스럽고 그늘진 세계를 살펴보는 내용이었어요.
거기서부터 그들은 역사상 최대 규모의 데이터 유출로 세상을 뒤흔들었어요. 바로 파나마 페이퍼스죠! 파나마 법률 회사인 모색 폰세카(Mossack Fonseca)에서 약 2.6테라바이트에 달하는 1,150만 개의 문서가 유출되면서 40년 동안의 거래, 계정 및 세계 유명 기업의 페이퍼 컴퍼니의 복잡한 웹이 기록되었어요.
후속 보고에서는 45개 이상 국가의 국가 지도자와 유명인사들의 사기, 탈세, 돈세탁, 국제 제재 회피(기타 불법 활동 포함)가 드러났어요. 종합하면, 25개 언어로 활동하는 100개 언론 매체의 기자들은 유출된 문서를 이용해 부패를 폭로했답니다.
그들의 노력은 결국 그들에게 퓰리처상을 안겨주었죠. 하지만 이 중 어느 것도 불가능했을 거예요. 연결된 데이터에 대한 액세스 가능한 모델이 없었다면요.
1년 뒤 ICIJ는 파라다이스 페이퍼 보고서를 발표했어요. Appleby 및 Asiaciti Trust에서 1,350만 개의 문서, 1.4테라바이트가 유출되었죠. 380명이 넘는 언론인들이 이번 유출을 이용해 애플, 나이키, 페이스북 등 유명 기업과 엘리자베스 여왕, 트럼프 행정부 등 국가 원수들의 불법 행위(불법, 비윤리 또는 둘 다)를 폭로했답니다.
이와 같은 데이터 저널리즘 조사가 있었기에 계속되는 가짜뉴스 확산에 맞설 수 있었죠. 이는 Neo4j 팀이 Neo4j connected data 펠로우십을 통해 ICIJ에 대한 지원을 계속할 뿐만 아니라 Neo4j 데이터 저널리즘 액셀러레이터 프로그램을 만들게 된 계기가 되었어요.
이런 멋진 프로젝트 이후에도 ICIJ는 꾸준히 좋은 활동을 이어오고 있어요. 서아프리카 누출 사건이나, 파나마 페이퍼스의 두 번째 유출 (규모는 작았지만)에서 Mossack Fonseca를 파헤친 것도 정말 대단하죠.
데이터 저널리즘 분야에서 NBC News 팀이 러시아 트롤 트윗 20만 건 사이의 복잡한 연결 관계를 매핑한 훌륭한 작업도 빼놓을 수 없어요.
이런 작업들이 바로 Graphs4Good 프로그램이 계속해서 소개하고 지원하고 싶은 활동의 핵심이에요. 하지만 데이터 저널리즘만이 그래프 기술이 긍정적인 영향을 미치는 유일한 분야는 아니랍니다.
다른 분야의 Graphs4Good
제가 그래프 기술 기반의 영향력 있는 프로젝트들을 전부 다 요약할 수 있을까요? 당연히 불가능하죠! 여기 소개하는 건 여러분이 알 만한 몇 가지 주요 사례일 뿐이에요. 더 많은 내용은 Graphs4Good 프로그램 페이지에서 확인해 보세요.
인류 역사가 시작된 이래로 우리는 질병과 싸워왔고, 이미 꽤 많은 치명적인 질병들을 이겨냈죠. 하지만 특히 암과의 싸움은 아직 갈 길이 멀어요. 저는 개인적으로 암 치료법을 연구하는 다양한 그래프 기반 프로젝트를 **8개**나 알고 있답니다. 그중에서도 정말 인상적인 이야기는 Candiolo 암 연구소 사례인데요, 꼭 한번 읽어보시길 추천드려요.
비슷한 맥락에서 독일 당뇨병 연구 센터(DZD)가 Neo4j를 사용해서 현재 당뇨병 환자들을 돕고, 이 질병을 완전히 없애기 위한 복잡한 연구를 진행하고 있다는 소식도 정말 기뻤어요.
전혀 다른 분야로 눈을 돌려볼까요? NASA는 Neo4j Knowledge Graph를 사용해서 화성 탐사 임무를 진행하고 있다고 해요.
NASA의 수석 지식 설계자인 David Meza는 이렇게 말했어요. 특히 Orion 우주선 임무와 관련해서 "Neo4j는 2년 이상의 작업 시간과 백만 달러의 세금을 절약해 줬습니다." 이 정도면 정말 *good*을 넘어선 훌륭한 성과라고 생각하지 않으세요?
과학적 탐구와 같은 맥락에서 국제 연어 데이터 연구소(2018년 10월 공식 출범)도 Graphs4Good 프로그램에 참여하게 되어 정말 기뻐요. 이들은 전 세계 연어 서식지에 대한 전체적인 분석과 생태학적 영향 연구를 지원하고 있답니다.
마지막으로, 긍정적인 영향을 미치는 그래프 프로젝트에 대한 *아주 간략한* 요약에서 지금은 사소해 보일 수 있지만 앞으로 몇 년 동안 그 파급력이 느껴질 만한 이야기를 빼놓을 수 없죠.
지난 여름 Neo4j 팀원들은 데이터 과학 캠프를 후원하고 이끌었어요. Pink Programming이라는, 기술 분야에서 여성의 역할을 발전시키는 것을 목표로 하는 단체를 통해서요. 올해 캠프는 규모가 작았지만(여성 20명), 참가자들은 그래프 기술을 사용해서 데이터 과학 기술을 키우는 방법을 배울 수 있었답니다. 20년 후, 이 여성들이 앞으로 수십 년 동안 기술 생태계에 어떤 긍정적인 영향을 미치게 될지 정말 기대돼요.
결론
그래프는 세상을 바라보는 새로운(사실은 오래된) 방식이고, 이 새로운 관점은 우리 사회를 더 나은 방향으로 변화시킬 수 있는 엄청난 힘을 가지고 있어요.
저는 매일 긍정적인 변화를 만들기 위해 그래프 기술이 어떻게 활용되고 있는지에 대한 이야기를 듣고 있어요. 그리고 Neo4j 커뮤니티가 세상을 변화시키는 모습에 늘 놀라움과 겸손함을 느껴요. Graphs4Good 프로그램의 많은 프로젝트는 커뮤니티 주도의 오픈 소스 프로젝트로 시작되었고, 또 계속해서 생겨나고 있답니다.
저는 이 점을 아무리 강조해도 지나치지 않다고 생각해요. Neo4j 커뮤니티는 여러분이 전 세계에 긍정적인 영향을 미칠 수 있도록 돕고 있거든요. 이 커뮤니티는 목적이 무엇이든, 그래프 기반 프로젝트를 시작하고 실행하는 데 (또는 원활하게 유지하는 데) 시간과 노력을 아낌없이 쏟는 친절하고 헌신적인 사람들로 이루어진 그래프 그 자체라고 할 수 있죠.
오늘 우리는 연결된 데이터를 사용하여 긍정적인 영향을 미치는 수백 가지 이야기를 담은 Graphs4Good 프로젝트를 시작해요. 내년에는 그 수가 수천 개가 되도록 만들어봐요.
우리 팀의 영향력은 냅킨에서 시작되었어요. 여러분의 작업은 그래프 플랫폼에서 시작될 거고요. 이걸로 무엇을 하시겠어요?
그래프4굿
icij
nasa
Neo4j 커뮤니티
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
편집자 주: 이 프레젠테이션은 Alexander Jarasch가 GraphConnect San Francisco 2016년 10월에 발표한 내용이에요.
프레젠테이션 요약
Alexander Jarasch는 독일 당뇨병 연구 센터의 데이터 및 지식 관리 책임자예요. Jarasch는 다양한 분석가들의 연구 결과를 통합하고, 이 정보를 활용해서 당뇨병을 더 효과적으로 예방하고 치료하는 데 힘쓰고 있다고 해요.
이번 프레젠테이션에서 Jarasch는 인간 당뇨병의 진화에 대해 이야기하는데요. 먼저 “당뇨병이 뭐죠?”라는 질문에 간단하게 답하고, 독일 당뇨병 연구 센터의 목표를 설명해요.
그리고 당뇨병 예방과 당뇨병에 효과적으로 대처하는 방법에 대해 소개하면서 데이터 문제를 짚어주죠.
독일 당뇨병 연구 센터가 가진 특별한 과제는 수많은 과학자와 연구자들이 각기 다른 관점에서 데이터를 바라본다는 점인데요. 이 모든 정보를 효율적으로 연결하고 통합해야 하죠. 이 데이터 수집에는 동종 데이터와 이종 데이터, 메타데이터 등이 포함돼요. 그래서 Graph Database를 선택한 건 정말 합리적인 결정이었죠.
프레젠테이션에서는 실제 사례를 통해 당뇨병의 대사적 특성을 설명하기도 해요.
마지막으로 Jarasch는 센터 연구에서 Graph Database의 미래에 대한 전망을 제시하며 마무리해요.
전체 프레젠테이션
안녕하세요, 저는 Alexander Jarasch입니다. 독일 당뇨병 연구 센터 뮌헨 본부에서 왔어요. 오늘은 저희가 어떻게 Graph Database와 그래프를 이용해서 당뇨병과 싸우고 있는지 이야기해 보려고 해요.
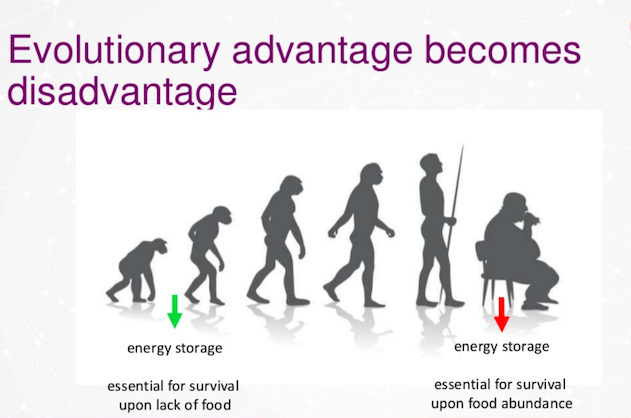
진화
공룡 시대, 슈퍼마켓이 없던 시절에는 에너지를 저장하는 유전적 이점이 있었어요. 음식이 부족할 때를 대비해서 에너지를 지방으로 저장했던 거죠.
하지만 이런 과거의 장점은 현대에는 단점이 되어버렸어요. 지금은 어디든 슈퍼마켓이 있고, 음식도 풍족하죠. 그런데도 우리는 여전히 많이 먹고, 지방은 계속 쌓여서 과체중이나 비만이 되기 쉬워요. 비만은 당뇨병을 유발하기 때문에 문제가 되는 거죠.
당뇨병이란 무엇입니까?
당뇨병은 대사 질환이에요. 어떤 경우에는 췌장에서 인슐린 생산이 급격히 줄어들기도 하고, 또 다른 경우에는 몸이 인슐린에 제대로 반응하지 못하기도 해요.
인슐린은 혈액에서 당분을 제거하는 데 필요한 호르몬이자 단백질인데요. 혈액에 당분이 많으면 근육 세포나 간 세포로 흡수되는 양이 줄어들어요. 혈관에 당분이 계속 남아있는 상태를 저혈당증이라고 부르죠.
당뇨병은 정말 무서운 합병증을 동반하고, 안타깝게도 현재로서는 완치가 불가능해요. 치료만 가능하다는 점이 아쉽죠.
당뇨병의 종류를 이야기할 때, 크게 네 가지 주요 유형이 있어요:
제1형 당뇨병
제2형 당뇨병
임신성 당뇨병 (임산부에게 나타나는 당뇨병)
현재 연구 중인 추가 형태
아래 오른쪽 그림은 건강한 신체의 모습이에요. 췌장에는 작은 녹색 점으로 표시된 인슐린을 생산하는 세포가 있죠. 위를 보면 설탕이 혈관으로 들어가는 걸 볼 수 있어요. 그러면 인슐린이 작용하게 되는데요. 모든 것이 제대로 작동하면 설탕이 간이나 근육 세포로 전달된답니다.
환자의 약 5%를 차지하는 제1형 당뇨병의 경우에는, 이 인슐린 생산 세포가 면역 체계에 의해 파괴돼요. 이 과정에는 대략 20개의 유전자가 관여한다고 해요. 이건 생활 방식과는 무관한 유전자 결함이라서, 환자들은 평생 동안 외부 인슐린 공급원에 의존해야 하죠.
제2형 당뇨병은 국가에 따라 환자의 약 90~95%를 차지할 정도로 흔해요. 세포는 인슐린을 생산하지만, 어떤 이유에서인지 인슐린 저항성이 생기는 거죠. 생산은 되지만 신체가 제대로 반응하지 않는 거예요. 일반적으로 사람들은 자신이 당뇨병을 앓고 있다는 사실을 잘 모르는 경우가 많아요. 이 과정에는 150개 이상의 유전자가 관여하며, 이는 당뇨병에 걸릴 위험을 증가시킨다고 해요.
당뇨병 진단을 부추기는 안 좋은 조합들이 있어요.
유전적 소인을 가지고 있는 경우
적절한 신체 활동이 부족한 경우
전 세계적으로 당뇨병을 앓고 있는 사람은 4억 명이 넘는다고 해요. 예전에는 노년층의 질병이라고 생각했지만, 실제로는 전체 환자의 3분의 2가 근로 연령대에 속해 있다는 사실!
게다가 진단을 받지 못한 당뇨병 환자가 2억 명이나 더 있다고 하니, 정말 심각한 문제죠. 당뇨병(대부분 1형 당뇨병)을 앓고 있는 어린이도 백만 명이 넘는다고 해요. 전체 의료 비용의 12%가 당뇨병으로 인해 발생한다니, 우리가 꼭 해결해야 할 심각한 문제임에 틀림없어요.
미국만 놓고 봐도 당뇨병 환자가 3천만 명이나 된다고 해요. 이 숫자는 매년 증가하고 있다니 걱정이에요. 당뇨병 전증 환자는 무려 8,500만 명에 달하며, 이로 인해 고통받는 사람들의 생산성 감소로 연간 900억 달러의 손실이 발생한다고 하네요.
1985년부터 2009년까지의 데이터를 요약한 차트인데요. 시간이 지날수록 점점 숫자가 늘어나고 있어서, 당뇨병에 걸리거나 비만으로 고통받는 사람들이 점점 더 많아지고 있다는 걸 알 수 있어요.
사실 당뇨병 자체보다는 합병증이 더 큰 문제예요. 사람들은 합병증 때문에 목숨을 잃는 경우가 많거든요. 뇌졸중이나 심장마비 같은 것들이죠. 모든 심장마비의 3분의 1은 당뇨병 때문에 발생한다고 해요. 사지의 신경이나 혈관이 손상되거나, 신장 문제, 심지어 당뇨병 때문에 발을 절단해야 하는 경우도 모두 당뇨병으로 인한 합병증이에요.
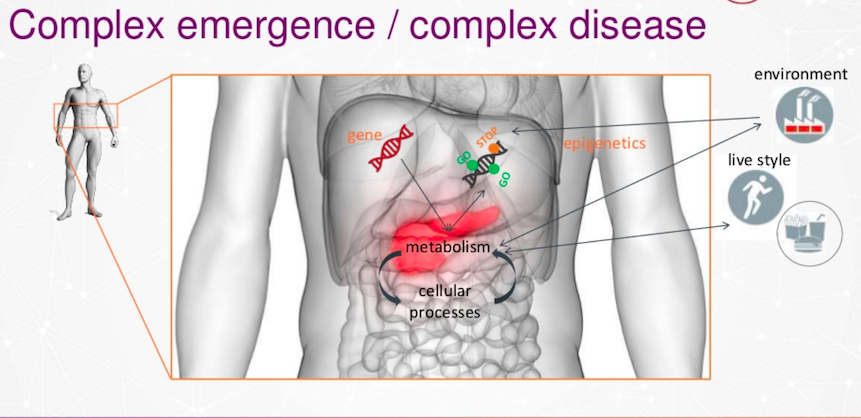
당뇨병은 정말 복잡한 질병이에요. 신진대사에 영향을 미치고, 췌장에도 영향을 주죠. 또한 환경이나 생활 방식, 유전학 또는 후생유전학에 따라서도 달라지는 세포 과정이기도 해요.
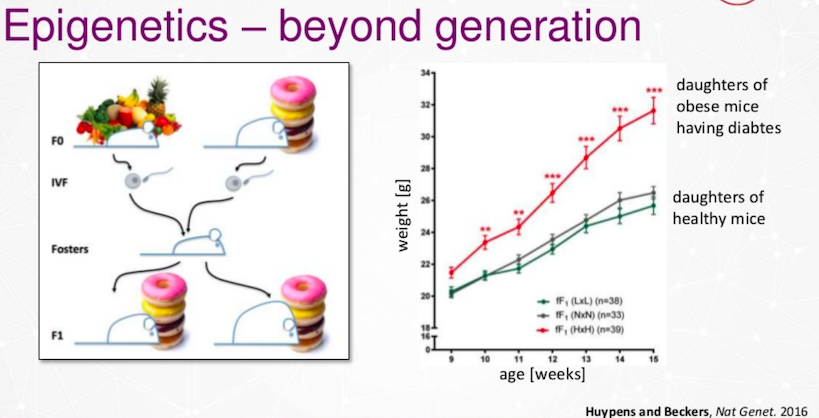
가장 큰 문제 중 하나는 환경과 생활 방식이에요. 여러분의 생활 방식은 다음 세대에게도 영향을 미치거든요. 쥐 실험이나 인간 쌍둥이 연구를 보면, 유전적으로 동일하더라도 DNA에 있는 후성유전학적 표지 때문에 차이가 나타나는 걸 알 수 있어요. 이로 인해 당뇨병이 발생하고, 심지어 다음 세대로까지 전이될 수 있다는 점이 정말 심각하죠.
저희 연구팀이 쥐를 대상으로 실험을 진행했어요. 일부 쥐에게는 정상적인 식단을, 다른 쥐에게는 고지방 식단을 제공했죠. 그런 다음 교배를 진행하고 그들의 자손을 관찰했는데요. 다음 세대는 과체중이 되었고, 이 과체중으로 인해 당뇨병 위험이 급격히 증가하는 것을 확인했어요.
우리는 누구인가
저희는 독일 당뇨병 연구 센터에요. 연방 기관이자 학술/비영리 조직이고요. 연방 교육 연구부와 주정부로부터 자금을 지원받고 있어요.
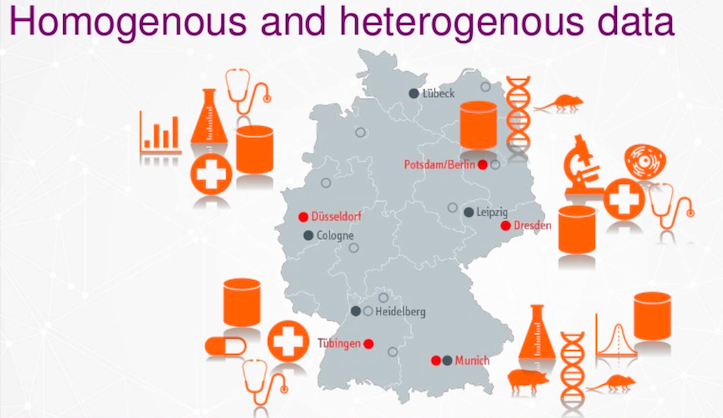
뮌헨, 튀빙겐, 뒤셀도르프, 베를린, 포츠담, 드레스덴에 5개의 주요 파트너가 있고, 관련 파트너를 포함해서 기초 연구부터 대학 병원까지 다양한 분야에서 약 400명의 연구원이 함께하고 있어요.
저희 연구 분야는 영양, 예방, 유전학, 집단 연구 및 기초 연구인데요. 주요 목표는 당뇨병을 예방하고 당뇨병을 더 잘 치료하며 합병증을 예방하는 것이에요.
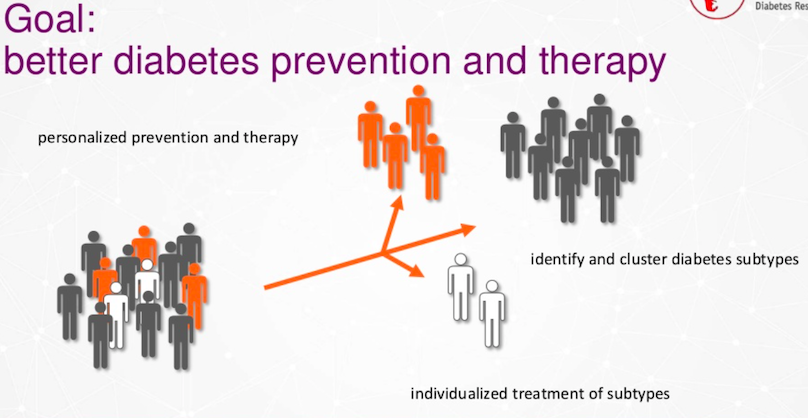
당뇨병 예방
저희는 1형, 2형 또는 현재 조사 중인 다른 새로운 유형의 당뇨병을 예방하고자 해요. 더 나아가 지능적인 알고리즘으로 환자를 식별하고 개별화된 방식으로 치료하고 싶어요.
당뇨병과 싸우는 방법
일반적인 연구원의 경우 조직 내의 정보와 데이터를 찾는 데 어려움을 겪는데요. 마치 건초 더미에서 바늘을 찾는 것과 같죠. 안타깝게도 저희 병원과 기초 연구에는 건초 더미가 너무 많아요.
데이터 문제
일반적으로 "어떤 혈액 샘플을 가지고 있나요?" 또는 "간에서 무엇을 측정했나요?"와 같은 간단한 질문에서부터 시작하는데요. 이러한 질문에 답하기가 점점 더 어려워지고 있고, 쿼리도 더욱 복잡해지고 있어요.
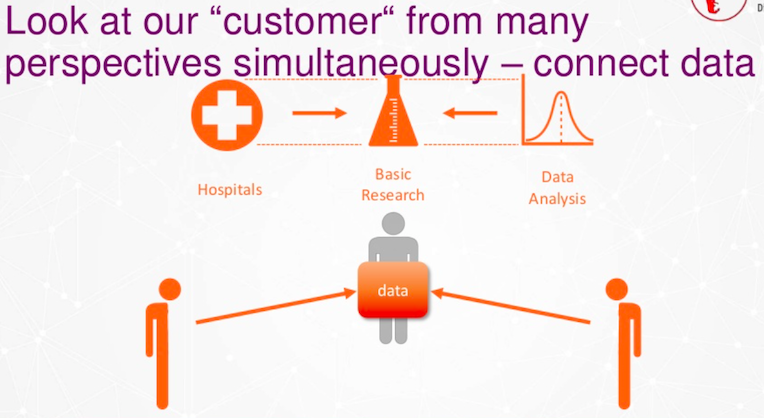
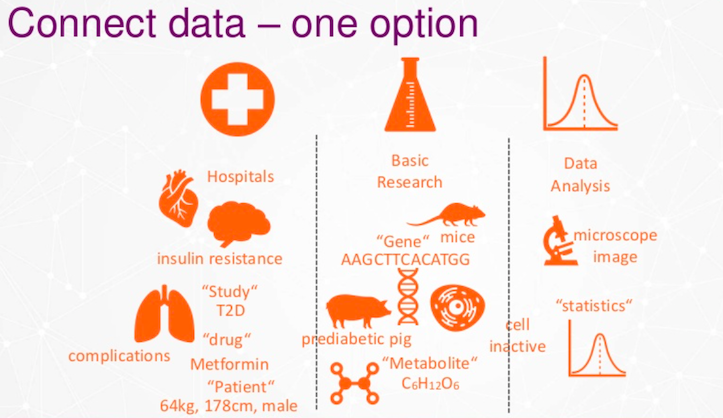
이러한 데이터 문제는 원래 서로 다른 기술을 가진 세 개의 조직이었기 때문에 발생했어요. 하지만 저희는 모두 같은 고객, 즉 당뇨병 환자를 위해 일하고 있었죠.
하지만 모두 이 당뇨병 환자를 조금씩 다르게 바라봤어요. 동물 모델로 보는 사람도 있고, 현미경 사진으로 보는 사람도 있고, 대사 산물을 보는 사람도 있었죠.
이제는 고객을 새로운 방식으로 바라보고 다양한 유형의 데이터를 결합해야 해요. 게다가 이는 데이터를 공유해야 함을 의미하죠.
이제 최대한 다양한 관점에서 고객을 바라봐야 하고, 이는 데이터를 하나로 연결해야 한다는 것을 의미해요.
두 가지 옵션이 있는데요. 한 가지 옵션은 모든 데이터베이스를 별도로 개발하는 것이에요.
별도의 데이터베이스를 사용하는 것은 좋은 생각이 아니에요. 그래서 저희는 새로운 레이어를 만들고 싶었고, 연결된 데이터를 선택했어요.
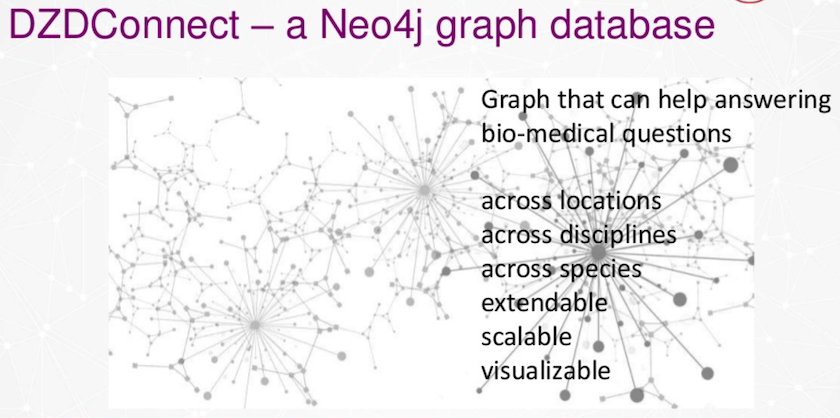
이것이 바로 우리가 DZDConnect라고 부르는 거예요. 이건 Graph Database인데, 이 Graph Database가 우리와 연구자들이 생물의학적 질문에 답하는 데 도움을 주고 있어요. 이런 질문들은 여러 위치에서 답변될 수 있죠. 말씀드린 것처럼, 독일에는 10개 이상의 지점이 있고, 학문 분야와 종을 넘나들며 질문에 답할 수 있답니다.
이 데이터베이스는 확장 가능해야 해요. 우리가 Graph Database를 좋아하는 주된 이유 중 하나는 데이터 시각화 기능 때문이기도 하고요.
동종 및 이종 데이터
우리는 이질적인 데이터와 동질적인 데이터를 다루고 있어요. 데이터 보안상의 이유로 원시 데이터는 건드리지 않죠. 다양한 위치의 데이터를 분류하고 라벨을 붙인 다음, 환자 데이터를 연결해서 서로 연결되도록 해요. 결국 이걸 단일 레이블로 줄이면 데이터가 그래프 모델과 비슷해지기 시작한답니다.
왜 그래프인가?
우리가 그래프를 좋아하는 첫 번째 이유는, 어쨌든 생물학 자체가 연결되어 있기 때문이에요. 모든 데이터와 생물학은 연결되어 있죠. 우리 연구원들은 이해하기 쉬워서 그래프를 좋아해요. 데이터 모델이 컴퓨터 과학자가 아니더라도 사람이 읽을 수 있을 정도로 직관적이거든요. 게다가 쿼리도 쉬워요. 일반 SQL보다 쿼리하기가 훨씬 쉬운 것 같아요.
그래프는 확장성과 적응력도 뛰어나요. 새로운 분야, 새로운 영역, 새로운 위치가 생기면 그래프 모델을 쉽게 적용할 수 있죠. 이렇게 확장하면 정말 멋진 시각화를 얻을 수 있답니다.
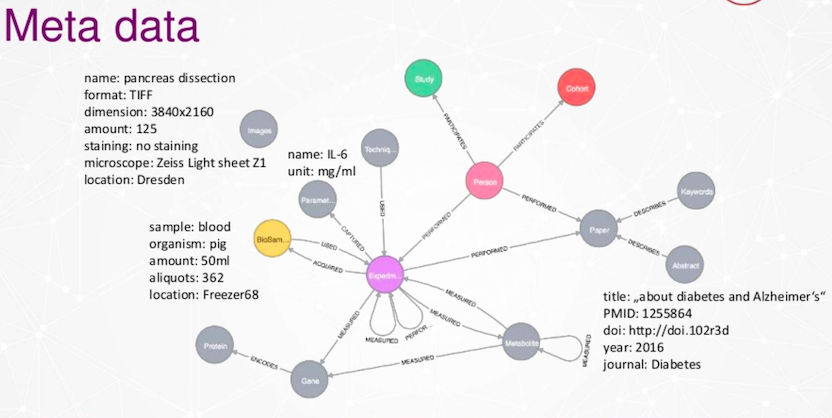
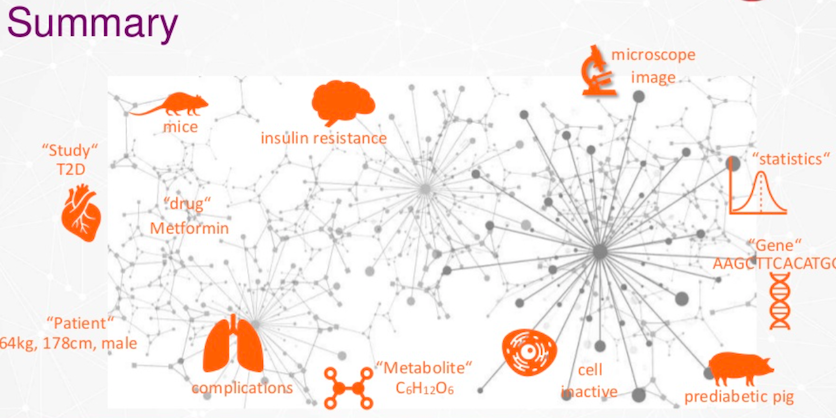
데이터에 대해 이야기할 때, 현재는 메타데이터를 포함하고 있어요.
위에 보이는 건 예비 데이터 모델이에요. 아주 큰 홉(hop)은 실험이죠. 우리는 연구자들이라서 실험을 많이 하거든요. 이 실험에서는 다양한 기술이나 장치를 사용해서 여러 매개변수를 측정해요. 어떤 실험에서는 혈액이나 소변 같은 생체 샘플을 수집하기도 하고요. 전문가들이 검토한 과학 출판물 같은 데이터도 포함하고 있답니다. 이런 것들이 모두 우리 데이터 모델에 연결되어 있어요.
메타데이터의 예로는 미세한 이미지가 있을 수 있겠네요. 치수를 설정하고, 매개변수 이름, 단위, 측정 방법 등을 설정하는 거죠. 우리는 액체 질소에 바이오 샘플을 저장하는 바이오 샘플 데이터베이스도 가지고 있어요.
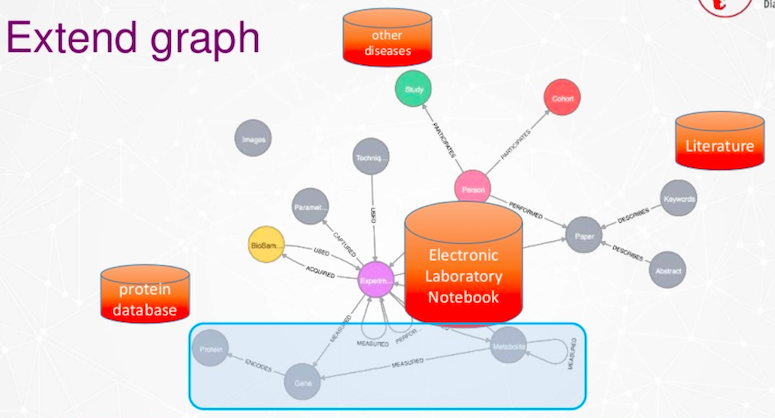
우리는 이 그래프를 확장하고 싶어요.
그래프를 확장하는 방법은 여러 가지가 있어요. 한 가지 옵션은 심혈관 질환이나 알츠하이머병 같은 다른 질병으로 확장하는 거죠. 공개적으로 이용 가능한 문헌 데이터베이스도 많이 있고요. 우리는 전자 연구 노트 데이터, 단백질 데이터베이스 데이터 등을 포함할 거예요. 또한 유전자, 단백질, 대사산물의 세계로 들어가는 특별한 사례 섹션도 만들 거고요.
Rush의 아주 멋진 포스터네요.
여기 보시는 건 신체의 모든 대사 경로를 요약한 거예요. 이제 우리는 파란색 상자에만 집중해 볼게요.
확대해서 보면 점점 복잡해지는 걸 알 수 있어요. 효소에 의해 대사되는 대사산물이 있고, 다른 대사산물 등에 의해 조절되죠. 이 데이터베이스는 정말 풍부하고 거대해요.
Knowing Health라는 뮌헨 Helmer Center의 스타트업 회사도 이와 동일한 문제를 다루고 있어요. 그들의 데이터 모델 역시 Neo4j를 사용해서 이러한 다양한 유전자, 전사물 및 단백질 세계를 연결하죠. Neo4j 데이터베이스는 엄청 커서 8억 개의 Nodes와 Relationships로 구성되어 있어요. 우리는 이 데이터베이스를 우리 데이터베이스에 포함시킬 수 있어요.
요약하자면, 우리는 그래프 기술을 사용해서 서로 다른 분야, 서로 다른 위치를 가지며 서로 연결되는 메타 데이터베이스를 구축하고 있어요.
예시
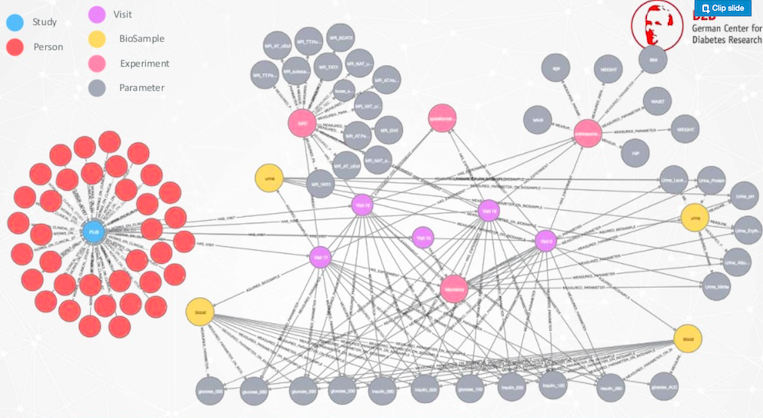
많은 의사들이 묻는 질문 중 하나는 "우리 임상 연구의 17차 방문에서 얼마나 많은 생체 시료를 확보했습니까?"에요.
이 임상 연구를 당뇨병 전단계 생활습관 중재 연구라고 해요. 우리는 이 생체 시료에 관심이 있어요. 우리는 그들이 그것을 어떻게 측정했는지 알고 싶고요. 이 질문은 대답하기가 쉽지 않아요.
이를 위해 우리는 특별한 데이터 모델을 구축했어요.
우리는 임상 연구를 진행하고 있고 환자들은 다양한 방문을 받아요. 이러한 방문에서 의사는 다양한 실험을 수행하고 매개변수를 측정하죠. 일부 방문에서는 저장되어 있는 생체 시료를 수집하고 그에 대한 데이터를 측정해요.
우리 의사들은 Neo4j Graph Database로 이동해요. 그들은 임상 연구를 받고 그것을 확장하고 여기 방문을 봅니다. 그런 다음 17번 방문을 찾아볼 수 있어요.
이제 상황이 복잡해지고 있음을 알 수 있어요. 분홍색으로 다양한 실험이 있고 회색으로 매개변수가 있고 노란색으로 바이오샘플이 있어요. 그렇기 때문에 이 질문에 대답하는 것이 너무 복잡한 거죠.
두 번째 예는 완전히 다른 것이에요.
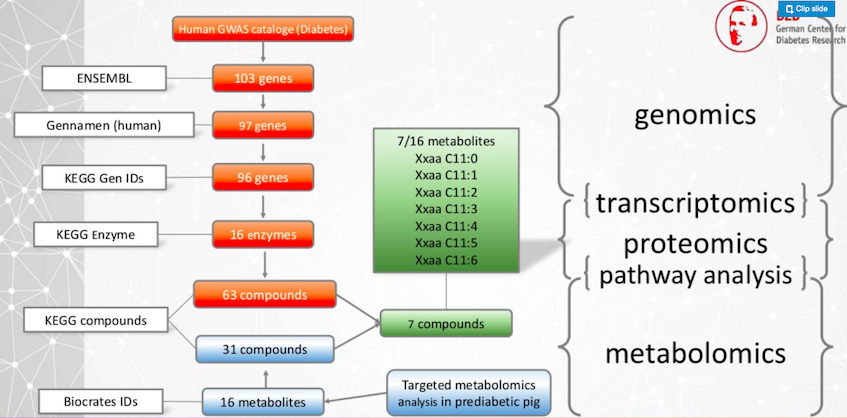
여기서 우리는 다양한 종, 즉 인간과 당뇨병 전증 돼지 모델의 데이터를 연결하려고 해요. 우리는 인간의 제2형 당뇨병 유전자를 동물 모델에서 연구할 수 있는지 질문하는 거죠.
이 질문에 답하기 위해서는 여기 있는 모든 분야가 많은 사람들이 연구하는 서로 다른 연구 분야라는 것을 알아야 하고, 이들을 연결해야 해요.
이러한 유전자는 공개적으로 이용 가능한 다양한 데이터베이스를 통해 충족돼요. 이들은 효소로 변하고, 이 효소는 다양한 화합물을 대사하죠. 이는 데이터의 인간 부분이에요.
이제 당뇨병 전증 돼지에 대한 표적 대사체학 에세이가 생겼어요. 우리는 16개의 서로 다른 대사산물을 측정하고, 공개 데이터베이스에서는 이 16개의 대사산물이 31개의 식별자예요. 그런 다음 우리는 이러한 세트의 결합을 갖고 동물 모델과 인간 데이터 사이에서 7가지 화합물을 식별할 수 있다는 결과를 얻었어요.
이제 우리 연구원들은 당뇨병에 대한 새로운 통찰력을 얻기 위해 이러한 대사산물을 조사하고 있어요.
전망
전망은 어떨까요? 우리는 공개적으로 이용 가능한 문헌 데이터로 그래프를 확장하고 싶어요. Pubnet이라는 매우 큰 데이터베이스에 동료가 검토한 아래 기사가 있어요.
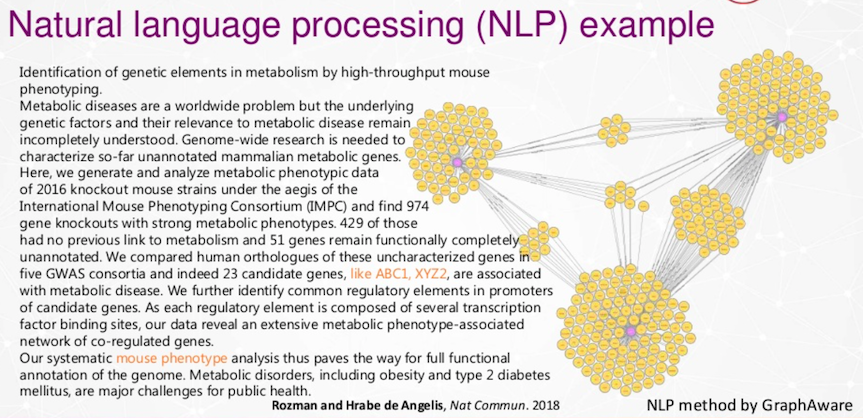
Pubnet에는 3천만 개의 텍스트가 있어요. 이 텍스트는 다양한 기본 연구 분야에 관한 것이며 누구도 더 이상 모든 텍스트를 읽을 수 없죠. 당뇨병을 찾을 때 읽을 수 있는 것은 병목 현상이에요. 우리는 유전자 이름을 배우거나 질병 또는 그에 대한 특정 용어를 배우기 위해 이러한 텍스트에 그래프 알고리즘을 적용함으로써 자동으로 이를 수행하고자 해요.
결국 우리는 많은 텍스트에 대해 이를 수행하고 텍스트 사이의 연결이 무엇인지 확인하고 싶어요.
여기 보라색 `Node`들은 Graphaware의 Natural Language Processing 절차를 거쳐 분석된 텍스트들이에요. 이걸 통해 서로 다른 연구 텍스트 간의 중복을 확인할 수 있죠.
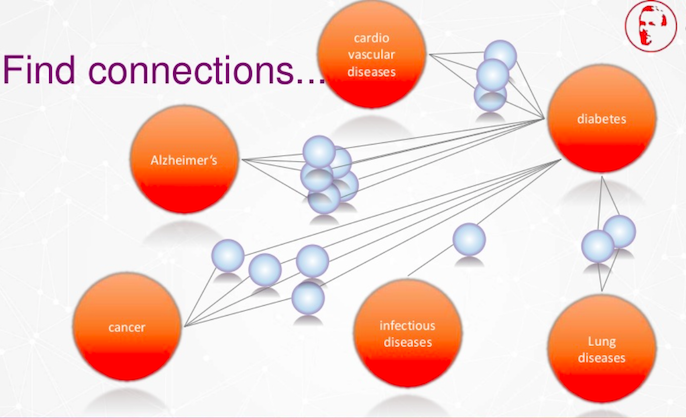
저희는 이런 연관성을 찾고 싶어요.
심혈관 영향, 알츠하이머, 암, 전염병, 폐 질환 사이의 연관성도 찾고 싶고요.
여기 주황색 점들은 독일 당뇨병 연구 센터처럼 저희와 같은 기관들이에요. 당뇨병이나 다른 질병과 싸우기 위해 서로 연결되기를 바라고 있죠.
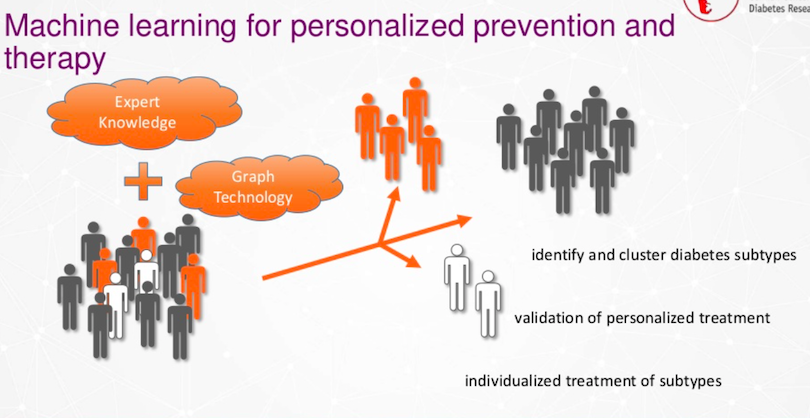
당뇨병이나 다른 질병의 다양한 하위 유형을 가진 사람들이 있고, 연구원, 의사, 진료소도 있어서 전문 지식을 갖추고 있어요. 이제 이걸 그래프 기술과 결합해서 더 잘 식별하거나 당뇨병의 새로운 하위 유형을 클러스터링해서 개별화된 치료나 예방을 제공하려고 해요.
이 센터는 곧 디지털 당뇨병 예방 센터(Digital Diabetes Prevention Center)라는 새로운 센터가 될 거예요.
저희는 사회의 사람들이 제공하는 엄청난 양의 데이터에서 패턴을 인식하고 싶어요. 데이터를 제공한 사람들에게 이익을 돌려주고, 사회 전체에도 이익을 주기 위해 지도 또는 비지도 Machine Learning 기술을 사용하려고 하죠.
제 생각에는 그래프 기술을 통해 당뇨병 예방과 치료에 새로운 차원이 열렸어요.
관계형 데이터베이스에서는 볼 수 없었던 이벤트들을 보게 돼요. 다양한 분야, 위치, 종을 연결하기 때문이죠.
자금 제공자, 연방 교육 연구부, 주정부에 감사를 표하고 싶어요. DZD의 모든 과학자들과 여기 주최측에도 감사의 말씀을 전하고 싶습니다. 그래프커넥트, 이렇게 좋은 회의를 열어주셔서 정말 감사해요.
그래프 기술이 처음이신가요?
무료 사본을 받아보세요. 초보자를 위한 그래프 데이터베이스 eBook을 통해 그래프 데이터베이스 기술의 기본 사항에 대한 이해하기 쉬운 가이드를 받아보세요. 사전 지식이 필요하지 않아요.
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.