
편집자 주: 이 프레젠테이션은 David Bader가 GraphConnect New York 2018년 9월에서 발표한 내용이에요.
프레젠테이션 요약
David Bader는 당시 Georgia Tech의 컴퓨터 과학 및 공학부 의장이었어요. 예측 분석 프레젠테이션에서 그는 자신과 팀이 그래프를 사용해서 어떤 실제 문제와 데이터를 다루고 있는지 간략하게 소개했답니다.
그래프가 어디에 구현되었을까요? 소셜 네트워크, 교통 시스템, 폭풍 대피, 그리고 학술 연구 분야인 과학, 물리학, 화학, 천체 물리학 등 다양한 곳에서 활용되고 있어요. Bader는 특히 분석 및 감시에 그래프가 사용되는 점을 강조했는데요. 그래프가 어떻게 Twitter에서 처음 가치를 발견했는지, 2009년 H1N1 바이러스 대유행 당시 미국 의회 도서관에 전체 트윗 데이터 세트가 게시된 현대까지 이야기가 이어진답니다.
그래프 기술이 아무리 발전했더라도, 다른 시각으로 살펴보는 건 여전히 중요해요. 그래프를 통해 일반적으로는 얻을 수 없는 통찰력을 얻을 수도 있으니까요.
STING은 Georgia Tech의 시공간 상호작용 네트워크 및 그래프 그룹인데요. 현실 세계의 문제 해결을 위해 노력하고 있어요. 국가 안보 문제인 이벤트 보안(Macy's 추수감사절 퍼레이드나 DHS, FBI, NYPD의 지원을 받은 슈퍼볼 등)도 다루죠. STING 데이터베이스는 Neo4j 기반으로 구축되었고, 파트너의 다양한 데이터 세트, 공개 데이터 세트, 신문 기사, 심지어 손으로 쓴 메모까지 결합한답니다.
데이터 연결 예측 그래프 분석은 PageRank 및 Gephi와 협력하여 Neo4j에서 실행되는데, 분석가가 더 많은 데이터를 입력할수록 점점 발전해 나간대요. 그래프는 고정되어 있지 않고, 본질적으로 사용자와 함께 "학습"하는 거죠.
예측 그래프를 통해 Bader는 비슷한 비극을 먼저 겪지 않아도 재앙이 발생하기 전에 예측하는 것을 목표로 하고 있어요. 그래프의 미래는 과거의 행동 패턴을 예측하고, 동시에 새로운 위협을 탐지하는 것이죠.
전체 프레젠테이션
저는 데이비드 베이더이고, 조지아 공과대학 전산 과학 및 공학 의장직을 맡고 있어요. 이렇게 대규모 Knowledge Graph의 예측 분석과 저희가 진행 중인 몇 가지 작업을 를 통해 이야기하게 되어 정말 기쁩니다.
실제 문제와 데이터
조지아 공과대학은 정말 멋진 곳이에요. 저희는 Coda라는 새 건물을 짓고 있는데, 미국 남동부에서 데이터 과학 및 엔지니어링 전용 건물이라고 해요. 저희 학교는 함께 일하는 다른 회사들과 협력해서 그 건물의 핵심을 형성할 거예요.

제 연구 분야는 데이터와 관련된 실제 문제를 해결하려고 노력해 왔어요. 그 과정에서 건강 관리부터 대규모 소셜 네트워크, 폭풍우를 대피시키는 방법과 같은 교통 시스템에 이르기까지 가장 까다롭고 어려운 그래프 분석 문제를 해결하기 위해 노력했죠.
이건 정말 도전적인 응용 분야에요. 저희가 다루고자 하는 인간의 삶에 영향을 미치는 실제 문제가 정말 많거든요. 종종 단일 컴퓨터를 압도하는 데이터 세트가 있어서 밀리초 내에 답변을 얻어야 하는 경우도 있고요. 질문이 뭔지 생각하기도 전에 답을 얻고 싶을 때도 있어요.
몇 가지 샘플 쿼리를 예로 들어볼게요. 특정 커뮤니티의 핵심이 될 수 있는 인구 및 개인 내의 커뮤니티를 이해하려고 시도하는 거죠. 하지만 시간이 지남에 따라 해당 커뮤니티는 다른 커뮤니티의 핵심으로 이동할 수도 있어요. 새로운 정보가 들어오면 이러한 커뮤니티는 시간이 지남에 따라 어떻게 변할까요?
예를 들어, "고객을 잃고 있나요? 그들이 왜 떠나고 있나요?" 와 같은 질문들이요.
저희는 또한 이전에 볼 수 없었던 새로운 패턴을 식별하기 위해 많은 애플리케이션을 개발하고 있어요. 사이버 보안에서는 위협을 다루고 다양한 유형의 공격에 대한 원인을 제공하죠. 그 중 일부는 이전에 볼 수 없었던 것일 수도 있고요.
이를 위해서는 실시간으로 대규모 변화를 예측하고 영향을 미치는 것이 필요해요. 이것이 바로 저희가 하고 있는 연구의 특징이죠. 저는 종종 사람들과 그들의 관계에 대해 쉽게 이야기할 수 있는 소셜 네트워크의 관점에서 사물을 설명해요. 하지만 이 비유를 네트워크 트래픽, 비즈니스 인텔리전스, DNA 등과 관련된 다양한 문제에 적용하는 데 사용한다는 것을 알아주셨으면 좋겠어요.
그래프를 구현하는 위치
그래프는 학술 연구, 과학, 물리학, 화학, 천체물리학 등 제 업무 분야에 정말 널리 퍼져 있어요.

저희는 여기저기서 그래프를 보게 돼요. 그래프 분석가로서 제 임무는 이러한 실제 문제를 해결하고 그래프 추상화를 살펴본 다음, 이러한 문제를 해결하는 데 도움이 되는 알고리즘과 도구를 구축하는 데 도움을 주는 것이죠.
천체 물리학에서 퀘이사를 탐지한 예가 있어요. 시간이 지남에 따라 하늘에 대한 두 개의 디지털 이미지를 갖게 될 수 있는데, 퀘이사가 될 수 있는 변화를 찾고 있는 거죠. 저희는 그걸 매우 빠르게 감지하고 몇 분 안에 망원경을 움직여 천체 사건을 포착하려고 해요. 이 이벤트에서 이미지의 시간적 변화와 그래프 클러스터링 또는 해당 이미지와 신체 간의 일치와 같은 그래프 문제를 살펴볼 수 있어요.
약물 표적 단백질을 식별하려는 생물정보학 문제의 예도 있죠. Betweenness Centrality 또는 기타 Centrality Network 알고리즘을 사용하거나 해당 단백질을 클러스터링하여 중심적인 단백질을 찾는 단백질 상호 작용 네트워크를 가지고 있고요.
사회 정보학의 경우 소셜 네트워크에 있는 개인 간의 최단 경로 또는 조직을 통한 정보 흐름을 살펴볼 수 있어요.
오늘날 이러한 데이터 세트에 대한 법의학 분석에 대한 많은 작업이 수행되고 있어요. 하지만 앞으로는 이러한 데이터 스트림을 활용해서 즉각적으로 결정을 내릴 수 있게 될 거예요.
이것이 실제로 이러한 도전의 모습이에요. 데이터가 점점 더 커지면서 이질성이 커지고 있죠. 저희는 우리가 가지고 있는 데이터의 다양한 품질에 대해 확신을 갖지 못할 때도 있어요. 결국 저희는 비즈니스나 조직을 추진하는 더 나은 결정을 내리고 싶어하는 거고요.
저는 이러한 데이터 분석이 실제로 다음 시대의 회사를 정의할 거라고 생각해요. 조직 내에서, 그리고 다른 사람들을 대하는 방식에서 수익을 창출하고 효율성을 높일 수 있게 될 테니까요. 이 그래프 영역은 정말 세상을 변화시킬 거라고 믿어요.
분석 및 감시용 그래프

공개 이미지 두 개가 있네요. 위쪽 이미지는 9.11 테러 당시 납치범들을 나타내고 있어요. 만약 그 당시에 그래프 분석을 할 수 있었다면, Centrality 같은 알고리즘을 사용해서 납치범, 링 리더, 그리고 비행기의 다양한 셀들을 탐지할 수 있었을 거라는 주장이 있었죠.
아래쪽 이미지는 그래프 분석의 또 다른 예시인데요. 관찰된 정보를 바탕으로 여러분이 알고 있는 패턴이 의심스러운 경우에요. 함께 사는 두 사람이 하는 일을 관찰하는 거죠. 한 명은 트럭을 빌리고, 다른 한 명은 비료를 사요. 뭔가 안 좋은 일을 꾸미고 있을 수도 있겠죠. 여러분이 원하는 건 대규모 데이터 세트 내에서 해당 패턴과 비슷한 다양한 버전을 찾는 거예요. 이걸 하위 그래프 동형현상이라고 하고, 보통 그래프 일치 또는 모티프 찾기라고 부른답니다.
특히 데이터 세트가 점점 더 커지는 상황에서는 정말 어려운 알고리즘 문제라고 할 수 있어요.
Graphs and Twitter
저희는 공개된 트윗 전체를 미국 의회 도서관에 올린 최초의 기업이기도 해요. 10년 전쯤, 2009년 9월과 10월의 트윗을 가져와서 크레이 머신이라는 슈퍼컴퓨터에 넣었죠.

Cray라는 이름을 아는 분들도 계실 텐데요. 저희는 테라바이트급 정보를 연구하기 위해 Pacific Northwest National Lab과 협력했어요. 저희가 알아내려고 했던 건 트위터가 어떤 용도로든 쓸모가 있느냐는 거였어요. 트윗에서 좋은 점을 얻을 수 있을까? 당시에는 확신이 없었죠. 다들 "트윗에서 어떻게 가치를 얻지?"라고 궁금해했으니까요.
저희는 그 기간에 두 가지 이벤트를 겪었어요. 왼쪽에는 H1N1이 보이네요. 2009년에는 이 새로운 바이러스 변종인 H1N1이 전 세계적으로 두 자릿수 사망률을 기록할 거라는 우려가 있었어요. 정말 무서웠고, 사람들은 뭘 해야 할지 몰랐죠. 항공 여행에 대한 패닉도 있었고요. 사람들은 이걸로 엄청난 사망자가 발생할까 봐 두려워했어요.
저희는 모든 트윗을 가져와서 팔로워, 팔로잉, 그리고 콘텐츠의 일부 키워드를 사용해서 그래프를 만들기로 결정했어요. 그리고 해당 그래프에서, 이 이벤트와 관련해서 트위터에서 찾을 수 있는 가장 영향력 있는 핸들이 뭔지 확인하기 위해 Betweenness Centrality를 임시 측정 방법으로 사용했죠.
약 15개의 트위터 핸들을 뽑았는데, 그중 몇몇은 뻔했어요. 여기가 사람들이 바이러스에 대한 정보를 얻는 곳이었거든요.
보시다시피 CDC가 1위네요! 미국 질병 통제 예방 센터죠. 많은 사람들이 정보를 얻기 위해 이곳을 찾을 거라고 예상했을 거예요. 4위는 flu.gov이고, 이 중 두 개는 목록 뒷부분에 나오는 CDC에요. CNN, New York Times, Time Magazine 같은 상업 미디어도 보이는데, 이런 미디어도 사람들이 정보를 얻는 방식에 큰 영향을 미칠 거라고 예상할 수 있죠.
그래프의 힘은 여기서 끝나지 않아요. 속보 이벤트에서 누구의 말을 들어야 할지 어떻게 알 수 있을까요? 정보의 출처와 가장 영향력 있는 사람이 누구인지 어떻게 알 수 있을까요? 그리고 이 목록의 상위 항목 중 하나인 @Official_PAX가 3위에 올라와 있네요.
알고 보니 이곳은 페니 아케이드(Penny Arcade)인 Penny Exchange였어요. 주로 시애틀에서 게임을 하던 청소년 남성 게이머들이었는데, 미국에서 H1N1에 감염된 최초의 그룹 중 하나였죠. 그들은 증상에 대해 서로 트윗하기 시작했어요.
이게 바로 H1N1이 얼마나 치명적인지, 그리고 증상이 무엇인지 이해하는 주요 소스 중 하나였던 거예요. 미리 조정하는 것에 대해선 전혀 생각 못 했을 텐데 말이죠. 라디오 다이얼을 뉴스 소스에 맞추는 것처럼, 그래프의 힘이 바로 이런 거랍니다.
몇 년 전에 인도에서 강연을 하고 있었는데, 한 학생이 백스트리트 보이즈(Backstreet Boys)의 열렬한 팬이었나 봐요. "백스트리트 보이즈가 왜 저기 있죠?"라는 질문을 받았어요. 그래서 "글쎄요, 저도 모르겠네요. 가서 알아봐야겠어요."라고 답했죠.
데이터를 다시 살펴보고 몇 가지 분석을 해봤어요. 그래프가 정보를 제공하는 데 매우 효과적이지만, 데이터 모델을 살펴보고 항상 예외가 있다는 걸 이해해야 하는 경우였죠. 백스트리트 보이즈(Backstreet Boys)가 앨범을 발표했는데, 팬들이 새 앨범과 H1N1에 대해 함께 트윗을 올렸다는 사실이 밝혀졌어요. 정말 흥미로운 크로스오버 현상이었죠!
Double-checks and reality checks
데이터와 실제 문제가 있다면 그래프에서 유용한 정보를 얻을 수 있어요. 하지만 이런 데이터 문제를 다룰 때는 항상 자신이 가진 것을 확인하고 현실 점검을 해야 해요.
저희는 또한 미국 전력망의 탄력성을 분석하는 연구도 진행하고 있어요.

이 그래프는 전력망을 나타내고 있어요.
미국에는 주로 동부 전력망과 서부 전력망이 있죠. 저희는 Pacific Northwest National Labs와 협력해서 그래프 문제로 표현되는 전력망의 탄력성을 조사하고 있어요. 전력망의 단일 장애로 인해 전체 지역에 대규모 정전이 발생할 수 있다는 걸 알고 있거든요.
오른쪽은 저희가 인간 프로테옴을 관찰하면서 작업한 문제인데요. 저희는 Betweenness Centrality 알고리즘을 돌려서 가장 상호작용적이지 않은 단백질을 프로테옴에서 찾았어요. 마치 건초 더미 속의 바늘 같았지만, 어떤 의미에서는 중심성 측면에서 가장 잘 연결되어 있었죠. 가장 높은 중심성을 갖고 있는 것으로 확인된 단백질 중 하나가 유방암과 관련이 있다는 사실을 알아냈답니다.
그래프를 활용하면 일반적으로는 쉽게 얻을 수 없는 통찰력을 얻고, 실제 문제 해결에 도움을 받을 수 있어요.
STING
제 연구실에서는 25년간 STING 프로그램을 진행해 왔어요.

Georgia Tech의 마스코트는 노란 재킷인데요. STING은 Spatio-Temporal Interaction Networks and Graphs의 약자예요. 즉, 시간이 지남에 따라 변하는 그래프로 모델링할 수 있는 실제 문제를 연구하는 거죠. 여기서 Nodes와 Edges는 시공간적 위치, 속성, 타임스탬프 등 다양한 특징을 가질 수 있어요.
저희는 문제 해결을 목표로 하는 DARPA 프로그램을 진행했는데요. Nidal Hasan 소령은 육군 심리학자이자 Fort Hood 사수였어요. 그는 휴가를 받았고, 다른 사람들의 정신 건강을 돌보려고 노력하는 사람이었죠. 그런데 어느 날 갑자기 여러 사람을 총으로 쏴 죽이는 사건이 발생했어요.
시간이 지나면서 변화가 생기고, 심각한 사건이 발생하기 전에 아무런 잘못이 없는 개인이 있을 때, 시스템은 내부 위협을 어떻게 처리해야 할까요? 이런 종류의 문제가 저희가 해결하고자 하는 문제예요. 정보의 양이 엄청나게 많고, 실시간으로 문제를 해결하려면 새로운 알고리즘은 물론이고 새로운 컴퓨터까지 만들어야 할 때도 있죠.
저희는 새로운 컴퓨터 아키텍처 엔지니어링을 지원하고, Intel, Qualcomm, NVIDIA, IBM, Cray 같은 회사와 협력해서 새로운 컴퓨터를 만들었어요. 스마트폰에서 흔히 볼 수 있는 구성 요소들이 있는데, 이런 기술들이 조금씩 발전하고 있는 거죠. 언젠가는 모든 Neo4j 애플리케이션을 스마트폰에서 실행할 수 있게 되기를 바라요.
STING은 Neo4j를 사용하는 분석가들을 위한 솔루션으로 만들어졌어요. 그래프에 수조 개의 엔터티가 있고, 분석가들은 밀리초 단위의 응답 시간을 요구하는 상황까지 가는 거죠. 이 그래프는 엄청난 양의 정보를 쏟아내는 소방 호스와 같아요.

저희는 현재 Neo4j에서 실행할 수 있는 속성을 조사하는 초기 알고리즘을 연구했어요. 예를 들어, 연결된 구성 요소, 최단 경로, 커뮤니티 감지 같은 것들이죠.
그래프가 실시간으로 변할 때, 이런 변화를 어떻게 추적해야 할까요? 고객과 사용자에게 중요한 변경 사항을 어떻게 감지하고, 표시하고, 보고해야 할까요?
이제 국토 안보부를 위해 저희가 하고 있는 문제에 대해 좀 더 자세히 알아볼까요?
국가 안보 문제
분석가가 참고 자료, 각주, 그림이 포함된 여러 페이지 분량의 Natural Language 보고서를 작성하는 현재 진행 중인 작업이 있어요. 그리고 특별 행사를 보호하려는 혐의로 기소된 사건이죠.

예를 들어, 뉴욕시에는 메이시스 데이 퍼레이드가 있고, 전국 각지에서는 슈퍼볼 행사가 열리죠. 저희는 이런 유형의 행사가 안전하게 진행되기를 바라요. 현지 법 집행 기관이 무슨 일이 일어나고 있는지 인지하고, 이런 행사에 참석하는 동안 여러분이 안전하게 지낼 수 있도록 하기 위해 매우 중요한 작업들이 수행되고 있어요.
분석가들은 보고서와 액세스 권한이 있는 공개 데이터 세트 간의 관계를 수동으로 검색하고 재발견해요. 모든 정보는 일반적으로 공개되어 있고, 현지 법 집행 기관, 대중과 공유되고 사용될 수 있다는 점을 말씀드리고 싶어요. 이건 해결해야 할 문제이고, 그래프는 이런 지식을 서로 연결하는 자연스럽고 중요한 구조라고 생각해요.
저희 접근 방식은 국토 안보부가 Knowledge Graph를 구축하도록 돕는 것이었어요.

저희는 이전 보고서, 이벤트, 신문 기사, 다양한 유형의 공격을 수집해서 그래프로 연결하려고 노력했어요. DHS, FBI, NYPD 등과 협력했죠. 스프레드시트, 원시 데이터 세트, 손으로 쓴 메모, 보고서 등을 기반으로 그래프를 구축한 다음, 이걸 Neo4j 인스턴스에 통합했어요.
Knowledge Graph가 생성된 후에는 보고서와 이벤트 간의 관계를 살펴보고 유지 관리해요.

슈퍼볼을 조사하는 분석가는 작년 슈퍼볼이나 지난 10번의 슈퍼볼에서 어떤 위협이 있었는지 파악하기 위해 이전 보고서를 다시 찾아볼 필요가 없어요. 그런 유형의 정보를 연결할 수 있게 되는 거죠. 지역적 위협의 경우에도 마찬가지예요. 분석가는 Knowledge Graph를 사용해서 시간이 지남에 따라 유사한 유형의 이벤트를 찾는 것이 자연스러운 방식으로 정보를 하나로 묶을 수 있어요.
저희는 분석가들이 수행하는 작업에서 더 많은 운영 효율성을 갖도록 돕고 있어요. 그들의 시간은 매우 소중하고, 이 나라의 모든 사람에게 영향을 미치는 매우 중요한 문제를 해결하고 있기 때문에, 저희는 그래프를 통해 그들을 돕기 위해 할 수 있는 모든 일을 하려고 노력하고 있어요.
법의학 분석에서 벗어나고 싶은 마음도 있어요. 안 좋은 일이 생기면 다들 "아, 데이터에서 봤어"라고 말하잖아요. 데이터 내에서 추적해서 "그래, 이걸 잡았어야 했어, 저걸 잡았어야 했어"라고 말할 수 있게 하고 싶어요. 아직 일어나지 않은 사건을 예측 분석하는 것보다 이미 알려진 사건을 찾는 게 훨씬 쉽죠.
매번 정확해야 하고, 이전에 보지 못했던 것들에 대해 미래를 말할 수 있어야 해요. 여기에는 이전에 접촉한 적이 없는 사람들과 이전에 경험하지 못한 다양한 유형의 위협이 포함되죠. 이 부분이 이 분야를 정말 어렵게 만드는 이유에요. 우리는 이 분야에서 수년 동안 그래프를 사용해서 다양한 데이터 세트를 신속하게 연결하고, 그래프 알고리즘을 작성해서 이러한 질문에 최대한 빠르게 답할 수 있었어요.
국토안보부의 Knowledge Graph에 사용하는 데이터 소스는 실제로 세 가지 다른 데이터 세트에서 나와요.

첫 번째 데이터 세트는 파트너가 제공하는 보고서 모음이에요. 수십 개의 보고서가 있죠. 그리고 공개 데이터 세트를 사용하는데, 메릴랜드 대학교에는 START라는 글로벌 테러 데이터베이스를 활용하는 센터가 있어요. 여기는 다양한 이벤트에 대해 아주 잘 정의된 데이터베이스와 스키마를 가지고 있고, 데이터는 수십 년 전으로 거슬러 올라가요. 해당 데이터베이스에는 수만 개의 이벤트가 들어있죠.
또, 기본적으로 스프레드시트 형식의 목록도 있는데, 네브래스카 오마하 대학의 연구를 통해 알려진 국내 폭력 극단주의자 약 211명이 포함되어 있어요. 그들은 미국에서 자생하는 극단주의자들을 찾기 위해 신문 보도와 기타 정보를 검토했고, 여기에는 그들이 무엇을 했는지, 체포되었는지 여부, 어떤 유형의 공격을 받았는지, 살아 있는지 죽었는지, 그리고 그들에 대해 알려진 다른 정보가 포함되어 있죠.
우리는 이걸 구조화되지 않은 텍스트로 수집하기로 결정했어요.

이걸 `Node`가 있는 그래프로 바꿀 건데요. `Node`는 다양한 미디어, 이벤트, 그룹, 개인 및 위치가 될 수 있어요. 그리고 공격 유형과 위협 유형의 속성을 공격 유형으로 제공했어요. 예를 들어 폭발 장치, 차량 공격 등이 있죠.
그 다음 개인이나 그룹을 다른 유형의 공격과 연결하는 보고서가 있을 때마다 해당 그래프에 `Edge`를 배치했어요.
그렇게 해서 얻은 결과물은 다양한 조각들이었어요.

다음은 Wikipedia의 항목이에요.
2016년 11월 28일 오전 9시 52분(동부 표준시) 오하이오주 콜럼버스에 있는 오하이오 주립대학교 와츠 홀에서 테러리스트 차량 충돌 및 흉부 공격이 발생했습니다. 공격자는 소말리아 난민 압둘 라자크 알리 아르탄(Abdul Razak Ali Artan)이 최초 대응한 OSU 경찰관의 총에 맞아 사망했으며 13명이 부상으로 병원에 입원했다.
구조화되지 않은 텍스트를 가져와서 그래프 객체를 만들어요. 예를 들어, 다양한 유형의 `Node`를 나타내기 위해 색상이 다르게 지정되었죠. 공격자라는 사람이 있고 차량 공격과 첨단 무기라는 두 가지 공격 유형이 있어요. 위치는 오하이오 주립 대학이고요. 이 정보를 종합하기 위해 그래프를 작성하는 거예요.

위협 평가 보고서에서 우리는 처음에 114개의 `Node`와 163개의 `Edge`로 그래프를 만들었어요. 그래프는 그리 크지는 않지만 매우 귀중한 정보를 담고 있죠. `Node`의 다양한 색상은 위치, 개인, 그룹 등의 다양한 `Node` 유형을 나타내요.
우리는 이걸 출발점으로 삼아 글로벌 테러 데이터베이스를 구축했어요.

이 데이터베이스에는 약 120,000개의 이벤트가 각각 행으로 포함되어 있어요. 우리는 그 데이터베이스 내에서 국내 행사를 찾아보았고, 대략 70,000개 정도의 이벤트가 있었죠. 데이터베이스 `Schema`를 하나의 행이 이벤트를 나타내는 CSV 파일로 변환했어요. 해당 이벤트의 많은 기능이 해당 행의 셀로 존재하고요. Neo4j를 사용해서 시작점에 로드하고 Python 스크립트로 일부 사전 처리를 수행했죠.
이건 메릴랜드 대학의 START 센터에서 공개적으로 사용 가능한 데이터 세트에요. 그 다음 그래프 `Schema`와 수집을 살펴봤어요.

우리가 가지고 있는 다양한 데이터 세트를 어떻게 결합할까요? 우리는 원본 데이터베이스나 보고서에서 필드 매핑을 생각해냈어요. 우리는 Neo4j의 그래프 `Schema`가 무엇인지 살펴보고 결국 약 325,000개의 `Node`와 약 270만 개의 `Edge`가 있는 그래프를 구축했죠. 다시 한 번 말씀드리지만, 사람, 장소, 사물, 공격 등을 서로 연결하는 정보가 있으므로 그 `Edge`를 그래프에 추가했어요.
이를 통해 예시 `Query`에서 표현한 Neo4j의 아주 간단한 `Query`를 사용해서 분석가분들을 도울 수 있었어요.
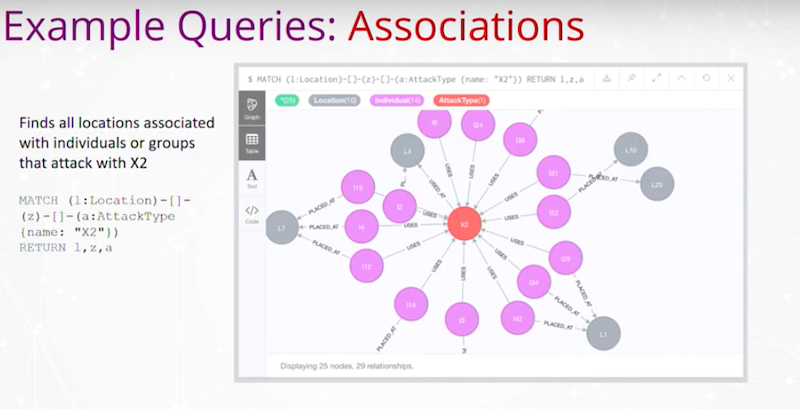
다른 공격 유형이나 무기로 공격하는 개인이나 그룹과 관련된 모든 위치를 찾는 `Query`가 있을 수 있어요. 여기서는 해당 공격 유형 중 하나를 나타내는 X2라고 부르죠.
여기에 연관 `Query`를 수행하기 위한 `Query`가 있고, 결과가 여기 있어요. 다음은 Neo4j의 X2와 해당 유형의 공격과 관련된 주변 위치인데요. 이건 정말 간단한 `Query`이고, 저희는 이런 작업을 많이 했답니다.
모티브 찾기
분석가분들은 아마 이런 질문을 할 수도 있을 거예요. “X2와 X3 모두를 사용해서 공격하는 개인 또는 그룹과 관련된 모든 위치를 찾아보세요.” 이건 마치 날카로운 무기 공격과 차량 공격이 함께 있었던 위 Wikipedia 항목과 같은 경우죠. 여기 `Graph`에서 라벤더 색으로 표시된 개인을 찾아볼게요. 이들 중 일부는 두 가지 공격 유형을 모두 사용하는 데 연루된 사람들이에요. 이게 바로 모티프 찾기의 간단한 예시랍니다.
저희는 개인 간 최단 경로를 가지고 있어요.
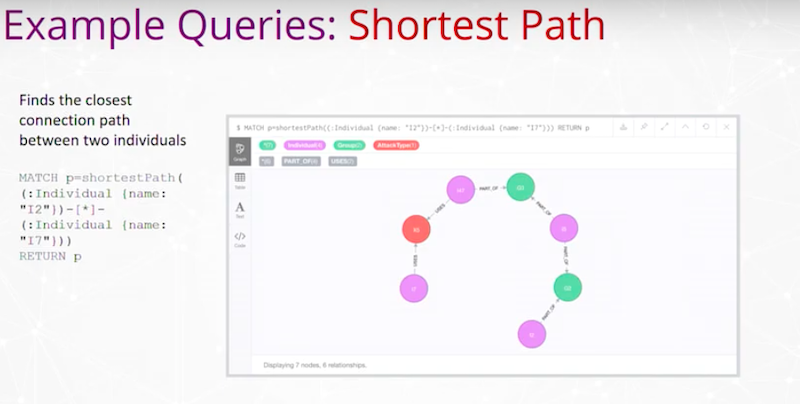
두 개인 사이의 가장 가까운 연결 경로를 찾는 거죠. 여기서 `Query`는 왼쪽에 있고, 두 개인은 이 체인의 양 끝에 있어요. 저희는 해당 데이터에서 그 개인들 간의 연결을 찾으려고 하는 거랍니다.
예전에는 다양한 보고서를 살펴보고, 다양한 식별자를 확인하고, 여러 `Database`를 뒤져봐야 했고, 이런 연결을 놓치는 경우가 많았어요. 하지만 이 `Graph` 공간으로 넘어오니 감지되지 않았거나 과거에 검색하는 데 많은 시간이 걸렸던 연결을 쉽게 찾을 수 있게 되었죠.
데이터 연결
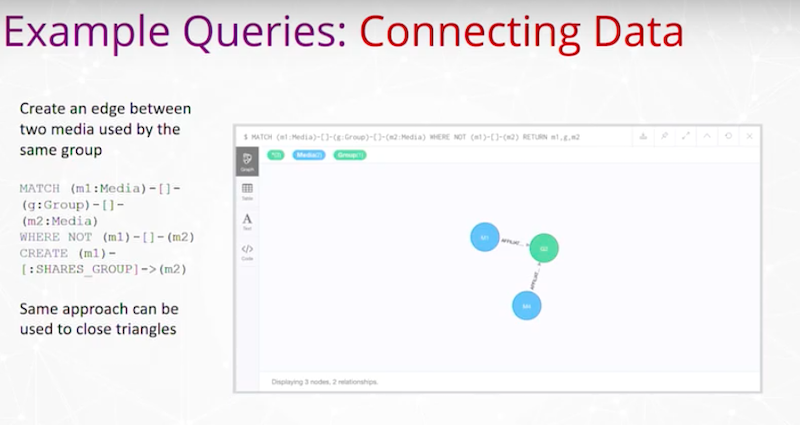
여기는 동일한 그룹에서 사용하는 두 미디어 사이에 엣지를 만드는 곳이에요. 여기 Neo4j와 이걸 수행할 수 있는 `Query`가 있답니다.
또한 `Graph`의 `Node`에 대해 PageRank 및 기타 유형의 중요도 순위를 실행했어요.
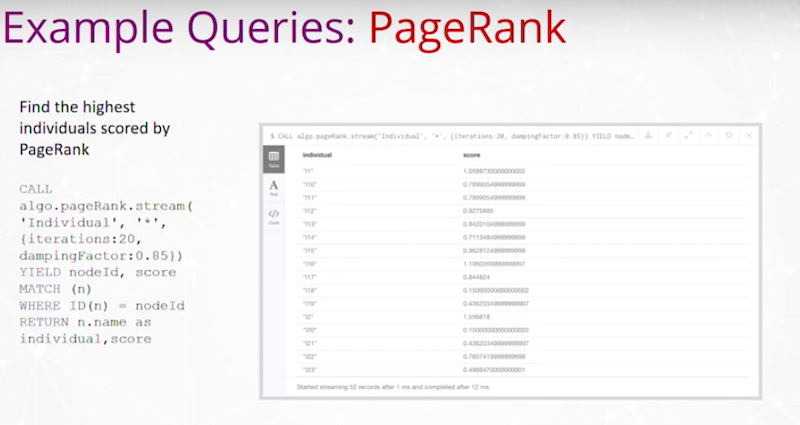
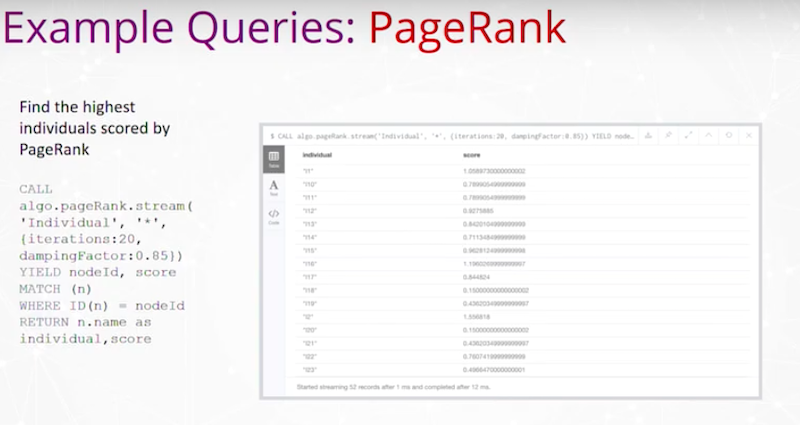
예를 들어, PageRank에서 점수가 가장 높은 개인을 찾는 거죠. 다음은 개인인 `Node`와 PageRank가 무엇인지에 대한 간단한 출력 결과에요.
이 `Graph`는 시각화를 위해 Gephi를 사용하고 있어요. 이건 미국 이벤트에서 실행되는 Louvain이라는 커뮤니티 감지 알고리즘이고, 색상은 서로 다른 커뮤니티를 나타낸답니다.

저는 중간에 `Node` 중요성을 가지고 있어요. 고유벡터 중심성 그리고 이러한 순위를 기반으로 더 영향력이 있거나 중요한 일부 행위자의 PageRank를 확인할 수 있죠. 고유벡터 중심성을 보고 그 중 일부의 그룹을 살펴보면 다음과 같아요.
첫 번째는 알려지지 않았지만 그룹을 추출하네요. 낙태 반대 극단주의자, 좌파 무장세력, 백인 극단주의자, 흑인 민족주의자, 동물 해방 전선. 이런 유형의 `Query`를 통해 이 데이터 세트 내에서 더 중심적이거나 더 영향력이 있는 일부 그룹을 파악할 수 있어요.
예측 `Graph` 분석은 실제로 데이터와 문제보다 앞서 나가고 있어요. 입력 `Graph`가 많으면 데이터를 부분적으로만 사용할 수 있으므로 데이터 세트를 스트리밍하거나 정보가 누락되기도 하죠. 더 많은 데이터를 갖고 싶지만, 가지고 있는 데이터를 바탕으로 빠르고 신속한 결정을 내려야 할 때도 있잖아요.
또한 이런 `Graph`는 시간이 지남에 따라 변하기도 해요. 고정된 `Graph`가 아니라는 거죠. 저희는 항상 무엇이 변화하고 있고 무슨 일이 일어나고 있는지 이해하려고 노력하고 있어요. 과거에는 중요하지 않았던 `Node`가 시간이 지남에 따라 매우 중요해질 수도 있고, 저희는 그걸 찾아낼 수 있기를 바라는 거랍니다.
예측 `Graph` 분석은 실제로 데이터가 채워지거나 본질적으로 변경될 때 분석에 어떤 일이 발생할지 예측하는 것을 목표로 하는 기술이에요.
저희는 실행 예시를 가지고 있어요. 페이지랭크
전이 학습이 포함된 훈련 모델을 사용해서 무작위 `Graph`를 훈련한 다음, 이걸 평가하거나 실제 `Graph`에서 실행할 수 있는 예측 PageRank가 있답니다.
이건 교육 유형을 수행하기 위해 거치는 프로세스를 강조해서 보여주는 거예요. 저희는 PageRank와 자연스럽게 연결되는 무작위 걷기를 수행했고, 이런 걷기를 사용해서 PageRank를 예측하는 `Neural Network` 시스템을 개발했답니다.
저희는 빠르고 신속하게 답변을 얻기 위해 이 모든 작업을 하고 있는 거에요.
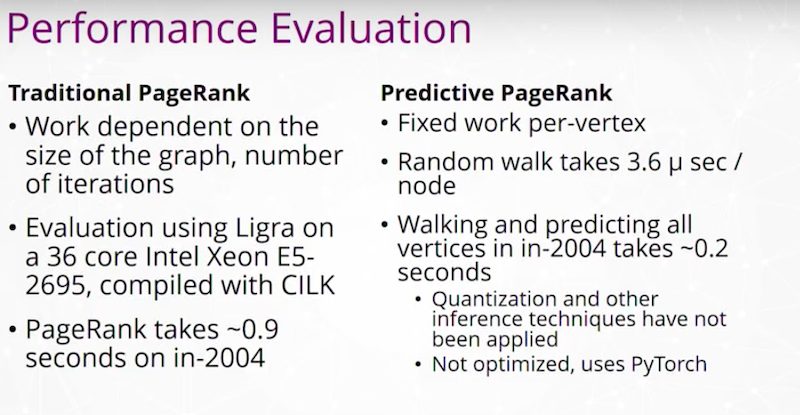
저희는 세계에서 가장 큰 그래프에서도 이런 유형의 그래프 쿼리를 밀리초에서 초 단위로 실행할 수 있기를 바라요.
결론 및 감사의 말씀
결론을 맺으면서, 많은 분들께 감사의 말씀을 드리고 싶어요.

먼저 Jason Riedy, Anita Zakrzewska 박사님, Oded Green과 같은 연구 과학자분들께 감사드립니다. 그리고 이 그래프 분야에서 함께 작업해 온 많은 대학원생들에게도 감사 인사를 전하고 싶어요.
Neo4j와 함께하게 되어 정말 기쁘고, 저와 함께 Neo4j의 대규모 Knowledge Graph를 통한 예측 분석에 대해 배우는 데 관심을 가져주셔서 감사해요!
- 페이지랭크
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'GraphRAG' 카테고리의 다른 글
| LlamaIndex에서 Property Graph Index를 내 입맛대로 커스터마이징하기 (0) | 2026.05.29 |
|---|---|
| 인공지능과 Machine Learning의 현재와 미래 (0) | 2026.05.29 |
| 2023년 그래프 기술 전망: Neo4j와 GraphRAG의 미래는? (1) | 2026.05.28 |
| Precise Economic Policy in a World of Chaos (0) | 2026.05.28 |
| 관찰 가능한 그래프: Neo4j로 GraphRAG 성능 극대화하기 (0) | 2026.05.27 |