
The Neo4j LLM 지식 그래프 빌더는 PDF 파일이나 웹 소스를 업로드하고, LLM을 사용해서 그래프 생성을 쉽게 할 수 있도록 사용자 친화적인 인터페이스를 제공해요. 게다가, 만들어진 Knowledge Graph를 활용한 채팅 경험, 즉 GraphRAG 리트리버도 제공하죠. 이번 블로그 포스팅에서는 이 도구의 프론트엔드 아키텍처에 대해 자세히 알아볼 거예요. (첫 Knowledge Graph를 구축하는 방법은 개발자 가이드: Knowledge Graph 구축 방법에서 단계별로 확인해 보세요!)

이 도구를 어떻게 사용하는지 짧은 영상으로 한번 살펴볼까요?
시작하기
LLM 지식 그래프 빌더 UI는 애플리케이션 로직과 컴포넌트에 React를 사용하고, 네트워크 호출 및 응답을 처리하기 위해 Axios를 사용하며, 실시간 데이터 업데이트를 위해 Long Polling 또는 Server-Sent Events (SSE)를 사용해요. Neo4j의 Needle Design System을 기반으로 하는 Tailwind CSS 또는 스타일 컴포넌트가 CSS 디자인을 담당하죠.
React Context API는 상태 관리를 맡고 있어요. UI는 Knowledge Graph 구축 과정과 채팅 경험의 각 단계를 사용자에게 안내하기 때문에, 다양한 기술 수준을 가진 사용자들이 쉽게 접근하고 사용할 수 있답니다.
UI 아키텍처 및 컴포넌트
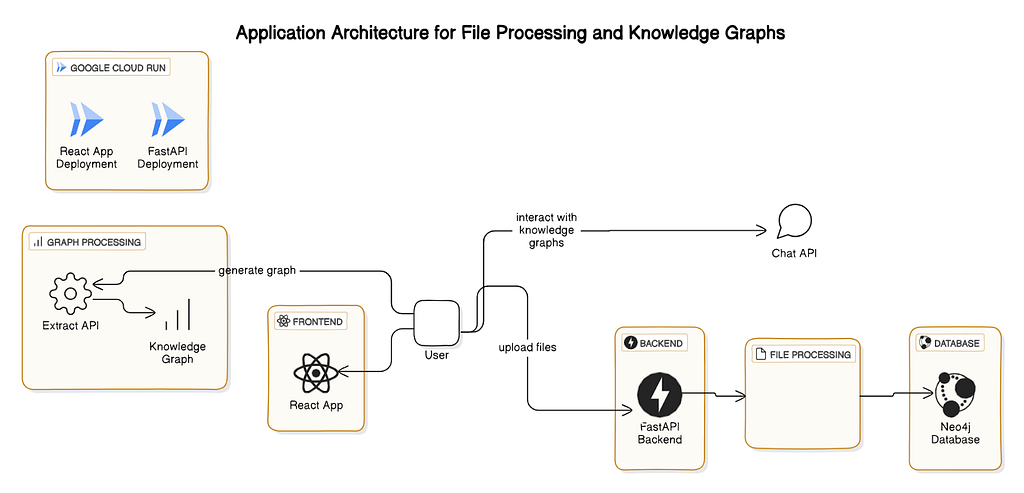
LLM Knowledge Graph Builder의 경우 다음 기술을 사용하고 있어요.
- React — 애플리케이션 로직
- Axios — 네트워크 통화 및 응답 처리용
- Styled Components — 모든 CSS를 작성하는 JavaScript에서 CSS를 처리해요. 또는 개발 속도를 높이기 위해 타사 CSS 클래스를 제공하는 Tailwind CSS
- Long Polling — Long Polling은 클라이언트와 서버 간의 안정적인 연결을 유지하는 간단한 방법이에요. 응답이 없으면 일정 기간 동안 요청을 보류하죠. 정기적으로 클라이언트에 새로운 정보를 업데이트하고 상태를 업데이트하며 매분마다 새로운 데이터로 청크를 처리합니다.
- SSE — Server-Sent Events는 서버가 루프에서 데이터를 생성하고 여러 이벤트를 클라이언트에 보내는 경우, 또는 서버에서 클라이언트로의 실시간 트래픽이 필요한 경우 가장 좋은 옵션이에요.
- React Context API — 상태 처리용; 애플리케이션이 복잡하지 않기 때문에 전역 상태 관리를 위해 Context API를 사용하고 있어요.
Needle Design System
저희는 Neo4j를 사용했어요. Needle Design System은 모든 Neo4j UI, 제품 도구 및 웹 페이지에 사용되는데요. 이에 따라 웹 접근성 등 웹의 업계 표준 지침을 준수하며, 애플리케이션에 통합된 사용자 친화적인 디자인 토큰, 색상 및 구성 요소를 제공해요. 또한 애플리케이션에서 따르는 패턴과 일반적인 UX 작성 표준이 포함되어 있죠.
The Neo4j Needle Starter Kit은 개발 속도를 높이는 데 도움이 되었어요. React 스타터 키트는 Neo4j Needle Design System으로 애플리케이션을 구축하여 Neo4j 기반 프런트엔드 애플리케이션의 가치 실현 시간을 가속화하는 데 사용되죠. 또한 기능에 따라 조정할 수 있는 기본 확장 가능한 구성 요소를 제공해요.
사용자 친화적인 인터페이스는 Neo4j Aura 연결, 파일 소스 액세스, PDF 파일 업로드, 그래프 생성, 그래프 시각화 및 채팅 인터페이스를 통해 사용자를 안내합니다.
- Neo4j Needle Design System 구성 요소
- Neo4j Visualization Library
- CSS: 인라인 스타일 지정, Tailwind CSS
Needle Design System은 기본적으로 어두운 테마, 밝은 테마 등을 지원하므로 개발자의 삶이 더욱 편리해져요.
이용 흐름
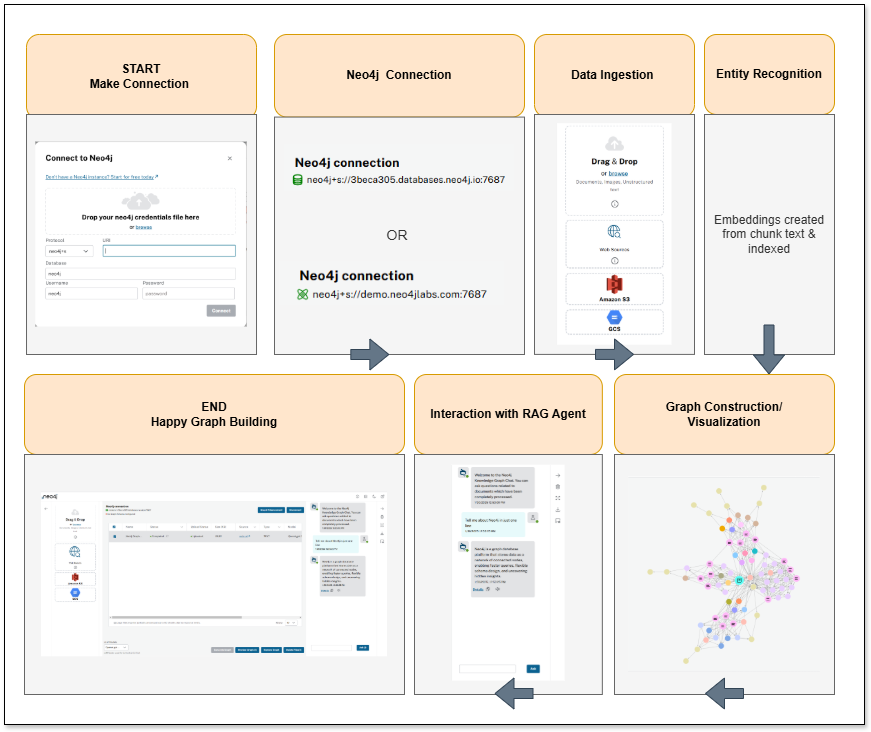
단계
1단계. 연결 시작
사용자 작업: 사용자는 애플리케이션을 시작하여 프로세스를 시작해요. 여기에서 도구를 열고 UI와 상호작용을 시작할 수 있죠.
2단계. Neo4j 연결
사용자 작업: 사용자는 Neo4j 데이터베이스와의 연결을 설정하는 데 필요한 자격 증명과 연결 세부 정보를 제공해요. 여기서는 의도한 데이터베이스 인스턴스에 도달하기 위한 호스트, 포트, 사용자 이름 및 비밀번호를 지정합니다.
3단계. 데이터 수집
사용자 작업: 사용자가 데이터 소스를 업로드하거나 지정해요. 여기에는 다음이 포함됩니다.
- 로컬 파일 — 파일(PDF, DOCX, TXT, 이미지 등) 드래그 앤 드롭
- 웹 링크 - 웹사이트, 유튜브 비디오, 또는 위키피디아 페이지의 URL 입력
- 클라우드 스토리지 - Amazon S3 또는 Google Cloud Storage 버킷에 대한 접근 구성
4단계. Entity Recognition (개체명 인식)
User action: 시스템은 섭취된 데이터를 LLM을 사용하여 처리하여 엔터티(키 객체, 개념 등)와 해당 엔터티 간의 관계를 식별해요. 여기서 LLM이 콘텐츠를 살펴보고 문서에서 관련 정보를 식별하고 추출하기 시작하는 거죠.
5단계. 그래프 구성
사용자 작업: 이전 단계에서 인식된 엔터티와 관계는 Neo4j 데이터베이스에서 Knowledge Graph를 구성하는 데 사용돼요. 여기에는 Graph Database를 구성하는 Node(엔터티)와 Edge(관계)를 결정하는 것이 포함되죠.
6단계. Visualization
사용자는 이제 구성된 그래프를 시각화할 수 있어요. 옵션은 다음과 같아요:
- 문서 및 청크 — 문서와 텍스트 청크 사이의 연결을 표시해요.
- Entity Graph - 식별된 엔터티 간의 관계를 보여주죠.
- 커뮤니티 — 엔터티 클러스터에 대한 커뮤니티 요약을 표시해요.
- 사용자는 고급 분석, Query 및 편집을 위해 Neo4j Bloom을 사용하여 그래프를 탐색할 수도 있어요.
7단계. RAG 에이전트와의 상호작용
사용자 작업: 사용자는 질문을 통해 챗봇과 상호 작용해요. 애플리케이션은 Retrieval-Augmented Generation(RAG)을 사용하여 Knowledge Graph에서 관련 정보를 검색하고 답변을 생성하죠. 사용자는 벡터 전용 방법과 GraphRAG 방법 중에서 선택할 수 있어요. RAG 에이전트가 소스 자료를 검색하고 사용하는 방법에 대한 세부 정보에도 추가로 액세스할 수 있고요. 사용자는 봇과 상호 작용하여 질문하고 문의 사항을 구체화할 수 있어요.
8단계. 종료
사용자 작업: 사용자가 상호 작용을 완료했어요. 여기에는 앱 닫기, 그래프 탐색, 데이터를 사용하기 위한 애플리케이션 구축 또는 데이터 내보내기가 포함될 수 있죠.
UI 연습
Neo4j 연결
사용자는 프로토콜, URI, 데이터베이스 이름, 사용자 이름 및 비밀번호와 같은 세부 정보를 추가하여 Neo4j 데이터베이스에 연결해요. 또는 연결 대화 상자에서 AuraDB 또는 Sandbox 인스턴스를 생성할 때 다운로드한 자격 증명 파일을 삭제하여 강력한 오류 처리 기능으로 양식을 채울 수도 있죠.
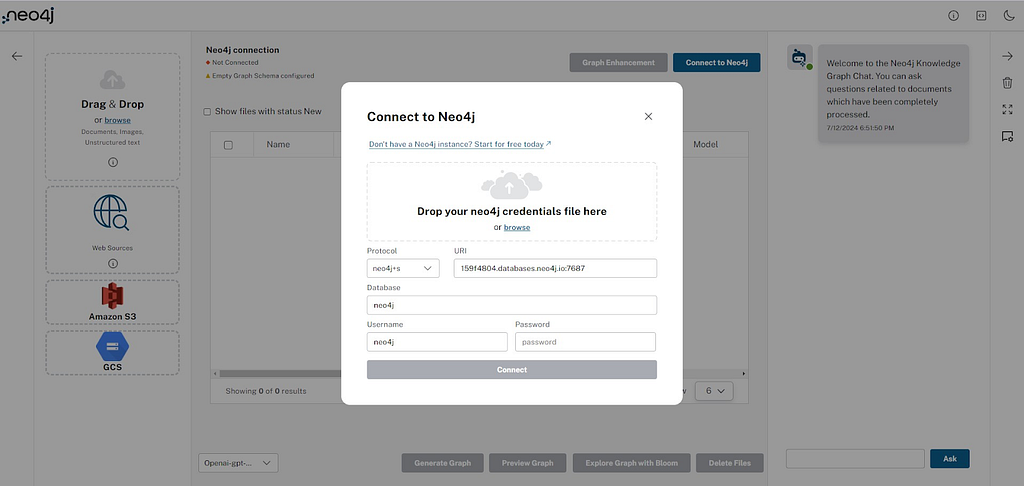
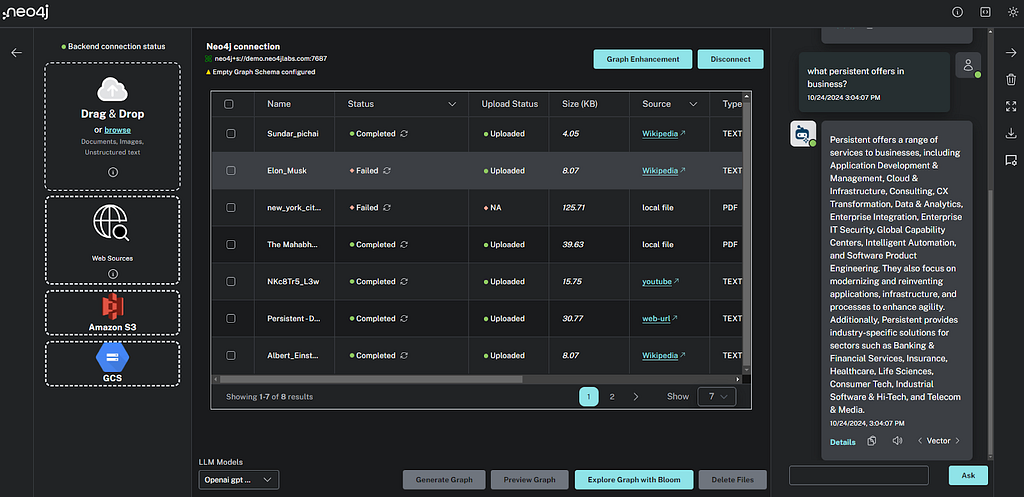
파일 업로드
사용자는 다음을 포함하여 다양한 유형의 파일을 업로드할 수 있어요.
- Microsoft Office(.docx, .pptx, .xls, .xlsx)
- PDF(.pdf)
- 이미지(.jpeg, .jpg, .png, .svg)
- 텍스트(.html, .txt, .md)
이는 파일 콘텐츠를 사용하여 청크를 생성하여 문서 Node로 변환돼요. CHUNK SIZE(5MB)보다 큰 파일은 바이너리 청크로 나누어 서버로 전송되죠. 서버 측에서는 문서 Node 생성을 위해 모든 청크가 병합되고 처리돼요. CHUNK SIZE는 Docker 파일 구성을 통해 구성할 수 있어요.
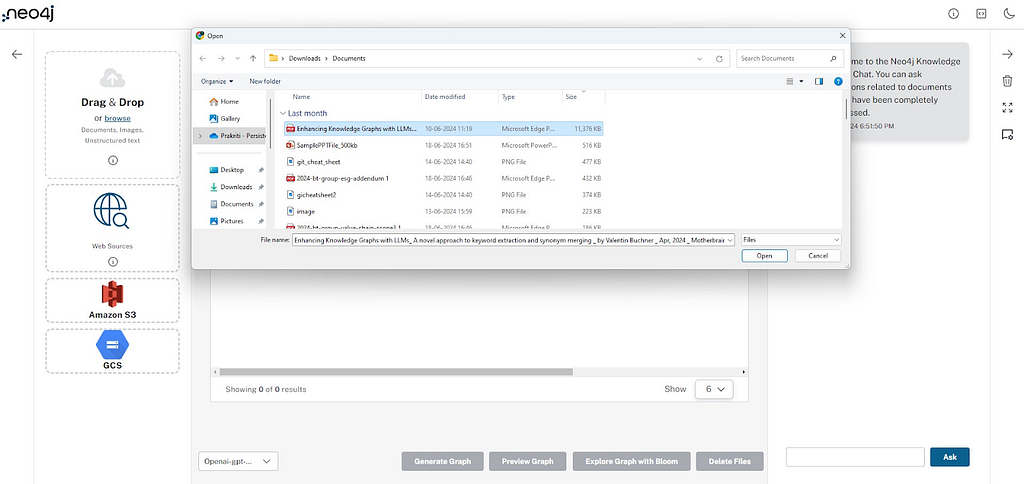
웹 소스
사용자는 Wikipedia, YouTube 비디오, 웹 URL(예: 기사)과 같은 웹 소스를 제공할 수 있으며, 이는 다음을 사용하여 처리됩니다.비정형 LangChain 로더. Document Node가 생성되고, 구성에 따라 소스의 내용을 처리하여 텍스트 Chunk가 생성돼요.
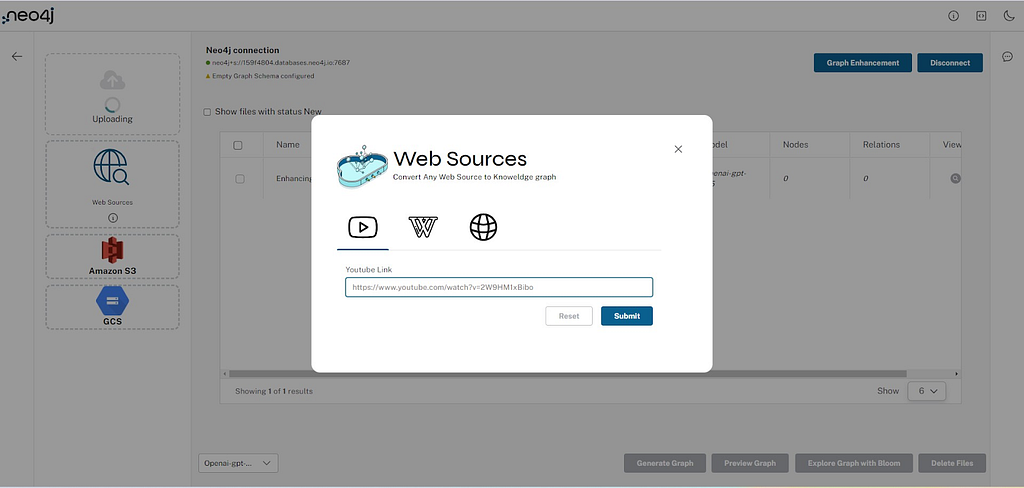
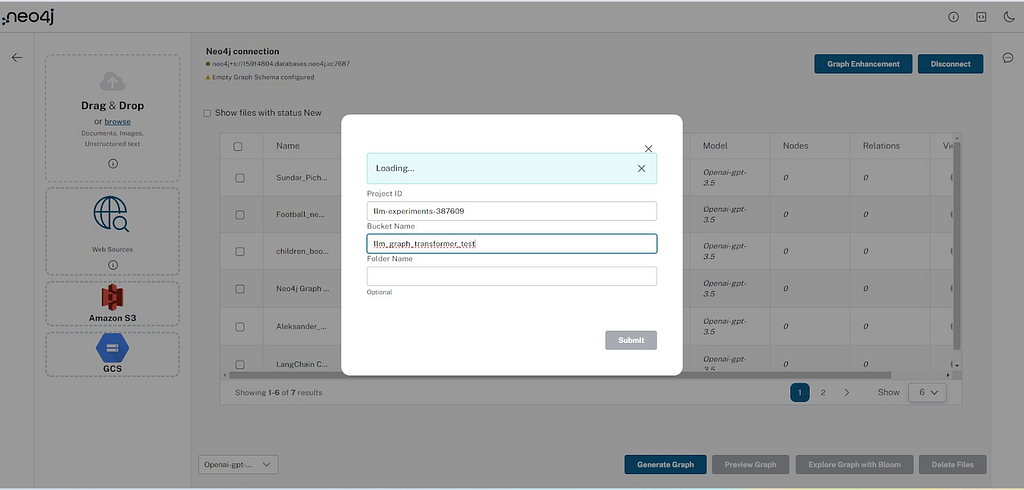
클라우드 제공업체 스토리지
사용자는 Amazon S3 및 Google Cloud Storage에서 일괄 업로드할 소스를 제공할 수 있어요.
S3의 경우 사용자는 액세스 키, 비밀 키 및 S3 URL을 제공해야 해요. 이러한 자격 증명을 제출하면 버킷과 폴더에 있는 모든 PDF 파일을 가져오고 해당 콘텐츠와 함께 각 파일에 대한 문서 Node가 청크 Node로 생성되죠.
아마존 S3:
Google 클라우드 스토리지:
사용자는 프로젝트 ID, 버킷 이름, 폴더를 제공해야 해요. 그런 다음 버킷에 액세스하기 위해 Google 계정을 인증하는 인증 페이지로 리디렉션되는 흐름을 받게 되죠.
LLM 선택
저희는 다양한 모델을 지원하고 있어요. OpenAI API를 지원하는 다른 모델을 선택하고, 설정에 키를 넣어 구성할 수도 있죠. 현재 선택된 모델은 추출, 후처리, 검색, 채팅, 평가 목적으로 사용되고, 필요에 따라 모델을 바꿔가며 사용할 수 있어요.

파일 추출
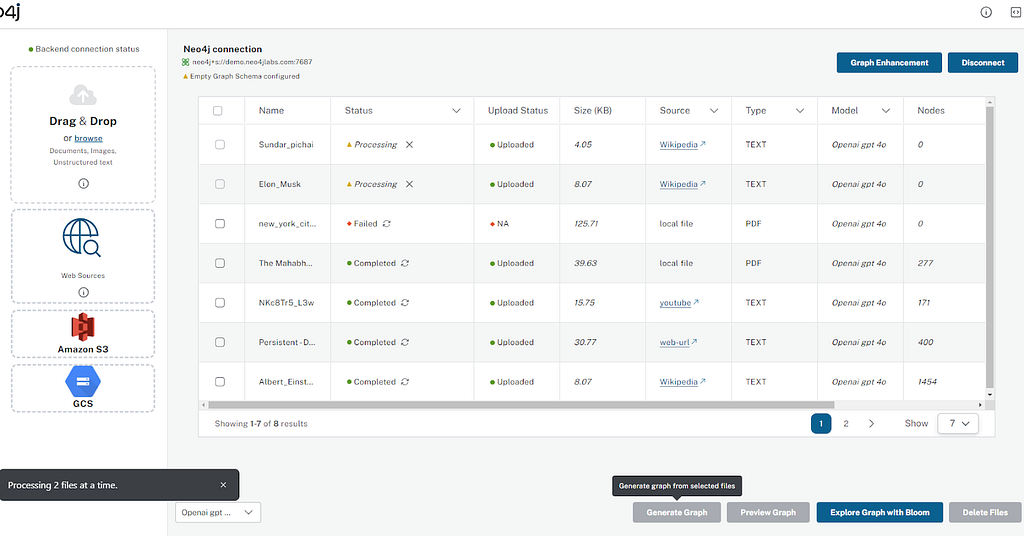
문서를 처리하려면 버튼을 클릭하면 되는데요, 그러면 추출 프로세스가 시작돼요. 이 과정은 LLM 그래프 변환기인 LangChain의 도구를 사용하죠. 추출하는 동안 선택한 파일이나 새로운 파일들은 "처리 중" 상태로 바뀌고, 오류가 없다면 "완료" 상태로 변경돼요.
처리 진행 상황을 업데이트하기 위해 서버는 데이터베이스에서 문서 상태를 실시간으로 읽어 스트리밍하는 서버 측 이벤트를 사용해요. 클라이언트 측에서는 성능 표준을 보장하기 위해 최소한의 리렌더링으로 진행 상황이 변경될 때마다 상태를 업데이트하고요.
처리 진행 상황 업데이트를 위해 컴포넌트 전체에서 사용되는 사용자 지정 훅을 만들었어요. 또한 일괄 처리 방식도 구현했는데요. 사용자가 파일을 3개 이상 선택하면 한 번에 2개(설정 가능)의 파일만 처리해서 공개 배포 버전의 백엔드 로드를 줄이는 방식이에요. 그리고 순서를 유지하기 위해 대기열 상태를 만들었죠. 배치 크기는 Docker 환경을 통해 구성할 수 있어요.
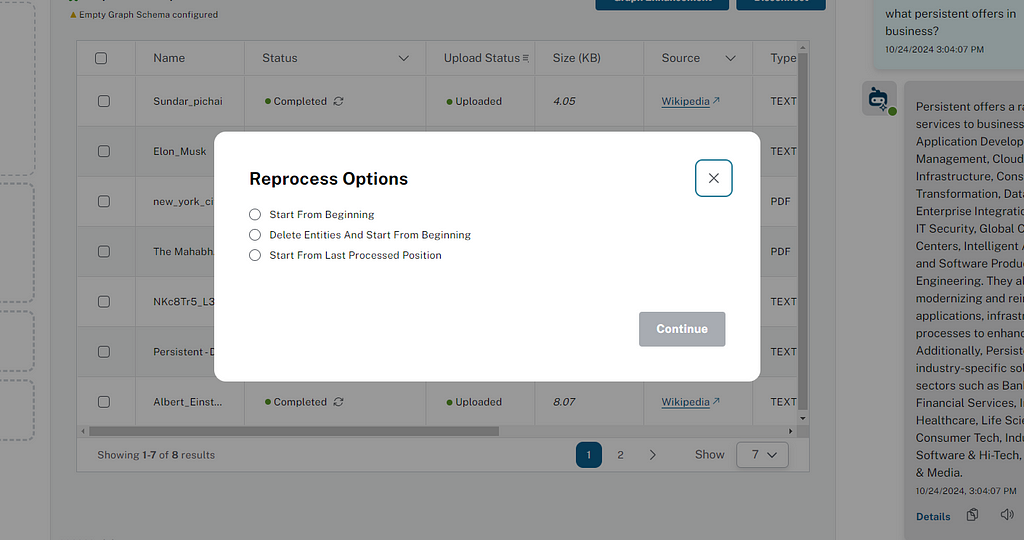
추출을 위한 재처리 옵션
사용자는 재처리 아이콘(↻)을 클릭할 수 있어요. 그러면 상태가 "재처리 준비됨"으로 변경되죠. 그 다음 버튼을 클릭해서 여러 파일을 다시 처리할 수 있어요.

사용자가 재처리할 수 있는 방법은 세 가지가 있어요.
- 항목 삭제 후 다시 시작
- 마지막으로 처리된 청크부터 시작
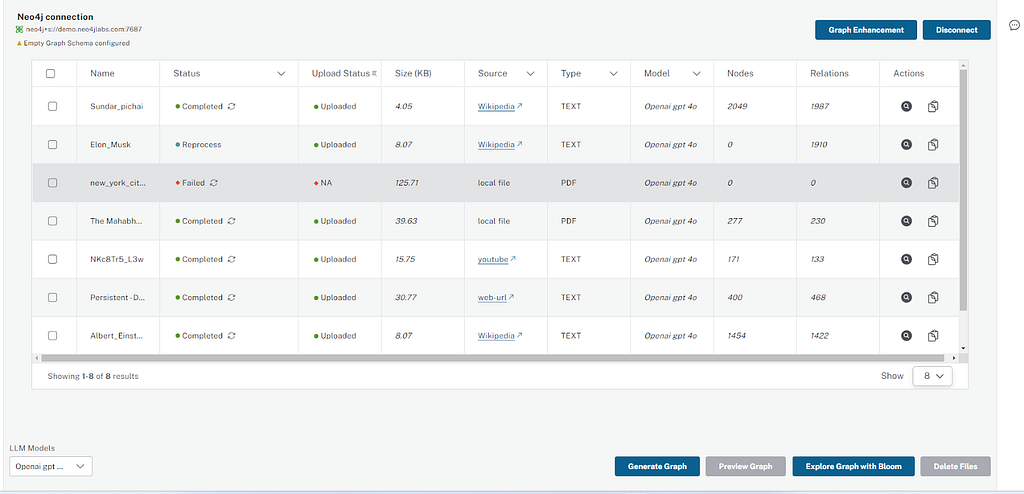
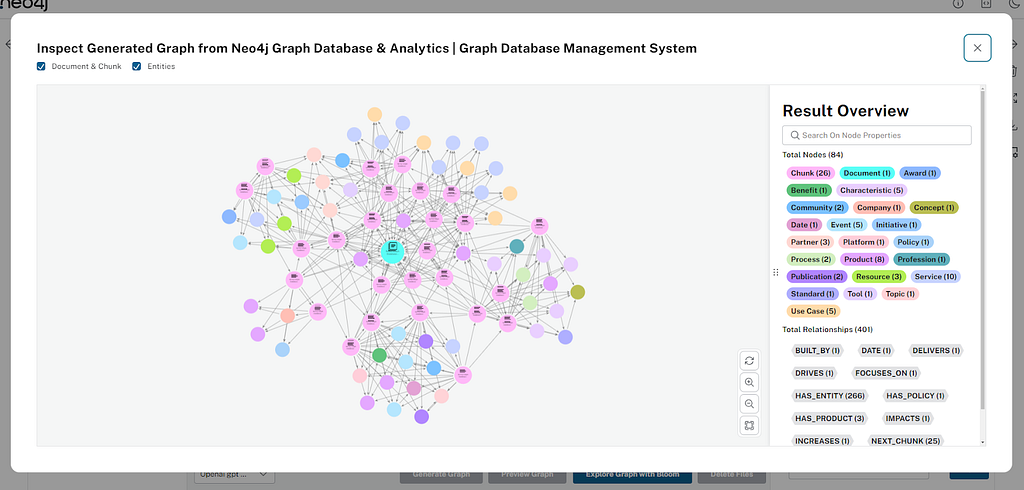
LLM Knowledge Graph Builder 그래프 시각화
그래프 시각화를 위해 InteractiveNvlWrapper 컴포넌트를 사용하고 있어요. 이 컴포넌트는 Neo4j Visualization Library로, 비즈니스 로직에 따라 그래프 시각화를 통합하는 유연성과 핸들러를 제공하죠. 애플리케이션의 다양한 단계에서 그래프를 렌더링하는 데 사용되는 재사용 가능한 컴포넌트를 만들었어요.
데이터베이스에서 Node와 Relationship을 가져오고, 더 빠른 사용자 경험을 위해 로컬에서 필터를 적용하기 위해 백엔드 API를 한 번 사용하고 있어요.
사용자는 Node를 클릭해서 Node에 대한 세부 정보(type, attributes 등)를 볼 수 있어요. 또한 클라이언트 측 검색 기능을 구현해서 사용자가 label 또는 order text로 특정 Node를 검색할 수 있도록 했죠. 문서 처리가 진행되는 동안 유용한 zoom in/out, refresh graph와 같은 간단한 시각화 동작도 지원하고요.
이 시리즈에서는 그래프 시각화의 복잡성과 이를 해결하는 방법에 대해 자세히 알아보는 별도의 블로그 게시물을 게시할 예정이에요.
그래프 개선
저희는 사용자가 추출을 위한 사용자 정의 그래프 스키마 설정, 유도 추출을 위한 추가 지침 얻기, 고아 Node를 대화형으로 제거, 중복 Node 병합(유사성에 따라)과 같은 설정을 구성할 수 있는 다양한 처리 개선 사항을 지원하고 있어요.
엔터티 추출
사용자는 자신의 스키마를 제공하거나, 기존 스키마 예제를 사용하거나, Neo4j 데이터베이스의 현재 스키마를 로드할 수 있어요.
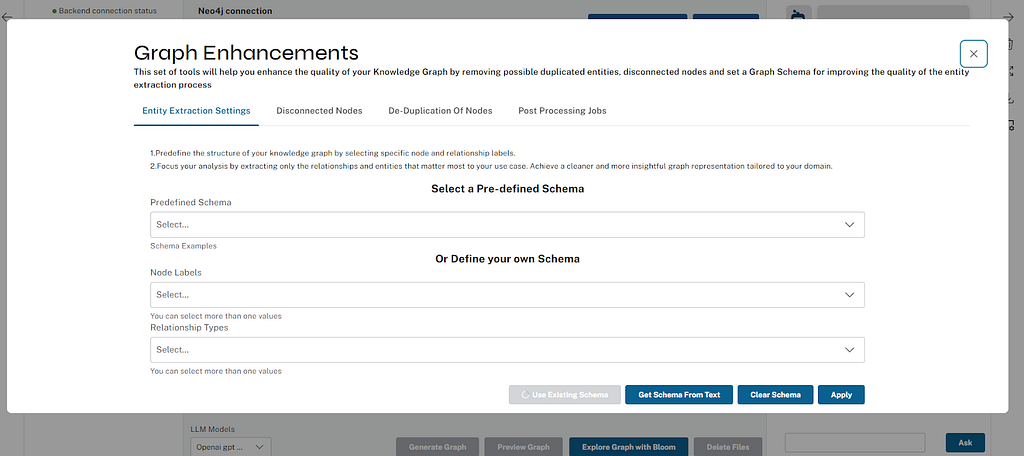
저희는 LLM을 통해 제공된 텍스트 예제(최대 여러 페이지)에서 스키마 추출을 지원해요. 스키마 설명 메타데이터(RDF 온톨로지, CREATE TABLE 문 또는 단순한 구두 설명 등) 뿐만 아니라 처리할 문서의 샘플 섹션에도 적용할 수 있죠.
결과적으로 사용자가 개선하거나 정리할 수 있는 후보 그래프 모델 생성 속도가 빨라질 수 있어요.

추가 지침
추가 지침은 추출 프롬프트에 추가 정보를 줘서 Knowledge Graph를 개선하는 데 사용돼요. 현재 이벤트에만 집중하거나, 특정 유형의 기술이나 조직을 무시하거나, 용어집이나 도메인 정보 같은 추가적인 맥락 정보를 모델에 제공할 수 있죠.
Chunking 구성
Chunk 프로세스에 대한 선택적 구성은 다음과 같아요:
• 청크당 토큰 수 (Tokens per chunk): 각 청크에서 처리되는 토큰 수를 정의해요 (기본값은 200으로 설정되어 있어요).
• 청크 오버랩 (Chunk overlap): 컨텍스트를 유지하기 위해 청크 사이에 겹치는 토큰을 지정합니다 (기본값은 20으로 설정되어 있어요).
• 결합할 청크 (Chunks to combine): 처리를 위해 병합되는 청크 수를 결정합니다 (기본값은 1로 설정되어 있어요).

연결이 끊긴 (고아) Node 삭제
사용자는 다른 엔터티 (단지 청크 또는 커뮤니티)에 연결되지 않은 연결이 끊긴 Node를 대화형으로 나열하고 삭제할 수 있어요.

Node 중복 제거
사용자는 유사한 엔터티를 병합해서 중복성을 제거하고 Knowledge Graph의 정확성과 명확성을 향상시킬 수 있어요. 후보를 그룹화하기 위해 Vector와 텍스트 거리 유사성의 조합을 사용하죠. 선택한 Node 행을 병합하기 전에 개별 Node를 삭제할 수도 있어요.
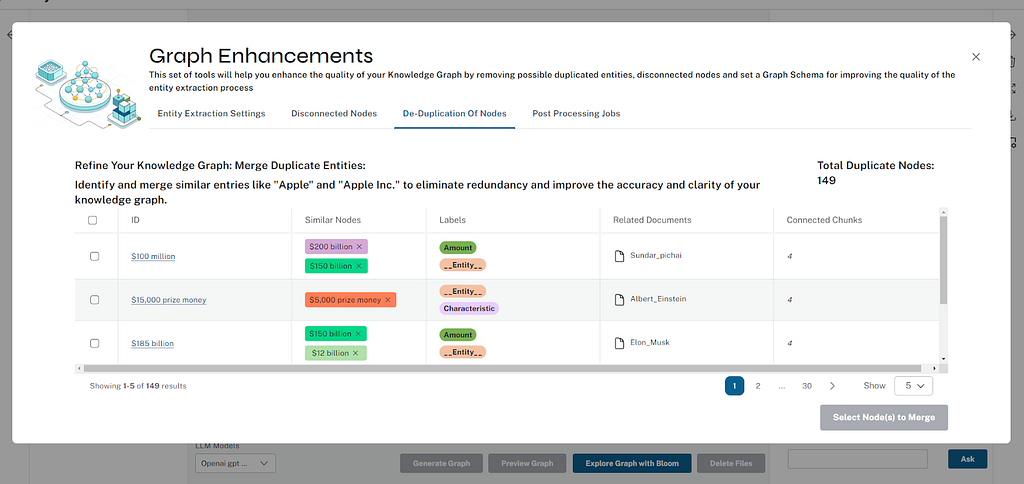
후처리 작업
사용자는 추출 프로세스 후에 실행할 수 있는 작업을 선택할 수 있는데, 이는 즉시 GraphRAG와 같은 기능을 향상시켜요. Graph Data Science(GDS) 및 비 GDS 인스턴스를 지원하므로 커뮤니티 옵션을 표시해 드릴게요.
- 텍스트 청크 유사성 구체화 (Text Chunk Similarity Refinement): Vector 유사성이 구성된 임계값을 초과하는 텍스트 청크 간에 유사한 Relationship을 만들어요.
- 하이브리드 검색 활성화 (Hybrid Search Activation): Neo4j Bloom에서 하이브리드 검색 및 전체 텍스트 검색을 위한 항목에 대한 전체 텍스트 Index를 만들어요.
- 엔터티 임베딩 구체화 (Entity Embedding Refinement): 엔터티에 대한 Embedding을 생성해요.
- 커뮤니티 활성화 (Community Activation): GDS 지원 데이터베이스 인스턴스에서 엔터티 클러스터를 계산하고 계층적 커뮤니티 요약을 생성해요.
- 그래프 스키마 통합 (Graph Schema Integration): 그래프 스키마가 구성되어 있지 않으면 이후에 LLM 호출을 통해 자동 생성된 그래프를 통합하고 정리해 보세요.

테이블 필터
사용자는 추출 상태, 소스 유형, 모델 유형 등과 같은 속성을 기반으로 문서 테이블을 정렬하고 필터링할 수 있어요.
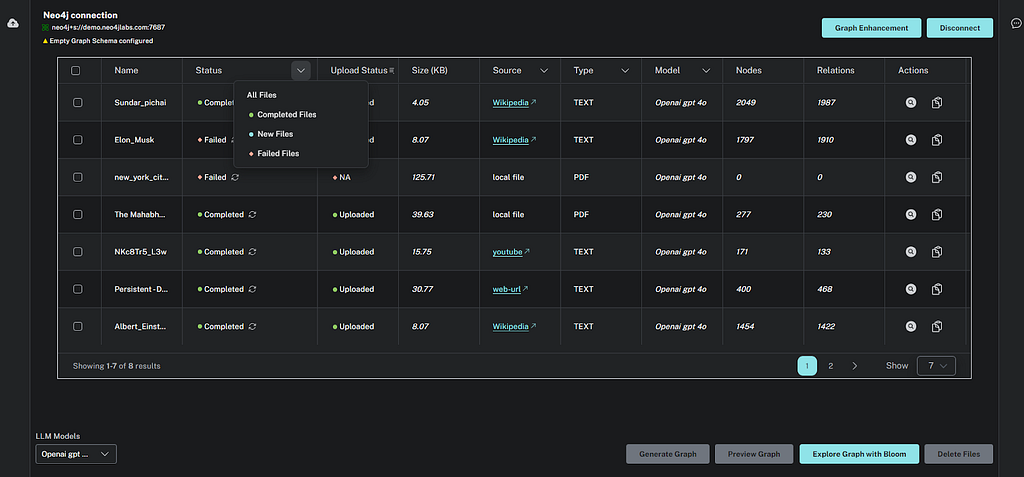
다양한 리트리버 모드를 갖춘 챗봇
리트리버 모드
그래프의 힘을 분석하기 위한 다양한 검색 모드, Vector 검색, 엔터티 검색을 지원해요. GraphRAG 구현이죠. 사용자는 채팅에 대해 하나 이상의 검색자를 선택하고 각 채팅 결과 간에 전환해서 생성된 답변의 차이를 시각적으로 확인할 수 있어요.
채팅 보기 및 기능
채팅 기능에 대해 두 가지 보기를 지원해요. 사용자는 기본 UI 사이드바 내에서 채팅하거나 더 나은 경험을 위해 별도의 모달에서 채팅할 수 있죠. 또한 사용자는 답변을 듣고, 복사하고, 대화를 JSON 형식으로 다운로드할 수 있어요.
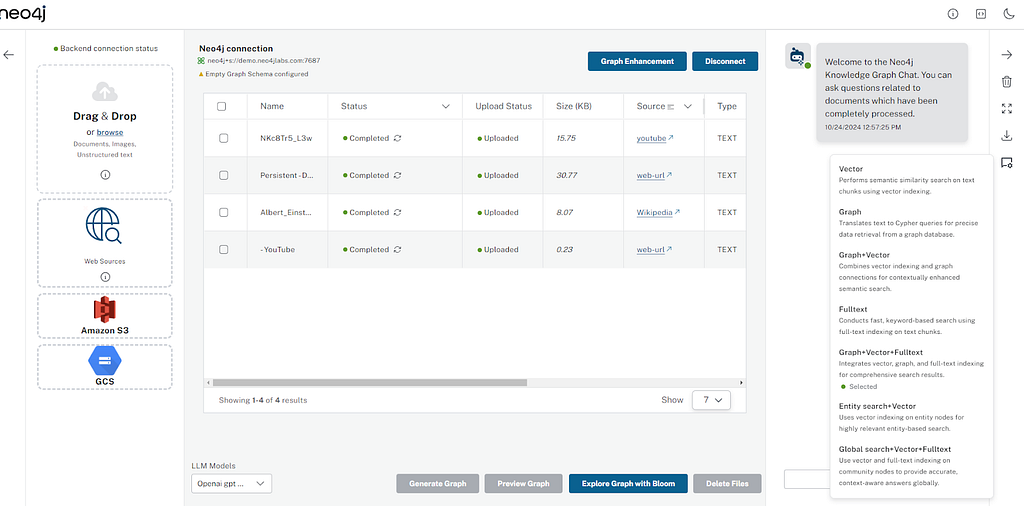
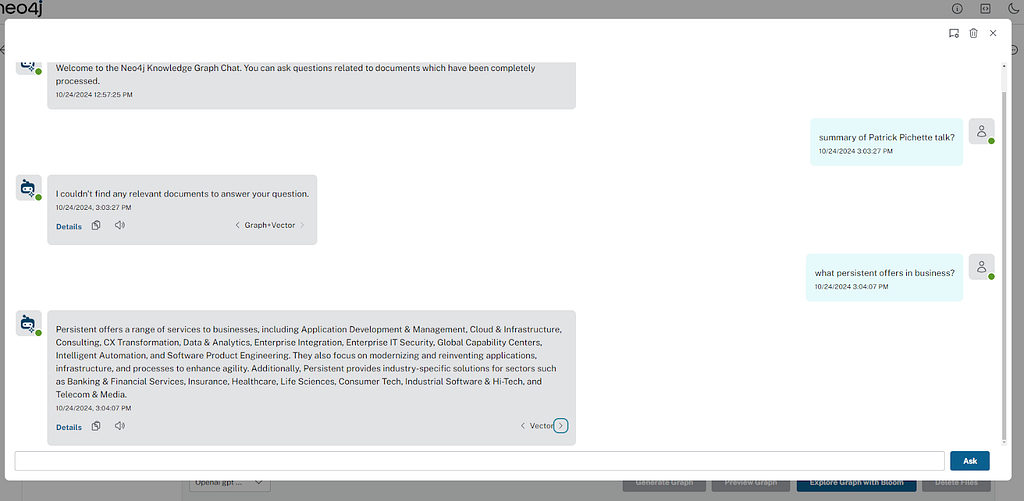
채팅 전용 모드
대화형 쿼리를 통해 Neo4j 데이터베이스의 데이터와 상호 작용하고 전용 채팅 전용 UI를 사용하여 쿼리에 대한 응답 소스에 대한 메타데이터를 검색해요.
전용 채팅 인터페이스의 경우 채팅 전용 경로에서 독립형 채팅 애플리케이션에 액세스하세요. 이 링크는 데이터 쿼리를 위한 집중적인 채팅 환경을 제공하죠.

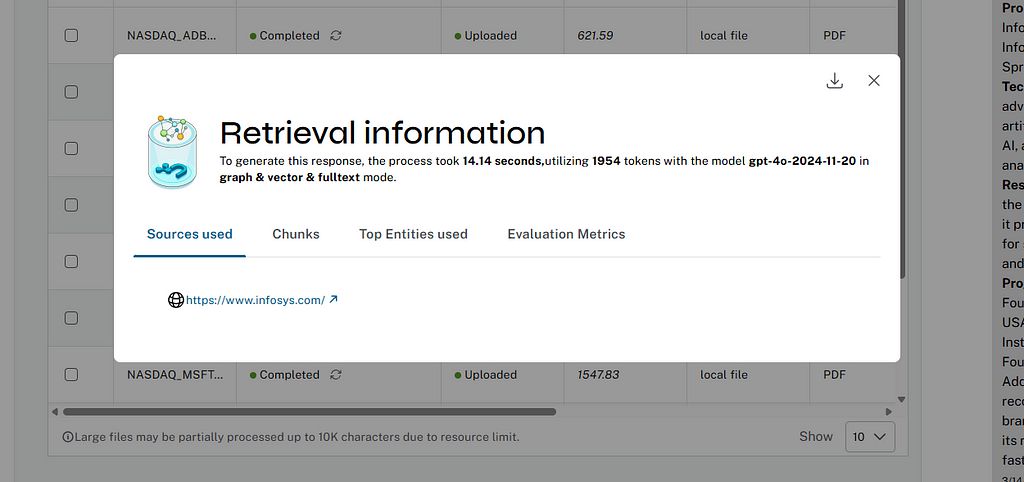
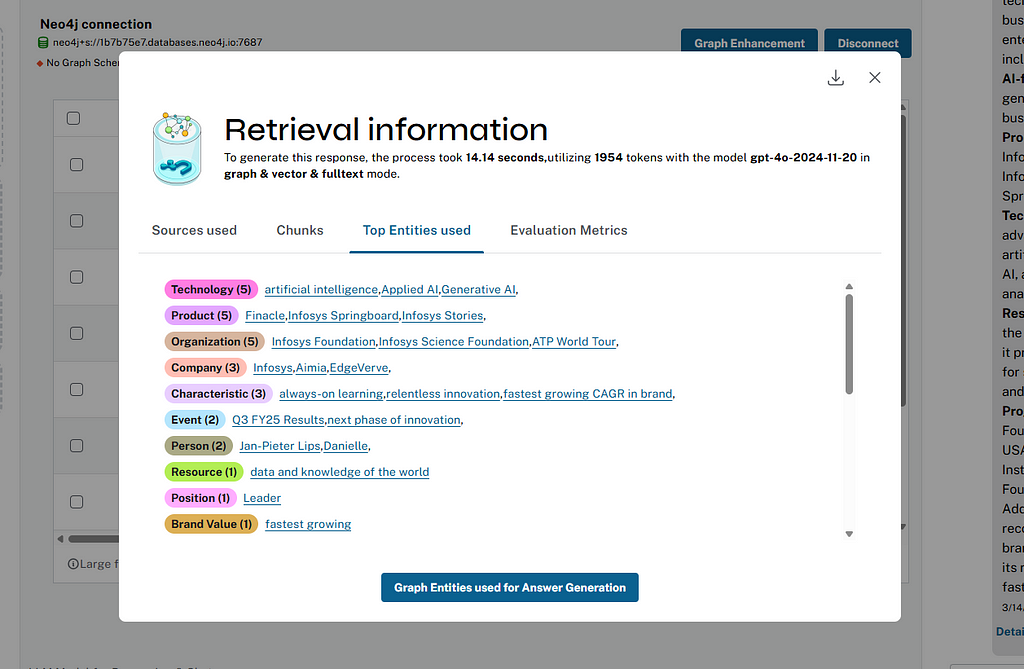
검색 통찰력
저희는 사용자가 Graph Database에서 검색하고 LLM에서 답변을 생성하는 데 사용하는 실제 답변 소스와 항목을 확인할 수 있도록 채팅 답변의 설명 가능성을 지원하고 있어요.
클릭하시면 보실 수 있습니다. 팝업에는 검색 모드, 모델, 토큰 및 런타임에 대한 정보뿐만 아니라 답변을 생성하는 데 사용된 청크, 엔터티, 커뮤니티도 표시됩니다.
사용자는 텍스트 덩어리와 항목의 주변 컨텍스트를 시각화하고 JSON 형식으로 통계를 다운로드할 수 있어요.
Ragas 평가 지표
사용자는 다음을 통해 모든 검색기의 답변 정확도를 측정/검증할 수 있어요. Ragas 버튼을 클릭하여 평가 파이프라인을 실행합니다. Ragas는 LLM과 추가 지표로 제공될 수 있는 실제 답변을 통해 RAG 시스템 응답의 품질을 측정하는 평가 도구랍니다.

요약
프런트 엔드 LLM 지식 그래프 빌더는 스타일 구성 요소 또는 Tailwind CSS를 통한 스타일 지정과 함께 React Context API인 React를 사용하여 개발된 사용자 중심 애플리케이션이에요. Neo4j Needle Design System을 사용하여 일관성, 접근성 및 세련된 디자인을 보장하죠. 이 시스템은 원활한 Neo4j 연결 관리를 제공하고 로컬, 웹 및 클라우드 소스의 파일 업로드를 지원하며 청크 및 병합을 통해 대용량 파일을 효율적으로 처리합니다.
주요 기능에는 LLM 선택을 위한 직관적인 워크플로, 자동화된 그래프 생성 및 시각화, RAG가 포함된 강력한 채팅 인터페이스, 설명 가능한 답변, 응답 평가를 위한 Ragas 지표가 포함돼요.
사용자는 스키마 조정, 노드 중복 제거, 고아 노드 제거 및 사후 처리 작업을 통해 그래프를 개선할 수 있어요. SSE, 테이블 필터링 및 재처리 기능을 통한 실시간 업데이트는 유용성을 향상시키는 동시에 확장성은 대규모 데이터 세트의 강력한 처리를 보장하죠.
전반적으로 이 애플리케이션은 현대적인 디자인 원칙과 유용성을 고급 기능과 결합하여 사용자가 Knowledge Graph를 쉽게 구축, 개선 및 상호 작용할 수 있도록 지원하여 데이터 통찰력에 더 쉽게 접근하고 실행 가능하게 만들어요.
여러분의 생각과 피드백을 환영합니다. 댓글을 남기거나 문제를 제기해 주세요. 에 여러분의 통찰력을 공유하기 위해서요!
자세히 알아보려면 다음을 확인하세요. Neo4j LLM 지식 그래프 빌더 소개 and LLM 지식 그래프 빌더 — 2025년 첫 번째 릴리스.
- 생성 AI 도구
- GraphRAG
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'Ontology & Knowledge Graph' 카테고리의 다른 글
| AI의 미래: Machine Learning과 Knowledge Graph의 만남 (0) | 2026.06.26 |
|---|---|
| I built a digital twin of my amateur-built airplane (0) | 2026.06.26 |
| From Identity Vacuum to Identity Driven Access Control: Securing LLM Agents in the Enterprise (0) | 2026.06.25 |
| 그래프에서 지식 그래프로: 그래프가 어떻게 Knowledge Graph가 되는가 (0) | 2026.06.25 |
| 그래프에서 지식 그래프로: 데이터 트렌드와 도전 과제 (0) | 2026.06.24 |