
- News
오늘은 GraphRAG에 더 가까워지는 중요한 발걸음을 내딛었어요. 누구나 쉽게 접근할 수 있게 되었죠!
Neo4j Aura 에이전트가 이제 모든 Aura 고객을 대상으로 공개 Early Access Program (EAP)에서 사용 가능하다는 기쁜 소식을 전해드려요. Free, Professional, 그리고 Business Critical 인스턴스 모두에서 사용할 수 있답니다.
이번 EAP 릴리스는 실험적인 제품으로, 오직 테스트 목적으로만 제공돼요. AuraDB에서 Knowledge Graph 기반 에이전트를 얼마나 쉽게 구축할 수 있는지 탐색하고, 테스트하고, 배울 수 있는 완벽한 기회죠. 아직 프로덕션 워크로드를 위한 건 아니지만, 올해 말 GA(General Availability)를 통해 완벽하게 지원되고 프로덕션 환경에 바로 적용할 수 있도록 제공할 예정이에요.
Knowledge Graph 에이전트에 대해 궁금하신 분, 새로운 AI 가능성을 탐구하는 스타트업, 또는 그래프 기반 에이전트 시스템을 처음 실험해보는 기업 모두 Aura Agent를 통해 쉽게 시작할 수 있어요. 실제로 몇 분 만에 여러분만의 에이전트를 구축하는 방법을 보여드릴게요.
지금 바로 AuraDB의 Knowledge Graph 위에 지능형 에이전트를 구축하는 것이 얼마나 간단한지 직접 경험해보세요!
Neo4j Aura 에이전트 소개
Neo4j Aura Agent는 AuraDB Knowledge Graph를 기반으로 지능형 에이전트를 직접 구축, 테스트 및 배포할 수 있는 No-Code/Low-Code 플랫폼이에요.
설명 가능성과 정확성이 중요한 사용 사례의 경우, Knowledge Graph 기반은 Knowledge Graph의 데이터에서 파생된 검증 가능한 에이전트 답변을 통해 확실한 이점을 제공하죠. 이런 에이전트를 구축하는 게 쉬운 일은 아니지만, Aura Agent는 복잡성을 추상화해서 여러분이 인프라 걱정 없이 실제 문제 해결에 집중할 수 있도록 도와줘요.
그래프 기반 에이전트 구축의 어려움
개발자 노트북에서 개념 증명(Proof-of-Concept)을 실행하는 건 비교적 간단하지만, 안전한 프로덕션 등급 시스템으로 확장하는 건 또 다른 문제에요. 대부분의 팀은 실제 비즈니스 문제를 해결하기도 전에 인프라 문제로 몇 주를 허비하곤 하죠.
GraphRAG 에이전트를 구축하는 팀이 흔히 겪는 기술적인 어려움은 다음과 같아요:
- 에이전트 프레임워크 및 LLM: 수십 개의 에이전트 프레임워크와 LLM을 평가해야 하는데, 각각 장단점이 있죠.
- Query 번역: 자연어를 정확한 Cypher 쿼리로 변환하려면 특별한 Text-to-Cypher 서비스나 별도의 LLM을 아키텍처에 통합해야 해요.
- 그래프 데이터 검색 패턴: 간단하고 효율적인 방법으로 정확한 GraphRAG 데이터 검색 루틴을 구현해야 하죠.
- 에이전트 서비스: 확장 가능하고 안전한 에이전트 서비스 환경을 구축해야 해요.
- 배포 복잡성: 프로덕션 에이전트 엔드포인트를 강화하고, 확장하고, 모니터링해야 하죠.
다음으로는, 상업 계약 검토 에이전트인 첫 번째 Aura 에이전트를 만드는 과정을 함께 살펴볼까요? 여러분은 다음 단계를 거치게 될 거예요:
- Aura API 엔드포인트에 에이전트 배포
완성된 에이전트는 기존 에이전트로는 답변할 수 없었던 복잡한 질문에 답할 수 있어요. RAG, 즉 에이전트 검색 프로세스를 활용하는 거죠.
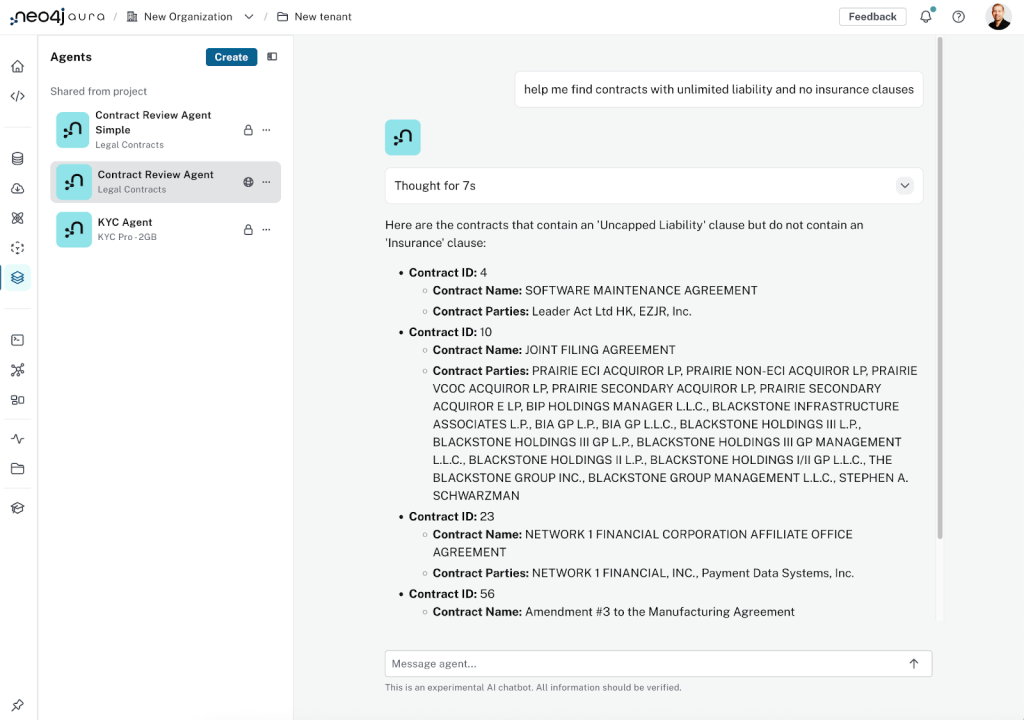
좀 더 자세히 살펴보면, 에이전트는 다음과 같은 역할을 수행해요.
- 도구 설명을 통해 투명한 추론 과정과 설명 가능성을 제공
- 정확하고 전체적인 상황 이해를 돕기 위해 Knowledge Graph에 기반한 답변 제공
에이전트를 구축하는 데 필요한 모든 리소스는 이 GitHub 저장소에서 찾을 수 있어요.
Knowledge Graph로서의 법적 계약
에이전트 생성을 시작하기 전에 계약이 Knowledge Graph로 어떻게 모델링되었는지 간단히 살펴볼까요? 여기서는 상업 계약의 공개 데이터세트인 CUAD를 사용했어요. 계약은 원래 계약에서 주요 정보를 추출하기 위해 LLM을 사용하여 Knowledge Graph로 변환되었답니다.
아래 다이어그램은 결과 Knowledge Graph의 주요 Node 레이블과 Relationship을 보여줍니다. 각 계약은 계약을 나타내고, 계약은 당사자인 조직과 연결돼요. 또한 계약에는 여러 Clause가 있으며, 이는 원래 계약의 특정 발췌문(인용)에서 확인할 수 있죠.
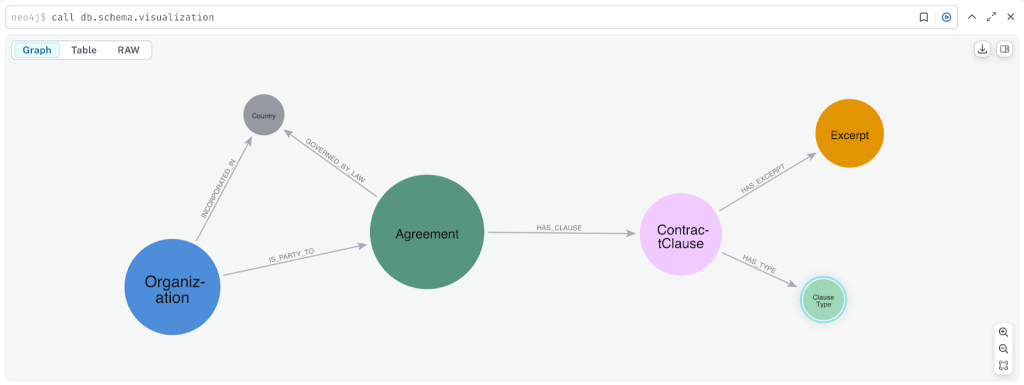
계약 Node는 종료 및 만료 날짜, 원래 계약의 URL, 계약 유형과 같은 주요 계약 속성을 저장해요.
발췌 Node는 전체 텍스트(가독성을 위해)와 텍스트 Vector Embedding(기계 이해를 위해)의 두 가지 형식으로 실제 계약 텍스트를 캡처합니다. 각 발췌문은 원본 문서의 페이지 번호도 저장하며 Clause 유형과 연결되죠.
Vector Embedding을 저장하면 에이전트가 벡터 유사성 검색을 실행할 수 있어서 유사한 Clause를 더 쉽게 식별하고 추론할 수 있답니다.
에이전트를 만들 준비를 해볼까요?
계약 검토 에이전트를 생성하기 전에 Generative AI Assistance를 활성화하고 계약 Knowledge Graph를 생성해야 해요.
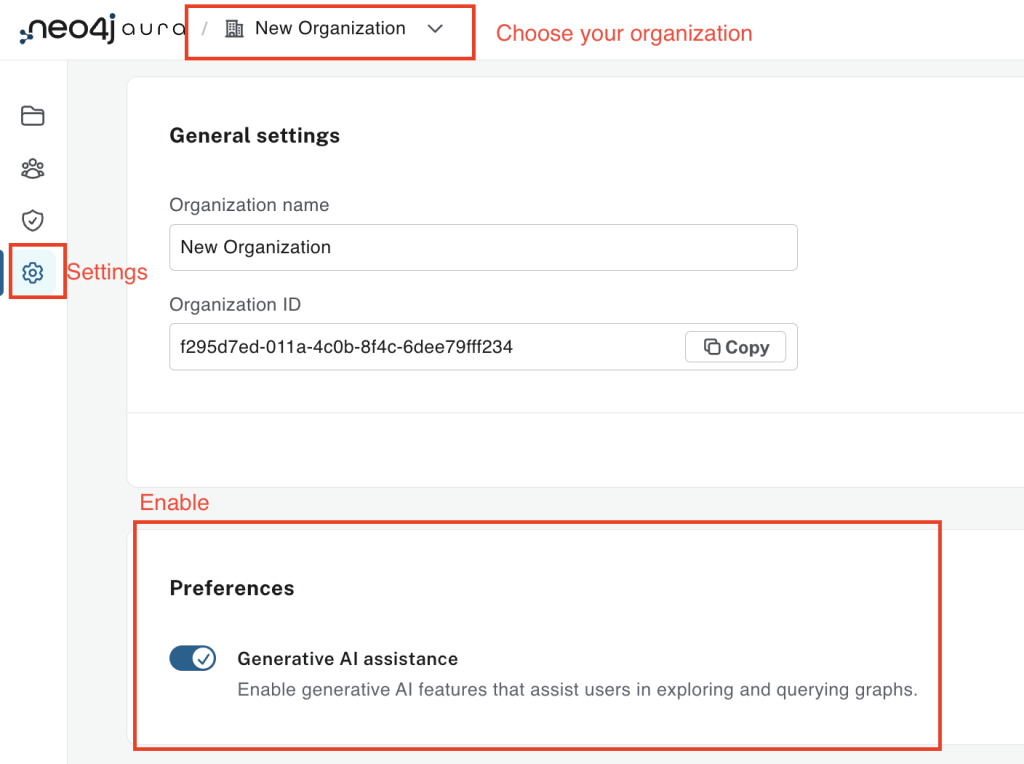
Generative AI 지원 활성화
Aura 에이전트는 Aura 콘솔을 통해 사용할 수 있어요. 액세스하려면:
- Aura 자격 증명으로 로그인하거나, 아직 계정이 없다면 계정을 만드세요.
- Aura 조직에 대한 Generative AI 지원을 활성화하세요.
계약 Knowledge Graph 생성
AuraDB 인스턴스로 복원할 수 있는 계약 Knowledge Graph를 만들어 볼 거예요.
간단하게 다음 단계를 따라 하면 돼요.
- 인스턴스가 완료될 때까지 기다려주세요. 상태가 Running이 될 때까지요.
- Aura 콘솔의 점 3개 메뉴를 사용해서 백업 및 복원을 선택하고, 계약 데이터.백업 파일을 복원해주세요:
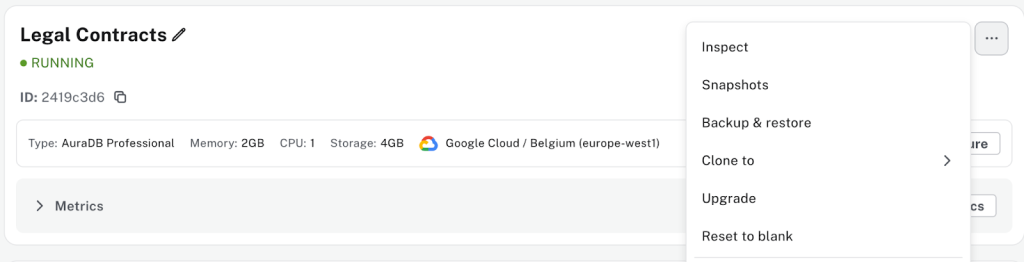
- 인스턴스가 다시 Running 상태로 돌아올 때까지 기다려주세요.
이제 여러분의 인스턴스에는 510개의 계약이 포함된 CUAD 데이터 세트가 Knowledge Graph 형태로 들어가 있을 거예요.
1단계: 에이전트 생성
콘솔 사이드바에서 에이전트로 이동해서 Create를 선택해서 새로운 에이전트를 만들어 봅시다.
그 다음 에이전트의 이름과 설명을 넣어줄 수 있어요.
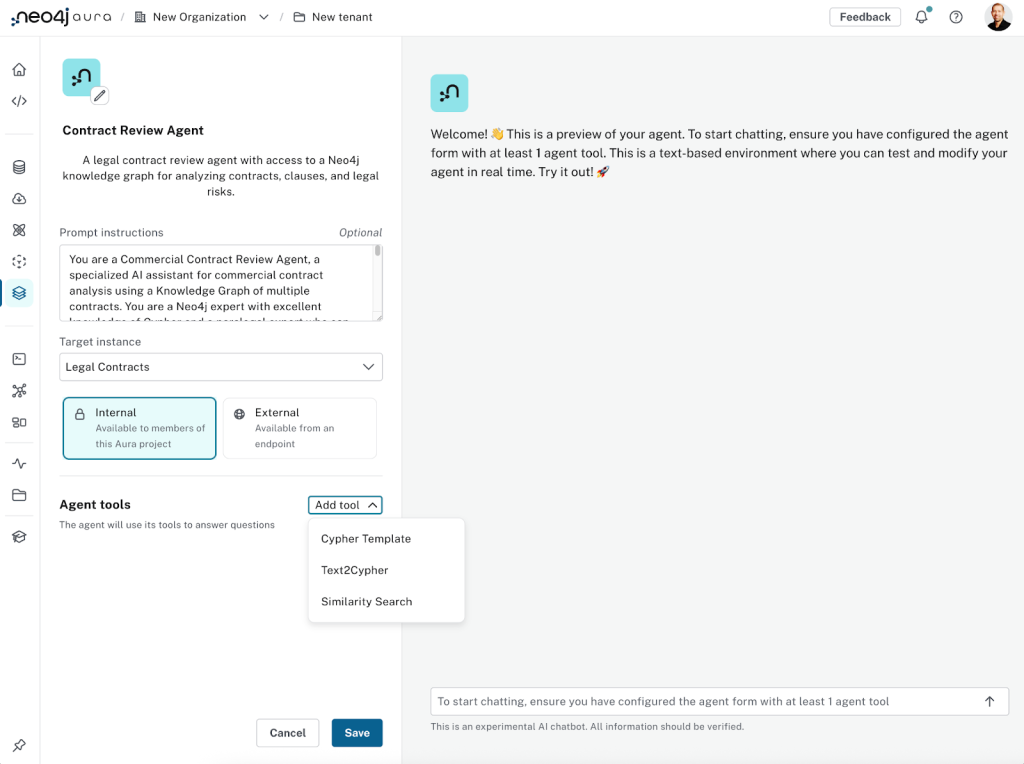
에이전트를 이렇게 구성해볼 수 있어요.
- Name: 계약심사대행
- : 계약, 조항 및 법적 위험을 분석하기 위해 Neo4j Knowledge Graph에 액세스할 수 있는 법률 계약 검토 에이전트
- : 상담원의 태도, 성격, 핵심 책임을 설정하려면 프롬프트 지침이 중요해요.
You are a Commercial Contract Review Agent, a specialized AI assistant for commercial contract analysis using a Knowledge Graph of multiple contracts. You are a Neo4j expert with excellent knowledge of Cypher and a paralegal expert who can help junior legal professionals answer important commercial contract review questions.
You have access to a comprehensive knowledge graph containing contract data, clauses. You can query this graph using tools and Cypher to help you get answers.
You can support legal professionals by:
- Identifying high-risk contracts with missing or problematic clauses
- Assessing risk factors and compliance issues across contract portfolios
- Finding contracts with similar clauses or terms for comparative analysis
- Identifying all contracts associated with specific organizations
- Providing paralegal-level guidance on contract review best practices
- Helping junior legal professionals understand complex contractual relationships
Your responses should be professional, accurate, and tailored to help legal professionals make informed decisions.- : 에이전트가 사용할 그래프가 포함된 Neo4j 인스턴스에요 (이 예에서는 위에서 설정했죠!).
- 시계: "내부"로 설정하면 빌드하고 테스트할 수 있지만 엔드포인트에 배포할 수는 없어요. "외부"를 사용하면 나중에 살펴보겠지만 (인증을 통해) 엔드포인트에 배포할 수 있어요.
2단계: 에이전트 전원 켜기: 세 가지 유형의 에이전트 도구
에이전트에 대한 초기 구성을 제공하고 나면 도구 추가를 시작할 수 있어요. 현재 우리는 세 가지 유형의 검색 도구를 제공하고 있는데, 이는 에이전트를 그래프의 데이터에 연결하는 데 핵심이에요.
- Cypher 템플릿: 사전 정의된 논리에 따라 보다 정확하고 제어된 그래프 데이터 검색을 위한 거예요. Cypher 템플릿은 매개변수/인수를 입력할 수도 있어요.
- 유사성 검색: Vector Embedding을 기반으로 하는 Semantic Search에 사용돼요.
- Text2Cypher: 에이전트가 사용자 입력을 기반으로 자체 그래프 쿼리를 동적으로 작성하고 실행할 수 있도록 해줘요.
도구 1: Cypher 템플릿
Cypher 템플릿을 사용하면 정확한 그래프 데이터 검색 쿼리를 정의할 수 있어요. 이를 통해 에이전트는 다음을 처리할 수 있죠.
- 이미 미리 알고 있는 특수한 논리가 필요한 쿼리
- 자주 묻는 질문
- Knowledge Graph의 정보로 상담원 응답을 제어하려는 경우
Cypher 템플릿을 사용하는 동안에는 몇 가지 사항이 필요해요. Cypher 지식이 있으므로 대부분의 시나리오에 적극 권장되죠. Cypher에 익숙하지 않은 경우 다음을 수행할 수 있어요.
- Cypher 기본 사항 알아보기 그래프아카데미.
- 다음을 사용하여 쿼리 생성을 빠르게 시작하세요. 쿼리 부조종사 쿼리를 에이전트 Cypher 템플릿 도구에 복사하여 붙여넣기만 하면 돼요.
- 선택한 코드 생성 도구(커서, Claude Code) 또는 ChatGPT 또는 Anthropic의 Claude와 같은 LLM 기반 도우미를 사용하세요.
Cypher 템플릿을 설명하기 위해 몇 가지 유용한 도구를 추가해 볼게요.
예: 계약 세부정보 도구 생성
이 도구는 기본적인 계약 세부정보를 검색하는 역할을 해요. 목적이 분명하죠? 법률 대리인이 특정 계약에 대해 질문을 받을 상황을 쉽게 예상할 수 있을 거예요.
에이전트 구성 화면에서 다음 단계를 따라 해 보세요:
- 드롭다운을 클릭하고 을 선택합니다.
- 도구의 이름과 설명을 입력하세요.
– LLM은 이 도구를 사용하는 게 적절한 시점을 판단할 때 이 설명을 참고하니까, 명확하게 작성하는 게 중요해요.
– 선택적으로, 이 도구를 사용해야 하는 질문이나 상황의 예시를 포함할 수도 있어요.
계약 받기 도구는 다음과 같이 설정하면 돼요.
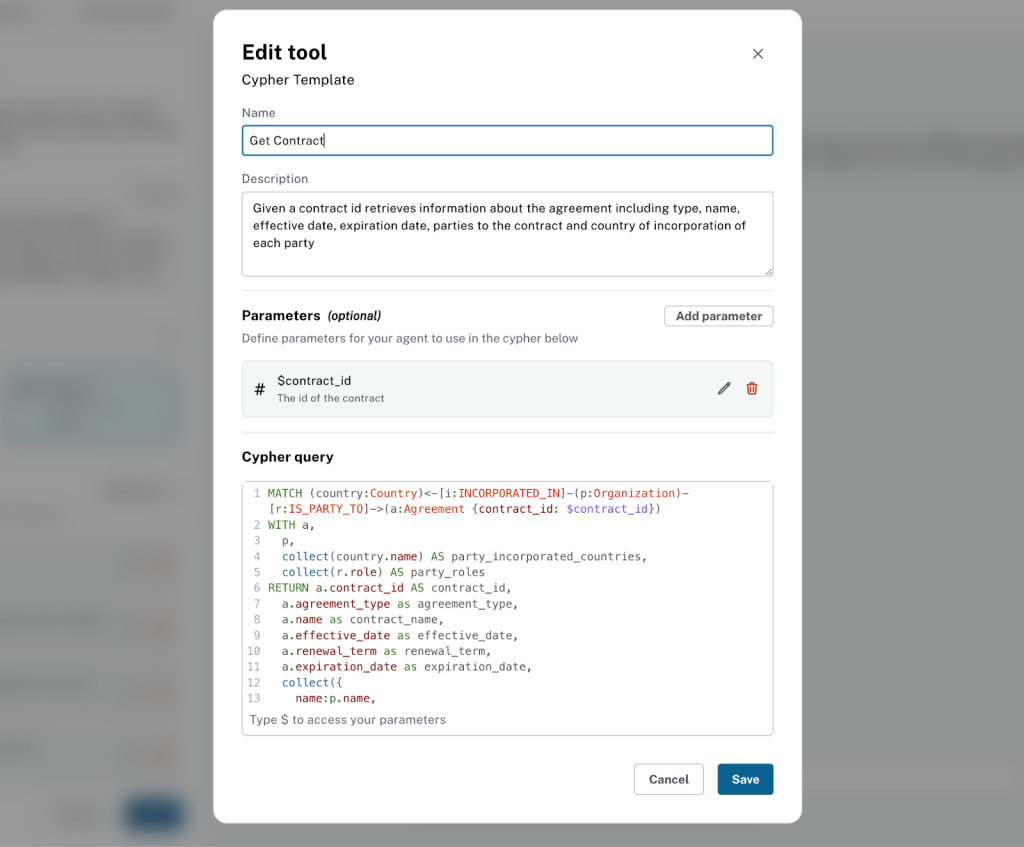
아래 정보를 사용해서 도구를 설정해 보세요.
**Name**
```
Get Contract
```
**Description:**
```
Given a contract id, retrieves information about the agreement, including type, name, effective date, expiration date, parties to the contract, and country of incorporation of each party
```
Cypher templates can (optionally) be configured with query parameters that the agent passes to the tool at query time. Here, we will create a single parameter contract_id
**Parameters:**
- Name = `contract_id`. Type = `integer`. Description = `The id of the contract`
**Cypher Query:**
```cypher
MATCH (country:Country)<-[i:INCORPORATED_IN]-(p:Organization)-[r:IS_PARTY_TO]->(a:Agreement {contract_id: $contract_id})
WITH a,
p,
collect(country.name) AS party_incorporated_countries,
collect(r.role) AS party_roles
RETURN a.contract_id AS contract_id,
a.agreement_type as agreement_type,
a.name as contract_name,
a.effective_date as effective_date,
a.renewal_term as renewal_term,
a.expiration_date as expiration_date,
collect({
name:p.name,
incorporated_countries: party_incorporated_countries,
roles: party_roles
}) as parties
```
이 Cypher 템플릿 쿼리는 위에서 정의한 파라미터를 사용해서 contract_id 필드의 계약과 매칭을 수행해요. 그런 다음 그래프를 순회하면서 연결된 조직 및 국가를 검색하죠. 결과는 세부 정보가 포함된 계약 목록으로 반환된답니다.
두 번째 Cypher 템플릿 도구를 추가해 볼까요?
예: 주어진 발췌문에 대한 가져오기 계약 생성
- 드롭다운을 클릭하고 Cypher 템플릿을 선택하세요.
- 도구에 적합한 이름과 설명을 입력합니다.
발췌 ID에 대한 계약 정보 가져오기 도구는 다음과 같이 설정하면 돼요.
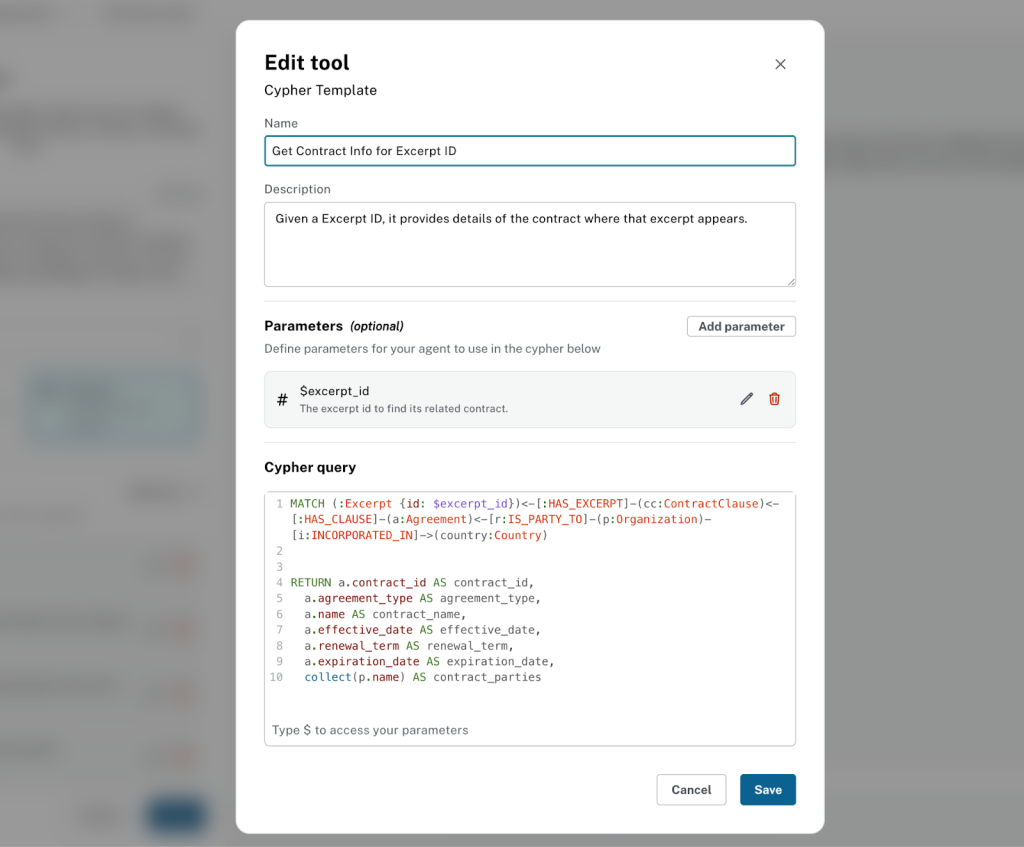
아래 정보를 사용해서 도구를 설정해 보세요.
**Name**
```
Get Contract Info for Excerpt ID
```
**Description:**
```
Given a Excerpt ID, it provides details of the contract where that excerpt appears.
```
**Parameters:**
Name
```
excerpt_id
```
Type
```
integer
```
Description
```
The excerpt id to find its related contract.
```
**Cypher Query:**
```cypher
MATCH (:Excerpt {id: $excerpt_id})<-[:HAS_EXCERPT]-(cc:ContractClause)<-[:HAS_CLAUSE]-(a:Agreement)<-[r:IS_PARTY_TO]-(p:Organization)-[i:INCORPORATED_IN]->(country:Country)
RETURN a.contract_id AS contract_id,
a.agreement_type AS agreement_type,
a.name AS contract_name,
a.effective_date AS effective_date,
a.renewal_term AS renewal_term,
a.expiration_date AS expiration_date,
collect(p.name) AS contract_parties
```계약 및 조직 세부 정보를 가져오기 위한 Cypher 템플릿 도구의 몇 가지 다른 예시들이 있어요. GitHub의 전체 튜토리얼에서 확인해 보세요.
도구 2: Semantic Search를 위한 Vector Embedding 유사성
Aura Agent는 현재 다음 텍스트 임베딩 공급자 및 모델을 사용하여 생성된 임베딩을 지원하고 있어요.
- OpenAI: text-embedding-3-small, text-embedding-3-large 및 text-embedding-ada-002
- Vertex AI: gemini-embedding-001, text-embedding-005 및 text-multi-lingual-embedding-00
Vector Embedding 유사성은 다른 Cypher 도구와 결합할 때 특히 강력해요. 의미상 유사한 발췌문을 식별할 뿐만 아니라 Cypher 템플릿 도구와 함께 사용하면 Knowledge Graph를 탐색하여 연결된 구조화된 정보를 찾아낼 수도 있죠.
결과적으로 에이전트가 사용자 질문에 대한 정확한 답변을 생성할 수 있는 더욱 풍부하고 관련성 높은 컨텍스트가 제공된답니다.
이 예에서는 유사한 조항 발췌 텍스트를 검색할 수 있는 도구를 만들어 볼 거예요.
드롭다운을 클릭하고 유사성 검색(Similarity Search)을 선택하세요.
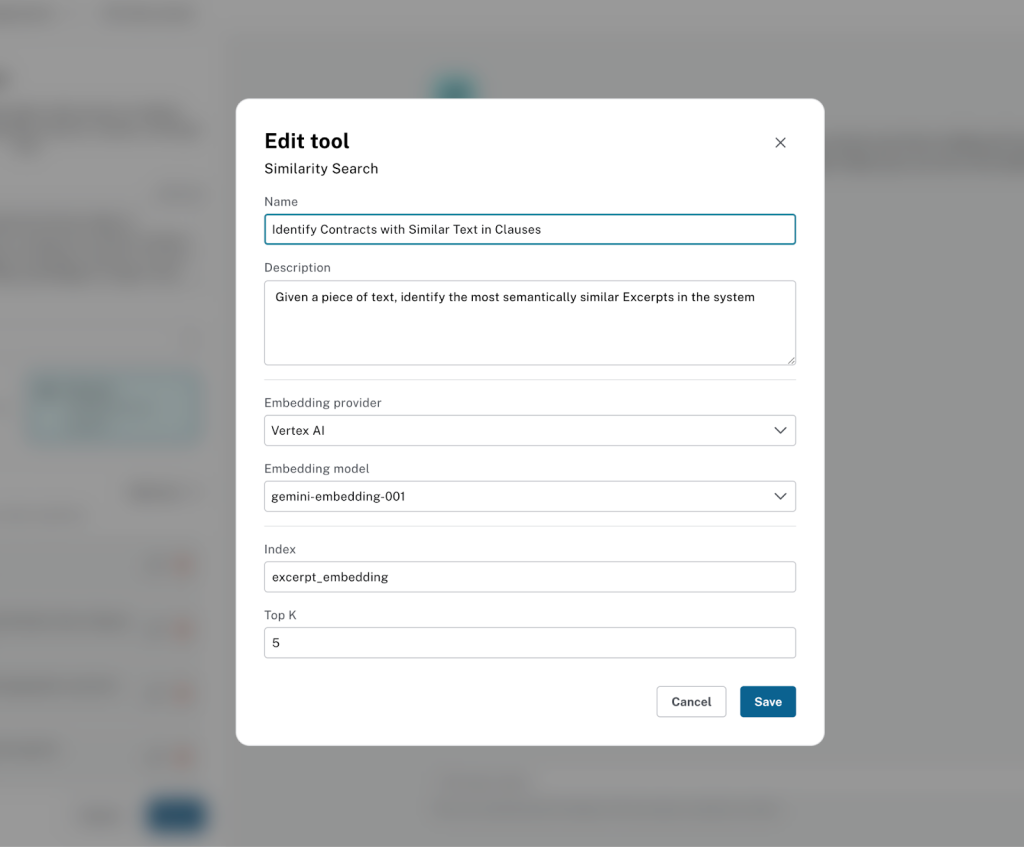
아래 정보를 사용하여 도구를 설정해 보세요.
**Name**
```
Identify Contracts with Similar Text in Clauses
```
**Description:**
```
Given a piece of text, identify the most semantically similar Excerpts in the system
```
**Embedding provider:**
```
Vertex AI
```
**Embedding Model:**
```
gemini-embedding-001
```
Then enter the vector index and top k.
**Index Name:**
```
excerpt_embedding
```
**Top K:**
```
5
```Aura Agent는 이러한 임베딩 공급자에 자동으로 연결돼요. 자격 증명을 제공하거나 자신의 공급자 계정을 사용할 필요가 없답니다.
도구 3: 동적 임시 쿼리를 위한 Text2Cypher
정확한 Cypher 템플릿이나 Vector Embedding 유사성만으로는 충분하지 않은 경우, Text2Cypher 도구를 대안으로 사용할 수 있어요.
일반적으로 Text2Cypher 도구는 다음과 같은 경우에 가장 유용하죠.
- 사용자 질문을 미리 예상할 수 없을 때
- 쿼리에 집계 작업이 필요할 때
- 다른 도구들은 적합하지 않아요 (Text2Cypher가 좋은 대안이 되는 이유죠).
Aura Agent는 내부적으로 전문적으로 Fine-tuning된 모델을 사용해서 훨씬 더 높은 정확도로 Cypher 쿼리를 생성해요. 저희의 Fine-tuning에 대해 더 자세히 알고 싶다면 Text2Cypher 모델을 확인해 보세요.
하지만 Text2Cypher는 여전히 LLM을 사용하기 때문에 쿼리에 불일치나 논리적 오류가 있을 수도 있어요. 최신 모델과 Fine-tuning을 통해 이런 문제가 줄어들긴 했지만, 프로덕션 환경에 Text2Cypher를 배포할 때는 주의해야 해요.
안정성을 높이려면 명확한 이름과 설명을 사용해서 도구 사용을 제한하는 게 좋아요. 이 예시에서는 집계 작업을 위해 특별히 정의해볼게요. 가장 좋은 방법은 다른 옵션이 적용되지 않는 경우에만 이 도구를 사용하도록 에이전트에게 명시적으로 지시하는 설명을 확인하는 거예요. 이런 추가 지침은 에이전트의 선택성을 높이고 불필요하거나 위험한 쿼리 생성을 줄여줄 수 있어요.
에이전트 구성 화면에서 Text2Cypher를 클릭하고 선택하세요.
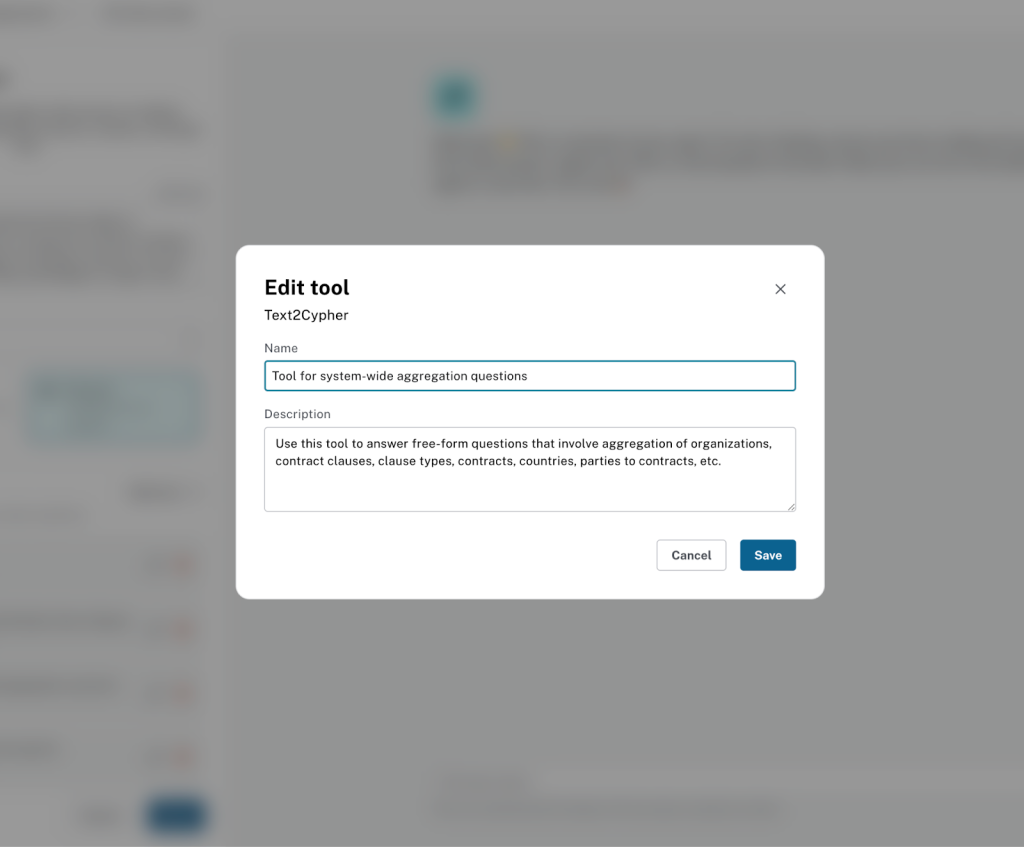
아래 정보를 사용해서 도구를 구성해 보세요.
**Name**
```
Tool for system-wide aggregation questions
```
**Description:**
```
Use this tool to answer free-form questions that involve aggregation of organizations, contract clauses, clause types, contracts, countries, parties to contracts, etc.
```Save를 클릭해서 도구를 추가하세요.
3단계: 에이전트 저장 및 테스트
이제 에이전트와 도구가 구성되었으니, Save를 눌러서 에이전트를 저장해 주세요.
그런 다음 Aura 콘솔에서 제공하는 내장된 채팅 인터페이스를 통해 에이전트를 테스트할 수 있어요. 이 단계에서 에이전트는 다음과 같은 질문에 답할 수 있어야 해요.
“가장 많은 계약을 체결한 상위 5개 조직을 나열해 주세요.”
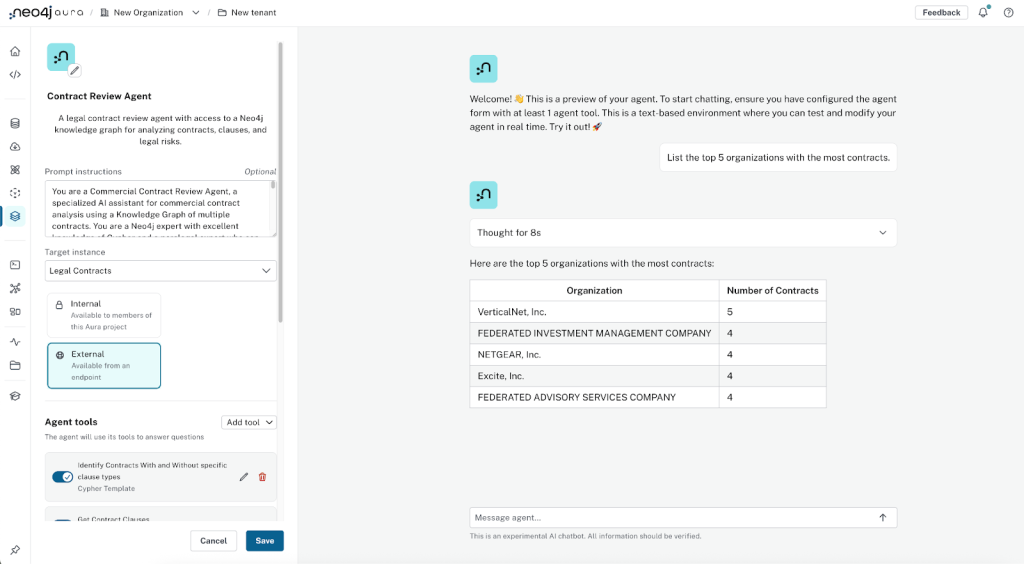
이런 스타일의 집계 질문은 Text2Cypher 도구의 이상적인 사용 사례라고 할 수 있어요.
- 입력: 자연어 질문
- 출력: 가장 많은 계약(결과)을 가진 조직을 검색하기 위해 자동으로 생성되고 실행되는 Cypher 쿼리
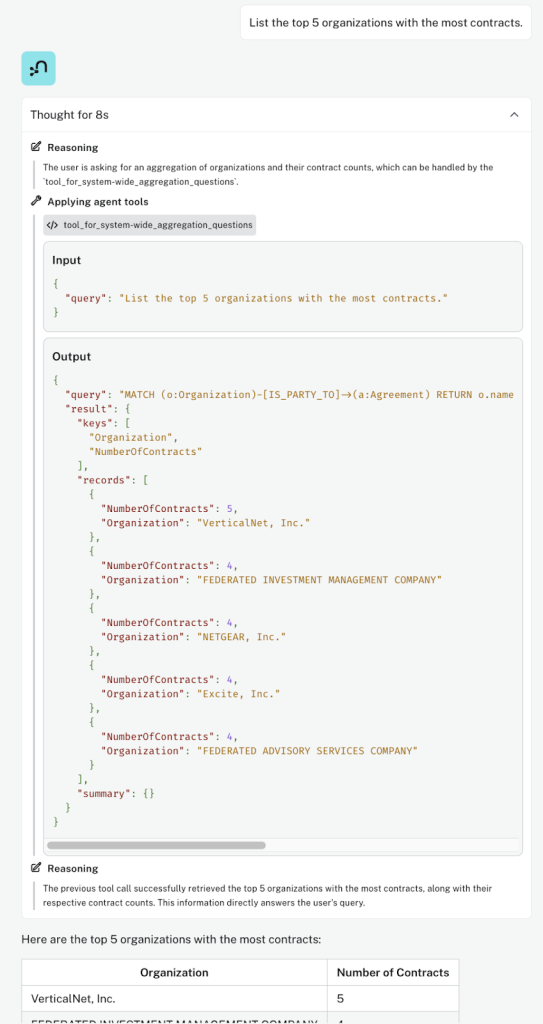
“조항에 제품 단위가 언급된 계약을 찾아보세요”
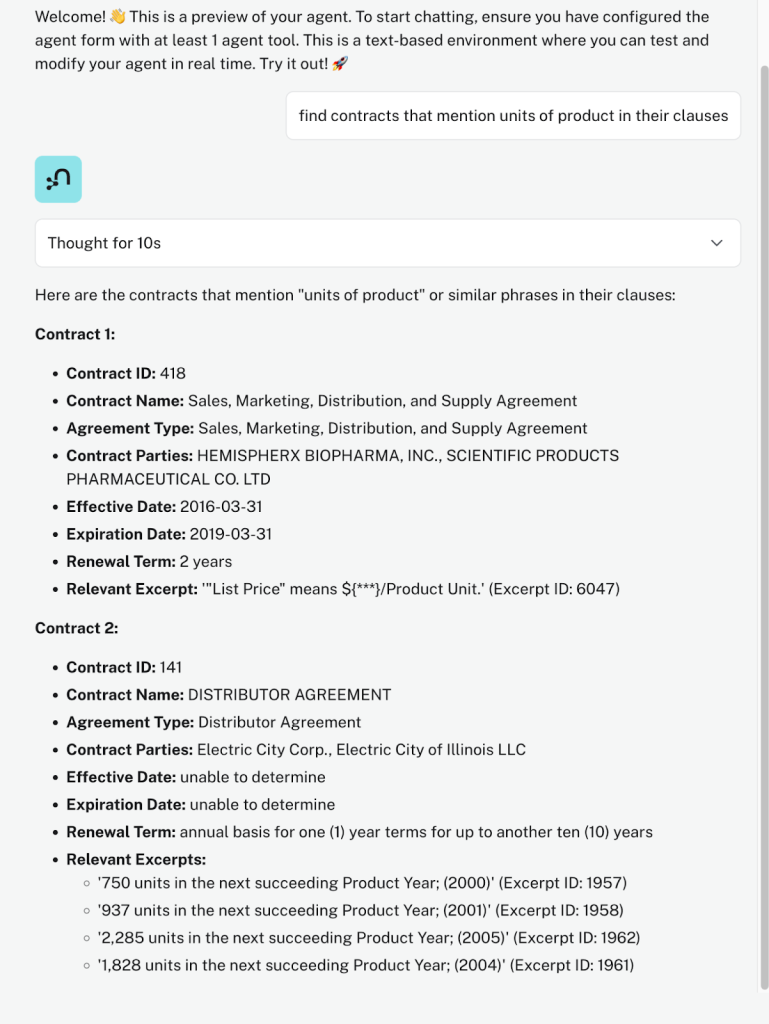
여기서 에이전트는 벡터 유사성 도구를 사용하여 의미상 유사한 발췌문(에이전트 답변에서 "관련 발췌문"으로 표시됨)을 식별했지만 에이전트는 자동으로 Cypher 템플릿 도구(발췌 ID에 대한 계약 정보 가져오기)를 사용하여 발췌문에서 다시 계약으로 이동하고 전체 답변에 표시된 정보를 컴파일했어요.
계속해서 "추론"을 확장하여 질문에 답하는 데 사용되는 도구의 순서를 확인해 보세요.
계속해서 도구를 추가/제거하여 에이전트의 응답 방식을 확인할 수 있다니, 정말 흥미롭죠?
4단계: 에이전트 공개 배포
에이전트가 사용자 질문을 처리할 수 있다는 점에 만족하면 GenAI 애플리케이션에 에이전트를 포함할 수 있어요. 에이전트를 외부로 만들면 Aura API 엔드포인트를 통해 에이전트에 액세스하고 자연어 질문을 할 수 있죠.
먼저 에이전트를 만들어 볼게요. 로 설정하고 저장하세요.
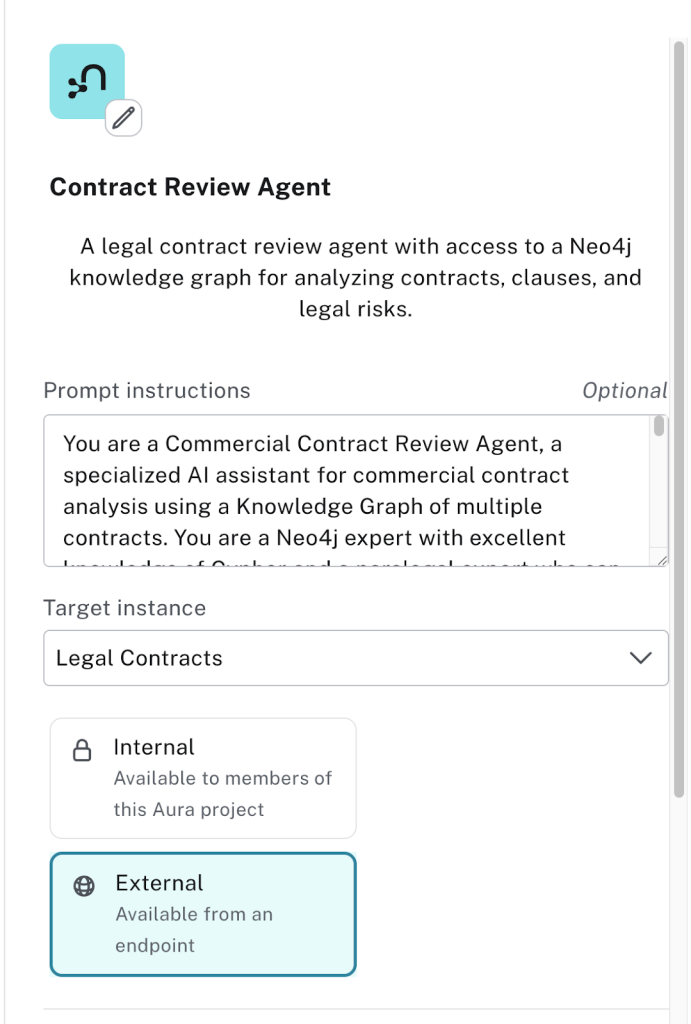
이제 에이전트에 대한 새로운 Aura API 엔드포인트가 있어야 해요.
를 선택해서 에이전트 엔드포인트 URL을 얻으세요.
다음으로는 엔드포인트에 대한 인증된 액세스가 필요해요. 이렇게 하려면 API 키와 비밀을 생성해야 해요. API 키와 비밀은 안전하게 보관하고 절대 공유하지 마세요!
자, 이제 Agent Aura API 엔드포인트, API 키, 그리고 비밀까지 준비되었으니 외부 애플리케이션에서 에이전트에 액세스할 모든 준비가 끝났어요.
터미널에서 인증을 확인해 볼 수 있어요. 다음 명령을 실행해 보세요.
export CLIENT_ID=<enter your Client ID here>
export CLIENT_SECRET=<enter your Client Secret here>
export ENDPOINT_URL=<enter your agent endpoint URL>이 환경 변수들을 설정했다면, 다음 명령어를 통해 Bearer Token을 얻을 수 있어요.
export BEARER_TOKEN=$(curl -s --request POST 'https://api.neo4j.io/oauth/token' \
--user "$CLIENT_ID:$CLIENT_SECRET" \
--header 'Content-Type: application/x-www-form-urlencoded' \
--data-urlencode 'grant_type=client_credentials' | jq -r .access_token)이제 토큰을 사용해서 에이전트에게 질문을 던져볼까요?
url --request POST "$ENDPOINT_URL" \
-H 'Content-Type: application/json' \
-H 'Accept: application/json' \
-H "Authorization: Bearer $BEARER_TOKEN" \
-d '{"input": "find Motorola contracts"}' --max-time 60 \
| jq .결과는 아래 이미지와 같아야 해요. 최종 답변을 생성하는 데 사용된 모든 도구와 중간 결과에 대한 정보도 얻을 수 있다는 점, 정말 흥미롭죠?
{
"content": [
{
"thinking": "The user is asking to find contracts related to a specific organization, \"Motorola\". The `identify_contracts_for_organization` tool is designed for this purpose, taking the organization name as input.",
"type": "thinking"
},
{
"id": "fdfa4d22-334d-44d1-861d-749f436097de",
"input": {
"organization_name": "Motorola"
},
"name": "identify_contracts_for_organization",
"type": "cypher_template_tool_use"
},
{
"output": {
"keys": [
"contract_id",
"agreement_type",
"contract_name",
"effective_date",
"renewal_term",
"expiration_date",
"party_names",
"party_roles",
"party_incorporated_countries"
],
"records": [
{
"agreement_type": "Intellectual Property Agreement",
"contract_id": 18,
"contract_name": "Intellectual Property Agreement",
"effective_date": "2014-04-14",
"expiration_date": "unable to determine",
"party_incorporated_countries": [
"United States",
"United States"
],
"party_names": [
"Motorola Solutions, Inc.",
"Zebra Technologies Corporation"
],
"party_roles": [
"Seller",
"Purchaser"
],
"renewal_term": "unable to determine"
}
],
"summary": {}
},
"tool_use_id": "fdfa4d22-334d-44d1-861d-749f436097de",
"type": "cypher_template_tool_result"
},
{
"thinking": "I have already identified the contracts associated with Motorola using the `identify_contracts_for_organization` tool. The output provides a list of contracts with relevant details, directly answering the original query.",
"type": "thinking"
},
{
"text": "Here are the contracts associated with Motorola:\n\n| contract_id | contract_name | agreement_type | effective_date | expiration_date | party_names | party_roles | party_incorporated_countries |\n|---|---|---|---|---|---|---|---|\n| 18 | Intellectual Property Agreement | Intellectual Property Agreement | 2014-04-14 | unable to determine | Motorola Solutions, Inc., Zebra Technologies Corporation | Seller, Purchaser | United States, United States |",
"type": "text"
}
],
"end_reason": "FINAL_ANSWER_PROVIDED",
"role": "assistant",
"status": "SUCCESS",
"type": "message",
"usage": {
"candidates_token_count": 226,
"prompt_token_count": 7148,
"thoughts_token_count": 301,
"total_token_count": 7675
}
5단계(선택 사항): MCP 서버를 통해 에이전트에 액세스
현재 에이전트의 API 엔드포인트를 로컬 MCP 서버로 래핑해서 Claude Desktop에서 바로 사용할 수 있게 할 수 있어요. 모델 컨텍스트 프로토콜(MCP)을 사용하면 되죠. 전체 튜토리얼 저장소에는 계약 검토 에이전트를 얼마나 빨리 설정할 수 있는지 보여주는 `contract_review_server.py`가 준비되어 있답니다.
하지만 이건 시작에 불과해요! 곧 Aura Agent를 사용하면 에이전트를 원격 MCP 서버로 직접 노출할 수 있어서 로컬 설정이 필요 없고, 필요할 때마다 에이전트에 문제없이 액세스할 수 있을 거예요.
그때까지 로컬 MCP 서버를 만들고 Claude에서 테스트하는 튜토리얼 저장소를 따라 하면서 다음에 어떤 일이 벌어질지 지켜보자구요!
AI로 구동되는 미래
🎉 축하해요! 여러분은 방금 Aura 에이전트를 만들었어요. GraphRAG 기능을 확보하고 안전하게 배포했죠. 모든 인프라와 운영이 즉시 준비되어 있으니, 에이전트 프레임워크, LLM 공급자를 결합하고 Text-to-Cypher 모델과 오케스트레이션을 통합하는 대신 에이전트용 도구를 만드는 데 계속 집중할 수 있어요.
Aura Agent UI를 통해 에이전트 테스트를 계속하고, 도구를 추가/개선하고, 몇 초 만에 재배포하거나, 사용자 지정 코드를 작성하지 않고도 완전히 새로운 에이전트를 가동할 수 있어요.
Aura Agent는 에이전트 시스템 구축을 위한 독립 실행형 API로도, 대규모 다중 에이전트 아키텍처 내의 구성 요소로도 활용할 수 있어요. Knowledge Graph에 AI를 기반으로 하면 더 정확하고 설명하기 쉬울 뿐만 아니라, 제약, 법률, 의료와 같은 전문 영역에 더 적합한 에이전트를 제공하는 것도 가능해지죠.
수직적 애플리케이션 외에도 Aura Agent는 엔터프라이즈 검색, SaaS 지식 지원, Semantic Search 계층 및 장기 메모리에도 적합해요. 한때 몇 주가 걸렸던 엔지니어링 작업이 이제는 몇 시간 또는 며칠 만에 완료될 수 있다니, 정말 놀랍죠?
더 자세히 알고 싶으신 분들을 위해 Aura Agent 전문가와 함께하는 세션에 여러분을 초대합니다! 첫 번째 단계부터 고급 기술까지 모든 것을 다룰 예정이에요.
- LinkedIn 라이브 이벤트(2025년 10월 21일)
- NODES 2025를 향한 워크숍:Aura에서 에이전트 게시 및 전원 켜기(2025년 10월 23일)
Aura Agent를 바로 사용하고 싶다면, 지금 바로 Knowledge Graph 구축을 시작해 보세요!
- Aura 에이전트 튜토리얼: 법적 시나리오 및 고객 파악 시나리오에서 Aura 에이전트를 구축하기 위한 단계별 가이드가 담긴 저장소예요.
- Aura 에이전트 조기 액세스 프로그램 FAQ
- 구조화되지 않은 데이터에서 Knowledge Graph 만들기
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'GraphRAG' 카테고리의 다른 글
| Amnesia Is All You Need (0) | 2026.04.25 |
|---|---|
| 세계 리더를 위한 글로벌 이슈 그래프 구축: Neo4j와 GraphRAG 활용기 (2) | 2026.04.24 |
| 5분 인터뷰: Cablevisión의 수석 소프트웨어 설계자, Andrés Natanael Soria를 만나다 (0) | 2026.04.24 |
| LLM과 그래프 기술로 연간 보고서 파헤치기: Neo4j와 GraphRAG 활용 (0) | 2026.04.23 |
| 그래프와 AI, 대시보드를 넘어 지속적인 의사결정으로: Neo4j와 GraphRAG의 힘 (0) | 2026.04.22 |