
베를린에서 샌프란시스코까지
같은 날, 베를린과 샌프란시스코에 있는 두 기술 커뮤니티가 모여 동일한 아키텍처 질문, 즉 에이전트 AI 시스템을 위한 메모리를 어떻게 설계해야 하는지에 대해 논의했어요.
베를린에서는 AI Memory와 Founders Night가 생산 AI 시스템을 연구하는 창립자, 엔지니어, 건축가를 한자리에 모았죠. 동시에 샌프란시스코에서 열린 첫 번째 컨텍스트 그래프 모임에서는 새롭게 떠오르는 아키텍처 패턴으로서의 컨텍스트 그래프를 탐구하는 연구원과 실무자가 모였답니다. 화자, 도시, 형식은 달랐지만 결론은 놀라울 정도로 일치했어요.


컨텍스트 그래프란 무엇일까요?
샌프란시스코 모임은 Will Lyon이 작업 정의를 설정하면서 시작되었어요. 컨텍스트 그래프는 쿼리 가능한 단일 구조의 엔터티, 정책 및 선례에 연결된 의사 결정 추적과 함께 조직 전체에서 의사 결정을 내리는 데 필요한 모든 정보를 포함하는 Knowledge Graph라는 거죠.
Jessica Talisman은 업계에서 현재 컨텍스트 그래프라고 부르는 것은 전통적으로 지식 관리에서 절차적 지식으로 알려져 왔으며, 컨텍스트 자체의 개념(사물 간의 관계에서 파생된 의미)이 바로 그래프가 항상 표현하기 위해 구축된 것임을 분명히 밝혔어요.
Yann Biliien는 Knowledge Graph와 행동 및 프로세스 그래프라는 두 그래프의 합으로 컨텍스트 그래프를 설명했어요.
Dave Bennett는 이를 차원의 문제로 구성했는데요. Knowledge Graph는 상위 집합이고 컨텍스트 그래프는 의사 결정 추적, 출처 및 시간적 타당성이라는 단순한 3가지 차원을 넘어 추가적인 차원을 추가한다는 거죠.
Emil Eifrem은 실용적인 프레임을 제공했는데요. 도메인 데이터를 가져와 그래프 형식으로 모델링하고 해당 Knowledge Graph 위에 결정 추적을 연결하면 이것이 컨텍스트 그래프라는 거예요.


베를린 논의에서는 다른 각도에서 비슷한 실무 정의에 도달했어요. 베를린 실무자들은 패턴이 수행해야 하는 작업에 대해 더 자세히 살펴봤는데, 바로 명시적 연결 유지였죠. `Vector Embedding`만으로는 엔터티 소유권, 계층 구조, 종속성, 시간적 순서 사이의 연결을 인코딩할 수 없으니까요.
두 커뮤니티 모두 같은 결론에 도달한 거죠. `Context Graph`의 가치는 구조화된 도메인 지식을 쿼리 가능하고, 탐색 가능하며, 감사 가능한 형식으로 의사 결정 과정 기록에 연결하는 데 있다는 거예요.
AI 메모리가 중심으로 이동하는 이유
지난 한 해 동안 많은 AI 애플리케이션이 `Retrieval-Augmented Generation`에만 의존해 왔어요. `Vector Search`는 의미상 유사한 콘텐츠를 검색하는 데 효과적이지만, 엔터티 간의 구조화된 관계를 유지하지는 못하죠.
시스템이 더욱 능동적으로 계획을 세우고, 여러 도구를 사용하고, 다단계 작업을 조정할 수 있게 되면서 베를린과 샌프란시스코 팀은 세션 전반에 걸쳐 지속되지 않는 메모리, 명시적이 아닌 암시적인 엔터티 간의 관계, 검사하거나 감사할 수 없는 추론 체인 등 동일한 반복적 제한에 직면했다고 설명했어요.
여러 참석자가 강조했는데, Andreas Kollegger의 세션(Neo4j)에서 `Context Graph`를 특히 명확하게 설명했죠. `Vector Search`는 `Semantic Search`에 여전히 효과적이지만, `Context Graph`는 항목 간의 관계를 명시적으로 만들어 에이전트가 워크플로, 시스템, 진화하는 컨텍스트 전반에 걸쳐 추론할 수 있도록 해줘요.


Emil Eifrem은 샌프란시스코 패널에서 구조적 격차를 명확하게 설명했어요. 에이전트가 프로덕션에서 유용하려면 네 가지가 필요하죠. 기록 시스템에 대한 액세스, 데이터 플랫폼에 대한 액세스, 대화 및 세션 상태를 위한 에이전트 메모리, 그리고 최근까지 명확한 이름이 부족했던 네 번째 부분은 조직이 실제로 운영되는 방식을 인코딩하는 결정 추적 및 제도적 지식이에요.
Lyon도 이 점을 강조했을 텐데요. 2025년 비즈니스 분야의 AI 현황, MIT에서 수행한 보고서에 따르면 AI 프로젝트의 95%가 가치를 제공하지 못하며, 근본 원인은 에이전트가 올바른 컨텍스트에 액세스하지 못하는 것이라고 해요.


이것은 지식 관리 문제
샌프란시스코 정기 모임에서 제기된 가장 실질적인 과제는 패널 토론을 통해 공감을 얻었는데, `Context Graph`를 작성하는 것은 주로 엔지니어링 문제가 아니라는 점이었어요.
그것은 지식 관리 문제에요. Jessica Talisman은 절차적 지식 온톨로지에 대한 Sephrial 그룹의 동료 검토 연구를 바탕으로 Siemens, Belco 및 Bosch의 배포 사례를 직접적으로 인용했죠. 의사 결정 추적은 데이터가 아니라 지식이며, 이를 캡처하려면 대부분의 엔지니어링 팀이 적용하지 않는 지식 추출, 공식 인코딩 및 온톨로지 분야가 필요해요.
그녀의 처방은 실용적이었어요. 지속성 계층 이전에 지식 모델을 구축하고, 인간과 관련된 추출 인프라에 투자하고, 단순한 실행 추적이 아닌 지식 캡처를 주요 목표로 취급하는 것이죠.
최종 패널은 이 점을 광범위하게 강조했어요. 대부분의 `Context Graph` 이니셔티브가 기본 작업을 수행하지 않고 실행 추적을 캡처하는 운영 계층으로 바로 이동하는 이유는 지식 관리가 실제로 어렵고 역사적으로 조직 전반에 걸쳐 투자가 부족했기 때문이에요. 그렇다면 우리가 올바르게 하면 어떤 모습일까요?
프로덕션에서 `Context Graph` 구축
Yann Bilien(Rippletide)은 모순이 추론 시간이 아닌 빌드 시간에 해결되어야 한다고 강조했어요. 두 데이터 소스가 정책 세부 사항에 동의하지 않는 경우 해당 불일치는 그래프 구성 중에 처리되어야 하며, `Large Language Model`이 런타임에 중재하도록 남겨두지 않아야 해요. 그리고 Dave Bennett(Indykite)는 거버넌스가 처음부터 설계되어야 함을 보여주었죠. 그의 라이브 데모에서는 OAuth 토큰 교환을 사용하여 구축된 전체 위임 체인이 모든 에이전트 작업을 원래 사용자에게 다시 연결하고, 부서 수준 그래프 정책에 따라 한 사용자에 대해서는 동일한 `Query`가 올바르게 차단되고 다른 사용자에게는 허용되는 방법을 보여주었어요.
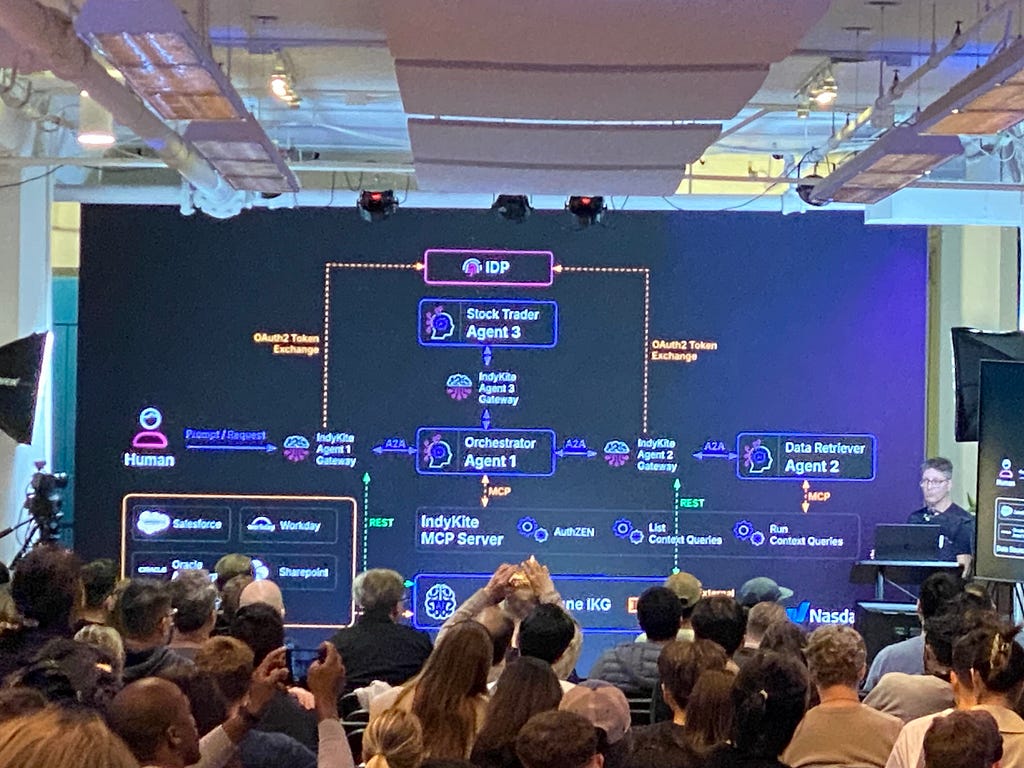

빌드 시간 엄격함과 런타임 거버넌스라는 두 가지 주제는 베를린 실무자들이 프로덕션 시스템의 추적성 및 감사 경로에 대한 질문에 초점을 맞춘 내용을 반영했어요.
베를린 AI Builder 커뮤니티의 통찰력
베를린 이벤트에서 얻은 가장 귀중한 통찰력 중 상당수는 빌더들이 현재 에이전트 시스템을 위한 메모리 레이어를 설계하는 방법을 비교하는 세션 간 토론에서 나타났어요.
생태계 관점에서 보면, AI 개발이 가속화됨에 따라 오늘날 팀이 내리는 아키텍처 선택은 배포하는 시스템의 안정성과 신뢰성을 형성할 거예요.

에이전트 AI의 운영 현실에 대한 대화도 있었는데요. 시스템이 점차 자율화될 때 에이전트 생성 코드를 안전하게 실행하고 제어를 유지하는 방법에 대한 내용이었어요.
메모리 아키텍처를 실용적인 개발자 도구 및 실제 구현 패턴과 연결한 Microsoft Foundry를 사용한 에이전트 구축에 대한 강연도 인상적이었다는 의견이 있었어요.


두 행사에서 눈에 띄는 점은 단순히 두 커뮤니티가 같은 날 비슷한 아이디어를 논의했다는 점만은 아니에요. 세계 각지에서 서로 다른 상황, 서로 다른 문제에 대해 작업하는 독립적인 엔지니어링 커뮤니티가 동일한 아키텍처 결론에 도달하고 있다는 거죠.
새로운 패턴은 점점 더 일관적으로 보이는 것 같아요. 모델은 응답을 생성하고, 에이전트 프레임워크는 워크플로를 조정하고, 구조화된 메모리 계층은 엔터티와 관계를 유지하며, 거버넌스 및 실행 계층은 안전과 재현성을 보장하죠. 이 스택 내에서 컨텍스트 그래프는 메모리 계층의 중심이 되고 있어요.
샌프란시스코 패널에서 나온 Emil Eifrem의 최종 비전은 방향을 잘 포착했는데요. 이상적인 미래는 기관의 지식과 결정 추적을 구조화된 계층으로 인코딩하는 것이 단위 테스트 작성만큼 눈에 띄지 않는 AI 지원 소프트웨어를 구축하는 데 있어 표준 위생이 되는 미래라고 해요.
베를린에서 샌프란시스코까지 방향이 일치하는 걸 보면, 패턴이 수렴되고 있는 것 같아요. 구축을 시작해 볼까요?
연사, 파트너 및 친구들에게 감사드립니다
베를린에서는 AI 메모리와 Founders Night에 Neo4j, Delta Campus, Cognee, Riverty, MemVerge, AWS, Microsoft, Google, Global AI Community 및 Google Developer Group Cloud Berlin 커뮤니티가 한자리에 모여 AI 메모리 및 컨텍스트 그래프를 논의하기 위한 개방적이고 사려 깊은 환경을 조성하는 데 도움을 주었어요.
샌프란시스코에서 Context Graph Meetup은 마찬가지로 열정적인 커뮤니티를 하나로 모았어요. 에이전트 AI 시스템의 핵심 아키텍처 패턴인 컨텍스트 그래프에 대한 최첨단 연구를 공유한 Neo4j, Contextually, Indykite 및 Rippletide의 발표자와 기여자에게 큰 감사를 드려요.
두 이벤트 모두 AI 시스템의 미래를 적극적으로 형성하고 있는 연사, 파트너, 개발자 커뮤니티 간의 놀라운 협력 덕분에 가능했어요.

- AI 메모리
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'GraphRAG' 카테고리의 다른 글
| Cypher 웨비나 후기: Neo4j, GraphRAG 활용 인사이트 (1) | 2026.04.27 |
|---|---|
| 고객 여정, 이제 그래프로 보세요: Neo4j와 GraphRAG 활용법 (1) | 2026.04.26 |
| Novartis의 초기 신약 개발, 점들을 잇다: Neo4j와 GraphRAG의 활약 (2) | 2026.04.26 |
| 헬스케어를 연결하다: Neo4j와 GraphRAG로 혁신을 이루는 방법 (0) | 2026.04.25 |
| 누가 비욘세 점심 메뉴에 관심을 가질까? GraphRAG로 나만의 지식 그래프 구축하기 (1) | 2026.04.25 |