The 모델 컨텍스트 프로토콜(MCP)는 애플리케이션이 LLM에 컨텍스트를 제공하여 표준화된 도구를 통해 외부 데이터 및 기능에 액세스할 수 있도록 하는 방법을 정의하는 개방형 표준이에요.
그러한 MCP 서버 중 하나는 MCP Neo4j Cypher 서버인데, 이걸 통해 에이전트는 Neo4j 데이터베이스를 `query`할 수 있어요. 이 MCP 서버를 사용하면 데이터베이스 `schema` 정보를 검색하고 Cypher 구문을 직접 배울 필요 없이 LLM(Text2Cypher)에서 생성된 Cypher `query` 읽기 및 쓰기를 모두 실행할 수 있죠. 이런 방식으로 Text2Cypher 접근 방식은 자연어와 기존 그래프 `query` 사이에 투명하고 효과적인 연결을 제공한답니다.
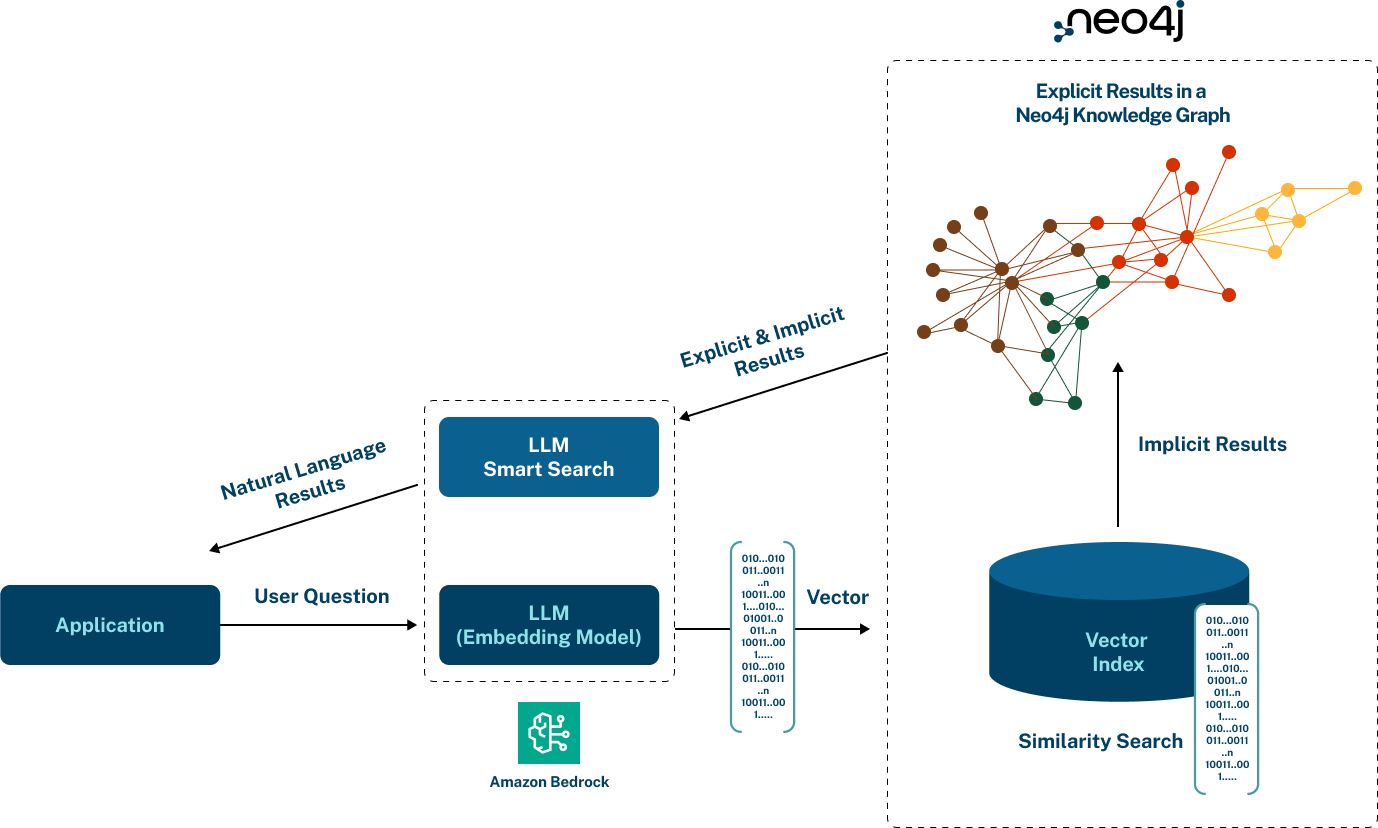
하지만, 벡터 검색은 또 다른 도전을 제시해요. Text2Cypher와 달리 벡터 검색은 단순히 자연어를 Cypher `query`로 변환하는 게 아니거든요. 대신 데이터와 `query`에 대한 `Vector Embedding`을 생성한 다음 이를 벡터 `index`에서 비교해야 해요. 이 때문에 프로세스가 덜 투명해지죠. 결과를 의미 있게 해석하려면 `Vector Embedding`을 생성하는 데 사용된 텍스트 `Vector Embedding` 모델과 `query`가 해당 모델과 어떻게 일치하는지 아는 것이 중요해요. 효과적인 벡터 검색을 설계하려면 암호 생성뿐만 아니라 `Vector Embedding` 관리 및 신중한 `query` 공식화가 필요하답니다.
이걸 해결하기 위해 Neo4j는 GraphRAG를 제공하는데, 그중 하나가 VectorCypherRetriever에요. 이건 벡터 검색과 Cypher를 결합한 거죠. 이 블로그 게시물에서는 이 검색기를 MCP 서버로 노출해서 에이전트를 위한 추가 도구로 사용할 수 있도록 하는 방법을 살펴볼게요.
MCP 코드는 다음 에서 확인할 수 있어요.
GraphRAG 리트리버를 MCP 서버로 노출
언급했듯이 텍스트 `Vector Embedding`도 생성해야 하므로 사용자 정의 검색기가 필요해요. 왜 LLM에 `Vector Embedding` 모델을 도구로 제공하고 이를 Text2Cypher와 결합하지 않는지 궁금할 수도 있을 것 같아요. 그 이유는 오늘날 한 도구의 결과를 다른 도구로 전달하는 유일한 방법은 LLM 컨텍스트 자체를 통해서이기 때문이에요. 하지만 `Vector Embedding`은 고차원 벡터이므로 LLM을 통해 이를 라우팅하는 것은 토큰 및 지연 시간 측면에서 비효율적이고 비용이 많이 들죠.
VectorCypherRetriever를 MCP 도구로 노출
위에 표시된 것처럼 더 나은 접근 방식은 검색기가 전체 워크플로를 처리해서 `Vector Embedding`을 생성하고 벡터 검색을 수행하도록 하는 거예요. 이렇게 하면 `Vector Embedding`이 LLM을 통과하지 않고 모든 것이 단일 도구 인터페이스 뒤에서 깔끔하게 추상화되죠.
GraphRAG 벡터Cypher MCP
이제 검색기를 구현할 차례에요. 저는 MCP 프레임워크 전문가가 아니기 때문에 MCP 프레임워크의 구조를 복사하는 것부터 시작했어요. MCP Neo4j Cypher 서버를 참고해서 FastMCP로 구축했고, 이걸 적용했죠.
`Vector Embedding` 모델을 구현하려면 유연한 방법이 필요해요. 코드 수정 없이 VectorCypherRetriever MCP가 모든 모델과 호환되도록 만들기 위해 LangChain의 init_embeddings 기능을 사용했어요. 이 함수는 간단한 provider:model 문자열을 사용하면 다양한 `Vector Embedding` 모델 간을 매우 쉽게 전환할 수 있게 해주죠.
# Example
embedding_model = init_embeddings("openai:text-embedding-3-small")
MCP 서버는 LLM과 외부 기능 사이의 다리 역할을 하면서 형태로 노출돼요. 이런 도구를 정의해두면 서버는 LLM이 사용자 쿼리에 응답하는 데 도움이 되는 도구 실행을 요청할 수 있게 되죠.
여기서는 벡터 검색을 수행하는 함수, 즉 단일 도구를 노출해볼게요.
@mcp.tool(
name=namespace_prefix + "neo4j_vector",
annotations=ToolAnnotations(
title="Neo4j vector",
readOnlyHint=True,
destructiveHint=False,
idempotentHint=True,
openWorldHint=True,
),
)
async def vector_search(
query: str = Field(..., description="Natural language question to search for.")
) -> list[ToolResult]:
"""Find relevant documents based on natural language input"""
try:
result = vector_retriever.search(query_text=query, top_k=5)
text = "\n".join(item.content for item in result.items)
return ToolResult(content=[TextContent(type="text", text=text)])
except Neo4jError as e:
logger.error(f"Neo4j Error executing read query: {e}\n{query}")
raise ToolError(f"Neo4j Error: {e}\n{query}")
except Exception as e:
logger.error(f"Error executing read query: {e}\n{query}")
raise ToolError(f"Error: {e}\n{query}")
이 함수는 Neo4j 데이터베이스에 대한 Semantic Search 도구 역할을 하는 거예요. LLM이 이 도구를 사용하기로 결정하면 자연어 쿼리가 전달되죠. 그러면 함수는 벡터 검색기를 사용해서 데이터베이스에서 가장 관련성이 높은 문서 5개를 찾고, 결합된 텍스트 콘텐츠를 LLM에 반환한답니다.
@mcp.tool 데코레이터는 vector_search 함수를 사용 가능한 도구로 만들어줘요. 도구 설명은 해당 문서 문자열에서 자동으로 생성되어서 LLM에게 명확한 지침을 제공하죠. 도구 정보는 다음과 같아요:
도구의 목적 ("무엇"): 함수의 주요 독스트링은 도구의 전반적인 설명이 돼요. 이 요약 정보는 LLM에게 도구의 기능을 알려주고 언제 사용해야 할지 결정하는 데 도움을 줘요.
도구의 입력 ("방법"): 함수에 필요한 각 파라미터도 설명해야 해요. 이런 구체적인 설명은 LLM에게 각 입력에 대해 어떤 정보를 제공해야 하는지 정확하게 알려줘서 도구를 올바르게 호출하도록 도와주죠.
추가적으로 도구 주석을 정의할 수도 있어요.
name: 도구에 고유한 이름을 부여해요.
readOnlyHint=True: 이 도구는 데이터를 읽기만 하고 데이터베이스를 변경하지 않는다는 의미예요.
destructiveHint=False: 도구가 파괴적이지 않다는 것을 명시적으로 나타내죠.
idempotentHint=True: 정확히 동일한 쿼리로 도구를 여러 번 호출해도 추가적인 부작용 없이 동일한 결과를 얻을 수 있다는 의미에요. 예를 들어 "cats"를 두 번 검색하면 동일한 결과가 나오고 아무것도 변경되지 않죠.
openWorldHint=True: 도구의 지식 소스(Neo4j 데이터베이스)가 독립적으로 업데이트될 수 있다는 것을 LLM에 알려줘요. 새 데이터가 추가되면 오늘 얻는 답변이 내일 얻는 답변과 다를 수 있다는 거죠.
Claude Desktop에서 테스트하기
이제 Claude 데스크탑 애플리케이션에서 다음 구성을 사용해서 서버를 테스트할 수 있어요.
이 설정은 공개 읽기 전용 Neo4j 영화 추천 데이터베이스에 연결되도록 미리 구성되어 있어요. OPENAI_API_KEY만 입력하면 텍스트 임베딩 모델을 사용할 수 있답니다.
moviePlotsEmbedding index를 사용하면 포함된 영화 줄거리 데이터에서 Natural Language Processing 검색이 가능해요. 한번 테스트해 볼까요?
Claude Desktop의 샘플 흐름
요약
작년의 검색 시스템은 더 이상 쓸모 없어진 게 아니라, 새로운 형태로 진화한 거예요. 에이전트 시대에는 리트리버가 모듈식, 효율적, 표준화된 도구로 포장되죠. 깔끔한 MCP 인터페이스 뒤에 임베딩 생성 및 Vector Search의 복잡성을 숨김으로써, LLM이 데이터 검색의 하위 수준 메커니즘보다는 추론 및 조정에 집중할 수 있도록 도와주는 거예요.
에이전트는 복잡한 내용을 알 필요가 없어요. text-embedding-3-small이나 Vector Index의 구조 같은 것 말이죠. 그냥 호출할 수 있는 강력한 Semantic Search 도구가 있다는 것만 알면 돼요. 동일한 원칙을 적용해서 다른 항목들을 노출할 수도 있어요. GraphRAG 검색기나 맞춤 데이터 액세스 로직을 사용해서 에이전트를 위한 다양하고 강력한 도구 상자를 만들 수 있죠.
MCP 코드는 에서 확인할 수 있어요.
자원
Free 필수 GraphRAG book
개발자가 모델 컨텍스트 프로토콜(MCP)에 대해 알아야 할 모든 것
GraphRAG란 무엇입니까?
Cypher
mcp 서버
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
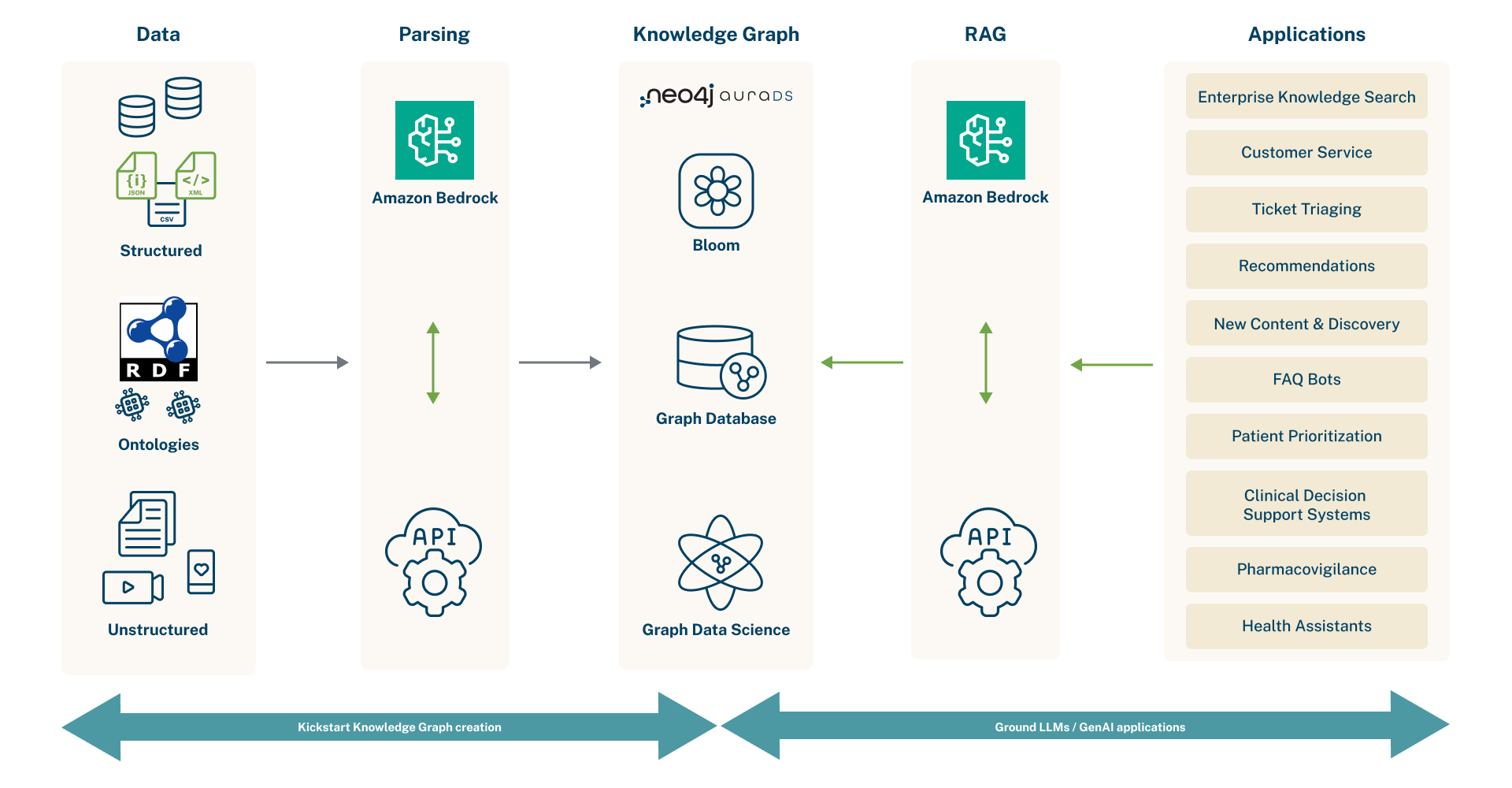
Neo4j와 Amazon Web Services(AWS)가 다년간의 전략적 협업 계약(SCA)을 체결했다는 기쁜 소식을 전해드려요! 이 협업은 엔터프라이즈 AI 개발 속도를 높이는 동시에 주요 AI 문제, 특히 LLM 환각 현상을 줄이는 데 초점을 맞추고 있어요.
Neo4j는 Vector Search 기능을 갖춘 유일한 Graph Database인데요, 이제 Amazon Bedrock과 완벽하게 통합될 예정이에요. Amazon Bedrock은 파운데이션 모델을 사용해서 GenAI 앱을 구축하고 확장하는 가장 간단하면서도 강력한 방법 중 하나죠. GenAI 개발자들이 쉽고 빠르게 시작할 수 있도록 완전 관리형 Graph Database 제품인 Neo4j AuraDB 프로를 AWS Marketplace에서 만나볼 수 있어요.
이 파트너십을 통해 조직은 GenAI 솔루션을 특정 데이터 도메인에 맞게 조정하고, AI 결과의 완전성, 정확성, 투명성을 높이는 데 필요한 도구를 얻을 수 있게 될 거예요.
플랫폼 통합 방식은 아래 그림을 통해 한 번 살펴볼까요?
엔터프라이즈급 GenAI를 향한 장벽을 허물다
GenAI가 비즈니스를 혁신할 잠재력은 정말 엄청나죠. McKinsey에 따르면 GenAI는 세계 경제에 연간 최대 7조 9천억 달러를 추가할 수 있다고 해요.
많은 개발자들이 GenAI를 활용하고 싶어하지만, LLM 환각 현상, 검증 문제, 제한된 입력 크기, 잠재적인 데이터 편향과 같은 일반적인 제약 사항 때문에 시작하거나 해결 방법을 찾는 게 쉽지 않았어요.
바로 이럴 때 Neo4j와 Amazon Bedrock이 필요한 거죠! Neo4j Knowledge Graph는 기업 데이터의 맥락적 깊이를 포착해서 Bedrock 기반 AI 시스템이 더 효과적으로 추론하고, 관계를 파악하고, 관련 정보를 검색할 수 있도록 도와줘요. 이는 특정 기업 데이터 및 도메인에 기반한 LLM에 대한 장기적인 기억이 필요한 개발자들의 일반적인 어려움을 해결해 준답니다.
Neo4j의 네이티브 Vector Search, Knowledge Graph, 그리고 Amazon Bedrock의 조합은 정말 강력해요. 한번 살펴볼까요?
환각 감소: Neo4j와 Bedrock은 RAG을 사용해서 기업 지식에 기반한 가상 비서를 만들 수 있어요. 이렇게 하면 환각을 줄이고 정확도를 높일 수 있죠.
개인화된 경험 창출: Bedrock에 통합된 Knowledge Graph는 관계와 결합해서 고도로 개인화된 텍스트 요약 및 생성을 지원하는 풍부한 기반 모델 생태계를 만들 수 있어요.
Kickstart Knowledge Graph 생성: Amazon Bedrock의 GenAI 기능을 통해 개발자는 구조화되지 않은 데이터를 처리하고 이를 Knowledge Graph에 로드할 수 있어요. 그러면 사용자는 그래프에서 통찰력을 추출하고 실시간 결정을 내릴 수 있죠. Neo4j generation LangChain 템플릿을 사용하면 더 빨리 시작할 수 있을 거예요.
Neo4j + Amazon Bedrock의 영향
Amazon Bedrock은 요약, 콘텐츠 생성, 질문 답변 등의 작업을 처리해요. Neo4j Knowledge Graph와 결합하면 모든 팀원에게 제도적 지식을 제공할 수 있죠. 이 조합은 또한 구조화되지 않은 데이터의 잠금을 해제해서 환각이 아닌 사실에 근거한 완전한 답변을 제공해요.
예를 들어, 이제 HR 정책 질문에 대한 전체 답변을 얻거나 저자 및 기관과 같은 맥락으로 묶인 관련 의학 논문 조각을 찾을 수 있어요. 기업 문서를 요약할 수도 있고요. 핵심은 Bedrock의 기능이 Neo4j의 사실적인 Knowledge Graph를 통해 강화된다는 거예요. 이는 LLM 추측 대신 정확하고 상황에 맞는 응답을 생성하죠.
"Neo4j의 Knowledge Graph와 Amazon Bedrock의 GenAI 기능을 결합하면 GenAI 애플리케이션을 대규모로 구축하고 신용 분석 및 통찰력을 민주화할 수 있습니다. 우리는 상인, 채권자 및 거래 유형에 대한 데이터를 포함하여 거래에서 모든 유형의 데이터를 보유하고 있습니다. Neo4j는 이렇게 고도로 연결된 거래를 보다 효율적으로 저장하고 보다 신속하게 새로운 규칙에 맞게 조정할 수 있는 완벽한 데이터베이스입니다."
AuraDB Pro를 AWS Marketplace로 가져오기
Neo4j AuraDB Pro를 AWS Marketplace에서 만나볼 수 있게 되어 정말 기뻐요! AuraDB Pro를 사용하면 GenAI용 Amazon Bedrock을 사용하는 개발자가 Neo4j의 에 쉽게 액세스하고 Knowledge Graph를 구축할 수 있어요. GenAI 프로젝트를 강화하고 기반을 다지는 것을 실질적으로 단순화하는 거죠.
AWS Marketplace를 통해 Neo4j AuraDB를 시작하면 팀에 다음과 같은 도움이 될 수 있어요.
실험 자금을 조달하기 위해 개인 신용 카드를 사용하지 않아도 돼요.
기존 AWS 할인 및 계약을 사용할 수 있어요.
단일 AWS 청구서로 지출을 쉽게 모니터링할 수 있죠.
Amazon Bedrock 및 Neo4j 시작하기
Neo4j와 Amazon Bedrock은 함께 자체 데이터를 기반으로 고성능 GenAI를 구축하는 데 필요한 모든 것을 제공해요. AWS에 Neo4j 배포, AWS Marketplace에서 AuraDB Pro를 사용할 수 있으므로 Knowledge Graph를 만드는 것이 정말 간단해졌어요. 또한 다음 옵션을 사용하여 Neo4j를 Amazon Bedrock과 더 간단하게 통합할 수 있어요. LangChain을 사용하여 Amazon Bedrock 및 자체 관리형 또는 AuraDB Neo4j 인스턴스를 LLM 오케스트레이션 워크플로에 쉽게 통합할 수 있죠. 예를 들어 Neo4j LangChain 템플릿을 사용하면 돼요. 자체 관리형 Neo4j의 경우 APOC 절차를 통해 Bedrock에 직접 전화할 수도 있고요.
파트너가 제공하는 다음 리소스도 확인해 보세요.
AWS 블로그: 설명 가능하고 안전하며 연결된 생성 AI 솔루션을 위해 Neo4j 및 Amazon Bedrock 활용
LangChain 블로그: Neo4j를 사용하여 고급 RAG 전략 구현
만약 여러분이 AWS re:Invent에 참가할 예정이라면, Neo4j와 Bedrock에 대해 더 자세히 알고 싶으실 텐데요. Neo4j 부스(#1304)에 들러 11월 28일 오후 5시 30분 Lightning Theater Five에서 열리는 Lightning Talk에 꼭 참석해보세요!
AWS
GenAI
LLM Hallucinations
LLM Knowledge Graph
Vector Search
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
[커뮤니티 콘텐츠로서 본 게시물은 특정 작성자의 견해와 의견을 반영한 것으로, Neo4j의 공식적인 입장이 반드시 반영되는 것은 아닙니다.]
프로젝트 관리자에게 물어보면 새 프로젝트를 시작하기 전에 배운 내용을 검토하는 게 얼마나 중요한지 알려줄 거예요.
교훈을 얻은 데이터베이스는 프로젝트 팀이 프로젝트 성공 가능성을 높이는 데 도움이 되는 귀중한 정보로 가득 차 있죠. 그런데 왜 대부분의 교훈을 얻은 데이터베이스가 프로젝트 팀에서 잘 사용되지 않을까요?
제 경험에 따르면 검색하기가 너무 어렵고, 결과 집합을 검토하는 데 몇 시간이나 걸리거든요.
최근에 한 프로젝트 엔지니어가 팀이 관심을 갖고 있는 22개의 핵심 용어 목록을 사용해서 배운 교훈을 검색할 수 있는지 물어봤어요. 현재 키워드 검색 엔진에서는 각 용어를 개별적으로 입력하고 링크를 선택한 다음 검토를 위해 문서를 저장해야 했죠. (게다가 데이터베이스만 검색할 수 있는 방법은 없었고, 이 쿼리는 2천만 개에 가까운 URL 전체를 검색하게 되는 상황이었어요.) 이런 방법으로는 불가능하죠.
저는 우리 검색팀에게 제공된 용어를 사용해서 레슨 데이터베이스에 대해서만 특수 쿼리를 실행할 것인지 물어봤어요. 그랬더니 해당 용어가 포함된 각 문서에 대한 링크가 포함된 스프레드시트를 줬는데, 목록에는 1100개가 넘는 문서가 들어있었어요. 엔지니어는 그를 위해 하던 일을 멈췄죠.
저는 더 나은 방법이 있어야 한다고 생각하기 시작했어요.
특히 더 쉬운 시각화 메커니즘을 통해 서로 다른 것처럼 보이는 문서를 연결하는 사용자를 돕기 위해 주제 모델링을 실험하고 있었거든요. 여러 페이지의 링크 목록보다는 훨씬 나을 거라고 생각했어요.
그래서 도구 상자를 모았어요. R/RStudio는 주제 모델링 및 데이터 탐색을 위해, 는 주제를 모델링하고 시각화하기 위해, 그리고 Linkurious는 사용자가 검색하고 시각화할 수 있는 웹 프런트 엔드 Graph Database를 위해서요.
주제 모델 구축
모든 코드와 데이터는 제 GitHub 저장소에서 찾을 수 있어요. 이번 글에서는 과 Cypher 코드가 Neo4j와 함께 어떻게 작동하는지에 초점을 맞출 거예요. 다음 기사에서는 주제 모델링 코드를 자세히 설명해 드릴게요.
이 데모를 위해 저는 2,000개가 넘는 레슨을 공개 NASA 엔지니어링 네트워크 교훈 데이터베이스에서 가져왔어요. 데이터는 상당히 깨끗했고 몇 가지 유용한 메타데이터가 포함되어 있었죠.
주제 모델을 생성하는 단계는 다음과 같아요.
말뭉치를 생성해요.
모델에 사용할 문서 용어 행렬을 만들어요.
모델에 대한 최적의 주제 수를 결정해요. (토픽 모델링에서는 k개의 토픽을 알아야 하죠. 저는 현재 조화 평균 접근법을 사용하고 있는데, 이 데이터의 경우 35개의 토픽이 최적으로 결정되었어요.)
모델을 실행해요.
문서는 둘 이상의 주제에 속할 수 있기 때문에 모델에서 세타(문서별 확률)를 추출하고 각 문서에 가장 진단적인 주제를 할당했어요. 그런 다음 순위 순으로 각 주제에 대한 상위 30개의 용어를 추출하고 상위 3개 용어를 기반으로 각 주제에 대한 레이블을 생성하고 각 문서와 관련된 카테고리 메타데이터를 기반으로 주제를 상호 연관시켰어요. 이 모든 정보는 제 그래프 모델을 개발하는 데 도움이 될 거예요.
여기서는 RNeo4j 및 visNetwork 패키지를 사용해서 R에서 Graph Database를 시각화하는 방법을 보여드리고 싶었어요. (자세한 내용은 Nicole White의 RNeo4j 및 visNetwork를 사용한 그래프 시각화를 참고하세요.)
이미 데이터베이스를 만들었다고 가정하고, 제가 실행한 첫 번째 쿼리에서는 "오염"이라는 용어와 해당 용어가 포함된 주제가 반환되었어요.
간선 가중치는 주제 내 용어의 순위에 따라 결정돼요. 간선이 두꺼울수록 주제에서 순위가 높은 용어라는 뜻이죠. 다음 `query`는 주제 27에 대한 모든 교훈을 반환했어요. 마지막으로 다음을 사용해서 R에서 모델을 시각화했죠. LDAvis 패키지.
각 주제에 대한 상위 30개의 용어와 해당 용어가 다른 주제에 어떻게 분포되어 있는지 확인할 수 있었어요. 저에게는 도움이 되었지만, 최종 사용자에게는 필요한 게 아니었죠. 그래서 모든 수업 정보를 CSV 파일로 저장해서 Neo4j로 가져왔답니다.
그림 1: R의 용어 `query`
그림 2: R의 주제 `query`
그림 3: LDAvis를 사용한 주제 모델의 시각화
Graph Database 구축
만약 여러분이 Graph Database와 Neo4j 작업을 막 시작했다면, Nicole White의 블로그를 읽어보세요. 다음 섹션은 그녀의 웹 세미나를 기반으로 해요. 실제 세계에서 CSV 로드 사용.
8트랙 시대에 태어난 저는 먼저 화이트보드에 그래프를 모델링해 보기로 했어요. 제안된 `node`들의 다양한 연결을 그래프로 보여주는 대략적인 개요를 그렸죠. 정말 간단해요. 하지만 이게 모델에 계속 집중하는 데 도움이 된다는 걸 알았어요.
그림 4: 교훈을 얻은 데이터베이스 그래프 모델
`node`를 생성하기 위해 Cypher에서 LOAD CSV를 사용하여 위에서 생성한 데이터를 가져왔어요.
코드의 첫 번째 섹션은 강의 `node`에 대한 고유 제약 조건을 생성해서 강의 ID 중복을 방지해요. CSV 파일을 읽으면 레슨 `node`가 생성되고 속성이 설정되죠.
속성은 각 강의와 관련된 메타데이터에서 추출되었어요. Nicole이 웨비나에서 제안한 대로 날짜를 세 부분으로 나누었고요. 나중에 연도 속성을 사용하여 간선에 가중치를 할당할 거예요. 레슨이 최신일수록 간선이 더 커지겠죠. 각 강의 `node`에는 초록, 강의 자체(사용 가능한 경우), 강의가 시작된 부서, 안전 문제인지 여부 및 NEN 웹 사이트의 강의 링크에 대한 속성도 포함된답니다.
// Nodes created for Lessons, Submitter, Center and Topic
// Relations created
// Uniqueness constraints.
CREATE CONSTRAINT ON (l:Lesson) ASSERT l.name IS UNIQUE;
// Load.
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS
FROM 'file:e:/Users/David/Dropbox/doctopics/data/llis.csv' AS line
WITH line, SPLIT(line.LessonDate, '-') AS date
CREATE (lesson:Lesson { name: TOINT(line.`LessonId`) } )
SET lesson.year = TOINT(date[0]),
lesson.month = TOINT(date[1]),
lesson.day = TOINT(date[2]),
lesson.title = (line.Title),
lesson.abstract = (line.Abstract),
lesson.lesson = (line.Lesson),
lesson.org = (line.MissionDirectorate),
lesson.safety = (line.SafetyIssue),
lesson.url = (line.url)
많은 Node들이 CSV 파일의 여러 강의와 연결되어 있어요. MERGE 명령은 Node가 없으면 Node를 생성하고, Node가 있으면 일치시키는 역할을 해요.
R 코드에서는 각 Topic에 대해 가장 대표적인 Category를 계산해서 CSV 파일에 저장했고, 이제 이를 Graph Database에 로드할 거예요. Node는 이미 이전에 생성되었기 때문에 MATCH 함수를 사용해서 Node를 얻은 다음, Topic과 Category의 관계를 만들죠.
// Topic, category.
// Adds the category node and creates a relations to the topic
// Load.
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS
FROM 'file:e:/Users/David/Dropbox/doctopics/data/topicCategory.csv' AS line
MATCH (topic:Topic { name: TOINT(line.Topic) })
MATCH (category:Category { name: UPPER(line.Category) })
CREATE (topic)-[:AssociatedTo]->(category)
;
그림 6: Category와 관련된 Topic
Topic을 연관시킨 다음 해당 관계를 Node에 추가할 수 있어요. 저는 방향이 지정되지 않은 관계를 사용하고 있었기 때문에 Edge를 생성하려면 MERGE를 사용해야 한다는 것을 알게 되었어요.
그런 다음 나중에 이 속성을 사용해서 Database에 Query해서 제가 관심 있는 강의와 연결되어 있는 강의가 포함될 수 있는 다른 Topic을 찾을 수 있죠.
// Topic, Correlation.
// Adds a relation to each topic using their correlation as a property of the relationship
// Load.
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS
FROM 'file:e:/Users/David/Dropbox/doctopics/data/topicCorr.csv' AS line
MATCH (topic:Topic), (topic2:Topic)
WHERE topic.name = TOINT(line.Topic) AND topic2.name = TOINT(line.ToTopic)
MERGE (topic)-[c:CorrelatedTo {corr : TOFLOAT(line.Correlation)}]-(topic2)
// MERGE is used because it is non directed relationship
;
다음 Cypher 코드는 각 주제의 상위 30개 용어에 대한 `Node`를 생성하고, 용어 `Node`와 주제 `Node` 사이의 경계를 생성하고, `rank` 관계 속성을 주제의 용어 순위로 설정하고, 마지막으로 레이블이 R 코드에서 생성한 주제 `Node`에 레이블 속성을 설정합니다.
// Topic, Terms.
// Creates term nodes and relationship to topic by the rank the
// term is in the topic. A rank of 1 means that the term is the most
// frequent in that topic
// Load.
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS
FROM 'file:e:/Users/David/Dropbox/doctopics/data/topicTerms.csv' AS line
MATCH (topic:Topic { name: TOINT(line.Topic) })
MERGE (term:Term { name: UPPER(line.Terms) })
CREATE (term)-[r:RankIn {rank : TOINT(line.Rank)}]->(topic)
;
// Topic, Labels.
// Creates label property for each topic by using the top 3 ranked terms in the topic.
// A rank of 1 means that term is the most frequent in that topic
// Load.
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS
FROM 'file:e:/Users/David/Dropbox/doctopics/data/topicLabels.csv' AS line
MATCH (topic:Topic { name: TOINT(line.Topic) })
SET topic.label = line.Label
;
Neo4j의 Graph Database에서 정보를 추출하는 방법을 보여주기 위해 몇 가지 샘플 `Query`와 그 결과를 준비했어요. `Graph`와 행 버전 모두 아래에 표시되어 있습니다.
이 `Query`는 주제 27의 교훈을 반환합니다.
MATCH (n:Topic)-[r:Contains]->(m:Lesson)
WHERE n.name = 27
RETURN n, m,
n.name AS from,
m.id AS to,
m.title AS title,
(m.year) AS value,
"In" AS label
그림 7: 주제 27의 교훈, `Graph` 보기
그림 8: 주제 27의 교훈, 행 보기
주제 27과 상관관계가 0.02보다 큰 주제:
MATCH (n:Topic)-[r:CorrelatedTo]->(m:Topic)
WHERE n.name = 27 AND (r.corr > 0.02)
RETURN n, m,
n.name AS from,
m.id AS to,
m.title AS title,
(m.year) AS value,
"In" AS label
그림 9: 주제 27과 상관관계가 0.02보다 큰 주제
상관관계가 0.40보다 큰 주제들이에요. 각 주제에 대한 모든 상관관계도 표시하고 있는데, 아직 작업 중이랍니다.
MATCH (n:Topic)-[r:CorrelatedTo]->(m:Topic)
WHERE r.corr > 0.40
RETURN n, m,
n.name AS from,
m.name AS to,
(r.corr) AS value
그림 10: 상관관계가 0.40보다 큰 주제
주제 27과 상관된 모든 주제를 보여주고 있어요. 엣지 레이블은 숫자 상관 값이죠.
MATCH (n:Topic)-[r:CorrelatedTo]->(m:Topic)
WHERE n.name = 27
RETURN n, m,
n.name AS from,
m.name AS to,
(r.corr) AS value
그림 11: 주제 27과 관련된 모든 주제
사용자 시각화
이제 모든 데이터가 Graph Database에 있지만, 최종 사용자가 자신의 기준에 따라 강의를 더 쉽게 검색하고 연결할 수 있도록 해야 해요.
Neo4j 배우기에서 여러 시각화 옵션이 언급되었는데요. 저는 여러 가지 애플리케이션을 평가했고 이 데모를 위해 Linkurious를 선택했어요. Linkurious는 사용자가 그래프 데이터를 검색하고 시각화할 수 있는 웹 기반 인터페이스랍니다.
Linkurious는 Neo4j 데이터베이스에 연결하도록 설계되었고, 시작하기 전에 Neo4j 데이터베이스가 실행되고 있어야 해요. 애플리케이션을 열면 다음 대시보드가 표시될 거예요.
그림 12: Linkurious 대시보드
Linkurious에는 Elastic Search 인스턴스가 내장되어 있어서, 원한다면 모든 Node와 Edge를 검색할 수 있어요. 아래 예를 참조하세요.
그림 13: Linkurious Elastic Search
첫 번째 시각화를 만들 때 정말 큰 이점을 얻을 수 있어요. 예를 들어, "연료", "물", "밸브" 또는 "고장"이라는 용어가 포함된 강의를 찾고 있다고 가정해 볼게요. 그러면 해당 단어가 포함된 강의가 있는 Lesson Node, 두 용어에 대한 Term Node, 그리고 레이블로 세 용어가 포함된 Topic Node가 표시될 거예요.
레이블은 각 주제에 대한 상위 3개 용어를 사용해서 만들어졌어요. 따라서 주제 2에 포함된 강의와 연료 밸브 및/또는 물 밸브 문제와 관련된 강의에서 해당 용어가 자주 등장한다고 생각해도 괜찮겠죠?
그림 14: 데이터베이스 검색
그림 15: 주제 2 Node
저는 주어진 주제를 탐구하고 관계를 밝혀낼 수 있어요. 주제가 다른 4개의 Node와 관련되어 있으니까, 화면에 표시하고 싶은 Node를 선택할 수 있는 옵션이 제공되는 거죠.
강의 Node를 선택하면 이 주제에 포함된 모든 강의를 표시할 수 있어요. 시각화를 조정해서 색상과 크기를 추가할 수도 있고요. 이 경우 각 Node 유형은 서로 다른 색상을 가지고, Node 크기는 강의가 작성된 연도에 따라 결정돼요. 최신 강의일수록 Node의 크기가 커지는 거죠.
각 Node의 속성이 왼쪽에 표시돼요. 아래 이미지에서 강조 표시된 Node에 대한 정보를 볼 수 있고, 사용자가 강의가 저장된 사이트를 방문하고 싶다면 속성에서 URL을 클릭하면 돼요.
그림 16: 주제 내 개별 강의
제 데이터를 계속 탐색할 수 있어요. 강조 표시된 Lesson Node를 클릭하면 Lesson의 작성자, Lesson이 발생한 센터, 그리고 연관된 카테고리를 알려주는 Edge가 표시된답니다.
그림 17: 강의 Node 탐색
주제 Node로 돌아가서 다시 클릭하면 관련 카테고리가 표시돼요. 그런 다음 카테고리 Node를 탐색해서 위험 관리, 에너지, 전력 또는 지상 지원 시스템과 관련된 강의를 볼 수 있죠. 이걸 통해 내가 찾고 있는 것과 밀접하게 일치하는 다른 강의를 찾을 수 있어요.
키워드 검색 목록에서는 이러한 연결을 볼 수 없다는 점!
그림 18: 카테고리 Node 추가하기
그림 19: 카테고리 Node 탐색
저는 Neo4j, R/RStudio 및 Linkurious를 통해 현재 검색 엔진이 할 수 없는 방식으로 데이터를 탐색하고 시각화할 수 있다고 생각해요. 아직 진행 중인 작업이지만, 이러한 방식으로 Graph Database를 사용하면 사용자에게 보다 효과적인 검색 경험을 제공해서 답변을 찾는 시간을 줄이고 올바른 방향으로 프로젝트를 시작할 수 있다고 믿습니다.
이러한 도구의 조합을 통해 분석가는 대규모 문서 저장소에 대한 탁월한 분석 및 시각적 표현을 생성할 수 있어요.
궁금한 점이나 제안 사항이 있다면 트위터로 편하게 연락 주세요!
교훈을 얻은 데이터베이스
링크리어스
nasa
r/rstudio
RNeo4j
rstudio
Visualization
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
"모든 것이 그래프에요. Neo4j의 발전 덕분에 더 많은 데이터를 더 빠르게 활용할 수 있게 되었죠. 다른 사람들도 그래프 Neural Network 같은 기술 발전을 활용할 수 있게 될 거고요. 더 나은 세상을 만드는 데 도움이 될 거라고 생각해요." Fractal 5의 Machine Learning 엔지니어 Bjartur Hjaltason의 말입니다.
이번 5분 인터뷰에서는 레이캬비크에 있는 소셜 미디어 스타트업 Fractal 5의 두 분과 이야기를 나눴어요. Sara Masdottir는 애플리케이션 개발자이고, Bjartur Hjaltason은 Machine Learning 엔지니어입니다. 지난여름 GraphSummit에서 그래프 기술에 대한 그들의 생각과 경험을 들어봤답니다.
많은 그래프 전문가들처럼, 이 두 분도 그래프의 혁신적인 힘을 활용하고 있고, 이 기술의 미래에 대해 긍정적인 전망을 가지고 있어요.
Neo4j를 어떻게 사용하나요?
사라 마스도티르: 저는 GraphQL API를 사용해서 Neo4j로 데이터를 수집하고, 제품을 통해 얻는 데이터에서 인사이트를 얻고 있어요. 소비자를 대상으로 하는 제품에서 어떤 분석 이벤트를 캡처해야 할지, 그리고 그걸 통해 제품을 어떻게 개선할 수 있을지 고민하죠. 제품 엔지니어링이라고 할 수 있겠네요.
Neo4j를 선택한 이유는 무엇인가요?
사라 마스도티르: 처음에는 훨씬 간단한 솔루션으로 시작했어요. 가장 인기 있는 NoSQL 데이터베이스인 Firebase를 선택했죠. 3초 만에 바로 작동하고 모든 것을 연결할 수 있었거든요. 하지만 금방 처음 생각했던 아이디어가 최선이 아닐 수도 있다는 걸 깨달았어요. 이미 하고 있던 것을 중심으로 확장하고 싶었죠. 그런데 백엔드에 뭔가를 추가하려고 할 때마다 백엔드 전체를 리팩토링해야 한다는 걸 알게 됐어요. 코드가 엉망진창이 되어버렸죠.
사람 데이터를 다루고 있었는데, 친구, 친구의 친구처럼 관계가 얽히고 설켜서 정말 복잡해졌어요. 그래서 앞으로 나아가려면, 스타트업의 힘과 속도를 유지하려면 더 민첩하고 확장 가능한 게 필요하다는 걸 깨달았죠. 그러던 중 엔지니어 한 분이 Neo4j로 전환하자고 제안했고, Firebase 프로젝트를 완전히 버리고 Neo4j로 처음부터 다시 만드는 게 당연한 선택이었어요. 데이터를 어떻게 구성하고 싶은지 더 많이 생각할 수 있게 되면서 제품을 발전시키는 데도 도움이 됐고요.
Neo4j를 사용하면서 어떤 놀라운 결과를 얻었나요?
비야르투르 히알타손: 제 이름은 Bjartur이고 Machine Learning 엔지니어입니다. Neo4j를 사용하면서 가장 놀라웠던 점은, 타당하다면 얼마나 쉽고 직관적인가 하는 점이에요. Neo4j, 특히 Cypher를 사용할 때 할 수 있는 모든 작업이나 설명이 매우 시각적이기 때문이죠. 예를 들어, 제가 중심성 알고리즘이나 가장 가까운 이웃 등을 작성하고 테스트할 때, 시각적으로 도움이 되기 때문에 설명하기도 쉽고 쓰기도 쉽다는 걸 느꼈어요.
Neo4j를 시작하는 사람에게 조언을 한다면?
사라 마스도티르: 그냥 간단하게 시작하라고 말하고 싶어요. 완벽한 데이터베이스를 만들려고 하거나, 미래에 이러저러한 기능이 필요할 거라고 생각하는 함정에 빠지기 쉽거든요. 예전에는 데이터베이스를 그렇게 생각해야 했지만요. Neo4j를 사용하면서 "아, 데이터베이스를 변경하거나 지우거나 재설정할 필요 없이 새로운 Relationship이나 새로운 Node를 만들고 연결하기만 하면 되는구나"라는 걸 깨달았어요. 물론 온라인에 문서나 튜토리얼도 많고, 질문에 기꺼이 답변해 주는 친절한 직원들도 있고요.
그래프 기술의 미래는 어떻게 될 거라고 생각하시나요?
비야르투르 히알타손: 모든 것이 그래프에요. Neo4j의 발전 덕분에 더 많은 데이터를 더 빠르게 활용할 수 있게 되었죠. 다른 사람들도 그래프 Neural Network 같은 기술 발전을 활용할 수 있게 될 거고요.
오싹하면서도 뻔하게 들릴 수도 있지만, 정말 그렇다니까요! 제품 라인처럼 모든 물류가 잠재력을 최대로 발휘하도록 최적화되어 있다고 상상해보세요. 모든 운송 노선, 모든 공항 노선, 운송이 최적화되고 모든 것이 훨씬 더 좋아질 거예요. 그리고 Graph Data는 어디에나 있죠. 그래서 그래프의 미래는 정말 밝다고 생각해요.
더 나은 연결형 소셜 애플리케이션 구축 사용 사례를 통해 그래프 기술이 소셜 미디어 애플리케이션에 어떻게 사용되는지 자세히 알아보세요.
5분 인터뷰
Machine Learning
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
MSFT GraphRAG 출력을 Neo4j에 저장하고 LangChain 또는 LlamaIndex를 사용하여 로컬 및 글로벌 검색기를 구현합니다.
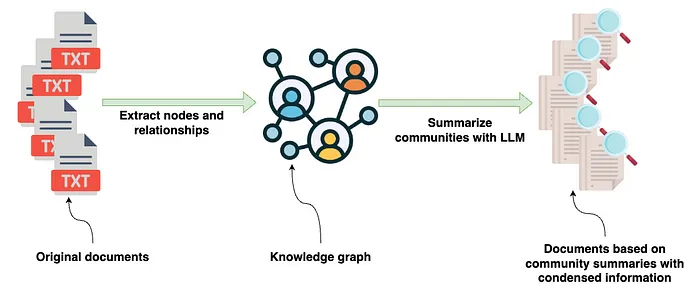
Microsoft의 GraphRAG 구현이 요즘 엄청난 관심을 받고 있죠. 제 지난 블로그 게시물에서는 그래프가 어떻게 구성되는지, 그리고 연구 논문에서 강조된 혁신적인 측면들을 살펴봤어요. 간단히 말해서, GraphRAG 라이브러리의 입력값은 다양한 정보가 담긴 소스 문서인데요. 이 문서는 LLM(Large Language Model)을 사용해서 처리되고, 문서에 나타나는 엔터티와 그 관계에 대한 구조화된 정보를 추출하는 데 사용돼요. 이렇게 추출된 구조화된 정보는 Knowledge Graph를 구성하는 데 쓰인답니다.
Microsoft의 GraphRAG 문서에 구현된 높은 수준의 인덱싱 파이프라인 — 작성자의 이미지
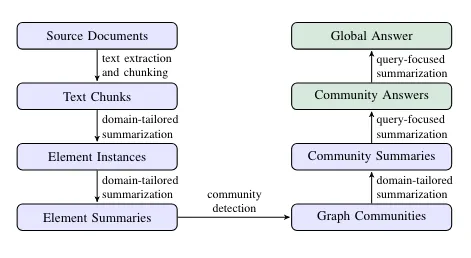
Knowledge Graph가 구성되면, GraphRAG 라이브러리는 그래프 알고리즘, 특히 Leiden 커뮤니티 감지 알고리즘과 LLM 프롬프트의 조합을 사용해서 Knowledge Graph에서 발견된 엔터티 및 관계 커뮤니티의 자연어 요약을 생성해요.
이번 포스팅에서는 GraphRAG 라이브러리를 사용해서 Neo4j에 저장한 다음, LangChain 및 LlamaIndex 오케스트레이션 프레임워크를 사용해서 Neo4j에서 직접 검색기를 설정하는 방법을 알아볼 거예요.
코드 및 GraphRAG 출력은 에서 확인할 수 있고, GraphRAG 추출 프로세스를 건너뛸 수도 있어요.
데이터세트
이 블로그 게시물에서 소개할 데이터세트는 Charles Dickens의 "A Christmas Carol"이고, Gutenberg Project를 통해 무료로 액세스할 수 있습니다.
찰스 디킨스의 크리스마스 캐롤
이 책이 강조 표시되어 있어서 원본 문서로 선택했는데, 소개 문서를 보면 추출을 쉽게 수행할 수 있다는 걸 알 수 있을 거예요.
그래프 구성
그래프 추출 부분을 건너뛰어도 괜찮지만, 제가 중요하다고 생각하는 몇 가지 구성 옵션에 대해 이야기해볼게요. 예를 들어, 그래프 추출은 토큰을 많이 사용하고 비용이 많이 들 수 있어요. 그래서 gpt-4o-mini처럼 비교적 저렴하면서도 성능이 좋은 LLM을 사용해서 추출을 테스트하는 게 합리적이죠. gpt-4-turbo를 사용하면 여기에 설명된 것처럼 뛰어난 정확도를 유지하면서 비용을 상당히 절감할 수 있답니다. 블로그 게시물을 참고해보세요.
GRAPHRAG_LLM_MODEL=gpt-4o-mini
가장 중요한 구성은 추출하려는 엔터티의 유형이에요. 기본적으로 조직, 사람, 이벤트 및 지역이 추출되죠.
이러한 기본 엔터티 유형은 책에 적합할 수 있지만, 특정 사용 사례에 대해 처리하려는 문서의 도메인에 따라 변경해야 할 수도 있어요.
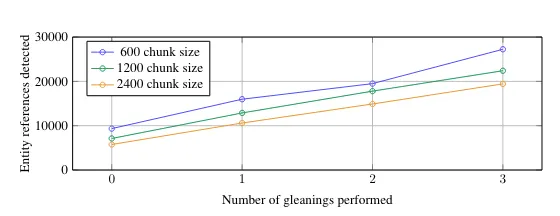
또 다른 중요한 구성 요소는 최대 수집 값이에요. 저자는 LLM이 단일 추출 단계에서 사용 가능한 모든 정보를 추출하지 않는다는 것을 확인했고, 별도로 검증했대요.
텍스트 청크 크기에 따른 추출 엔터티 수 - 이미지 GraphRAG paper, CC BY 4.0에 따라 라이센스가 부여됨
수집 구성을 통해 LLM은 여러 추출 과정을 수행할 수 있어요. 위 이미지에서 다중 패스(줍기)를 수행할 때 더 많은 정보를 추출한다는 것을 명확하게 볼 수 있죠. 다중 패스는 토큰 집약적이므로 gpt-4o-mini와 같은 저렴한 모델은 비용을 낮게 유지하는 데 도움이 될 거예요.
GRAPHRAG_ENTITY_EXTRACTION_MAX_GLEANINGS=1
또한 기본적으로 청구 또는 공변량 정보는 추출되지 않아요. GRAPHRAG_CLAIM_EXTRACTION_ENABLED 구성을 설정하여 활성화할 수 있답니다.
모든 구조화된 정보가 단일 패스에서 추출되지는 않는다는 것이 반복되는 주제인 것 같아요. 따라서 여기에도 수집 구성 옵션이 있는 거죠.
흥미로운 점은 프롬프트 튜닝 섹션에 대해 더 깊이 파고들 시간이 없었다는 거예요. Prompt Tuning은 선택 사항이지만 정확성을 향상시킬 수 있으므로 적극 권장된답니다.
Prompt Tuning ⚙️
구성이 설정된 후 다음을 따를 수 있어요. 그래프 추출 파이프라인을 실행하기 위한 지침, 이는 다음 단계로 구성되어 있대요.
파이프라인의 단계 — 다음의 이미지 GraphRAG paper, CC BY 4.0에 따라 라이센스가 부여됨
추출 파이프라인은 위 이미지의 파란색 단계를 모두 실행해요. 제 검토 이전 블로그 게시물에서 그래프 구성 및 커뮤니티 요약에 대해 자세히 알아보세요. MSFT GraphRAG 라이브러리의 그래프 추출 파이프라인의 출력은 다음과 같이 Parquet 파일 세트입니다. 덜스 작전의 예.
이러한 Parquet 파일은 다운스트림 분석, 시각화 및 검색을 위해 Neo4j Graph Database로 쉽게 가져올 수 있어요. 우리는 무료 클라우드 Aura 인스턴스를 사용하거나 로컬 Neo4j 환경을 설정할 수 있죠. 제 친구 마이클 헝거가 Parquet 파일을 Neo4j로 가져오는 대부분의 작업을 수행했어요. 이번 블로그 게시물에서는 가져오기 설명을 건너뛰겠지만, 5~6개의 CSV 파일에서 Knowledge Graph를 가져오고 구성하는 것으로 구성되어 있답니다. CSV 가져오기에 대해 자세히 알아보려면 다음을 확인하세요. Neo4j 그래프 아카데미 과정.
가져오기 코드는 GitHub의 Jupyter 노트북에 GraphRAG 출력 예시와 함께 있답니다.
그래프 추출을 수행할 때 청크 크기를 300으로 설정했었죠. 이후 작성자는 기본 청크 크기를 1200으로 변경했는데, 다음 Cypher 구문을 사용해서 청크 크기를 확인할 수 있어요.
db_query(
"MATCH (n:__Chunk__) RETURN n.n_tokens as token_count, count(*) AS count"
)
# token_count count
# 300 230
# 155 1
결과를 보면 230개의 청크에는 300개의 토큰이 있고, 마지막 청크에는 155개의 토큰만 있는 것을 확인할 수 있어요. 그럼 이제 예제 엔터티와 해당 설명을 한번 살펴볼까요?
db_query(
"MATCH (n:__Entity__) RETURN n.name AS name, n.description AS description LIMIT 1"
)
엔터티 이름 및 설명 예시 (이미지 출처: 작성자).
구텐베르크 프로젝트는 책의 어딘가, 아마도 처음 부분에 설명되어 있는 것 같아요. 설명을 통해 엔터티 이름보다 더 자세하고 복잡한 정보를 캡처할 수 있다는 점을 알 수 있죠. MSFT GraphRAG 문서는 텍스트에서 더 정교하고 미묘한 데이터를 유지하기 위해 도입되었어요.
예제 관계도 확인해 보도록 할게요.
db_query(
"MATCH ()-[n:RELATED]->() RETURN n.description AS description LIMIT 5"
)
관계 설명의 예시 이미지예요.
MSFT GraphRAG는 자세한 관계 설명을 캡처해서 엔터티 간의 단순한 관계 유형을 추출하는 것 이상의 역할을 해요. 이 기능을 사용하면 단순한 관계 유형보다 훨씬 더 미묘한 정보를 캡처할 수 있다는 점이 매력적이죠.
단일 커뮤니티와 생성된 설명을 한번 살펴볼까요?
db_query("""
MATCH (n:__Community__)
RETURN n.title AS title, n.summary AS summary, n.full_content AS full_content LIMIT 1
""")
커뮤니티 설명 예시 이미지예요.
커뮤니티에는 LLM을 사용해서 생성된 제목, 요약 및 전체 콘텐츠가 있어요. 작성자가 검색 중에 전체 맥락을 사용하는지, 아니면 요약만 사용하는지는 확인하지 못했지만 둘 중 하나를 선택할 수 있죠. 정보가 나온 엔터티와 관계를 가리키는 `full_content`에서 인용을 볼 수 있어요. 다음 예와 같이 LLM이 인용이 너무 길면 때때로 잘라내는 게 재밌어요.
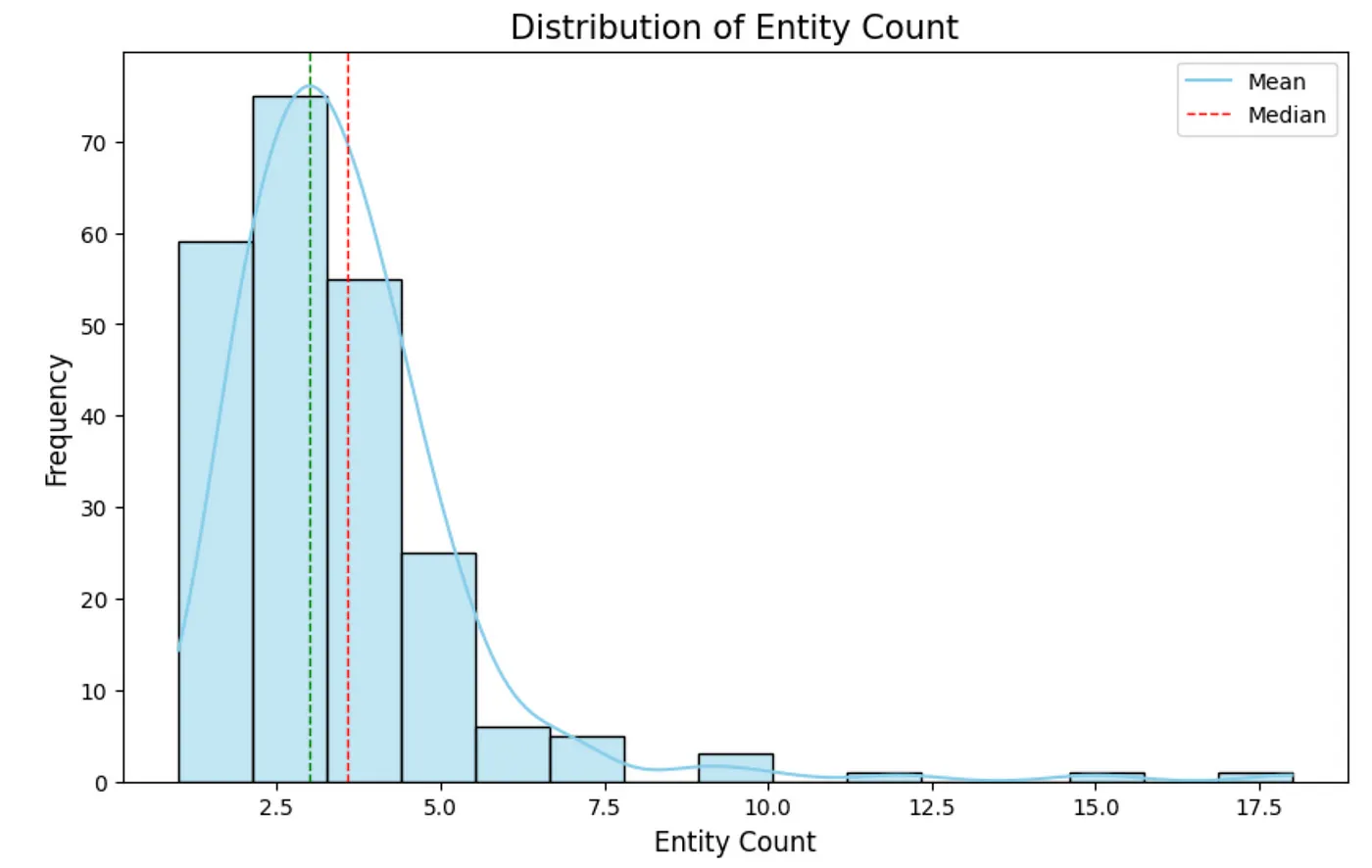
텍스트 청크는 300개의 토큰으로 구성되어 있다는 점, 기억하시죠? 그래서 추출된 엔터티 수는 텍스트 청크당 평균 약 3개 정도로 비교적 적어요. 추출은 단일 추출 패스로 진행됐어요. 수집 횟수를 늘리면 분포가 어떻게 변할지 살펴보는 것도 흥미로울 것 같아요.
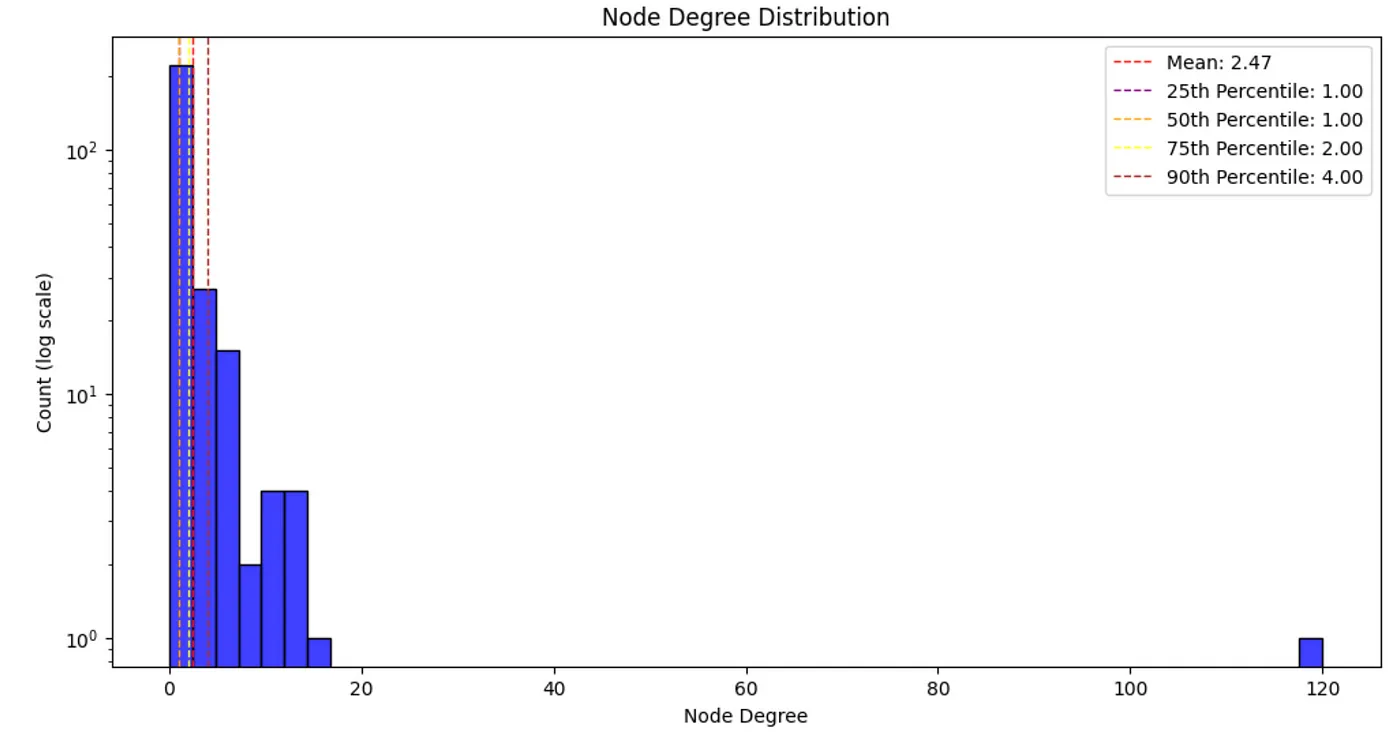
다음으로는 Node 차수 분포를 평가해볼게요. Node 등급은 해당 Node가 가지고 있는 관계의 수를 의미해요.
degree_dist_df = db_query(
"""
MATCH (e:__Entity__)
RETURN count {(e)-[:RELATED]-()} AS node_degree
"""
)
# Calculate mean and median
mean_degree = np.mean(degree_dist_df['node_degree'])
percentiles = np.percentile(degree_dist_df['node_degree'], [25, 50, 75, 90])
# Create a histogram with a logarithmic scale
plt.figure(figsize=(12, 6))
sns.histplot(degree_dist_df['node_degree'], bins=50, kde=False, color='blue')
# Use a logarithmic scale for the x-axis
plt.yscale('log')
# Adding labels and title
plt.xlabel('Node Degree')
plt.ylabel('Count (log scale)')
plt.title('Node Degree Distribution')
# Add mean, median, and percentile lines
plt.axvline(mean_degree, color='red', linestyle='dashed', linewidth=1, label=f'Mean: {mean_degree:.2f}')
plt.axvline(percentiles[0], color='purple', linestyle='dashed', linewidth=1, label=f'25th Percentile: {percentiles[0]:.2f}')
plt.axvline(percentiles[1], color='orange', linestyle='dashed', linewidth=1, label=f'50th Percentile: {percentiles[1]:.2f}')
plt.axvline(percentiles[2], color='yellow', linestyle='dashed', linewidth=1, label=f'75th Percentile: {percentiles[2]:.2f}')
plt.axvline(percentiles[3], color='brown', linestyle='dashed', linewidth=1, label=f'90th Percentile: {percentiles[3]:.2f}')
# Add legend
plt.legend()
# Show the plot
plt.show()
Node 등급 분포. 이미지 출처: 작성자.
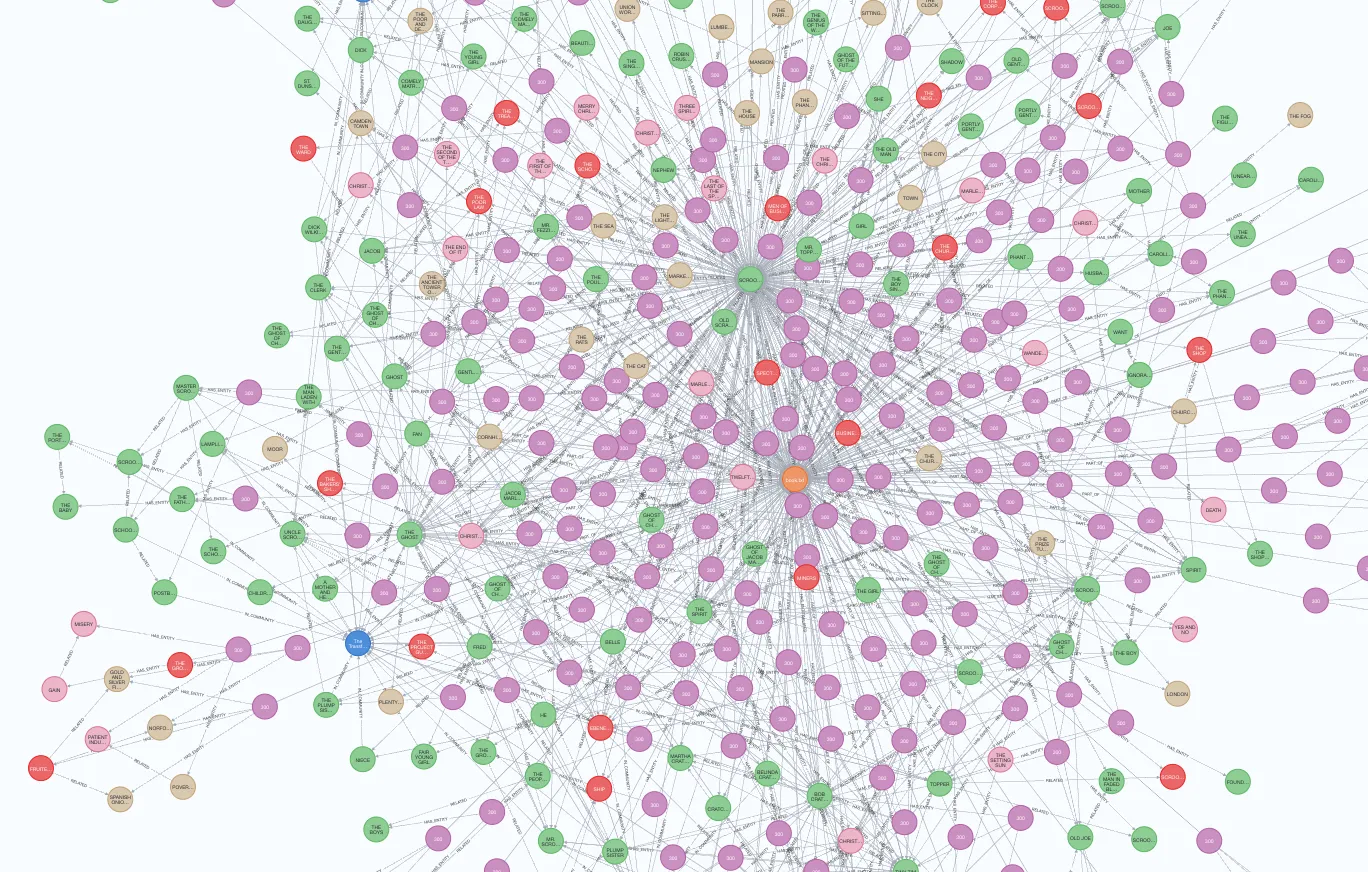
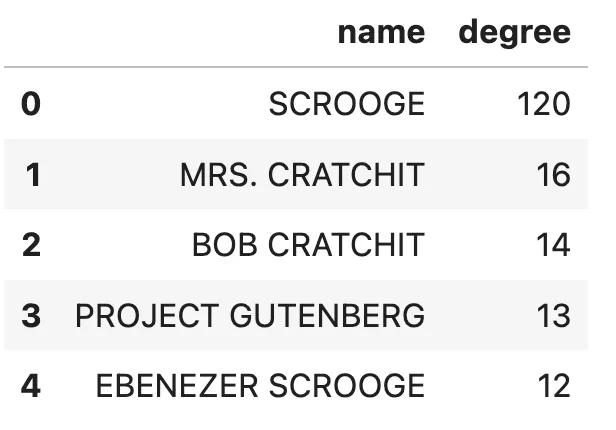
대부분의 실제 네트워크는 멱법칙(power law) Node 차수 분포를 따르는데, 이는 대부분의 Node가 비교적 작은 차수를 갖고, 일부 중요한 Node는 많은 차수를 갖는다는 의미에요. 이 그래프는 크기가 작지만 Node 차수는 멱법칙을 따르고 있네요. 어떤 엔터티가 120개의 관계(전체 엔터티의 43%에 연결)를 가지고 있는지 확인해 보는 것도 재밌을 것 같아요.
db_query("""
MATCH (n:__Entity__)
RETURN n.name AS name, count{(n)-[:RELATED]-()} AS degree
ORDER BY degree DESC LIMIT 5""")
관계가 가장 많은 엔터티를 보여주고 있어요. 이미지 출처는 작성자입니다.
단연 스크루지가 책의 주인공이라고 짐작할 수 있겠죠? Ebenezer Scrooge와 Scrooge가 실제로 동일한 엔터티라고 추측해 볼 수도 있지만, MSFT GraphRAG에는 엔터티 확인 단계가 없어서 병합되지는 않았어요.
그리고 Project Gutenberg에는 책 내용과는 관련 없는 13개의 관계가 있네요. 데이터를 분석하고 정리하는 과정이 노이즈 정보를 줄이는 데 얼마나 중요한지 보여주는 부분이에요.
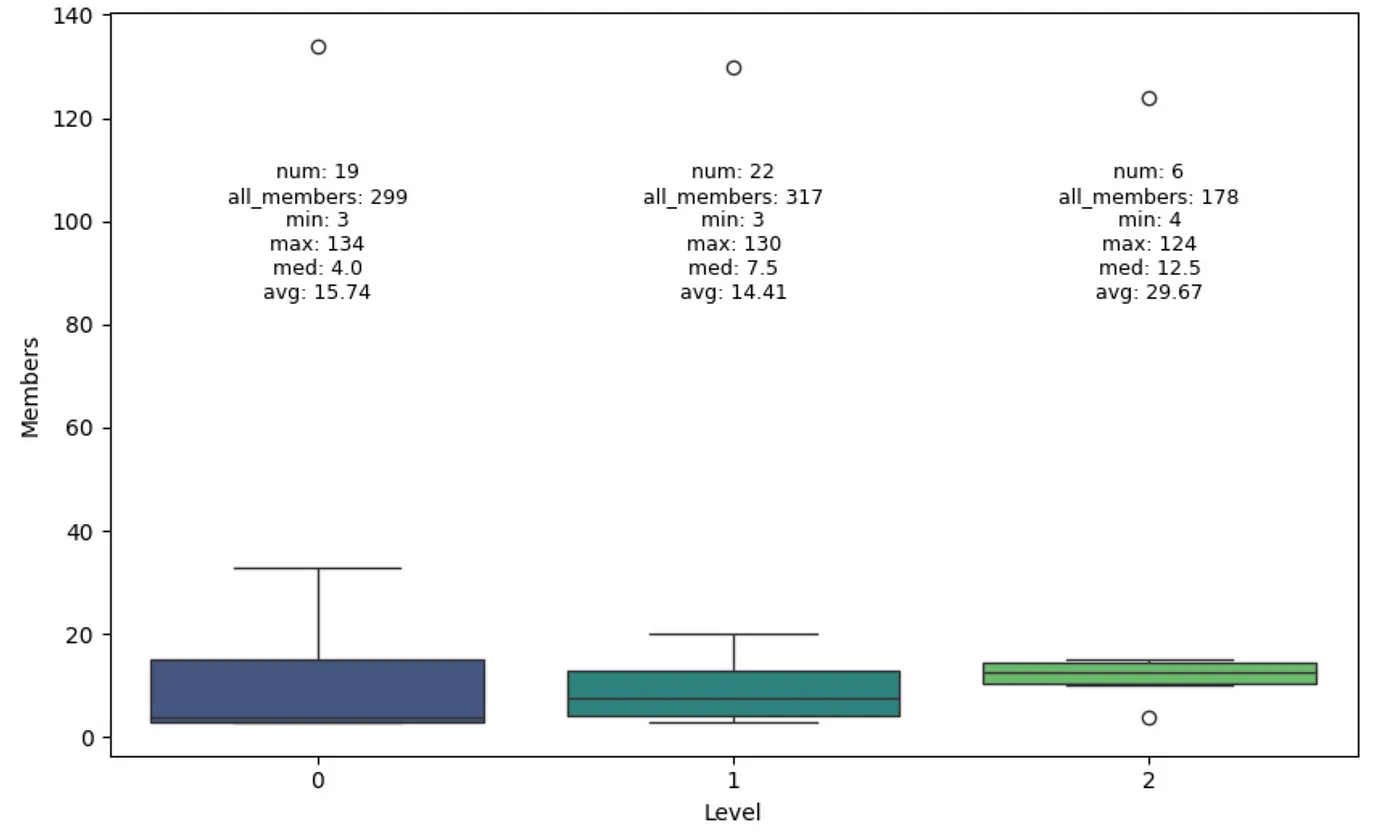
마지막으로, 레벨별 커뮤니티 규모 분포를 한번 살펴볼까요?
community_data = db_query("""
MATCH (n:__Community__)
RETURN n.level AS level, count{(n)-[:IN_COMMUNITY]-()} AS members
""")
stats = community_data.groupby('level').agg(
min_members=('members', 'min'),
max_members=('members', 'max'),
median_members=('members', 'median'),
avg_members=('members', 'mean'),
num_communities=('members', 'count'),
total_members=('members', 'sum')
).reset_index()
# Create box plot
plt.figure(figsize=(10, 6))
sns.boxplot(x='level', y='members', data=community_data, palette='viridis')
plt.xlabel('Level')
plt.ylabel('Members')
# Add statistical annotations
for i in range(stats.shape[0]):
level = stats['level'][i]
max_val = stats['max_members'][i]
text = (f"num: {stats['num_communities'][i]}n"
f"all_members: {stats['total_members'][i]}n"
f"min: {stats['min_members'][i]}n"
f"max: {stats['max_members'][i]}n"
f"med: {stats['median_members'][i]}n"
f"avg: {stats['avg_members'][i]:.2f}")
plt.text(level, 85, text, horizontalalignment='center', fontsize=9)
plt.show()
레벨별 커뮤니티 규모 분포예요. 이미지 출처는 작성자입니다.
Leiden 알고리즘은 세 가지 레벨의 커뮤니티를 식별했는데, 레벨이 높을수록 평균적으로 규모가 더 크네요. 하지만 all_members 수를 확인해 보면, 이론적으로는 동일해야 함에도 불구하고 각 레벨마다 노드 수가 다른 걸 확인할 수 있어요. 제가 알지 못하는 기술적인 부분이 있는 것 같아요. 그리고 커뮤니티가 더 높은 레벨에서 병합된다면, 왜 레벨 0에는 19개의 커뮤니티가 있고 레벨 1에는 22개의 커뮤니티가 있을까요? 작성자분이 여기서 몇 가지 최적화와 요령을 사용했지만, 아직 자세히 살펴볼 시간이 없었다고 하네요.
AI를 위한 Knowledge Graph에 대한 무료 Gartner® 보고서를 읽어보세요.
검색기 구현
이번 블로그 포스팅의 마지막 부분에서는 MSFT GraphRAG에 지정된 로컬 및 글로벌 검색기에 대해 알아볼 거예요. 검색기는 LangChain 및 LlamaIndex와 함께 구현되고 통합되죠.
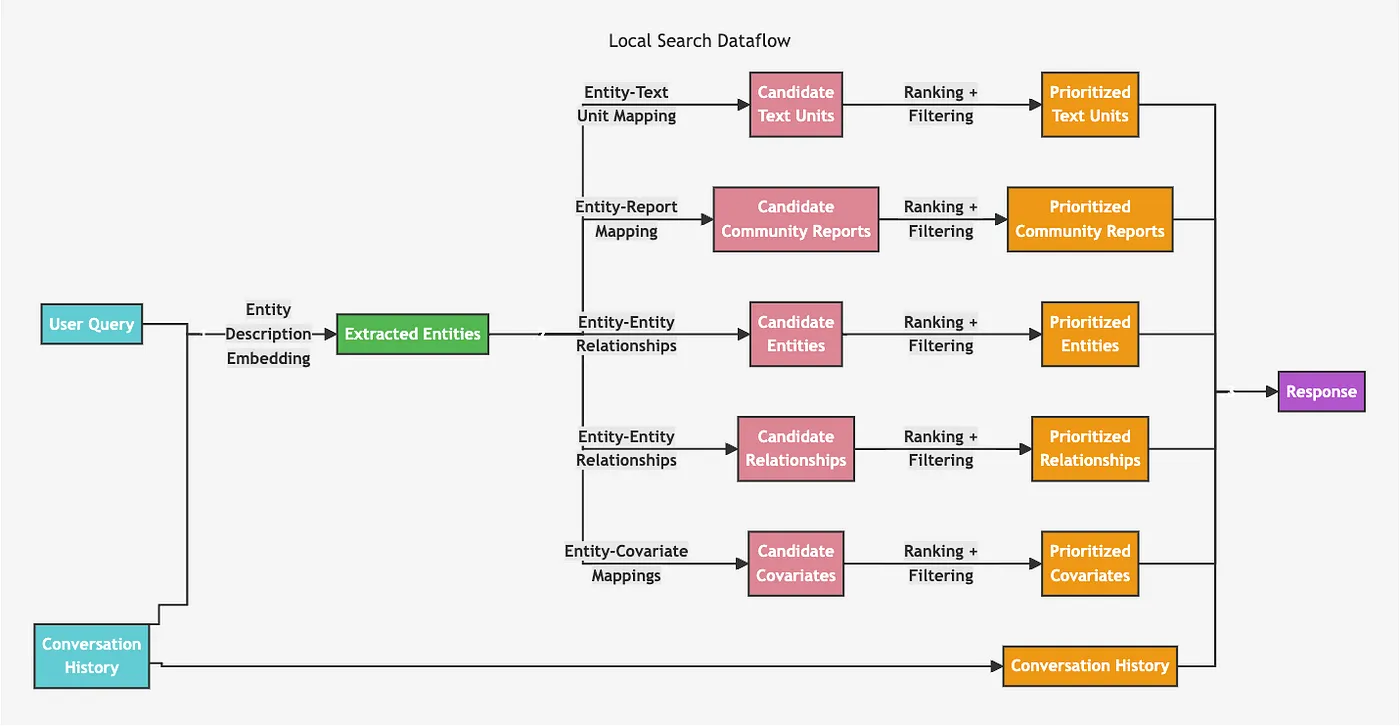
로컬 리트리버
로컬 검색기는 Vector Search를 사용해서 관련된 Nodes를 식별한 다음, 연결된 정보를 수집해서 LLM 프롬프트에 넣어줘요.
로컬 리트리버 아키텍처. 이미지 출처:
이 다이어그램, 복잡해 보일 수 있지만 쉽게 구현할 수 있어요. 먼저 엔터티 설명의 텍스트 임베딩을 기반으로 하는 벡터 유사성 검색을 사용해서 관련 엔터티를 식별하는 거죠. 관련 엔터티가 식별되면 관련 텍스트 덩어리, 관계, 커뮤니티 요약 등을 탐색할 수 있어요. 벡터 유사성 검색을 사용한 다음 그래프 전체를 탐색하는 패턴은 LangChain과 LlamaIndex 모두의 retrieval_query 기능을 사용해서 쉽게 구현할 수 있답니다.
가장 먼저 벡터 index를 구성해야 해요.
index_name = "entity"
db_query(
"""
CREATE VECTOR INDEX """
+ index_name
+ """ IF NOT EXISTS FOR (e:__Entity__) ON e.description_embedding
OPTIONS {indexConfig: {
`vector.dimensions`: 1536,
`vector.similarity_function`: 'cosine'
}}
"""
)
그리고 커뮤니티의 엔터티가 나타나는 고유한 텍스트 청크의 수로 정의되는 커뮤니티 가중치를 계산하고 저장할 거예요.
db_query(
"""
MATCH (n:`__Community__`)<-[:IN_COMMUNITY]-()<-[:HAS_ENTITY]-(c)
WITH n, count(distinct c) AS chunkCount
SET n.weight = chunkCount"""
)
각 섹션의 후보자 수(텍스트 단위, 커뮤니티 보고서 등)는 구성 가능해요. 원래 구현에는 토큰 수를 기반으로 한 필터링이 약간 더 포함되어 있지만 여기서는 단순화할게요. 기본 구성 값을 기반으로 다음과 같은 단순화된 상위 후보 필터 값을 개발했어요.
LangChain 구현부터 시작해볼게요. 우리가 정의해야 할 유일한 것은 더 복잡한 retrieval_query 랍니다.
lc_retrieval_query = """
WITH collect(node) as nodes
// Entity - Text Unit Mapping
WITH
collect {
UNWIND nodes as n
MATCH (n)<-[:HAS_ENTITY]->(c:__Chunk__)
WITH c, count(distinct n) as freq
RETURN c.text AS chunkText
ORDER BY freq DESC
LIMIT $topChunks
} AS text_mapping,
// Entity - Report Mapping
collect {
UNWIND nodes as n
MATCH (n)-[:IN_COMMUNITY]->(c:__Community__)
WITH c, c.rank as rank, c.weight AS weight
RETURN c.summary
ORDER BY rank, weight DESC
LIMIT $topCommunities
} AS report_mapping,
// Outside Relationships
collect {
UNWIND nodes as n
MATCH (n)-[r:RELATED]-(m)
WHERE NOT m IN nodes
RETURN r.description AS descriptionText
ORDER BY r.rank, r.weight DESC
LIMIT $topOutsideRels
} as outsideRels,
// Inside Relationships
collect {
UNWIND nodes as n
MATCH (n)-[r:RELATED]-(m)
WHERE m IN nodes
RETURN r.description AS descriptionText
ORDER BY r.rank, r.weight DESC
LIMIT $topInsideRels
} as insideRels,
// Entities description
collect {
UNWIND nodes as n
RETURN n.description AS descriptionText
} as entities
// We don't have covariates or claims here
RETURN {Chunks: text_mapping, Reports: report_mapping,
Relationships: outsideRels + insideRels,
Entities: entities} AS text, 1.0 AS score, {} AS metadata
"""
lc_vector = Neo4jVector.from_existing_index(
OpenAIEmbeddings(model="text-embedding-3-small"),
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
index_name=index_name,
retrieval_query=lc_retrieval_query
)
이 Cypher query는 node 집합에서 여러 분석 작업을 수행해서 관련 텍스트 데이터를 추출하고 구성해요.
1. 엔터티-텍스트 단위 매핑: 각 node에 대해 query는 연결된 텍스트 청크(__Chunk__)를 식별하고 이를 각 청크와 연결된 개별 node 수로 집계하고 빈도별로 정렬해요. 최상위 청크는 'text_mapping'으로 반환되죠.
2. 엔터티-보고서 매핑: 각 node에 대해 query는 연결된 커뮤니티(__Community__)를 찾고 순위 및 가중치를 기준으로 최상위 커뮤니티의 요약을 반환해요.
3. 외부 관계: 이 섹션에서는 관련 엔터티(m)가 초기 node 집합의 일부가 아닌 관계(RELATED)에 대한 설명을 추출해요. 관계는 순위가 지정되며 최상위 외부 관계로 제한된답니다.
4. 내부 관계: 외부 관계와 유사하지만 이번에는 두 엔터티가 초기 node 집합 내에 있는 관계만 고려해요.
5. 엔터티 설명: 초기 세트의 각 node에 대한 설명을 간단히 수집합니다.
마지막으로 query는 수집된 데이터를 기본 점수 및 빈 메타데이터 개체와 함께 청크, 보고서, 내부 및 외부 관계, 엔터티 설명으로 구성된 구조화된 결과로 결합해요. 검색 부분 중 일부를 제거해서 결과에 어떤 영향을 미치는지 테스트할 수 있는 옵션도 있답니다.
이제 다음 코드를 사용해서 검색기를 실행할 수 있어요.
docs = lc_vector.similarity_search(
"What do you know about Cratchitt family?",
k=topEntities,
params={
"topChunks": topChunks,
"topCommunities": topCommunities,
"topOutsideRels": topOutsideRels,
"topInsideRels": topInsideRels,
},
)
# print(docs[0].page_content)
LlamaIndex를 사용해서 똑같은 검색 패턴을 구현할 수 있어요. LlamaIndex의 경우, Vector Index가 제대로 작동하려면 먼저 Node에 메타데이터를 추가해야 해요. 만약 Node에 기본 메타데이터가 추가되지 않으면 Vector Index는 에러를 뱉을 거예요.
# https://github.com/run-llama/llama_index/blob/main/llama-index-core/llama_index/core/vector_stores/utils.py#L32
from llama_index.core.schema import TextNode
from llama_index.core.vector_stores.utils import node_to_metadata_dict
content = node_to_metadata_dict(TextNode(), remove_text=True, flat_metadata=False)
db_query(
"""
MATCH (e:__Entity__)
SET e += $content""",
{"content": content},
)
이번에도 LlamaIndex의 `retrieval_query` 기능을 사용해서 검색기를 정의할 수 있어요. LangChain과는 다르게, 쿼리 매개변수 대신 f-string을 사용해서 상위 후보 필터 매개변수를 전달하죠.
retrieval_query = f"""
WITH collect(node) as nodes
// Entity - Text Unit Mapping
WITH
nodes,
collect {{
UNWIND nodes as n
MATCH (n)<-[:HAS_ENTITY]->(c:__Chunk__)
WITH c, count(distinct n) as freq
RETURN c.text AS chunkText
ORDER BY freq DESC
LIMIT {topChunks}
}} AS text_mapping,
// Entity - Report Mapping
collect {{
UNWIND nodes as n
MATCH (n)-[:IN_COMMUNITY]->(c:__Community__)
WITH c, c.rank as rank, c.weight AS weight
RETURN c.summary
ORDER BY rank, weight DESC
LIMIT {topCommunities}
}} AS report_mapping,
// Outside Relationships
collect {{
UNWIND nodes as n
MATCH (n)-[r:RELATED]-(m)
WHERE NOT m IN nodes
RETURN r.description AS descriptionText
ORDER BY r.rank, r.weight DESC
LIMIT {topOutsideRels}
}} as outsideRels,
// Inside Relationships
collect {{
UNWIND nodes as n
MATCH (n)-[r:RELATED]-(m)
WHERE m IN nodes
RETURN r.description AS descriptionText
ORDER BY r.rank, r.weight DESC
LIMIT {topInsideRels}
}} as insideRels,
// Entities description
collect {{
UNWIND nodes as n
RETURN n.description AS descriptionText
}} as entities
// We don't have covariates or claims here
RETURN "Chunks:" + apoc.text.join(text_mapping, '|') + "nReports: " + apoc.text.join(report_mapping,'|') +
"nRelationships: " + apoc.text.join(outsideRels + insideRels, '|') +
"nEntities: " + apoc.text.join(entities, "|") AS text, 1.0 AS score, nodes[0].id AS id, {{_node_type:nodes[0]._node_type, _node_content:nodes[0]._node_content}} AS metadata
"""
그리고 반환 값이 살짝 다르다는 점도 기억해야 해요. Node 타입과 콘텐츠를 메타데이터로 반환해야 하는데, 그렇지 않으면 리트리버가 제대로 작동하지 않을 거예요. 이제 Neo4j Vector Store를 인스턴스화하고, 이걸 쿼리 엔진으로 사용해 봅시다.
response = loaded_index.query("What do you know about Scrooge?")
print(response.response)
#print(response.source_nodes[0].text)
# Scrooge is an employee who is impacted by the generosity and festive spirit
# of the Fezziwig family, particularly Mr. and Mrs. Fezziwig. He is involved
# in the memorable Domestic Ball hosted by the Fezziwigs, which significantly
# influences his life and contributes to the broader narrative of kindness
# and community spirit.
바로 떠오르는 생각 중 하나는, Vector Search만 하는 대신 관련 엔티티를 찾기 위해 하이브리드 접근 방식(Vector + 키워드)을 사용해서 로컬 검색을 더 향상시킬 수 있다는 점이에요.
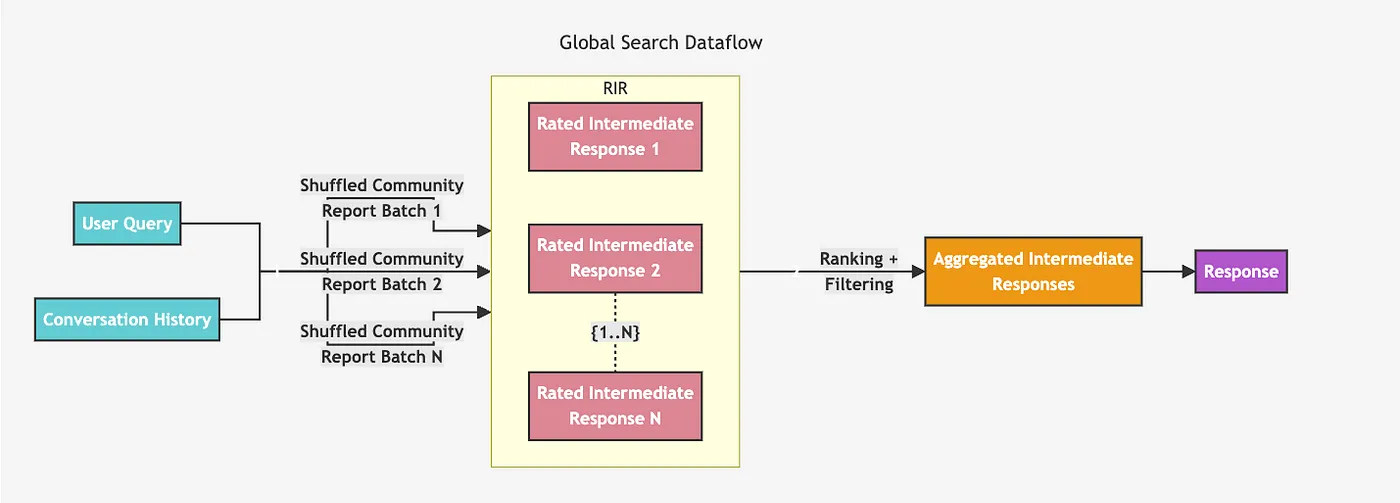
글로벌 리트리버
The 글로벌 리트리버 아키텍처는 조금 더 간단해요. 지정된 계층 수준에서 모든 커뮤니티 요약을 반복해서 중간 요약을 만들고, 이 중간 요약을 바탕으로 최종 응답을 생성하는 방식인 것 같아요.
글로벌 리트리버 아키텍처. 이미지 출처:
어떤 계층 수준을 반복할지 미리 정해야 하는데, 뭐가 더 잘 작동할지 모르니까 간단한 결정은 아니에요. 계층적 수준이 높아질수록 커뮤니티 규모는 커지지만, 커뮤니티 수는 줄어들죠. 요약을 직접 검사하지 않고는 얻을 수 있는 유일한 정보이기도 하고요.
다른 파라미터를 사용하면 순위나 가중치 임계값 미만의 커뮤니티를 무시할 수도 있지만, 여기서는 사용하지 않을 거예요. LangChain을 사용해서 글로벌 검색기를 구현할 건데요, map and reduce 프롬프트는 GraphRAG 논문에 나온 것과 같아요. 시스템 프롬프트가 엄청 길어서 여기에 넣거나 체인 구성을 포함하진 않을 거예요. 하지만 모든 코드는 다음 notebook에서 확인할 수 있어요.
print(global_retriever("What is the story about?", 2))
이 이야기는 주로 삶에 대한 냉소적인 견해를 가지고 크리스마스를 싫어하는 스크루지 영감님을 중심으로 펼쳐져요. 그의 변화는 죽은 동업자 제이콥 말리의 유령이 나타나면서 시작되고, 이어서 크리스마스 과거, 현재, 미래를 상징하는 세 유령이 나타나죠. 이 만남들을 통해 스크루지는 자신의 삶과 행동의 결과를 되돌아보게 되고, 결국 크리스마스 정신을 받아들이면서 엄청난 개인적인 성장을 경험하게 된답니다 [데이터: 보고서 (32, 17, 99, 86, +more)].
### Jacob Marley와 영혼의 역할
Jacob Marley의 유령은 초자연적인 촉매제 역할을 하면서 스크루지에게 다가올 세 영혼의 방문을 경고하죠. 각 영혼은 스크루지를 자기 발견의 여정으로 이끌면서 그의 선택이 미치는 영향과 연민의 중요성을 보여줘요. 영혼은 스크루지에게 그의 행동이 자신의 삶뿐만 아니라 다른 사람들의 삶에도 어떤 영향을 미치는지 보여주면서, 특히 구원과 상호 연결이라는 주제를 강조하고 있어요 [데이터: 보고서 (86, 17, 99, +more)].
### 스크루지의 관계와 변화
스크루지와 Cratchit 가족, 특히 Bob Cratchit과 그의 아들 Tiny Tim과의 관계는 그의 변화에 아주 중요한 역할을 해요. 영혼이 제시한 비전을 통해 스크루지는 공감 능력을 키우고 Cratchit 가족의 상황을 개선하기 위한 실질적인 조치를 취하도록 영감을 얻죠. 이야기는 스크루지의 새롭게 발견된 관대함이 그의 공동체 내에서 동정심과 사회적 책임을 키우기 때문에 개인의 행동이 사회에 중대한 영향을 미칠 수 있다는 점을 강조하고 있어요 [데이터: 보고서 (25, 158, 159, +more)].
### 구원과 희망의 주제
전반적으로 이 이야기는 시대를 초월하는 희망의 상징이며, 공감, 성찰, 개인적인 변화의 가능성과 같은 주제를 강조하고 있어요. 외로운 구두쇠에서 자비로운 인물로 변모한 스크루지의 여정은 변화하기에 너무 늦지 않았다는 것을 보여주죠. 작은 친절의 행동은 개인과 더 넓은 지역 사회에 상당한 긍정적인 영향을 미칠 수 있어요 [데이터: 보고서(32, 102, 126, 148, 158, 159, +more)].
요약하자면, 이 이야기는 크리스마스의 변혁적인 힘과 인간 관계의 중요성을 보여주면서 구원과 휴가 기간 동안 한 개인이 다른 사람에게 미칠 수 있는 영향에 대한 감동적인 이야기가 되는 것 같아요.
지정된 수준의 모든 커뮤니티를 반복하는 글로벌 검색기에 적합하기 때문에 응답은 매우 길고 철저하죠. 커뮤니티 계층 수준을 변경하면 응답이 어떻게 바뀌는지 테스트해 볼 수 있어요.
요약
이번 블로그 포스팅에서는 Microsoft의 GraphRAG를 Neo4j에 통합하고 LangChain 및 LlamaIndex를 사용하여 검색기를 구현하는 방법을 보여드렸어요. 이렇게 하면 GraphRAG를 다른 검색기 또는 에이전트와 원활하게 통합할 수 있죠. 로컬 검색기는 Vector Embedding 유사성 검색과 그래프 순회를 결합하는 반면, 글로벌 검색기는 커뮤니티 요약을 반복하여 포괄적인 응답을 생성해요. 이 구현은 향상된 정보 검색 및 질문 답변을 위해 구조화된 Knowledge Graph와 언어 모델을 결합하는 기능을 보여주고 있어요. 이러한 Knowledge Graph에는 사용자 정의 및 실험의 여지가 있다는 점을 기억하는 것이 중요해요. 이에 대해서는 다음 블로그 포스팅에서 살펴볼게요.
언제나 그렇듯이 코드는 에서 확인할 수 있어요.
필수 GraphRAG
Knowledge Graph를 통해 RAG의 잠재력을 최대한 활용하세요. 한정된 기간 동안 Manning으로부터 최종 가이드를 무료로 받아보세요.
GraphRAG
Microsoft
RAG
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
Named Entity Linking과 Wikipedia 데이터 강화를 결합하여 인터넷 뉴스를 분석하는 방법이에요
인터넷에는 정말 많은 정보가 매일 쏟아져 나오죠. 뉴스나 다른 콘텐츠 웹사이트를 잘 이해하는 건 비즈니스 성공에 점점 더 중요해지고 있어요. 기회를 잡거나, 새로운 리드를 만들거나, 경제 지표를 파악하는 데 도움이 될 수 있거든요.
이번 블로그에서는요, Natural Language Processing(NLP)과 Knowledge Graph 기술을 합쳐서 뉴스 모니터링 데이터 파이프라인을 만드는 방법을 보여드리려고 해요.
데이터 파이프라인은 크게 세 부분으로 나눌 수 있어요. 첫 번째는 인터넷 뉴스 제공업체의 기사를 스크랩하는 부분이고요. 다음으로는 NLP 파이프라인을 거쳐 기사를 분석하고, 그 결과를 Knowledge Graph 형태로 저장해요. 마지막으로, 위키데이터 API를 이용해서 지식을 더 풍부하게 만들 거예요. Knowledge Graph를 사용해서 데이터 파이프라인 정보를 저장하면 어떤 장점이 있는지 보여드리기 위해 간단한 네트워크 분석을 해보고, 유용한 정보를 찾아볼게요.
목차
인터넷 뉴스 스크래핑
Wikiifier를 사용한 Entity Linking
Wikipedia 데이터 강화
그래프 모델
Knowledge Graph 저장을 위해 Neo4j를 사용할 거예요. 이 블로그를 따라 하시려면 APOC와 Graph Data Science 라이브러리를 모두 설치해야 해요. 모든 코드는 에서 확인하실 수 있습니다.
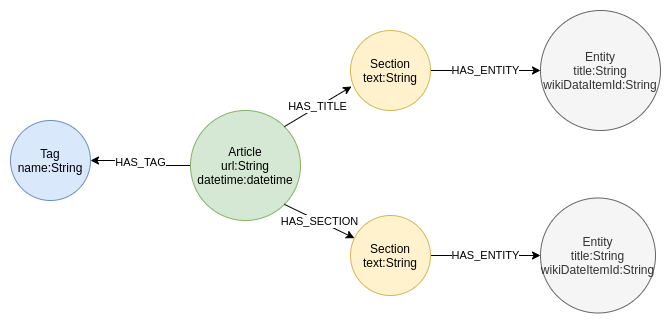
그래프 스키마. 작성자 이미지
그래프 데이터 모델은 기사와 그 태그로 구성되어 있어요. 각 기사에는 여러 텍스트 섹션이 있고요. NLP 파이프라인으로 섹션 텍스트를 분석하면 언급된 항목을 추출해서 다시 그래프에 저장하는 방식이에요.
먼저 고유 제약 조건(Unique Constraint)을 정의해서 그래프를 만들어볼게요. 고유성 제약 조건은 데이터 무결성을 보장하고 Cypher 쿼리 성능을 최적화하는 데 사용돼요.
CREATE CONSTRAINT IF NOT EXISTS ON (a:Article) ASSERT a.url IS UNIQUE;
CREATE CONSTRAINT IF NOT EXISTS ON (e:Entity) ASSERT e.wikiDataItemId is UNIQUE;
CREATE CONSTRAINT IF NOT EXISTS ON (t:Tag) ASSERT t.name is UNIQUE;
인터넷 뉴스 스크래핑
다음으로는 CNET 뉴스 포털을 스크래핑해볼게요. CNET 포털을 선택한 이유는 HTML 구조가 가장 일관적이어서 스크래핑 자체보다는 데이터 파이프라인 개념을 더 쉽게 보여줄 수 있기 때문이에요. HTML 스크래핑에는 `apoc.load.html` 프로시저를 사용할 건데요, 이 프로시저는 jsoup을 사용해요. 더 자세한 내용은 에서 확인하실 수 있습니다.
먼저 인기 있는 주제들을 반복하면서 각 주제에 대한 최신 기사 12개의 링크를 Neo4j에 저장할 거예요.
CALL apoc.load.html("",
{topics:"div.tag-listing > ul > li > a"}) YIELD value
UNWIND value.topics as topic
WITH "" + topic.attributes.href as link
CALL apoc.load.html(link, {article:"div.row.asset > div > a"}) YIELD value
UNWIND value.article as article
WITH distinct "" + article.attributes.href as article_link
MERGE (a:Article{url:article_link});
이제 기사 링크가 있으니, 기사 내용과 태그, 게시 날짜를 스크랩할 수 있겠죠? 앞서 정의한 그래프 스키마에 맞춰서 결과를 저장할 거예요.
MATCH (a:Article)
CALL apoc.load.html(a.url,
{date:"time", title:"h1.speakableText", text:"div.article-main-body > p", tags: "div.tagList > a"}) YIELD value
SET a.datetime = datetime(value.date[0].attributes.datetime)
FOREACH (_ IN CASE WHEN value.title[0].text IS NOT NULL THEN [true] ELSE [] END |
CREATE (a)-[:HAS_TITLE]->(:Section{text:value.title[0].text})
)
FOREACH (t in value.tags |
MERGE (tag:Tag{name:t.text}) MERGE (a)-[:HAS_TAG]->(tag)
)
WITH a, value.text as texts
UNWIND texts as row
WITH a,row.text as text
WHERE text IS NOT NULL
CREATE (a)-[:HAS_SECTION]->(:Section{text:text});
기사 결과를 저장하는 Cypher 쿼리를 더 복잡하게 만들고 싶지 않아서, 계속하기 전에 태그를 약간 정리해야 해요.
MATCH (n:Tag)
WHERE n.name CONTAINS "Notification"
DETACH DELETE n;
스크래핑 프로세스를 평가하고 얼마나 많은 기사가 성공적으로 스크래핑되었는지 한번 살펴볼까요?
MATCH (a:Article)
RETURN exists((a)-[:HAS_SECTION]->()) as scraped_articles,
count(*) as count
제 경우에는 245개 기사에 대한 정보 수집에 성공했어요. 타임머신이 없으면 이 분석을 똑같이 재현할 수는 없을 거예요. 2021년 1월 30일에 웹사이트를 스크랩했는데, 아마도 나중에 하실 것 같아요. 대부분의 분석 쿼리를 일반적으로 준비했으므로 뉴스 스크랩 날짜와 관계없이 잘 작동할 거예요.
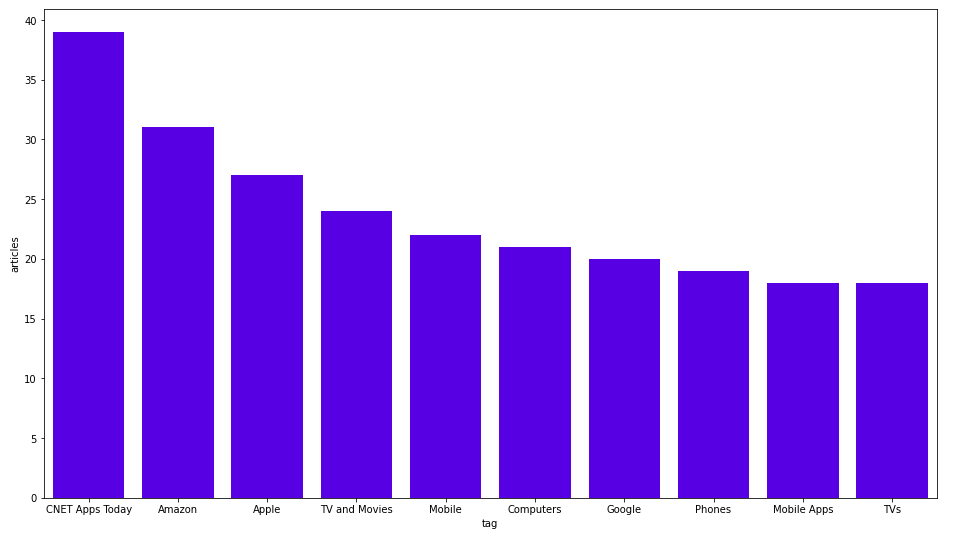
기사에서 가장 자주 사용되는 태그도 살펴볼게요.
MATCH (n:Tag)
RETURN n.name as tag, size((n)<-[:HAS_TAG]-()) as articles
ORDER BY articles DESC
LIMIT 10
결과는 다음과 같아요.
작성자 이미지
이 블로그 게시물의 모든 차트는 시본 도서관에서 만들었어요. CNET Apps Today가 가장 자주 사용되는 태그네요. 제 생각에는 그냥 일간 뉴스의 일반적인 태그일 뿐인 것 같아요. Amazon, Apple, Google과 같은 다양한 대기업을 위한 맞춤 태그가 있다는 것도 확인할 수 있어요.
명명된 엔터티 연결: Wikification
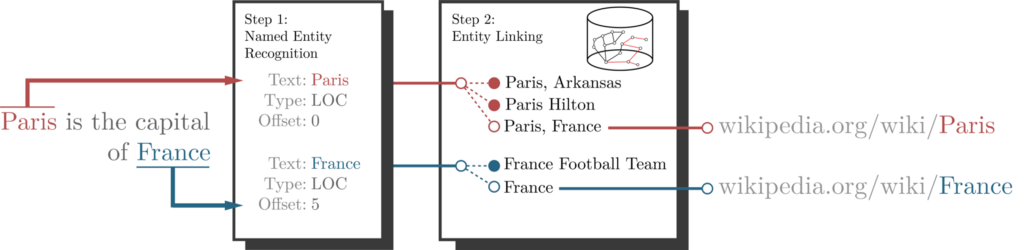
제 이전 블로그 게시물에서, Knowledge Graph를 생성하기 위한 명명된 엔터티 인식 기술을 이미 다뤘었죠. 여기서는 한 단계 더 나아가 명명된 엔터티 연결에 대해 자세히 살펴볼게요.
먼저, 명명된 엔터티 연결이란 정확히 뭘까요?
이미지 작성자:아파라비 on 위키피디아. CC BY-SA 4.0에 따라 라이선스가 부여됨
명명된 엔터티 연결은 엔터티 인식 기술의 업그레이드 버전이라고 할 수 있어요. 텍스트의 모든 개체를 인식하는 것부터 시작하는데요. 명명된 엔터티 인식 프로세스가 완료되면 해당 엔터티를 대상 Knowledge Graph에 연결하려고 시도해요. 일반적으로 대상 Knowledge Graph는 Wikipedia 또는 DBpedia이지만, 다른 Knowledge Graph도 물론 있죠.
위의 예에서 명명된 엔터티 인식 프로세스가 파리를 엔터티로 인식한 것을 확인할 수 있어요. 다음 단계는 이를 Knowledge Graph의 대상 엔터티에 연결하는 거예요. 여기서는 Wikipedia를 대상 Knowledge Graph로 사용하고 있네요. 이는 Wikification 프로세스라고도 불려요.
Wikipedia에 제목에 Paris가 포함된 많은 엔터티가 존재한다는 것을 알 수 있어서 엔터티 연결 프로세스는 약간 까다로울 수 있어요. 따라서 엔터티 연결 프로세스의 일부로 NLP 모델은 엔터티 명확성을 수행하게 돼요.
시중에는 12개의 엔터티 연결 모델이 있어요. 그 중 일부는 다음과 같아요.
저는 슬로베니아 출신이라, 어쩔 수 없이 편향된 결정을 내리게 되는데, 바로 슬로베니아 솔루션인 Wikifier[1]를 사용하는 거예요. 사실 NLP 모델을 제공하는 건 아니지만, 무료로 사용할 수 있는 API 엔드포인트가 있답니다. 사용하려면 해야 해요. 심지어 비밀번호나 이메일도 필요 없으니, 정말 다행이죠?
Wikifier는 100개 이상의 언어를 지원하고, 결과를 Fine-tuning하는 데 사용할 수 있는 몇 가지 파라미터도 제공해요. 가장 중요한 파라미터는 pageRankSqThreshold인데, 모델의 재현율이나 정확성을 최적화하는 데 사용할 수 있죠.
위의 예제를 Wikifier API를 통해 실행하면 다음과 같은 결과를 얻을 수 있어요.
Wikifier API가 세 개의 엔터티와 해당 Wikipedia URL, WikiData 항목 ID를 반환한 것을 확인할 수 있죠? WikiData 항목 ID를 Neo4j에 다시 저장하기 위한 고유 식별자로 사용할 거예요.
APOC 라이브러리에는 모든 API 엔드포인트에서 결과를 검색하는 데 사용할 수 있는 apoc.load.json 프로시저가 있어요. 더 많은 양의 데이터를 처리하는 경우에는 일괄 처리 목적으로 apoc.periodic.iterate 프로시저를 사용하는 게 좋답니다.
이 모든 것을 종합하면, 다음 Cypher 쿼리는 API 엔드포인트에서 각 섹션에 대한 주석 결과를 가져와 결과를 Neo4j에 저장해요.
CALL apoc.periodic.iterate('
MATCH (s:Section) RETURN s
','
WITH s, "?" +
"text=" + apoc.text.urlencode(s.text) + "&" +
"lang=en&" +
"pageRankSqThreshold=0.80&" +
"applyPageRankSqThreshold=true&" +
"nTopDfValuesToIgnore=200&" +
"nWordsToIgnoreFromList=200&" +
"minLinkFrequency=100&" +
"maxMentionEntropy=10&" +
"wikiDataClasses=false&" +
"wikiDataClassIds=false&" +
"userKey=" + $userKey as url
CALL apoc.load.json(url) YIELD value
UNWIND value.annotations as annotation
MERGE (e:Entity{wikiDataItemId:annotation.wikiDataItemId})
ON CREATE SET e.title = annotation.title, e.url = annotation.url
MERGE (s)-[:HAS_ENTITY]->(e)',
{batchSize:100, params: {userKey:$user_key}})
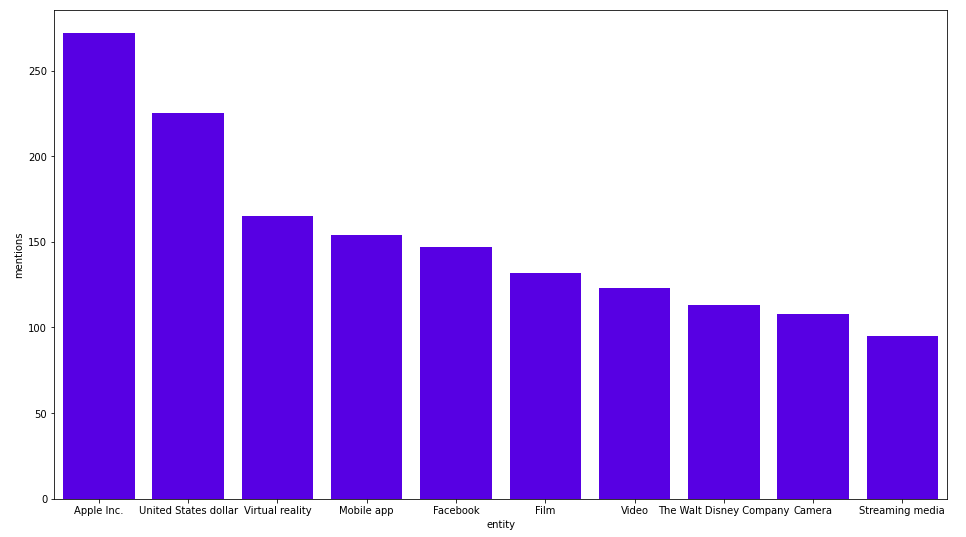
Named Entity Linking 프로세스는 몇 분 정도 걸릴 거예요. 이제 가장 자주 언급되는 항목을 확인할 수 있답니다.
MATCH (e:Entity)
RETURN e.title, size((e)<--()) as mentions
ORDER BY mentions DESC LIMIT 10;
결과는 다음과 같아요.
작성자 이미지
가장 자주 언급되는 기업은 Apple Inc.네요. 저는 모든 달러 기호나 USD 언급이 미국 달러와 연결되어 있다고 추측하고 있어요. 기사별로 가장 많이 언급되는 태그도 살펴볼까요?
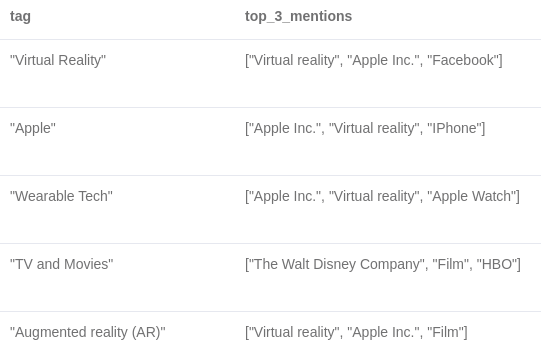
MATCH (e:Entity)<-[:HAS_ENTITY]-()<-[:HAS_SECTION]-()-[:HAS_TAG]->(tag)
WITH tag.name as tag, e.title as title, count(*) as mentions
ORDER BY mentions DESC
RETURN tag, collect(title)[..3] as top_3_mentions
LIMIT 5;
결과는 다음과 같아요.
작성자 이미지
WikiData 강화
Wikification 프로세스 사용의 보너스는 엔터티의 WikiData 항목 ID가 있다는 점이에요. 이걸 이용하면 추가 정보를 얻기 위해 WikiData API를 스크랩하는 게 정말 쉬워진답니다.
모든 비즈니스 및 개인 엔터티를 정의한다고 가정해 볼게요. WikiData API에서 엔터티 클래스를 가져오고, 해당 정보를 사용해서 엔터티를 그룹화하는 거죠. 다시 apoc.load.json 프로시저를 사용해서 API 엔드포인트에서 응답을 검색할 거예요.
MATCH (e:Entity)
// Prepare a SparQL query
WITH 'SELECT *
WHERE{
?item rdfs:label ?name .
filter (?item = wd:' + e.wikiDataItemId + ')
filter (lang(?name) = "en" ) .
OPTIONAL{
?item wdt:P31 [rdfs:label ?class] .
filter (lang(?class)="en")
}}' AS sparql, e
// make a request to Wikidata
CALL apoc.load.jsonParams(
"" +
apoc.text.urlencode(sparql),
{ Accept: "application/sparql-results+json"}, null)
YIELD value
UNWIND value['results']['bindings'] as row
FOREACH(ignoreme in case when row['class'] is not null then [1] else [] end |
MERGE (c:Class{name:row['class']['value']})
MERGE (e)-[:INSTANCE_OF]->(c));
계속해서 엔터티의 가장 빈번한 클래스를 검사해볼게요.
MATCH (c:Class)
RETURN c.name as class, size((c)<--()) as count
ORDER BY count DESC LIMIT 5;
결과는 다음과 같아요.
작성자 이미지
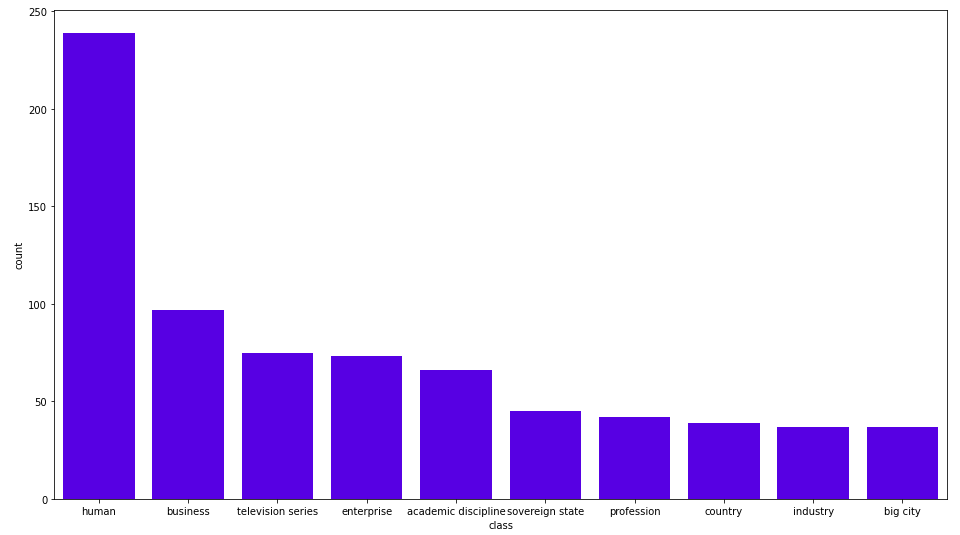
Wikification 프로세스에서는 거의 250개의 인간 엔터티와 100개의 비즈니스 엔터티가 발견되었어요. 추가적인 Cypher 쿼리를 단순화하기 위해 개인 및 비즈니스 엔터티에 보조 라벨을 할당할게요.
MATCH (e:Entity)-[:INSTANCE_OF]->(c:Class)
WHERE c.name in ["human"]
SET e:Person;
MATCH (e:Entity)-[:INSTANCE_OF]->(c:Class)
WHERE c.name in ["business", "enterprise"]
SET e:Business;
보조 라벨을 추가하면 이제 가장 자주 언급되는 사업체를 쉽게 조사할 수 있어요.
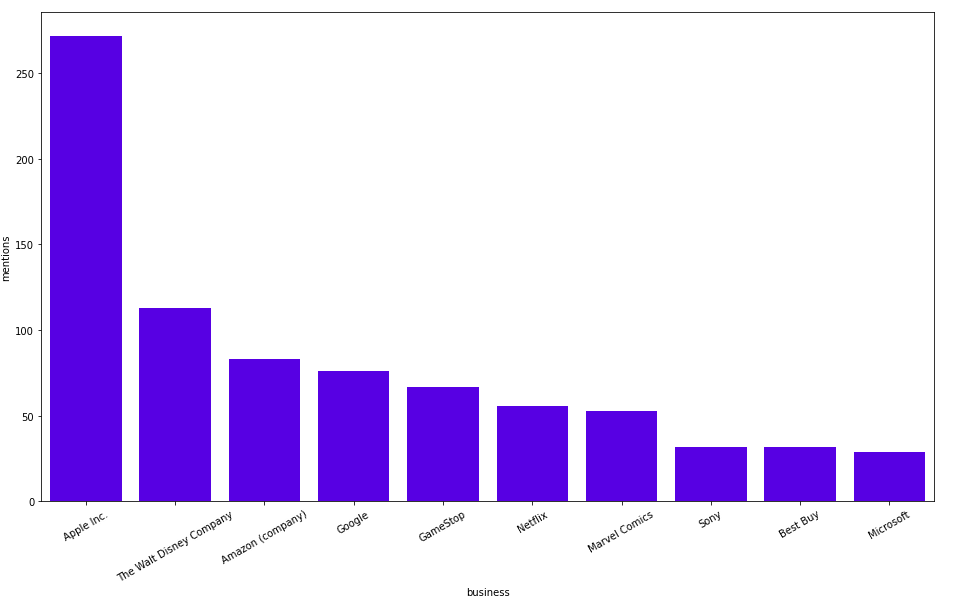
MATCH (b:Business)
RETURN b.title as business, size((b)<-[:HAS_ENTITY]-()) as mentions
ORDER BY mentions DESC
LIMIT 10
결과는 다음과 같아요.
작성자 이미지
우리는 이미 Apple과 Amazon이 많이 논의되었다는 것을 알고 있었죠. 여러분 중 일부는 GameStop에 대한 많은 언급을 볼 수 있기 때문에 이번 주가 주식 시장에서 흥미로운 한 주였다는 것을 이미 알고 있을 거예요.
가능하기 때문에 WikiData API에서 사업체의 산업도 가져와 볼게요.
MATCH (e:Business)
// Prepare a SparQL query
WITH 'SELECT *
WHERE{
?item rdfs:label ?name .
filter (?item = wd:' + e.wikiDataItemId + ')
filter (lang(?name) = "en" ) .
OPTIONAL{
?item wdt:P452 [rdfs:label ?industry] .
filter (lang(?industry)="en")
}}' AS sparql, e
// make a request to Wikidata
CALL apoc.load.jsonParams(
"" +
apoc.text.urlencode(sparql),
{ Accept: "application/sparql-results+json"}, null)
YIELD value
UNWIND value['results']['bindings'] as row
FOREACH(ignoreme in case when row['industry'] is not null then [1] else [] end |
MERGE (i:Industry{name:row['industry']['value']})
MERGE (e)-[:PART_OF_INDUSTRY]->(i));
탐색적 그래프 분석
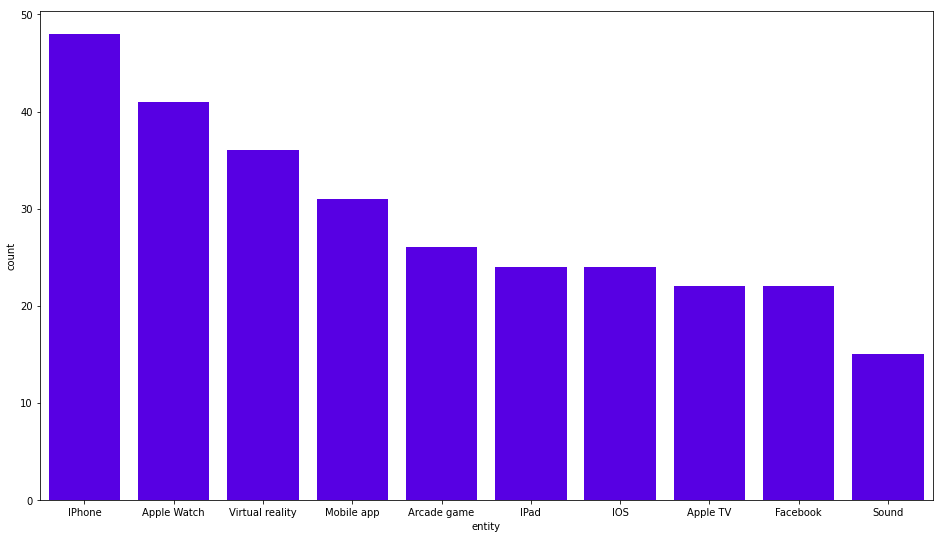
데이터 파이프라인 수집이 완료되었어요. 이제 우리는 재미를 느끼고 Knowledge Graph를 탐색할 수 있어요. 먼저 가장 자주 언급되는 법인 중 가장 많이 동시 발생하는 법인을 살펴볼게요. 제 경우에는 Apple Inc.이에요.
MATCH (b:Business)
WITH b, size((b)<-[:HAS_ENTITY]-()) as mentions
ORDER BY mentions DESC
LIMIT 1
MATCH (other_entities)<-[:HAS_ENTITY]-()-[:HAS_ENTITY]->(b)
RETURN other_entities.title as entity, count(*) as count
ORDER BY count DESC LIMIT 10;
결과는 다음과 같아요.
작성자 이미지
여기에는 멋진 것이 없네요. iPhone, Apple Watch 및 VR도 언급되는 섹션에는 Apple Inc.가 나타나요. 좀 더 흥미로운 소식을 살펴볼게요. 나는 흥미로울 만한 기사의 관련 태그를 검색하고 있었어요.
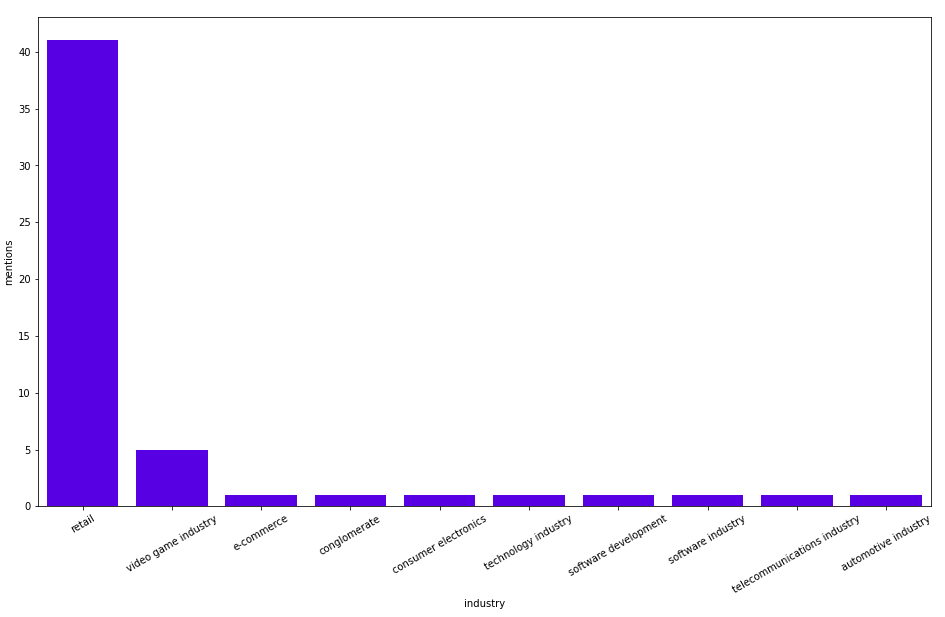
CNET에는 많은 특정 태그가 있었지만, 지금은 태그가 더 광범위하고 관련성이 높아졌어요. 주식 시장 기사 카테고리에서 가장 많이 언급된 업종을 확인해볼까요?
MATCH (t:Tag)<-[:HAS_TAG]-()-[:HAS_SECTION]->()-[:HAS_ENTITY]->(entity:Business)-[:PART_OF_INDUSTRY]->(industry)
WHERE t.name = "Stock Market"
RETURN industry.name as industry, count(*) as mentions
ORDER BY mentions DESC
LIMIT 10
결과는 다음과 같아요.
작성자 이미지
소매업이 가장 많이 언급되고, 그 다음은 비디오 게임 산업이네요. 그 외 다른 산업들은 언급 횟수가 적어요. 다음으로 주식 시장 카테고리에서 가장 많이 언급되는 기업이나 인물을 알아볼게요.
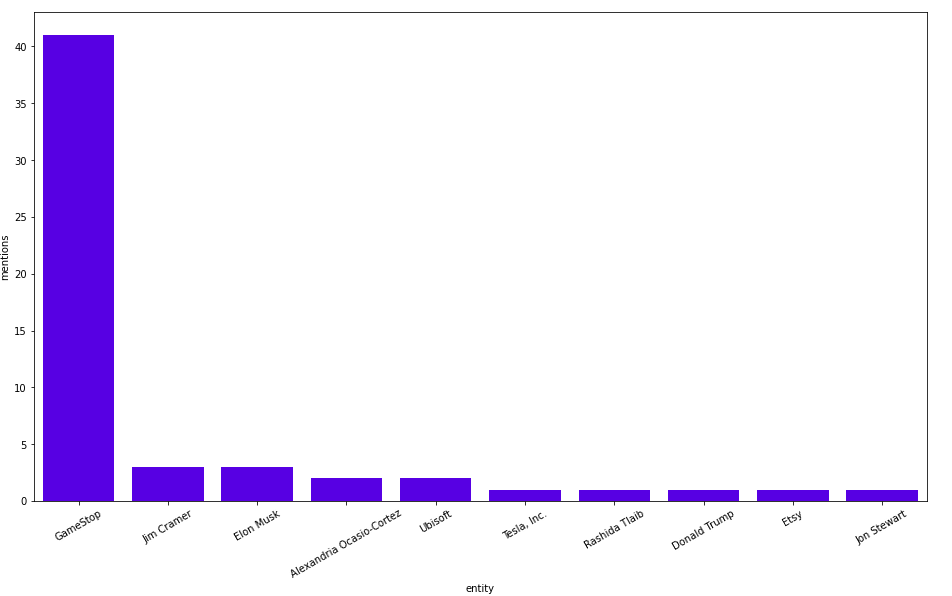
MATCH (t:Tag)<-[:HAS_TAG]-()-[:HAS_SECTION]->()-[:HAS_ENTITY]->(entity)
WHERE t.name = "Stock Market" AND (entity:Person OR entity:Business)
RETURN entity.title as entity, count(*) as mentions
ORDER BY mentions DESC
LIMIT 10
결과는 이렇습니다.
작성자 이미지
와, GameStop이 이번 주말에 40번 넘게 언급되면서 엄청난 인기를 얻었네요! Jim Cramer, Elon Musk, Alexandria Ocasio-Cortez는 훨씬 뒤쳐져 있어요. GameStop이 왜 이렇게 핫한지, 동시에 발생하는 엔터티를 살펴보면서 알아볼까요?
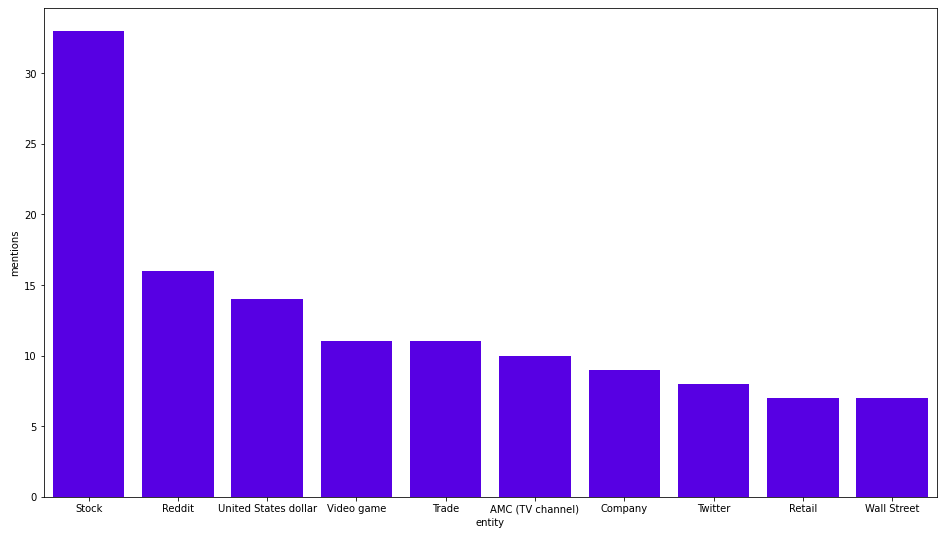
MATCH (b:Business{title:"GameStop"})<-[:HAS_ENTITY]-()-[:HAS_ENTITY]->(other_entity)
RETURN other_entity.title as co_occurent_entity, count(*) as mentions
ORDER BY mentions DESC
LIMIT 10
결과는 다음과 같습니다.
작성자 이미지
GameStop과 같은 섹션에서 가장 자주 언급되는 엔터티는 Stock, Reddit, US Dollar네요. 뉴스를 보면 결과가 꽤나 타당하다는 걸 알 수 있어요. AMC(TV 채널)는 잘못 식별된 것 같고, 아마 AMC Theatres 회사일 거라고 추측해봅니다.
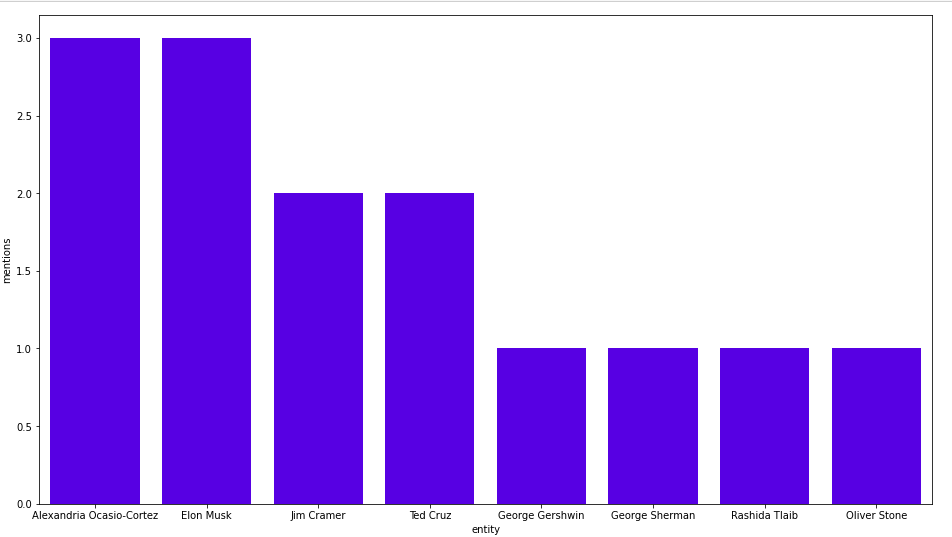
Natural Language Processing 프로세스에는 항상 약간의 실수가 있을 수 있죠. 결과를 조금 필터링해서 GameStop에 가장 많이 동시 발생하는 개인이나 사업체를 찾아볼게요.
MATCH (b:Business{title:"GameStop"})<-[:HAS_ENTITY]-()-[:HAS_ENTITY]->(other_entity:Person)
RETURN other_entity.title as co_occurent_entity, count(*) as mentions
ORDER BY mentions DESC
LIMIT 10
결과는 다음과 같아요.
작성자 이미지
Alexandria Ocasio-Cortez(AOC)와 Elon Musk는 GameStop 관련 섹션에 각각 등장하네요. AOC가 GameStop과 함께 발생하는 텍스트를 한번 살펴볼까요?
MATCH (b:Business{title:"GameStop"})<-[:HAS_ENTITY]-(section)-[:HAS_ENTITY]->(p:Person{title:"Alexandria Ocasio-Cortez"})
RETURN section.text as text
결과는 이렇습니다.
작성자 이미지
Graph Data Science
지금까지는 Cypher 쿼리 언어를 사용해서 몇 가지 집계만 수행했어요. 정보를 저장하기 위해 Knowledge Graph를 활용하고 있으니, 여기에 몇 가지 그래프 알고리즘을 실행해볼게요. Neo4j Graph Data Science 라이브러리는 현재 50개 이상의 그래프 알고리즘을 사용할 수 있는 Neo4j용 플러그인이에요. 알고리즘은 커뮤니티 감지 및 중심성부터 Node Embedding 및 그래프 Neural Network 범주까지 다양하답니다.
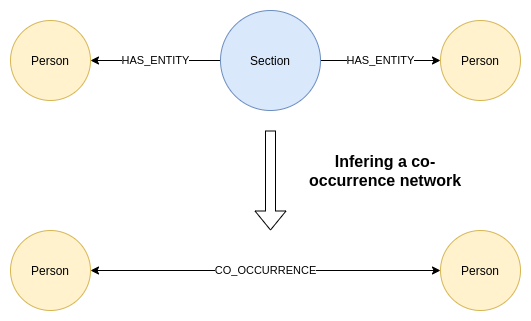
우리는 지금까지 일부 동시 발생 개체를 이미 검사했죠. 다음으로 Knowledge Graph 내에서 사람들의 동시 발생 네트워크를 추론해볼게요. 이 프로세스는 기본적으로 동일한 섹션에서 두 엔터티가 언급되는 간접적인 관계를 해당 두 엔터티 간의 직접적인 관계로 변환하는 거예요. 아래 다이어그램이 프로세스를 이해하는 데 도움이 될 거예요.
작성자 이미지
개인 동시 발생 네트워크를 추론하기 위한 Cypher 쿼리는 다음과 같아요.
MATCH (s:Person)<-[:HAS_ENTITY]-()-[:HAS_ENTITY]->(t:Person)
WHERE id(s) < id(t)
WITH s,t, count(*) as weight
MERGE (s)-[c:CO_OCCURENCE]-(t)
SET c.weight = weight
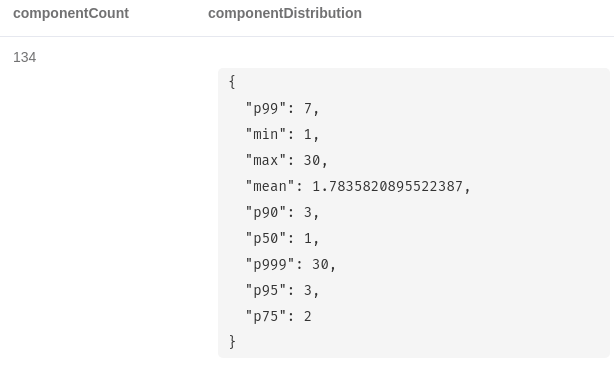
우리가 사용하는 첫 번째 그래프 알고리즘은 Weakly Connected Components 알고리즘이에요. 이건 네트워크 내에서 연결이 끊긴 구성 요소나 아일랜드를 식별하는 데 사용되죠.
알고리즘은 그래프 내에서 연결이 끊긴 구성 요소 134개를 발견했어요. p50 값은 커뮤니티 규모의 50번째 백분위수이고요. 대부분의 구성 요소는 단일 node로 구성되어 있네요.
이는 CO_OCCURENCE relationship이 없다는 의미겠죠. 가장 큰 node 섬은 30개의 구성원으로 구성되어 있어요. 우리는 그 구성원을 보조 label로 표시할 거예요.
MATCH (p:Person)
WITH p.wcc as wcc, collect(p) as members
ORDER BY size(members) DESC LIMIT 1
UNWIND members as member
SET member:LargestWCC
우리는 커뮤니티 구조를 조사하고 가장 중심적인 node를 찾으려고 노력함으로써 가장 큰 구성 요소를 추가로 분석할 거예요. 동일한 투영 그래프에서 여러 알고리즘을 실행할 계획이 있다면 명명된 그래프를 사용하면 좋아요. 동시 발생 네트워크의 relationship은 방향이 지정되지 않은 것으로 간주돼요.
어떤 사람들은 한 장의 사진이 천 마디 말보다 낫다고 말하죠. 소규모 네트워크를 다룰 때는 결과의 네트워크 시각화를 만드는 것이 정말 좋아요. 다음 시각화는 Neo4j Bloom을 사용하여 생성되었어요.
Node 색상은 커뮤니티를 나타내고 node 크기는 PageRank 점수를 나타내요. 작성자 이미지
결론
저는 Natural Language Processing과 Knowledge Graph가 완벽하게 어울리는 방식이 정말 좋더라고요. 데이터 파이프라인을 구현하고 결과를 Knowledge Graph 형식으로 저장하는 방법에 대한 몇 가지 아이디어와 지침을 제공했기를 바라요. 어떻게 생각하는지 알려주세요!
언제나 그렇듯이 코드는 다음에서 사용할 수 있어요: .
참고 자료
[1] 야네즈 브랑크, 그레고르 레반, 마르코 그로벨닉. 관련 Wikipedia 개념으로 문서에 주석 달기. 슬로베니아 데이터 마이닝 및 데이터 웨어하우스에 관한 회의 간행물(SiKDD 2017), 슬로베니아 류블랴나, 2017년 10월 9일.
명명된 엔터티 연결
news
nlp
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
마하바라타에 더욱 매료될 준비 되셨나요? 이전 탐험에서 마하바라타를 통해 매혹적인 여행을 시작했었죠. 저희는 Graph Database와 챗봇의 힘을 활용해서 이 서사시적인 인도 이야기의 중심에 있는 복잡한 관계와 인물을 풀어냈어요.
아직 읽지 않으셨다면 이 시리즈의 1부를 읽어보시는 걸 추천드려요.
Mahabharata의 웹 공개: Neo4j Graph Database를 사용한 엄청난 관계 분석(1부)
더 나은 이해를 위해 2부도 읽어보시면 좋을 것 같아요.
마하바라타 서사시를 생생하게 구현하기: Google Gemini를 사용한 Neo4j 기반 챗봇(2부)
이제 마하바라타에 생명을 불어넣는 기술적 경이로움, 즉 상황이 풍부하고 직관적인 챗봇에 대해 더 깊이 탐구해볼게요. 이걸 달성하는 데 도움이 된 GraphRAG라는 혁신적인 접근 방식에 중점을 두고 이 혁신적인 시스템의 내부 작동 방식을 분석해볼게요.
강력한 챗봇: RAG의 힘 설명
마하바라타 전문가인 친구와 대화를 나눈다고 상상해보세요. 등장인물과 사건에 대해 설명하고 그 연관성을 설명해줄 수 있겠죠. 물론 지금은 이 인도 서사시의 전문가를 찾기가 쉽지 않아요. 이것이 바로 저희가 챗봇을 통해 목표로 하는 것이에요! 하지만 LLM(Large Language Model)으로 구축된 기존 챗봇은 때때로 이 문제로 어려움을 겪을 수 있어요.
LLM은 엄청난 양의 텍스트 데이터에 대해 훈련받은 초강력 언어 학습자와 같아요. 인상적인 반응을 이끌어낼 수 있지만, 기술 세계에서 저희가 "환각(hallucination)"이라고 부르는 것을 꾸며내는 경향도 있어요. 이는 옳지 않은 세부 사항을 엮거나 마하바라타와 같은 복잡한 내러티브로 완전히 목표를 놓칠 수 있다는 의미에요.
여기서 RAG(Retrieval-Augmented Generation)라는 멋진 접근 방식이 등장해요. RAG를 LLM에 도움을 주는 방법으로 생각할 수 있어요. RAG는 검색 기반 모델을 LLM과 결합하거든요. 검색 모델은 강력한 검색 엔진처럼 작동해서 특정 질문에 대해 가장 관련성이 높은 정보를 찾기 위해 방대한 양의 정보를 검색해요. RAG는 검색된 조각을 활용해서 LLM의 응답을 알리고 이를 실제 정보에 기반을 두고 더욱 정확하게 만들죠.
RAG에 대해 더 자세히 알아보고 싶으신가요? 이걸 확인해보세요. 3분짜리 영상에서 LLM용 RAG를 설명해주고, 좀 더 기술적인 설명을 원하시면 참고하시면 좋을 것 같아요. 하지만 지금은 RAG가 Mahabharata 챗봇이 순조롭게 진행되고 창의적이고 사실적으로 정확한 응답을 제공하는 데 도움이 된다고 가정해볼게요.
GraphRAG 이해하기: 벡터를 넘어서
이제 GraphRAG 접근 방식에 대해 이야기해볼게요. 기존의 챗봇은 RAG 모델을 사용하는 경우가 많아요. 이러한 모델은 사용자 Query를 기반으로 관련 정보(예: 텍스트 구절 또는 대화 조각)를 검색하고 검색된 Vector Embedding을 조작해서 응답을 생성하는 방식으로 작동해요. 이 접근 방식은 효과적이지만 제한이 있을 수 있어요. Vector Embedding 전용 표현은 마하바라타와 같은 복잡한 서술에 내재된 풍부한 맥락과 관계를 완전히 포착하지 못할 수 있거든요.
출처: DALL-E
이것이 GraphRAG가 개입하는 곳이에요. 다음과 같은 Graph Database의 기능을 통합해서 기존 RAG 모델을 확장하는 거죠. . GraphRAG는 그래프 구조 내 데이터의 상호 연결성을 사용해서 관련 정보를 검색하고 엔터티 간의 관계를 이해해요. 이를 통해 챗봇은 더욱 미묘하고 상황에 맞는 응답을 생성해서 마하바라타의 캐릭터와 그들의 복잡한 관계를 더욱 의미 있게 생생하게 전달할 수 있어요.
Neo4j를 사용한 Knowledge Graph 및 RAG에 대해 자세히 알아보세요. 그래프아카데미.
Neo4j LLM Knowledge Graph Builder
그래서 저희는 GraphRAG가 챗봇에게 절실히 필요한 기능을 제공한다는 사실을 확인했어요. 하지만 실제로 이 모든 것을 어떻게 통합할 수 있을까요? 여기에 멋진 도구가 있어요. Neo4j LLM Knowledge Graph Builder가 등장하는 거죠.
챗봇을 위한 완벽한 Knowledge Graph를 만들 수 있는 마법의 주방이라고 생각해보세요. 이 온라인 도구를 사용하면 마하바라타에 대한 모든 종류의 정보(텍스트 구절, 인물 설명, 심지어 복잡한 가족 관계까지!)를 제공할 수 있어요! 그런 다음 Neo4j LLM Knowledge Graph Builder는 영리한 AI(기본적으로 선택된 LLM 중 하나 — OpenAI의 GPT-4o, 4 및 3.5, Diffbot 또는 Gemini 1.5 Pro)를 사용해서 이 모든 데이터를 분석하고 강력한 Knowledge Graph, 즉 서사시의 본질을 포착하는 상호 연결된 정보의 웹을 구축해요. 도구에 대한 자세한 내용은 Neo4j 연구소를 참조하세요.
이 Knowledge Graph는 RAG 기반 챗봇의 비밀 무기가 될 거예요. 사용자가 질문을 하면 챗봇은 RAG에서 검색된 스니펫을 활용하고 이 상세한 Knowledge Graph를 참조해서 캐릭터, 이벤트 및 위치 간의 관계를 이해할 수 있어요. 이를 통해 챗봇은 통찰력 있고 상황에 맞게 풍부한 응답을 제공해서 마하바라타 모험을 더욱 매력적으로 만들어줄 거예요.
LLM 그래프 빌더 도구 작동 중
저는 이 도구가 정말 마음에 들어요! 챗봇이 마하바라타 문의의 모든 질문에 답변할 수 있게 해주거든요. 예를 들어 이런 간단한 질문부터:
가토타카흐를 죽인 사람은 누구인가? (스포일러 주의 — 카르나였어요!)
더 복잡한 질문까지도요:
판다바족은 왜 12년 동안 숲에서 살아야만 했나요? (이건 사기, 추방, 잘못된 주사위 게임에 대한 이야기죠!)
Neo4j LLM Knowledge Graph 빌더는 챗봇이 이런 유형의 질문을 쉽게 탐색할 수 있도록 도와줘요. 더 간단한 Knowledge Graph에서는 관련 연결을 효율적으로 찾아낼 수 있죠. 복잡한 질문의 경우 챗봇이 관계, 동기, 역사적 맥락을 고려해서 다재다능한 설명을 만들어낼 수 있어요. 마치 서사시의 신비를 풀 준비가 된 개인 마하바라타 학자를 여러분 손끝에 둔 것과 같아요!
마하바라타와의 대화: 새롭고 향상된 경험
GraphRAG와 Neo4j LLM Knowledge Graph 빌더 도구의 마법을 살펴봤으니, 이제 주인공인 마하바라타 챗봇에 대해 이야기해 볼게요. 여러분의 마하바라타 여정을 더욱 발전시키기 위해 제 친구 브리즈라즈 싱이 이 챗봇을 위해 특별히 세련되고 사용자 친화적인 웹 앱을 디자인했답니다.
이 웹 앱은 Hugging Face Spaces에서 호스팅되는 이전 Gradio 챗봇을 훨씬 더 개선한 버전이에요 (단순히 IFrame을 가져오는 것 이상이죠). 이유는 다음과 같아요.
향상된 사용자 인터페이스 - 웹 앱은 더욱 직관적이고 시각적으로 매력적인 인터페이스를 제공해서 챗봇과 더 쉽게 상호 작용하고 마하바라타를 탐색할 수 있어요.
- 웹 앱은 GraphRAG 및 Knowledge Graph 구성 요소와 완벽하게 통합되어 원활하고 효율적인 사용자 경험을 보장해요.
- 이 앱은 더 많은 사람들이 마하바라타의 지혜를 쉽게 접할 수 있도록 설계되었어요.
다음 링크로 이동해서 나만의 대화형 마하바라타 모험을 시작해 보세요. 질문을 하고, 인물 관계를 탐구하고, 시대를 초월한 이 서사시에 대해 더 깊이 이해할 수 있을 거예요.
끊임없이 진화하는 마하바라타 여정: 미리보기
이건 저의 마하바라타 챗봇 여정의 시작일 뿐이에요. 저는 챗봇의 능력을 개선하고 확장할 수 있는 방법을 끊임없이 찾고 있답니다. 앞으로 어떤 흥미로운 가능성이 있는지 몇 가지 소개해 드릴게요.
- GraphRAG 이상의 Natural Language Generation 기술을 통합하면 챗봇이 질문에 답하고, 매혹적인 이야기를 만들고, 마하바라타의 다양한 측면을 탐색할 수 있게 될 거예요.
- 챗봇을 다국어로 만들면 더 많은 사람들이 이용할 수 있고, 서사시에 대한 전 세계적인 이해도를 높일 수 있겠죠.
고급 캐릭터 상호작용 - 마하바라타의 등장인물과 직접 대화를 나눈다고 상상해 보세요! 등장인물들의 동기를 탐구하고, 주요 사건을 그들의 관점에서 보고, 그들의 성격에 대한 더 깊은 이해를 얻을 수 있을 거예요.
제 마하바라타 챗봇의 미래는 밝다고 생각해요. 현재 Google의 Vertex AI에서 Model Garden의 code-bison 및 text-bison의 강력한 기능을 활용하고 있지만, Gemini 1.5 Pro 또는 Gemini 1.5 Flash와 같이 훨씬 더 발전된 LLM의 잠재력을 탐구할 준비를 하고 있어요. 또한 Anthropic의 Claude 또는 OpenAI의 GPT-4o와 같은 다른 LLM 모델과 함께 챗봇을 테스트해서 마하바라타 내러티브의 복잡성을 어떻게 해결하는지 알아볼 거예요. 이 실험을 통해 이 특정 애플리케이션에 대한 최적의 LLM을 식별할 수 있을 거라고 생각해요.
GitHub – sidagarwal04/mahabharata-genai: 마하바라타의 웹 공개: Neo4j를 사용한 그래프 여행 및 마하바라타 탐색을 위한 gen-ai 챗봇 구축
GenAI
GraphRAG
마하바라타
RAG
Vertex AI
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
편집자 주: 이 프레젠테이션은 Paul Starrett이 GraphConnect New York 2017년 10월에서 발표한 내용이에요.
프레젠테이션 요약
이번 블로그에서는 활발하게 사용되는 특정 데이터 과학 도구를 시너지 효과를 내도록 활용하는 방법과, Graph Database를 연구 및 정보 표현의 소스로 사용하는 방법에 대해 집중적으로 다룰 거예요. 보너스로, 오늘 제시된 탐색적 노력의 대부분은 산업 전반에 걸쳐 예측 분석에 활용될 수 있다는 점!
먼저 빅데이터와 데이터 과학의 기초부터 살펴볼까요? 빅 데이터는 정말 많은 문제를 안고 있죠. 기존 방식으로는 처리하기에 너무 방대하고 복잡하며, 변화도 너무 빨라요. 다행히 우리는 데이터에서 지식을 추출하는 데 사용할 수 있는 과학적 방법에 대한 학제간 분야인 데이터 과학에서 해답을 찾을 수 있어요.
사립 탐정은 엄청난 양의 정보를 분류해야 하는데, 어디서부터 시작해야 할지 막막할 수 있어요. 하지만 이상 탐지 (Anomaly Detection)에 의존하면 비정상적인 행동을 쉽게 알아챌 수 있고, 과거 데이터 패턴을 기반으로 사기를 예측하는 데 도움이 되는 예측 분석은 훌륭한 출발점이 될 수 있죠.
손끝에 있는 모든 정보를 구조화된 데이터, 검색 가능한 데이터베이스 개발 및 관련 그래프 시각화 생성을 통해, 여러분이 검색하고 있는지도 몰랐던 관련 데이터를 더욱 가까이에서 발견할 수 있도록 도와줄 거예요.
전체 프레젠테이션: 사기 조사를 위한 데이터 과학 도구 활용
이 블로그에서는 데이터 과학, Machine Learning 및 Neo4j를 사용하여 사기 적발을 포함하여 다양한 목적으로 사용할 수 있는 검색 가능한 데이터베이스를 개발하는 방법에 대해 자세히 알아볼 거예요.
Starrett Consulting은 실리콘 밸리에 기반을 둔 풀 서비스 조사 회사로, 정보 거버넌스, 규정 준수 및 위협 탐지에 대한 컨설팅도 제공하고 있어요.
오늘 우리는 모든 유형의 도구를 활용하는 실제 조사에 집중할 건데요, 예를 들어 , Elasticsearch, Solar, LESS 및 오픈 소스 API (주로 Python) 같은 것들이죠. 제가 강조하고 싶은 점은, 우리는 분석을 판매하는 것이 아니라 정보를 판매한다는 거예요.
저는 작년에 예측 분석 과학 석사 학위를 취득한 사립 탐정이자 변호사예요. 저는 주로 Python과 Apache 프로젝트 도구를 사용해서 작업해 왔지만, 무엇보다도 저는 조사자랍니다.
이 프레젠테이션에서 다루지 *않는* 몇 가지 내용을 살펴볼게요.
이런 방법은 아니죠. 사기를 찾아내는 것은 Graph Database를 사용해서, 보유하고 있는 클러스터 수에 대해 논의하거나 쿼리 또는 JOIN을 얼마나 빨리 수행할 수 있는지 검토하는 것과는 달라요. 이 프레젠테이션은 데이터 과학 도구를 시너지 효과적으로 사용하는 방법과 Graph Database를 연구 및 정보 표현의 소스 중 하나로 사용하는 방법에 대해 설명하고 있어요. 보너스로, 오늘 제시된 탐색적 노력의 대부분은 산업 전반에 걸쳐 예측 분석을 알리는 데 사용될 수 있다는 점이죠.
우선 정의 측면에서 같은 페이지에 있는지 확인하기 위해 빅 데이터와 데이터 과학부터 시작해서, 더 구체적으로 사기 조사로 넘어가 볼 거예요. 이는 다음 질문에 답하는 데 도움이 될 거예요. 우리가 있어야 할 곳에 집중하는 데 도움이 되도록 데이터 과학 및 전자 데이터에서 어떤 것을 사용해야 할까요?
또한 그래프가 실제로 가장 유용한 사기와 음모, 공모 및 이해 상충에 대해서도 논의할 거예요. 마지막으로 상당히 일반적으로 사용되는 구성을 통해 실제 사례를 한번 살펴볼게요.
빅데이터 및 데이터 과학
우리는 데이터 과학, Machine Learning, 예측 분석 및 인공 지능의 사용이 회사로서 진정한 경쟁력을 유지하는 데 가장 중요한 측면 중 일부라는 것을 알고 있어요. 이는 규정 준수 및 사기 분야는 물론 법적 요구 사항이 적용되는 모든 분야에서 특히 그렇겠죠.
우리는 빅데이터를 "손에 닿지 않는" 데이터, 즉 기존 방식으로 처리하기에는 너무 방대하고 복잡하거나 빠르게 움직이는 데이터로 정의해요. 현재 방법으로 해당 데이터를 처리할 수 없으면 어떻게 해야 할까요? "수학, 통계, 정보 과학 및 컴퓨터 과학 분야의 주제와 관련된 데이터에서 지식을 추출하는 과학적 방법에 관한 학제간 분야"로 정의되는 데이터 과학에서 솔루션을 찾을 수 있어요.
저는 빅데이터가 비이고, 데이터 과학이 우산이라고 말하고 싶어요. 주목해야 할 가장 중요한 점은 데이터 과학이 상황에 따라 다르며 모든 사람의 사용 사례에 적용될 수 있다는 것이에요. 이에 대해서는 잠시 후에 살펴볼게요.
제 사업은 정보예요. 그 정보가 어디에 있을지 모르기 때문에 정량적, 구조적, 비구조적, 질적 데이터 등 모든 유형의 데이터에 대해 생각해야 해요. 저는 개인적으로 만능 관리자를 더 많이 유지하고 내 사건을 진행하기 위해 해야 할 일에 따라 필요한 경우 박사 학위를 가져와요. 제가 사용하는 대부분의 데이터 과학 도구는 리드 생성을 위한 것이므로 어디에 집중해야 할지 알고 있죠. 모든 통찰력과 생성된 리드에는 다른 소스의 후속 조치와 확증이 필요해요.
이는 네 가지 데이터 유형에 대한 대략적인 정의예요.
모든 유형의 데이터가 데이터 과학의 맥락에서 유용해지려면 구조화되지 않은 데이터를 구조화된 데이터로 변환해야 하며, 정성적(또는 범주형) 특성에 수치적 측면을 적용해야 해요.
예를 들어, 문서에서 두 개의 특정 단어가 얼마나 멀리 떨어져 있는지 또는 문서의 밀도를 설명하는 숫자 값을 추가할 수 있어요.
사기 조사
사기 조사에서는 다음을 포함한 모든 정보 출처를 고려해요.
인터뷰 및 심문
소셜 미디어, 웹 데이터, 비디오 및 오디오
물리적 기록(종이 문서)
그래프 등
이러한 다양한 유형의 데이터는 사례가 증가함에 따라 반복적으로 사용되며 다양한 순열로 사용돼요.
3단계 프로세스
사기 적발은 3단계의 순차적 프로세스로 이루어져요.
고객과 대화할 때는 관련 법률, 정책, 그리고 우선순위를 먼저 알아야 해요.
그 다음엔, 요청받은 사항을 처리하기 위해 어떤 데이터가 필요한지, 그리고 데이터 과학 도구를 사용할지 결정해야 하죠. 데이터 과학 도구를 사용할 땐, 기술적인 배경이 없는 사람들도 이해할 수 있도록 최대한 간단하게 설명하는 게 중요해요.
이상 탐지 및 예측 분석
사기는 보통 이상 탐지(Anomaly Detection)와 예측 분석이라는 두 가지 방법으로 찾아낼 수 있어요.
만약 아무것도 모르는 상태라면, 이상 탐지(Anomaly Detection)를 활용하는 거죠. 뭐가 이상한지, 뭐가 안 맞는지 찾아보는 거예요. 예측 분석은 사기 사례와 정상 사례를 비교해서, 새로 들어오는 데이터가 사기 행위를 나타낼 가능성이 있는지 판단하는 데 도움을 주는 패턴을 만들어내요.
평균으로부터의 평균 거리인 표준 편차를 이용해서 이상 탐지(Anomaly Detection)에 대해 좀 더 자세히 알아볼까요? 예를 들어, 방에 사람들이 있는데 절반은 30살이고 절반은 50살이라면, 평균 나이는 40살이고 평균 거리는 10이 되겠죠.
하나의 숫자 변수가 있는 다음 예시를 한번 살펴볼게요.
이상 탐지(Anomaly Detection)를 통해 우리는 무엇이 정상에서 벗어나는지 확인하려고 해요. 표준 편차를 벗어나는 것은 무엇일까요?
파란색 수평선은 평균을 나타내고, D1 – D7은 서로 다른 점과 평균으로부터의 거리를 나타내고, 빨간색 선은 표준 편차를 나타냅니다. 평균 위의 선은 더 큰 표준 편차를 표시하며(빨간색 선이 평균에서 더 멀기 때문에) 평균의 양쪽에서 D6, D7 및 D2가 표준 편차를 약간 벗어나는 것을 볼 수 있습니다. 이러한 데이터 포인트는 자세히 살펴볼 가치가 있겠죠.
이제 두 개의 숫자 변수가 있는 영업사원 통화의 예를 살펴볼게요.
주당 판매 전화 수와 월별 총 판매량 사이에는 선형 관계가 있어요. "550만 달러를 벌려면 일주일에 몇 번이나 통화해야 할까요?"라고 질문할 수 있겠죠. 그래프의 빨간색 상자를 보면 2.5번의 통화를 해야 한다는 걸 알 수 있어요. 상관관계는 기준을 설정하고, 예측 분석(또는 회귀)은 현실 세계에서 특이한 데이터를 찾는 데 도움을 준답니다.
얼핏 보면 오른쪽 하단에서 이상값을 쉽게 확인할 수 있어요. 이 사람은 일주일에 한 통의 전화 통화로 어떻게 한 달에 1,300만 달러를 벌 수 있을까요? 어쩌면 그는 슈퍼스타일 수도 있고, 리베이트를 받고 전혀 전화를 걸지 않을 수도 있죠.
이제 분류 및 범주형 변수를 살펴볼게요.
오른쪽에는 개, 고양이 클래스가 있고, 각 레코드에는 머리카락 길이, 귀 개수, 꼬리 유무 등과 같은 다양한 변수 값이 있어요. 두 클래스 모두 꼬리와 귀가 두 개 있기 때문에 결국 쓸모가 없게 되죠. 고양이에는 눈썹이 없으므로 해당 변수만으로도 이 모델에서 예측을 하기에는 충분할 거예요.
우리의 예측 모델은 이 데이터를 기반으로 학습해요. 테이블에서 동물 유형을 제거하면 모델에 예측을 요청하여 예측 정확도(예: 모델이 동물 종류를 올바르게 예측한 정도)를 제공할 수 있어요. 이것이 바로 Machine Learning이 작동하는 방식이에요.
다음은 문서에서 단어를 그룹화하는 방법에 대한 예시인데요. 이를 통해 패턴을 적용하고 관련성 있는 단어와 관련되지 않은 단어를 결정할 수 있어요.
이는 데이터를 탐색하고 어디에 집중해야 할지 결정하는 데 도움이 되죠.
사기란 무엇일까요?
그래서, 사기(fraud)란 무엇일까요? 다음은 다양한 요소들이에요.
중요한 사실(예: 중요한 사실)을 허위로 표현한 경우
피고인이 허위 사실을 인지한 경우
피해자의 합리적인 신뢰
피해자가 입은 손실
형사 사기, 민사 사기 등이 있는데 이를 “의도적 허위 진술”이라고 해요.
이제 음모(conspiracy)의 정의를 살펴볼게요. 그래프가 특히 유용한 또 다른 영역은 다음과 같아요.
둘 이상의 사람이 하나 이상의 범죄를 저지르기로 합의한 것
대상 중 적어도 하나를 알고 있으며 도움을 주려는 의도를 가지고 있어요.
음모를 조장하기 위한 적어도 하나의 명백한 행위(일부 관할권)
그래프는 이해 상충(conflict of interest) 사례에도 도움이 되는데요, 다음과 같이 정의돼요.
서로 다른 두 당사자의 관심사나 목표가 양립할 수 없는 경우, 또는
공적인 자격으로 이루어진 행동이나 결정으로부터 개인적인 이익을 얻을 수 있는 위치에 있는 것
뉴 호라이즌: 기초 위에 구축
제가 성배라고 생각하는 것에 대해 알아볼게요. 구조화된 데이터와 구조화되지 않은 데이터를 그래프로 함께 가져오는 것이죠.
기억하세요, 이건 조사를 위한 것이므로 저는 사람들을 인터뷰하는 것뿐만 아니라 강력한 첨단 기술 도구를 활용하는 등 모든 험난한 일을 하고 있어요.
조사 및 위협 탐지 시스템에서 가장 자주 사용되는 모든 데이터를 그래프로 가져오는 기본 접근 방식은 다음과 같아요.
원본 파일에는 텍스트가 포함되어 있는데, 이 텍스트를 추출해서 MongoDB나 Cassandra 같은 텍스트 저장소에 넣어야 해요. 파일 이름이나 날짜 같은 모든 원본 메타데이터를 텍스트 파일 저장소에 보관하고, 이 데이터를 사용해서 정보 검색을 위한 검색 엔진을 만드는 거죠.
이 시스템에 대해 좀 더 자세히 알아볼까요?
첫 번째 파일(파란색)은 Microsoft Office 문서일 가능성이 높고, 두 번째 파일(주황색)은 일종의 재고 또는 재무 기록, 세 번째 파일(회색)은 이메일, 네 번째 파일(진한 파란색)은 웹사이트에요. 이 모든 것은 텍스트 저장소로 들어가고, 결국 검색 엔진으로 들어가게 되죠.
정보 검색
특정한 내용을 찾기 위해 책을 훑어본다고 생각해봐요. 첫 페이지부터 시작해서 원하는 내용을 찾을 때까지 각 페이지를 훑어보시겠어요? 아니죠! 색인(index)으로 이동해서 검색하려는 용어를 찾고, 해당 페이지로 바로 이동할 거예요. "the"나 "too"와 같은 stop words나 의미 없는 용어 같은 항목은 실제로 정보를 제공하지 않기 때문에 생략되고, 이런 것들을 저장하면 index가 엄청나게 커지거든요.
토큰화를 사용해서 검색할 때 정확한 대상을 검색할 수 있도록 단어 또는 단어 조합으로 분류해요. 대소문자 변환을 사용하면 대문자 때문에 검색에서 항목이 누락되지 않도록 모든 문자를 소문자로 만들죠. 형태소 분석과 표제어 분석을 사용하면 단어를 가장 간단한 형태로 줄일 수 있어요.
예를 들어 "실행", "실행함", "실행했다"라는 용어를 생각해 볼까요? 이 단어들은 모두 index에서 "실행"으로 변환되기 때문에, 단어의 한 버전을 검색하면 해당 단어의 모든 버전이 검색 결과에 다시 표시되는 거예요. 이러한 변환은 index에만 적용되는 게 아니라, 검색이 처리되기 전에 query에도 적용되어야 해요.
모든 변환이 완료되면 데이터는 다음과 같이 희소 행렬로 표시돼요.
문서를 추가할 때 해당 문서의 모든 단어에 대한 열도 추가해야 해요. 이렇게 되면 4,000열에 깊이가 10,000행이 되는 아주 복잡한 형태가 될 수 있죠. 대신, 단어와 그 단어가 발견된 모든 문서를 포함하는 반전된 index를 만들 수 있어요.
이것은 문서 컬렉션에서 중요한 단어를 찾는 비지도 Machine Learning 접근 방식을 나타내요. 이론은 단어가 문서에 여러 번 나타나는 경우 중요하지만, 문서 모집단 및 컬렉션 전반에 걸쳐 여러 번 나타나는 경우에는 중요하지 않다는 것이죠.
그 다음, 단어에는 연구 관련성 순위 및 키워드 호출에 사용되는 TF-IDF 점수가 부여돼요. 괄호 안에 표시된 TF-IDF 점수를 inverted index에 추가하는 거죠.
이 예시에서 "apple"이라는 단어는 문서 3에 있고 TF-IDF 점수가 4인 반면, 문서 6에서는 이 단어가 더 자주 나타나기 때문에 5점을 받았어요. 따라서 "apple"이라는 단어를 검색하면 TF-IDF 점수가 더 높은 문서가 가장 먼저 나타나겠죠?
정보 추출
지금까지는 검색 엔진을 만들고, 검색을 실행해서 일련의 결과를 가져오는 과정을 살펴봤어요.
다음 단계에서는 텍스트 파일 저장소로 이동해서, 원하는 경우 해당 측면에서 구조화된 데이터를 제거한 다음(경우에 따라 다르지만), 구조화되지 않은 자유 텍스트를 Natural Language Processing에 넣을 거예요.
Natural Language Processing을 통해 자유 형식 텍스트에서 데이터를 가져오면 위치와 같은 이름-값 쌍이 생성될 수 있어요.
기술이 들어가서 위치를 식별하고 뽑아내고 컬럼에 넣어서 구조화하는 거죠. 조사를 할 때 수십만 개의 문서가 있다면 정말 중요한 것이 무엇인지 바로 파악하고 싶을 텐데요.
작동 방식은 다음과 같아요.
이 데이터의 대부분은 구조화되어 있지만 빨간색 원으로 표시된 일부 데이터는 구조화되지 않았어요. 정보 추출이라는 프로세스를 통해 Natural Language Processing을 사용해 구조화되지 않은 데이터를 재구성해 볼 수 있어요.
이를 위해 원시 텍스트부터 시작해서 문장 분할, 토큰화, 품사 태깅 및 엔터티 감지를 수행하여 엔터티 추출로 마무리해요.
예를 들어 이런 식이에요:
문장을 가져와서 분해하고, 구문을 개별 단어로 토큰화하고, 품사 태그를 적용했어요. 이걸 수천 개의 문서에 적용하면 Machine Learning을 통해 패턴을 식별할 수 있죠.
예를 들어 명사가 연속으로 세 개 있으면 사람일 가능성이 높아요.
아래에는 다양한 데이터 유형이 나와 있는데, Python에서 사용할 수 있는 모든 유형을 대표한다고 생각해요.
우리에게는 조직, 돈 등이 있어요. 따라서 이메일에 들어가서 달러 가치를 찾아 뽑아내고 그것을 돈이라고 부르고 스프레드시트에 넣을 수 있죠. 이 모든 데이터를 꺼내서 누가, 무엇을, 언제, 어디서, 왜 중요한 정보를 자동으로 알려주는 거예요.
핵심 문구 추출을 고려할 때 실제로는 TF-IDF에 지나지 않아요. 개념, 중요한 용어, 주제, 코드 단어 및 기타 "용어"를 식별하는 데 도움이 되는 키워드 및 단어 조합을 추출하며 문서 분류 및 클러스터링에도 사용할 수 있어요.
카테고리, 개념, 감정, 메타데이터, 의미론적 역할 등을 추출할 수 있으며 이러한 도구를 사용하여 세그먼트 분석과 같은 모든 종류의 다른 멋진 작업을 수행할 수 있어요.
그리고 지금: 그래프!
이를 통해 마침내 이 모든 데이터를 Graph Database에 넣을 수 있게 되었어요. 이는 단일 주소에서 여러 등록을 식별하여 유권자 사기와 같은 것을 발견하는 데 도움이 될 수 있어요. 개인 간의 연관성을 밝혀 음모를 꾸미거나, 다양한 사람, 조직 등 간의 관련 숨겨진 연결을 찾아내 이해 상충 사례를 탐색할 수도 있죠.
그래프 기술은 또한 거래 데이터와 자주 발생하는 항목의 패턴을 찾아낼 뿐만 아니라 관계의 순서를 고려하는 시퀀스 마이닝도 찾아내요. 예로는 금융 거래, 배송 사기, 웹 서버 활동, 해외 사기 등이 있어요.
배송 사기 관련 사건에 연루되었던 적이 있어요. 이동하는 데 일정 시간이 걸리고 도중에 특정 주유소에 정차하는 일반적인 경로를 탐색하고 있었는데, 특이한 정류장 때문에 일반적인 패턴에서 눈에 띄는 사람을 만났고, 알고 보니 이 사람이 훔친 물건을 하역하고 있었죠.
결국, 당신은 이것을 왼쪽에 두고 그것을 맥락으로 변환하고 있어요. 일반적인 패턴은 무엇일까요? 사람들은 사이트를 어떻게 순서대로 살펴보나요? 이를 통해 해당 패턴을 찾고 무엇이 정상인지 아닌지를 알 수 있는 거죠.
실제 사례
제가 얻은 다음 데이터를 살펴 볼게요. 뷰로 반 다이크를 통해 시각화로 렌더링됩니다 폴리노드.
이 그래프는 Trump Organization과 고문 및 감사인의 관계를 보여주며, 실제로 눈에 띄고 이해 상충 사례를 나타낼 수 있는 일부 데이터 그룹을 지적했어요.
더 많은 실제 사례는 Citizenaudit.org에서 찾아볼 수 있어요. 여기는 IRS 990에 대해 검색 가능한 유일한 소스인데, Elastic과 Neo4j를 사용하고 있대요. 그리고 ICIJ와 파나마 논문 데이터 세트는 ICIJ가 Neo4j와 Python을 사용해서 대규모 데이터 세트에서 사기를 적발했죠.
직접 다운로드해서 구축할 수 있는 Trump BuzzFeed 그래프도 있어요. 다음 데모에서는 이 데이터 세트를 그래프로 변환하는 방법을 보여줄 거예요.
결론
우리는 본질적으로 단순한 데이터베이스를 만든 셈이에요. 그렇다고 해서 반드시 결정적인 증거나 패턴을 찾을 거라는 의미는 아니에요. 그저 모든 주요 정보를 한 곳에 저장해서 학습할 수 있는 공간일 뿐이죠.
키워드와 명명된 엔터티를 통해서 우리는 가야 할 곳을 정확히 식별할 수 있고, 이는 사례를 더 효율적으로 평가하는 데 도움이 돼요. 각 `Node`에는 개인의 나이, 소득, 주소 또는 기타 정보가 포함될 수 있겠죠.
새로 발견된 명명된 엔터티와 키워드는 검색 엔진을 통해 실행해서 사건의 범위를 더욱 확장할 수 있고, `Graph Database`의 `Query`는 사기, 음모 및 이해 상충 연구에 도움이 되는 시각화용 하위 그래프를 생성할 수 있어요. 이러한 탐색적 노력은 모두 생산 수준의 예측 분석을 알리는 데 사용될 수 있답니다.
마지막으로, Neo4j 팀이 제게 준 내용이 있어요. 조사를 수행하고 특정 패턴을 확립하면 이러한 결과를 Neo4j의 예측 모델에 사용할 수 있다는 걸 보여주죠.
바울의 연설에서 영감을 얻으셨나요? 이 백서를 통해 기업 사기 탐지 활동을 위해 `Graph Database`의 강력한 기능을 활용하는 방법을 알아보세요. 사기 탐지: 그래프 데이터베이스와의 연결 검색.
Machine Learning
Natural Language Processing
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
TechCrunch에서 좋은 소식을 전했네요! 을 보시면, 지니가 공식적으로 세상에 나왔어요. 2주 전 오늘, 멋진 VC 회사인 Sunstone Capital과 Conor Venture Partners로부터 250만 달러의 시드 단계 투자를 유치했답니다.
저희 친구들과 가족들은 아시겠지만, 꽤 오랫동안 멋진 VC 댄스를 춰왔어요. 사실 Sunstone과 Conor 팀을 처음 만난 건 1년도 더 전이었죠. 그동안 꾸준히 데이트를 해왔고, 서로에게 호감이 있었지만, 아직 데이트에서 결혼으로 발전할 준비는 안 됐었어요.
하지만 이제는 상황이 달라졌어요. 주변에서 NOSQL에 대한 관심이 높아지면서 대체 데이터베이스에 대한 관심이 지난 3~4개월 동안 *폭발적으로* 증가했고, 저희도 속도를 내고 싶고 또 그래야 한다는 게 점점 더 분명해졌죠. 저희는 저희가 어디로 향하고 있는지 완전히 믿고 있어요. 벤 스코필드는 Viget Labs에서 이렇게 설명하죠. '데이터 저장에 대한 다원적 접근 방식'이라고요. 즉, 단일 애플리케이션이 일반적으로 *여러* 데이터베이스와 작동하고 각 데이터베이스가 가장 적합한 데이터 세트를 저장하는 아키텍처라는 거죠.
모든 데이터를 관계형 데이터베이스에 쑤셔 넣는 대신, 데이터 세트에 가장 잘 맞는 데이터베이스 패러다임을 선택하는 것이 중요한 세상에서 저희는 엄청난 기회가 있다고 믿고 있어요. 특히 Graph Database 말이죠! Sunstone과 Conor가 합류하면서 이번 투자는 저희에게 이 기회를 추구할 수 있는 수단을 제공해 줄 거예요.
종자 단계 투자
VC 회사
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
LangChain4j는 Python 및 JavaScript용 LangChain과 유사한 Java 라이브러리로, AI/LLM 기능을 Java 애플리케이션에 통합하는 작업을 단순화해요. It provides a clean API for working with a variety of LLM providers and embedding stores.
또한 LangChain4j에는 감정 분석 및 정보 추출과 같은 AI 작업을 위한 도구가 포함되어 있어요. 라이브러리는 아직 활발하게 개발 중이지만 핵심 기능은 안정적이고 사용 가능하답니다.
이 기사에서는 연결된 데이터 관리를 위해 설계된 고성능 오픈 소스 그래프 데이터베이스인 Neo4j와 함께 LangChain4j 프레임워크를 설정하고 사용하여 그래프 기반 질문 답변을 수행하는 방법을 보여줄 거예요. LangChain4j를 Neo4j와 통합하면 고급 언어 모델과 그래프 데이터를 활용하여 데이터베이스 내에 저장된 relationships 및 properties를 기반으로 복잡한 queries에 응답할 수 있어요.
이 가이드는 버전 1.0.0-beta4를 기반으로 하며 향후 릴리스에서는 여기에 설명된 동작이나 인터페이스 중 일부를 변경할 수 있는 변경 사항이나 추가 기능이 도입될 수 있다는 점에 유의하는 것이 중요해요.
Neo4j 클래스
LangChain4j는 Neo4j 통합을 위해 다음 클래스를 제공해요.
Neo4jEmbeddingStore — EmbeddingStore 인터페이스를 구현하여 Neo4j 데이터베이스에 Vector Embedding을 저장하고 query할 수 있어요.
Neo4jText2CypherRetriever — 사용자 질문에서 Cypher 쿼리를 생성 및 실행하기 위한 ContentRetriever 인터페이스를 구현하여 Neo4j 데이터베이스에서 콘텐츠 검색을 향상시켜요.
EmbeddingStore 인터페이스는 embeddings(데이터의 Vector 표현)을 저장하고 검색하는 표준 방법을 정의해요. 여기에는 세 가지 주요 메서드 세트가 있어요.
add/addAll — 하나 또는 여러 개의 embeddings을 추가해요.
search(EmbeddingSearchRequest 요청) — query embedding 및 검색 매개변수를 기반으로 유사한 embeddings을 검색해요. EmbeddingSearchRequest는 query 삽입(검색 대상)을 포함하는 빌더이며 선택적으로(원하는 일치 수) 및(선택적 최소 유사성 임계값).
제거/removeAll — ID별로 embeddings을 제거해요.
ContentRetriever 인터페이스는 query를 기반으로 관련 콘텐츠를 검색하기 위한 간단한 계약을 정의해요. 여기에는 query(텍스트, 필터 등을 포함할 수 있음)를 가져와 관련 콘텐츠 항목 목록을 반환하는 검색(문자열 query)이라는 하나의 주요 메서드가 있어요.
ContentRetriever는 높은 수준의 추상화예요. 데이터베이스, Vector 저장소, 검색 엔진, 심지어 맞춤 로직과 같은 다양한 시스템의 지원을 받을 수 있죠.
다음 예에서는 langchain4j-embeddings-all-minilm-l6-v2를 사용하여 EmbeddingModel 인터페이스를 구현하는 AllMiniLmL6V2EmbeddingModel을 생성해요. 또는 langchain4j-open-ai 모듈의 OpenAiEmbeddingModel과 같이 LangChain4j에서 제공하는 수많은 모델 중 하나를 사용할 수도 있어요.
보시다시피 필수 구성은 Neo4j 인덱스 `dimension` 매개변수와 Neo4j Java 드라이버 연결 인스턴스예요. Neo4j Java 드라이버 대신 `Neo4jEmbeddingStore.builder().withBasicAuth(<url>, <username>, <password>)`를 생성하여 내부적으로 드라이버 연결 인스턴스를 생성할 수 있어요.
나중에 살펴보겠지만 빌더를 통해 다른 선택적 구성을 추가할 수 있답니다.
임베딩 저장
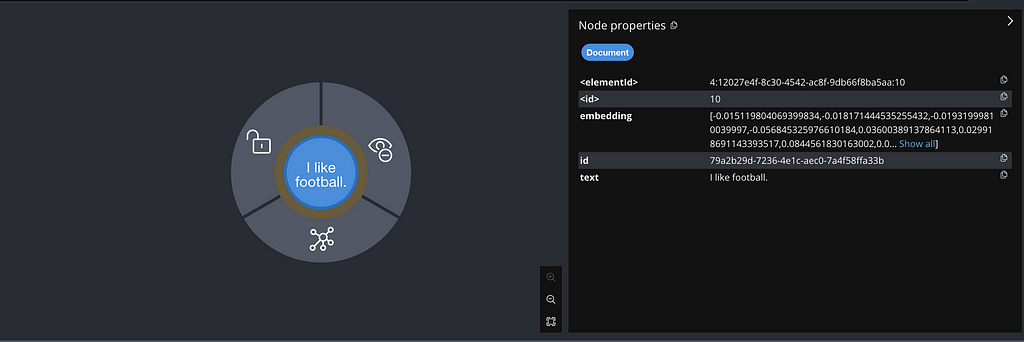
EmbeddingStore<TextSegment> minimalEmbedding = Neo4jEmbeddingStore.builder()
.withBasicAuth(neo4j.getBoltUrl(), "neo4j", neo4j.getAdminPassword())
.dimension(embeddingModel.dimension())
.build();
// or use OpenAIEmbeddingModel or other EmbeddingModel implementations
EmbeddingModel embeddingModel = new AllMiniLmL6V2QuantizedEmbeddingModel();
// add a single embedding
TextSegment segment = TextSegment.from("I like football.");
Embedding embedding = embeddingModel.embed(segment).content();
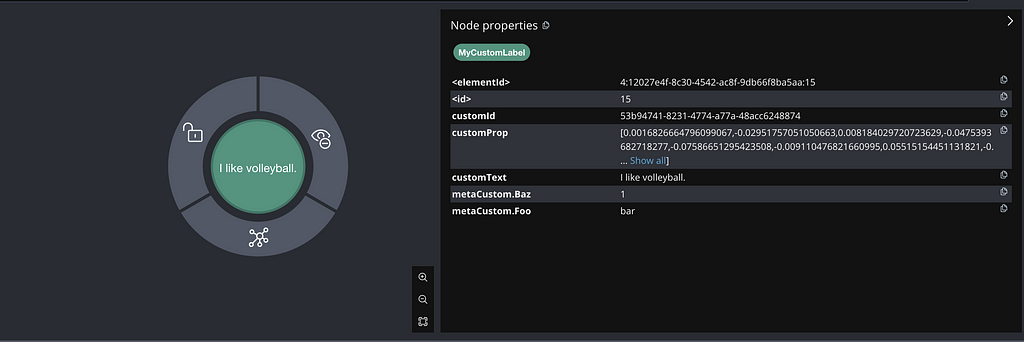
minimalEmbedding.add(embedding, segment);
위의 코드는 Label `Document`와 다음 속성을 사용하여 `Node`를 생성해요.
`Vector Embedding`으로 삽입
원본 텍스트가 포함된 텍스트
UUID가 포함된 ID
위 예시를 바탕으로, 다음 코드를 실행하여 Neo4j에서 `embeddings`를 가져올 수 있어요.
Embedding queryEmbedding = embeddingModel.embed("What is your favourite sport?").content();
final EmbeddingSearchRequest request = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(1)
.build();
List<EmbeddingMatch<TextSegment>> relevant = minimalEmbedding.search(request).matches();
EmbeddingMatch<TextSegment> embeddingMatch = relevant.get(0);
System.out.println(embeddingMatch.score());
// result like this: 0.8144289255142212
System.out.println(embeddingMatch.embedded().text());
// I like football.
와 를 기반으로 검색 쿼리 삽입이 가능하고, <indexName>과 <검색 쿼리>는 사용자 정의할 수 있어요. 첫 번째 인자에는 기본값 'vector'가 있고, 두 번째 인자에는 다음과 같은 기본값이 있죠.
RETURN properties(node) AS metadata,
node.<idProperty> AS <idProperty>,
node.<textProperty> AS <textProperty>,
node.<embeddingProperty> AS <embeddingProperty>,
score
<idProperty>, <textProperty>, 그리고 <embeddingProperty> 값도 나중에 살펴보겠지만, 커스터마이징할 수 있다는 점 기억해주세요.
위의 경우 (기본값) 전체 쿼리는 다음과 같아요.
CALL db.index.vector.queryNodes('vector', 1, 'What is your favourite sport?')
YIELD node, score
WHERE score >= 0.0
RETURN properties(node) AS metadata,
node.id AS id,
node.text AS text,
node.embedding AS embedding,
score
선택적 구성
위에서 살짝 언급했듯이, 몇 가지 선택적 구성들이 있어요. 현재(글을 쓰는 시점) 다음과 같은 것들이 있답니다.
다음 결과를 통해 TextSegment의 Metadata.from() 메서드를 확인할 수 있어요.
메타데이터 필터는 LangChain4j 클래스 필터링을 기반으로 해요. 임베딩 검색 중 검색 결과를 필터링하는 데 사용되는 조건을 나타내죠.
Filter builder 매개변수를 지정하면 db.index.Vector.queryNodes가 현재 수행할 수 있는 기능이 제공되지 않기 때문에 쿼리가 달라져요. WHERE 절이 없거든요.
쿼리:
CYPHER runtime = parallel parallelRuntimeSupport=all
MATCH (n:<label>)
WHERE n.<embeddingProperty> IS NOT NULL
AND size(n.<embeddingValue>) = toInteger(<dimension>)
AND <metadataFilter>
WITH n,
vector.similarity.cosine(n.<embeddingProperty>, <embeddingValue>) AS score
WHERE score >= <minScore>
WITH n AS node, score
ORDER BY score DESC
LIMIT <maxResults>
EmbeddingSearchRequest로 검색을 수행할 때 필터를 연결해서 결과를 제한할 수 있어요. 예를 들어 특정 메타데이터(예: 문서 유형, 사용자 ID 등)와 일치하는 임베딩만 반환하는 거죠. 일반적으로 value1 = value2, value1 > value2, value1 <= value2와 같은 표현식과 AND, OR, NOT을 사용한 복잡한 논리 조합을 작성하는 데 사용돼요.
예를 들어, 필터를 사용해볼까요?
IsEqualTo filter = new IsEqualTo("key", value);
final EmbeddingSearchRequest requestWithFilter = EmbeddingSearchRequest.builder()
.filter(filter)
.queryEmbedding(/*embeddingToSearch*/)
.build();
final EmbeddingSearchResult<TextSegment> searchWithFilter = embeddingStore.search(requestWithFilter);
그러면 위 쿼리로 실행할 <metadataFilter>가 생성돼요.
WHERE n['key'] = 'value'
사용할 수 있는 필터는 다음과 같아요.
IsEqualTo(key, value)
IsNotEqualTo(key, value)
IsGreaterThan(key, value)
IsGreaterThanOrEqualTo(key, value)
IsLessThan(key, value)
IsLessThanOrEqualTo(key, value)
IsIn(key, 값 집합)
IsNotIn(key, setOfValues)
And(하위 필터, 하위 필터)
Not(하위 필터)
Or(하위 필터, 하위 필터)
더 복잡한 필터를 만들 수도 있어요.
Or filter = new Or(
new And(new IsEqualTo("key1", "value1"), new IsGreaterThan("key2", "value2")),
new Not(new And(new IsIn("key3", valueKey3), new IsLessThan("key4", "value4"))));
// requestWithFilter and search ...
그러면 <metadataFilter>가 생성되죠.
WHERE (
(n['key1'] = 'value1' AND n['key2'] > 'value2')
OR NOT ( (any(x IN ['1', '2'] WHERE x IN n['key3']) AND n['key4'] < 'value4') )
)
하이브리드 검색
벡터 유사성 검색과 전체 텍스트 검색을 결합한 하이브리드 검색을 구현하면 결과를 개선할 수 있어요.
하이브리드 접근 방식은 두 데이터 유형(벡터 및 텍스트)의 장점을 활용해서 포괄적인 쿼리 응답을 보장하는 거죠.
내부적으로 autoCreateFullText builder 매개변수(기본값: false)가 true로 설정된 경우 다음이 생성돼요.
CREATE FULLTEXT INDEX <fullTextIndexName> IF NOT EXISTS FOR (n:<label>) ON EACH [n.<idProperty>]
search(EmbeddingSearchRequest 요청) 메소드를 실행하면 다음 쿼리가 실행돼요.
CALL db.index.vector.queryNodes($indexName, $maxResults, $embeddingValue)
YIELD node, score
WHERE score >= $minScore
// <retrievalQuery>
UNION
CALL db.index.fulltext.queryNodes($fullTextIndexName, $fullTextQuery, {limit: $maxResults})
YIELD node, score
WHERE score >= $minScore
// fullTextRetrievalQuery
전체 텍스트 쿼리 “UNION <fullTextSearch>” 부분을 추가하려면 빌더 메소드가 필요해요.
최소 설정:
Neo4jEmbeddingStore embeddingStore = Neo4jEmbeddingStore.builder()
.withBasicAuth(...)
.dimension(384)
.fullTextIndexName("movie_text")
.fullTextQuery("Matrix")
.build()
// ... add embeddings, e.g. with embeddingStore.addAll(embeddings);
final EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.minScore(0.5)
.maxResults(1)
.build();
// get embeddings
List<EmbeddingMatch<TextSegment>> results =
embeddingStore.search(embeddingSearchRequest).matches();
실행된 Neo4j `Query`:
// CALL db.index.fulltext.queryNodes part
UNION
CALL db.index.fulltext.queryNodes('movie_text', 'Matrix', {limit: 1})
YIELD node, score
WHERE score >= 0.5
RETURN properties(node) AS metadata, node.id AS id, node.text AS text, node.embedding AS embedding, score
필요한 경우 `fullTextRetrievalQuery`와 `fullTextIndexName`을 사용자 정의할 수도 있어요.
Neo4jEmbeddingStore embeddingStore = Neo4jEmbeddingStore.builder()
.withBasicAuth(...)
.dimension(...)
.fullTextIndexName("elizabeth_text")
.fullTextQuery("elizabeth*")
.fullTextRetrievalQuery("RETURN node.test AS metadata, score, datetime() as datetime")
그러면 Neo4j `Query`가 생성되죠.
// CALL db.index.vector.queryNodes part
UNION
CALL db.index.fulltext.queryNodes('elizabeth_text', 'elizabeth*', {limit: $maxResults})
YIELD node, score
WHERE score >= $minScore
RETURN node.test AS metadata, score, datetime() as datetime
Spring Boot 예시
Spring Boot 스타터 예제를 생성하려면 다음 `dependency`들을 추가하면 돼요.
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-neo4j-spring-boot-starter</artifactId>
<version>${langchain.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>${langchain.version}</version>
</dependency>
<!-- or other embedding models, like langchain4j-open-ai -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-embeddings-all-minilm-l6-v2</artifactId>
<version>${langchain.version}</version>
</dependency>
Neo4j 스타터는 현재 다음을 제공합니다.application.properties:
# the builder.dimension(dimension) method langchain4j.community.neo4j.dimension=<dimension> # the builder.withBasicAuth(uri, username, password) method langchain4j.community.neo4j.auth.uri=<boltURI> langchain4j.community.neo4j.auth.user=<username> langchain4j.community.neo4j.auth.password=<password> # the builder.label(label) method langchain4j.community.neo4j.label=<label> # the builder.indexName(indexName) method langchain4j.community.neo4j.indexName=<indexName> # the builder.metadataPrefix(metadataPrefix) method langchain4j.community.neo4j.metadataPrefix=<metadataPrefix> # the builder.embeddingProperty(embeddingProperty) method langchain4j.community.neo4j.embeddingProperty=<embeddingProperty> # the builder.idProperty(idProperty) method langchain4j.community.neo4j.idProperty=<idProperty> # the builder.textProperty(textProperty) method langchain4j.community.neo4j.textProperty=<textProperty> # the builder.databaseName(databaseName) method langchain4j.community.neo4j.databaseName=<databaseName> # the builder.retrievalQuery(retrievalQuery) method langchain4j.community.neo4j.retrievalQuery=<retrievalQuery> # the builder.awaitIndexTimeout(awaitIndexTimeout) method langchain4j.community.neo4j.awaitIndexTimeout=<awaitIndexTimeout>
자, 여러분이 Bolt URI를 가진 Neo4j 인스턴스를 가지고 있다고 가정해 볼게요. 예를 들어 bolt://localhost:7687이고, 사용자 이름이 'neo4j', 비밀번호가 'pass1234'라면, 다음과 같은 속성들을 설정할 수 있어요.
이제 아래와 같이 Spring Boot 프로젝트를 만들어 봅시다. 여기에는 SpringBootApplication 어노테이션이 붙은 메인 클래스와 두 개의 엔드포인트가 있는 API REST 컨트롤러가 있어요. /add는 임베딩을 저장하고, /search는 가장 유사한 5개의 항목을 가져오는 역할을 해요.
@SpringBootApplication
public class SpringBootExample {
public static void main(String[] args) {
SpringApplication.run(SpringBootExample.class, args);
}
@Bean
public AllMiniLmL6V2EmbeddingModel embeddingModel() {
return new AllMiniLmL6V2EmbeddingModel();
}
}
@RestController
@RequestMapping("/api/embeddings")
public class EmbeddingController {
private final EmbeddingStore<TextSegment> store;
private final EmbeddingModel model;
public EmbeddingController(EmbeddingStore<TextSegment> store, EmbeddingModel model) {
this.store = store;
this.model = model;
}
// add embeddings
@PostMapping("/add")
public String add(@RequestBody String text) {
TextSegment segment = TextSegment.from(text);
Embedding embedding = model.embed(text).content();
return store.add(embedding, segment);
}
// search embeddings
@PostMapping("/search")
public List<String> search(@RequestBody String query) {
Embedding queryEmbedding = model.embed(query).content();
EmbeddingSearchRequest request = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(5)
.build();
return store.search(request).matches()
.stream()
.map(i -> i.embedded().text()).toList();
}
}
위 코드를 사용하면 다음과 같이 REST API를 통합할 수 있답니다.
# to create a new embedding
# and store it with a label "SpringBoot"
curl -X POST localhost:8083/api/embeddings/add -H "Content-Type: text/plain" -d "embeddingTest"
# to search the first 5 embeddings
curl -X POST localhost:8083/api/embeddings/search -H "Content-Type: text/plain" -d "querySearchTest"
이 컴포넌트는 자연어 질문을 Cypher 쿼리로 동적으로 변환해서 Neo4j에 저장된 데이터에 대한 강력한 상황 인식 액세스를 제공해요. 사용자 의도를 그래프 기반 검색과 연결함으로써 검색된 콘텐츠의 정확성과 관련성을 크게 향상시켜 Neo4j를 단순한 데이터베이스가 아닌 지능형 지식 엔진으로 만들어주죠.
Neo4jGraph 클래스 Neo4j 데이터베이스와의 향상된 상호 작용을 위해 설계된 클래스인 Neo4jGraph를 활용하는데, 읽기/쓰기 작업 및 스키마 관리를 포함하고 있어요. 이걸 사용해서 읽기/쓰기 작업을 생성할 수 있죠.
Driver driver = /* org.neo4j.driver.Driver instance */
Neo4jGraph neo4jGraph = Neo4jGraph.builder()
.driver(driver)
.build();
// create simple dataset
driver.session()
.run("CREATE (book:Book {title: 'Dune'})<-[:WROTE {when: date('1999')}]-(author:Person {name: 'Frank Herbert'})")
Neo4jText2CypherRetriever retriever = Neo4jText2CypherRetriever.builder()
.graph(neo4jGraph)
.chatLanguageModel(chatLanguageModel)
.build();
// retrieve the result
Query query = new Query("Who is the author of the book 'Dune'?");
List<Content> contents = retriever.retrieve(query);
System.out.println(contents.get(0).textSegment().text());
// output: "Frank Herbert"
다음 프롬프트 문자열을 사용하여 채팅 요청을 실행해 보세요.
Task:Generate Cypher statement to query a graph database.
Instructions
Use only the provided relationship types and properties in the schema.
Do not use any other relationship types or properties that are not provided.
Schema:
{{schema}}
{{examples}}
Note: Do not include any explanations or apologies in your responses.
Do not respond to any questions that might ask anything else than for you to construct a Cypher statement.
Do not include any text except the generated Cypher statement.
The question is: {{question}}
여기서 {{question}}은 '듄'이라는 책의 저자는 누구인가요?이고, 위의 코드에서 {{examples}}는 비어 있으며(기본적으로){{schema}}는 Neo4j Graph에 의해 처리됩니다. apoc.meta.data는 현재 Neo4j 스키마를 검색하고 문자열화하는 procedure에요.
// it samples 3000 nodes for each label
Neo4jGraph neo4jGraph = Neo4jGraph.builder()
.driver(driver)
.sample(3000L)
.build();
위 데이터세트의 스키마 문자열은 다음과 같아요.
Node properties are the following:
:Book {title: STRING}
:Person {name: STRING}
Relationship properties are the following:
:WROTE {when: DATE}
The relationships are the following:
(:Person)-[:WROTE]->(:Book)
또한 <examples> 섹션에 몇 가지 예시를 추가해서 결과를 더 풍부하게 만들고 개선할 수도 있죠. 예를 들어:
Neo4jGraph neo4jGraph = /* Neo4jGraph instance */
List<String> examples = List.of(
"""
# Which streamer has the most followers?
MATCH (s:Stream)
RETURN s.name AS streamer
ORDER BY s.followers DESC LIMIT 1
""",
"""
# How many streamers are from Norway?
MATCH (s:Stream)-[:HAS_LANGUAGE]->(:Language {{name: 'Norwegian'}})
RETURN count(s) AS streamers
""");
Neo4jText2CypherRetriever neo4jContentRetriever = Neo4jText2CypherRetriever.builder()
.graph(neo4jGraph)
.chatLanguageModel(openAiChatModel)
// add the above examples
.examples(examples)
.build();
// retrieve the optimized results
final String textQuery = "Which streamer from Italy has the most followers?";
Query query = new Query(textQuery);
List<Content> contents = neo4jContentRetriever.retrieve(query);
System.out.println(contents.get(0).textSegment().text());
// output: "The most followed italian streamer"
앞으로 더 많은 내용이 추가될 예정이에요!
LangChain4j와 Neo4j 핵심 기능은 AI/LLM 기능을 Java 애플리케이션에 통합하기 위한 비교적 새로운 도구에요. 라이브러리는 아직 활발하게 개발 중이지만 핵심 기능은 이미 사용할 수 있죠.
Neo4j 통합 역시 많은 개선과 새로운 기능을 통해 발전하고 있어요. 통합이 빠르게 진행되고 있는데요, 오늘 제공되는 기능은 시작에 불과하다는 점! 곧 포함될 몇 가지 기능은 다음과 같아요.
LLMGraphTransformer— 그래프에서 하나 이상의 문서를 변환하는 패키지예요. 데이터베이스에 구애받지 않으며, 텍스트를 다른 Graph Database에서도 사용할 수 있는 Node 및 Edge 세트로 변환하죠.
— LLMGraphTransformer를 사용하여 Node 및 Edge를 Neo4j 엔터티로 변환합니다.
GraphRAG— Knowledge Graph를 사용하여 Retrieval-Augmented Generation (RAG) 구현을 가능하게 하는 유틸리티 세트예요. 예를 들어, 다음을 구현합니다. 부모-자식 리트리버는 문서를 (더 큰) 청크(상위 청크)로 분할하고 이러한 청크를 더 작은 청크(하위 청크)로 분할하여 임베드 가능하고 임시 검색 쿼리를 통해 사용할 수 있게 해줘요.
— ChatMemory 구현은 메시지 및 세션 Node, LAST_MESSAGE 및 NEXT_MESSAGE Relationship을 통해 Neo4j 데이터베이스에 대화를 저장해요.
향후 업데이트는 더 넓은 LangChain 생태계와 더욱 긴밀하게 연계될 뿐만 아니라 완전히 새로운 기능을 도입할 거예요. LLMGraphTransformer와 같은 그래프 인식 변환기, 고급 GraphRAG 패턴 및 그래프 구조 데이터용으로 설계된 영구 채팅 메모리를 생각해 보세요. AI와 Knowledge Graph가 성장함에 따라 스마트 검색 및 추론을 위한 도구도 향상될 거랍니다.
또한 임베딩 및 검색기에 대한 향상된 재시도 처리와 같은 기존 구성 요소의 사소한 개선 및 구성도 포함될 예정이에요.
— ChatModels에서 생성된 쿼리가 유효하지 않은 것으로 확인된 경우 실행을 다시 시도해요.
사이퍼-DSL— Targeted Cypher 쿼리를 생성하는 유형이 안전한 방법을 목표로 하는 Java Builder
Resources
LangChain4j 저장소의 구현: 임베딩 스토어, 콘텐츠 리트리버, 스프링 부트 스타터
더 많은 예시는 langchain4j-예제 저장소에 있어요.
LangChain4j 선적 서류 비치
Neo4j Labs 문서
LangChain
LangChain4j
Text2Cypher
Vector Search
지식 그래프를 사용하여 대규모 언어 모델의 힘 활용
여러분, Large Language Model(LLM)이 얼마나 강력한지 알고 계시죠? 하지만 LLM을 Knowledge Graph와 결합하면 더욱 놀라운 일이 벌어진다는 사실! 한번 살펴볼까요?
최근 몇 년 동안 LLM은 텍스트를 이해하고 생성하는 능력 덕분에 엄청난 인기를 얻었어요. 하지만 LLM은 방대한 양의 텍스트 데이터로 학습하기 때문에 때로는 부정확하거나 일관성이 없는 정보를 제공하기도 해요. 바로 이 지점에서 Knowledge Graph가 구세주로 등장하는 거죠.
Knowledge Graph는 엔터티와 그 관계를 구조화된 방식으로 나타내는 것이에요. Knowledge Graph를 LLM과 통합함으로써 LLM의 정확성, 신뢰성 및 추론 능력을 향상시킬 수 있어요. 정말 흥미롭죠?
이 블로그 게시물에서는 Knowledge Graph를 사용하여 LLM의 잠재력을 최대한 활용하는 방법을 알아볼 거예요. 그럼 시작해 볼까요?
Knowledge Graph란 무엇인가요?
Knowledge Graph는 엔터티(예: 사람, 장소, 사물, 개념)와 그 관계를 그래프 구조로 나타내는 전문화된 데이터베이스의 한 형태에요. 각 엔터티는 그래프의 node로 표현되고, 엔터티 간의 관계는 relationship으로 표현돼요. Knowledge Graph는 일반적으로 Property Graph로 표현되며, 여기서 node와 relationship 모두 property(키-값 쌍)를 가질 수 있어요.
Knowledge Graph는 다양한 소스에서 정보를 저장하고 추론할 수 있는 유연하고 효율적인 방법을 제공해요. 덕분에 데이터 통합, Semantic Search, 추천 시스템 등 다양한 애플리케이션에 이상적이죠.
Neo4j와 같은 Graph Database는 Knowledge Graph를 저장하고 관리하는 데 최적화되어 있어요. Neo4j는 node와 relationship을 사용하여 데이터를 저장하는 NoSQL Graph Database에요. 또한 Cypher라는 강력한 query 언어를 제공하여 Knowledge Graph에서 데이터를 효율적으로 query하고 조작할 수 있어요.
LLM이란 무엇인가요?
LLM은 방대한 양의 텍스트 데이터로 학습하여 인간과 유사한 텍스트를 생성할 수 있는 Deep Learning 모델의 한 유형이에요. LLM은 텍스트 번역, 언어 번역, 텍스트 요약 등 다양한 Natural Language Processing(NLP) 작업에 사용할 수 있어요.
하지만 LLM은 완벽하지 않아요. LLM은 방대한 양의 텍스트 데이터로 학습하기 때문에 때로는 부정확하거나 일관성이 없는 정보를 제공할 수 있어요. 또한 LLM은 학습 데이터에 없는 새로운 정보를 추론하는 데 어려움을 겪을 수 있어요.
Knowledge Graph로 LLM을 향상시키는 방법
Knowledge Graph를 LLM과 통합하면 LLM의 정확성, 신뢰성 및 추론 능력을 향상시킬 수 있어요. Knowledge Graph를 사용하여 LLM을 향상시키는 방법은 다음과 같아요.
검색 증강 생성(RAG): RAG는 LLM이 응답을 생성하기 전에 외부 Knowledge Graph에서 관련 정보를 검색하는 기술이에요. Knowledge Graph에서 관련 정보를 검색함으로써 LLM은 보다 정확하고 신뢰할 수 있는 응답을 생성할 수 있어요.
프롬프트 엔지니어링: Knowledge Graph를 사용하여 LLM에 대한 프롬프트를 개선할 수 있어요. Knowledge Graph에서 관련 엔터티와 관계를 포함함으로써 LLM이 프롬프트를 이해하고 정확하고 관련성 높은 응답을 생성하도록 도울 수 있어요.
Fine-tuning: Knowledge Graph 데이터를 사용하여 특정 작업에 대해 LLM을 Fine-tuning할 수 있어요. Knowledge Graph 데이터로 LLM을 Fine-tuning함으로써 특정 작업에 대한 정확성과 성능을 향상시킬 수 있어요.
지식 주입: Knowledge Graph를 사용하여 LLM에 새로운 지식을 주입할 수 있어요. Knowledge Graph에서 새로운 엔터티와 관계를 포함함으로써 LLM이 새로운 정보를 학습하고 추론 능력을 향상시키도록 도울 수 있어요.
Knowledge Graph와 LLM 통합의 이점
Knowledge Graph와 LLM을 통합하면 다음과 같은 여러 가지 이점이 있어요.
향상된 정확성: Knowledge Graph는 LLM에 정확하고 구조화된 정보를 제공하여 LLM의 정확성을 향상시키는 데 도움이 될 수 있어요.
향상된 신뢰성: Knowledge Graph는 LLM에 신뢰할 수 있는 정보를 제공하여 LLM의 신뢰성을 향상시키는 데 도움이 될 수 있어요.
향상된 추론 능력: Knowledge Graph는 LLM이 새로운 정보를 추론하는 데 도움이 될 수 있어요. Knowledge Graph는 엔터티와 그 관계에 대한 구조화된 표현을 제공함으로써 LLM이 학습 데이터에 없는 새로운 정보를 추론하는 데 도움이 될 수 있어요.
향상된 설명 가능성: Knowledge Graph는 LLM의 의사 결정을 설명하는 데 도움이 될 수 있어요. Knowledge Graph는 LLM이 응답을 생성하는 데 사용한 엔터티와 관계에 대한 명확하고 간결한 표현을 제공함으로써 LLM의 의사 결정을 설명하는 데 도움이 될 수 있어요.
Knowledge Graph와 LLM 통합의 사용 사례
Knowledge Graph와 LLM 통합은 다음과 같은 다양한 사용 사례에 사용할 수 있어요.
챗봇: Knowledge Graph를 사용하여 챗봇의 정확성과 관련성을 향상시킬 수 있어요. Knowledge Graph에서 관련 정보를 검색함으로써 챗봇은 사용자에게 보다 정확하고 관련성 높은 응답을 제공할 수 있어요.
Semantic Search: Knowledge Graph를 사용하여 Semantic Search 결과의 정확성과 관련성을 향상시킬 수 있어요. Knowledge Graph에서 관련 엔터티와 관계를 검색함으로써 Semantic Search 엔진은 사용자에게 보다 정확하고 관련성 높은 결과를 제공할 수 있어요.
추천 시스템: Knowledge Graph를 사용하여 추천 시스템의 정확성과 관련성을 향상시킬 수 있어요. Knowledge Graph에서 관련 엔터티와 관계를 검색함으로써 추천 시스템은 사용자에게 보다 정확하고 관련성 높은 추천을 제공할 수 있어요.
사기 탐지: Knowledge Graph를 사용하여 사기 탐지 시스템의 정확성과 효율성을 향상시킬 수 있어요. Knowledge Graph에서 사기 활동과 관련된 엔터티와 관계를 식별함으로써 사기 탐지 시스템은 사기 활동을 보다 정확하고 효율적으로 탐지할 수 있어요.
결론
Knowledge Graph는 LLM의 정확성, 신뢰성 및 추론 능력을 향상시키는 데 사용할 수 있는 강력한 도구에요. Knowledge Graph를 LLM과 통합함으로써 LLM의 잠재력을 최대한 활용하고 다양한 사용 사례에 대한 새로운 가능성을 열 수 있어요.
이 블로그 게시물이 Knowledge Graph를 사용하여 LLM의 잠재력을 최대한 활용하는 방법에 대한 귀중한 통찰력을 제공했기를 바랍니다. 읽어주셔서 감사해요!
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.