
- 사이퍼 & GQL

Vector Search는 "가장 유사한 것이 무엇입니까?"에 대한 답을 찾는 데 효과적이에요. 하지만 실제 애플리케이션에서는 "가장 가까운 이웃"을 *모든 것*에서 찾고 싶어 하지는 않죠.
사용자들은 올바른 언어, 올바른 테넌트, 특정 기간 내, 재고가 있는, 보관되지 않은, 카테고리와 일치하는 가장 가까운 이웃을 보고 싶어 할 거예요.
Neo4j v2026.01에는 미리보기 기능으로 필터를 사용한 Vector Search가 도입되었어요. 조건자를 적용할 수 있는데, *Query 시 Vector Index 내부*에서 적용되죠. 따라서 Index는 기준과 일치하는 벡터만 포함하는 것처럼 동작해요. 이를 통해 초과 가져오기나 대규모 후보 스캔 및 사후 필터링에 의존하지 않고도 지연 시간을 낮게 유지하고 결과의 관련성을 유지할 수 있어요.
시사: Enterprise Edition, Community Edition 및 Neo4j Aura의 모든 계층에서 Cypher 25의 미리 보기 기능으로 Neo4j v2026.01에서 사용할 수 있어요. 미리 보기 기능은 평가 및 피드백을 위한 것이며 프로덕션 용도로는 지원되지 않아요. GA는 Neo4j v2026.02를 대상으로 해요. 전체 문서가 곧 공개될 예정이에요.
그리고 필터로 Vector Search를 보완하기 위해 다음도 출시합니다. 벡터 검색을 위한 기본 Cypher 구문. 이는 Query 작성을 간소화하고, Cypher 내부에서 고급 검색을 기본으로 만들고, 프로시저 호출의 필요성을 없애고, 고급 AI 및 GraphRAG 기능을 위해 데이터베이스를 준비하죠.
Vector Search 결과를 필터링하는 세 가지 방법
이제 필터링하는 대상과 보장해야 하는 대상에 따라 사용할 수 있는 세 가지 고유한 패턴이 있어요.
- 새로운 기능: 필터를 사용한 Vector Search(Index 필터링)
검색 실행 중에 Vector Index 내부에 조건자를 적용해요. - Vector Search 후 암호화(사후 필터링)
필터 사용 여부에 관계없이 먼저 Vector Search를 실행한 다음 Cypher에서 결과를 구체화/확대해요. - Vector Search 전 암호화(사전 필터링)
Cypher를 사용하여 후보 하위 그래프를 정의한 다음 벡터 유사성을 기준으로 해당 후보에만 점수를 매겨요.
경험상 다음과 같아요.
- Use 인덱스 내 필터링 필터가 단순한 속성에 대한 것이고 지연 시간이 짧은 일관된 검색이 필요한 경우.
- Use 포함이 더 풍부한 그래프 논리에 따라 달라지거나 순회를 통해 결과를 확장하려는 경우.
- Use 후보 세트를 제한적으로 정의할 수 있고 해당 세트 내에서 정확한 점수를 원하는 경우
Index 내 필터링을 사후 필터링과 결합하여 두 접근 방식의 이점을 모두 얻을 수 있어요.
1) 필터를 이용한 Vector Search(In-index 필터링)
이는 `index`가 필터 기준을 충족하는 `vector`만 포함하는 것처럼 동작해야 하는 경우에 이상적이에요. 테스트에서는 넓은(대부분의 데이터 포함) 필터와 좁은(대부분의 데이터 제외) 필터 모두에서 지연 시간이 낮게 유지되고 재현 정확도가 높게 유지되었어요. 가장 큰 단점은 `index` 생성 시 필터링된 속성을 식별해야 한다는 것이에요. 반면 `Cypher` 이후/이전 필터는 모든 `graph` 요소, 패턴 또는 속성을 기반으로 필터를 구성할 수 있는 `Cypher graph query`의 완전한 유연성을 제공하죠.
`Index` 만들기
`Vector index`를 생성할 때 `index`된 `node`/`relationship`에서 속성을 선택하여 각 `embedding`과 함께 메타데이터로 저장할 수 있어요. 아래 예에서는 문서의 작성자와 `published_year`가 `vector index`에 포함되어 있어요.
CYPHER 25
CREATE VECTOR INDEX documentIndex
IF NOT EXISTS
FOR (document:Document)
ON document.embedding
WITH [document.author, document.published_year]`Index` 쿼리
`Query` 시 새로운 `SEARCH` 문의 `WHERE` 조건자는 일치할 수 있는 `index`화된 `vector`를 제한해요.
CYPHER 25
MATCH (document)
SEARCH document IN (
VECTOR INDEX documentIndex
FOR $query_vec
WHERE document.author = 'David'
AND document.published_year >= 2020
LIMIT $top_k
) SCORE AS score
RETURN document, score`SEARCH` 문 내의 `WHERE` 절은 현재 `MATCH` 아래 `WHERE` 절의 하위 집합을 지원해요.
2) `Vector` 검색 후 `Cypher` (Post-filtering)
`SEARCH` 명령을 사용하여 `vector` 검색을 실행한 다음 `Cypher`를 사용하여 결과를 반환하기 전에 결과를 구체화, 검증 또는 확장할 수 있어요. 사후 필터링은 결과 포함 결정이 메타데이터로 표현될 수 있는 것보다 풍부한 `graph` 논리에 따라 달라지거나 `graph`를 탐색하여 관련 항목을 다시 가져오려는 경우에 특히 유용하죠.
필터링은 `vector` 검색 후에 발생하므로 속성을 `index`에 복사할 필요가 없지만 최종 결과 집합에는 요청된 k개보다 적은 결과가 포함될 수 있어요. 이를 보완하기 위해 원하는 결과 크기에 도달하기 위해 `query`를 과도하게 가져오거나 다시 `query`해야 할 수도 있어요.
CYPHER 25
MATCH (document)
SEARCH document IN (
VECTOR INDEX documentIndex
FOR $query_vec
LIMIT $ef_search
) SCORE AS score
MATCH (project:Project)<-[:WRITTEN_FOR]-(document)
-[:WRITTEN_BY]->(author:Author)
WHERE author.name = 'David'
AND document.published_year >= 2020
AND project.completed = true
RETURN document, project, author, score
ORDER BY score DESC
LIMIT $top_k위의 `query`에서는 `$ef_search`를 사용하여 `vector index`에서 오버페치를 지정하고 `$top_k`를 사용하여 `query`에서 반환되는 결과 수를 제한했어요. 첫 번째 `SEARCH` 블록은 `WHERE` 필터를 사용할 수 있으므로 `Cypher`는 필터를 사용하여 `vector` 검색 결과를 확장하고 세분화할 수 있죠.
3) `Vector` 검색 전 `Cypher` (Pre-filtering)
사전 필터링에서 `Cypher`는 먼저 후보 하위 `graph`(예: 사용자가 볼 수 있는 모든 항목)를 식별해요. 그런 다음 `query`는 `query vector`와의 유사성을 기준으로 해당 후보의 순위를 매기죠. 이렇게 하면 일반적으로 `vector index`에서 반환되는 대략적인 결과(`ANN`)가 아니라 후보 세트에 대한 정확한 가장 가까운 이웃(`ENN`) 결과가 생성돼요.
사전 필터링은 `graph` 패턴 일치의 완전한 표현력을 제공하고 후보 세트에 대한 완벽한 재현을 보장할 수 있어요. 그러나 후보 세트가 매우 큰 경우(예: 수백만 개의 `vector`) `query`에서 직접 많은 `embedding` 점수를 매겨야 할 수 있으므로 성능이 확장되지 않을 수 있죠.
CYPHER 25
MATCH (project:Project)<-[:WRITTEN_FOR]-(document:Document)
-[:WRITTEN_BY]->(author:Author)
WHERE author.name = 'David'
AND document.published_year >= 2020
AND project.completed = true
WITH document, project, author,
vector.similarity.cosine(document.embedding, $query_vec) AS score
RETURN document, project, author, score
ORDER BY score DESC
LIMIT $top_k성능
이러한 다양한 성능 특성을 보여주기 위해 간단한 `GraphRAG`에서 영감을 받은 데이터 모델을 만들고 10M `vector`를 로드했어요. 다음 단계는 `vector` 세트를 전체 데이터 세트의 다양한 비율(0.001% ~ 100%)로 제한하는 필터를 고안한 다음 위의 각 기술에 대한 `query`를 작성하는 것이었어요. 나는 `vector` 검색 후 `Cypher`에 대한 `query`를 두 번 테스트했어요. 한 번은 오버 페칭 없이, 또 한 번은 충분한 오버 페칭을 사용하여 일정한 리콜 정확도를 제공했죠.
예를 들어 위의 `query` 예는 내 데이터에서 실행될 때 동일한 `vector` 집합 또는 전체 `vector`의 약 0.1%로 제한돼요.
아래 차트는 필터 선택성(`X`축: 적합한 `vector`의 %)에 대한 `query` 대기 시간(ms)(`Y`축)을 표시해요. 각 포인트에는 % 재현율 정확도로 주석이 추가되어 있죠. 주요 시사점:
- 검색 전 `Cypher`(녹색): `graph`를 사용하여 `vector`를 작은 세트로 빠르게 좁힐 수 있을 때 가장 좋은 성능을 발휘해요. 결과는 항상 100% 재현 정확도를 가지지만, 필터가 확장됨에 따라 철저한 검색은 계산 비용이 너무 많이 들고 대기 시간이 늘어나죠.
- 검색 후 `Cypher`(파란색): 일관되게 수행되지만 필터의 범위가 좁아짐에 따라 점점 더 많은 결과가 필터링되어 재현율 정확도가 떨어져요.
- 오버페치를 사용한 검색 후 암호화(노란색): 필터에 대응하기 위해 오버페치를 확장했더니, 90년대 수준의 높은 재현율 정확도를 꾸준히 얻을 수 있었어요. 하지만 필터가 좁아지면 오버페치가 증가해서 계산 비용이 너무 많이 들고 대기 시간이 늘어나는 문제가 생기죠.
- 필터를 사용한 Vector Search(빨간색): HNSW 알고리즘은 인덱스 내부 속성을 필터링해서 벡터를 빠르게 필터링하고, 비교 비용을 절감하면서 가장 유망한 영역에서만 지능적으로 검색을 확장할 수 있어요. 지연 시간은 계속 낮게 유지되면서 재현 정확도는 높았답니다!
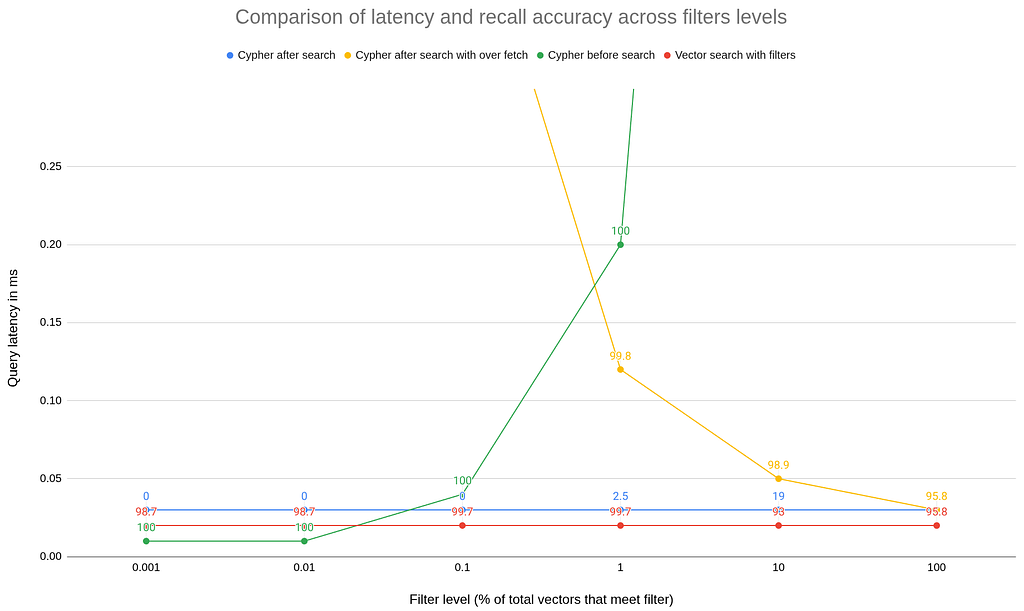
모든 기술은 동일한 인덱스 구성 및 쿼리 매개변수를 사용해서 동일한 머신 및 데이터세트(10M 벡터)에서 테스트했어요. 표시된 결과는 평균 대기 시간이고요. 재현율 정확도는 필터링된 후보 세트의 정확한 기준선을 기준으로 측정되었어요. 캐시가 예열된 상태에서 테스트를 10회 반복했답니다.
피드백
최근에 제품을 빠르게 출시하고 있는데, 이 기능은 그래프 + 검색을 최신 AI 및 RAG 스타일 워크로드를 위한 훌륭한 기반으로 만들기 위한 노력의 일환이에요.
저희 Vector Search 기능을 사용해 보셨다면, 어떤 점을 발견했는지 정말 듣고 싶어요! david.pond@neo4j.com으로 편하게 의견을 보내주세요. 무엇이 효과가 있었고 무엇이 효과가 없었는지, 그리고 무엇을 바꾸고 싶은지에 대한 솔직한 의견이 가장 도움이 될 것 같아요. 사용 사례와 가장 큰 장애물(있다면)에 대한 짧은 메모도 다음 단계의 우선순위를 정하는 데 큰 도움이 될 거예요.
- 그래프RAG
- Vector Search
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'GraphRAG' 카테고리의 다른 글
| NEuler에서 그래프 임베딩 알고리즘 결과 시각화하기 (0) | 2026.06.08 |
|---|---|
| 벡터와 그래프, 함께하면 더 강력해진다: Neo4j와 GraphRAG의 시너지 (0) | 2026.06.08 |
| 벡터 인덱스와 비정형 데이터 입문 - 새로운 GraphAcademy 강좌 (0) | 2026.06.07 |
| BAML을 활용한 비정형 데이터의 Neo4j 그래프 데이터 변환 (0) | 2026.06.07 |
| 스키마의 힘을 깨우다: Python용 Neo4j GraphRAG 패키지의 새로운 기능 (0) | 2026.06.06 |