드디어! Langchain-neo4j가 발표됐어요. 🎉 Neo4j GraphRAG를 LangChain 생태계와 통합하는 공식 파트너 패키지랍니다. GraphRAG는 Knowledge Graph의 강력한 기능과 Retrieval-Augmented Generation(RAG)을 결합해서, 동일한 소스 데이터로 답할 수 있는 질문의 깊이와 폭을 훨씬 넓혀줘요.
LangChain은 수백만 명의 개발자가 GenAI 애플리케이션을 구축하는 데 사용하는 오픈 소스 프레임워크죠. LangChain 사용자들은 이미 커뮤니티 중심의 다양한 통합 기능들을 선택해서 사용하고 있을 텐데요. LangChain v0.2에서는 기술 파트너와의 통합을 공동으로 유지하는 새로운 파트너 패키지를 도입했어요.
이번에 나온 최신 패키지인 langchain-neo4j는 LangChain 사용자에게 Neo4j의 강력한 기능들을 제공한답니다.
AI 앱에 Neo4j GraphRAG를 사용하는 이유가 뭘까요?
Neo4j는 AI 애플리케이션을 구축하는 데 아주 적합한 솔루션이에요.
그래프 기반 데이터 표현: Neo4j의 Graph Database는 데이터를 Nodes와 Relationships로 표현하는데, 이게 바로 비정형 데이터와 정형 데이터의 혼합을 모델링하는 가장 자연스러운 방법이거든요. 이런 연결 구조는 더 나은 답변을 제공하는 패턴을 나타내준답니다.
효율적인 Queries: Neo4j의 쿼리 언어인 Cypher는 패턴 매칭을 위해 설계되었고, 텍스트 청크와 데이터 레코드 전반에 걸쳐 효율적인 Queries를 가능하게 해줘요.
확장성 및 유연성: Neo4j는 대규모 데이터 세트를 처리하도록 확장할 수 있고, 다양한 AI 사용 사례를 지원할 수 있을 만큼 유연하답니다.
langchain-neo4j는 어떻게 작동하나요?
langchain-neo4j 패키지는 LangChain과 Neo4j 간의 원활한 통합을 도와주는 몇 가지 주요 기능들을 제공해요.
Neo4jGraph: Neo4j의 Python 드라이버를 사용해서 Neo4j Database와 직접 상호 작용하기 위한 간단한 인터페이스를 제공해요. 이걸 통해 Cypher Queries를 실행하고 Database에서 데이터를 검색할 수 있죠.
Neo4jChatMessageHistory: Neo4j Database에 채팅 메시지 기록을 저장하고 관리하는 기능을 제공해요. 기록은 메시지를 Nodes와 Relationships로 나타내기 때문에, 대화 기록을 효율적으로 Query하고 분석할 수 있답니다.
GraphCypherQAChain: 이 클래스는 Neo4j Database와의 Natural Language 상호 작용을 도와줘요. Large Language Model(LLM)을 활용해서 사용자 질문을 Cypher Queries로 변환하고, Database에 대해 실행하며, 결과를 사용해서 Natural Language 응답을 생성한답니다.
langchain-neo4j 패키지는 LangChain과 Neo4j의 장점을 모두 활용하는 AI 애플리케이션을 구축하기 위한 강력한 툴킷을 제공해요. LangChain의 유연성과 Neo4j의 그래프 기반 기능을 결합해서, 개발자들은 더욱 지능적이고 효율적이며 확장 가능한 AI 앱을 만들 수 있게 될 거예요.
더 자세한 정보는 langchain-neo4j 패키지 저장소를 방문하거나, GraphAcademy에서 GraphRAG의 기본을 배워보세요!
GraphRAG
LangChain
Partner
RAG
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
드디어! Langchain-neo4j가 발표됐어요. 🎉 Neo4j GraphRAG를 LangChain 생태계와 통합하는 공식 파트너 패키지랍니다. GraphRAG는 Knowledge Graph의 강력한 기능과 Retrieval-Augmented Generation(RAG)을 결합해서, 동일한 소스 데이터로 답할 수 있는 질문의 깊이와 폭을 훨씬 넓혀줘요.
LangChain은 수백만 명의 개발자가 GenAI 애플리케이션을 구축하는 데 사용하는 오픈 소스 프레임워크죠. LangChain 사용자들은 이미 커뮤니티 중심의 다양한 통합 기능들을 선택해서 사용하고 있을 텐데요. LangChain v0.2에서는 기술 파트너와의 통합을 공동으로 유지하는 새로운 파트너 패키지를 도입했어요.
이번에 나온 최신 패키지인 langchain-neo4j는 LangChain 사용자에게 Neo4j의 강력한 기능들을 제공한답니다.
AI 앱에 Neo4j GraphRAG를 사용하는 이유가 뭘까요?
Neo4j는 AI 애플리케이션을 구축하는 데 아주 적합한 솔루션이에요.
그래프 기반 데이터 표현: Neo4j의 Graph Database는 데이터를 Nodes와 Relationships로 표현하는데, 이게 바로 비정형 데이터와 정형 데이터의 혼합을 모델링하는 가장 자연스러운 방법이거든요. 이런 연결 구조는 더 나은 답변을 제공하는 패턴을 나타내준답니다.
효율적인 Queries: Neo4j의 쿼리 언어인 Cypher는 패턴 매칭을 위해 설계되었고, 텍스트 청크와 데이터 레코드 전반에 걸쳐 효율적인 Queries를 가능하게 해줘요.
확장성 및 유연성: Neo4j는 대규모 데이터 세트를 처리하도록 확장할 수 있고, 다양한 AI 사용 사례를 지원할 수 있을 만큼 유연하답니다.
langchain-neo4j는 어떻게 작동하나요?
langchain-neo4j 패키지는 LangChain과 Neo4j 간의 원활한 통합을 도와주는 몇 가지 주요 기능들을 제공해요.
Neo4jGraph: Neo4j의 Python 드라이버를 사용해서 Neo4j Database와 직접 상호 작용하기 위한 간단한 인터페이스를 제공해요. 이걸 통해 Cypher Queries를 실행하고 Database에서 데이터를 검색할 수 있죠.
Neo4jChatMessageHistory: Neo4j Database에 채팅 메시지 기록을 저장하고 관리하는 기능을 제공해요. 기록은 메시지를 Nodes와 Relationships로 나타내기 때문에, 대화 기록을 효율적으로 Query하고 분석할 수 있답니다.
GraphCypherQAChain: 이 클래스는 Neo4j Database와의 Natural Language 상호 작용을 도와줘요. Large Language Model(LLM)을 활용해서 사용자 질문을 Cypher Queries로 변환하고, Database에 대해 실행하며, 결과를 사용해서 Natural Language 응답을 생성한답니다.
langchain-neo4j 패키지는 LangChain과 Neo4j의 장점을 모두 활용하는 AI 애플리케이션을 구축하기 위한 강력한 툴킷을 제공해요. LangChain의 유연성과 Neo4j의 그래프 기반 기능을 결합해서, 개발자들은 더욱 지능적이고 효율적이며 확장 가능한 AI 앱을 만들 수 있게 될 거예요.
더 자세한 정보는 langchain-neo4j 패키지 저장소를 방문하거나, GraphAcademy에서 GraphRAG의 기본을 배워보세요!
GraphRAG
LangChain
Partner
RAG
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
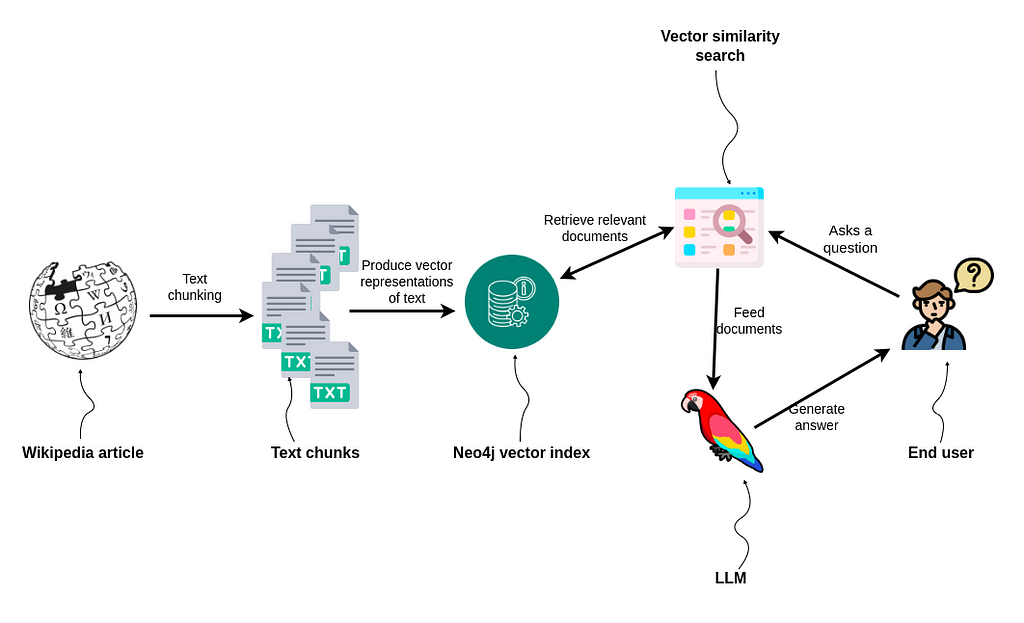
만약 LLM(Large Language Model)이 자체 지식 외에도 검색을 통해 더 넓은 세상의 정보를 가져올 수 있다면, LLM 기반 애플리케이션을 만들 때 훨씬 더 다양한 옵션을 활용할 수 있겠죠. 외부 소스에서 데이터를 검색하는 이 기술을 Retrieval-Augmented Generation(RAG)이라고 불러요.
RAG 애플리케이션은 LLM 기반 애플리케이션 개발을 위한 대표적인 프레임워크인 LangChain을 사용해서 구축할 수 있어요. LangChain은 대부분의 LLM 제공업체와 데이터베이스를 통합 인터페이스에 통합해서 개발 과정을 단순화해주죠. LangChain 라이브러리의 Neo4j vector index를 사용하면, 개발자는 Vector Embedding을 효율적으로 저장하고 검색하기 위한 고급 vector indexing을 쉽게 구현할 수 있답니다.
이번 블로그 포스팅에서는 LangChain과 Neo4j vector index를 사용해서 Wikipedia 기사 정보를 기반으로 질문에 효과적으로 답변할 수 있는 간단한 RAG 애플리케이션을 구축하는 방법을 보여드릴게요. 다음 단계를 함께 살펴볼까요?
Wikipedia 기사를 읽고 Chunking하기
Neo4j를 사용해서 텍스트를 저장하고 Indexing하기
Vector Similarity Search 수행하기
질의 응답 워크플로우 구현하기
Retrieval-Augmented Generation 워크플로우
언제나처럼, 코드는 에서 확인하실 수 있어요.
Neo4j 환경 설정
이 블로그 포스팅의 예제를 따라 하시려면 Neo4j 5.11 이상을 설정해야 해요. 가장 쉬운 방법은 Neo4j AuraDB에서 무료 인스턴스를 시작하는 건데요, Neo4j 데이터베이스의 클라우드 인스턴스를 제공해준답니다. 아니면 Neo4j Desktop을 다운로드해서 로컬 Neo4j 데이터베이스를 설정하고 애플리케이션을 생성해서 로컬 데이터베이스 인스턴스를 만들 수도 있어요.
1. Wikipedia 기사 읽기 및 Chunking
먼저 Wikipedia 기사를 읽고 Chunk로 나누는 것부터 시작해볼게요. LangChain이 Wikipedia 문서 로더와 텍스트 Chunking 모듈을 통합했기 때문에 과정은 아주 간단해요.
from langchain.document_loaders import WikipediaLoader
from langchain.text_splitter import CharacterTextSplitter
# Read the wikipedia article
raw_documents = WikipediaLoader(query="Leonhard Euler").load()
# Define chunking strategy
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1000, chunk_overlap=20
)
# Chunk the document
documents = text_splitter.split_documents(raw_documents)
# Remove summary from metadata
for d in documents:
del d.metadata['summary']
Neo4j는 Graph Database이니까, 그래프 이론의 아버지인 Leonhard Euler에 대한 Wikipedia 기사를 사용하는 게 딱 어울리겠죠?
다음으로, OpenAI에서 만든 토크나이저인 을 사용해서 기사를 Chunk로 분할하는 텍스트 Chunking 모듈을 사용할 건데요, Chunk 크기는 *1000* 토큰으로 설정할 거예요. 이 글에서 텍스트 Chunking 전략에 대해 더 자세히 알아볼 수 있어요.
LangChain의 WikipediaLoader는 기본적으로 각 Chunk에 요약을 추가하는데, 저는 추가된 요약이 약간 중복된다고 생각했어요. Vector Similarity Search를 사용해서 상위 3개 결과를 검색하면 요약이 세 번 반복되니까요. 그래서 데이터세트에서 요약을 제거하기로 결정했답니다.
2. Neo4j로 텍스트 저장 및 Indexing
Neo4j vector index는 LangChain vector store로 래핑되어 있어요. 그래서 다른 벡터 데이터베이스와 상호 작용하는 데 사용되는 구문을 그대로 사용할 수 있답니다.
from_documents 메서드는 Neo4j 데이터베이스에 연결해서 문서를 가져오고, 임베딩하고, Vector Index를 생성해요. 데이터는 기본적으로 청크 Node로 표현되죠. 앞서 말씀드린 것처럼 데이터를 저장하는 방법과 반환할 데이터를 사용자 정의할 수 있어요.
데이터가 채워진 기존 Vector Index가 이미 있다면 from_existing_index 메서드를 사용할 수 있어요.
기업들은 업무상 중요한 애플리케이션에 LLM(Large Language Model)을 통합하고 싶어 하죠. 하지만 LLM의 예측 불가능한 특성 때문에 환각 현상이 발생할 수 있어요. 환각은 부정확한 추론이나 명백한 오류를 의미하는데, 정확성, 설명 가능성, 신뢰성을 중요하게 생각하는 기업에게는 심각한 문제가 될 수 있습니다.
Retrieval-Augmented Generation(RAG)은 LLM을 사실에 기반하여 작동하도록 만드는 중요한 방법이에요. Knowledge Graph와 Vector Database는 RAG를 구현하기 위한 잠재적인 솔루션으로 많이 거론되는데요. 그렇다면 LLM을 위한 더 정확하고 신뢰할 수 있으며 설명 가능한 기반을 제공하는 것은 무엇일까요?
LLM을 기반으로 Knowledge Graph와 Vector Database 중에서 선택할 때 고려해야 할 몇 가지 핵심 요소를 한번 살펴볼까요?
복잡한 질문에 답하기
질문의 복잡성이 높을수록 Vector Database가 결과를 빠르고 효율적으로 반환하기가 어려워져요. 쿼리에 더 많은 주제를 추가하면 Database에서 원하는 정보를 찾기가 더 힘들어지죠.
예를 들어: Knowledge Graph와 Vector Database 모두 "우리 회사의 CEO는 누구입니까?"라는 질문에 대한 답변은 쉽게 찾을 수 있을 거예요. 하지만 "지난 12개월 동안 최소한 두 명의 회원이 투표에서 기권한 이사회 회의는 무엇입니까?"와 같은 질문에는 Knowledge Graph가 Vector Database보다 훨씬 뛰어난 성능을 보여줍니다.
Vector Database는 구체적인 답 대신 Vector 공간 내 주제의 중간쯤에서 답을 찾으려고 할 가능성이 높아요. 반면에 Knowledge Graph는 관계로 연결된 그래프를 탐색하면서 정확한 정보를 찾아 반환하죠.
완전한 응답 얻기
Vector Database는 유사성 점수와 미리 정의된 결과 제한에 의존하기 때문에 답변을 반환할 때 불완전하거나 관련 없는 결과를 제공할 가능성이 높습니다.
예를 들어: "John Smith가 쓴 모든 책을 나열하세요."라고 묻는 경우, Vector Database는 다음과 같은 결과를 반환할 수 있어요.
불완전한 제목 목록 (사전 정의된 한도가 너무 낮음) 또는
John Smith의 모든 제목과 다른 저자의 일부 제목 (사전 정의된 제한이 너무 높음) 또는
정확한 답 (사전 정의된 한도가 딱 맞음).
개발자는 가능한 모든 쿼리에 대해 미리 정의된 제한을 알 수 없기 때문에 Vector Database에서 정확한 답변을 얻는 것은 거의 불가능에 가깝습니다.
하지만 Knowledge Graph의 entity는 관계로 직접 연결되어 있기 때문에 entity마다 관계의 개수가 달라요. Knowledge Graph는 정확한 답변만을 검색해서 반환하죠. 이 경우 Knowledge Graph 쿼리는 John Smith가 쓴 모든 책을 반환하고, 그 외에는 아무것도 반환하지 않아요.
신뢰할 수 있는 응답 얻기
Vector Database는 두 가지 사실 정보를 서로 연결하여 부정확한 정보를 추론할 수 있습니다.
예를 들어: "제품 관리팀에 누가 있나요?"라고 물었을 때, 어떤 사람이 제품 팀에서 생성된 문서(사실)에 자주 댓글을 달고 액세스했다면, Vector Database는 그 사람이 제품 팀에 있었다고 잘못 추론할 수 있어요. Knowledge Graph는 Node와 Relationship을 사용해서 조직 내 사람들의 관계를 정확하게 식별하므로, 제품 팀에 있는 사람들만 반환하죠.
Knowledge Graph 쿼리는 연결된 정보의 흐름을 따르기 때문에 지속적으로 정확하고 설명 가능한 응답을 제공할 수 있습니다.
LLM 환각 교정
Knowledge Graph는 사람이 읽을 수 있는 데이터 표현을 가지고 있지만, Vector Database는 블랙박스만 제공합니다.
예를 들어: 제품 팀 구성원이 잘못 식별된 경우, Vector Database는 잘못된 정보를 추론하는 데 사용한 사실을 식별할 수 없어요. 이는 실행 취소가 불가능하거나 오류의 원인을 이해할 수조차 없다는 의미죠. 반면, Knowledge Graph 사용자는 LLM이 뭔가 잘못 추론한 경우 잘못된 정보를 찾아 수정하기가 훨씬 쉬워요.
Knowledge Graph는 완전한 투명성을 가지고 있기 때문이에요. 데이터의 잘못된 정보를 식별하고, 쿼리 경로를 추적하고, 이를 수정하는 데 도움을 주므로 LLM 정확도를 높이는 데 효과적이죠. 반면 Vector Database는 투명성을 거의 제공하지 않으며 특정 수정 기능도 제공하지 않아요.
LLM을 위한 Knowledge Graph
Knowledge Graph는 LLM을 뒷받침하는 최고의 선택이라고 할 수 있어요. 정확성, 설명 가능성, 맥락을 보장하는 데 큰 도움이 되죠. Neo4j의 신뢰할 수 있고 검증 가능한 Knowledge Graph는 LLM 정확성과 설명 가능성을 높여주고, 데이터 보호, 거버넌스, 고가용성, 확장성 및 유연한 배포와 같은 강력한 엔터프라이즈 기능도 제공합니다. 덕분에 미션 크리티컬 애플리케이션을 지원하는 LLM과 함께 사용할 수 있는 안정적이고 확장 가능한 선택이 되는 거죠.
자세한 내용은 LLM 기반 애플리케이션을 위한 Neo4j의 Knowledge Graph를 살펴보거나, Knowledge Graph 구축 방법에 대한 개발자 가이드를 읽어보세요.
개발자 가이드 다운로드
GenAI
LLM 환각
Machine Learning
Retrieval-Augmented Generation
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
팀에서 와 WhyHow.AI의 그래프 및 벡터 검색 시스템이 어떻게 함께 작동해서 RAG (Retrieval-Augmented Generation) 시스템을 개선하는지 알아볼 거예요. 재무 보고서 RAG 예시를 사용해서 그래프와 벡터 검색 간의 응답 차이를 살펴보고, 두 가지 유형의 답변 출력을 벤치마킹하고, 그래프 구조를 통해 깊이와 폭을 최적화할 수 있는 방법을 보여주고, 그래프와 벡터 검색을 결합하는 것이 RAG의 미래인 이유를 알아볼게요.
Neo4j와 같은 Graph Database는 `노드`와 `관계`의 모음인 그래프 개념을 기반으로 구축되었어요. `노드`는 개별 데이터 포인트를 나타내고, `관계`는 `노드` 간의 연결을 정의하죠. 각 `노드`는 `노드`에 대한 추가 컨텍스트 또는 속성을 제공하는 키-값 쌍인 `속성`을 가질 수 있어요. 이 접근 방식은 데이터 내의 복잡한 관계와 종속성을 모델링하는 유연하고 직관적인 방법을 제공해요. Knowledge Graph는 흔히 인간의 뇌가 작동하는 방식과 비슷하다고 불리는데요. 그래프를 사용하면 명시적인 `관계`를 저장하고 `쿼리`할 수 있어서 환각을 줄이고 상황 주입을 통해 정확도를 높일 수 있어요.
Knowledge Graph는 데이터와 데이터 포인트 간의 연결을 저장해서 모든 관련 정보에 대한 포괄적인 보기를 제공함으로써 추론 및 추출 기능을 향상시키죠. 이는 또한 그래프 내에서 의존하는 데이터가 표시되고 추적 가능하므로 설명 가능성의 이점을 제공해요. 다음을 확인해 보세요. 개발자 가이드: Knowledge Graph 구축 방법 Knowledge Graph에 대해 자세히 알아보세요.
이 기능은 재무 지표, 시장 상황, 사업체 간의 복잡한 `관계`를 이해하는 것이 중요한 재무 분석과 같은 분야에서 특히 유용해요.
예를 들어, Graph Database는 실제 상호 작용을 반영하는 일관된 모델에서 임원진술서, 재무 결과, 시장 상황과 같은 다양한 정보를 연결할 수 있어요. 이를 통해 재무 분석가는 그래프를 탐색하여 직간접적인 영향을 확인함으로써 특정 제품 라인에 대한 거시 경제 변화의 영향과 같은 복잡한 시나리오를 탐색할 수 있죠. Neo4j의 그래프 쿼리 언어인 Cypher를 사용하면 Knowledge Graph에서 인플루언서가 제품에 미치는 영향과 같은 복잡한 `관계`를 발견할 수 있어요.
def explore_impact_on_product(graph, product_name):
query = """
MATCH (p:Product {name: $product_name})<-[r:IMPACTS]-(m)
RETURN m.name AS Influencer, r.description AS ImpactDescription
"""
result = graph.run(query, product_name=product_name)
for record in result:
print(f"Influencer: {record['Influencer']}, Impact: {record['ImpactDescription']}")
비즈니스 시나리오에서 의사 결정자는 격리된 데이터 포인트가 어떻게 연결되어 있는지 확인하고 싶어하죠. 그래프는 공급자 역학의 변화가 생산 일정, 재고 수준 및 재무 결과에 어떤 영향을 미치는지 보여줄 수 있어요. 그래프 구조의 유연성 덕분에 기본적인 데이터베이스 스키마를 크게 재설계할 필요 없이 새로운 데이터 유형 및 관계가 도입될 때 동적으로 적응할 수 있다는 점도 매력적이죠.
깊이 및 너비 그래프 검색 사용
일반적으로 사용되는 Retrieval-Augmented Generation (RAG)에서는 Vector Embedding 검색을 통해 의미상 유사한 단어와 문구를 찾아 해당 정보를 Large Language Model (LLM)에 반환하여 질문에 대한 답변을 구성해요. Vector Embedding 검색은 질문과 관련된 일부 유형의 정보를 가져오는 강력한 방법이죠. 예를 들어, “John은 어떤 애완동물을 키웠나요?”라는 질문에 대해 'cat'과 'dog'가 잠재적으로 의미상 'pets'와 유사하다는 것을 추론할 수 있으므로 John의 고양이나 개에 대한 정보를 검색할 수 있어요. 이는 그러한 단어가 검색되기 전에 '애완동물'이라는 개념과 명시적으로 연결될 필요가 없다는 것을 의미하죠. 하지만 많은 정보가 의미상 유사하지만 관련성이 없거나, 관련성이 있지만 의미상 유사하지 않을 수도 있어요.
그래프 검색은 정보 검색을 더욱 세밀하게 제어할 수 있도록 최적화할 수 있는 특정 수단과 패턴을 제공해요. 특정 조사 방향 내에서 더 깊은 수준의 정보 검색이 필요한 쿼리의 경우, 그래프는 관계 계층을 통한 탐색을 용이하게 하여 특정 패턴에 대한 심층 분석을 가능하게 하죠. 반대로 그래프를 사용하면 데이터에 대한 더 넓은 관점을 추구하고 정보의 전체 범위에 초점을 맞추는 쿼리에 대해 광범위한 인접 관계 집합에서 검색할 수 있어요.
이는 그래프 내 수직(깊이/Depth) 및 수평(넓음/Breadth) 순회와 유사하게 볼 수 있어요.
재무 보고서 RAG를 통해 그래프 및 벡터 검색 평가
Apple의 분기별 재무 보고서를 살펴보면서 재무 정보 검색 시스템에서 그래프 및 벡터 검색을 적용하는 방법을 한번 살펴볼까요?
재무 분석가는 회사 성과, 시장 동향, 제품 통찰력에 관한 복잡한 쿼리를 처리하기 위해 고군분투하죠. 여러 분기에 걸쳐 환율이 iPhone 수익에 미치는 영향을 평가하는 임무를 맡은 분석가를 생각해 보세요. 이러한 질문을 하려면 제품 성능, 재무 건전성, 외부 경제 요인에 대한 이해가 필요해요.
수익 보고 기록을 재무 지표, 제품 및 시장 상황 간의 관계를 설명하는 구조화된 형식으로 변환함으로써 Knowledge Graph는 회사 성과에 대한 포괄적인 보기를 제공해요. 이러한 구조화된 접근 방식을 통해 분석가는 빠르고 정확한 분석을 수행하여 다양한 비즈니스 부문이 어떻게 상호 작용하고 서로 영향을 미치는지에 대한 더 깊은 통찰력을 제공하여 전략적 투자 의사 결정을 향상시킬 수 있죠. 그래프 구조를 사용하면 주요 데이터 엔터티와 인접 엔터티를 직접 추출할 수 있어요.
아래 코드를 사용하면 엔터티의 이름을 가져오고, 해당 이웃(관련 Node)을 검색하고 종속성을 설치할 수 있어요.
pip install numpy pyvis neo4j openai
from neo4j import GraphDatabase
from typing import Optional, Union, List, Dict
import numpy as np
from openai import OpenAI
from pyvis.network import Network
def get_embedding(text, model="text-embedding-3-small"):
client = OpenAI()
text = text.replace("n", " ")
return client.embeddings.create(input = [text], model=model).data[0].embedding
def calculate_similarity(embedding1, embedding2):
# Placeholder for similarity calculation, e.g., using cosine similarity
# Ensure both embeddings are numpy arrays for calculation
return np.dot(embedding1, embedding2) / (np.linalg.norm(embedding1) * np.linalg.norm(embedding2))
class NodeSimilaritySearchMan():
def __init__(self, neo4j_driver: GraphDatabase):
"""
Initialize the NodeSimilaritySearchMan with a Neo4j driver instance.
Args:
neo4j_driver (GraphDatabase): The Neo4j driver to facilitate connection to the database.
"""
self.driver = neo4j_driver
def find_relationship_neighbors(self, node_name: str) -> List[Dict[str, Union[int, str]]]:
"""
Finds neighbors of a given node based on direct relationships in the graph.
Args:
node_name (str): The name of the node for which to find neighbors.
Returns:
List[Dict[str, Union[int, str]]]: A list of dictionaries, each representing a neighbor with its ID and name.
"""
result = self.driver.execute_query(
"""
MATCH (n)-[r]->(neighbor)
WHERE n.name = $node_name
RETURN neighbor.name AS name,
type(r) AS relationship_type
""",
{"node_name": node_name}
)
neighbors = [{ "name": record["name"],
"relationship_type": record["relationship_type"]} for record in result]
return neighbors
def visualize_relationship_graph_interactive(self,neighbors, node_name,graph_name, edge_label='relationship_type'):
# Initialize the Network with cdn_resources set to 'remote'
net = Network(notebook=True, cdn_resources='remote')
# Add the main node
net.add_node(node_name, label=node_name, color='red')
# Add neighbors and edges to the network
for neighbor in neighbors:
title = neighbor.get('neighbor_chunks_summary', '')
if edge_label == 'similarity': # Adjust title for similarity
title += f" (Similarity: {neighbor[edge_label]})"
else:
title += f" ({edge_label}: {neighbor[edge_label]})"
net.add_node(neighbor['name'], label=neighbor['name'], title=title)
net.add_edge(node_name, neighbor['name'], title=str(neighbor[edge_label]))
net.show(f'{graph_name}_graph.html')
return net
그래프 검색과 벡터 검색의 차이점을 이해하기 위해 WhyHow.AI SDK를 사용해서 PDF 파일에서 바로 Knowledge Graph를 생성해볼 수 있어요. WhyHow SDK는 Knowledge Graph 구성을 간소화하도록 설계된 강력한 도구인데요. 이 SDK를 사용하면 광범위한 Knowledge Graph를 효율적으로 생성, 관리, Query할 수 있어서 기업은 원하는 방식으로 데이터를 구성하고 사용할 수 있게 되죠.
WhyHow SDK를 사용하면 미리 정의된 Schema에서 Knowledge Graph를 구성할 수 있어요. 여기서 Schema는 관련된 entity (Node)의 유형, entity를 연결하는 Relationship (Edge)의 종류, 그리고 Relationship이 따라야 하는 패턴을 지정해서 Knowledge Graph의 구조를 정의하는 역할을 해요. 이렇게 하면 높은 수준의 제어가 가능하기 때문에 사용자는 Knowledge Graph를 특정 요구 사항에 맞춰서 커스터마이징하고, 그래프가 원시 데이터에 내재된 관계를 정확하게 반영하도록 만들 수 있죠.
Schema를 정의함으로써 사용자는 Knowledge Graph에 포함되어야 하는 요소와 연결을 정확하게 지정하게 돼요. 예를 들어 문학적 분석에서는 등장인물과 개체, 비즈니스 애플리케이션에서는 제품과 사용자 상호 작용 같은 것들이 포함될 수 있겠죠. Schema는 구성된 그래프가 정의된 컨텍스트에 대한 일관성과 관련성을 유지하도록 보장해서 복잡한 문서에서 의미 있는 통찰력을 추출하는 강력한 도구가 된답니다.
먼저 WhyHow 클라이언트를 초기화하고 그래프에 표현하려는 문서를 Namespace에 추가해볼게요.
from whyhow import WhyHow
import os
from dotenv import load_dotenv
load_dotenv()
user = os.getenv("NEO4J_USERNAME")
password = os.getenv("NEO4J_PASSWORD")
url = os.getenv("NEO4J_URL")
client = WhyHow(neo4j_user=user,neo4j_password=password,neo4j_url=url)
# Define namespace name
namespace = "apple-earning-calls"
documents = [
"earning-calls-apple/Apple (AAPL) Q1 2023 Earnings Call Transcript _ The Motley Fool.pdf",
"earning-calls-apple/Apple (AAPL) Q2 2022 Earnings Call Transcript _ The Motley Fool.pdf",
"earning-calls-apple/Apple (AAPL) Q4 2022 Earnings Call Transcript _ The Motley Fool.pdf"
]
# Add documents to your namespace
documents_response = client.graph.add_documents(
namespace = namespace, documents = documents
)
둘째, 그래프에 대해 원하는 Schema를 정의합니다.
{
"entities": [
{
"name": "Company",
"description": "The company discussed in the document, specifically Apple Inc."
},
{
"name": "Financial_Metric",
"description": "Quantitative measures of Apple's financial performance, including revenue, gross margin, operating expenses, net cash position, etc."
},
{
"name": "Product",
"description": "Physical goods produced by Apple, such as iPhone, Mac, iPad, Apple Watch."
},
{
"name": "Service",
"description": "Services offered by Apple, including Apple TV+, Apple Music, iCloud, Apple Pay."
},
{
"name": "Geographic_Segment",
"description": "Market areas where Apple operates, such as Americas, Europe, Greater China, Japan, Rest of Asia Pacific."
},
{
"name": "Executive",
"description": "Senior leaders of Apple who are often quoted or mentioned in earnings calls, like CEO (Tim Cook), CFO (Luca Maestri)."
},
{
"name": "Market_Condition",
"description": "External economic or market factors affecting Apple's business, such as inflation, foreign exchange rates, geopolitical tensions."
},
{
"name": "Event",
"description": "Significant occurrences influencing the company, including product launches, earnings calls, and global or regional economic events."
},
{
"name": "Time_Period",
"description": "Specific time frames discussed in the document, typically fiscal quarters or years."
}
],
"relations": [
{
"name": "Reports",
"description": "An executive discusses specific financial metrics, typically during an earnings call."
},
{
"name": "Impacts",
"description": "Describes the influence of events or market conditions on financial metrics, products, services, or geographic segments."
},
{
"name": "Operates_In",
"description": "Denotes the geographic areas where Apple's products and services are available."
},
{
"name": "Presents",
"description": "Associates products or services with their financial performance metrics, as presented in earnings calls or official releases."
},
{
"name": "Occurs_During",
"description": "Connects an event with the specific time period in which it took place."
},
{
"name": "Impacted_By",
"description": "Shows the effect of one entity on another, such as a financial metric being impacted by a market condition."
},
{
"name": "Offers",
"description": "Indicates that the company provides certain services."
},
{
"name": "Influences",
"description": "Indicates the effect of strategies or innovations on various aspects of the business."
}
],
"patterns": [
{
"head": "Executive",
"relation": "Reports",
"tail": "Financial_Metric",
"description": "An executive reports on a financial metric, such as revenue growth or operating margin."
},
{
"head": "Event",
"relation": "Impacts",
"tail": "Financial_Metric",
"description": "An event, like a product launch or economic development, impacts a financial metric."
},
{
"head": "Product",
"relation": "Presents",
"tail": "Financial_Metric",
"description": "A product is associated with specific financial metrics during a presentation, such as sales figures or profit margins."
},
{
"head": "Product",
"relation": "Operates_In",
"tail": "Geographic_Segment",
"description": "A product is available in a specific geographic segment."
},
{
"head": "Event",
"relation": "Occurs_During",
"tail": "Time_Period",
"description": "An event such as an earnings call occurs during a specific fiscal quarter or year."
},
{
"head": "Financial_Metric",
"relation": "Impacted_By",
"tail": "Market_Condition",
"description": "A financial metric is affected by a market condition, such as changes in foreign exchange rates."
},
{
"head": "Company",
"relation": "Offers",
"tail": "Service",
"description": "Apple offers a service like Apple Music or Apple TV+."
},
{
"head": "Service",
"relation": "Influences",
"tail": "Market_Condition",
"description": "A service influences market conditions, potentially affecting consumer behavior or competitive dynamics."
}
]
}
여기서 `노드`와 `관계`는 각각 스키마에 정의된 엔터티와 관계이고, 패턴은 우리가 관찰한 그래프를 구성하는 실제 관계를 의미해요.
동시에 `Vector Index`를 사용하여 동일한 문서를 벡터 표현으로 저장하는 검색 체인과 이러한 문서에 대한 질문 답변을 위한 GPT-4 모델을 정의했어요. 또한 검색 파이프라인을 최적화하기 위해 Cohere의 Rerank를 구현합니다.
from langchain_community.document_loaders import PyPDFLoader
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import OpenAIEmbeddings
from langchain import hub
from langchain_openai import ChatOpenAI
from langchain_community.document_loaders import PyPDFDirectoryLoader
from langchain.retrievers.document_compressors import FlashrankRerank
from langchain.retrievers import ContextualCompressionRetriever
import os
from langchain import PromptTemplate, LLMChain
from langchain_cohere import CohereRerank
from cohere import Client
from dotenv import load_dotenv
load_dotenv()
cohere_api_key = os.getenv("COHERE_API_KEY")
co = Client(cohere_api_key)
class CustomCohereRerank(CohereRerank):
class Config():
arbitrary_types_allowed = True
CustomCohereRerank.update_forward_refs()
def format_docs(docs):
return "nn".join(doc.page_content for doc in docs)
def query_vector_db(query,faiss_index):
retriever = faiss_index.as_retriever()
compressor = CustomCohereRerank(client=co)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
template = """You are a helpful assistant who is able to answer any question using the provided context. Answer the question using just the context provided to you
question: {question}
context: {context}
Provide a concise response with maximum three sentences"""
prompt = PromptTemplate(template=template,
input_variables=["context","question"])
llm = ChatOpenAI(model="gpt-4")
rag_chain = LLMChain(prompt=prompt,llm=llm)
docs = compression_retriever.invoke(query)
context = format_docs(docs)
answer = rag_chain.invoke({"question":query,"context":context})
return answer
def index_docs_vectordb(path):
loader = PyPDFDirectoryLoader(path)
pages = loader.load_and_split()
faiss_index = FAISS.from_documents(pages, OpenAIEmbeddings())
return faiss_index
# index docs
path = "earning-calls-apple" # the path to the folder containing the PDF documents
index = index_docs_vectordb(path)
마지막으로, `Vector` 저장소와 `Graph`를 각각 쿼리하기 위해 두 개의 함수(`query_Vectordb` 및 `query_graph`)를 정의할 거예요.
완전성이란 중요한 세부 정보를 놓치지 않고 `Query`에 대한 모든 관련 정보를 제공하는 시스템의 능력을 의미해요. `Graph Database`는 관계형 특성 덕분에 상호 연결된 모든 데이터를 철저하게 검색해서 포괄적인 답변을 제공할 수 있죠. 반대로, 유사한 텍스트 덩어리를 찾는 데는 효율적이지만 `Vector` `Index`는 더 넓은 맥락이나 데이터 포인트 간의 상호 관계에 대한 완전한 보기를 항상 포착하지 못할 수도 있어요. Apple의 Mac 제품 라인에 직접적으로 영향을 미치는 모든 시장 상황을 전체적으로 파악해야 한다고 상상해 보세요. 여기에는 경제적 요인, 공급망 문제, 경쟁 역학 등이 포함될 수 있어요. 이 정보를 검색하기 위해 `GraphQueryManager` 클래스를 정의할 수 있답니다.
from neo4j import GraphDatabase
class GraphQueryManager:
def __init__(self, uri, user, password):
self.driver = GraphDatabase.driver(uri, auth=(user, password))
def close(self):
self.driver.close()
def get_impacting_market_conditions(self, product_name):
with self.driver.session() as session:
result = session.run("""
MATCH (n)-[r:IMPACTS]->(m) WHERE m.name=$product_name AND n.namespace="apple-earning-calls"
RETURN n.name as Condition, r.description as Description, m.name as Product
""", product_name=product_name)
return [{"Condition": record["Condition"], "Description": record["Description"], "Product": record["Product"]} for record in result]
# Usage
graph_manager = GraphQueryManager(url, "neo4j", password)
conditions = graph_manager.get_impacting_market_conditions("Mac")
graph_manager.close()
Graph를 쿼리하면 Apple Mac에 영향을 미친 모든 시장 상황을 검색해서 제품과 관련된 모든 시장 상황을 포함할 수 있어요. 이는 다음과 같은 시장 상황 목록을 생성하죠.
for condition in conditions:
print(f"- {condition['Condition']}","n")
- COVID-19
- foreign exchange
- macro environment
- macroeconomic outlook
- Market Condition
- product
- services
- softening macro
- PC industry
- iPhone
- revenue
- silicon shortage
- strong March results
- product launch
- sellout conditions
- tightness in the supply chain
- COVID disruptions
- foreign currency
- market condition
- macroeconomic headwinds
- macroeconomic outlook
- COVID-related impacts
- FX headwinds
- digital advertising
- gaming
각 항목은 Graph Database의 구조화된 관계를 기반으로 Mac에 영향을 미치는 것으로 태그가 지정돼요. 이러한 직접 연결을 통해 정보의 관련성과 쿼리 의도를 정확하게 타겟팅할 수 있죠.
Vector Store 기반 체인에 대해 동일한 쿼리를 실행하면 덜 완전한 답변을 얻을 수 있어요.
vectordb_conditions = query_vectordb(
"what are the market conditions that impact Mac products?")
print(vectordb_conditions)
Mac 제품에 영향을 미치는 시장 상황에는 외환 역풍, 심각한 공급 제약, 거시 경제 환경 등이 있어요.
그래프 검색과는 달리, 벡터 검색은 본질적으로 다양한 시장 상황과 Mac에 미치는 영향 사이의 관계를 명확하게 이해하거나 전달하지 않아요. 연결을 이해하려면 추가적인 분석이 필요한 텍스트 덩어리를 제공하는 거죠. 이는 분석 과정에서 중요한 정보가 간과될 수 있고, 시간이 지남에 따라 일관성 없는 답변이 나올 수 있다는 의미이기도 해요. 포괄적인 관련 개념 세트를 강조하고 나열하는 관계 기반 구조가 없다면, 벡터 검색만으로는 완전한 응답을 생성하기 어려울 수 있어요.
하지만 그래프 전용 검색에도 한계는 존재해요. 그래프는 텍스트의 기본 정보를 트리플(즉, 엔터티 - 관계 - 엔터티)로 단순화해서 표현하거든요. 이렇게 정보를 단순화하고 추상화하는 과정에서 기본적인 맥락의 일부를 잃을 위험이 있는 거죠.
Neo4j의 공동 창립자이자 CEO인 Emil Eifrem은 이렇게 말했어요. "저희는 벡터로 찾아낸 암시적인 관계와 그래프로 찾아낸 명시적이고 사실적인 관계 및 패턴을 결합하는 데 큰 가치가 있다고 생각해요. 고객은 생성 AI로 혁신할 때, 배포 결과가 정확하고 투명하며 설명 가능하다는 점을 신뢰해야 하죠."
심층 질문
Neo4j에서 depth 파라미터를 구현하면 Graph Database 내의 복잡한 관계를 분석하는 메커니즘을 제공하게 돼요. 다음 코드 스니펫에서는 Tim Cook이 보고한 재무 측정항목과 이에 영향을 미치는 시장 상황을 검색하는 쿼리를 실행하는 것을 보여줍니다.
depth 파라미터는 Cypher 쿼리의 관계 패턴에 지정되는데요. 이 경우 depth 파라미터는 [:REPORTS] 및 [:IMPACTED_BY] 관계 모두에서 *1..20 범위로 표시돼요. 이 범위는 시작 Node('임원')에서 대상 Node('재무 지표' 및 '시장 조건')까지 통과하는 최소 및 최대 홉(또는 관계) 수를 나타내죠.
MATCH path = (exec:EXECUTIVE)-[:REPORTS*1..20]->
(metric:FINANCIAL_METRIC)-[:IMPACTED_BY*1..20]->(cond:MARKET_CONDITION)
WHERE exec.name='Tim Cook'
RETURN exec, metric, cond, path
결과적으로 다음과 같은 하위 그래프를 얻게 됩니다.
그래프는 지정된 그래프 검색 깊이를 탐색해서 쿼리와 관련된 상호 연결된 엔터티를 보여줘요. 또한 그래프의 Node와 관련된 청크를 검색할 수 있는 최신 청크 연결 기능을 활용하면서 WhyHow SDK를 사용하여 구성된 그래프를 쿼리해서 반환된 결과를 사용해 깊이 지향 질문을 탐색하는 그래프의 기능을 확인할 수 있어요.
from langchain.chat_models import ChatOpenAI
from langchain import PromptTemplate, LLMChain
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
def run_chain(question,txt_context):
template = """ You are a helpful assistant who is able to answer any question using the provided context. Answer the question using just the context provided to you
Question : {question},
Context:{context}
Provide a concise response with maximum three sentences"""
prompt = PromptTemplate(template=template,
input_variables=["context","question"])
# load the model
chat = ChatOpenAI(model_name="gpt-4",openai_api_key=OPENAI_API_KEY, temperature=0.0)
chain = LLMChain(llm=chat, prompt=prompt)
answer = chain.invoke({"question":question,'context':txt_context})
def query_graph_with_chain(question):
context = client.graph.query_graph(
query = question,
namespace = "apple-earning-calls",
include_chunks = True
)
txt_context = context.answer
txt = " "
for chunk in context.chunks:
for text in chunk.chunk_texts:
txt += text
txt_context += txt
chain_answer = run_chain(question,txt_context)
return chain_answer['text']
gr = query_graph_with_chain(question['question'])
vc = query_vector_db(question['question'],index)
print("Graph: ", gr)
print("Vector: ", vc['text'])
: 경영진은 팬데믹 기간 동안 소비자 행동 변화가 Apple의 비즈니스 모델에 미치는 영향을 어떻게 설명했나요?
그래프 쿼리 답변: 경영진은 팬데믹 기간 동안 소비자 행동 변화가 Apple 제품 및 서비스에 대한 수요 증가로 이어지는 영향을 설명했어요. 특히 원격 근무, 온라인 학습, 디지털 엔터테인먼트 분야에서 두드러졌죠. 따라서 팬데믹은 Apple의 비즈니스 모델에 긍정적인 영향을 미쳤다고 할 수 있어요.
벡터 DB 답변: 팬데믹 기간 동안 소비자 행동의 변화는 iPhone 14 Pro 및 iPhone 14 Pro Max의 공급에 큰 영향을 미쳤어요. 이 때문에 Apple이 예상하지 못한 배송 시간이 길어졌죠. 게다가 회사는 Mac과 웨어러블 기기에 가장 큰 영향을 미치고 iPhone에는 가장 적은 영향을 미치는 등 제품과 서비스 전반에 걸쳐 어느 정도 영향을 미쳤다고 해요.
: 그래프 쿼리에서는 소비자 행동의 특정 부문(원격 근무, 온라인 학습, 디지털 엔터테인먼트) 내에서 소비자 행동의 구체적인 영향을 언급했어요. 반면 벡터 쿼리에서는 답변이 팬데믹 관련 영향에 대해 좀 더 일반적으로 말하는 것처럼 보이네요.
: 경영진 논의에서는 중화권 지역 시장 상황과 Apple의 재무 성과 간의 관계를 어떻게 자세히 설명했나요?
그래프 쿼리 답변: 경영진 토론에서는 iPhone, Mac, iPad, Wearables와 같은 다양한 Apple 제품의 판매를 조사해서 중화권 시장 상황과 Apple 재무 성과 간의 관계를 자세히 설명했어요. 또한 설치 기반 및 AppleCare와 같은 요소도 고려했고요. iPhone 14 Pro, Apple Watch Series 8과 같은 특정 제품의 인기도 고려되었답니다.
벡터 DB 답변: 경영진 토론에서는 코로나19 제한과 공급 제약이 수요와 성장에 미치는 영향을 논의하면서 중화권 지역 시장 상황과 Apple의 재무 성과 사이의 관계를 자세히 설명했어요. 이러한 어려움에도 불구하고 Apple은 12월부터 매장 트래픽과 수요에 뚜렷한 변화를 보였죠. 또한 공급 부족에도 불구하고 "Pro" 제품에 대한 강력한 사이클을 언급하면서 고급 제품에 대한 소비자 선택을 유도할 수 있는 능력을 보여줬어요.
: 그래프 쿼리에서는 특정 제품의 인기도에 대한 내용이 언급되고 탐색되었어요. 벡터 쿼리에서 대답은 특히 중국의 성과와 더 밀접하게 연결되는 것이 아니라 '시장 상황'이라는 용어 때문에 전염병 관련 영향에 대해 더 일반적으로 말하는 것처럼 보이고요.
: Apple은 스마트폰 시장의 경쟁 과제를 해결하기 위해 어떤 세부 전략을 사용했나요?
그래프 쿼리 답변: Apple은 지속적인 혁신과 강력한 마케팅 캠페인을 통해 스마트폰 시장의 경쟁 과제를 해결했어요. 또한 독점적인 기능을 활용하고 고객 사이에서 브랜드 충성도를 높였죠. 이러한 전략은 시장에서 경쟁력을 유지하는 데 도움이 되었답니다.
벡터 DB 답변: 스마트폰 시장의 경쟁적 과제를 해결하기 위한 Apple의 전략에는 장기적으로 관리하고 통제할 수 없는 상황에 신속하게 적응하는 것이 포함돼요. 그들은 또한 혁신, 사람, 긍정적인 사회적 영향에 투자하고요. 다른 전략에는 고객의 삶을 풍요롭게 하고 고객의 창의적 잠재력을 발휘하는 데 도움이 되는 기술 개발도 있답니다.
: 그래프 쿼리에서는 사용된 전략 유형(독점 기능 및 강력한 마케팅 캠페인)에 대한 답변이 더 구체적이었고, 벡터 쿼리에서는 더 광범위해 보였어요(혁신에 투자).
폭넓은 질문
폭 넓은 질문에는 특정 주제와 관련된 다양한 개념에 대한 통찰력을 추출하는 광범위한 개요가 필요해요. 그래프 쿼리의 폭을 제어한다는 것은 검색을 제한해야 하는 범위를 확장하거나 축소한다는 의미죠. 이를 통해 Node 주변의 즉각적인 연결을 탐색하고 바깥쪽으로 확장해서 시작 Node가 직접 연결된 Node 또는 Node 유형의 수를 확인하는 질문에 답할 수 있어요.
이 그래프 내에서 이 정보를 LLM에 제공해서 사후 처리를 수행하고 Semantic Search 유사성을 검색하고 추적하려는 특정 Relationship 유형 또는 특정 Node 유형을 식별해서 가장 관련성이 높은 데이터 포인트를 결정할 수 있어요.
예를 들어, Relationship 유형에 따른 경우:
MATCH (n:PRODUCT)-[r]->(m)
WHERE n.name="iPhone"
RETURN n, r, m
또는 `Node` 유형별로 이렇게도 할 수 있어요:
MATCH (n:PRODUCT)-[r]->(m)
WHERE (m:GEOGRAPHIC_SEGMENT OR m:FINANCIAL_METRIC) AND n.name="iPhone"
RETURN n, r, m
: Apple은 제품 개발에 있어 기술 혁신과 비용 관리의 균형을 어떻게 유지하나요?
그래프 쿼리 답변: Apple은 첨단 제품을 만들기 위한 연구 개발에 막대한 투자를 통해 기술 혁신과 비용 관리의 균형을 맞추고 있어요. 또한 공급망 효율성을 최적화해서 비용을 관리하죠. 비용을 낮게 유지하기 위해 공급업체와 유리한 가격을 협상하기도 하고요.
벡터 DB 답변: Apple은 부품 비용 상승과 기타 시장 상황에 적응하여 제품 개발에서 기술 혁신과 비용 관리의 균형을 유지합니다. 이들은 구성 요소 비용의 상승 및 하락 순을 관리하여 어려운 환경을 효과적으로 탐색하려고 노력합니다. Apple은 또한 고객의 삶을 풍요롭게 하고 고객의 창의적 잠재력을 발휘하는 데 도움이 되는 기술을 제공하는 데 중점을 두고 혁신과 인력에 지속적으로 투자하고 있습니다.
: 그래프 쿼리 답변에는 공급업체 협상 및 공급망 관리와 같은 구체적인 조치가 언급되어 있어요. 벡터 DB의 대답은 '도전적인 환경 탐색'과 '혁신에 대한 투자'에 대해 더 모호하죠.
깊이와 폭에 대한 질문
그래프의 깊이와 폭을 탐색해야 하는 질문은 실제 시나리오에서 자주 접하게 돼요. 이러한 질문에는 심층적인 개념 정보뿐 아니라 해당 정보가 다른 개념과 어떻게 관련되는지에 대한 이해가 필요하죠.
Graph Database를 사용하면 그래프 `쿼리`에서 두 가지 검색 유형을 결합할 수 있으므로 풍부한 통찰력이 포함된 복잡한 하위 그래프를 더 쉽게 검색할 수 있어요.
사용 사례에서 Apple의 전략적 결정이 일련의 분기에 걸쳐 다양한 지리적 부문에 걸쳐 재무 지표에 어떤 영향을 미치는지, 그리고 이러한 지표가 제품 개발 전략에 어떻게 영향을 미치는지 알아보고 싶다고 가정해 보겠습니다. 이러한 엔터티 간의 상호 연결된 `관계`를 나타내는 그래프 `쿼리`를 구성할 수 있어요.
MATCH (exec:EXECUTIVE)-[r1:REPORTS]->(metric:FINANCIAL_METRIC),
(metric)-[r2:IMPACTED_BY]->(cond:MARKET_CONDITION),
(prod:PRODUCT)-[r3:PRESENTS]->(metric),
(prod)-[r4:OPERATES_IN]->(geo:GEOGRAPHIC_SEGMENT),
(event:EVENT)-[r5:OCCURS_DURING]->(time:TIME_PERIOD),
(event)-[r6:IMPACTS]->(metric)
WHERE exec.name IN ['Tim Cook', 'Luca Maestri'] AND
geo.name IN ['Americas', 'Europe', 'Greater China'] AND
time.name IN ['Q1 2023', 'Q2 2023', 'Q3 2023']
RETURN exec, metric, cond, prod, geo, event, time, r1,r2,r3,r4,r5,r6
WhyHow의 청크 연결 기능은 `노드`와 해당 청크를 모두 사용하여 LLM에 완전한 컨텍스트를 제공함으로써 이러한 유형의 질문에 대해 작동해요.
: 특히 Apple의 제품 혁신 및 시장 확장 계획과 관련하여 기술 지출 성장 둔화에 대한 투자자의 우려를 완화하기 위해 Tim Cook은 Apple 2022년 4분기 Earnings Call에서 어떤 구체적인 전략을 설명했습니까?
그래프 쿼리 답변: Apple 2022년 4분기 Earnings Call에서 Tim Cook은 기술 지출 성장 둔화에 대한 투자자의 우려를 완화하기 위한 전략을 제시했어요. 그는 시장 리더십과 고객 관심을 유지하기 위해 iPhone 14 및 iPad Pro와 같은 제품에 새로운 기능을 도입하여 지속적인 혁신을 강조했죠. Cook은 또한 고객 기반과 판매 확대에 중요한 인도 및 라틴 아메리카와 같은 신흥 시장에서의 Apple의 성장을 강조했어요. 또한 그는 Apple Music과 같은 서비스 강화와 탄소 중립을 위한 노력, 재활용 재료 사용 등 환경을 생각하는 이해관계자들의 공감을 불러일으키는 지속 가능성에 대한 회사의 약속을 강조했죠.
Vector DB 답변: Apple 2022년 4분기 실적 발표에서 Tim Cook은 iPhone 14와 같은 제품의 지속적인 혁신을 강조하고, 신흥 시장으로 확장하고, Apple Music과 같은 서비스를 강화하고, 지속 가능성 노력에 집중함으로써 기술 지출 둔화에 대한 우려를 해결했습니다.
해설: Graph 쿼리 답변에서 언급된 전략이 여러 지역과 제품 라인에 걸쳐 있는 동시에 특정 국가나 특정 전략의 목적에 대해 더 깊이 언급하고 있음을 알 수 있어요. Vector DB 답변에 일부 부분이 언급되어 있지만 답변은 덜 철저하고(폭) 덜 자세합니다(깊이).
Vector Search를 강화하는 Graph Search 레버로서의 깊이와 폭
Graph Search를 사용하면 폭과 깊이가 다중 에이전트 시스템에서 검색을 위한 잠재적인 수단으로 볼 수 있어요. 코디네이터 에이전트는 질문을 평가하여 검색에 더 많은 폭 및/또는 깊이가 필요한지 여부를 결정할 수 있죠. 그런 다음 Graph 쿼리의 일부로 개별 범위(예: 0.0~1.0)를 사용하여 너비 또는 깊이 수준을 구성할 수 있어요. 에재귀 검색 에이전트를 사용하면 그래프를 수평(너비) 또는 수직(깊이)으로 탐색하는 동안 무엇을 유지하고 제거할지 결정하고 추가로 평가하는 데 도움이 될 수 있어요.
이러한 특정 유형의 검색은 특히 Vector RAG만으로는 결정적이고 정확한 방식으로 구축하기 어렵죠. 이러한 유형의 검색 패턴은 그래프 구조를 사용하여 검색용 데이터를 저장하는 새로운 기회를 보여줍니다. 의미 구조를 저장할 뿐만 아니라 정보 탐색을 위해.
폭이나 깊이에 대해 최적화할지 여부는 특정 비즈니스 시나리오 또는 쿼리를 수행하는 사용자 페르소나에 따라 달라지며 이를 기반으로 사용자 정의할 수 있어요. 예를 들어, 소비자를 대상으로 하는 일반 연구 플랫폼은 처음에는 폭 넓은 검색을 최적화하는 데 더 관심이 있을 수 있으며, 사용자가 특정 주제를 더 깊이 탐색하고 있음을 발견하면 점점 더 깊이 있는 검색을 최적화할 수 있어요. 이와 대조적으로 변호사가 사용하는 내부용 법적 RAG 플랫폼은 처음부터 심층 검색에 더 최적화될 수 있죠. RAG의 개별 개인화는 검색 시스템이 사용자의 스타일과 선호도에 따라 폭이나 깊이를 최적화함으로써 구현될 수도 있답니다.
결론
그래프 구조는 답변 검색을 위한 폭과 깊이를 위한 수단을 만드는 데 도움이 돼요. 실제 재무 분석 사례를 사용하여 그래프 구조가 깊이와 폭 모두에서 보다 완전한 답변을 생성하는 데 훨씬 더 많은 영향력을 제공한다는 것을 확인했어요. 또한 정보 검색을 수행하기 위한 의미론적으로 일관되고 정확하며 결정론적인 방법을 만들죠. Vector Search와 함께 그래프 구조를 사용하면 높은 수준의 결정적이고 완전한 검색이 보장되며 이는 기업 작업 흐름에 매우 중요해요.
rag
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
두 번째 기조 연설 인터뷰에서는 Matt Cloyd가 무대에 올라 시민 기술과 그래프가 만나는 지점에서 어떤 일을 하는지 Jim과 이야기 나눴어요. 그는 분쟁 해결 및 정치적 폭력 분야에서 진행 중인 흥미로운 프로젝트에 대해서도 이야기했는데, 정말 모두에게 도움이 될 만한 일인 것 같았어요.
이 이야기도 한번 확인해 보세요! Jim은 Asurion의 Julie Fisher와 함께 인터뷰를 진행했답니다. 앞으로 더 많은 인터뷰가 공개될 예정이니 기대해주세요!
재밌게 봐주세요!
시민 기술 전문가 Matt Cloyd를 만나봐요
Jim Webber: 오늘 폐막 기조연설의 두 번째 게스트를 소개하게 되어 정말 기쁩니다. Matt Cloyd, 당신은 오랫동안 Neo4j 커뮤니티에 참여해 왔죠. 마지막 기조연설 전에 이 커뮤니티 사람들이 공통적으로 가진 것에 대해 이야기했는데요. 먼저 시민 기술과 그래프를 연결해서 어떤 일을 하는지 알려줄 수 있을까요?
Matt Cloyd: 물론이죠. 제가 생각하는 시민 기술은 적절한 규모의 기술을 사용해서 지역 사회가 여러 문제를 해결하도록 돕는 거예요. 저는 Code for Boston을 시작했는데요. 처음에는 5명에서 10명 정도의 작은 그룹이었지만, 지금은 보스턴 주변 도시와 협력하기 위해 기술, 디자인 시스템, 사고 연구 등과 같은 기술 관련 기술을 사용하는 데 관심 있는 수백 명의 커뮤니티로 성장했어요. 때로는 회의에 50명이나 모이기도 하죠. 저희는 정부 관료들과 협력해서 정부와 유권자 간의 관계를 개선하고, 정부가 더 나은 공무원이 되도록 돕고, 정부에 대한 사람들의 신뢰를 높이고 싶었어요. 결국 관계를 구축하는 게 가장 중요하죠. 그리고 이번 인터뷰를 하기에 아주 좋은 시기인 것 같아요. 왜냐하면 이번 주부터 미국 연방 디지털 에이전시 중 하나인 18F에서 컨설팅 엔지니어로 일하게 되었거든요.
Jim Webber: 정말 멋지네요! 축하해요!
Matt Cloyd: 감사합니다.
Jim Webber: 첫 주부터 방해해서 미안하네요.
시민 기술 전문가로서 그래프 기술을 어떻게 사용할까요?
Matt Cloyd: 아니에요, 오리엔테이션 훈련 중에 잠깐 쉬는 시간으로 딱 좋아요. 그래프는 저에게 우연히 다가왔어요. 제가 읽은 가장 영향력 있는 책 중 하나가 "생태 민주주의를 위한 디자인(Design for Ecological Democracy)"이라는 책인데, 환경의 지속 가능성, 대인 관계 형평성, 민주주의 전체 사이의 교차점을 다루고 있어요. 저에게 정말 강력했던 개념 중 하나는 커뮤니티의 특정 문제를 자세히 살펴보고 '누가 이 문제를 바꿀 힘을 가지고 있고, 그들과 연결된 사람은 누구이며, 의미 있는 변화를 만들기 위해 누구와 이야기해야 할까?'를 생각하는 파워 매핑 아이디어였어요. 그게 제가 처음 그래프를 시작할 때 영감을 받았던 부분 중 하나였죠.
Jim Webber: 정말 흥미로운데요? 상황을 더 좋게 바꾸기 위해 어떻게 권력에 연결하고, 어떤 영향력을 행사할 수 있을지 고민하는 거잖아요. 이제 그게 그래프 문제라는 게 명확해졌어요. 당신과 당신의 시민 정신을 가진 기술 팀에게도 그래프 문제가 분명했나요?
Matt Cloyd: 그게 바로 명확해졌는지는 모르겠어요. 저는 일반적인 컴퓨팅 교육을 받았고, 그래프 데이터베이스와 다른 그래프 관련 개념을 우연히 발견했을 때 비로소 두 가지가 연결되었다고 생각했어요.
Jim Webber: 흥미롭네요. 행운이 당신을 이끌었군요. 알아두면 좋겠어요. 우리 모두에게 행운이 따른다면 할 수 있을 거라고 생각해요. 기술 전문가들과 함께 일한다고 했으니 이제 조금 이해가 되기 시작했어요. 요즘 기술 전문가들은 그래프 기술에 꽤 익숙해진 것 같아요. 확실히 처음 시작했을 때보다 훨씬 친숙해졌죠. Neo4j조차도 Java Plus Maven 지옥이었던 시절이 있었죠. 제로 포인트 X 버전 같은... 하지만 요즘에는 정말 사용하기 편해졌다고 생각해요. Cypher는 적당한 기술적 배경을 가진 사람들에게 매우 친숙하고 생산적인 언어죠. 하지만 당신은 한 단계 더 나아가서 더욱 친숙한 언어로 특별히 설계된 Aspen이라는 언어를 사용하고 있잖아요. 그 언어에 대해 좀 더 이야기해 줄 수 있을까요?
결과를 얻기 위해 Aspen과 Cypher를 사용한 코딩
Matt Cloyd: 물론이죠. Aspen의 핵심은 일종의 그래프 데이터 생성을 위한 마크다운으로 설계되었다는 점이에요. 쿼리 언어가 아니에요. 그래프 데이터를 생성하려는 경우 Cypher는 약간 투박하게 느껴질 수 있지만, 쿼리 언어로는 정말 훌륭하죠. Aspen은 쿼리를 시도하는 언어가 아니라 그래프 데이터를 생성하려고 할 때 사용하는 언어예요.
그리고 이건 제가 2019년 가을에 들었던 수업에서 시작된 아이디어예요. 시민 기술 분야에서 일하다가 커뮤니티 의사 결정과 갈등 해결 방법에 대해 더 깊이 배우고 싶어서 갈등 해결 석사 학위를 받기로 결심했거든요. 평등과 평화를 촉진하는 방식으로 결정을 내리는 데 관심이 많았어요. 첫 수업에서 갈등 이론 개요를 배우면서 화이트보드에 갈등의 모든 요인과 당사자를 모델링하는 활동을 했는데, 화이트보드를 시작하자마자 '아, 이거 그래프 같은데?'라는 생각이 딱 들더라고요. 다른 사람이 화이트보드에 글을 쓰는 걸 보면서 '이걸 Neo4j에 넣을 수 있을까?' 하고 노트북을 켰죠. 계산 가능하고 분석 가능한 갈등 그래프를 갖는 게 정말 흥미롭지 않겠어요? 거기서부터 네트워크 분석이나 다른 것들을 할 수 있을지 궁금해졌어요.
그래서 바로 코딩을 시작해서 브라우저 콘솔에 직접 Cypher를 썼어요. 그런데 엔티티가 존재하는지 확인하고, 모든 걸 올바른 순서로 유지하고, 모든 별칭이 뭔지 기억하는 등 너무 구체적인 작업을 해야 하는 게 좀 답답하더라고요. 그래서 갈등에 대해 메모할 수 있다면 어떤 모습일까 상상하면서 언어를 스케치하기 시작했어요. 예를 들어, 제가 분쟁 지역의 연구원이고 이 사람이 저 사람과 어떻게 연결되어 있는지, 이 사람이 저 커뮤니티 리더와 어떻게 연결되어 있는지 알고 싶다고 가정해 볼게요. 일종의 파워 매핑인데, 약간 다른 각도에서 보는 거죠.
제가 작성하고 싶은 코드를 쓰기 시작했고, 간단한 언어를 만드는 방법에 대한 놀라운 블로그 게시물들을 발견했어요. 저는 언어 전문가는 아니에요. 그냥 Ruby 기반 웹 애플리케이션을 만들거든요. 그래서 관계에 대한 간단한 메모를 작성하고, 엔티티나 Node에는 괄호를 추가하고, Edge나 관계에는 대괄호를 추가하면 Aspen이 그걸 Cypher로 변환해서 Neo4j에 추가해주는 간단한 언어를 Ruby로 만들었어요.
짐 웨버: 아, 정말 멋진데요! 비슷한 이야기를 많이 들었는데, 저는 David Easley와 Jon Kleinberg의 책 *네트워크, 군중, 시장(Networks, Crowds, and Markets)*에 푹 빠져 있었어요. 그 책의 한 챕터에서는 제1차 세계 대전의 시작점을 그래프로 보여주는데, 우정과 적의 삼각형을 만들어내는 세 명의 황제 연맹에서 어떻게 진화했는지 설명하죠. 그러면서 "이게 제1차 세계 대전으로 발전하는 과정이야"라고 말하는데, 정말 놀라웠어요. 그래프가 그런 일도 할 수 있다니!
현대 시대와 현재 진행 중인 문화 전쟁을 생각하면, 이건 정말 특별한 종류의 갈등이기도 해요. 특히 Aspen은 북동부의 이웃인 하버드 정치학자 Sophie Hill에게 도움이 될 수 있을 것 같아요. 그녀는 "My Little Crony"라는 시스템을 운영하고 있는데, 정말 재밌는 말장난이죠. 제 생각에 Aspen 같은 건 정치 과학자들이 누가 누구에게 투표하는지, 누가 누구를 위해 돈을 받는지, 누가 선출되면 계약을 받는지 등을 이해하는 데 사용할 수 있을 거예요. 다른 분야의 전문가들에게도 그래프 기술을 개방할 수 있는 굉장한 방법이라고 생각해요. 말씀하신 것처럼, 몰스킨 책에 글을 쓰고 기적적으로 그 책에서 그래프를 얻을 수 있는 그런 종류의 일이죠. 정말 놀랍고 마음에 듭니다.
그래프를 처음 접했을 때 (사람을 따라가면서 Cypher를 입력하려고 할 때) 그래프용 새로운 DSL을 발명하게 된 건 꽤 야심찬 일이었죠. 당신의 경험을 바탕으로, 그래프에 익숙하지 않고 무엇을 할 수 있는지 알고 참여하고 싶어 하는 사람들에게 해주고 싶은 말이 있나요? 이전에 보낸 편지가 앞으로 나아가는 데 도움이 될까요?
어린 Matt에게 전하는 지혜의 말씀
맷 클로이드: 커뮤니티에서 따뜻하게 맞아주는 것만으로도 정말 큰 시작이라고 생각해요. 그래프 이론에 관한 책 몇 권을 읽는 것도 좋은 방법이고요. 제가 시작했던 방법이 바로 그거였어요. 어떻게 커뮤니티에 참여하게 됐는지 정확히 기억은 안 나지만, 커뮤니티의 누군가 (아마 Michael Hunger였던 것 같아요)가 어느 날 갑자기 저에게 이메일을 보냈던 것 같아요. 그 사람이 누군지도 몰랐는데, 정말 따뜻하게 맞아주면서 다른 몇몇 사람들과 연결해줬어요.
그리고 최근까지 커뮤니티 관리자였던 Karin [Wolok]에게도 정말 감사하다는 말씀을 드리고 싶어요. 그녀는 정말 환영해주고 적극적이었어요. 작년에 NODES에 참석한 모든 사람들에게 그랬을 거라고 생각해요. 그녀는 그냥 "어서 와서 공유할 것을 공유하고, 이 커뮤니티의 일원이 되어라"라고 말해줬어요. 그래서 제 조언은 그냥 커뮤니티에 뛰어들어서 어떤 방법으로든 사람들을 만나라는 거예요. 사람들은 정말 친절하고 도움을 주는 경향이 있거든요.
짐 웨버: 네, 저도 그렇게 생각해요. Neo4j 비즈니스의 많은 부분에서 우리는 항상 변화를 원하죠. 커뮤니티가 성장하기를 바라고, 규모도 커지기를 바라요. 커뮤니티가 엄청나게 성장했음에도 불구하고 변함없이 유지되는 것 중 하나는 모두가 여전히 정말 친절하다는 거예요.
맷 클로이드: 네.
짐 웨버: 제가 가본 기술 커뮤니티 중에서 가장 멋진 곳 중 하나예요. 다른 커뮤니티에 스며드는 것처럼 보이는 논쟁적인 성격도 없고, 매우 도움이 되죠. 사실 저도 마찬가지예요. 저에게 명확하지 않은 문제에 대한 답을 알고 싶을 때마다 커뮤니티에 참여해요. 항상 저를 도와주는 사람이 있는데, 부끄러울 수도 있지만 전혀 그렇지 않아요. 저는 그게 정말 좋아요. 커뮤니티는 정말 최고예요. 커뮤니티가 여러분을 도와준다면, 그래프를 사용해서 더 많은 일을 하길 바라요. 시민 기술 등 세계에서 그래프가 어디로 갈 거라고 생각하세요?
갈등 해결의 미래에 대한 그래프
맷 클로이드: 일반적으로 예측하기는 어렵겠지만, 제가 계획하고 있는 프로젝트 중 하나는 이번 여름에 분쟁 해결 분야 석사 학위를 마치는 거예요. 보스턴 UMass의 평화, 민주주의, 개발 센터를 통해 정치적으로 관련된 폭력에 대한 국가 최초의 조기 경고 및 조기 대응 시스템을 개발하는 그룹과 협력하고 있어요. 작년에 미국에서 일어난 모든 사건을 살펴보고, 전 세계 다른 나라에서 갈등 예측 및 예방 작업을 수행한 사람들의 전문 지식을 활용하는 것과 같아요.
우리는 기본적으로 데이터를 가져와서 예측하고, 가능한 정치적 갈등에 개입하기 위한 여러 가지 모델 중 하나로 그래프를 사용하는 방법을 검토하고 있어요. 지금은 매우 초기 단계이고, 이제 막 시작하는 단계예요. 아직 분석을 위해 그래프를 사용한 적은 없지만, 도시나 수도권 통계 지역 수준에서 데이터를 분석하고 싶기 때문에 정말 흥미롭고 거의 철학적인 작업을 하고 있죠.
그리고 이건 지금까지 문헌 검토에서 찾은 것보다 훨씬 더 자세한 분석이에요. 다른 사람들도 있을 수 있지만, 이런 식으로 접근하는 사람은 본 적이 없어요. 그래서 저희는 오레곤 주 포틀랜드에서 매일 밤 일어나는 시위와 관련된 상호 작용, 그리고 일련의 사건들을 살펴보고 있죠. 누가 참여하고 있는지, 어떻게 상호 작용하는지, 상호 작용의 질은 어떤지, 그리고 그게 더 큰 갈등을 키우는지 아니면 줄이는지 등을 분석하고 있어요. 이런 분석을 위해 어떻게 하면 이런 것들을 Graph Database에서 모델링할 수 있을지 고민을 많이 해야 해요. 아직 답은 없지만 정말 흥미로운 개념적 작업이죠. 앞으로 6~12개월 후에는 예측에 도움이 될 수도 있을 거예요. 완벽하진 않겠지만, 폭력으로 번지기 전에 개입해서 갈등을 줄일 수 있는 그래프 기반 분석을 갖게 되기를 희망해요.
짐 웨버: 와, 정말 유용한 케이스네요. Matt, 오늘 함께 해주셔서 정말 감사해요. 이렇게 가상으로 모시게 되어 기쁩니다. 앞으로 실제로 만날 기회가 있기를 바라요. 석사 논문, 새로운 직장, 그리고 이렇게 큰 분석 프로젝트에 참여해주셔서 정말 감사합니다. 진심으로 감사드리고, 앞으로도 잘 부탁드립니다.
맷 클로이드: 감사합니다!
Cypher
Nodes
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
Neo4j GraphRAG Python 라이브러리에 다음과 같은 강력한 새 기능이 추가되었어요. 바로 ToolsRetriever 클래스와 Retriever.convert_to_tool() 메서드랍니다. 이 기능 덕분에 라이브러리의 유연성이 훨씬 좋아졌어요. 이제 LLM이 작업에 가장 적합한 검색기를 똑똑하게 선택해서, 단일 쿼리에서 여러 검색기를 도구처럼 활용할 수 있게 되었거든요. 이번 블로그 포스팅에서는 이 기능이 왜 필요했는지, 어떻게 구현되었는지, 그리고 이걸 활용해서 어떻게 동적인 Retrieval-Augmented Generation(RAG) 애플리케이션을 만들 수 있는지 자세히 알아볼게요.
동기 부여: 유연하고 똑똑한 검색
RAG 시스템은 검색기를 사용해서 지식 기반에서 관련 데이터를 가져온 다음, LLM 응답에 필요한 맥락을 제공하죠. 보통은 쿼리 하나에 검색기 하나를 사용하는데, 쿼리마다 필요한 데이터 유형이나 검색 전략이 다를 수 있거든요. 예를 들어 "내일 일정"을 물어보는 쿼리에는 달력 기반 검색기가 필요할 거고, "내일 날씨"를 물어보는 쿼리에는 날씨 검색기가 필요하겠죠?
ToolsRetriever는 여러 검색기(도구)를 하나의 인터페이스로 묶어서 이런 문제를 해결해 줘요. 검색기를 직접 선택하는 대신, 시스템이 LLM을 사용해서 쿼리에 가장 알맞은 도구를 알아서 선택하는 거죠. 이렇게 추상화하면 개발 과정이 훨씬 간단해지고, RAG 파이프라인이 더 유연하고 효율적으로 바뀌어서 다양한 쿼리를 한 번에 처리할 수 있게 돼요.
게다가 Retriever.convert_to_tool() 메서드를 사용하면 Retriever 인터페이스를 따르는 모든 검색기를 ToolsRetriever와 호환되는 도구로 바꿀 수 있어요. 예를 들어, Semantic Search를 위한 VectorRetriever와 구조화된 그래프 쿼리를 위한 Text2CypherRetriever를 함께 사용하고 싶을 때 정말 유용하겠죠? 이 둘을 대체 또는 보완 메커니즘으로 활용할 수 있으니까요.
주요 특징
ToolsRetriever
ToolsRetriever는 여러 도구(도구로 변환된 검색기 포함)를 하나로 모으고, LLM을 사용해서 쿼리에 따라 어떤 도구를 호출할지 결정하는 새로운 클래스예요. Retriever 인터페이스를 따르기 때문에 기존 GraphRAG 클래스와도 문제없이 잘 연동돼서 엔드투엔드 RAG 워크플로우를 만들 수 있답니다.
ToolsRetriever를 사용하는 방법은 다음과 같아요.
from neo4j_graphrag.llm import OpenAILLM
from neo4j_graphrag.retrievers import ToolsRetriever
from neo4j_graphrag.graphrag import GraphRAG
import neo4j
# Hypothetical imports from a reader's file system
from my_tools import CalendarTool, WeatherTool
# Initialize tools and LLM
calendar_tool = CalendarTool()
weather_tool = WeatherTool()
llm = OpenAILLM()
driver = neo4j.GraphDatabase.driver(…)
# Create ToolsRetriever with multiple tools
tools_retriever = ToolsRetriever(
driver=driver,
llm=llm,
tools=[calendar_tool, weather_tool],
)
# Integrate with GraphRAG
graphrag = GraphRAG(
llm=llm,
retriever=tools_retriever,
)
# Perform a search
result = graphrag.search(query_text="Tell me about tomorrow", return_context=False)
이 예시에서 LLM은 "내일에 대해 말해 주세요"라는 쿼리에 CalendarTool, WeatherTool, 아니면 둘 다 필요한지 판단해서 가장 관련성 높은 데이터를 검색해 줄 거예요.
Retriever.convert_to_tool()
Retriever.convert_to_tool() 메서드를 사용하면 VectorRetriever나 Text2CypherRetriever처럼 어떤 검색기든 ToolsRetriever에서 사용할 수 있는 도구로 변환할 수 있어요. 다양한 검색 전략을 결합할 때 특히 강력하죠. 예를 들어 VectorRetriever는 Semantic Search에 뛰어나고, Text2CypherRetriever는 Neo4j 그래프에서 정확하고 구조화된 쿼리를 수행하는 데 더 적합하거든요.
검색기를 도구로 변환하는 예시를 한번 살펴볼까요?
from neo4j_graphrag.retrievers import VectorRetriever, Text2CypherRetriever
from neo4j_graphrag.retrievers import ToolsRetriever
from neo4j_graphrag.llm import OpenAILLM
from neo4j_graphrag.graphrag import GraphRAG
import neo4j
# Initialize retrievers and LLM
driver = neo4j.GraphDatabase.driver(…)
llm = OpenAILLM()
vector_retriever = VectorRetriever(driver, …)
text2cypher_retriever = Text2CypherRetriever(driver, …)
# Convert retrievers to tools
vector_tool = vector_retriever.convert_to_tool()
text2cypher_tool = text2cypher_retriever.convert_to_tool()
# Create ToolsRetriever
tools_retriever = ToolsRetriever(
driver=driver,
llm=llm,
tools=[vector_tool, text2cypher_tool],
)
# Use in GraphRAG
graphrag = GraphRAG(
llm=llm,
retriever=tools_retriever,
)
# Perform a search
result = graphrag.search(query_text="Find documents about AI and their authors", return_context=False)
이 경우 LLM은 쿼리의 의도에 따라 VectorRetriever (Semantic Search를 위해) 또는 Text2CypherRetriever (구조화된 쿼리를 위해)를 사용할지 결정하는 거예요.
구현 세부정보
ToolsRetriever
ToolsRetriever 클래스는 기존 Neo4j GraphRAG 프레임워크와 자연스럽게 통합되도록 설계되었어요. 주요 구현 세부 정보는 다음과 같아요.
LLM 기반 Tool 선택: ToolsRetriever는 LLM을 사용해서 쿼리를 분석하고 가장 적합한 Tool을 선택해요. 이렇게 하면 시스템이 쿼리 요구 사항에 맞춰서 동적으로 적응할 수 있죠.
Tool 이름 고유성: 구현 시 모든 Tool에 고유한 이름이 있는지 확인해서 Tool 선택 중에 충돌이 발생하지 않도록 유효성 검사를 포함하고 있어요.
일관된 결과 형식: ToolsRetriever는 Tool의 `RetrieverResult` 객체를 처리해서 각 검색기의 형식 지정 로직을 유지하면서 결과 형식이 일관되게 유지되도록 해요.
GraphRAG와의 통합: `Retriever` 인터페이스를 준수함으로써 ToolsRetriever는 GraphRAG 클래스의 다른 검색기에 대한 드롭인 대체품으로 사용할 수 있어요.
Retriever.convert_to_tool()
convert_to_tool() 메서드가 Retriever 기본 클래스에 추가되어서 모든 검색기를 Tool로 변환할 수 있게 되었어요. 구현의 주요 측면은 다음과 같아요.
추상 get_parameters() 메서드: 새로운 추상 메서드인 get_parameters()가 `Retriever` 기본 클래스에 추가되었기 때문에 모든 구체적인 검색기 클래스에서 해당 파라미터를 정의해야 해요. 이렇게 하면 Tool로 변환할 때 호환성이 보장되죠.
검색 방법 통합: convert_to_tool() 메서드는 검색기의 search() 검색기에 내장된 결과 포맷터를 활용해서 일관된 결과 포맷을 보장하는 방법이에요.
메타데이터 및 속성: 변환된 Tool은 메타데이터와 속성을 유지해서 데이터 소스의 추적성을 보장해요.
이점
동적 Tool 선택: LLM은 쿼리에 가장 적합한 Tool을 지능적으로 선택하므로 수동 검색기 구성의 필요성이 줄어들어요.
: 여러 검색기 (예: VectorRetriever, Text2CypherRetriever)를 Tool로 결합해서 하이브리드 검색 전략을 활성화할 수 있어요.
: ToolsRetriever는 기존 GraphRAG 프레임워크와 통합되어서 다른 구성 요소와의 호환성을 유지해요.
: convert_to_tool() 방법을 사용하면 모든 검색기를 Tool로 사용할 수 있으므로 시스템 확장성이 높아져요.
향상된 사용자 경험: Tool 선택을 추상화함으로써 검색기 로직 관리가 아닌 애플리케이션 구축에 집중할 수 있어요.
요약
ToolsRetriever 및 Retriever.convert_to_tool() 메서드는 Neo4j GraphRAG Python 라이브러리의 발전을 보여주는 좋은 예시라고 할 수 있어요. Tool로 여러 검색기의 동적 LLM 기반 선택을 활성화함으로써 이 기능은 RAG 파이프라인을 더욱 유연하고 강력하게 만들어 줘요. 다양한 데이터 소스가 필요한 애플리케이션을 구축하든, 다양한 검색 전략을 위한 폴백 메커니즘이 필요한 애플리케이션을 구축하든, 이 기능은 강력하고 확장 가능한 솔루션을 제공해 줄 거예요.
편집자 주: 이 프리젠테이션은 Geoffrey Horrell이 GraphConnect New York 2017년 10월에 진행한 내용이에요.
프레젠테이션 요약
Thomson Reuters는 지난 150년 동안 데이터를 수집해 왔는데요. 재무 분석 고객들이 어려움을 겪고 있다는 게 분명해졌어요. 두 가지 핵심 과제가 있었는데, 바로 데이터 사일로와 중요한 데이터 연결을 쉽게 찾아낼 수 있는 도구가 부족하다는 점이었죠.
이러한 문제점을 바탕으로 해결책을 찾기 위해 데이터 스택을 살펴봤어요. 그 결과 , Graph ETL, 그리고 중요한 데이터 분석이 필요하다는 걸 알게 되었죠. 바로 이 부분에서 Neo4j가 등장하게 된답니다. 덕분에 재무 분석가들이 데이터를 더 효과적으로 분석하고 중요한 실시간 결정을 내릴 수 있는 지능형 추천 엔진을 개발할 수 있었어요.
전체 프레젠테이션: 재무 분석가를 위한 지능형 추천 엔진
이번 블로그에서는 재무 분석가를 위한 성공적인 지능형 추천 엔진을 개발한 방법을 자세히 알아볼 거예요.
저는 Thomson Reuters의 혁신 부서에서 제품 인큐베이팅 업무를 담당하고 있어요. 기업가 정신으로 무장한 아이디어를 받아들여 수십억 달러 규모의 대기업을 스타트업 시대로 이끌려고 노력하죠. 새롭고 흥미로운 것들을 만들고 창조하는 일을 하고 있는데, 오늘은 그중 하나에 대해 이야기해 보려고 해요.
GraphConnect로 향하는 여정은 고객의 의견을 경청하고 가장 시급한 문제를 파악하는 것에서 시작되었어요. 그리고 나서 Knowledge Graph를 구축하고 를 활용했죠.
고객 문제 식별
세계 최대 금융 기관의 최고 기술 책임자(CTO)들과 함께 금융 서비스 원탁회의를 열고, 익명으로 가장 큰 과제가 무엇인지 물어봤어요. 그들이 직면한 가장 큰 문제는 데이터 사일로 때문에 데이터를 식별하고 연결하기 어렵다는 것이었죠.
저희 고객 중 일부는 조직 내에 20,000~100,000개의 데이터 사일로를 가지고 있다고 해요. 정말 놀라울 정도로 복잡하죠?
제가 CTO라면 기술 변화는 당연하다고 생각하기 때문에 유연한 솔루션을 원할 거예요. 레거시 시스템에 연결하면서 클라우드로 이동할 수 있는 기능도 중요하겠죠. (물론, 분석가들이 쉽게 사용할 수 있는 플랫폼을 제공하는 것도 빼놓을 수 없고요.)
다음 단계는 재무 분석가에게 직접 물어보는 거였어요. "무엇이 당신의 하루를 힘들게 하나요?"
분석가들은 신뢰할 수 있고 정확한 데이터를 수집하는 데 약 35%의 시간을 쓴다고 답했어요. 사실 데이터 작업에는 훨씬 더 많은 시간이 필요하지만, 이 작업에만 추가로 시간을 할애할 여유가 없는 거죠.
게다가 분석가들은 예전보다 더 많은 기업을 다루게 되면서, 기존과 동일한 도구에 의존하게 되어 정보 과부하가 발생하고 있어요. 이 때문에 데이터를 검토하고 정확한 권장 사항을 제공하는 것이 점점 더 어려워지고 있죠. 이벤트를 어떻게 추적해야 할까요? 텍스트 전체에서 키워드 검색을 하는 건 별로 효과가 없어요. 특히 받은 편지함에 디지털 문서가 쌓여있는 경우에는 더욱 그렇고요.
솔루션 식별
고객과의 대화를 통해 두 가지 주요 문제점을 확인했어요. CTO가 지적한 고립된 데이터와 재무 분석가가 지적한 데이터 과부하, 이 두 가지였죠. 해결책은 사용자 중심 분석 도구를 맨 위에 배치하여 기업을 위한 Knowledge Graph를 개발하는 것이었어요.
데이터 기술보다 데이터 자체에 중점을 두는 빅 데이터 전략이 얼마나 많은지 놀라울 정도예요. 하지만 핵심은 데이터라는 거죠.
스택의 두 번째 부분에서는 그래프 ETL을 통해 얻을 수 있는 유용한 재무 데이터 통찰력을 제공하기 위해 데이터를 신중하게 연결하고, 연결하고, 결합할 수 있어요. 그리고 스택의 세 번째 부분에서는 정말 유용한 도구를 제공할 수 있는 방법을 찾을 수 있도록 재무 분석가에 대해 고민해야 해요.
그래프 스택의 구성 요소를 자세히 살펴볼까요?
Knowledge Graph
Thomson Reuters에 대한 간략한 배경 설명이에요.
저희는 100개국에 50,000명의 직원을 두고 있으며, 매일 수백만 비트의 데이터를 수집하고 데이터베이스화하는 데 많은 시간을 투자하고 있어요. 고도로 구조화되고 정규화된 콘텐츠 분석가, 인간 전문 지식, 대규모 파트너 네트워크, 텍스트 및 구조화된 데이터에 대한 이해를 제공하고 있죠.
저희는 15년 넘게 뉴스와 구조화된 텍스트에서 Natural Language Processing (NLP)를 활용해 왔어요. 아래 슬라이드 왼쪽에 보이는 것처럼요.
저희는 모든 콘텐츠를 추출해서 재무 분석 세계가 어떻게 돌아가는지 잘 설명된 분류 체계, 즉 Knowledge Graph (위의 원으로 표시된)를 통해 사람, 위치, 이벤트, 도구 같은 핵심 개체에 연결해요. 이 데이터를 자체 엔터프라이즈 애플리케이션으로 가져올 수 있죠.
모든 메타데이터에는 변경되지 않는 고유 식별자가 있어서 데이터를 연결하고 결합할 수 있어요. 저희는 고객이 동일한 툴킷에 액세스할 수 있도록 15년 동안 구축해 온 NLP 시스템을 제공하고 있답니다.
다음은 연결하려는 몇 가지 기본 데이터예요.
이건 회사가 실제로 뭘 하고 있는지 이해하는 데 도움이 될 수 있는 회사 주변의 전략적 관계를 보여줘요. 경영진이 말하는 내용과 현실은 다를 수 있는데, 그래프를 보면 그걸 파악할 수 있는 거죠.
Knowledge Graph에 포함된 데이터 유형은 다음과 같아요.
600만 개 조직
3백만 명의 임원과 이사. 이 데이터는 1980년대 중반까지 거슬러 올라가고, 모든 공개 회사의 임원 및 이사와 함께 전체 업무 이력 및 근무했던 회사가 포함돼요.
전 세계 모든 시장에 상장된 1억 2,500만 개의 지분 상품이 고도로 정규화되고 설명된 방식으로 구성되어 있어요.
데이터에 의미와 맥락을 더하는 국가, 지역, 도시 등 7,500만 개의 메타데이터 개체
질문에 답하는 정보와 2억 개의 전략적 관계: 나의 경쟁자는 누구인가? 내 공급자는 누구인가? 이 신제품을 만들기 위한 합작 투자 회사는 누구인가? 동맹자는 누구인가? 나는 어떤 업종에 종사하고 있나? 이 조직의 가계도는 무엇인가?
저희 Knowledge Graph를 통해 전문 고객에게 매일 전달하는 데이터예요. 약 20억 개의 RDF 트리플과 1,300억 개의 경로를 나타내죠. 꽤 크고, 이걸로 할 수 있는 일이 정말 많아요.
Graph ETL
Knowledge Graph는 저희가 제공하는 핵심 자산이지만, 이건 시작일 뿐이에요. 기초를 제공하지만, 다음으로는 모든 정보를 전달하는 도구가 필요하죠.
우리는 내부 그래프 저장 시스템에서 의미가 포함된 Knowledge Graph를 추출해서 전달해요. 생성하려는 Property Graph의 Nodes와 Relationships, 그리고 이러한 Relationships를 중심으로 데이터를 모델링하는 방법에 대해 생각해야 하기 때문에 변환 단계도 정말 중요하죠. 우리 데이터 융합 플랫폼 내에서 이러한 다양한 데이터 세트를 연결하고 결합할 수 있어요.
마지막 단계는 데이터를 서로 연결하고 결합하고 연결하는 거예요. 우리는 고객이 보유하고 있는 기본 데이터 세트의 모든 조직이 Thomson Reuters에서 제공되는 데이터와 일치하는지 확인해요. 이러한 연결이 정확하지 않으면 많은 잘못된 일치와 중복이 발생하므로 일치와 연결이 절대적으로 중요하죠. 이것이 바로 우리 데이터 융합 제품이 하는 일이에요.
Knowledge Graph 위에 있는 데이터 관리 계층인 데이터 융합을 빠르게 살펴볼게요.
그 안에서 엔터티 유형(예: 조직인지, 사람인지 등)을 결정할 수 있어요. 이를 설정할 수 있으며 나머지 데이터와 결합할 엔터티는 다음과 같아요.
이 경우에는 조직에 연결되는 6개의 서로 다른 데이터 소스와 "사람" 엔터티 유형에 연결되는 3개의 데이터 소스가 있어요.
그런 다음 모든 개별 데이터 소스가 스트리밍돼요.
이들은 모두 실시간으로 스트리밍되며 핵심 엔터티에 대해 Index가 생성되고 결합돼요.
이 경우에는 학업 자격, 장교 정보 및 개인 정보를 포함하는 인물 데이터가 있어요. 우리 데이터 관리 플랫폼 내에서 핵심 Property Graph Node에 연결할 부분, 해당 Node 또는 Edge의 속성으로 가질 부분, 연결하지 않고 남겨둘 부분을 결정할 수 있어요.
이는 고객이 요구하는 데이터를 관리하기 위한 유연한 관리 도구를 제공해요. 또한 데이터 융합에서 데이터를 가져오는 API와 데이터를 시각적으로 탐색할 수 있는 탐색기 도구도 있어요.
이는 우리가 만든 데이터 관리 플랫폼에 대한 창을 제공하지만 아직 분석을 제공하지는 않아요. 데이터를 결합하고, 연결하고, 병합하는 것은 다음 단계를 위해 매우 중요해요. 이는 그래프 스택에 추가되는 가치이며 특히 데이터 분석가에게는 더욱 그렇겠죠.
분석 제공
그래프 분석 구성 요소를 개발하는 것은 약간 흥미로워요.
Take One에서는 분석을 나머지 데이터와 함께 ETL 계층에 넣었지만 작동하지 않았어요. Take Two에서는 인메모리 그래프 시스템이 매우 빠르기 때문에 작업해 보았지만, 정적이어서 지속적으로 이동하고 업데이트되는 데이터가 있는 경우에는 작동하지 않아요. Take Three에서는 다른 Graph Database를 사용해 보았으나 효과가 없었어요(이에 대해서는 더 이상 언급하지 않겠어요). 그리고 마침내 Take Four를 통해 우리는 를 선택했어요.
우리가 Neo4j를 선택한 세 가지 주요 이유가 있어요.
첫 번째는 커뮤니티가 훌륭하다는 것이에요. 우리는 Emil과 이벤트 수, 개발자 수, 고객 기반의 엄청난 채택률에 대해 이야기했죠.
게다가 지원도 놀라워요. 우리는 가입하자마자 계약 체결 후 몇 시간 내에 문제를 해결하는 개발자와 Slack 채널을 가졌어요. 기업 고객은 Neo4j로부터 환상적인 지원을 받아요. 또한 Neo4j가 작동한다는 점을 강조하고 싶어요. 빠르고 성능이 뛰어나며 필요한 작업을 수행하죠.
Neo4j를 사용하는 방법을 살펴볼게요.
저희는 Amazon Web Service 사용자 환경에 넣어서 사용하고 있어요. Bolt Protocol과 정말 놀라운 데이터베이스 언어인 Cypher를 함께 사용하는데, 문법이 정말 간결하면서도 강력하답니다.
저희는 엄청난 양의 태그된 뉴스와 추가적인 관계를 포함하는 데이터 융합 계층에서 데이터를 가져와요. 모든 데이터를 정말 빠르게 로드한 다음, 매칭하고 새로운 인스턴스에 연결할 수 있죠. 그런 다음 다양한 최단 경로 계산을 실행하고, 고객은 결과를 필터링하기 위한 기본 설정을 지정해요.
잠시만요! 여기서 우리가 하려는 일이 정확히 뭔지 한번 이야기해볼까요?
앞서 말씀드렸듯이, 재무 분석가들은 끊임없이 뉴스를 접하고 이를 자신의 포트폴리오에 추가하죠. 그리고 그들은 해당 포트폴리오 아래에 모든 관련 고객, 공급업체, 합작 투자, 제휴 및 가계도가 있다는 것을 알고 있지만, 그 모든 정보를 놓치고 있어요. 저희의 임무는 정보 과부하를 주지 않으면서 해당 정보를 보여주는 거예요.
이를 위해 뉴스에 태그를 지정해서 해당 뉴스가 특정 고객과 얼마나 관련성이 있는지 확인하고, 뉴스 기사에 신뢰도 점수를 할당해요. 다음으로, 전체 Knowledge Graph의 맥락에서 우리 자신의 Knowledge Graph의 하위 그래프를 살펴보고, 그것이 전달되는 다른 모든 뉴스 기사와 어떻게 연결되는지 확인하죠. 최종 사용자는 해당 관계의 유형과 범주를 결정하고 점수를 매기게 돼요.
다음은 일주일 간의 데이터에 대한 일반적인 스냅샷이에요.
일반적으로 특정 주에 수천 개의 뉴스 기사가 게시되는데, 저희는 뉴스 기사에서 언급된 회사의 관련성을 결정하는 알고리즘은 물론 전략적 관계와 두 단계 떨어진 회사에 대한 분석도 갖추고 있어요. 일반적인 포트폴리오는 200개 정도의 기업으로 구성되니까, 해당 기업과 관련된 모든 데이터 관계를 분석하고 결과를 점수화한 후 스트리밍 사용과 연결해서 그래프를 반환하는 거죠.
이를 위해서는 약 800,000개의 최단 경로 계산을 동시에 실행해야 하고, 특정 순간에 제품을 사용하는 여러 고객이 있어요. 각 개별 계산에는 약 10초가 소요되는데, 이는 저희가 시도한 다른 옵션보다 훨씬 빠르지만, 전체 작업을 훨씬 더 빠르게 만드는 방법을 계속 연구하고 있답니다.
추천 엔진 데모
다음은 추천 엔진이 실시간으로 작동하는 방식을 보여주는 데모 영상이에요.
이건 현재 저희를 위한 프로토타입이고, Knowledge Graph와 Graph Database 분석의 힘을 보여주기 위해 고객과 함께 사용하고 있는 거예요.
그래프에 대해 이야기할 때, 사용자들은 그래프를 탐색하고 싶어한다고 생각하지만 그렇지 않은 경우가 많아요. 대부분의 경우 그들은 단지 질문에 대한 답변을 원하죠. 시간을 절약하고 귀중한 통찰력을 얻는 데 도움이 되는 계산을 원하는 거예요. 바로 이것이 그래프가 제공하는 가치랍니다.
이 백서를 다운로드하세요. 지속 가능한 경쟁 우위: 데이터 관계를 통해 비즈니스 가치 창출, 그리고 귀하의 회사가 Graph Database 기술을 사용해서 경쟁에서 앞서나갈 수 있는 방법을 알아보세요.
금융 데이터 통찰력
GraphConnect
Natural Language Processing
Property Graph
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
Google의 Genkit 프레임워크를 사용하여 그래프 기반 벡터 저장, 의미 체계 검색, 고급 지식 그래프 애플리케이션을 활용하는 방법에 대한 종합 가이드
Genkit x Neo4j
Genkit x Neo4j: AI 데이터 검색 발전
AI 에이전트가 더욱 복잡해짐에 따라 기존 벡터 데이터베이스는 다중 홉 추론 및 구조화된 관계로 어려움을 겪는 경우가 많습니다.그래프RAG(Graph Retrieval-Augmented Generation)은 LLM의 의미론적 이해와 지식 그래프의 연결된 특성을 병합하여 이러한 제한 사항을 해결합니다. 보다자세한 내용은
구글 젠킷확장 가능한 플러그인 생태계를 통해 AI 애플리케이션 개발을 단순화하는 오픈 소스 프레임워크입니다. Neo4j 플러그인은 기본 벡터 검색을 Genkit과 통합하여 순회 가능한 관계를 유지하면서 문서를 노드로 저장할 수 있습니다. 이는 의미론적 유사성과 구조적 컨텍스트가 모두 필요한 GraphRAG 파이프라인에 이상적입니다.
이 가이드에서는 기본 의미 검색부터 고급 GraphRAG 토폴로지 및 영구 채팅 메모리까지 이동하는 전체 통합 프로세스를 다룹니다.
1. 설치 및 전제조건
시작하려면 먼저 Node.js 또는 TypeScript 환경을 설정해야 합니다. 통합은 Genkit의 핵심 라이브러리, 특정 Neo4j 플러그인, 임베딩 제공자(이 예에서는 Google AI를 사용함) 및 공식 Neo4j JavaScript 드라이버에 의존합니다.
또한 실행 중인 Neo4j 인스턴스도 필요합니다. 이는 로컬 Docker 컨테이너, Neo4j Desktop 인스턴스 또는 클라우드 호스팅 Neo4j AuraDB 인스턴스일 수 있습니다. Neo4j 버전이 벡터 검색을 지원하는지 확인하세요(버전 5.26+가 권장되지만 나중에 살펴보겠지만 버전 2026.01+는 훨씬 더 강력한 기본 필터링 기능을 잠금 해제합니다).
2. 플러그인 및 연결 구성 초기화
Genkit 인스턴스를 생성할 때 플러그인을 초기화하세요. 적어도 indexId와 embedder를 제공해야 합니다. 플러그인은 Genkit의 추상화 레이어와 그래프에 대해 실행되는 기본 Cypher 쿼리 사이의 브리지 역할을 합니다.
import { genkit } from 'genkit';
import { neo4j } from 'genkitx-neo4j';
import { googleAI } from '@genkit-ai/google-genai';
const ai = genkit({
plugins: [
googleAI(),
neo4j([
{
indexId: 'my-vector-index',
embedder: googleAI.embedder('gemini-embedding-001'),
},
]),
],
});
Neo4j 색인과 사용하려는 임베딩 모델을 지정해야 합니다.
연결 자격 증명 관리
다음 두 가지 방법으로 Neo4j 연결을 구성할 수 있습니다.
1. 환경 변수 사용:매개변수가 명시적으로 전달되지 않으면 플러그인은 시스템에서 다음 환경 변수를 찾습니다.
NEO4J_URI=bolt://localhost:7687 # Neo4j's binary protocol
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=password
NEO4J_DATABASE=neo4j # Optional: specify database name
# ..And other additional keys, like GOOGLE_GENAI_API_KEY=<apiKey>
2. 사용하기clientParams 옵션:초기화 중에 코드에서 직접 연결 구성을 전달할 수 있습니다.
그래프 데이터베이스를 벡터 저장소로 사용하는 주요 이점은 의미론적 검색과 구조적 그래프 기능을 결합한다는 것입니다. 실제 애플리케이션에서는 빈 데이터베이스로 시작하는 경우가 거의 없습니다. :Product, :Employee 또는 :Article과 같은 노드가 있는 기존 스키마가 있을 수 있습니다.
사전 정의된 스키마로 제한되는 대신 사용자 정의 노드 레이블, ID 필드, 텍스트 및 임베딩에 대한 속성을 사용하도록 플러그인을 구성할 수 있습니다. 이를 통해 기존 Neo4j 도메인 모델에 임베딩을 원활하게 통합할 수 있습니다.
예를 들어 다음과 같은 수집을 수행할 수 있습니다.
import { genkit, Document } from 'genkit';
import { neo4j, neo4jIndexerRef, neo4jRetrieverRef } from 'genkitx-neo4j';
import { googleAI } from '@genkit-ai/google-genai';
// 1. Initialization with custom mappings
const ai = genkit({
plugins: [
googleAI(),
neo4j([
{
indexId: 'custom-entities-idx',
embedder: googleAI.embedder('gemini-embedding-001'),
// clientParams can be omitted if environment variables are set
// Define your domain-specific schema mapping here:
label: 'Article',
textProperty: 'bodyContent',
embeddingProperty: 'semanticVector',
idProperty: 'articleId',
},
]),
],
});
// 2. Ingestion over custom schema
async function ingestCustomArticles(ai: any) {
const INDEXER_REF = neo4jIndexerRef({ indexId: 'custom-entities-idx' });
const doc = new Document({
content: [{ text: 'The integration of Genkit and Neo4j enables advanced GraphRAG.' }],
// metadata keys must match the idProperty defined in the config (articleId)
metadata: {
articleId: 'art-001',
author: 'Giuseppe Villani'
},
});
await ai.index({
indexer: INDEXER_REF,
documents: [doc],
});
console.log('Article indexed successfully using custom schema.');
}
결과는 다음과 같습니다.
이 구성을 사용하여 문서의 색인을 생성하면 플러그인은 병합을 위해 기사 ID를 사용하고 bodyContent에 텍스트를 저장하는 :Article 라벨을 대상으로 하는 Cypher 쿼리를 실행합니다.
의미론적 검색은 만능이 아닙니다. 때로는 정확한 키워드 일치가 필요하거나(예: 벡터 거리가 거짓 긍정을 생성할 수 있는 "TX-9000"과 같은 특정 제품 ID 검색) 엄격한 기준에 따라 결과를 필터링해야 합니다(예: 상태 = 'ACTIVE'인 문서만 반환).
4.1 메타데이터 필터링(Neo4j 2026.01+ 구문)
플러그인은 고급 메타데이터 필터링을 지원하므로 검색 쿼리에 의미론적 유사성과 함께 구조화된 제약 조건을 포함할 수 있습니다.
MatchSearchClauseStrategy를 사용하여 플러그인은 Neo4j 2026.01에 도입된 새로운 벡터 검색 구문(MATCH (n) SEARCH n IN VECTOR INDEX)을 활용합니다. 이를 통해 기본 인덱스 내 필터링이 가능해 쿼리 속도가 훨씬 빨라집니다. 사후 필터링(상위 K 벡터를 검색하고then필터링하여 잠재적으로 0개의 결과를 반환함), 인덱스 내 필터링은 메타데이터 조건을 평가합니다.~ 동안벡터 순회.
See 이 기사자세한 내용은
성능을 최적화하려면 filterMetadata를 전달하여 Neo4j에 해당 필드에 대해 특별히 인덱스 구조를 구축하도록 명시적으로 지시할 수 있습니다.
하이브리드 검색은 정확한 전체 텍스트 키워드 일치와 벡터 검색의 의미 순위를 혼합합니다. 이는 전체 순위에 대한 의미론적 추론을 활용하면서 쿼리에 정확하게 일치해야 하는 도메인별 전문 용어, 부품 번호 또는 정확한 이름이 포함된 경우 특히 유용합니다.
// 1. Initialization with Hybrid Search enabled
neo4j([
{
indexId: 'hybrid-search-idx',
embedder: googleAI.embedder('gemini-embedding-001'),
searchType: 'hybrid', // Enables both vector and full-text keyword retrieval
fullTextIndexName: 'custom-fulltext-index', // Optional
// A static keyword appended to every full-text search query.
// Useful to scope results to a specific domain by default.
fullTextQuery: 'documentation',
},
])
// .. embedding operations
// 2. Retrieval using Hybrid Search
const RETRIEVER_REF = neo4jRetrieverRef({ indexId: 'hybrid-search-idx' });
const docs = await ai.retrieve({
retriever: RETRIEVER_REF,
query: query,
options: { k: 5 },
});
return docs;
참고: 메타데이터 필터링은 아직 하이브리드 검색 접근 방식과 함께 사용할 수 없습니다. 통과를 시도 중필터: {…} 동안searchType: '하이브리드'가 활성화되면 오류가 발생합니다.
// !! This will throw at runtime:
// "Metadata filtering can't be use in combination with a hybrid search approach."
const docs = await ai.retrieve({
retriever: RETRIEVER_REF,
query: 'some query',
options: {
k: 10,
filter: { status: 'active' }, // ← NOT allowed with hybrid search
},
});
4.3 사용자 정의 검색 쿼리 및 그래프 순회
표준 벡터 유사성은 복잡한 추론에 필요한 구조적 맥락을 포착하지 못하는 경우가 많습니다. retrievalQuery 매개변수를 사용하면 벡터 검색과 그래프 순회 및 집계를 결합하는 맞춤 Cypher 쿼리로 기본 검색 논리를 재정의할 수 있습니다.
이 접근 방식은 관련 노드를 포함하도록 컨텍스트 창을 확장하는 데 매우 효과적입니다. 예를 들어 단순히 문서의 텍스트를 검색하는 대신 그래프를 탐색하여 작성자의 약력 및 작성자가 작성한 기타 관련 기사를 포함하여 LLM에 소스에 대한 보다 포괄적인 배경을 제공할 수 있습니다.
// 1. Initialization with Advanced Graph Traversal Retrieval
neo4j([
{
indexId: 'custom-query-idx',
embedder: googleAI.embedder('gemini-embedding-001'),
// We navigate from the retrieved 'node' to its Author
// and collect other documents written by the same person.
retrievalQuery: `
MATCH (node)-[:AUTHORED_BY]->(author:Author)
OPTIONAL MATCH (author)<-[:AUTHORED_BY]-(other:Document)
WHERE other <> node
RETURN node.text AS text,
{
authorName: author.name,
authorBio: author.bio,
otherWorks: collect(other.title)[0..3]
} AS metadata
`
},
])
// ... embedding and retrieval
5. GraphRAG 기능: 컨텍스트 확장
플러그인은 기본적으로 고급 번들을 번들로 제공합니다.그래프RAG전략. 이러한 전략은 그래프의 연결된 특성을 활용하여 단순한 벡터 유사성에 비해 LLM에 훨씬 더 풍부한 컨텍스트를 제공합니다.
부모-자식 리트리버
상위-하위 전략은 조밀하고 정확한 벡터 일치를 위해 문서를 더 작은 하위 청크로 분할하지만 더 넓은 컨텍스트('상위' 문서 또는 청크)를 검색하여 LLM에 제공합니다.
이것이 왜 중요합니까? 작은 응집력 있는 텍스트 덩어리는 정확한 검색을 위한 최상의 벡터 임베딩을 생성하지만 LLM에 아주 작은 문장만 제공하면 주변 컨텍스트가 부족하여 환각을 일으키는 경우가 많습니다. 이 전략으로 문제가 해결되었습니다. 플러그인은 이 토폴로지에 따른 데이터를 자동으로 수집하기 위한 특정 도구(parentChildIngestor)를 제공합니다.
import { neo4jParentChildRetrieverRef } from 'genkitx-neo4j';
async function useParentChildGraphRag(ai: any, userQuery: string) {
const INDEX_ID = 'graphrag-index';
// 1. Ingest Data using the bundled Genkit Tool
// NOTE: Ensure 'llm-chunk' is installed in your project for this tool to work
const ingestorTool = ai.tool(`neo4j/${INDEX_ID}/parentChildIngestor`);
await ingestorTool({
documents: [{ text: "Massive corporate document text...", metadata: { source: "internal" } }]
});
// 2. Retrieve using Parent-Child strategy
const PC_RETRIEVER_REF = neo4jParentChildRetrieverRef({ indexId: INDEX_ID });
const parentDocs = await ai.retrieve({
retriever: PC_RETRIEVER_REF,
query: userQuery,
options: { k: 3 }
});
return parentDocs;
}
// .. useParentChildGraphRag(..) execution
5.1 가설 질문 검색기(HyDE)
HyDE는 LLM을 사용하여 먼저 사용자 쿼리에 대한 가상의 이상적인 답변을 생성한 다음 생성된 텍스트를 사용하여 벡터 공간을 쿼리합니다. 이는 사용자의 잠재적으로 모호한 질문을 대상 문서에서 사용되는 정확한 어휘로 매핑합니다.
완전히 사용자 정의된 다중 홉 그래프 검색 전략(예: 노드 찾기 및 모든 "형제" 반환)을 정의할 수 있습니다.
import { neo4jCustomRetrieverRef } from 'genkitx-neo4j';
// 1. Define custom Cypher traversal during initialization
neo4j([
{
indexId: 'custom-rag-index',
embedder: googleAI.embedder('gemini-embedding-001'),
customGraphRagConfigs: {
'sibling-search': {
systemPrompt: "Use the sibling documents to answer the question.",
idMetadataKey: "docId",
cypherIdParamName: "startIds",
cypherQuery: `
MATCH (start:Document)-[:SIBLING_OF]->(sibling:Document)
WHERE start.id IN $startIds
RETURN sibling.text AS siblingText
`,
cypherReturnTextField: "siblingText"
}
}
},
])
// 2. Execute retrieval
async function useCustomGraphRag(ai: any, userQuery: string) {
const CUSTOM_RAG_REF = neo4jCustomRetrieverRef({
indexId: 'custom-rag-index',
name: 'sibling-search'
});
const customRagDocs = await ai.retrieve({
retriever: CUSTOM_RAG_REF,
query: userQuery,
options: { k: 3 }
});
return customRagDocs;
}
// .. useCustomGraphRag(..) execution
5.3 내부적으로: 프로그래밍 방식의 GraphRAG API
Genkit 도구(ai.tool) 또는 플러그인 구성에 의존하는 것이 표준 애플리케이션에 권장되는 경로이지만, 특히 사용자 정의 ETL 파이프라인을 구축하거나 외부 오케스트레이션 시스템과 통합할 때 더욱 세부적인 제어가 필요할 수 있습니다.
플러그인은 기본 유틸리티 클래스인 ParentChildRetriever, HypotheticalQuestionRetriever 및 GenericGraphRagRetriever를 노출하여 이를 동적으로 인스턴스화하고 표준 Genkit 검색기 추상화를 우회하여 프로그래밍 방식으로 수집 또는 검색을 트리거할 수 있습니다.
GenericGraphRagRetriever는 기본 Neo4j 드라이버를 반환하는 getNeo4jInstance()도 노출합니다. 이는 동일한 파이프라인의 일부로 원시 Cypher 쿼리를 실행해야 하는 고급 시나리오에 유용합니다. 예를 들어 검색 전에 인덱싱된 노드 간의 그래프 관계를 수동으로 생성해야 합니다.
프로그래밍 방식 수집:번들로 제공되는 Genkit 도구를 사용하는 대신, 검색기를 직접 인스턴스화하고 ingestDocument() 메서드를 호출할 수 있습니다:
메시지라벨: (선택 과목)스레드 내의 개별 메시지 노드에 할당된 노드 레이블을 사용자 정의합니다. 기본값은 '메시지'입니다.
nextMessageRelType: (선택 과목)메시지를 연대순 선행 메시지(채팅 기록의 링크 목록 형성)에 연결하는 암호 관계 유형을 정의합니다. 기본값은 'NEXT'입니다.
lastMessageRelType: (선택 과목)기본 세션 노드를 가장 최근 메시지에 직접 연결하는(스레드의 헤드 역할을 하는) 암호화 관계 유형을 정의합니다. 기본값은 'LAST_MESSAGE'입니다.
플러그인은 Neo4jSessionStore를 제공하여 Neo4j에 기본적으로 매핑된 강력한 세션 지속성 계층을 설정합니다. 모듈 모델 대화는 연결된 그래프((:Session)-[:LAST_MESSAGE]->(:Message)<-[:NEXT]-(:Message))로 전환되어 상태 지속성을 부여하고 쉽게 조정 가능한 컨텍스트 제한 및 장기적인 대화 분석을 제공합니다.
setWindowSize(n)를 사용하면 컨텍스트 창에 삽입되는 기록 메시지의 양을 제한하여 전체 기록을 그래프에 안전하게 저장하는 동시에 LLM 토큰 부풀림을 방지할 수 있습니다.
참고: setWindowSize(n)는 컨텍스트에서 유지할 대화 차례(즉, 사용자 - 보조 메시지 쌍) 수를 정의합니다. 6개 메시지 스레드에서 2로 설정하면 마지막 4개 메시지(2턴 × 2개 메시지)가 반환됩니다.
import { Neo4jSessionStore } from 'genkitx-neo4j';
async function startPersistentChat(ai: any, sessionId: string, userMessage: string) {
// 1. Initialize the Neo4j backed session memory
const neo4jStore = new Neo4jSessionStore({
url: '<connection URI>',
username: '<username>',
password: '<password>',
});
// 2. Control Token Bloat: Only feed the last 10 messages into the LLM context
neo4jStore.setWindowSize(10);
// 3. Initialize the chat session
const chat = ai.chat({
model: 'googleai/gemini-2.5-flash',
store: neo4jStore,
sessionId: sessionId
});
// 4. Send message and persist to Graph
const response = await chat.send(userMessage);
console.log(response.text);
}
// .. startPersistentChat(..) execution
기존 애플리케이션 스키마에 맞게 노드 레이블과 관계 유형을 사용자 정의할 수 있습니다. 사용자의 세션 기록을 프로그래밍 방식으로 지울 수도 있습니다.
import { Neo4jSessionStore } from 'genkitx-neo4j';
async function manageChatSessions() {
// Custom schema configuration
const customStore = new Neo4jSessionStore({
url: 'bolt://localhost:7687',
username: 'neo4j',
password: 'password',
sessionLabel: 'AppSession', // Defaults to 'GenkitSession'
messageLabel: 'ChatMessage', // Defaults to 'Message'
nextMessageRelType: 'THREAD_NEXT', // Defaults to 'NEXT'
lastMessageRelType: 'THREAD_HEAD' // Defaults to 'LAST_MESSAGE'
});
const sessionId = 'user-123-session';
// Programmatically clear/delete all messages and relationships for a session
await customStore.clear(sessionId);
console.log(`Session ${sessionId} has been wiped.`);
}
// .. manageChatSessions(..) execution
6.1 수동 세션 관리
때때로 상점을 ai.chat()에 직접 전달하는 것만으로는 충분하지 않습니다. 분리된 프런트엔드와 통합하거나 기록 스레드 데이터를 분석하거나 상태를 수동으로 마이그레이션하는 경우 save() 및 get() 프리미티브를 사용하여 기본 그래프 구조와 상호 작용할 수 있습니다.
동일한 sessionId에서 save()를 여러 번 호출하는 것은 추가적입니다. 즉, 새 메시지는 이전 메시지를 덮어쓰지 않고 기존 스레드에 새 그래프 노드로 추가됩니다. LAST_MESSAGE 관계는 항상 가장 최근에 추가된 메시지를 가리키도록 업데이트됩니다.
이를 통해 대화형 페이로드에 대한 전체 프로그래밍 방식 액세스 권한이 부여됩니다.
import { Neo4jSessionStore } from 'genkitx-neo4j';
async function manualSessionManagement() {
const store = new Neo4jSessionStore({
url: 'bolt://localhost:7687',
username: 'neo4j',
password: 'password',
});
const sessionId = 'test-session-1';
// 1. Explicitly save a session payload to the graph
await store.save(sessionId, {
id: sessionId,
state: { user: 'Alice', role: 'admin' }, // Store arbitrary state metadata
threads: {
main: [
{ content: [{ text: 'Can you help me reset the database?' }], role: 'user', metadata: {} },
{ content: [{ text: 'Of course. Please provide your credentials.' }], role: 'model', metadata: {} },
],
},
});
// 2. Programmatically read and inspect the entire persisted state
const sessionData = await store.get(sessionId);
if (sessionData) {
console.log('Session Metadata:', sessionData.state);
console.log('Main Thread Message Count:', sessionData.threads.main.length);
}
}
// .. manualSessionManagement(..) execution
결론
Genkit을 Neo4j와 통합하면 개발자는 지식 그래프의 구조적 컨텍스트를 활용하여 격리된 벡터 검색 이상으로 이동할 수 있습니다. 이 접근 방식을 사용하면 다중 홉 추론과 향상된 컨텍스트 관리가 가능한 보다 정확한 RAG 시스템이 가능해집니다.
genkitx-neo4j 플러그인은 Genkit의 추상화와 Neo4j의 엔진 사이에 구성 가능한 브리지를 제공하여 기본 인덱스 내 필터링, 고급 GraphRAG 토폴로지 및 영구 채팅 메모리와 같은 기능을 지원합니다. 검색 증강 생성이 계속 발전함에 따라 이 통합은 정교한 그래프 지원 AI 애플리케이션을 구축하기 위한 강력한 기반을 제공합니다.
자원
GenkitxNeo4j GitHub 저장소
Genkit GitHub 저장소
Genkit Neo4j 문서
그래프RAG
지식 그래프
벡터 검색
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.