
부인 성명:Neo4j에서는 LightRAG를 GraphRAG로 분류된 기술로 봅니다. 현재 LightRAG가 실제 기업 환경에서 의미 있는 개선을 제공한다는 것을 보여주는 프로덕션 수준 통계는 없어요.
이 블로그 시리즈의 두 번째 부분에서는 LightRAG 검색 엔진이 어떻게 작동하는지 자세히 살펴볼게요. 혹시 여기로 바로 오셨다면, 첫 번째 글을 확인해 보세요. LightRAG가 구조화되지 않은 문서를 구조화된 지식으로 변환하는 방법을 다뤘거든요. 자동차를 운전하기 전에 엔진이 어떻게 작동하는지 배우는 것과 같다고 생각하면 돼요.
TL;DR
- 다양한 각도에서 종합적인 답변을 얻으세요: LightRAG는 두 가지 검색을 동시에 실행해요. 하나는 사용자의 관계 패턴을 따르는 Knowledge Graph이고, 다른 하나는 Vector Embedding 저장소에서 의미상 유사한 콘텐츠를 찾는 거예요. 그런 다음 두 검색 모두 검색된 정보를 기반으로 Key-Value 저장소를 활용해서 저장된 메타데이터로 컨텍스트를 강화하죠.
- 질문이 더 자연스럽게 이해됩니다.: LightRAG는 기본적인 키워드 매칭이나 사용자 Query 기반의 순수 Semantic Search 대신, 사용자의 질문에서 두 가지 유형의 키워드, 즉 상위 테마(Query가 무엇에 대한 것인지)에 대한) 및 낮은 수준의 세부 사항(누가 또는 무엇인지에 대한)을 추출해요. 이는 큰 그림과 중요한 세부 사항을 모두 이해하는 데 도움이 되며 검색이 더욱 정확하고 상황에 맞게 만들어진다는 거죠.
- 당신이 알고 있는 것 중 가장 중요한 것의 우선순위를 정하세요: LightRAG는 단순히 관련 정보를 찾는 것이 아니라 Knowledge Network에서 사물이 얼마나 잘 연결되어 있고 중심에 있는지에 따라 우선 순위를 정해요. 먼저 개념 간의 다리 역할을 하는 가장 영향력 있는 Relationship과 Entity를 표면화하죠. 이렇게 하면 가장 유사한 텍스트뿐만 아니라 가장 중요한 컨텍스트를 얻을 수 있어요.
검색 프로세스: 이중 수준 하이브리드 전략
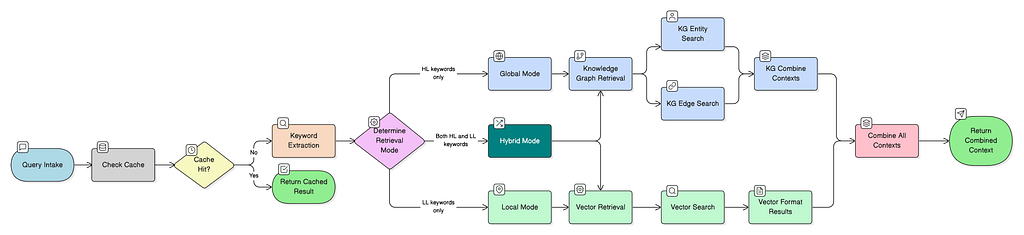
LightRAG에서 사용되는 검색 전략은 Graph Traversal과 Semantic Vector 유사성을 결합해요. 이 하이브리드 접근 방식은 정확하고 설명 가능한 것을 목표로 하며, 이는 상황별 깊이와 추적성이 필요한 작업에 이상적이죠. 이번 글에서는 하이브리드 검색 전략에 중점을 둘 거예요.
개요: 두 개의 병렬 검색 경로
LightRAG의 혼합 모드에서는 검색이 두 개의 병렬 경로를 따라 발생해요.
(A) get_kg_context()는 지식을 그래프 및 주변 문서에서 검색해요:
- 이중 레벨 키워드 Semantic Search
- Entity 및 Relationship에 대한 Graph Traversal
(B) get_vector_context()는 데이터를 Semantic 일치를 사용해서 검색해요:
- 전체 Query 임베딩(선택적 채팅 기록 포함)
- 원시 문서 덩어리 전체에 대한 순수 Vector 유사성 검색
# lightrag/operate.py
kg_context, vector_context = await asyncio.gather(
get_kg_context(), get_vector_context()
)이중 레벨 키워드 추출
이 프로세스의 가장 흥미로운 측면 중 하나는 LightRAG가 저자가 부르는 개념을 사용하여 사용자의 Query를 처리하는 방법이에요. 바로 이중 레벨 키워드 추출이죠. 이 접근 방식에서 LLM은 아래 프롬프트에 표시된 대로 두 개의 보완적인 키워드 세트('상위 수준 및 하위 수준 키워드')를 추출하라는 메시지를 받아요.
# lightrag/prompts.py
PROMPTS["keywords_extraction"] = """---Role---
You are a helpful assistant tasked with identifying both high-level and low-level keywords in the user's query and conversation history.
---Goal---
Given the query and conversation history, list both high-level and low-level keywords. High-level keywords focus on overarching concepts or themes, while low-level keywords focus on specific entities, details, or concrete terms.
---Instructions---
- Consider both the current query and relevant conversation history when extracting keywords
- Output the keywords in JSON format, it will be parsed by a JSON parser, do not add any extra content in output
- The JSON should have two keys:
- "high_level_keywords" for overarching concepts or themes
- "low_level_keywords" for specific entities or details
######################
---Examples---
######################
{examples}
#############################
---Real Data---
######################
Conversation History:
{history}
Current Query: {query}
######################
The `Output` should be human text, not unicode characters. Keep the same language as `Query`.
Output:
"""- 상위 수준 키워드: 개념 또는 테마
- 하위 수준 키워드: 엔터티 또는 용어
사용자 쿼리가 다음과 같다고 가정해 볼게요.
“생물 다양성에 대한 삼림 벌채의 환경적 결과는 무엇입니까?”
{
"high_level_keywords": ["Environmental consequences", "Deforestation", "Biodiversity loss"],
"low_level_keywords": ["Species extinction", "Habitat destruction", "Carbon emissions", "Rainforest", "Ecosystem"]
}상위 수준 키워드는 LightRAG가 쿼리 내용이 무엇인지 이해하도록 도와줘요. 하위 수준 키워드는 LightRAG가 누구에 관한 것인지, 무엇에 관한 것인지 식별하도록 돕죠. 이들은 함께 설명 가능하고 의미가 풍부한 하이브리드 검색 전략을 추진한답니다.
(A) 이중 레벨 키워드 검색
LightRAG는 Semantic Search와 그래프의 기능을 혼합하여 근거 있고 설명 가능하며 유연한 검색을 지원하는 하이브리드 접근 방식을 사용해요. 두 경로 모두 1) 의미론적으로 관련된 콘텐츠를 표면화하기 위해 벡터 유사성을 활용하고 2) 그래프 순회 및 메타데이터로 이를 강화하죠. 맥락에 따라 아래 논의는 Neo4j의 구현을 기반으로 합니다.

1) 상위 수준 키워드 — 관계 중심 컨텍스트 검색
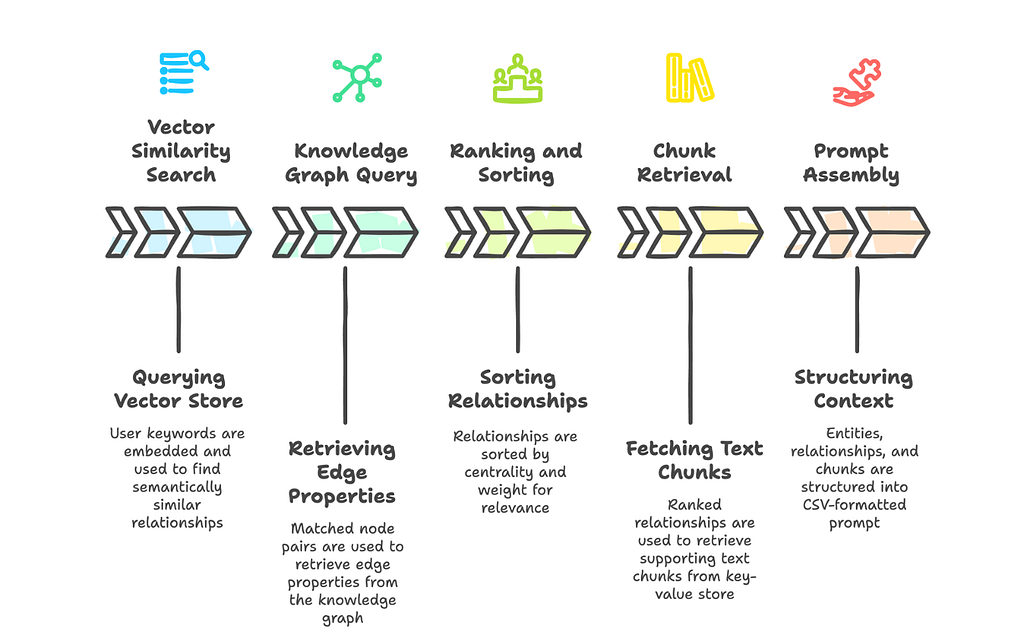
이중 레벨 추출 프로세스에서 각 관계는 상위 수준 키워드를 사용하여 요약됩니다. 추출 프롬프트에서 키워드는 표면적인 세부사항이 아닌 연결의 전반적인 특성을 요약하는 추상적인 용어를 나타내요.
1단계: 벡터 유사성 검색
이러한 삽입된 콘텐츠 문자열은 이전에 추출 파이프라인 중에 벡터 저장소에서 인덱싱되었어요.
# For relationship
content = f"{src_id}\t{tgt_id}\n{keywords}\n{description}"사용자의 쿼리에서 추출된 상위 키워드는 쿼리 임베딩으로 변환되며, 이는 정확한 키워드가 표시되지 않더라도 벡터 유사성 비교에 사용되어 의미상 관련 있는 관계를 찾습니다.
#lightrag/operate.py
results = await relationships_vdb.query(
keywords, top_k=query_param.top_k, ids=query_param.ids
)2단계: Knowledge Graph에서 관계/에지 속성 검색
벡터 유사성 검색 결과와 함께 Node 쌍(src_id and tgt_id) 일치하는 두 Node 사이의 실제 Edge에 대한 Knowledge Graph를 Query합니다. 이렇게 하면 가중치, 설명, 키워드 등 모든 Edge 속성이 반환됩니다.source_id.
#lightrag/kg/neo4j_impl.py
query = """
MATCH (start:base {entity_id: $source_entity_id})-[r]-(end:base {entity_id: $target_entity_id})
RETURN properties(r) as edge_properties
"""
3a단계: 관계의 그래프 중요성 정량화
관계에 관련된 각 소스 Node와 대상 Node 쌍의 정도를 검색합니다. Edge의 결합된 중심성을 나타내기 위해 각도의 합을 계산해요.
#lightrag/kg/neo4j_impl.py
query = """
MATCH (n:base {entity_id: $entity_id})
OPTIONAL MATCH (n)-[r]-()
RETURN COUNT(r) AS degree
"""3b단계: 순위 및 가중치를 기준으로 관계 정렬
강화된 관계는 두 개의 Key를 사용하여 내림차순으로 정렬됩니다.
- 순위 — Node의 중심 정도(도의 합)
- 가중치 — 관계가 얼마나 강한지(이전 추출에서)
이렇게 하면 LLM이 판단한 대로 잘 연결되고 관련성이 높은 관계가 먼저 표시되죠.
이것을 기억하세요. weight 속성은 이전에 추출된 항목을 기반으로 하는
relationship_strength점수인데, 하드 데이터가 아닌 LLM의 해석에서 나온 점수라는 점! 마치 누군가에게 “이 두 사람이 얼마나 친하다고 생각하시나요?”라고 묻는 것과 같아요. 실제 상호작용을 계산하는 것이 아니라 LLM은 맥락을 바탕으로 정보에 기반한 추측을 하고 있는 거죠.
#lightrag/operate.py
edge_datas = sorted(
edge_datas, key=lambda x: (x["rank"], x["weight"]), reverse=True
)이 프로세스는 생성된 답변이 단순히 정보뿐만 아니라 그래프 내에서 정보가 되도록 도와줘요.
3c단계: Knowledge Graph에서 Node 속성 검색
관계를 정렬한 후 최상위 Edge에 포함된 각 고유 엔터티에 대한 메타데이터가 검색됩니다. 여기에는 다음과 같은 속성이 포함됩니다. entity_type and description.
#lightrag/kg/neo4j_impl.py
query = "MATCH (n:base {entity_id: $entity_id}) RETURN n"
...
node = records[0]["n"]
node_dict = dict(node) # Node metadata returned
...
return node_dict비슷하게, node_degree는 후속 순위를 위해 각 엔터티 쌍에 대해 계산됩니다. 조립된 토큰의 총 크기가 max_token_size 한도를 초과하면 토큰 크기를 제한하기 위해 결과가 잘립니다.
#lightrag/operate.py
node_datas = [
{**n, "entity_name": k, "rank": d}
for k, n, d in zip(entity_names, node_datas, node_degrees)
if n is not None
]4단계: Key-Value 저장소에서 텍스트 청크 검색
순위가 매겨진 관계를 사용하여 (edge_datas, 3b단계) 각 관계의 청크 ID (source_id, 다음과 같이 보일 수 있습니다: chunk-001|||chunk-002")는 구분 기호를 기준으로 분할되고 Key-Value 저장소에서 검색되어 전체 청크 메타데이터를 검색합니다. 그런 다음 최종 출력은 순위가 매겨진 관계의 원래 순서를 기준으로 정렬된 다음, max_token_size를 초과하는 경우 잘립니다.
#lightrag/operate.py
async def fetch_chunk_data(c_id, index):
if c_id not in all_text_units_lookup:
chunk_data = await text_chunks_db.get_by_id(c_id)
# Only store valid data
if chunk_data is not None and "content" in chunk_data:
all_text_units_lookup[c_id] = {
"data": chunk_data,
"order": index,
}5단계: Node, 관계, 청크 컨텍스트 결합
검색 후:
- 상위 수준 키워드를 통해 의미적으로 일치하는 관계
- Knowledge Graph의 해당 Edge 메타데이터
- 해당 Edge(소스 및 대상 Node)와 관련된 항목
- 해당 엔터티 및 관계를 참조하거나 지원하는 문서 청크
변환은 세 가지 섹션으로 구성된 Prompt 준비 구조적 컨텍스트를 조합합니다.
#lightrag/operate.py
# structuring entities
entites_section_list.append(
[
i,
n["entity_name"],
n.get("entity_type", "UNKNOWN"),
n.get("description", "UNKNOWN"),
n["rank"],
created_at,
file_path,
]
)
entities_context = list_of_list_to_csv(entites_section_list)
...
# structuring relationships
relations_section_list = [
[
"id",
"source",
"target",
"description",
"keywords",
"weight",
"rank",
"created_at",
"file_path",
]
]
relations_context = list_of_list_to_csv(relations_section_list)
...
# structuring chunks
text_units_section_list = [["id", "content", "file_path"]]
text_units_context = list_of_list_to_csv(text_units_section_list)
...
return entities_context, relations_context, text_units_context이 코드는 CSV 형식의 문자열 블록으로 반환되는데, 이게 꽤 괜찮은 방법 같아요. 왜냐하면 이전에 강조했던 것처럼, 에서도 나오듯이 모델이 쉽게 구문 분석하고, 추론하고, 응답을 생성할 수 있거든요.
#lightrag/operate.py
# structuring entities
entites_section_list.append(
[
i,
n["entity_name"],
n.get("entity_type", "UNKNOWN"),
n.get("description", "UNKNOWN"),
n["rank"],
created_at,
file_path,
]
)
entities_context = list_of_list_to_csv(entites_section_list)
...
# structuring relationships
relations_section_list = [
[
"id",
"source",
"target",
"description",
"keywords",
"weight",
"rank",
"created_at",
"file_path",
]
]
relations_context = list_of_list_to_csv(relations_section_list)
...
# structuring chunks
text_units_section_list = [["id", "content", "file_path"]]
text_units_context = list_of_list_to_csv(text_units_section_list)
...
return entities_context, relations_context, text_units_context2) 하위 수준 키워드 — 엔티티 중심 컨텍스트 검색

비슷하게, 이중 수준 추출 과정에서 각 엔터티는 하위 수준 키워드를 사용해서 요약돼요. 여기서 하위 수준 키워드란 사용자의 검색어에 직접 언급된 특정 명사, 용어, 또는 개념을 말하죠. 이러한 하위 수준 키워드는 Knowledge Graph에서 의미적으로, 구조적으로 가장 관련성이 높은 Node가 표시되는 엔터티 중심 검색을 구동하는 역할을 해요.
1단계: Vector 유사성 검색
각 항목의 콘텐츠 문자열은 아래 형식을 사용해서 추출 파이프라인 중에 Vector 저장소에 삽입돼요.
# For entities
content = f"{entity_name}\n{description}"
# e.g., "Alex\nAlex is a character..."상위 수준 관계 임베딩과 마찬가지로, 이러한 엔터티 Vector는 Vector 저장소에 미리 Indexing되어 있어요. 하위 수준 키워드는 Query 시간에 포함되어 이 Index와 비교되고, 의미상 유사한 엔터티/Node를 검색하게 되죠.
# lightrag/operate.py
results = await entities_vdb.query(
query, top_k=query_param.top_k, ids=query_param.ids
)2단계: Knowledge Graph에서 Node 속성 검색
Vector 유사성 결과가 반환되면, 일치하는 각 엔터티/Node를 Knowledge Graph에서 조회해서 해당 속성을 검색해요.
#lightrag/kg/neo4j_impl.py
query = "MATCH (n:base {entity_id: $entity_id}) RETURN n"
...
node = records[0]["n"]
node_dict = dict(node) # Node metadata returned
...
return node_dict3a단계: 항목의 그래프 중요성 정량화
관계의 순위가 Edge 중심성에 따라 결정되는 것처럼, 항목의 순위는 Node가 갖는 관계 수를 기반으로 계산되는 Node 등급에 따라 결정돼요.
#lightrag/kg/neo4j_impl.py
query = """
MATCH (n:base {entity_id: $entity_id})
OPTIONAL MATCH (n)-[r]-()
RETURN COUNT(r) AS degree
"""고도로 연결된 Node는 Multi-hop 추론에서 영향력이 있거나 브리지 역할을 할 가능성이 더 높아요.
3b단계: 등급(순위)을 기준으로 항목 정렬
각 엔터티에는 Node 등급에 따라 순위가 할당돼요. 항목 목록은 정의된 토큰 한도에 따라 정렬된 다음 잘립니다.
# lightrag/operate.py
node_datas = [
{**n, "entity_name": k, "rank": d}
for k, n, d in zip(entity_names, node_datas, node_degrees)
if n is not None
]3c단계: Knowledge Graph에서 관련 관계 검색
엔터티 컨텍스트를 강화하려면 다음 중 하나를 수행하세요.–검색된 각 엔터티에 대해 홉 관계가 수집돼요. 각 항목 이름에 대해 단일 홉 에지를 검색하여 Node 쌍 목록을 제공하죠.
#lightrag/kg/neo4j_impl.py
query = """MATCH (n:base {entity_id: $entity_id})
OPTIONAL MATCH (n)-[r]-(connected:base)
WHERE connected.entity_id IS NOT NULL
RETURN n, r, connected"""
...
source_label = (
source_node.get("entity_id")
if source_node.get("entity_id")
else None
)
target_label = (
connected_node.get("entity_id")
if connected_node.get("entity_id")
else None
)
if source_label and target_label:
edges.append((source_label, target_label))
...
return edges각각의 고유한 Node 쌍 집합에 대해 Edge/관계 메타데이터는 Edge 등급 정보(소스 및 대상 Node의 등급 합계)와 동시에 가져와요.
#lightrag/operate.py
all_edges_pack, all_edges_degree = await asyncio.gather(
asyncio.gather(*[knowledge_graph_inst.get_edge(e[0], e[1]) for e in all_edges]),
asyncio.gather(
*[knowledge_graph_inst.edge_degree(e[0], e[1]) for e in all_edges]
),
)Edge 속성 검색을 위한 Cypher Query:
#lightrag/kg/neo4j_impl.py
query = """
MATCH (start:base {entity_id: $source_entity_id})-[r]-(end:base {entity_id: $target_entity_id})
RETURN properties(r) as edge_properties
"""Edge 메타데이터와 Edge 등급 점수가 수집된 후 각 관계는 소스 및 대상 Node, 설명, 계산된 순위 및 가중치를 포함하는 사전으로 표시돼요. 그런 다음 이러한 관계는 먼저 순위(즉, 중심도)를 기준으로 내림차순으로 정렬된 다음 가중치를 기준으로 정렬된 다음 최종 컨텍스트에 추가되죠.
#lightrag/operate.py
all_edges_data = [
{"src_tgt": k, "rank": d, **v}
for k, v, d in zip(all_edges, all_edges_pack, all_edges_degree)
if v is not None
]
all_edges_data = sorted(
all_edges_data, key=lambda x: (x["rank"], x["weight"]), reverse=True
)이 정렬 프로세스는 영향력이 큰 관계를 식별하는 데 필수적이에요.
4단계: 키-값 저장소에서 텍스트 청크 검색
관계 기반 접근 방식과 유사하게 이 대체 구현은 텍스트 청크를 검색하지만 관계가 아닌 순위가 지정된 엔터티 Node에서 시작해요. 두 접근 방식 모두 다음을 따릅니다.동일한 핵심 패턴:
- 소스 필드에서 청크 ID 추출
- 키-값 저장소에서 전체 청크 데이터 검색
- 관련성을 기준으로 정렬하고 정의된 토큰 한도에 따라 잘라냅니다.
The 이 구현에는 관계 분석이 있다는 거예요. 첫 번째 접근 방식은 관계에서 참조되는 청크를 직접 검색하는 반면, 이 버전은 다음과 같아요.
- Knowledge Graph에서 1홉 인접 엔터티를 식별합니다.
- 각 청크의 관계 발생 횟수를 계산합니다.
- 이러한 개수를 추가 순위 요소로 사용합니다.
최종 출력은 원래 엔터티 순위 순서에 따라 먼저 정렬된 다음 관계 밀도에 따라 정렬되어 여러 엔터티를 연결하는 청크의 우선 순위가 지정됩니다.
#lightrag/operate.py
# Sort by entity order and relationship density
all_text_units = sorted(
all_text_units, key=lambda x: (x["order"], -x["relation_counts"])
)
# Truncate to respect token limits
all_text_units = truncate_list_by_token_size(
all_text_units,
key=lambda x: x["data"]["content"],
max_token_size=query_param.max_token_for_text_unit,
)
항목 중심 경로의 독특한 점은 청크 점수 매기기에 그래프 이웃 중첩이 통합된다는 것이에요.
5단계: Node, Relationship, 청크 컨텍스트 결합
엔터티 또는 Relationship이 검색의 시작점 역할을 했는지 여부에 관계없이 두 가지 접근 방식 모두 검색 출력의 사후 처리에서 유사해요. 그런 다음 이러한 구성 요소는 최종적으로 구조화되고 프롬프트 가능한 CSV 형식의 컨텍스트로 변환되죠. 각 구성요소가 추출되고 조합되는 방법에 대한 자세한 설명은 위의 관계 중심 컨텍스트 검색 섹션의 5단계를 참조하세요.
결합된 컨텍스트 — 관계 중심 및 엔터티 중심
하위 수준(엔티티) 및 상위 수준(Relationship) 키워드를 모두 사용하여 컨텍스트를 별도로 검색한 후 결합된 컨텍스트는 다시 정리되고 중복이 제거되며 CSV 형식의 문자열 블록으로 재결합됩니다.
#lightrag/utils.py
def process_combine_contexts(hl: str, ll: str):
header = None
list_hl = csv_string_to_list(hl.strip())
list_ll = csv_string_to_list(ll.strip())
...
combined_sources = []
seen = set()
for item in list_hl + list_ll:
if item and item not in seen:
combined_sources.append(item)
seen.add(item)
...
for i, item in enumerate(combined_sources, start=1):
combined_sources_result.append(f"{i},\t{item}")
return "\n".join(combined_sources_result)
(B) 순수 Semantic Vector Similarity Retrieval
이중 레벨 키워드 검색(섹션 A에서 논의됨)이 Knowledge Graph를 통한 검색에 초점을 맞추는 반면, LightRAG는 동시에 Semantic Search를 병렬로 실행합니다.
1단계: 대화 기록을 사용한 쿼리 확대
Vector Search의 대화 내용을 더욱 잘 인식할 수 있도록 사용자의 현재 쿼리가 대화 기록으로 보강됩니다.
#lightrag/operate.py
async def get_vector_context():
# Consider conversation history in vector search
augmented_query = query
if history_context:
augmented_query = f"{history_context}\n{query}"
...
대화 기록을 추가하는 것은 진행 중인 의도, 주제 연속성 및 이전 턴의 암시적 참조를 캡처하는 것을 목표로 하며 이는 다중 턴 상호 작용에 유용할 수 있어요.
2단계: Vector 저장소 및 키-값 저장소를 통한 검색
그런 다음 증강된 쿼리가 내장되어 사전 인덱싱된 Vector 저장소에서 의미상 유사한 청크를 검색하는 데 사용됩니다. 각 결과에 대해 실제 콘텐츠도 고유한 청크 ID를 사용하여 키-값 저장소에서 검색됩니다.
#lightrag/operate.py
# Reduce top_k for vector search in hybrid mode since we have structured information from KG
mix_topk = min(10, query_param.top_k)
results = await chunks_vdb.query(
augmented_query, top_k=mix_topk, ids=query_param.ids
)
if not results:
return None
# key-value chunk lookup
chunks_ids = [r["id"] for r in results]
chunks = await text_chunks_db.get_by_ids(chunks_ids)
하이브리드 모드에서 실행할 때 Vector Search는 더 작은 크기를 사용합니다.top_kKnowledge Graph는 이미 구조화된 정보를 제공하기 때문에 가치가 있죠.
3단계: 청크 메타데이터 강화
다음으로 각 청크의 형식을 지정하고 중요한 메타데이터를 강화해 줄 거예요.
#lightrag/operate.py
# Include time information in content
formatted_chunks = []
for c in maybe_trun_chunks:
chunk_text = "File path: " + c["file_path"] + "\n" + c["content"]
if c["created_at"]:
chunk_text = f"[Created at: {time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(c['created_at']))}]\n{chunk_text}"
formatted_chunks.append(chunk_text)
...
return "\n--New Chunk--\n".join(formatted_chunks)청크는 다음과 같이 신중하게 형식화되는데요. --New Chunk--는 청크 간 컨텍스트 블리딩을 방지하고 타임스탬프를 기반으로 한 추적을 용이하게 하는 구분 기호랍니다.
하이브리드 검색 결과 결합
이제 Knowledge Graph와 문서 청크 벡터 검색 경로 모두에서 결과를 가져왔으니, 이 두 검색 결과를 신중하게 합쳐볼 차례에요. 이 단계는 답변 생성 프롬프트가 만들어지기 전 검색 파이프라인의 마지막 단계라고 할 수 있죠.
#lightrag/prompts.py
sys_prompt = PROMPTS["mix_rag_response"].format(
kg_context=kg_context or "No relevant knowledge graph information found",
vector_context=vector_context or "No relevant text information found",
response_type=query_param.response_type,
history=history_context,
)
PROMPTS["mix_rag_response"] = '''
---Role---
You are a helpful assistant responding to user query about Data Sources provided below.
---Goal---
Generate a concise response based on Data Sources...
---Conversation History---
What did we discuss about deforestation last time?
---Data Sources---
1. From Knowledge Graph(KG):
Alex → Taylor: "Power dynamic conflict" [2023-10-15], weight: 7
2. From Document Chunks(DC):
[Created at: 2023-11-12 14:02:31]
File path: reports/biodiversity_impacts.txt
Deforestation disrupts ecosystems and can lead to extinction-level threats...
---Response Rules---
- Use markdown formatting with appropriate section headings
- Organize in sections like: **Causes**, **Consequences**, **Recent Observations**
- Reference up to 5 most important sources with `[KG/DC] file_path`
'''이 접근 방식은 Large Language Model(LLM)에 구조화된 Knowledge Graph 정보와 구조화되지 않은 벡터 검색 콘텐츠를 모두 제공해서, 사용자 쿼리에 대한 보완적인 관점을 제공하는 데 도움이 돼요.
- Knowledge Graph 컨텍스트: 명확한 구조를 지닌 명시적인 실체, 관계, 그리고 이를 뒷받침하는 사실들이죠.
- : 전체 텍스트 컨텍스트와 더 넓은 Semantic Search를 가능하게 해줘요.
- Knowledge Graph는 명시적인 관계와 구조화된 정보를 포착하는 데 탁월하죠.
- 벡터 검색은 의미적 유사성과 암시적 연결을 포착하는 데 아주 뛰어나고요.
결과적으로 만들어진 하이브리드 컨텍스트는 사용자 쿼리에 대해 더 포괄적이고 정확하며 상황에 맞는 응답을 제공할 수 있게 되는 거랍니다.
요약
LightRAG는 Knowledge Graph 기반 추론과 Semantic Search를 결합해서 학문적 환경에서는 점진적인 개선을 보여줄 수 있지만, 아직까지는 확실한 생산 수준의 결과가 입증되지는 않았어요. LightRAG는 좀 더 성숙하고 광범위한 환경 내에서 하나의 제한적인 구현 사례라고 볼 수 있죠. 그래프RAG 생태계 말이에요.
LightRAG를 특별하게 만들어주는 점은 그래프 구조를 사용해서 정보의 우선순위를 정하는 방식인데요. 그래프에 사실을 저장하는 대신, 연결 패턴을 사용해서 가장 중요한 것이 무엇인지 결정하는 거죠. 이는 시스템이 단순히 키워드 일치 항목을 찾는 게 아니라, 가장 관련성이 높은 정보를 먼저 보여준다는 의미랍니다.
실질적인 이점은 분명해요. 유연한 설계 덕분에 모든 것을 다시 구축하지 않아도 새로운 정보를 추가할 수 있다는 점이죠. 이는 지식이 끊임없이 진화하는 비즈니스에 특히 유용할 거예요.
다음 단계
Under the Covers With LightRAG: Neo4j가 LightRAG를 만나다의 마지막 기사도 계속해서 지켜봐 주세요! 이 기사에서는 지금까지 다룬 내용을 모두 통합하고, Neo4j를 사용한 LightRAG 구현을 자세히 안내해 드릴 예정이랍니다.
다음에 또 만나요!
- GraphRAG
- LightRAG
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'GraphRAG' 카테고리의 다른 글
| 스키마의 힘을 깨우다: Python용 Neo4j GraphRAG 패키지의 새로운 기능 (0) | 2026.06.06 |
|---|---|
| 벡터 검색을 넘어: 더 똑똑한 추천을 위한 GraphRAG의 힘 발휘 (0) | 2026.06.06 |
| LightRAG 속살 파헤치기: 추출 (Extraction) (0) | 2026.06.05 |
| 정적인 위험 평가를 역동적인 데이터 기반 전략으로 혁신하기 (0) | 2026.06.05 |
| RAG 애플리케이션의 더 나은 시맨틱 검색을 위한 Neo4j GDS 기반 토픽 추출 (0) | 2026.06.05 |