
만약 LLM(Large Language Model)이 자체 지식 외에도 검색을 통해 더 넓은 세상의 정보를 가져올 수 있다면, LLM 기반 애플리케이션을 만들 때 훨씬 더 다양한 옵션을 활용할 수 있겠죠. 외부 소스에서 데이터를 검색하는 이 기술을 Retrieval-Augmented Generation(RAG)이라고 불러요.
RAG 애플리케이션은 LLM 기반 애플리케이션 개발을 위한 대표적인 프레임워크인 LangChain을 사용해서 구축할 수 있어요. LangChain은 대부분의 LLM 제공업체와 데이터베이스를 통합 인터페이스에 통합해서 개발 과정을 단순화해주죠. LangChain 라이브러리의 Neo4j vector index를 사용하면, 개발자는 Vector Embedding을 효율적으로 저장하고 검색하기 위한 고급 vector indexing을 쉽게 구현할 수 있답니다.
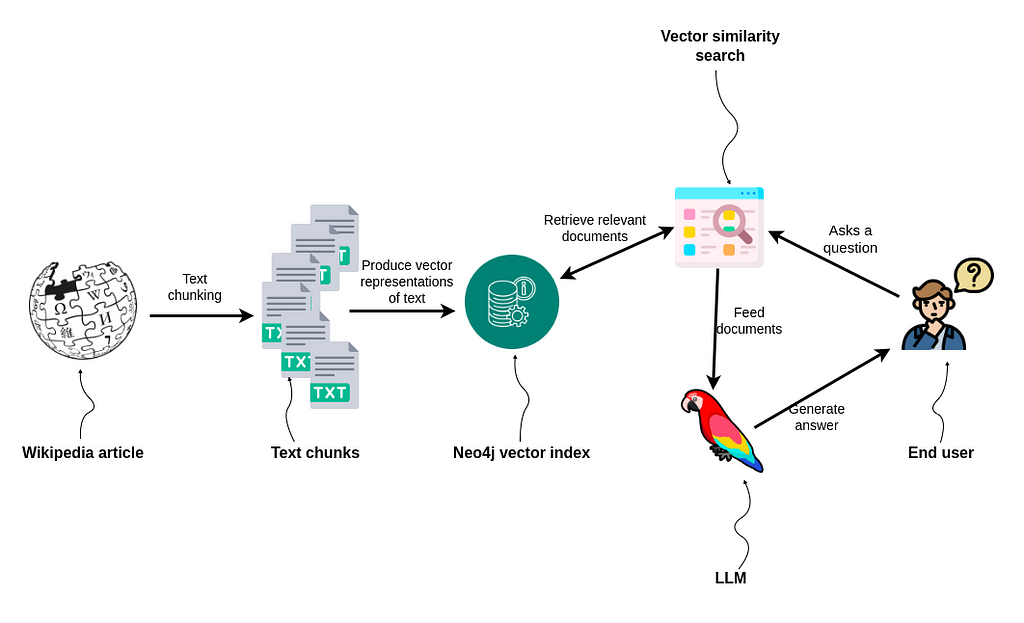
이번 블로그 포스팅에서는 LangChain과 Neo4j vector index를 사용해서 Wikipedia 기사 정보를 기반으로 질문에 효과적으로 답변할 수 있는 간단한 RAG 애플리케이션을 구축하는 방법을 보여드릴게요. 다음 단계를 함께 살펴볼까요?
-
- Wikipedia 기사를 읽고 Chunking하기
- Neo4j를 사용해서 텍스트를 저장하고 Indexing하기
- Vector Similarity Search 수행하기
- 질의 응답 워크플로우 구현하기
언제나처럼, 코드는 에서 확인하실 수 있어요.
Neo4j 환경 설정
이 블로그 포스팅의 예제를 따라 하시려면 Neo4j 5.11 이상을 설정해야 해요. 가장 쉬운 방법은 Neo4j AuraDB에서 무료 인스턴스를 시작하는 건데요, Neo4j 데이터베이스의 클라우드 인스턴스를 제공해준답니다. 아니면 Neo4j Desktop을 다운로드해서 로컬 Neo4j 데이터베이스를 설정하고 애플리케이션을 생성해서 로컬 데이터베이스 인스턴스를 만들 수도 있어요.
1. Wikipedia 기사 읽기 및 Chunking
먼저 Wikipedia 기사를 읽고 Chunk로 나누는 것부터 시작해볼게요. LangChain이 Wikipedia 문서 로더와 텍스트 Chunking 모듈을 통합했기 때문에 과정은 아주 간단해요.
from langchain.document_loaders import WikipediaLoader
from langchain.text_splitter import CharacterTextSplitter
# Read the wikipedia article
raw_documents = WikipediaLoader(query="Leonhard Euler").load()
# Define chunking strategy
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1000, chunk_overlap=20
)
# Chunk the document
documents = text_splitter.split_documents(raw_documents)
# Remove summary from metadata
for d in documents:
del d.metadata['summary']Neo4j는 Graph Database이니까, 그래프 이론의 아버지인 Leonhard Euler에 대한 Wikipedia 기사를 사용하는 게 딱 어울리겠죠?
다음으로, OpenAI에서 만든 토크나이저인 을 사용해서 기사를 Chunk로 분할하는 텍스트 Chunking 모듈을 사용할 건데요, Chunk 크기는 *1000* 토큰으로 설정할 거예요. 이 글에서 텍스트 Chunking 전략에 대해 더 자세히 알아볼 수 있어요.
LangChain의 WikipediaLoader는 기본적으로 각 Chunk에 요약을 추가하는데, 저는 추가된 요약이 약간 중복된다고 생각했어요. Vector Similarity Search를 사용해서 상위 3개 결과를 검색하면 요약이 세 번 반복되니까요. 그래서 데이터세트에서 요약을 제거하기로 결정했답니다.
2. Neo4j로 텍스트 저장 및 Indexing
Neo4j vector index는 LangChain vector store로 래핑되어 있어요. 그래서 다른 벡터 데이터베이스와 상호 작용하는 데 사용되는 구문을 그대로 사용할 수 있답니다.
from langchain.vectorstores import Neo4jVector from langchain.embeddings.openai import OpenAIEmbeddings # Neo4j Aura credentials url="neo4j+s://.databases.neo4j.io" username="neo4j" password="<insert password>" # Instantiate Neo4j vector from documents neo4j_vector = Neo4jVector.from_documents( documents, OpenAIEmbeddings(), url=url, username=username, password=password )
from_documents 메서드는 Neo4j 데이터베이스에 연결해서 문서를 가져오고, 임베딩하고, Vector Index를 생성해요. 데이터는 기본적으로 청크 Node로 표현되죠. 앞서 말씀드린 것처럼 데이터를 저장하는 방법과 반환할 데이터를 사용자 정의할 수 있어요.
데이터가 채워진 기존 Vector Index가 이미 있다면 from_existing_index 메서드를 사용할 수 있어요.
3. 벡터 유사성 검색 수행
모든 게 의도한 대로 작동하는지 확인하기 위해 간단한 벡터 유사성 검색부터 시작해볼게요.
query = "Where did Euler grow up?"
results = neo4j_vector.similarity_search(query, k=1)
print(results[0].page_content)
LangChain 모듈은 지정된 임베딩 기능(이 예에서는 OpenAI)을 사용해서 질문을 임베딩한 다음, 사용자 질문과 인덱싱된 문서 간의 코사인 유사성을 비교해서 가장 유사한 문서를 찾아요.
Neo4j Vector Index는 코사인 유사성과 함께 유클리드 유사성 메트릭도 지원한답니다.
4. 질의 응답 워크플로 구현
LangChain은 한두 줄의 코드만으로 질문 답변 워크플로를 지원해요. 예를 들어, 다음 코드를 사용해서 주어진 컨텍스트를 기반으로 답변을 생성하고 소스 문서를 제공하는 질문 답변 워크플로를 만들 수 있어요.
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQAWithSourcesChain
chain = RetrievalQAWithSourcesChain.from_chain_type(
ChatOpenAI(temperature=0),
chain_type="stuff",
retriever=neo4j_vector.as_retriever()
)
query = "What is Euler credited for popularizing?"
chain(
{"question": query},
return_only_outputs=True,
)
보시다시피 LLM은 Wikipedia 기사를 기반으로 정확한 답변을 구성하고 사용한 소스를 반환했는데, 코드 한 줄만 필요했다니 정말 놀랍죠?
코드를 테스트하는 동안 소스가 항상 반환되지 않는 것을 발견했어요. 여기서 문제는 Neo4j 벡터 구현이 아니라 GPT-3.5-turbo라는 점이에요. 때로는 원본 문서를 반환하라는 지시를 듣지 않더라구요. 하지만 GPT-4를 사용하면 문제가 사라진답니다.
마지막으로 ChatGPT 인터페이스를 복제하려면 메모리 모듈을 사용하면 돼요. 후속 질문을 할 수 있도록 LLM에 대화 기록을 제공하는 거죠. 단 두 줄의 코드만 필요해요:
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
qa = ConversationalRetrievalChain.from_llm(
ChatOpenAI(temperature=0), neo4j_vector.as_retriever(), memory=memory)이제 테스트해 보겠습니다.
print(qa({"question": "What is Euler credited for popularizing?"})["answer"])
이제 후속 질문이에요.
print(qa({"question": "Where did he grow up?"})["answer"])
간편해진 RAG 애플리케이션 구축
LangChain 통합은 Neo4j의 Vector Index를 기존 또는 새로운 Vector Index에 통합하는 과정을 간단하게 만들어줘요. RAG 애플리케이션에 딱 맞는 기능이라, 더 자세한 설명은 필요 없겠죠?
LangChain은 이미 Cypher 구문 생성을 지원하고 있어요. 생성된 Cypher를 사용해서 컨텍스트를 검색하는 거죠. 이걸 활용하면 구조화된 정보와 구조화되지 않은 정보를 모두 검색할 수 있다는 사실!
더욱 스마트한 LLM 애플리케이션을 구축하기 위해 Knowledge Graph를 사용하는 방법에 대해 더 자세히 알고 싶다면, 이 블로그 시리즈의 다른 게시물들도 한번 확인해 보세요.
-
- Neo4j로 Large Language Model 활용하기
- Knowledge Graph 및 LLM: Multi-Hop 질문 답변
- 구조화되지 않은 텍스트에서 Knowledge Graph 구성하기
- Knowledge Graph를 사용하여 RAG 애플리케이션 구현하기
- ChatGPT
- LangChain
- LangChain 라이브러리
- Neo4j Vector Index
- RAG
- Vector Index
- 위키피디아
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'GraphRAG' 카테고리의 다른 글
| LangChain-Neo4j 파트너 패키지: 공식 지원 GraphRAG, 이제 시작하세요! (1) | 2026.05.23 |
|---|---|
| LangChain-Neo4j 파트너 패키지: 공식 지원 GraphRAG, 이제 시작하세요! (0) | 2026.05.23 |
| Python으로 Neo4j GraphRAG 지식 그래프 구축하기 (0) | 2026.05.22 |
| LLM 기반 지식 정합성을 위한 선택: Knowledge Graph vs. Vector Database (1) | 2026.05.22 |
| 지식 그래프 vs 벡터 RAG: 벤치마킹, 최적화, 그리고 금융 분석 예시 (0) | 2026.05.22 |