
Named Entity Linking과 Wikipedia 데이터 강화를 결합하여 인터넷 뉴스를 분석하는 방법이에요
인터넷에는 정말 많은 정보가 매일 쏟아져 나오죠. 뉴스나 다른 콘텐츠 웹사이트를 잘 이해하는 건 비즈니스 성공에 점점 더 중요해지고 있어요. 기회를 잡거나, 새로운 리드를 만들거나, 경제 지표를 파악하는 데 도움이 될 수 있거든요.
이번 블로그에서는요, Natural Language Processing(NLP)과 Knowledge Graph 기술을 합쳐서 뉴스 모니터링 데이터 파이프라인을 만드는 방법을 보여드리려고 해요.
데이터 파이프라인은 크게 세 부분으로 나눌 수 있어요. 첫 번째는 인터넷 뉴스 제공업체의 기사를 스크랩하는 부분이고요. 다음으로는 NLP 파이프라인을 거쳐 기사를 분석하고, 그 결과를 Knowledge Graph 형태로 저장해요. 마지막으로, 위키데이터 API를 이용해서 지식을 더 풍부하게 만들 거예요. Knowledge Graph를 사용해서 데이터 파이프라인 정보를 저장하면 어떤 장점이 있는지 보여드리기 위해 간단한 네트워크 분석을 해보고, 유용한 정보를 찾아볼게요.
목차
- 인터넷 뉴스 스크래핑
- Wikiifier를 사용한 Entity Linking
- Wikipedia 데이터 강화
그래프 모델
Knowledge Graph 저장을 위해 Neo4j를 사용할 거예요. 이 블로그를 따라 하시려면 APOC와 Graph Data Science 라이브러리를 모두 설치해야 해요. 모든 코드는 에서 확인하실 수 있습니다.
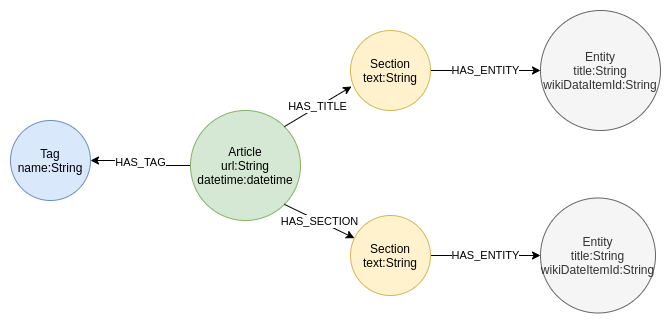
그래프 데이터 모델은 기사와 그 태그로 구성되어 있어요. 각 기사에는 여러 텍스트 섹션이 있고요. NLP 파이프라인으로 섹션 텍스트를 분석하면 언급된 항목을 추출해서 다시 그래프에 저장하는 방식이에요.
먼저 고유 제약 조건(Unique Constraint)을 정의해서 그래프를 만들어볼게요.
고유성 제약 조건은 데이터 무결성을 보장하고 Cypher 쿼리 성능을 최적화하는 데 사용돼요.
CREATE CONSTRAINT IF NOT EXISTS ON (a:Article) ASSERT a.url IS UNIQUE;
CREATE CONSTRAINT IF NOT EXISTS ON (e:Entity) ASSERT e.wikiDataItemId is UNIQUE;
CREATE CONSTRAINT IF NOT EXISTS ON (t:Tag) ASSERT t.name is UNIQUE;인터넷 뉴스 스크래핑
다음으로는 CNET 뉴스 포털을 스크래핑해볼게요. CNET 포털을 선택한 이유는 HTML 구조가 가장 일관적이어서 스크래핑 자체보다는 데이터 파이프라인 개념을 더 쉽게 보여줄 수 있기 때문이에요. HTML 스크래핑에는 `apoc.load.html` 프로시저를 사용할 건데요, 이 프로시저는 jsoup을 사용해요. 더 자세한 내용은 에서 확인하실 수 있습니다.
먼저 인기 있는 주제들을 반복하면서 각 주제에 대한 최신 기사 12개의 링크를 Neo4j에 저장할 거예요.
CALL apoc.load.html("",
{topics:"div.tag-listing > ul > li > a"}) YIELD value
UNWIND value.topics as topic
WITH "" + topic.attributes.href as link
CALL apoc.load.html(link, {article:"div.row.asset > div > a"}) YIELD value
UNWIND value.article as article
WITH distinct "" + article.attributes.href as article_link
MERGE (a:Article{url:article_link});이제 기사 링크가 있으니, 기사 내용과 태그, 게시 날짜를 스크랩할 수 있겠죠? 앞서 정의한 그래프 스키마에 맞춰서 결과를 저장할 거예요.
MATCH (a:Article)
CALL apoc.load.html(a.url,
{date:"time", title:"h1.speakableText", text:"div.article-main-body > p", tags: "div.tagList > a"}) YIELD value
SET a.datetime = datetime(value.date[0].attributes.datetime)
FOREACH (_ IN CASE WHEN value.title[0].text IS NOT NULL THEN [true] ELSE [] END |
CREATE (a)-[:HAS_TITLE]->(:Section{text:value.title[0].text})
)
FOREACH (t in value.tags |
MERGE (tag:Tag{name:t.text}) MERGE (a)-[:HAS_TAG]->(tag)
)
WITH a, value.text as texts
UNWIND texts as row
WITH a,row.text as text
WHERE text IS NOT NULL
CREATE (a)-[:HAS_SECTION]->(:Section{text:text});기사 결과를 저장하는 Cypher 쿼리를 더 복잡하게 만들고 싶지 않아서, 계속하기 전에 태그를 약간 정리해야 해요.
MATCH (n:Tag)
WHERE n.name CONTAINS "Notification"
DETACH DELETE n;스크래핑 프로세스를 평가하고 얼마나 많은 기사가 성공적으로 스크래핑되었는지 한번 살펴볼까요?
MATCH (a:Article)
RETURN exists((a)-[:HAS_SECTION]->()) as scraped_articles,
count(*) as count제 경우에는 245개 기사에 대한 정보 수집에 성공했어요. 타임머신이 없으면 이 분석을 똑같이 재현할 수는 없을 거예요. 2021년 1월 30일에 웹사이트를 스크랩했는데, 아마도 나중에 하실 것 같아요. 대부분의 분석 쿼리를 일반적으로 준비했으므로 뉴스 스크랩 날짜와 관계없이 잘 작동할 거예요.
기사에서 가장 자주 사용되는 태그도 살펴볼게요.
MATCH (n:Tag)
RETURN n.name as tag, size((n)<-[:HAS_TAG]-()) as articles
ORDER BY articles DESC
LIMIT 10결과는 다음과 같아요.
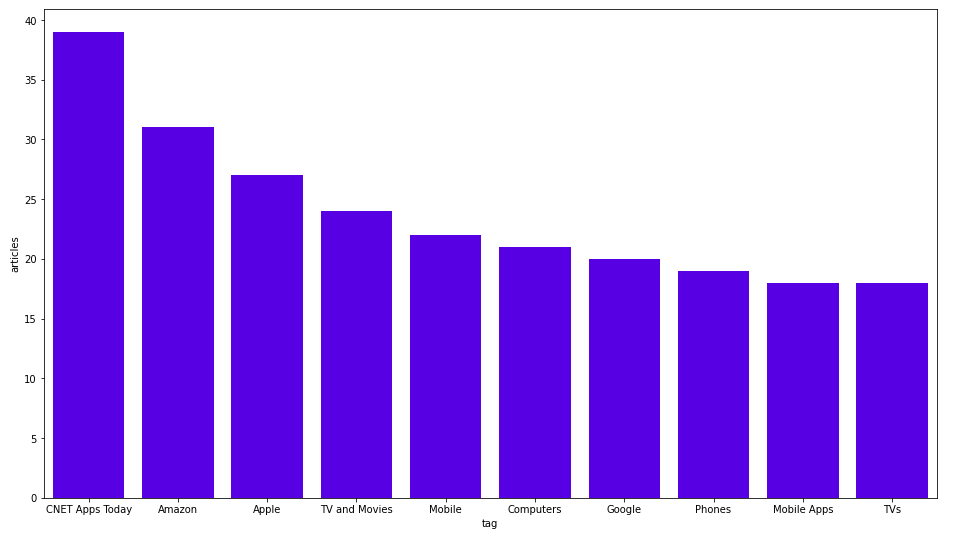
이 블로그 게시물의 모든 차트는 시본 도서관에서 만들었어요. CNET Apps Today가 가장 자주 사용되는 태그네요. 제 생각에는 그냥 일간 뉴스의 일반적인 태그일 뿐인 것 같아요. Amazon, Apple, Google과 같은 다양한 대기업을 위한 맞춤 태그가 있다는 것도 확인할 수 있어요.
명명된 엔터티 연결: Wikification
제 이전 블로그 게시물에서, Knowledge Graph를 생성하기 위한 명명된 엔터티 인식 기술을 이미 다뤘었죠. 여기서는 한 단계 더 나아가 명명된 엔터티 연결에 대해 자세히 살펴볼게요.
먼저, 명명된 엔터티 연결이란 정확히 뭘까요?
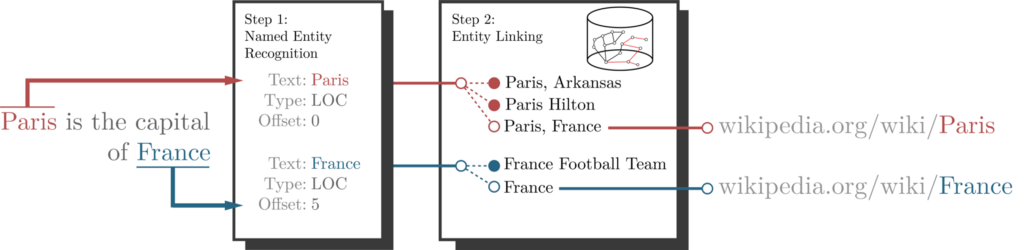
명명된 엔터티 연결은 엔터티 인식 기술의 업그레이드 버전이라고 할 수 있어요. 텍스트의 모든 개체를 인식하는 것부터 시작하는데요. 명명된 엔터티 인식 프로세스가 완료되면 해당 엔터티를 대상 Knowledge Graph에 연결하려고 시도해요. 일반적으로 대상 Knowledge Graph는 Wikipedia 또는 DBpedia이지만, 다른 Knowledge Graph도 물론 있죠.
위의 예에서 명명된 엔터티 인식 프로세스가 파리를 엔터티로 인식한 것을 확인할 수 있어요. 다음 단계는 이를 Knowledge Graph의 대상 엔터티에 연결하는 거예요. 여기서는 Wikipedia를 대상 Knowledge Graph로 사용하고 있네요. 이는 Wikification 프로세스라고도 불려요.
Wikipedia에 제목에 Paris가 포함된 많은 엔터티가 존재한다는 것을 알 수 있어서 엔터티 연결 프로세스는 약간 까다로울 수 있어요. 따라서 엔터티 연결 프로세스의 일부로 NLP 모델은 엔터티 명확성을 수행하게 돼요.
시중에는 12개의 엔터티 연결 모델이 있어요. 그 중 일부는 다음과 같아요.
저는 슬로베니아 출신이라, 어쩔 수 없이 편향된 결정을 내리게 되는데, 바로 슬로베니아 솔루션인 Wikifier[1]를 사용하는 거예요. 사실 NLP 모델을 제공하는 건 아니지만, 무료로 사용할 수 있는 API 엔드포인트가 있답니다. 사용하려면 해야 해요. 심지어 비밀번호나 이메일도 필요 없으니, 정말 다행이죠?
Wikifier는 100개 이상의 언어를 지원하고, 결과를 Fine-tuning하는 데 사용할 수 있는 몇 가지 파라미터도 제공해요. 가장 중요한 파라미터는 pageRankSqThreshold인데, 모델의 재현율이나 정확성을 최적화하는 데 사용할 수 있죠.
위의 예제를 Wikifier API를 통해 실행하면 다음과 같은 결과를 얻을 수 있어요.
Wikifier API가 세 개의 엔터티와 해당 Wikipedia URL, WikiData 항목 ID를 반환한 것을 확인할 수 있죠? WikiData 항목 ID를 Neo4j에 다시 저장하기 위한 고유 식별자로 사용할 거예요.
APOC 라이브러리에는 모든 API 엔드포인트에서 결과를 검색하는 데 사용할 수 있는 apoc.load.json 프로시저가 있어요. 더 많은 양의 데이터를 처리하는 경우에는 일괄 처리 목적으로 apoc.periodic.iterate 프로시저를 사용하는 게 좋답니다.
이 모든 것을 종합하면, 다음 Cypher 쿼리는 API 엔드포인트에서 각 섹션에 대한 주석 결과를 가져와 결과를 Neo4j에 저장해요.
CALL apoc.periodic.iterate('
MATCH (s:Section) RETURN s
','
WITH s, "?" +
"text=" + apoc.text.urlencode(s.text) + "&" +
"lang=en&" +
"pageRankSqThreshold=0.80&" +
"applyPageRankSqThreshold=true&" +
"nTopDfValuesToIgnore=200&" +
"nWordsToIgnoreFromList=200&" +
"minLinkFrequency=100&" +
"maxMentionEntropy=10&" +
"wikiDataClasses=false&" +
"wikiDataClassIds=false&" +
"userKey=" + $userKey as url
CALL apoc.load.json(url) YIELD value
UNWIND value.annotations as annotation
MERGE (e:Entity{wikiDataItemId:annotation.wikiDataItemId})
ON CREATE SET e.title = annotation.title, e.url = annotation.url
MERGE (s)-[:HAS_ENTITY]->(e)',
{batchSize:100, params: {userKey:$user_key}})Named Entity Linking 프로세스는 몇 분 정도 걸릴 거예요. 이제 가장 자주 언급되는 항목을 확인할 수 있답니다.
MATCH (e:Entity)
RETURN e.title, size((e)<--()) as mentions
ORDER BY mentions DESC LIMIT 10;결과는 다음과 같아요.
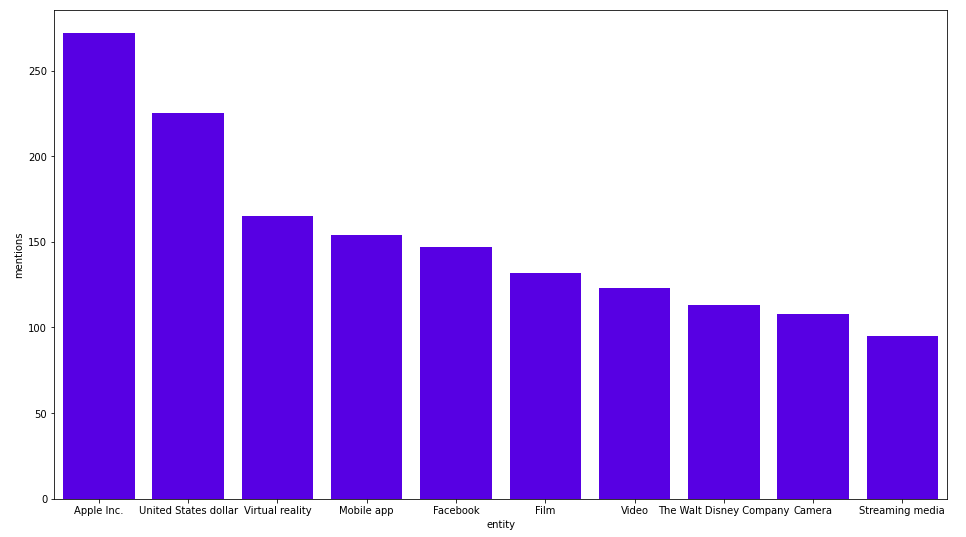
가장 자주 언급되는 기업은 Apple Inc.네요. 저는 모든 달러 기호나 USD 언급이 미국 달러와 연결되어 있다고 추측하고 있어요. 기사별로 가장 많이 언급되는 태그도 살펴볼까요?
MATCH (e:Entity)<-[:HAS_ENTITY]-()<-[:HAS_SECTION]-()-[:HAS_TAG]->(tag)
WITH tag.name as tag, e.title as title, count(*) as mentions
ORDER BY mentions DESC
RETURN tag, collect(title)[..3] as top_3_mentions
LIMIT 5;결과는 다음과 같아요.
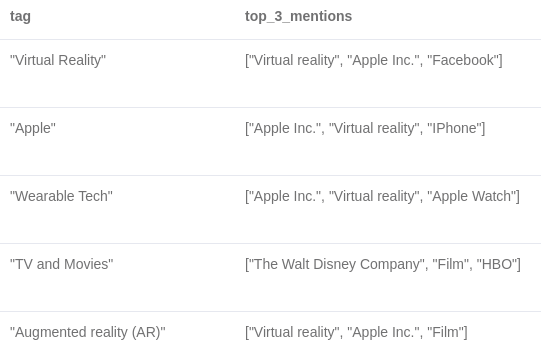
WikiData 강화
Wikification 프로세스 사용의 보너스는 엔터티의 WikiData 항목 ID가 있다는 점이에요. 이걸 이용하면 추가 정보를 얻기 위해 WikiData API를 스크랩하는 게 정말 쉬워진답니다.
모든 비즈니스 및 개인 엔터티를 정의한다고 가정해 볼게요. WikiData API에서 엔터티 클래스를 가져오고, 해당 정보를 사용해서 엔터티를 그룹화하는 거죠. 다시 apoc.load.json 프로시저를 사용해서 API 엔드포인트에서 응답을 검색할 거예요.
MATCH (e:Entity)
// Prepare a SparQL query
WITH 'SELECT *
WHERE{
?item rdfs:label ?name .
filter (?item = wd:' + e.wikiDataItemId + ')
filter (lang(?name) = "en" ) .
OPTIONAL{
?item wdt:P31 [rdfs:label ?class] .
filter (lang(?class)="en")
}}' AS sparql, e
// make a request to Wikidata
CALL apoc.load.jsonParams(
"" +
apoc.text.urlencode(sparql),
{ Accept: "application/sparql-results+json"}, null)
YIELD value
UNWIND value['results']['bindings'] as row
FOREACH(ignoreme in case when row['class'] is not null then [1] else [] end |
MERGE (c:Class{name:row['class']['value']})
MERGE (e)-[:INSTANCE_OF]->(c));계속해서 엔터티의 가장 빈번한 클래스를 검사해볼게요.
MATCH (c:Class)
RETURN c.name as class, size((c)<--()) as count
ORDER BY count DESC LIMIT 5;결과는 다음과 같아요.
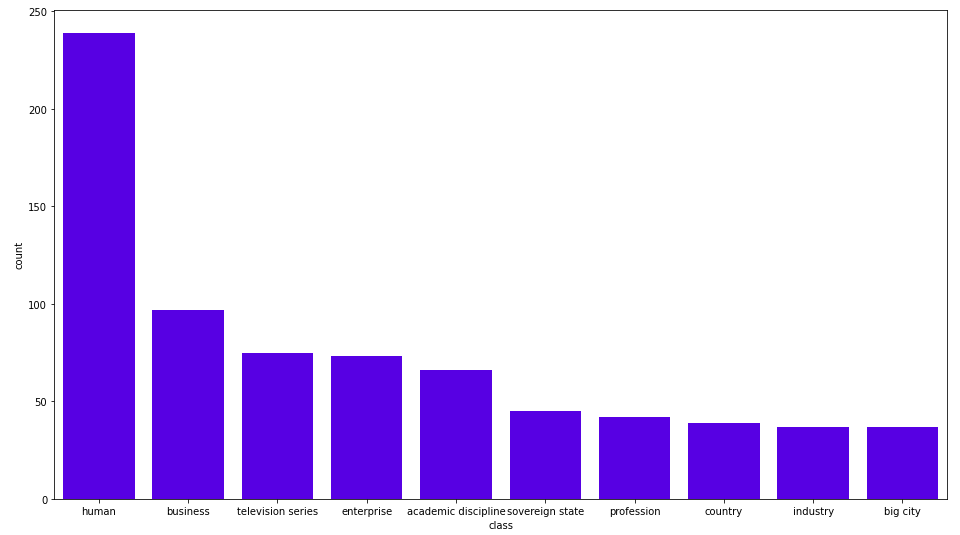
Wikification 프로세스에서는 거의 250개의 인간 엔터티와 100개의 비즈니스 엔터티가 발견되었어요. 추가적인 Cypher 쿼리를 단순화하기 위해 개인 및 비즈니스 엔터티에 보조 라벨을 할당할게요.
MATCH (e:Entity)-[:INSTANCE_OF]->(c:Class)
WHERE c.name in ["human"]
SET e:Person;
MATCH (e:Entity)-[:INSTANCE_OF]->(c:Class)
WHERE c.name in ["business", "enterprise"]
SET e:Business;보조 라벨을 추가하면 이제 가장 자주 언급되는 사업체를 쉽게 조사할 수 있어요.
MATCH (b:Business)
RETURN b.title as business, size((b)<-[:HAS_ENTITY]-()) as mentions
ORDER BY mentions DESC
LIMIT 10결과는 다음과 같아요.
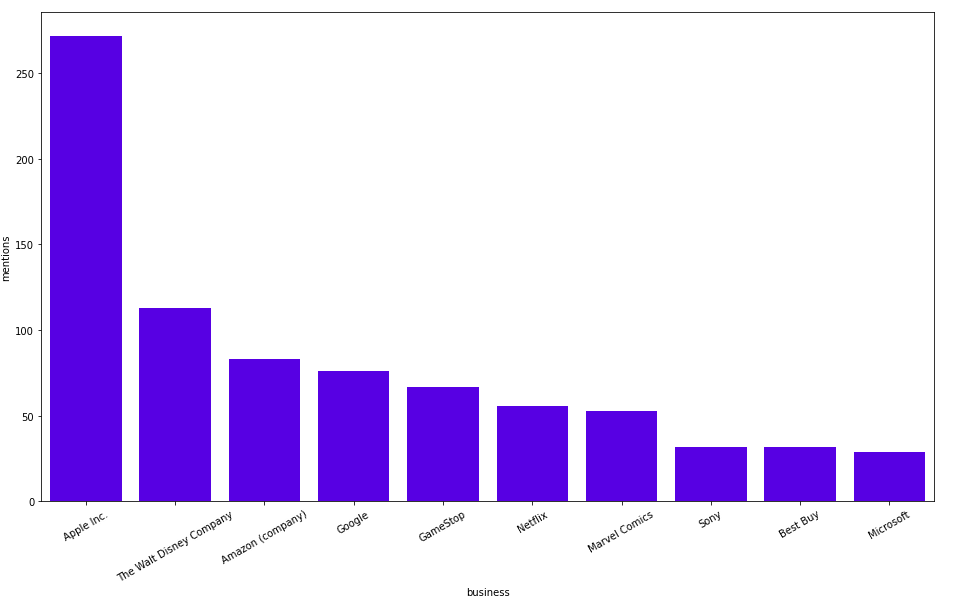
우리는 이미 Apple과 Amazon이 많이 논의되었다는 것을 알고 있었죠. 여러분 중 일부는 GameStop에 대한 많은 언급을 볼 수 있기 때문에 이번 주가 주식 시장에서 흥미로운 한 주였다는 것을 이미 알고 있을 거예요.
가능하기 때문에 WikiData API에서 사업체의 산업도 가져와 볼게요.
MATCH (e:Business)
// Prepare a SparQL query
WITH 'SELECT *
WHERE{
?item rdfs:label ?name .
filter (?item = wd:' + e.wikiDataItemId + ')
filter (lang(?name) = "en" ) .
OPTIONAL{
?item wdt:P452 [rdfs:label ?industry] .
filter (lang(?industry)="en")
}}' AS sparql, e
// make a request to Wikidata
CALL apoc.load.jsonParams(
"" +
apoc.text.urlencode(sparql),
{ Accept: "application/sparql-results+json"}, null)
YIELD value
UNWIND value['results']['bindings'] as row
FOREACH(ignoreme in case when row['industry'] is not null then [1] else [] end |
MERGE (i:Industry{name:row['industry']['value']})
MERGE (e)-[:PART_OF_INDUSTRY]->(i));탐색적 그래프 분석
데이터 파이프라인 수집이 완료되었어요. 이제 우리는 재미를 느끼고 Knowledge Graph를 탐색할 수 있어요. 먼저 가장 자주 언급되는 법인 중 가장 많이 동시 발생하는 법인을 살펴볼게요. 제 경우에는 Apple Inc.이에요.
MATCH (b:Business)
WITH b, size((b)<-[:HAS_ENTITY]-()) as mentions
ORDER BY mentions DESC
LIMIT 1
MATCH (other_entities)<-[:HAS_ENTITY]-()-[:HAS_ENTITY]->(b)
RETURN other_entities.title as entity, count(*) as count
ORDER BY count DESC LIMIT 10;결과는 다음과 같아요.
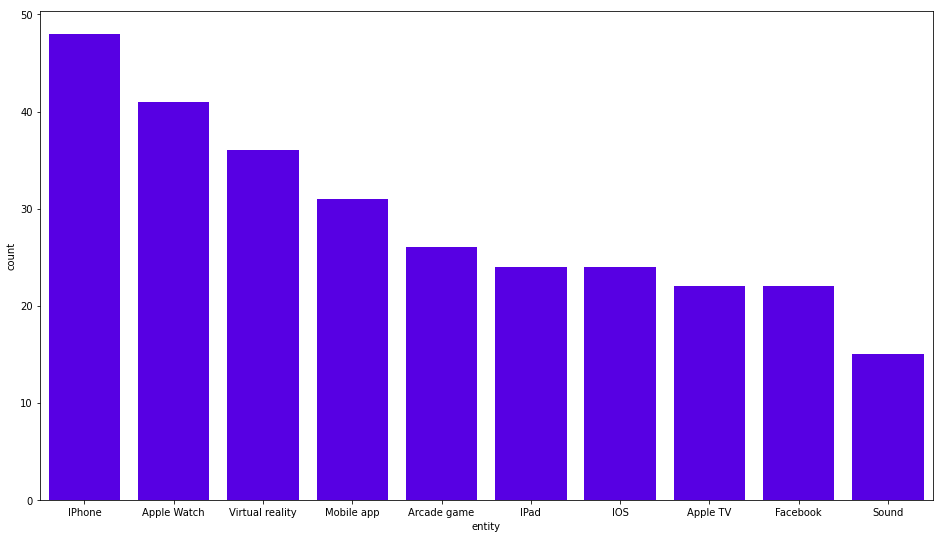
여기에는 멋진 것이 없네요. iPhone, Apple Watch 및 VR도 언급되는 섹션에는 Apple Inc.가 나타나요. 좀 더 흥미로운 소식을 살펴볼게요. 나는 흥미로울 만한 기사의 관련 태그를 검색하고 있었어요.
CNET에는 많은 특정 태그가 있었지만, 지금은 태그가 더 광범위하고 관련성이 높아졌어요. 주식 시장 기사 카테고리에서 가장 많이 언급된 업종을 확인해볼까요?
MATCH (t:Tag)<-[:HAS_TAG]-()-[:HAS_SECTION]->()-[:HAS_ENTITY]->(entity:Business)-[:PART_OF_INDUSTRY]->(industry)
WHERE t.name = "Stock Market"
RETURN industry.name as industry, count(*) as mentions
ORDER BY mentions DESC
LIMIT 10결과는 다음과 같아요.
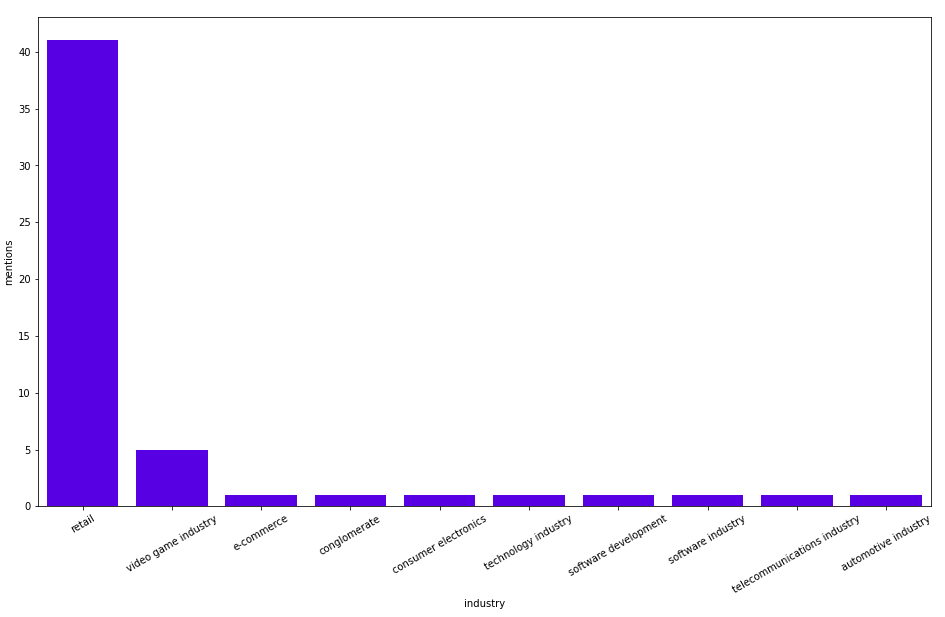
소매업이 가장 많이 언급되고, 그 다음은 비디오 게임 산업이네요. 그 외 다른 산업들은 언급 횟수가 적어요. 다음으로 주식 시장 카테고리에서 가장 많이 언급되는 기업이나 인물을 알아볼게요.
MATCH (t:Tag)<-[:HAS_TAG]-()-[:HAS_SECTION]->()-[:HAS_ENTITY]->(entity)
WHERE t.name = "Stock Market" AND (entity:Person OR entity:Business)
RETURN entity.title as entity, count(*) as mentions
ORDER BY mentions DESC
LIMIT 10결과는 이렇습니다.
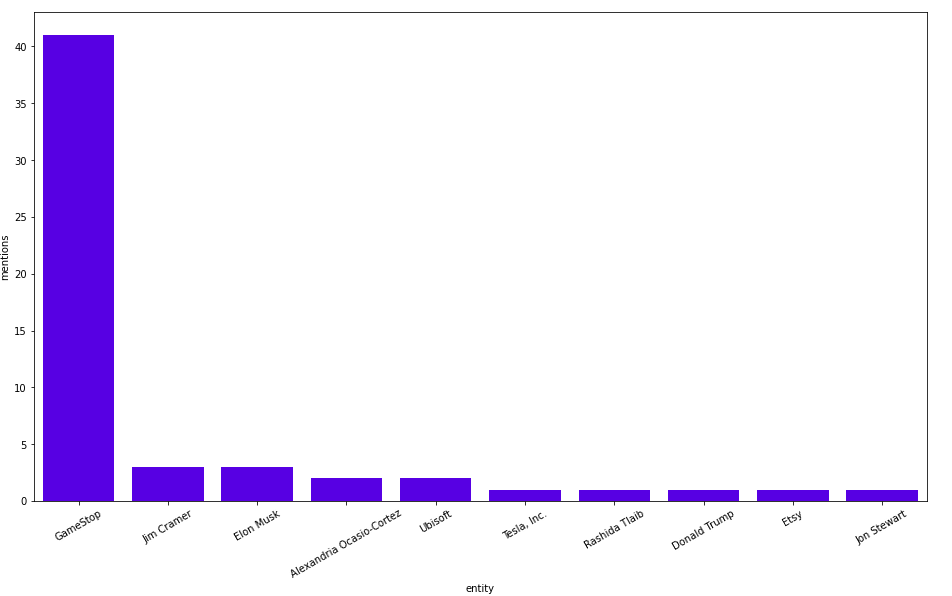
와, GameStop이 이번 주말에 40번 넘게 언급되면서 엄청난 인기를 얻었네요! Jim Cramer, Elon Musk, Alexandria Ocasio-Cortez는 훨씬 뒤쳐져 있어요. GameStop이 왜 이렇게 핫한지, 동시에 발생하는 엔터티를 살펴보면서 알아볼까요?
MATCH (b:Business{title:"GameStop"})<-[:HAS_ENTITY]-()-[:HAS_ENTITY]->(other_entity)
RETURN other_entity.title as co_occurent_entity, count(*) as mentions
ORDER BY mentions DESC
LIMIT 10결과는 다음과 같습니다.
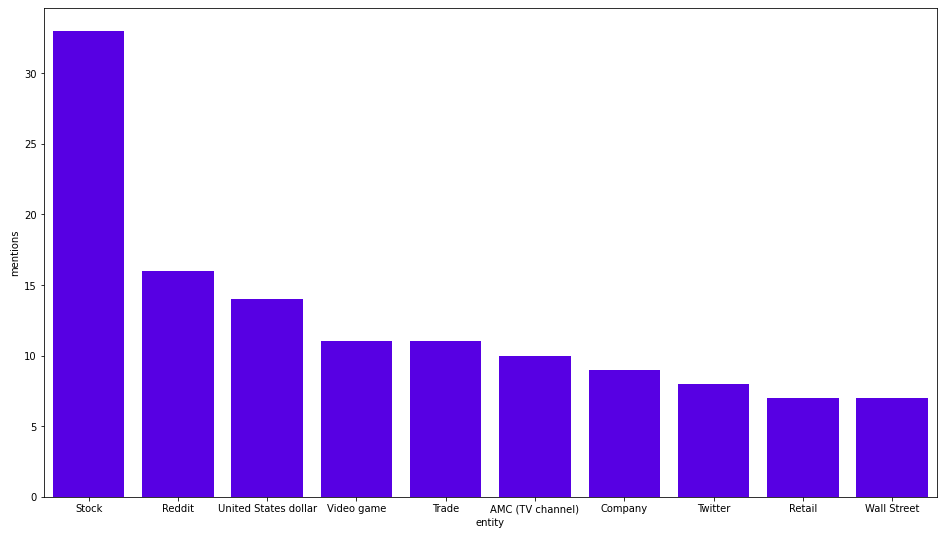
GameStop과 같은 섹션에서 가장 자주 언급되는 엔터티는 Stock, Reddit, US Dollar네요. 뉴스를 보면 결과가 꽤나 타당하다는 걸 알 수 있어요. AMC(TV 채널)는 잘못 식별된 것 같고, 아마 AMC Theatres 회사일 거라고 추측해봅니다.
Natural Language Processing 프로세스에는 항상 약간의 실수가 있을 수 있죠. 결과를 조금 필터링해서 GameStop에 가장 많이 동시 발생하는 개인이나 사업체를 찾아볼게요.
MATCH (b:Business{title:"GameStop"})<-[:HAS_ENTITY]-()-[:HAS_ENTITY]->(other_entity:Person)
RETURN other_entity.title as co_occurent_entity, count(*) as mentions
ORDER BY mentions DESC
LIMIT 10결과는 다음과 같아요.
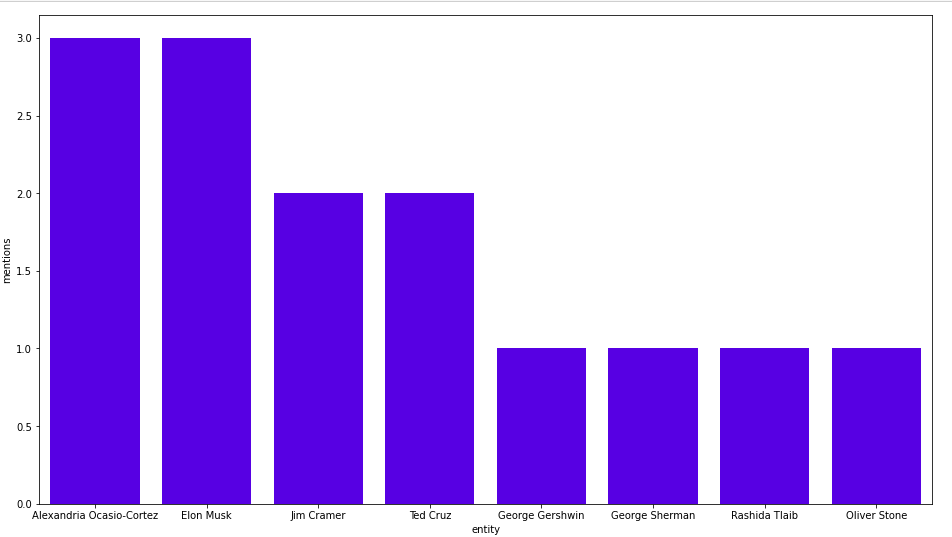
Alexandria Ocasio-Cortez(AOC)와 Elon Musk는 GameStop 관련 섹션에 각각 등장하네요. AOC가 GameStop과 함께 발생하는 텍스트를 한번 살펴볼까요?
MATCH (b:Business{title:"GameStop"})<-[:HAS_ENTITY]-(section)-[:HAS_ENTITY]->(p:Person{title:"Alexandria Ocasio-Cortez"})
RETURN section.text as text결과는 이렇습니다.

Graph Data Science
지금까지는 Cypher 쿼리 언어를 사용해서 몇 가지 집계만 수행했어요. 정보를 저장하기 위해 Knowledge Graph를 활용하고 있으니, 여기에 몇 가지 그래프 알고리즘을 실행해볼게요. Neo4j Graph Data Science 라이브러리는 현재 50개 이상의 그래프 알고리즘을 사용할 수 있는 Neo4j용 플러그인이에요. 알고리즘은 커뮤니티 감지 및 중심성부터 Node Embedding 및 그래프 Neural Network 범주까지 다양하답니다.
우리는 지금까지 일부 동시 발생 개체를 이미 검사했죠. 다음으로 Knowledge Graph 내에서 사람들의 동시 발생 네트워크를 추론해볼게요. 이 프로세스는 기본적으로 동일한 섹션에서 두 엔터티가 언급되는 간접적인 관계를 해당 두 엔터티 간의 직접적인 관계로 변환하는 거예요. 아래 다이어그램이 프로세스를 이해하는 데 도움이 될 거예요.
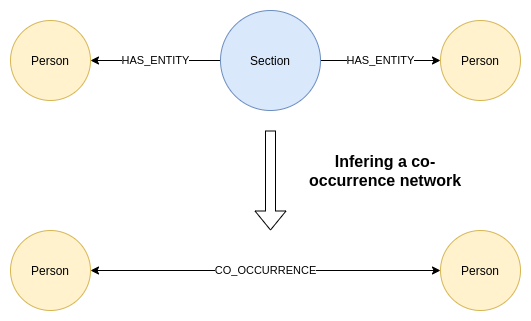
개인 동시 발생 네트워크를 추론하기 위한 Cypher 쿼리는 다음과 같아요.
MATCH (s:Person)<-[:HAS_ENTITY]-()-[:HAS_ENTITY]->(t:Person)
WHERE id(s) < id(t)
WITH s,t, count(*) as weight
MERGE (s)-[c:CO_OCCURENCE]-(t)
SET c.weight = weight우리가 사용하는 첫 번째 그래프 알고리즘은 Weakly Connected Components 알고리즘이에요. 이건 네트워크 내에서 연결이 끊긴 구성 요소나 아일랜드를 식별하는 데 사용되죠.
CALL gds.wcc.write({
nodeProjection:'Person',
relationshipProjection:'CO_OCCURENCE',
writeProperty:'wcc'})
YIELD componentCount, componentDistribution결과는 다음과 같아요.
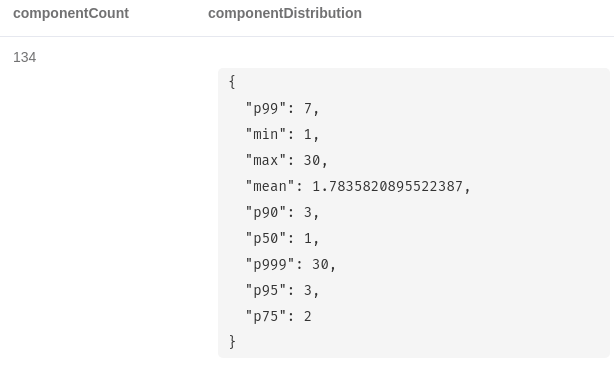
알고리즘은 그래프 내에서 연결이 끊긴 구성 요소 134개를 발견했어요. p50 값은 커뮤니티 규모의 50번째 백분위수이고요. 대부분의 구성 요소는 단일 node로 구성되어 있네요.
이는 CO_OCCURENCE relationship이 없다는 의미겠죠. 가장 큰 node 섬은 30개의 구성원으로 구성되어 있어요. 우리는 그 구성원을 보조 label로 표시할 거예요.
MATCH (p:Person)
WITH p.wcc as wcc, collect(p) as members
ORDER BY size(members) DESC LIMIT 1
UNWIND members as member
SET member:LargestWCC우리는 커뮤니티 구조를 조사하고 가장 중심적인 node를 찾으려고 노력함으로써 가장 큰 구성 요소를 추가로 분석할 거예요. 동일한 투영 그래프에서 여러 알고리즘을 실행할 계획이 있다면 명명된 그래프를 사용하면 좋아요. 동시 발생 네트워크의 relationship은 방향이 지정되지 않은 것으로 간주돼요.
CALL gds.graph.create('person-cooccurence', 'LargestWCC',
{CO_OCCURENCE:{orientation:'UNDIRECTED'}},
{relationshipProperties:['weight']})먼저 가장 중심적인 node를 식별하는 데 도움이 되는 PageRank 알고리즘을 실행해 볼게요.
CALL gds.pageRank.write('person-cooccurence', {relationshipWeightProperty:'weight', writeProperty:'pagerank'})다음으로 커뮤니티 탐지 알고리즘인 Louvain 알고리즘을 실행할 거예요.
CALL gds.louvain.write('person-cooccurence', {relationshipWeightProperty:'weight', writeProperty:'louvain'})어떤 사람들은 한 장의 사진이 천 마디 말보다 낫다고 말하죠. 소규모 네트워크를 다룰 때는 결과의 네트워크 시각화를 만드는 것이 정말 좋아요. 다음 시각화는 Neo4j Bloom을 사용하여 생성되었어요.

결론
저는 Natural Language Processing과 Knowledge Graph가 완벽하게 어울리는 방식이 정말 좋더라고요. 데이터 파이프라인을 구현하고 결과를 Knowledge Graph 형식으로 저장하는 방법에 대한 몇 가지 아이디어와 지침을 제공했기를 바라요. 어떻게 생각하는지 알려주세요!
언제나 그렇듯이 코드는 다음에서 사용할 수 있어요: .
참고 자료
[1] 야네즈 브랑크, 그레고르 레반, 마르코 그로벨닉. 관련 Wikipedia 개념으로 문서에 주석 달기. 슬로베니아 데이터 마이닝 및 데이터 웨어하우스에 관한 회의 간행물(SiKDD 2017), 슬로베니아 류블랴나, 2017년 10월 9일.
- 명명된 엔터티 연결
- news
- nlp
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'GraphRAG' 카테고리의 다른 글
| 그래프의 시각적 단순성: Fractal 5 팀과의 5분 인터뷰 (Neo4j, GraphRAG, Machine Learning, API) (1) | 2026.05.25 |
|---|---|
| Neo4j에 Microsoft GraphRAG 통합하기 (0) | 2026.05.25 |
| 고대 서사시에서 현대적 경이로움으로: GraphRAG으로 마하바라타 챗봇 파헤치기 (3부) (0) | 2026.05.24 |
| 데이터 과학 도구를 활용한 사기 조사 파헤치기 (0) | 2026.05.24 |
| Neo4j와 GraphRAG로 떠나는 Machine Learning API 개발 여행 (0) | 2026.05.24 |