
구조화되지 않은 데이터를 풍부한 Knowledge Graph로 쉽게 변환하고 자연어로 쿼리하는 걸 상상해보세요. 지난 1년 동안, GraphRAG 애플리케이션이 많은 주목을 받았지만, 원시 데이터에서 고품질 Knowledge Graph를 만드는 건 여전히 주요 병목 현상으로 남아있어요.
ERE(Entity Relationship Extraction) 작업에 LLM(Large Language Model)을 사용하면 Knowledge Graph 구축 과정이 훨씬 쉬워지죠. 하지만 적절한 지침이 없으면 가장 강력한 LLM이라도 관련성이 없거나 일관되지 않은 Nodes와 Relationships를 생성해서 다운스트림 질문 응답 성능이 저하될 수 있어요.
이것이 바로 Schema가 중요한 이유예요! Schema는 LLM이 무엇을 추출해야 하는지 안내하는 청사진과 같다고 생각하면 돼요. 하지만 특히 비전문가이거나 복잡하고 계속 발전하는 데이터를 처리할 때는 Schema를 정의하는 게 어려울 수 있죠.
좋은 소식은, Knowledge Graph 초보자든 노련한 그래프 전문가든 이제 Python용 Neo4j GraphRAG 패키지에 도입된 새로운 Schema 기능 덕분에 Knowledge Graph 구성 프로세스를 개선할 수 있다는 거예요(neo4j-graphrag). 현재 버전 1.8.0에서는 다음을 할 수 있어요:
- 텍스트에서 자동으로 Schema 추론
- 유연한 Schema 적용 옵션 적용
- 추출 프로세스를 세부적으로 제어
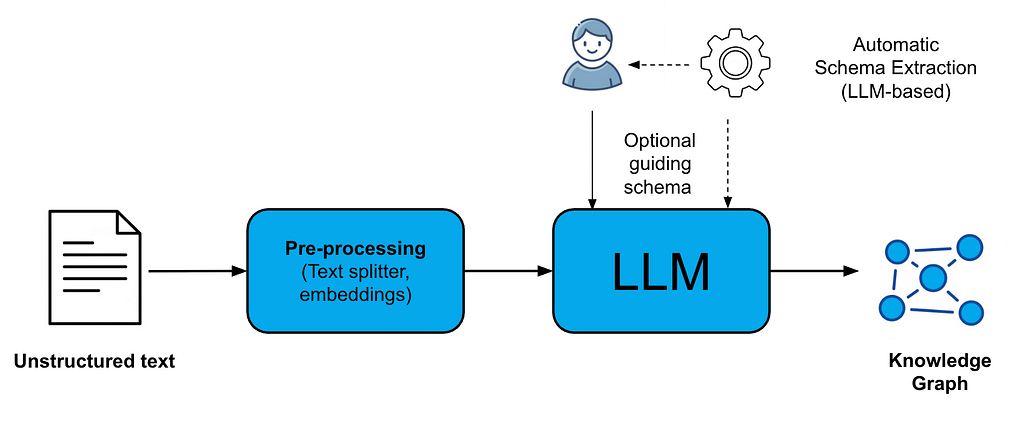
이 블로그에서는 이러한 각 기능을 자세히 살펴볼게요.
예: 사이버 위협 인텔리전스에 대한 Knowledge Graph 구성
사이버 위협 인텔리전스(CTI)는 잠재적이거나 진행 중인 사이버 위협에 대한 정보를 수집, 분석, 공유하여 사이버 공격을 사전에 식별, 완화, 대응하는 작업이에요.
CISA(Cybersecurity and Infrastructure Security Agency) 자문에서 다음과 같은 통찰력을 추출해 볼까요? AA21–287A: 미국 상하수 시스템에 대한 지속적인 사이버 위협. 이 문서는 물 인프라를 표적으로 삼는 위협 행위자를 설명하고 실제 사건을 나열하며 권장 완화 방법을 포함하고 있어요.
초보자를 위한: Knowledge Graph 구축을 안내하는 간편한 Schema 통합
Knowledge Graph를 처음 접하고 neo4j-graphrag Python 패키지를 이제 막 시작했다면 AA21–287A와 같은 권고에서 사이버 보안 Knowledge Graph를 구축하는 건 정말 간단해요.
선호하는 Embedding 모델, ERE 관련 매개변수와 함께 LLM, 결과 Knowledge Graph가 저장될 Neo4j Database 연결 세부 정보를 지정해서 파이프라인을 구성하기만 하면 돼요.
import neo4j
import os
from dotenv import load_dotenv
from neo4j_graphrag.embeddings import OpenAIEmbeddings
from neo4j_graphrag.llm import OpenAILLM
# This example requires adding OPENAI_API_KEY, and Neo4j connection details to a .env file
load_dotenv()
# Create the embedder instance
embedder = OpenAIEmbeddings()
# Create the llm instance
llm = OpenAILLM(
model_name="gpt-4o",
model_params={
"max_tokens": 2000,
"response_format": {"type": "json_object"},
"temperature": 0,
},
)
# Initialize the Neo4j driver
# If a local Neo4j dbms instance is used, this example requires the APOC plugin to be installed
URI = os.getenv("NEO4J_URI")
AUTH = (os.getenv("NEO4J_USER"), os.getenv("NEO4J_PASSWORD"))
driver = neo4j.GraphDatabase.driver(URI, auth=AUTH)SimpleKGPipeline을 실행해서 Embedder, LLM 및 Neo4j Driver 인스턴스를 사용하세요. 내부적으로 파이프라인은 관련 Nodes 및 Relationships 추출 시 LLM을 안내하는 Schema를 자동으로 추론한답니다.
from neo4j_graphrag.experimental.pipeline.kg_builder import SimpleKGPipeline
# Create a SimpleKGPipeline instance without providing a schema
# This will trigger automatic schema extraction
kg_builder = SimpleKGPipeline(
llm=llm,
driver=driver,
embedder=embedder,
from_pdf=True,
)
# Run the pipeline on the PDF file
await kg_builder.run_async(file_path="AA21–287A.pdf")자, 이제 권고에 설명된 주요 엔터티와 관계를 강조하는 Knowledge Graph가 생성될 거예요. 다음은 이런 그래프가 어떻게 표시되는지 보여주는 예시랍니다.
결과 그래프는 두 가지 보완적인 부분으로 구성되어 있어요.
- 어휘 하위 그래프는 텍스트를 덩어리(chunk)로 처리하는 것과 그 특성(예: Vector Embedding 등) 및 이들 간의 관계(예:
FROM_DOCUMENT,NEXT_CHUNK)를 나타내요. - 도메인 하위 그래프는 도메인(예: 사이버 보안) — 실제 개체(예:
Ransomware,Organization,ThreatActor)와 관련된 지식을 설명하고, 이들 사이의 관계(TARGETS,PROTECTS,USES)를 나타내죠.
그래프 모양에 대한 자세한 내용은 GraphRAG에서 확인해 보세요.
내부적으로 무슨 일이 일어나는지 궁금하다면 neo4j-graphrag를 사용하면 자세한 로깅을 활성화해서 문서에서 추론된 Schema를 포함하여 파이프라인의 각 단계를 검사할 수 있어요. 이렇게 하려면 파이프라인을 실행하기 전에 로깅을 구성하면 돼요.
import logging
# Set log level to Debug
logging.basicConfig()
logging.getLogger("neo4j_graphrag").setLevel(logging.DEBUG)로깅이 활성화되면 로그, 특히 SchemaFromTextExtractor 요소에서 JSON 형식의 Schema 출력을 볼 수 있을 거예요. 이 추론된 Schema에는 추출된 Node 유형, Relationship 유형, 선택적 Property 및 이러한 요소가 연결되는 방식을 설명하는 Pattern이 포함되어 있답니다. 예를 들어볼까요?
{
"node_types": [
{
"label": "Organization",
"description": "",
"properties": [
{
"name": "name",
"type": "STRING",
"description": "",
"required": false
}
],
"additional_properties": false
},
{
"label": "Facility",
"description": "",
"properties": [
{
"name": "location",
"type": "STRING",
"description": "",
"required": false
}
],
"additional_properties": false
},
{
"label": "ThreatActor",
"description": "",
"properties": [],
"additional_properties": true
},
{
"label": "Ransomware",
"description": "",
"properties": [],
"additional_properties": true
},
{
"label": "System",
"description": "",
"properties": [
{
"name": "type",
"type": "STRING",
"description": "",
"required": false
}
],
"additional_properties": false
}
],
"relationship_types": [
{
"label": "TARGETS",
"description": "",
"properties": [],
"additional_properties": true
},
{
"label": "USES",
"description": "",
"properties": [],
"additional_properties": true
},
{
"label": "PROTECTS",
"description": "",
"properties": [],
"additional_properties": true
}
],
"patterns": [
["ThreatActor", "TARGETS", "Facility"],
["ThreatActor", "USES", "Ransomware"],
["Organization", "PROTECTS", "Facility"],
["Facility", "USES", "System"]
],
"additional_node_types": false,
"additional_relationship_types": false,
"additional_patterns": false
}Schema가 추론되면 파이프라인은 다음 섹션에서 살펴볼 기본 시행 플래그도 연결한답니다.
그래프 전문가를 위한 팁: 다양한 스키마 수준에서 유연한 스키마 적용
전체 Knowledge Graph 파이프라인을 직접 구성하지 않고도 스키마를 더 효과적으로 제어하고 싶다면 SimpleKGPipeline을 사용해서 직접 스키마를 정의할 수 있어요. schema 파라미터를 사용하면 되는데요. 이렇게 하면 개발 경험은 간단하게 유지하면서도 추출되는 내용을 유연하게 구성할 수 있죠. 스키마는 다음 두 가지 방법으로 전달할 수 있어요.
- 사전(dictionary) 형태로:
node_types,relationship_types, 그리고patterns키를 정의하고, 각각 정의 목록을 넣어주는 거예요. 정의 목록은 연결 패턴을 나타내는 트리플과 함께 레이블만 간단하게 넣을 수도 있고, 설명이나 속성 목록처럼 자세하게 넣을 수도 있어요. - 리터럴로:
–“FREE”: 스키마 적용을 완전히 비활성화해요.
–“EXTRACTED”: 텍스트에서 자동으로 스키마를 추론하도록 설정해요.
NODE_TYPES = [
# Node types can be defined with a simple label
"Facility",
"Organization",
# or with a dict if more details are needed
# such as a description
{"label": "ThreatActor", "description": "Represents an individual, group, or organization responsible for carrying out or coordinating malicious cyber activities."},
# or a list of properties
{"label": "Ransomware", "properties": [{"name": "name", "type": "STRING", "required": True}, {"name": "family", "type": "STRING"}]},
]
# Same for relationships:
RELATIONSHIP_TYPES = [
"TARGETS",
{
"label": "USES",
"description": "Indicates that an entity is using a malware or tool to carry out an action on another entity.",
},
{"label": "PROTECTS", "properties": [{"name": "protectionLevel", "type": "STRING"}]},
]
PATTERNS = [
("ThreatActor", "TARGETS", "Facility"),
("ThreatActor", "USES", "Ransomware"),
("Organization", "PROTECTS", "Facility"),
]
kg_builder = SimpleKGPipeline(
llm=llm,
driver=driver,
embedder=embedder,
schema ={
"node_types": NODE_TYPES,
"relationship_types": RELATIONSHIP_TYPES,
"patterns": PATTERNS,
"additional_node_types": False,
},
# schema="EXTRACTED" # enable automatic schema extraction
# schema="FREE", # no guiding schema at all in the extraction process
from_pdf=True,
)스키마 요소를 정의하는 것 외에도, neo4j-graphrag Python 패키지를 사용하면 다양한 수준에서 스키마 적용을 제어할 수 있어요. 그래프를 구성할 때 모델의 출력이 정의를 얼마나 엄격하게 따라야 하는지 조절할 수 있다는 거죠. 스키마는 다음 레벨에서 적용할 수 있어요.
- 속성 레벨: Node나 Relationship type의 모든 속성을 필수로 지정할 수 있어요. 추출된 항목에 필수 속성이 없다면, 해당 항목은 그래프에서 제외돼요.
- Node/Relationship 레벨:
additional_properties를 사용해서 해당 Node/Relationship type에 대해 스키마에 명시적으로 정의되지 않은 추가 속성을 허용하거나 허용하지 않을 수 있어요. - 그래프 레벨:
additional_node_types,additional_relationship_types, 그리고additional_patterns를 사용해서 스키마에 명시적으로 정의되지 않은 Node, Relationship type, Pattern을 허용하거나 허용하지 않을 수 있어요.
경험적으로 봤을 때, 더 자세히 정의할수록 파이프라인이 더 엄격해지는 경향이 있어요. 예를 들어 Relationship type이나 Pattern 목록을 정의하면, 파이프라인은 명시적인 적용 플래그로 재정의하지 않는 한 사용자가 해당 항목만 사용하길 원한다고 생각하는 거죠.
예를 들어, 위에서 정의한 스키마를 사용해서 추출 프로세스를 안내한다면, 결과 그래프에는 스키마에 나열된 Node와 Relationship type만 포함될 거예요. Facility와 Organization Node의 경우, LLM이 식별한 추가 속성이 유지되겠죠. ThreatActor와 Ransomware의 경우에는 스키마에 명시적으로 정의된 속성만 포함될 거고요. 만약 Ransomware Node에 필수 항목인 name 속성이 없다면, 최종 그래프에서 완전히 제외될 거예요. Relationship 측면에서는 TARGETS와 USES에 추가 속성이 허용되지만, PROTECTS는 스키마에 정의된 속성만 포함하겠죠.
이런 계층적인 적용 방식을 통해 그래프의 품질과 정확도를 세밀하게 제어할 수 있다는 점, 정말 흥미롭죠?
추가적인 그래프 정리 작업 이해하기
사용자 정의 스키마 적용 설정을 기반으로 수행되는 정리 작업 외에도, Knowledge Graph 구성 파이프라인에는 최종 그래프의 일관성과 품질을 보장하는 데 도움이 되는 그래프 정리 작업이 내장되어 있어요. 어떤 것들이 있는지 한번 살펴볼까요?
- 빈 Label 및 Type을 가진 Node 및 Relationship 제거
- 남은 속성이 없는 Node 제거
- 그래프에서 source 또는 target `Node`가 더 이상 존재하지 않는 `Relationship` 삭제
- `Schema` 정의 패턴과 잘못 정렬된 경우 `Relationship` 방향 수정
정리 작업을 모니터링해서 최종 그래프가 어떻게 만들어지는지 더 잘 이해할 수 있어요. `Graph Pruner` 컴포넌트는 파이프라인 실행 중 작업을 기록하므로 특정 `Node`나 `Relationship`이 제외된 이유를 쉽게 추적할 수 있죠. 예를 들어, 위 경우에 ThreatActor `Node`가 추출되었지만 `Schema` 적용 후 유효한 속성이 없는 경우, 해당 `Node`가 정리되었음을 나타내는 다음 로그 항목이 나타날 수 있어요.
{
'pruning_stats': {
'pruned_nodes': [
{
'label': 'ThreatActor',
'item': {
'id': '82e2fc31-59a8-42d6-a88c-faadfc63863d:6',
'label': 'ThreatActor',
'properties': {},
'embedding_properties': None
},
'pruned_reason': 'NO_PROPERTY_LEFT',
'metadata': {}
}
]
}
}이러한 로그는 정리 논리에 대한 투명성을 제공해서 자신 있게 디버깅하고, `Schema`를 개선하거나 적용 수준을 조정하는 데 도움이 될 거예요.
고급 사용자의 경우: `Schema` 워크플로 맞춤설정
이미 패키지에 익숙하고 직접 파이프라인 구성을 선호하는 경우, `neo4j-graphrag`를 사용하면 직접 제작한 `Schema` 컴포넌트를 제공하든 상관없이 기본 파이프라인을 자신의 `Schema` 컴포넌트로 교체할 수 있어요. GraphSchema를 통해 객체 SchemaBuilder 또는 즉석에서 하나를 추론하는 SchemaFromTextExtractor를 사용하면 되죠. 이 접근 방식을 사용하면 `Knowledge Graph` 구성의 모든 측면을 세부적으로 제어할 수 있어요.
이 작업을 수행하는 이유:
- 기존 데이터 모델에 맞춰 정렬— 예를 들어, `Knowledge Graph`의 기반으로 관계형 데이터베이스 또는 기존 Neo4j 그래프에서 외부 `Schema`를 가져와요.
- `Schema` 추론 `Fine-tuning` - 예를 들어 자동 `Schema` 추출에 사용되는 기본 `LLM` 및 `Prompt` 템플릿을 재정의합니다 (모델에 "랜섬웨어 제품군 및 MITRE ATT&CK® 기술에 집중"하도록 지시할 수 있음).
- 반복 및 개선 - 텍스트에서 `Schema`를 생성하고 이를 JSON 파일에 저장하고 `Schema`를 조정한 다음 후속 추출 실행을 위해 다시 로드합니다 (사이버 보안과 같이 빠르게 발전하는 도메인에 이상적).
from neo4j_graphrag.experimental.components.pdf_loader import PdfLoader
from neo4j_graphrag.experimental.components.schema import SchemaFromTextExtractor, GraphSchema
from neo4j_graphrag.experimental.pipeline.kg_builder import SimpleKGPipeline
# Extract schema and save to JSON file or YAML file
schema_extractor = SchemaFromTextExtractor(llm=llm, prompt_template=custom_template)
inferred_schema = await schema_extractor.run(text=PdfLoader.load_file("AA21–287A.pdf")
inferred_schema.save(JSON_FILE_PATH)
# load schema and use it in the pipeline
schema = GraphSchema.from_file(JSON_FILE_PATH)
kg_builder = SimpleKGPipeline(
# ...
schema=schema,
# ...
)요약
`neo4j-graphrag` 1.8.0 Python 패키지는 자동 `Schema` 추론을 막 시작하든 사용자 지정 `Schema` 및 적용 규칙을 만드는 전문가이든 관계없이 모든 사람이 접근할 수 있는 `Schema` 중심 `Knowledge Graph` 구성을 제공해요. 강력한 `Schema` 지침과 세분화된 정리 기능을 결합하면 구조화되지 않은 데이터를 보다 정확하고 `Query` 가능한 그래프로 바꿀 수 있죠. 한번 시도해 보고 `Schema` 기반 추출이 `RAG` 및 QA 워크플로를 어떻게 개선할 수 있는지 알아보세요!
- 그래프RAG
- Schema
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'GraphRAG' 카테고리의 다른 글
| 벡터 인덱스와 비정형 데이터 입문 - 새로운 GraphAcademy 강좌 (0) | 2026.06.07 |
|---|---|
| BAML을 활용한 비정형 데이터의 Neo4j 그래프 데이터 변환 (0) | 2026.06.07 |
| 벡터 검색을 넘어: 더 똑똑한 추천을 위한 GraphRAG의 힘 발휘 (0) | 2026.06.06 |
| LightRAG 속살 파헤치기: Retrieval 집중 탐구 (0) | 2026.06.06 |
| LightRAG 속살 파헤치기: 추출 (Extraction) (0) | 2026.06.05 |