
- 사이퍼 & GQL
LangChain4j에 Neo4j 통합에 대한 간략한 개요
빠른 개요
LangChain4j는 Python 및 JavaScript용 LangChain과 유사한 Java 라이브러리로, AI/LLM 기능을 Java 애플리케이션에 통합하는 작업을 단순화해요. It provides a clean API for working with a variety of LLM providers and embedding stores.
또한 LangChain4j에는 감정 분석 및 정보 추출과 같은 AI 작업을 위한 도구가 포함되어 있어요. 라이브러리는 아직 활발하게 개발 중이지만 핵심 기능은 안정적이고 사용 가능하답니다.
이 기사에서는 연결된 데이터 관리를 위해 설계된 고성능 오픈 소스 그래프 데이터베이스인 Neo4j와 함께 LangChain4j 프레임워크를 설정하고 사용하여 그래프 기반 질문 답변을 수행하는 방법을 보여줄 거예요. LangChain4j를 Neo4j와 통합하면 고급 언어 모델과 그래프 데이터를 활용하여 데이터베이스 내에 저장된 relationships 및 properties를 기반으로 복잡한 queries에 응답할 수 있어요.
이 가이드는 버전 1.0.0-beta4를 기반으로 하며 향후 릴리스에서는 여기에 설명된 동작이나 인터페이스 중 일부를 변경할 수 있는 변경 사항이나 추가 기능이 도입될 수 있다는 점에 유의하는 것이 중요해요.
Neo4j 클래스
LangChain4j는 Neo4j 통합을 위해 다음 클래스를 제공해요.
- Neo4jEmbeddingStore — EmbeddingStore 인터페이스를 구현하여 Neo4j 데이터베이스에 Vector Embedding을 저장하고 query할 수 있어요.
- Neo4jText2CypherRetriever — 사용자 질문에서 Cypher 쿼리를 생성 및 실행하기 위한 ContentRetriever 인터페이스를 구현하여 Neo4j 데이터베이스에서 콘텐츠 검색을 향상시켜요.
EmbeddingStore 인터페이스는 embeddings(데이터의 Vector 표현)을 저장하고 검색하는 표준 방법을 정의해요. 여기에는 세 가지 주요 메서드 세트가 있어요.
- add/addAll — 하나 또는 여러 개의 embeddings을 추가해요.
- search(EmbeddingSearchRequest 요청) — query embedding 및 검색 매개변수를 기반으로 유사한 embeddings을 검색해요. EmbeddingSearchRequest는 query 삽입(검색 대상)을 포함하는 빌더이며 선택적으로(원하는 일치 수) 및(선택적 최소 유사성 임계값).
- 제거/removeAll — ID별로 embeddings을 제거해요.
ContentRetriever 인터페이스는 query를 기반으로 관련 콘텐츠를 검색하기 위한 간단한 계약을 정의해요. 여기에는 query(텍스트, 필터 등을 포함할 수 있음)를 가져와 관련 콘텐츠 항목 목록을 반환하는 검색(문자열 query)이라는 하나의 주요 메서드가 있어요.
ContentRetriever는 높은 수준의 추상화예요. 데이터베이스, Vector 저장소, 검색 엔진, 심지어 맞춤 로직과 같은 다양한 시스템의 지원을 받을 수 있죠.
Neo4j 임베딩 스토어
다음 종속성을 추가해야 해요.
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-neo4j</artifactId>
<version>${langchain.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>${langchain.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-embeddings-all-minilm-l6-v2</artifactId>
<version>${langchain.version}</version>
</dependency>다음 예에서는 langchain4j-embeddings-all-minilm-l6-v2를 사용하여 EmbeddingModel 인터페이스를 구현하는 AllMiniLmL6V2EmbeddingModel을 생성해요. 또는 langchain4j-open-ai 모듈의 OpenAiEmbeddingModel과 같이 LangChain4j에서 제공하는 수많은 모델 중 하나를 사용할 수도 있어요.
Neo4j 데이터베이스에 연결하고 Embedding Store 인스턴스 만들기
다음과 같은 방법으로 만들 수 있어요.
Driver graphDatabaseDriver = /* org.neo4j.driver.Driver instance */
Neo4jEmbeddingStore.builder()
.withBasicAuth("bolt://<neo4jBoltUrlHost>:<port>", "<user>", "<password>")
.dimension(384)
.build();또는 동등하게:
Driver graphDatabaseDriver = /* org.neo4j.driver.Driver instance */
Neo4jEmbeddingStore.builder()
.driver(graphDatabaseDriver)
.dimension(384)
.build();보시다시피 필수 구성은 Neo4j 인덱스 `dimension` 매개변수와 Neo4j Java 드라이버 연결 인스턴스예요. Neo4j Java 드라이버 대신 `Neo4jEmbeddingStore.builder().withBasicAuth(<url>, <username>, <password>)`를 생성하여 내부적으로 드라이버 연결 인스턴스를 생성할 수 있어요.
나중에 살펴보겠지만 빌더를 통해 다른 선택적 구성을 추가할 수 있답니다.
임베딩 저장
EmbeddingStore<TextSegment> minimalEmbedding = Neo4jEmbeddingStore.builder()
.withBasicAuth(neo4j.getBoltUrl(), "neo4j", neo4j.getAdminPassword())
.dimension(embeddingModel.dimension())
.build();
// or use OpenAIEmbeddingModel or other EmbeddingModel implementations
EmbeddingModel embeddingModel = new AllMiniLmL6V2QuantizedEmbeddingModel();
// add a single embedding
TextSegment segment = TextSegment.from("I like football.");
Embedding embedding = embeddingModel.embed(segment).content();
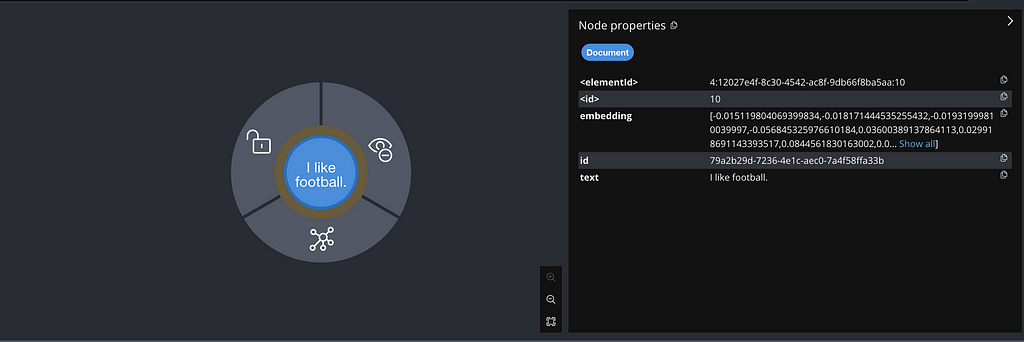
minimalEmbedding.add(embedding, segment);위의 코드는 Label `Document`와 다음 속성을 사용하여 `Node`를 생성해요.
- `Vector Embedding`으로 삽입
- 원본 텍스트가 포함된 텍스트
- UUID가 포함된 ID
위 예시를 바탕으로, 다음 코드를 실행하여 Neo4j에서 `embeddings`를 가져올 수 있어요.
Embedding queryEmbedding = embeddingModel.embed("What is your favourite sport?").content();
final EmbeddingSearchRequest request = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(1)
.build();
List<EmbeddingMatch<TextSegment>> relevant = minimalEmbedding.search(request).matches();
EmbeddingMatch<TextSegment> embeddingMatch = relevant.get(0);
System.out.println(embeddingMatch.score());
// result like this: 0.8144289255142212
System.out.println(embeddingMatch.embedded().text());
// I like football.내부적으로는 다음이 실행된답니다.
CALL db.index.vector.queryNodes(<indexName>, <maxResults>, <embeddingValue>)
YIELD node, score
WHERE score >= <minScore>
// <retrievalQuery>와 를 기반으로 검색 쿼리 삽입이 가능하고, <indexName>과 <검색 쿼리>는 사용자 정의할 수 있어요. 첫 번째 인자에는 기본값 'vector'가 있고, 두 번째 인자에는 다음과 같은 기본값이 있죠.
RETURN properties(node) AS metadata,
node.<idProperty> AS <idProperty>,
node.<textProperty> AS <textProperty>,
node.<embeddingProperty> AS <embeddingProperty>,
score<idProperty>, <textProperty>, 그리고 <embeddingProperty> 값도 나중에 살펴보겠지만, 커스터마이징할 수 있다는 점 기억해주세요.
위의 경우 (기본값) 전체 쿼리는 다음과 같아요.
CALL db.index.vector.queryNodes('vector', 1, 'What is your favourite sport?')
YIELD node, score
WHERE score >= 0.0
RETURN properties(node) AS metadata,
node.id AS id,
node.text AS text,
node.embedding AS embedding,
score선택적 구성
위에서 살짝 언급했듯이, 몇 가지 선택적 구성들이 있어요. 현재(글을 쓰는 시점) 다음과 같은 것들이 있답니다.
- Index 이름 (기본값: vector)
- Neo4j Node Label (기본값: Document)
- Neo4j Index의 distanceType 파라미터
- Metadata 접두사 (기본값: metadata)
- 텍스트 필드를 저장하는 Text Property Key (기본값: text)
Neo4jEmbeddingStore customEmbeddingStore = Neo4jEmbeddingStore.builder()
.withBasicAuth("bolt URI", "neo4j", neo4j.getAdminPassword())
.dimension(embeddingModel.dimension())
.indexName("customIdx")
.label("MyCustomLabel")
.embeddingProperty("customProp")
.idProperty("customId")
.textProperty("customText")
.build();
TextSegment segment = TextSegment.from("I like tennis");
Embedding embedding = embeddingModel.embed(segment).content();
customEmbeddingStore.add(embedding, segment);
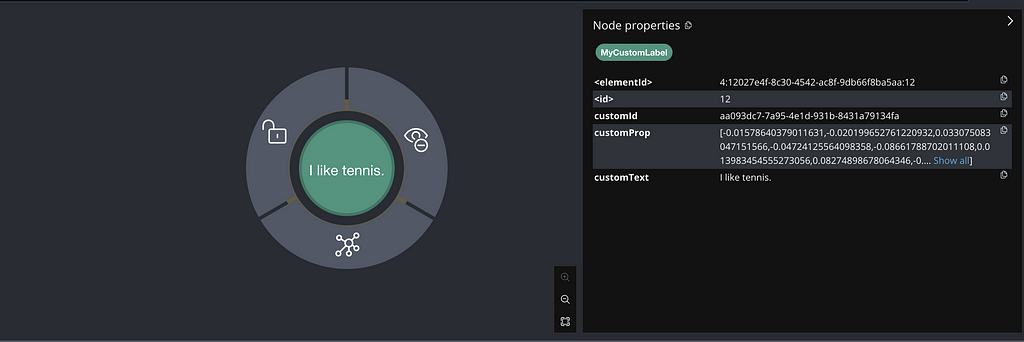
// customEmbeddingStore.search(..).matches();위 예시는 m.customId가 없는 경우 (m:MyCustomLabel) vector index customIdx 생성을 보여주고, MyCustomLabel Label과 다음 속성을 사용해서 Node를 생성해요.
- UUID를 가진 customId
- Embedding된 텍스트를 가진 customProp
- 원본 텍스트를 포함한 customText
다음과 같은 방법으로 커스텀 접두사가 붙은 Metadata를 삽입할 수 있어요 (기본값은 metadata를 사용합니다).
Neo4jEmbeddingStore customEmbeddingStore = Neo4jEmbeddingStore.builder()
.withBasicAuth("bolt://localhost:7687", "neo4j", "pass1234")
.dimension(embeddingModel.dimension())
.indexName("customIdxName")
.label("MyCustomLabel")
.embeddingProperty("customProp")
.idProperty("customId")
.textProperty("customText")
.metadataPrefix("metaCustom")
.build();
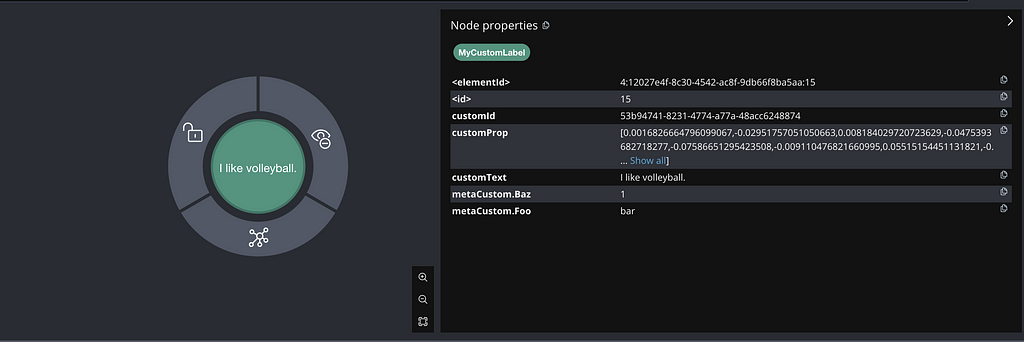
TextSegment segment = TextSegment.from("I like volleyball.", Metadata.from(Map.of("foo", "bar", "baz", 1)));
Embedding embedding = embeddingModel.embed(segment).content();
customEmbeddingStore.add(embedding, segment);다음 결과를 통해 TextSegment의 Metadata.from() 메서드를 확인할 수 있어요.
메타데이터 필터는 LangChain4j 클래스 필터링을 기반으로 해요. 임베딩 검색 중 검색 결과를 필터링하는 데 사용되는 조건을 나타내죠.
Filter builder 매개변수를 지정하면 db.index.Vector.queryNodes가 현재 수행할 수 있는 기능이 제공되지 않기 때문에 쿼리가 달라져요. WHERE 절이 없거든요.
쿼리:
CYPHER runtime = parallel parallelRuntimeSupport=all
MATCH (n:<label>)
WHERE n.<embeddingProperty> IS NOT NULL
AND size(n.<embeddingValue>) = toInteger(<dimension>)
AND <metadataFilter>
WITH n,
vector.similarity.cosine(n.<embeddingProperty>, <embeddingValue>) AS score
WHERE score >= <minScore>
WITH n AS node, score
ORDER BY score DESC
LIMIT <maxResults>EmbeddingSearchRequest로 검색을 수행할 때 필터를 연결해서 결과를 제한할 수 있어요. 예를 들어 특정 메타데이터(예: 문서 유형, 사용자 ID 등)와 일치하는 임베딩만 반환하는 거죠. 일반적으로 value1 = value2, value1 > value2, value1 <= value2와 같은 표현식과 AND, OR, NOT을 사용한 복잡한 논리 조합을 작성하는 데 사용돼요.
예를 들어, 필터를 사용해볼까요?
IsEqualTo filter = new IsEqualTo("key", value);
final EmbeddingSearchRequest requestWithFilter = EmbeddingSearchRequest.builder()
.filter(filter)
.queryEmbedding(/*embeddingToSearch*/)
.build();
final EmbeddingSearchResult<TextSegment> searchWithFilter = embeddingStore.search(requestWithFilter);
그러면 위 쿼리로 실행할 <metadataFilter>가 생성돼요.
WHERE n['key'] = 'value'사용할 수 있는 필터는 다음과 같아요.
IsEqualTo(key, value)IsNotEqualTo(key, value)IsGreaterThan(key, value)IsGreaterThanOrEqualTo(key, value)IsLessThan(key, value)IsLessThanOrEqualTo(key, value)IsIn(key, 값 집합)IsNotIn(key, setOfValues)And(하위 필터, 하위 필터)Not(하위 필터)Or(하위 필터, 하위 필터)
더 복잡한 필터를 만들 수도 있어요.
Or filter = new Or(
new And(new IsEqualTo("key1", "value1"), new IsGreaterThan("key2", "value2")),
new Not(new And(new IsIn("key3", valueKey3), new IsLessThan("key4", "value4"))));
// requestWithFilter and search ...그러면 <metadataFilter>가 생성되죠.
WHERE (
(n['key1'] = 'value1' AND n['key2'] > 'value2')
OR NOT ( (any(x IN ['1', '2'] WHERE x IN n['key3']) AND n['key4'] < 'value4') )
)하이브리드 검색
벡터 유사성 검색과 전체 텍스트 검색을 결합한 하이브리드 검색을 구현하면 결과를 개선할 수 있어요.
하이브리드 접근 방식은 두 데이터 유형(벡터 및 텍스트)의 장점을 활용해서 포괄적인 쿼리 응답을 보장하는 거죠.
내부적으로 autoCreateFullText builder 매개변수(기본값: false)가 true로 설정된 경우 다음이 생성돼요.
CREATE FULLTEXT INDEX <fullTextIndexName> IF NOT EXISTS FOR (n:<label>) ON EACH [n.<idProperty>]search(EmbeddingSearchRequest 요청) 메소드를 실행하면 다음 쿼리가 실행돼요.
CALL db.index.vector.queryNodes($indexName, $maxResults, $embeddingValue)
YIELD node, score
WHERE score >= $minScore
// <retrievalQuery>
UNION
CALL db.index.fulltext.queryNodes($fullTextIndexName, $fullTextQuery, {limit: $maxResults})
YIELD node, score
WHERE score >= $minScore
// fullTextRetrievalQuery전체 텍스트 쿼리 “UNION <fullTextSearch>” 부분을 추가하려면 빌더 메소드가 필요해요.
최소 설정:
Neo4jEmbeddingStore embeddingStore = Neo4jEmbeddingStore.builder()
.withBasicAuth(...)
.dimension(384)
.fullTextIndexName("movie_text")
.fullTextQuery("Matrix")
.build()
// ... add embeddings, e.g. with embeddingStore.addAll(embeddings);
final EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.minScore(0.5)
.maxResults(1)
.build();
// get embeddings
List<EmbeddingMatch<TextSegment>> results =
embeddingStore.search(embeddingSearchRequest).matches();실행된 Neo4j `Query`:
// CALL db.index.fulltext.queryNodes part
UNION
CALL db.index.fulltext.queryNodes('movie_text', 'Matrix', {limit: 1})
YIELD node, score
WHERE score >= 0.5
RETURN properties(node) AS metadata, node.id AS id, node.text AS text, node.embedding AS embedding, score필요한 경우 `fullTextRetrievalQuery`와 `fullTextIndexName`을 사용자 정의할 수도 있어요.
Neo4jEmbeddingStore embeddingStore = Neo4jEmbeddingStore.builder()
.withBasicAuth(...)
.dimension(...)
.fullTextIndexName("elizabeth_text")
.fullTextQuery("elizabeth*")
.fullTextRetrievalQuery("RETURN node.test AS metadata, score, datetime() as datetime")그러면 Neo4j `Query`가 생성되죠.
// CALL db.index.vector.queryNodes part
UNION
CALL db.index.fulltext.queryNodes('elizabeth_text', 'elizabeth*', {limit: $maxResults})
YIELD node, score
WHERE score >= $minScore
RETURN node.test AS metadata, score, datetime() as datetimeSpring Boot 예시
Spring Boot 스타터 예제를 생성하려면 다음 `dependency`들을 추가하면 돼요.
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-neo4j-spring-boot-starter</artifactId>
<version>${langchain.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>${langchain.version}</version>
</dependency>
<!-- or other embedding models, like langchain4j-open-ai -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-embeddings-all-minilm-l6-v2</artifactId>
<version>${langchain.version}</version>
</dependency>Neo4j 스타터는 현재 다음을 제공합니다.application.properties:
# the builder.dimension(dimension) method
langchain4j.community.neo4j.dimension=<dimension>
# the builder.withBasicAuth(uri, username, password) method
langchain4j.community.neo4j.auth.uri=<boltURI>
langchain4j.community.neo4j.auth.user=<username>
langchain4j.community.neo4j.auth.password=<password>
# the builder.label(label) method
langchain4j.community.neo4j.label=<label>
# the builder.indexName(indexName) method
langchain4j.community.neo4j.indexName=<indexName>
# the builder.metadataPrefix(metadataPrefix) method
langchain4j.community.neo4j.metadataPrefix=<metadataPrefix>
# the builder.embeddingProperty(embeddingProperty) method
langchain4j.community.neo4j.embeddingProperty=<embeddingProperty>
# the builder.idProperty(idProperty) method
langchain4j.community.neo4j.idProperty=<idProperty>
# the builder.textProperty(textProperty) method
langchain4j.community.neo4j.textProperty=<textProperty>
# the builder.databaseName(databaseName) method
langchain4j.community.neo4j.databaseName=<databaseName>
# the builder.retrievalQuery(retrievalQuery) method
langchain4j.community.neo4j.retrievalQuery=<retrievalQuery>
# the builder.awaitIndexTimeout(awaitIndexTimeout) method
langchain4j.community.neo4j.awaitIndexTimeout=<awaitIndexTimeout>
자, 여러분이 Bolt URI를 가진 Neo4j 인스턴스를 가지고 있다고 가정해 볼게요. 예를 들어 bolt://localhost:7687이고, 사용자 이름이 'neo4j', 비밀번호가 'pass1234'라면, 다음과 같은 속성들을 설정할 수 있어요.
server.port=8083
langchain4j.community.neo4j.dimension=384
langchain4j.community.neo4j.auth.uri=bolt://localhost:7687
langchain4j.community.neo4j.auth.user=neo4j
langchain4j.community.neo4j.auth.password=pass1234
langchain4j.community.neo4j.label=CustomLabel이제 아래와 같이 Spring Boot 프로젝트를 만들어 봅시다. 여기에는 SpringBootApplication 어노테이션이 붙은 메인 클래스와 두 개의 엔드포인트가 있는 API REST 컨트롤러가 있어요. /add는 임베딩을 저장하고, /search는 가장 유사한 5개의 항목을 가져오는 역할을 해요.
@SpringBootApplication
public class SpringBootExample {
public static void main(String[] args) {
SpringApplication.run(SpringBootExample.class, args);
}
@Bean
public AllMiniLmL6V2EmbeddingModel embeddingModel() {
return new AllMiniLmL6V2EmbeddingModel();
}
}
@RestController
@RequestMapping("/api/embeddings")
public class EmbeddingController {
private final EmbeddingStore<TextSegment> store;
private final EmbeddingModel model;
public EmbeddingController(EmbeddingStore<TextSegment> store, EmbeddingModel model) {
this.store = store;
this.model = model;
}
// add embeddings
@PostMapping("/add")
public String add(@RequestBody String text) {
TextSegment segment = TextSegment.from(text);
Embedding embedding = model.embed(text).content();
return store.add(embedding, segment);
}
// search embeddings
@PostMapping("/search")
public List<String> search(@RequestBody String query) {
Embedding queryEmbedding = model.embed(query).content();
EmbeddingSearchRequest request = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(5)
.build();
return store.search(request).matches()
.stream()
.map(i -> i.embedded().text()).toList();
}
}위 코드를 사용하면 다음과 같이 REST API를 통합할 수 있답니다.
# to create a new embedding
# and store it with a label "SpringBoot"
curl -X POST localhost:8083/api/embeddings/add -H "Content-Type: text/plain" -d "embeddingTest"
# to search the first 5 embeddings
curl -X POST localhost:8083/api/embeddings/search -H "Content-Type: text/plain" -d "querySearchTest"Neo4j Text2Cypher Retriever
다음 dependency를 추가해 주세요.
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-neo4j-retriever</artifactId>
<version>${langchain.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>${langchain.version}</version>
</dependency>이 컴포넌트는 자연어 질문을 Cypher 쿼리로 동적으로 변환해서 Neo4j에 저장된 데이터에 대한 강력한 상황 인식 액세스를 제공해요. 사용자 의도를 그래프 기반 검색과 연결함으로써 검색된 콘텐츠의 정확성과 관련성을 크게 향상시켜 Neo4j를 단순한 데이터베이스가 아닌 지능형 지식 엔진으로 만들어주죠.
Neo4jGraph 클래스
Neo4j 데이터베이스와의 향상된 상호 작용을 위해 설계된 클래스인 Neo4jGraph를 활용하는데, 읽기/쓰기 작업 및 스키마 관리를 포함하고 있어요. 이걸 사용해서 읽기/쓰기 작업을 생성할 수 있죠.
Neo4jGraph neo4jGraph = Neo4jGraph.builder()
.driver(driver)
.build();
neo4jGraph.executeRead("<Neo4j read query>");
neo4jGraph.executeWrite("<Neo4j write query>");Neo4j 엔터티 개요를 얻는 데도 사용할 수 있어요. 자세한 내용은 아래에서 한번 살펴볼까요?
Neo4jGraph neo4jGraph = /* Neo4jGraph instance */;
String schema = neo4jGraph.getSchema();콘텐츠 Retriever 예시
기본 예시:
Driver driver = /* org.neo4j.driver.Driver instance */
Neo4jGraph neo4jGraph = Neo4jGraph.builder()
.driver(driver)
.build();
// create simple dataset
driver.session()
.run("CREATE (book:Book {title: 'Dune'})<-[:WROTE {when: date('1999')}]-(author:Person {name: 'Frank Herbert'})")
Neo4jText2CypherRetriever retriever = Neo4jText2CypherRetriever.builder()
.graph(neo4jGraph)
.chatLanguageModel(chatLanguageModel)
.build();
// retrieve the result
Query query = new Query("Who is the author of the book 'Dune'?");
List<Content> contents = retriever.retrieve(query);
System.out.println(contents.get(0).textSegment().text());
// output: "Frank Herbert"다음 프롬프트 문자열을 사용하여 채팅 요청을 실행해 보세요.
Task:Generate Cypher statement to query a graph database.
Instructions
Use only the provided relationship types and properties in the schema.
Do not use any other relationship types or properties that are not provided.
Schema:
{{schema}}
{{examples}}
Note: Do not include any explanations or apologies in your responses.
Do not respond to any questions that might ask anything else than for you to construct a Cypher statement.
Do not include any text except the generated Cypher statement.
The question is: {{question}}여기서 {{question}}은 '듄'이라는 책의 저자는 누구인가요?이고, 위의 코드에서 {{examples}}는 비어 있으며(기본적으로){{schema}}는 Neo4j Graph에 의해 처리됩니다. apoc.meta.data는 현재 Neo4j 스키마를 검색하고 문자열화하는 procedure에요.
// it samples 3000 nodes for each label
Neo4jGraph neo4jGraph = Neo4jGraph.builder()
.driver(driver)
.sample(3000L)
.build();위 데이터세트의 스키마 문자열은 다음과 같아요.
Node properties are the following:
:Book {title: STRING}
:Person {name: STRING}
Relationship properties are the following:
:WROTE {when: DATE}
The relationships are the following:
(:Person)-[:WROTE]->(:Book)필요하다면 기본 프롬프트를 변경할 수도 있어요.
Neo4jText2CypherRetriever.builder()
.neo4jGraph(/* Neo4jGraph instance */)
.promptTemplate("<custom prompt>")
.build();또한 <examples> 섹션에 몇 가지 예시를 추가해서 결과를 더 풍부하게 만들고 개선할 수도 있죠. 예를 들어:
Neo4jGraph neo4jGraph = /* Neo4jGraph instance */
List<String> examples = List.of(
"""
# Which streamer has the most followers?
MATCH (s:Stream)
RETURN s.name AS streamer
ORDER BY s.followers DESC LIMIT 1
""",
"""
# How many streamers are from Norway?
MATCH (s:Stream)-[:HAS_LANGUAGE]->(:Language {{name: 'Norwegian'}})
RETURN count(s) AS streamers
""");
Neo4jText2CypherRetriever neo4jContentRetriever = Neo4jText2CypherRetriever.builder()
.graph(neo4jGraph)
.chatLanguageModel(openAiChatModel)
// add the above examples
.examples(examples)
.build();
// retrieve the optimized results
final String textQuery = "Which streamer from Italy has the most followers?";
Query query = new Query(textQuery);
List<Content> contents = neo4jContentRetriever.retrieve(query);
System.out.println(contents.get(0).textSegment().text());
// output: "The most followed italian streamer"앞으로 더 많은 내용이 추가될 예정이에요!
LangChain4j와 Neo4j 핵심 기능은 AI/LLM 기능을 Java 애플리케이션에 통합하기 위한 비교적 새로운 도구에요. 라이브러리는 아직 활발하게 개발 중이지만 핵심 기능은 이미 사용할 수 있죠.
Neo4j 통합 역시 많은 개선과 새로운 기능을 통해 발전하고 있어요. 통합이 빠르게 진행되고 있는데요, 오늘 제공되는 기능은 시작에 불과하다는 점! 곧 포함될 몇 가지 기능은 다음과 같아요.
- LLMGraphTransformer— 그래프에서 하나 이상의 문서를 변환하는 패키지예요. 데이터베이스에 구애받지 않으며, 텍스트를 다른 Graph Database에서도 사용할 수 있는 Node 및 Edge 세트로 변환하죠.
- — LLMGraphTransformer를 사용하여 Node 및 Edge를 Neo4j 엔터티로 변환합니다.
- GraphRAG— Knowledge Graph를 사용하여 Retrieval-Augmented Generation (RAG) 구현을 가능하게 하는 유틸리티 세트예요. 예를 들어, 다음을 구현합니다. 부모-자식 리트리버는 문서를 (더 큰) 청크(상위 청크)로 분할하고 이러한 청크를 더 작은 청크(하위 청크)로 분할하여 임베드 가능하고 임시 검색 쿼리를 통해 사용할 수 있게 해줘요.
- — ChatMemory 구현은 메시지 및 세션 Node, LAST_MESSAGE 및 NEXT_MESSAGE Relationship을 통해 Neo4j 데이터베이스에 대화를 저장해요.
향후 업데이트는 더 넓은 LangChain 생태계와 더욱 긴밀하게 연계될 뿐만 아니라 완전히 새로운 기능을 도입할 거예요. LLMGraphTransformer와 같은 그래프 인식 변환기, 고급 GraphRAG 패턴 및 그래프 구조 데이터용으로 설계된 영구 채팅 메모리를 생각해 보세요. AI와 Knowledge Graph가 성장함에 따라 스마트 검색 및 추론을 위한 도구도 향상될 거랍니다.
또한 임베딩 및 검색기에 대한 향상된 재시도 처리와 같은 기존 구성 요소의 사소한 개선 및 구성도 포함될 예정이에요.
- — ChatModels에서 생성된 쿼리가 유효하지 않은 것으로 확인된 경우 실행을 다시 시도해요.
- 사이퍼-DSL— Targeted Cypher 쿼리를 생성하는 유형이 안전한 방법을 목표로 하는 Java Builder
Resources
- LangChain4j 저장소의 구현: 임베딩 스토어, 콘텐츠 리트리버, 스프링 부트 스타터
- 더 많은 예시는 langchain4j-예제 저장소에 있어요.
- LangChain4j 선적 서류 비치
- Neo4j Labs 문서
- LangChain
- LangChain4j
- Text2Cypher
- Vector Search
지식 그래프를 사용하여 대규모 언어 모델의 힘 활용
여러분, Large Language Model(LLM)이 얼마나 강력한지 알고 계시죠? 하지만 LLM을 Knowledge Graph와 결합하면 더욱 놀라운 일이 벌어진다는 사실! 한번 살펴볼까요?
최근 몇 년 동안 LLM은 텍스트를 이해하고 생성하는 능력 덕분에 엄청난 인기를 얻었어요. 하지만 LLM은 방대한 양의 텍스트 데이터로 학습하기 때문에 때로는 부정확하거나 일관성이 없는 정보를 제공하기도 해요. 바로 이 지점에서 Knowledge Graph가 구세주로 등장하는 거죠.
Knowledge Graph는 엔터티와 그 관계를 구조화된 방식으로 나타내는 것이에요. Knowledge Graph를 LLM과 통합함으로써 LLM의 정확성, 신뢰성 및 추론 능력을 향상시킬 수 있어요. 정말 흥미롭죠?
이 블로그 게시물에서는 Knowledge Graph를 사용하여 LLM의 잠재력을 최대한 활용하는 방법을 알아볼 거예요. 그럼 시작해 볼까요?
Knowledge Graph란 무엇인가요?
Knowledge Graph는 엔터티(예: 사람, 장소, 사물, 개념)와 그 관계를 그래프 구조로 나타내는 전문화된 데이터베이스의 한 형태에요. 각 엔터티는 그래프의 node로 표현되고, 엔터티 간의 관계는 relationship으로 표현돼요. Knowledge Graph는 일반적으로 Property Graph로 표현되며, 여기서 node와 relationship 모두 property(키-값 쌍)를 가질 수 있어요.
Knowledge Graph는 다양한 소스에서 정보를 저장하고 추론할 수 있는 유연하고 효율적인 방법을 제공해요. 덕분에 데이터 통합, Semantic Search, 추천 시스템 등 다양한 애플리케이션에 이상적이죠.
Neo4j와 같은 Graph Database는 Knowledge Graph를 저장하고 관리하는 데 최적화되어 있어요. Neo4j는 node와 relationship을 사용하여 데이터를 저장하는 NoSQL Graph Database에요. 또한 Cypher라는 강력한 query 언어를 제공하여 Knowledge Graph에서 데이터를 효율적으로 query하고 조작할 수 있어요.
LLM이란 무엇인가요?
LLM은 방대한 양의 텍스트 데이터로 학습하여 인간과 유사한 텍스트를 생성할 수 있는 Deep Learning 모델의 한 유형이에요. LLM은 텍스트 번역, 언어 번역, 텍스트 요약 등 다양한 Natural Language Processing(NLP) 작업에 사용할 수 있어요.
하지만 LLM은 완벽하지 않아요. LLM은 방대한 양의 텍스트 데이터로 학습하기 때문에 때로는 부정확하거나 일관성이 없는 정보를 제공할 수 있어요. 또한 LLM은 학습 데이터에 없는 새로운 정보를 추론하는 데 어려움을 겪을 수 있어요.
Knowledge Graph로 LLM을 향상시키는 방법
Knowledge Graph를 LLM과 통합하면 LLM의 정확성, 신뢰성 및 추론 능력을 향상시킬 수 있어요. Knowledge Graph를 사용하여 LLM을 향상시키는 방법은 다음과 같아요.
- 검색 증강 생성(RAG): RAG는 LLM이 응답을 생성하기 전에 외부 Knowledge Graph에서 관련 정보를 검색하는 기술이에요. Knowledge Graph에서 관련 정보를 검색함으로써 LLM은 보다 정확하고 신뢰할 수 있는 응답을 생성할 수 있어요.
- 프롬프트 엔지니어링: Knowledge Graph를 사용하여 LLM에 대한 프롬프트를 개선할 수 있어요. Knowledge Graph에서 관련 엔터티와 관계를 포함함으로써 LLM이 프롬프트를 이해하고 정확하고 관련성 높은 응답을 생성하도록 도울 수 있어요.
- Fine-tuning: Knowledge Graph 데이터를 사용하여 특정 작업에 대해 LLM을 Fine-tuning할 수 있어요. Knowledge Graph 데이터로 LLM을 Fine-tuning함으로써 특정 작업에 대한 정확성과 성능을 향상시킬 수 있어요.
- 지식 주입: Knowledge Graph를 사용하여 LLM에 새로운 지식을 주입할 수 있어요. Knowledge Graph에서 새로운 엔터티와 관계를 포함함으로써 LLM이 새로운 정보를 학습하고 추론 능력을 향상시키도록 도울 수 있어요.
Knowledge Graph와 LLM 통합의 이점
Knowledge Graph와 LLM을 통합하면 다음과 같은 여러 가지 이점이 있어요.
- 향상된 정확성: Knowledge Graph는 LLM에 정확하고 구조화된 정보를 제공하여 LLM의 정확성을 향상시키는 데 도움이 될 수 있어요.
- 향상된 신뢰성: Knowledge Graph는 LLM에 신뢰할 수 있는 정보를 제공하여 LLM의 신뢰성을 향상시키는 데 도움이 될 수 있어요.
- 향상된 추론 능력: Knowledge Graph는 LLM이 새로운 정보를 추론하는 데 도움이 될 수 있어요. Knowledge Graph는 엔터티와 그 관계에 대한 구조화된 표현을 제공함으로써 LLM이 학습 데이터에 없는 새로운 정보를 추론하는 데 도움이 될 수 있어요.
- 향상된 설명 가능성: Knowledge Graph는 LLM의 의사 결정을 설명하는 데 도움이 될 수 있어요. Knowledge Graph는 LLM이 응답을 생성하는 데 사용한 엔터티와 관계에 대한 명확하고 간결한 표현을 제공함으로써 LLM의 의사 결정을 설명하는 데 도움이 될 수 있어요.
Knowledge Graph와 LLM 통합의 사용 사례
Knowledge Graph와 LLM 통합은 다음과 같은 다양한 사용 사례에 사용할 수 있어요.
- 챗봇: Knowledge Graph를 사용하여 챗봇의 정확성과 관련성을 향상시킬 수 있어요. Knowledge Graph에서 관련 정보를 검색함으로써 챗봇은 사용자에게 보다 정확하고 관련성 높은 응답을 제공할 수 있어요.
- Semantic Search: Knowledge Graph를 사용하여 Semantic Search 결과의 정확성과 관련성을 향상시킬 수 있어요. Knowledge Graph에서 관련 엔터티와 관계를 검색함으로써 Semantic Search 엔진은 사용자에게 보다 정확하고 관련성 높은 결과를 제공할 수 있어요.
- 추천 시스템: Knowledge Graph를 사용하여 추천 시스템의 정확성과 관련성을 향상시킬 수 있어요. Knowledge Graph에서 관련 엔터티와 관계를 검색함으로써 추천 시스템은 사용자에게 보다 정확하고 관련성 높은 추천을 제공할 수 있어요.
- 사기 탐지: Knowledge Graph를 사용하여 사기 탐지 시스템의 정확성과 효율성을 향상시킬 수 있어요. Knowledge Graph에서 사기 활동과 관련된 엔터티와 관계를 식별함으로써 사기 탐지 시스템은 사기 활동을 보다 정확하고 효율적으로 탐지할 수 있어요.
결론
Knowledge Graph는 LLM의 정확성, 신뢰성 및 추론 능력을 향상시키는 데 사용할 수 있는 강력한 도구에요. Knowledge Graph를 LLM과 통합함으로써 LLM의 잠재력을 최대한 활용하고 다양한 사용 사례에 대한 새로운 가능성을 열 수 있어요.
이 블로그 게시물이 Knowledge Graph를 사용하여 LLM의 잠재력을 최대한 활용하는 방법에 대한 귀중한 통찰력을 제공했기를 바랍니다. 읽어주셔서 감사해요!
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'GraphRAG' 카테고리의 다른 글
| 데이터 과학 도구를 활용한 사기 조사 파헤치기 (0) | 2026.05.24 |
|---|---|
| Neo4j와 GraphRAG로 떠나는 Machine Learning API 개발 여행 (0) | 2026.05.24 |
| LangChain-Neo4j 파트너 패키지: 공식 지원 GraphRAG, 이제 시작하세요! (1) | 2026.05.23 |
| LangChain-Neo4j 파트너 패키지: 공식 지원 GraphRAG, 이제 시작하세요! (0) | 2026.05.23 |
| LangChain 라이브러리, Neo4j 벡터 인덱스 완벽 지원 추가 (0) | 2026.05.23 |