
이 기사에서는 정적 YAML 스키마 파일을 Neo4j 지식 그래프로 대체하여 토큰 사용량을 평균 20~30%(간단한 쿼리의 경우 최대 10배) 줄이는 동시에 복잡한 다중 테이블 질문의 정확도를 ~10% 포인트 향상시키는 방법을 보여 드리겠습니다. 모두 3분 안에 실행할 수 있는 라이브 데모에서 벤치마킹되었습니다.
중요한 이유
비즈니스 컨텍스트
데이터 기반 기업의 경우 데이터를 기반으로 주요 결정을 내려야 하므로 데이터에 대한 보편적인 액세스(정책 및 거버넌스 측면에서)는 선도하기 위한 필수 이니셔티브입니다.
그러나 대부분의 데이터는 데이터베이스에 상주하며 조직은 이 데이터를 지속적으로 대시보드로 전송하기 위해 IT 팀에 상당한 시간과 리소스를 투자합니다. 이러한 대시보드는 회사의 KPI를 기반으로 한 결정을 안내하는 중요한 자산이며 앞으로도 그럴 것입니다. 이제 비즈니스 사용자는 더 많은 것을 기대합니다. 그들은 숫자만 보고 싶어하는 것이 아닙니다. 그들은 조직 가치 사슬 전반에 걸쳐 데이터에 직접 액세스하여 '이유'를 이해하고 싶어합니다.
이러한 비즈니스 사용자에게 가장 쉬운 방법은 자연어를 사용하여 해당 산업에 특정한 뉘앙스와 기술 전문 용어를 사용하여 풍부한 맥락에 대한 생각을 전달하고 제공하는 것입니다. 이것이 사용자가 여러 데이터베이스의 데이터와 대화하고 탐색할 수 있도록 AI 에이전트가 개발되는 이유입니다.
오늘날 Text-to-SQL 에이전트의 문제점
데이터베이스와 대화한다는 것은 에이전트가 자연어 질문을 번역하고 PostgreSQL, Oracle, Snowflake, Databricks, BigQuery, Azure Fabric 등을 통해 SQL을 사용하여 데이터를 쿼리한다는 의미입니다.
표준 접근 방식: LLM에 모든 테이블/열 메타데이터가 포함된 포괄적인 YAML(또는 Markdown) 파일을 제공하거나 의미론적 유사성에 대한 벡터 기반의 동등한 파일, SKILL 및 쿼리를 안내하는 추가 비즈니스 설명을 제공합니다.
기본적인 질문에 효과가 있고 데모를 통해 쉽게 '와우' 효과를 제공할 수 있지만 몇 가지 문제점이 있습니다.
- 높은 토큰 비용: 요청마다 큰 부분 또는 전체 스키마가 전송됩니다.
- 상황에 따른 소음:관련 없는 테이블은 정확성을 저하시키고 환각을 유발합니다.
- 정적 제한사항:플랫 파일은 사용 패턴, 사전 또는 비즈니스 의미가 발전함에 따라 유지 관리하기가 어렵습니다. 지속적인 유지가 없으면 시간이 지남에 따라 에이전트의 성능이 저하됩니다.
Neo4j 의미 계층 접근 방식
Neo4j 의미 계층은 다음을 사용하여 GraphRAG 접근 방식을 도입합니다.동적 의미 계층으로서의 Neo4j. 선형 텍스트 파일에서 지식 그래프로 이동하면 에이전트는 모든 메타데이터 '읽기'를 중지하고 데이터 아키텍처를 지능적으로 '탐색'하기 시작합니다.
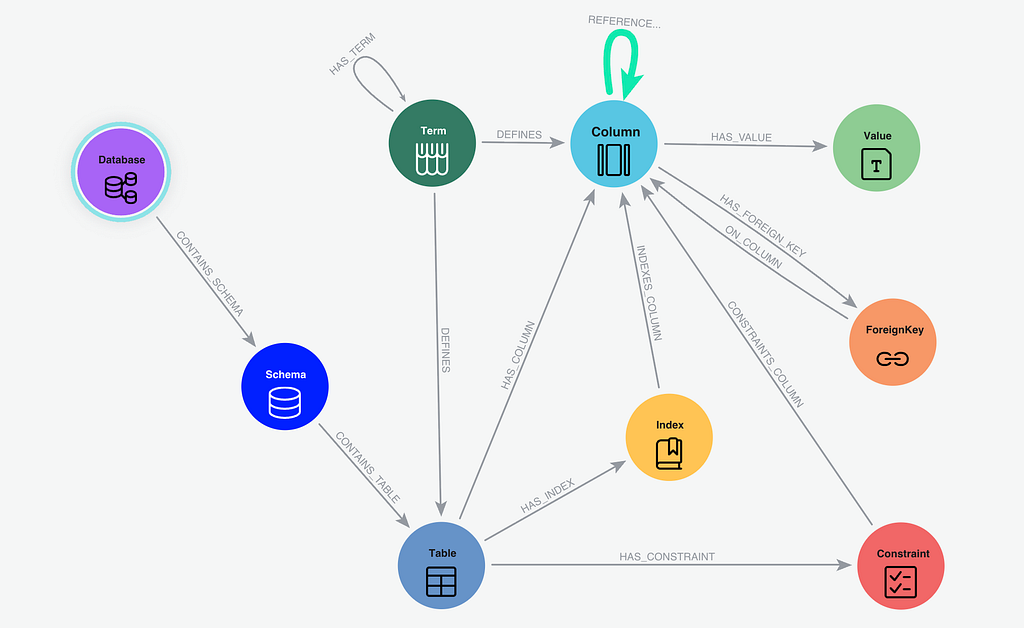
의미 계층에는 무엇이 저장되나요? 외과적 정밀도로 LLM을 기반으로 하고 유효한 SQL을 생성하기 위해 Neo4j 의미 계층은 다음을 저장합니다.
- : 스키마, 테이블, 열, 유형.
- : 외래 키 및 색인.
- : 열의 특정 값 또는 몇 가지 예입니다.
- : 도메인별 용어 및 정의와 기본 분류 구조
- : 데이터베이스에서 외래 키로 지정되지 않은 RDBMS 트랜잭션 로그에서 조인합니다.
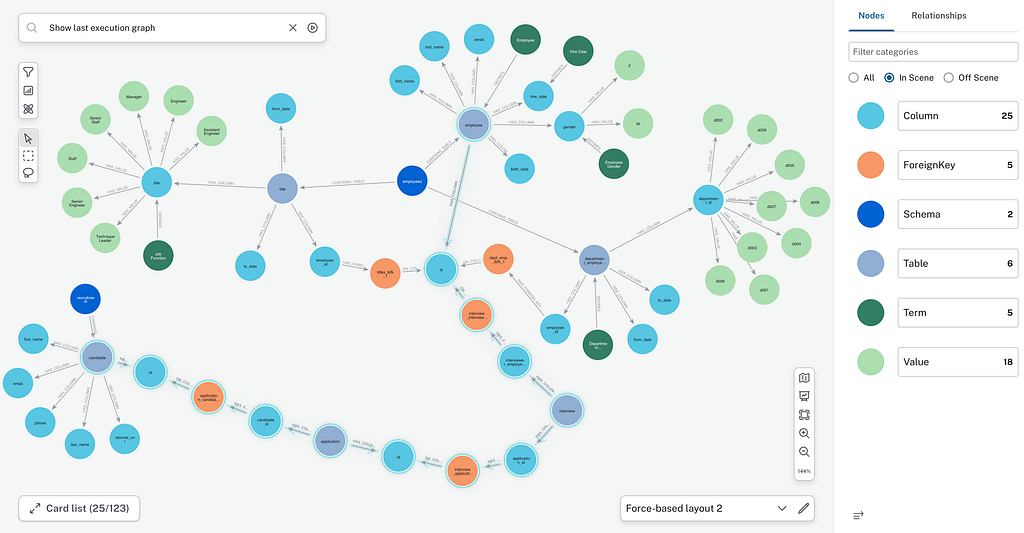
그리고 에이전트가 데이터베이스를 쿼리해야 할 때 에이전트는질문과 관련된 그래프 부분만, 의미 검색 + 그래프 순회(최단 경로)를 사용합니다.
구체적인 예
벤치마크 애플리케이션

In 이 응용 프로그램, 동일한 Streamlit 애플리케이션에서 두 에이전트를 나란히 사용하여 두 가지 접근 방식을 검토하고 시험해 볼 수 있습니다.
- YAML 에이전트: 호출할 때마다 전체 Database_schema.yaml(44KB, 테이블 ~50개)을 읽습니다.
- Neo4j 의미 계층 에이전트: 그래프를 쿼리하여 관련 컨텍스트만 검색합니다.
2개의 에이전트는 스키마 검색 도구의 유일한 차이점을 제외하고 완전히 동일한 LangChain 에이전트 체인 및 도구 세트를 사용하고 있습니다. 불공정한 비교를 피하기 위해 yaml 파일에는 사용자 행동을 기반으로 한 중요한 조인(아래 그래프에서 볼 수 있는 이메일 간의 "REFERENCES" 녹색 관계)과 같이 의미 계층에 저장된 모든 주요 정보가 포함되어 있습니다. 상담사에게 대화 내역이 전송되지 않으므로 세션을 삭제하지 않고도 쉽게 결과를 비교할 수 있습니다.
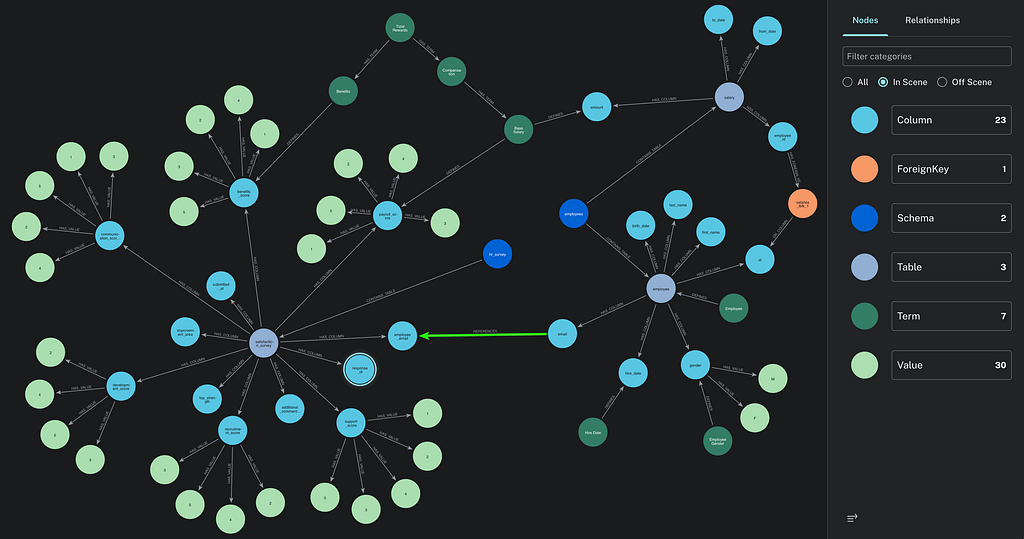
이 애플리케이션은 Neo4j 및 에이전트 로직에 저장된 의미 계층의 의미 유사성 검색을 위해 OpenAI GPT(gpt-5.4-mini + text-embedding-3-small)를 사용하여 PostgreSQL 데이터베이스에 저장된 인사 데이터(가짜 공개 데이터 세트)를 쿼리합니다.
상담원에게 질문하기
애플리케이션에는 예상되는 SQL 쿼리를 기반으로 답변의 정확성을 확인하고 증가하는 복잡성을 다룰 수 있도록 HR 데이터에 대한 3가지 질문이 사전 연결되어 있습니다.
- 단순 카운트, 단일 테이블(“후보자는 몇 명이에요?”)
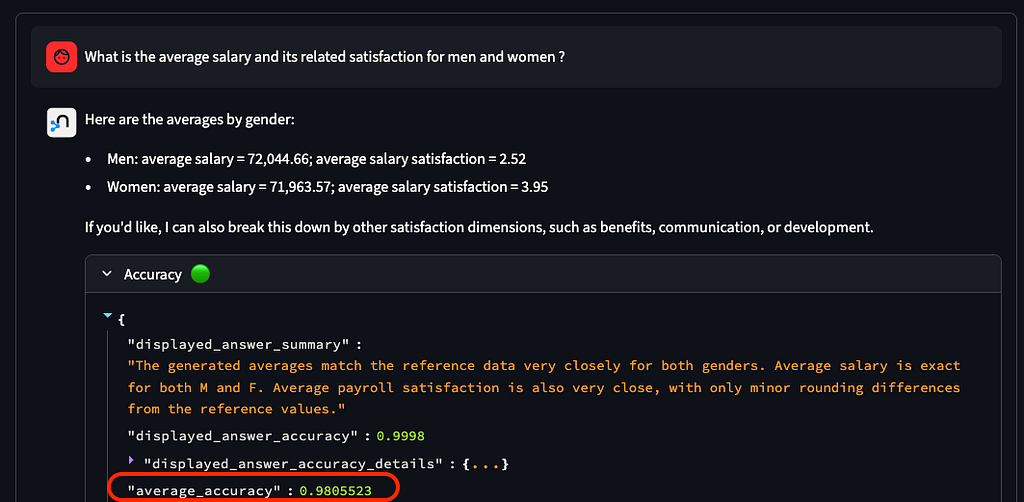
- 다중 테이블 조인 및 집계(“남성과 여성의 평균 급여와 만족도는 얼마입니까?”)
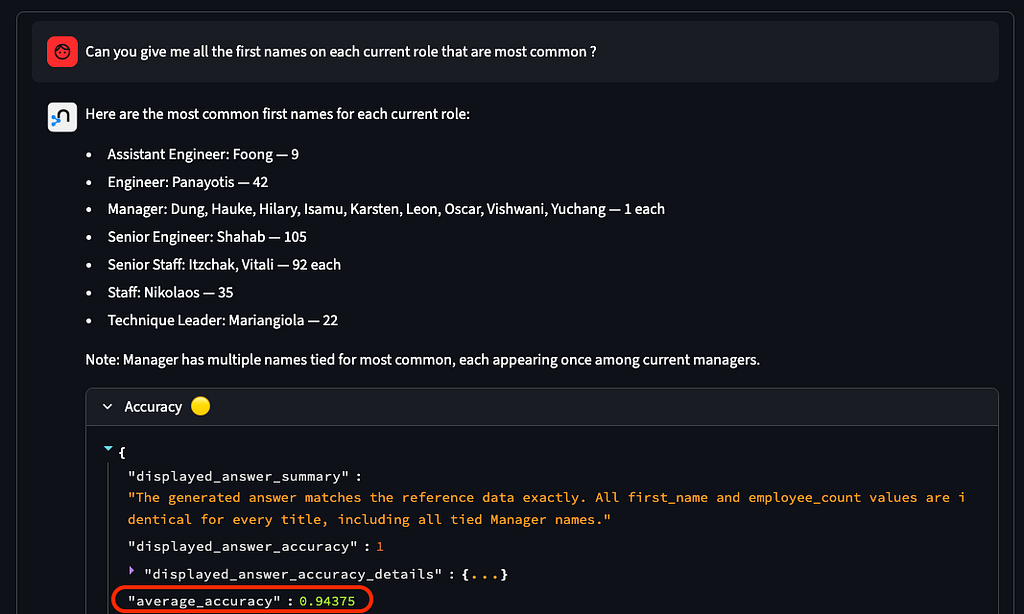
- 공통 테이블 표현식(CTE) + 창 함수(ROW_NUMBER()), 그룹화(“현재 각 역할에서 가장 흔한 이름은 무엇입니까?”)
YAML 에이전트의 정확성 및 비용
데모 애플리케이션(아래 스크린샷 참조)에서 에이전트의 기본 구성을 사용하면YAML 설명 사용, 일반적인 결과는 다음과 같습니다.
- 간단한 질문에 대한 100% 완벽한 정확성
- 다중 조인을 사용한 질문의 정확도 ~90%
- 중간 보기(CTE)가 필요한 질문에 대한 정확도 ~85%

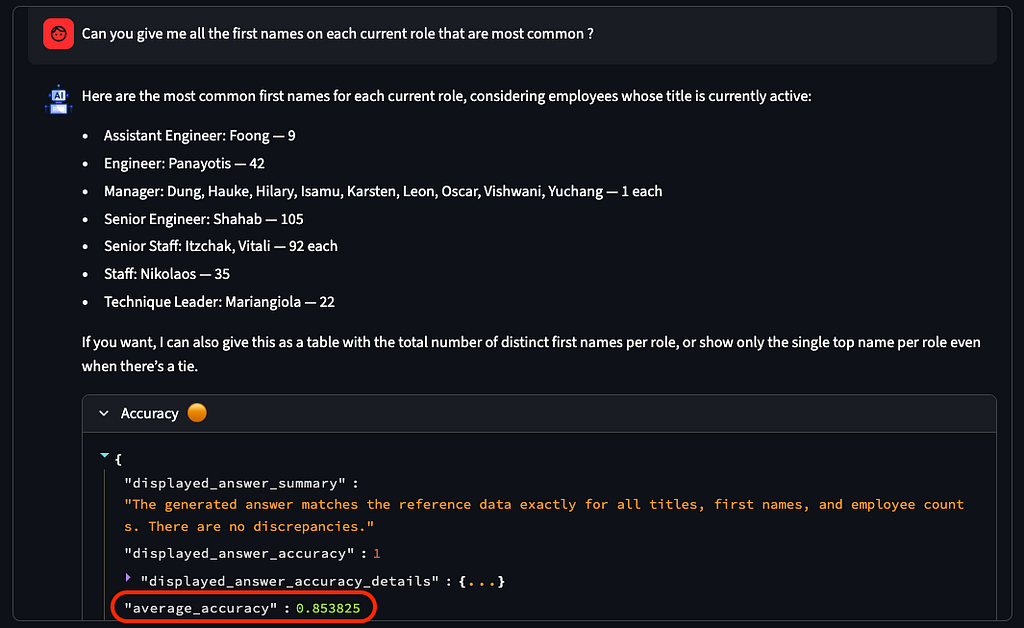
복잡한 질문에 대한 YAML 에이전트의 평균 정확도(각각 10회 실행)
비용과 관련하여 컨텍스트로 제공된 YAML 파일의 크기를 반영하는 안정적인 토큰 사용량(18,000개 토큰)을 볼 수 있습니다. 에이전트가 환각을 느끼는 상황에서 질문을 하면 비용이 급격히 증가할 수 있습니다. 컨텍스트를 너무 많이 추가하면 잘못된 SQL 쿼리가 생성될 위험이 높아지고 에이전트가 오류를 수정하기 위해 루프를 반복하고 토큰 소비가 늘어날 위험이 있습니다.
Neo4j 의미 계층 에이전트의 정확성 및 비용
데모 애플리케이션을 유지하면서 설정에서 Neo4j 의미 계층 에이전트로 전환하면 일반적으로 정확도가 향상됩니다.
- 간단한 질문의 경우 100% 정확도
- 다중 조인을 사용한 질문의 정확도 ~98%
- 중간 보기(CTE)가 필요한 질문에 대한 정확도 ~94%
비용과 관련하여 YAML 에이전트는 환각이 아닌 답변에 대해 거의 일정한 수의 토큰을 사용하는 반면 Neo4j 의미 계층은 질문의 복잡성에 따라 달라집니다.
- 간단한 질문에 토큰 최대 1,800개
- 다중 조인 관련 질문에 최대 5,000개의 토큰
- 중간 보기(CTE)가 필요한 질문에 대한 토큰 최대 7,300개
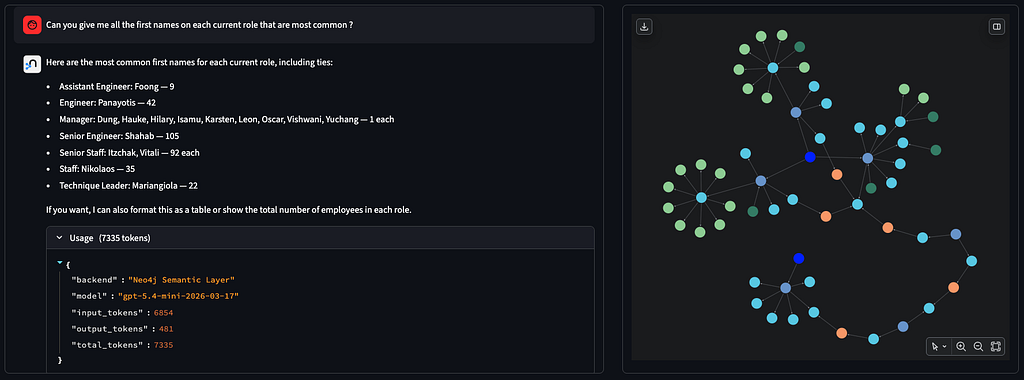
결과 분석 및 그래프가 복잡한 질문에 적합한 이유
간단한 질문의 경우 두 에이전트 모두 비슷한 성능을 발휘하지만 사용되는 토큰은 확실히 줄어듭니다. 평균적으로, 그리고 이 접근 방식을 사용하는 프로젝트 현장에서 수집한 내용을 통해 우리는 최소한의 결과를 확인했습니다.토큰 20~30% 감소YAML 파일(또는 다중 에이전트로 분산된 여러 YAML 파일)을 사용하는 정적 접근 방식과 비교됩니다.
복잡한 다중 테이블 쿼리의 경우Neo4j 에이전트는 훨씬 더 높은 정확도를 보여줍니다(이 데모에서는 +10% 포인트).컨텍스트 그래프의 관련 부분에만 초점을 맞추기 때문입니다. 이 이점은 더 큰 스키마(50~100개 이상의 테이블)와 쿼리에 여러 테이블 간의 조인이 포함될 때 증가합니다. 비즈니스 용어집, 관련 분류 및 예제 값을 사용하면 특히 업계의 특정 용어 및 비즈니스 복잡성을 정의할 때 의미 계층 신뢰성이 향상됩니다.
제공된 정보에는 조인 경로가 포함됩니다. 이러한 조인 경로는 데이터베이스(외래 키)의 기술 메타데이터를 사용합니다.또한 데이터 엔지니어/분석가의 행동에서 지속적으로 업데이트될 수 있는 외래 키로 선언되지 않은 사용 추론 조인도 있습니다.. 관계형 데이터베이스 트랜잭션 로그에서 추출된 이러한 행동 정보는 다음에서 가중치로 사용될 수 있습니다.경로 찾기 알고리즘가장 많이 사용되는 항목만 제안합니다.

Neo4j 의미 계층에 대한 심층 분석
토큰 감소와 정확성 향상은 LLM이 완벽한 SQL 쿼리를 생성하는 데 필요한 메타데이터를 찾는 것을 기반으로 합니다. 이는 3단계로 이루어집니다.
- 의미적 유사성을 사용하여 가장 유사한 용어와 열 및 관련 테이블을 찾습니다.
MATCH (column:Column)
SEARCH column IN (VECTOR INDEX column_similarity
FOR $userEmbedding LIMIT 10) SCORE as score
WHERE score>$threshold
RETURN DISTINCT column
UNION
MATCH (entryTerm:Term)
SEARCH entryTerm IN (VECTOR INDEX term_similarity FOR $userEmbedding LIMIT 10) SCORE as score
WHERE score>$threshold-0.1
MATCH (entryTerm)-[:HAS_TERM*0..]->(:Term)-[:DEFINES|HAS_COLUMN*1..2]->(column:Column)
RETURN DISTINCT column2. 식별된 테이블 사이에서 가능한 모든 조인을 찾습니다.
WITH collect(DISTINCT column) as columns
UNWIND columns as sourceColumn
UNWIND columns as targetColumn
WITH sourceColumn, targetColumn
OPTIONAL MATCH links = SHORTEST 1
(sourceTable:Table {name:sourceColumn.tableName})
(()-[:HAS_COLUMN|HAS_FOREIGN_KEY|ON_COLUMN|REFERENCES]-(x)){0,16}
(targetTable:Table {name:targetColumn.tableName})3. 추가 컨텍스트 수집
WITH DISTINCT sourceColumn as columnSimilarity, links
MATCH (table:Table)-[:HAS_COLUMN]->(columnSimilarity:Column)
MATCH p=(:Schema)-[:CONTAINS_TABLE]->(table)-[:HAS_COLUMN]->(column:Column)
OPTIONAL MATCH termCol = (:Term)-[:HAS_TERM*0..]->(:Term)-[:DEFINES]->(column)
OPTIONAL MATCH termTable = (:Term)-[:HAS_TERM*0..]->(:Term)-[:DEFINES]->(table)
OPTIONAL MATCH values = (column)-[:HAS_VALUE]->(:Value)그러면 테이블 정보와 테이블 간의 가능한 조인이 포함된 결과가 JSON 형식으로 단 몇 ms 만에 상담사에게 제공될 수 있습니다.
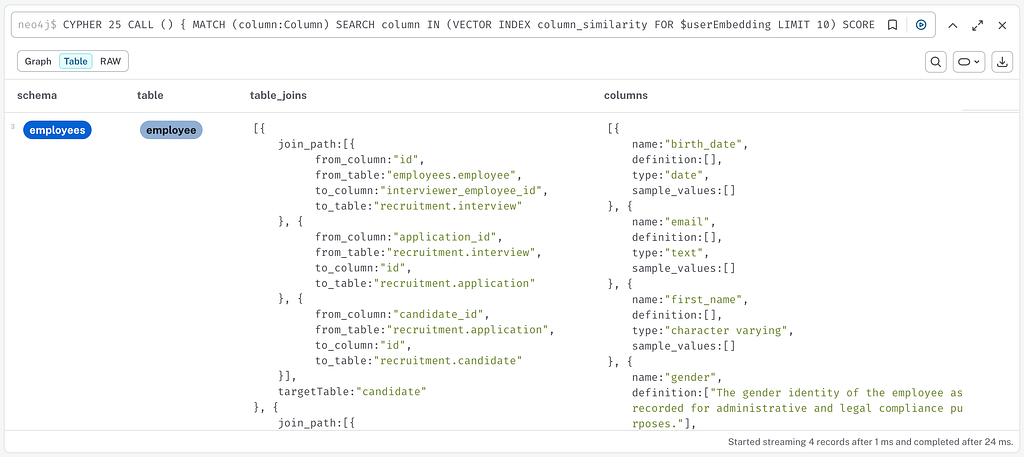
직접 시도해 보세요!
빠른 설치
특히 커서나 클로드 코드가 있는 경우 노트북에서 이 애플리케이션을 3분 안에 실행하면 이 주장을 쉽게 비교할 수 있습니다.
- gpt-4o-mini 및 text-embedding-3-small 모델을 사용하려면 OPENAI_API_KEY가 있어야 합니다.
- PostgreSQL 설치(Mac의 예:또는 Databricks Lakebase, Snowflake postgres)
- 코딩 에이전트(커서, VS Code…)에서 데모 코드 폴더를 열고 모든 작업을 수행하도록 요청합니다. Init는 인터넷에서 HR 데이터세트를 다운로드하고 PostgreSQL 및 Neo4j에 데이터를 로드합니다.
Can you look at the README.md and run this application in a virtual python 3.13.3 environment ?
The application must reach openAI api on the internet, so don't configure proxy blocking internet access.
* I have installed locally PostgreSQL with database postgres and no password
* I have installed locally Neo4j with password text2sql
* You should have the openAI key in your env context
내장된 예시를 뛰어넘으세요
미리 연결된 세 가지 질문은 증가하는 SQL 복잡성을 다루지만 이에 국한되지는 않습니다. 설정 옆에 있는 버튼을 사용하여 다음을 입력할 수 있는 대화상자를 열어 자신만의 테스트 사례를 정의할 수 있습니다.
- 자연어 관련 질문
- 예상되는 정답을 나타내는 참조 SQL
- 비교 지침(검사기가 결과를 확인하기 위해 사용하는 열)
귀하의 질문이 목록에 나타나고 정확성 검사가 자동으로 실행됩니다. 이를 통해 자신의 시나리오에서 나온 질문에 대해 두 상담원을 모두 벤치마킹할 수 있습니다.
더 나아가기: 그래프 데이터 과학, 플러그 앤 플레이 MCP
Neo4j 의미 계층의 주요 장점 중 하나는 기본 설정으로도 견고한 결과를 제공하는 동시에 특히 그래프 데이터 과학(GDS)을 통해 상당한 개선 여지를 남겨둔다는 것입니다.
- 가중치를 사용한 경로 찾기: 트랜잭션 로그에서 조인이 실행된 횟수를 'REFERENCES' 에지에 대한 가중치로 사용하여 트래픽이 많은 조인을 선호합니다.경로 찾기 알고리즘
- 엔터티 해결: use 약하게 연결된 구성요소(WCC) and K-최근접이웃(KNN)구조화되지 않은 비즈니스 문서에서 추출된 항목에 대해 동의어를 비즈니스 용어집 용어에 자동 연결합니다.
- : 각 비즈니스 사용자가 액세스할 수 있는 데이터만 그래프 컨텍스트에 반영되도록 사용자 그룹 액세스 제어를 포함합니다.
- 비즈니스 프로세스 강화: 데이터 흐름을 그래프 경로로 모델링하여 프로세스 수준 질문에 답합니다.
- : 에이전트는 의미 계층에서 대화 기록과 사용자 피드백을 캡처하여 시간이 지남에 따라 더 높은 품질의 SQL 쿼리를 생성할 수 있습니다. (에이전트 지속적인 개선)
가속기로서 의미 체계 계층은 플러그 앤 플레이 MCP 서버를 갖춘 프로젝트 Neocarta에서 사용할 수 있습니다.
관계형 데이터베이스에 대한 자연어 쿼리는 이제 주요 플랫폼 전반에 걸쳐 표준이 되었습니다. 데모와 프로덕션 시스템을 구분하는 것은 제공하는 컨텍스트입니다.
전통적인 플랫 파일 또는 벡터 기반 접근 방식은 스키마 문서를 컨텍스트 창에 덤프할 텍스트 덩어리로 취급합니다. 이로 인해 프롬프트가 지나치게 커지고, API 비용이 높아지며, 의미 있는 추론이 시작되기도 전에 관련 없는 테이블 정의로 인해 LLM의 부담이 커집니다.
Neo4j 의미 계층은 접근 방식을 근본적으로 바꿉니다. 에이전트에게 모든 것을 제공하고 에이전트가 알아낼 것이라고 기대하는 대신, 질문에 답하는 데 필요한 것, 즉 관련 테이블, 열, 조인 경로 및 비즈니스 용어에 대한 정확한 실시간 하위 그래프만 제공합니다. 결과는 분명합니다. 특히 구조적 맥락과 비즈니스 맥락이 모두 필요한 복잡한 다중 테이블 질문의 경우 모든 쿼리에서 토큰 사용량이 낮아지고 정확도가 훨씬 높아졌습니다.
그래프는 또한 YAML 파일이 근본적으로 포착할 수 없는 것, 즉 데이터가 실제로 사용되는 방식을 포착합니다. 트랜잭션 로그에서 채굴된 패턴, 모호한 언어를 해결하는 비즈니스 용어집, 이론적인 경로보다 검증된 경로를 선호하는 사용량 가중치 관계 등을 조인하세요. 이는 데이터 생태계의 역동적이고 살아 있는 속성이며, 지식 그래프는 이를 모델링하는 데 적합한 도구입니다.
LLM에는 더 큰 컨텍스트 창이 필요하지 않습니다. 더 나은 지도, 즉 그래프 기반 지도가 필요합니다.
- 그래프RAG
- 텍스트-SQL
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'GraphRAG' 카테고리의 다른 글
| 500마일도 걷게 만드는 Neo4j GraphRAG 활용법 (0) | 2026.05.20 |
|---|---|
| GraphRAG Python 패키지로 그래프 기반 RAG 애플리케이션을 위한 하이브리드 검색 구현하기 (0) | 2026.05.20 |
| GraphTalk Pharma & Life Sciences 2025 되짚어보기 (0) | 2026.05.20 |
| Graphs4Good: 그래프로 파헤치는 경찰의 부당행위 (Neo4j, GraphRAG 활용) (1) | 2026.05.20 |
| Graphs4Good: 더 나은 세상을 위한 연결된 데이터 (Neo4j, GraphRAG 활용) (0) | 2026.05.19 |