
- Graph Data Science
- Machine Learning
편집자 주: 이 프레젠테이션은 Tatiana Hartinger가 GraphConnect New York 2018년 9월에 진행했어요.
프레젠테이션 요약
Tatiana Hartinger는 수학자이자 그래프 이론을 전문으로 하는 인지 솔루션 컨설턴트예요. Cognitiva는 그래프를 사용해서 가상 비서를 향상시키고 있다고 해요.
Cognitva는 IBM의 Watson Assistant와 Neo4j 기반의 Graph Database를 결합했대요. 문제는 가상 비서가 고객의 요청과 관심사에 맞춰 빠른 추천을 제공해야 한다는 점이죠.
Watson Assistant는 Intents와 Entities를 사용하는데요. Intent는 사용자 입력의 목적을 나타내고, Entity는 Intent와 관련된 용어나 개체를 의미해요.
그래프에서 가상 비서에 사용되는 `정점(vertex)`에는 다양한 유형이 있어요. `정점(vertex)`은 색상으로 구분되어 있고, 각 `정점(vertex)`에는 `유형(type)` 값이 있는데, 이 `유형(type)` 값은 `정점(vertex)`의 질문에 대한 가능한 답변이 되는 거죠.
가상 비서와 Neo4j를 결합하기 위해 Cognitiva는 둘 사이를 오가는 Python 스크립트를 사용하고 있어요.
코드는 크게 세 부분으로 나눌 수 있어요.
- Neo4j에서 그래프 생성
- `정점(vertex)`과 `엣지(edge)`를 생성하는 데 사용되는 함수는 `엣지(edge)`의 가중치를 계산하는 데 사용돼요.
- 코드의 일부를 사용하면 Neo4j에서 `쿼리(query)`를 작성하는 동안 Watson Assistant의 대화 상자를 연결할 수 있어요.
솔루션이 어떻게 작동하는지 설명하기 위해 Hartinger는 영화 추천 예시를 사용해서 이 솔루션의 이점과 잠재력을 요약하고 있어요.
이 기술은 언젠가 특정 제품 판매, 예비 의료 진단, 환자 지원 및 상호 작용이 문제 해결의 핵심 단계인 기타 분야로 확장될 수 있을 거예요.
전체 프레젠테이션
저는 수학자이고 박사 과정에서 Graph Theory를 전공하고 있는 타티아나 하팅거에요. 현재 아르헨티나 부에노스아이레스의 Cognitiva에서 인공지능 관련 솔루션을 구현하는 기술 분야의 인지 솔루션 전문가로 일하고 있습니다.
저희가 구현하는 솔루션 중 하나는 다양한 회사를 위한 가상 비서 솔루션인데요, 통신 회사, 금융 서비스, 헬스케어 산업 분야에서 활용되고 있어요.
이번 내용은 페데리코 코스타, 하비에르 포르틸로와 함께 작업한 내용을 바탕으로 하고 있습니다.
저희 팀 리더가 그래프를 사용해서 가상 비서를 향상시키자는 아이디어를 냈을 때, 솔루션 개발에 착수하게 되었어요. 그때부터 어떻게 구현할 수 있을지 조사하기 시작했고, 마침내 해결책을 찾았죠.
소개
저희는 IBM의 AI Watson Assistant 기술과 IBM이 지원하는 Graph Database를 결합했어요. 고객의 선호도나 니즈에 따라 추천을 제공하고 싶었고, 가능한 한 빠르게 결과를 얻고 싶었거든요.
여기서 공유하는 예시는 영화 추천이지만, 사실 모든 유형의 추천이나 검색에 적용할 수 있어요. Graph Database에는 추천에 필요한 모든 정보가 담겨 있답니다.
중요한 점은, 저희가 선택한 지표를 사용해서 계산한 특정 연령대에 대한 가중치가 그래프에 있다는 거예요. 이 엣지 가중치는 가장 빠른 방법으로 추천 프로세스를 수행할 수 있게 해주는 핵심 요소랍니다.
해결하고 싶었던 문제

저희 목표는 가상 비서 환경에서 요청이나 관심사를 기반으로 고객에게 빠른 추천을 제공하는 것이었어요.
이것이 고객과의 첫 번째 소통이라고 가정해볼 수 있어요. 고객의 선호도나 좋아하는 것에 대한 사전 지식이 없는 상태죠. 그래서 정보를 수집해야 하는데, 여기서 가상 비서가 활약하게 돼요.
저희는 사용자의 선호도를 파악하기 위해 어시스턴트가 질문을 던지도록 설계했어요. 좋은 사용자 경험을 제공하고 싶었거든요. Watson Assistant 덕분에 자연어로 대화하는 부분은 물론, 전체 프로세스에 걸리는 시간을 최소화하고 싶었어요.
바로 이 지점에서 Neo4j를 사용한 그래프가 등장하는 거죠!
Watson Assistant Tool
IBM Watson Tool에 대해 조금 이야기해볼게요. 여기서 저희는 가상 비서를 개발했답니다.
IBM Watson Assistant를 사용하면 자연어로 입력된 내용을 이해한 다음, Query에 대한 답변을 제공할 수 있습니다.

Watson Assistant는 구조화되지 않은 데이터를 분석하고 자연어를 처리해요. 문법과 맥락을 이해하기 위해 복잡한 질문을 이해하고 각 경우에 가능한 모든 의미를 평가하는 솔루션을 교육했죠.
Watson 가상 어시스턴트는 학습 기술을 적용해서 문장이나 구문에 대해 미리 정의된 최상의 클래스를 예측한답니다.
가상 비서가 수행하는 이 "사고" 서비스는 텍스트 뒤에 숨겨진 의도를 해석하고 특정 신뢰 수준에 해당하는 분류를 반환해줘요.
선택된 값은 해당 작업을 트리거하는 데 사용되는데요. 해당 작업은 애플리케이션을 리디렉션하거나 질문에 답변하는 것일 수 있어요.
우리 봇은 각 경우에 Cognitiva의 AI 트레이너와 이 가상 비서를 위해 우리를 고용한 회사인 도메인 전문가의 특정 지식에 따라 특정 도메인에서 교육을 받아요.
Intents and Entities
Watson Assistant는 Intents 및 Entities와 함께 작동해요.
Intent란 뭘까요? 사용자 입력의 목적을 나타내요. 예를 들어, 영화 추천 요청이나 필요에 가장 적합한 제품 요청 등 무엇이든 될 수 있죠.
Entity는 Intent와 관련된 용어 또는 개체를 나타내요. 이는 우리가 사용자로부터 얻는 정보인데요. 우리 경우에는 Entity의 값으로 발생할 수 있는 다양한 질문에 대한 가능한 모든 답변을 정의해요.

Entity를 생각해보면 Genre 영화 추천의 경우 다음과 같은 값을 갖죠. drama, sci-fi, comedy, romance, 등.
오른쪽 아래에는 Watson Assistant의 대화 상자가 어떻게 보이는지 보여주는 이미지가 있어요. 보시다시피 트리와 같은 구조를 가지고 있죠. 항상 welcome Node에서 시작해서 anything-else Node로 끝나는데, 다른 모든 Node의 조건과 일치하지 않는 모든 항목이 이동하는 Node에요.

사용자가 입력을 입력할 때마다 Watson Assistant는 이 입력이 Node의 조건 중 하나에 해당하는지, Node의 이 조건이 충족되는지 확인해요. 그렇다면 해당 Node에 설정한 모든 작업이 계속 진행되죠. 우리는 답변을 제공하고 다른 특정 Node나 우리가 원하는 다른 것으로 이동할 수도 있어요.
그래프 디자인
Neo4j를 이용한 그래프 디자인에 대해 말씀드릴게요.
이 그래프에는 다양한 유형의 Node가 포함되어 있어요. 우리는 질문 유형별로 이러한 Node를 정의하는데요. 아래 두 번째 레이어에서 파란색으로 표시되는 Node가 바로 그거에요.
예를 들어 영화 추천을 생각해 본다면, genre, favorite actor, favorite director, 그리고 release date 정도가 있겠죠. 이런 것들이 사용자에게 물어볼 질문들이 될 거예요.
그 아래에는 type value 형태의 정점들이 있어요. 각 값은 질문에 대한 가능한 답변이 되는 거죠.
분홍색 부분에는 가능한 모든 directors가 있는데, 이들은 type question director 정점에 인접해 있어요. 빨간색은 영화의 가능한 모든 genres를 가지고 있고요. 초록색에는 다양한 dates 유형의 영화들이 있을 수 있겠죠.

우리의 경우, modern과 classic으로 나뉘어 있어요. 그리고 회색으로는 모든 type actor 정점이 있고, 이들은 당연히 actor 정점에 인접해 있답니다.
노란색 하단에는 추천 정점이 있는데, 이는 데이터베이스의 모든 영화들이에요. 결과는 상위권에 있죠. 우리가 이름을 붙인 더미 정점인 Start가 보이는데, 이 정점은 question type의 모든 정점에 인접하게 돼요.
앞서 말씀드렸듯이 각 type question은 해당 질문에 대한 가능한 답변에 해당하는 모든 정점에 인접하게 됩니다.
마지막으로 하단에 추천 정점이 있고, 이러한 유형의 정점에 대한 인접성은 정점의 특성에 해당해요.
영화를 본다고 해볼까요? 시애틀의 잠 못 이루는 밤을 빨간색으로 표시했어요.
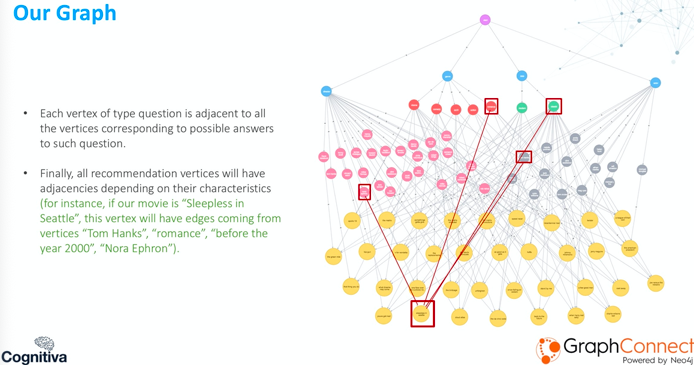
그러면 Tom Hanks 엣지가 생기겠죠. 왜냐하면 그는 영화에 출연하는 배우이기 때문이에요. 그리고 Classic으로부터 오는 우위를 갖게 될 텐데, 왜냐하면 2000년 이전 영화이기 때문이죠. 또한 Romance라는 이점도 있는데, 그건 영화의 장르니까요. 마지막으로 Nora Ephron이라는 이점도 얻게 되는데, 그녀는 영화의 감독이니까요!
물론 이 예에서는 아주 작은 그래프를 보여드리고 있어요. 간단하게 유지하기 위해 배우 한 명, 감독 한 명, 장르 하나에만 인접한 영화를 만들기로 결정했죠. 물론, 실제로는 훨씬 더 많은 인접성을 가질 수 있을 거예요.
Start 정점과 vertices of type question 사이의 엣지는 엣지 가중치를 갖게 될 거예요. 이러한 가중치는 사용자에게 해당 질문을 요청할 경우 제외될 잠재적 추천의 최소 수에 해당하죠.

우리의 목표는 해당 엣지에 최대 가중치가 있는지 질문하는 거예요. 이렇게 하면 최악의 시나리오에서도 추천 정점에 더 빠르게 도달할 수 있답니다.
이 부분에 대해 좀 더 자세히 설명해 볼게요.
우리가 하는 일은 먼저 가능한 각 대답 B에 대해 질문 Q을 던져서, 질문 Q에 사용자가 응답했을 때 제외될 영화의 수를 계산하는 거예요.
그런 다음 그 답변 중 최소값을 취해서 질문 B을 던질 질문 Q, 더미 node 사이의 edge의 무게로 둬요. Start 질문 유형 node Q 사이에 말이죠.

마지막으로 우리는 어느 edge에 최대 가중치가 있는지 질문하죠. 이게 바로 우리가 물어볼 가장 좋은 질문으로 선택할 질문이 될 거예요.
이제 사용자에게 질문을 하고 답변을 얻으면 그래프가 업데이트돼요. 그런 다음 더 이상 관련이 없는 모든 vertex와 edge를 삭제하고, edge 가중치를 계산하는 거죠.
두 가지를 결합하는 방법
이제 우리 솔루션의 두 가지 측면을 어떻게 결합하는지 알려드릴게요. Watson Assistant의 가상 비서와 Neo4j의 그래프 말이죠.
이를 위해 우리는 Watson Assistant와 Neo4j 사이를 오가는 Python 스크립트를 작성했어요. JSON, Watson Developer Cloud 및 Py2neo 라이브러리를 사용했죠.
코드는 세 가지 주요 부분으로 구성돼요.
첫 번째는 Neo4j에서 그래프를 생성하는 부분이에요. 이전에 설명했듯이 몇 가지 기능을 사용해서 vertex와 edge를 만들었죠.
그런 다음 제가 언급한 edge의 가중치를 계산하는 데 필요한 몇 가지 기능이 있어요. Start와 질문 사이에요. 우리는 이전에 본 이 측정항목을 정의하고 솔루션의 각 단계에서 물어볼 가장 좋은 질문을 결정하는 함수를 만들어요. 또한 다음과 같이 그래프를 수정할 수 있는 몇 가지 기능도 있죠. Cypher, Neo4j의 쿼리 언어에요.

마지막으로 Neo4j에서 쿼리를 작성하는 동안 Watson Assistant의 대화 사이를 연결할 수 있게 해주는 코드 부분이 있어요.
우리는 이 작업에 필요한 모든 인텐트, 엔터티 및 컨텍스트 변수를 포함하는 Watson Assistant에서 이 대화 상자를 만들었어요. 의도가 감지되면 Watson은 가능한 한 최단 시간 내에 사용자를 위한 추천을 얻기 위해 필요한 질문을 계속 던지죠.
각 질문 후에 사용자의 응답은 컨텍스트 변수에 저장되고 그래프를 수정하는 데 사용돼요. 주목해야 할 중요한 점은 사용자가 하나 이상의 질문에 대해 명확한 대답을 갖고 있지 않은 경우도 고려한다는 것이에요.
이 경우 그에 따라 그래프를 수정할 거예요.
여기에 우리 솔루션의 작은 다이어그램이 있어요.

한편으로는 Watson Assistant가 있어요. 사용자와 대화를 나눈 다음 두 부분을 연결하는 코드를 작성하죠.
반면에 Neo4j에는 사용자에게 추천하는 데 필요한 모든 정보가 포함된 Graph Database가 있어요.
의도를 감지할 때마다 대화가 시작돼요. 사용자가 무언가를 입력하면 Watson이 의도를 감지하죠. 이를 통해 어떤 그래프를 봐야 하는지 알 수 있어요. 그런 다음 이 단계에서 물어볼 가장 좋은 질문을 계산하는 작업을 진행해요.
이 정보는 Watson Assistant로 다시 전달돼요. 어시스턴트는 사용자에게 해당 질문을 하고 답변을 얻은 다음, 해당 답변을 사용하여 그래프를 수정해요. 우리는 동일한 절차를 계속할 거예요.
영화 추천 예시
이 솔루션이 어떻게 작동하는지 영화 추천 예시를 보여드릴게요.
첫째, 우리는 Start vertex가 상단에 있어요. 그럼 우리는 네 가지 vertices of type 질문을 가지고 있어요. 이 예에서 고려한 질문은 director, genre, date 그리고 actor (영화의) 이에요.
그 다음 분홍색으로 표시된 유형 값의 vertex를 가지고 있어요. 모든 directors는 빨간색으로 표시되어 있고, 모든 genres 영화는 녹색으로 표시되어 있어요. 우리는 release dates를 2000년을 기준으로 classic과 modern으로 구분했어요. 그리고 회색으로는 모든 possible actors를 가지고 있어요.
마지막으로 하단에는 추천 vertex가 있어요. 추천 vertex는 우리 데이터베이스에 있는 영화들이에요. 우리는 사용자 추천으로 이러한 영화 중 하나를 찾으려고 노력하고 있어요.

이 부분의 해결방법에서 현재 그래프의 상태가 어떤지 먼저 확인해볼게요.

우리는 14개의 vertex를 가지고 있는데, type actor, 두 개의 vertex는 type date, 26개의 directors 그리고 다섯 개의 genres를 가지고 있어요. 데이터베이스에 있는 46개의 영화로 시작하죠. 사용자에게 물어볼 수 있는 질문은 네 가지에요. 우리는 더미 vertex의 이름을 Start라고 지었어요.
질문할 수 있는 네 가지 질문이 있으므로 더미 node 사이의 edge에 가중치를 부여해요. Start와 그 질문 vertex 사이에요. 제가 언급한 측정항목을 사용하여 이를 계산할 거예요.
우리는 사용자에게 영화의 배우에 대해 묻는 경우 제외될 수 있는 가능한 영화 추천 수를 계산하고, 거기에서 두 영화 사이의 edge 가중치를 얻어요. Start 와 actor 사이는 27이에요.
우리는 다른 세 가지 질문에 대해서도 동일한 작업을 수행하여 두 질문 사이의 edge 가중치를 얻어요. Start와 date 사이는 9, Start와 director 사이는 32, 그리고 Start와 genre 사이는 23이에요.

우리는 최대값을 찾고 있으므로 이 첫 번째 단계에서 선택할 가장 좋은 질문은 director에요. 이는 Watson이 사용자에게 물어볼 가상 비서죠. 여기서는 첫 번째 단계에서 그래프가 어떻게 보이는지 확인하고, 사이에 해당하는 모든 edge 가중치를 갖습니다. Start와 모든 질문 유형 vertex 사이에요.
이런 식으로 대화가 진행될 수 있어요. 먼저 비서가 "안녕하세요. 무엇을 도와드릴까요?"라고 물어보죠. 사용자는 "이번 주말에 볼 만한 영화 추천해 주실 수 있나요?"와 같이 대답할 수 있을 거예요.
이 경우 Watson Assistant는 의도, 즉 영화 추천을 감지하고 "물론입니다. 도와드리러 왔습니다."라는 응답을 시작하죠.

그때 우리는 이전에 가지고 있던 그래프를 살펴보고, 그래프에서 이 경우에 물어볼 가장 좋은 질문을 얻어내요.
우리는 이 질문이 영화 감독에 관한 것이라고 판단하고, "좋아하는 감독이 있나요?"라고 물어보죠. 이에 대해 사용자는 "별로 그렇지 않습니다."라고 대답할 수 있어요. 선호하는 감독이 없을 수도 있지만 괜찮아요.
이 경우 Watson Assistant는 엔터티를 감지하고 Director의 값은 "모르겠어요"가 되죠. 그러면 응답이 시작돼요.

"알겠습니다. 문제 없어요. 그러면 제가 선택할게요." 그리고 사용자로부터 얻은 이 정보를 디렉터라는 컨텍스트 변수에 저장하죠.
그래프를 수정하기 위해 이 컨텍스트 변수를 사용하는데요. 이제 이 단계에서 그래프가 어떻게 보이는지 한번 살펴볼까요?

그래프의 현재 상태를 보면 14개의 vertex 유형이 있어요. Director, 두 가지 유형의 Date, 다섯 개의 Genres, 그리고 여러 Movies가 있죠. 이 경우에는 여전히 36개네요. 사용자로부터 어떠한 정보도 얻지 못했기 때문에 그 어느 것도 배제할 수 없었지만, 질문 수는 3개로 줄었어요.
이제 우리는 세 가지 가능한 질문을 갖게 되었어요. 우리는 사이의 간선 가중치를 계산해야 해요. Start와 남은 세 가지 질문 사이의 가중치요.
이렇게 해서 Start와 Actor 사이의 간선에 대해 27의 가중치를 얻고, Start와 Date 사이에서 9의 가중치를 얻고, Start와 Genre 사이의 가중치는 23이 돼요.
우리는 최대값을 찾고 있으므로 이 단계에서는 영화의 배우에 대해 묻는 것이 가장 좋은 질문이라고 선택할 수 있겠죠.

이제 이 단계에서 그래프가 어떻게 보이는지 한번 살펴볼까요?
Director 타입의 vertex는 더 이상 관련 정보가 아니기 때문에 사라졌어요. 이미 사용자에게 물어봤으니 다시 물어볼 필요는 없겠죠? 그래서 가능한 질문 vertex는 세 개가 남았네요.
대화는 계속 진행될 거예요. 배우에 대해 물어봐야 한다는 걸 알고 있으니, 어시스턴트는 "가장 좋아하는 배우는 누구인가요?"라고 물어볼 거예요. 그러면 사용자는 "저는 톰 행크스의 열렬한 팬입니다!"라고 대답할 수 있겠죠.

여기서 우리는 정보를 얻고, actor 엔티티를 감지하는데, 이번에는 값이 Tom Hanks네요.
이 정보는 그래프를 수정하는 데 사용될 context variable에 저장돼요. 이제 그래프가 어떻게 보이는지 한번 살펴볼까요?

두 개의 Date 타입 vertex와 다섯 개의 Genre 타입 vertex가 있네요. 이 단계에서는 가능한 추천 영화 수가 확 줄었어요. 남은 영화는 9편이고, 남은 질문 수는 2개입니다.
이 단계에서는 두 edge의 edge weight를 계산해야 해요. Start와 이 두 가지 가능한 질문이 있네요.
Start와 Date 사이의 edge weight를 계산하면 3이 돼요. 그리고 Start와 Genre 사이의 edge weight를 계산하면 4가 되죠. 우리는 최대값에 관심이 있으니 영화의 장르를 선택할 거예요.
이제 그래프를 한번 살펴볼까요?

이 단계에서는 그래프가 훨씬 작아졌어요. 더 이상 Actor 타입의 vertex는 없고, Actor 질문 vertex 역시 사라졌죠. 이들은 더 이상 우리와 관련이 없으니까요. 우리에게는 Genre와 Date, 이렇게 두 가지 질문이 남아있고, 우리는 가장 좋은 질문은 영화의 Genre에 관한 것이라는 사실을 확인했어요.
그렇게 대화가 진행되는 거예요. 어시스턴트는 "어떤 장르를 선호하시나요?"라고 물어보죠. 사용자는 "로맨스 영화를 보는 것 같아요."라고 말할 수 있고요. 이 단계에서 엔터티를 감지하는데, genre의 값은 Romance가 되는 거죠.

다시 한번 이 정보를 컨텍스트 변수 genre에 저장하고, 그래프를 다시 수정하는 데 사용할 거예요.
이 단계에서 그래프의 현재 상태를 살펴보면 Date 타입의 Node가 두 개, Movie 타입의 Node가 한 개 있는 것을 확인할 수 있어요.

이제 사용자에게 추천을 해줄 수 있는 단계에 왔어요. 아직 한 가지 질문이 남아있지만, 기존 방식대로 했다면 모든 질문을 다 해야 했을 거예요. 하지만 이 솔루션을 사용하면 질문 하나를 아낄 수 있었죠.
이것은 아주 작은 예시라서 솔루션을 쉽게 볼 수 있도록 단순하게 유지하고 싶었어요. 데이터 양이 엄청나게 많은 경우에 가장 큰 이점을 얻을 수 있고, 가능한 많은 추천을 배제할 수 있답니다.
이것이 현재 그래프의 모습이에요.

다음과 같은 Node 타입이 하나 남아있네요. 바로 Recommendation! 추천해 드릴 영화라는 뜻이죠. 두 개 이상의 추천을 원할 수도 있어요. 사용자에게 제공하는 추천 목록을 3개, 5개, 또는 원하는 만큼 가질 수 있고, 순위대로 정렬될 수도 있답니다.
어시스턴트가 이 영화를 추천해 줄 거예요.

영화는 바로 시애틀의 잠 못 이루는 밤이에요. 이 영화는 1993년에 나온 클래식 로맨스 영화라는 것을 알고 있죠. 톰 행크스와 멕 라이언이 출연하고 노라 에프론이 감독을 맡았고요.
결국 추천을 받았습니다!
요약
우리의 주요 목표는 고객의 관심사나 요청에 따라 고객에게 빠른 추천을 제공하기 위해 가상 비서를 사용하는 것이었어요. 이 문제를 해결하는 데 필요한 모든 정보를 Neo4j Graph Database 형태로 모델링했답니다.
대화를 가능하게 해주는 Watson Assistant 인스턴스를 만들어 볼게요. 저희는 솔루션의 두 가지 측면을 결합하는데요. 어시스턴트가 특정 의도를 감지할 때마다 edge 가중치를 통해 그래프에 의해 결정되는 순서대로 사용자 선호도를 알아보기 위해 사용자에게 질문을 시작하는 거죠.
사용자로부터 답변을 얻으면 그래프를 수정하기 위해 이 정보를 저장하고, 추천을 작성하는 데 필요한 모든 정보를 얻을 때까지 동일한 방식으로 대화를 계속해요.
이 솔루션을 요약하면, 저희가 얻은 것은 인간 간의 대화를 시뮬레이션하는 프로세스와 가능한 가장 짧은 시간에 솔루션에 도달할 수 있도록 도와주는 Neo4j 모델을 사용한 추천 시스템이라고 할 수 있어요.

솔루션의 이점/잠재력
일반적인 가상 비서는 사용자의 질문에 답변하기 위해 훈련을 받지만, 그 능력에는 한계가 있죠. 일반적으로 반응적인 형태이고, 대화는 단방향적인 경향이 있어요. 또, 지능은 사용자의 요청을 해석하고 이에 대한 답변을 제공하는 것에만 집중되어 있고요.
저희가 생각하는 이러한 유형 기술의 다음 단계는 가상 비서가 특정 도메인의 전문가가 되어, 가장 관련성이 높은 질문을 먼저 제시하여 사용자에게 유용한 지침을 제공하는 대화형 및 양방향 대화를 구축하는 것이에요. 궁극적으로 목표는 사용자가 가능한 한 빠르고 효율적으로 최상의 답변을 얻을 수 있도록 돕는 것이죠.
해당 분야 전문가가 가질 수 있는 모든 정보가 포함된 하나 이상의 그래프를 통해 가상 비서에 또 다른 지능 계층을 추가한 셈이에요.
이러한 유형의 솔루션에 대한 몇 가지 가능한 응용 분야는 특정 제품에 대한 판매 고문이나 전문 판매원이 될 수 있다는 점이에요.
다양한 유형의 제품에 해당하는 그래프를 가질 수 있어요. 냉장고 추천에 대한 그래프, 전자레인지용 그래프, TV용 그래프 등을 가질 수 있는 거죠. 이러한 경우 추천 node는 저희가 사용할 수 있는 제품이 되고요. 그런 다음 질문은 해당 제품의 크기, 가격 또는 모든 유형의 특성에 해당할 수 있겠죠.
그런 다음 예비 의료 진단이나 환자 지원에도 적용될 수 있어요. 저희의 node는 가능한 모든 질병이 될 수 있으며, 환자가 가지고 있는 다양한 증상에 대해 질문할 수 있고요.
마지막으로, 기술 지원을 위한 문제 해결을 위해 보조자가 사용자에게 질문하여, 저희가 돕고 싶은 장치의 특정 오작동에 도달할 수 있는 최선의 방향을 안내하기를 원할 수도 있겠죠.
또한 이 동일한 솔루션에는 다양한 테마나 주제에 대한 그래프가 있을 수 있으므로, 어시스턴트는 한 번에 두 개 이상의 주제에 대해 사용자에게 지침을 제공할 수 있으며, 여기에서 다양한 유형의 의도를 모두 감지할 수 있다는 점도 언급하고 싶네요.
Cognitiva에서는 Neo4j 그래프 데이터베이스를 사용하여 가상 비서를 반응형으로 만들고 각 단계에서 최고의 질문을 할 수 있도록 함으로써 강화했어요. 이 프로세스는 사용자 선호도를 파악하는 데 도움이 되며, 이를 가능한 가장 빠른 방법으로 수행하여 사용자에게 귀중한 조언을 제공할 수 있게 되는 거죠.
- Cypher
- GraphConnect
- JSON
- Machine Learning
- py2neo
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'GraphRAG' 카테고리의 다른 글
| 상업 계약을 위한 에이전트 기반 GraphRAG (1) | 2026.04.22 |
|---|---|
| 고성능 LLM 애플리케이션을 위한 고급 RAG 기술 마스터하기 (1) | 2026.04.21 |
| 관계가 중요했던 한 해: Neo4j와 GraphRAG의 부상 (1) | 2026.04.21 |
| 당신의 데이터가 그래프임을 알려주는 7가지 신호 (Neo4j, GraphRAG, Machine Learning, API 활용) (1) | 2026.04.20 |
| 무엇을 만들고 있나요? Stephen O’Grady와의 5분 인터뷰: Neo4j, GraphRAG, 그리고 Machine Learning에 대한 생각 (1) | 2026.04.19 |