
경쟁 우위를 확보하려는 기업에게 지식의 힘을 활용하는 건 필수적이에요.
누구나 지식을 포착하고 자신이 알고 있는 모든 것을 연결하고 싶어하죠. 하지만 데이터를 지식으로 전환하는 건 아직도 진행 중인 노력이에요. 진전은 있었지만, 대부분의 데이터 환경은 아직 성숙하지 못했어요.
모든 시스템, 클라우드, 백업, 데이터 레이크 전반에 걸쳐 우리가 가진 데이터를 연결하는 방법이 필요해요. 데이터 파이프라인 중 일부는 실시간으로 깨끗한 데이터를 대시보드에 제공하고 비즈니스 프로세스에 알리는 등 강력할 수 있지만, 그것만으로는 충분하지 않아요. 그 성공을 모든 곳에서 반복해야 해요.
이제 데이터를 연결해서 관리 가능하고 유용하게 만들 차례에요. 업무를 수행하기 위해 데이터가 필요한 조직의 모든 사람은 데이터를 어디서 찾을 수 있는지 알고, 정확성을 확신하며, 자신의 문제를 쉽게 해결할 수 있어야 해요.
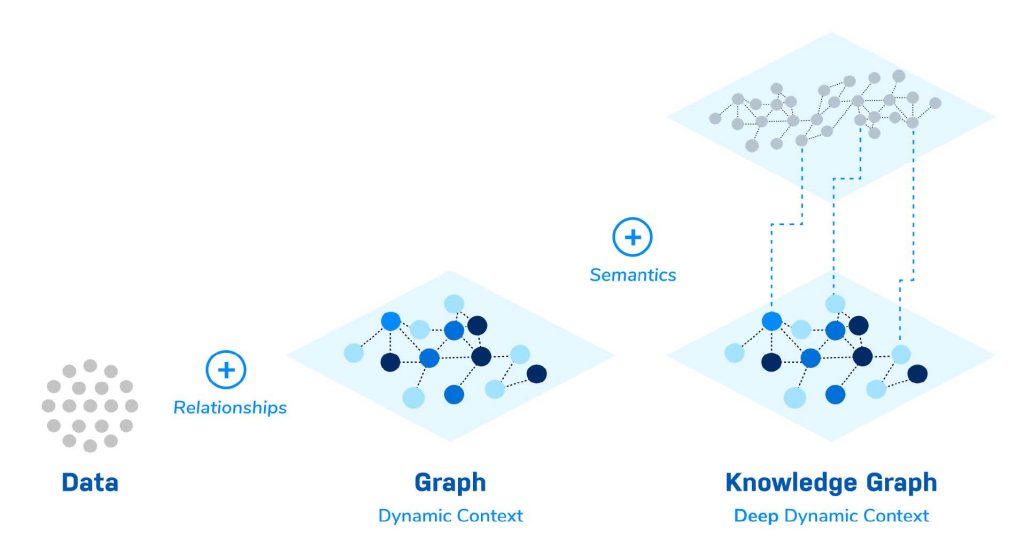
이 블로그 시리즈에서는 그래프부터 Knowledge Graph까지 – 작게 시작해서 즉각적인 가치를 얻은 다음, 외부로 확장하면서 무한한 통찰력을 향한 짧은 여정을 시작할 거예요.
3부작 시리즈의 첫 번째 블로그에서는 오늘날의 데이터 동향과 과제에 대해 이야기해볼게요.
2부: 그래프가 Knowledge Graph가 되는 방법
3부: 실행 및 결정 Knowledge Graph
사일로
첫째, 고립된 데이터가 있어요. 데이터 저장소와 애플리케이션은 종종 개별 그룹이나 부서에 서비스를 제공하죠. HR 팀에는 하나의 플랫폼이 있고 영업 팀에서는 Salesforce와 같은 다른 플랫폼을 사용할 수 있어요. 기록 시스템은 데이터를 유지 및 제어하고 거버넌스 정책을 수립하기 때문에 중요하지만, 데이터 사일로로 인해 분석 속도, 보고 정확성, 데이터 품질이 저하되기도 해요.
데이터 확산 및 데이터 레이크
대부분의 조직에는 기록 시스템, 고객 데이터, 거래 데이터, 제품 데이터 및 주문 데이터의 기반이 되는 데이터 레이크, 데이터 웨어하우스, 관계형 데이터베이스가 있으며 그 목록은 계속 늘어나죠. 이러한 데이터 분산은 데이터 확산에 기여해요.
데이터 레이크는 대량의 정형, 반정형, 비정형 데이터를 저장하기 위한 저렴한 옵션으로 인기가 높아요. Amazon S3와 같은 객체 스토리지는 데이터 레이크를 생성하는 데 종종 사용돼요.
비용 측면에서 데이터 레이크는 매력적이에요. 애플리케이션 및 서비스에서 생성된 로그 파일을 포함하여 모든 유형의 데이터를 저장할 수 있는 장소를 제공하니까요. 데이터 레이크에 데이터를 넣는 것은 쉽고 편리해요. 하지만 해당 데이터를 관리하고 데이터가 무엇인지 아는 것조차 어려워지죠.
클라우드 스토리지
클라우드 컴퓨팅은 혁신적이지만 더 많은 시스템에 더 많은 데이터가 저장되므로 거버넌스 문제가 여전히 남아 있어요. iCloud, Google Drive, Dropbox 등은 물론 Evernote, Gmail, Notes에 있을 수 있는 개인 클라우드 데이터를 고려해 보세요.
이로 인해 데이터 형식이 다양하고 부분적으로 중복될 뿐만 아니라 대부분 단절된 엄청난 양의 데이터가 남게 돼요.
어둡고 지저분한 데이터는 규정 준수에 있어서 악몽과 같아요.
만약 GDPR 준수를 위해 어떤 사람의 데이터를 잊어야 한다고 할 때, 그 사람의 모든 데이터가 어디에 있는지 아시나요? 그 사람의 소유인지도 모르는 쿠키는 어떻고요? 귀하의 물류 시스템과 파트너 시스템의 데이터는요?
과거 데이터는 창 밖으로 바로 이동됩니다.
과거 데이터는 Machine Learning 예측을 촉진해요. 그러나 코로나19 팬데믹으로 인해 경제 전반에 혼란이 파급되면서 역사적 데이터가 쓸모없게 되었죠. 예를 들어 과거 데이터는 일반적으로 구매 행동을 예측하는 데 사용되잖아요.
전염병으로 인해 봉쇄 기간 동안 온라인 쇼핑이 시장을 장악하게 되면서 거의 하룻밤 사이에 구매 행동이 바뀌게 되었어요. 소비자 행동의 이러한 극적인 변화로 인해 과거 데이터로는 더 이상 구매 행동을 정확하게 예측할 수 없게 된 거죠.
제한된 데이터로 인해 데이터의 연결이 중요해지고 가치가 높아져요. 데이터를 Graph Database에 연결과 관계를 포착하는 거죠.
보유한 데이터는 가치가 있지만 해당 데이터 내외의 관계(이미 존재하는 관계)를 저장하면 관련 기록 데이터가 없더라도 예측 능력이 향상돼요. 연결과 관계가 중요하기 때문이에요. 가장 예측 가능한 요소는 데이터에 있거든요.
결론
이러한 모든 요인으로 인해 여러분과 같은 기업은 지식을 얻기 위해 Graph Database의 데이터를 연결하는 쪽으로 이동하고 있어요.
다음 주 이 시리즈의 블로그 2에서는 그래프가 Knowledge Graph가 되는 방법을 정확히 살펴볼게요.
- Graph
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'Ontology & Knowledge Graph' 카테고리의 다른 글
| From Identity Vacuum to Identity Driven Access Control: Securing LLM Agents in the Enterprise (0) | 2026.06.25 |
|---|---|
| 그래프에서 지식 그래프로: 그래프가 어떻게 Knowledge Graph가 되는가 (0) | 2026.06.25 |
| 그래프에서 지식 그래프로: Actioning 지식 그래프 vs. Decisioning 지식 그래프 (0) | 2026.06.24 |
| 지식 그래프로 건초 더미 속 바늘 찾기: Fraud Detection (사기 탐지) (1) | 2026.06.24 |
| 파울러, 새로운 DB (그리고 Neo4j)에 대해 말하다 (0) | 2026.06.23 |