
다양한 소스에서 Knowledge Graph를 더 쉽게 생성해서 생명공학 전문가와 연구자들의 삶을 더 편하게 만들어주는 방법에 대해 이야기해봤어요.
전체 에피소드를 보려면 이 블로그 게시물 끝으로 스크롤해주세요.
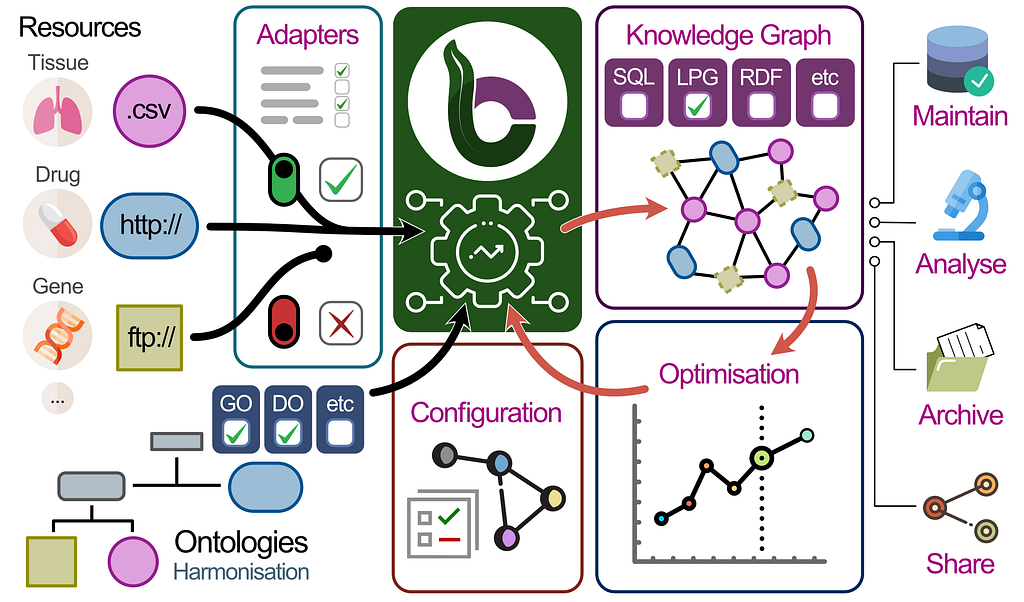
Knowledge Graph의 생성
최근에 Neo4j GraphSummit 뮌헨에서 카타리나 카리가 Knowledge Graph를 만들기 시작하기 전에 의미론적 분류를 순서대로 정리하기 위해 사전에 시간을 투자하는 것이 얼마나 중요한지 이야기하는 걸 들었어요. 이 초기 단계가 안정적인 기반을 바탕으로 구축되지 않으면 나머지 프로세스가 실패할 수 있고 목표를 달성하지 못할 수도 있다네요.
Sebastian도 이러한 우려에 동의하면서, 팀들이 자체 프로세스를 구축할 수 있는 대역폭이 없는 경우가 많아서 목표와 100% 일치하지 않더라도 "충분하다"고 여겨지는 이미 존재하는 것에 의존한다고 말해요. 이것이 BioCypher를 구축하게 된 큰 동기였다고 하는데요. 기존 리소스에서 자체 데이터와 결합해서 Knowledge Graph를 더 쉽게 생성하고, 동시에 해당 프로세스를 더욱 유연하게 만드는 거죠.
바이오사이퍼
BioCypher는 세 가지 주요 영역을 결합해서 이 문제를 해결하고 있어요.
- 자원: ETL과 유사한 프로세스를 통해 모든 종류의 데이터를 프레임워크에 파이프해요. 어댑터를 통해 선택된 데이터는 고도로 맞춤화될 수 있고, 사용자가 Node/Edge 수준에서 필요한 정보를 정의하는 데 도움이 되죠 (Graph Modeling을 생각해 보세요!). 따라서 사용자는 필요한 데이터만 로드하고 파이프라인은 이미 해당 데이터를 올바른 위치에 배치해줘요. 옴니패스처럼 모든 종류의 소스에 대한 많은 어댑터가 있답니다.
- 온톨로지: 전문적으로 선별된 정보가 데이터와 매핑돼요. 또한 사용자는 사용하려는 온톨로지를 선택하고 필요에 맞게 다양한 온톨로지를 함께 연결할 수 있어요. 앞으로는 온톨로지 병합까지 허용할 계획이라고 하네요.
- 산출: 그런 다음 결합된 데이터는 사용자가 데이터로 작업할 수 있도록 Property Graph, SQL 또는 RDF로 내보내져요. 다른 사용자가 쉽게 복제할 수 있도록 Schema를 공유할 수도 있답니다.
BioCypher 사용
에피소드를 마무리하면서 Sebastian은 BioCypher의 빠른 데모를 보여줬는데요, 메타그래프를 Neo4j로 로드하는 걸 볼 수 있어요.
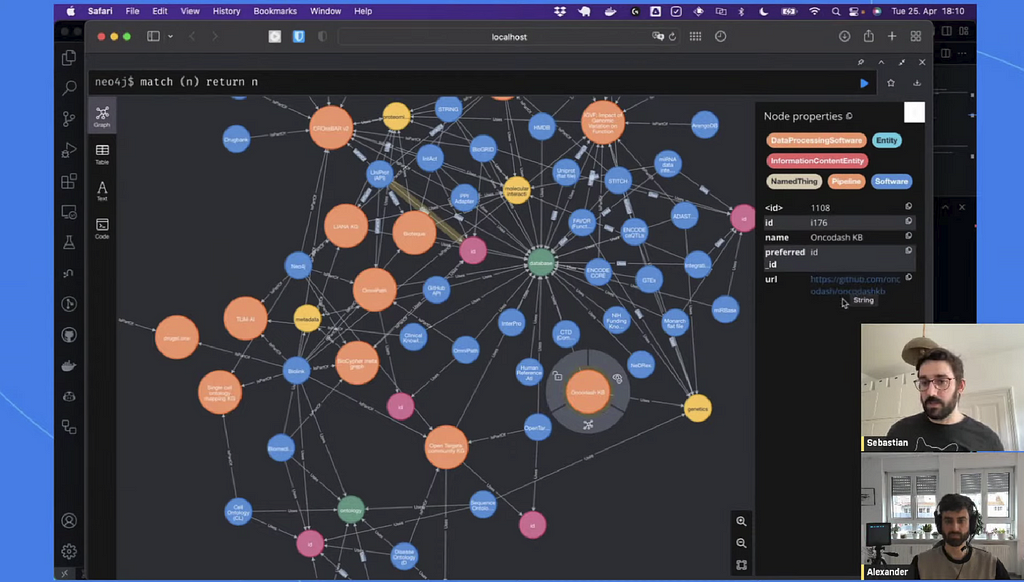
BioCypher 팀은 단위 테스트를 통해 이 접근 방식을 최대한 강력하게 만들고, 사용자에게 Knowledge Graph 구조에 대한 자세한 피드백을 제공하거나 중복 항목을 강조 표시하고 있어요.
앞으로는 사용 사례별 워크플로, 온톨로지 추론을 확장하고 성능을 개선하며, 더 직관적인 사용자 인터페이스(GUI도 가능)를 개발하고 싶어 한다고 해요.
관심 있는 커뮤니티 구성원의 도움을 언제나 환영한다고 하니 참고하세요!
전체 에피소드 보기
흥미로운 링크
BioCypher:
Github:
종이:
Sebastian Lobentanzer:
Graphs4Good:
HealthECCO:
OmniPath:
Meta 진행 중:
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'Ontology & Knowledge Graph' 카테고리의 다른 글
| 지식에 투자하며 여성 역사의 달을 기념하다 (0) | 2026.06.14 |
|---|---|
| 엔터프라이즈 Knowledge Graph 구축하기 (1) | 2026.06.13 |
| 증강 지능: NEORIS Demian Bellumio와의 5분 인터뷰 (0) | 2026.06.13 |
| 증강 지능: NEORIS Demian Bellumio와의 5분 인터뷰 (0) | 2026.06.13 |
| AI & 그래프 기술: 지식 그래프란 무엇일까요? (0) | 2026.06.12 |