
메타 변화의 20개 에피소드 – 요약
이번 라이브 스트리밍 시리즈에서는님과 Semantic, 온톨로지, Knowledge Graph의 다양한 측면을 탐구했어요. 얘기하다 보니 몇 가지 주제가 계속 나오더라구요. 그래서 꽤 많은 에피소드 중에서 길을 찾는데 도움이 될 것 같아서, 이 주제들에 대해 이야기해보려고 해요.
메타로 나아가다
2022년 2월, Jesús Barrasa님과 제가 첫 번째 에피소드를 시작했을 때, 앞으로 어떻게 될지 잘 몰랐어요. 좀 더 직접적이고 대화를 많이 나눌 수 있을까 고민했죠. 주요 주제는 Semantic, 온톨로지, Knowledge Graph가 될 거라는 것, 그리고 대상 청중은 실무자라는 건 알고 있었어요. 그래서 저희는 이 공간을 추상적인 논의만 가득하고 실질적인 가치는 거의 없는 모호함, 또는 지나치게 이론적이거나 학문적인 접근 방식과는 거리를 두고 싶었어요. 에피소드마다 사람들이 아이디어를 얻어갈 뿐만 아니라, 논의된 개념을 문제에 바로 적용할 수 있도록 자산도 제공하고 싶었거든요.
“왜?” 이런 테마를 선택한 이유는 두 가지가 있었어요. 첫째, 시맨틱 스택(RDF, 온톨로지, 추론…)의 Neo4j 통합 요소에서 구현되는 Knowledge Graph 프로젝트가 점점 더 많아지고 있다는 걸 알게 됐죠. 그리고 RDF와 Neo4j 모두에 대한 특별한 배경 지식을 가진 Jesús님도 함께였으니까요. Jesús님은 Neosemantics의 핵심 인물이에요. Neosemantics는 RDF와 Linked Data를 Neo4j와 통합하는 역할을 하죠. 게다가 최근에는 O'Reilly 책 Knowledge Graph 실무자 가이드도 공동 집필했답니다.
반응은 정말 놀라웠어요! 지금까지 YouTube 총 조회수는 40,000회에 달했고, GitHub에는 수많은 스타가 찍혔답니다. 왜냐하면 처음부터 저희는 Github 저장소를 만들어서 각 에피소드에서 사용되는 모든 자산(코드, 쿼리, 데이터 세트, 온톨로지, 노트북 등)을 공유했거든요.
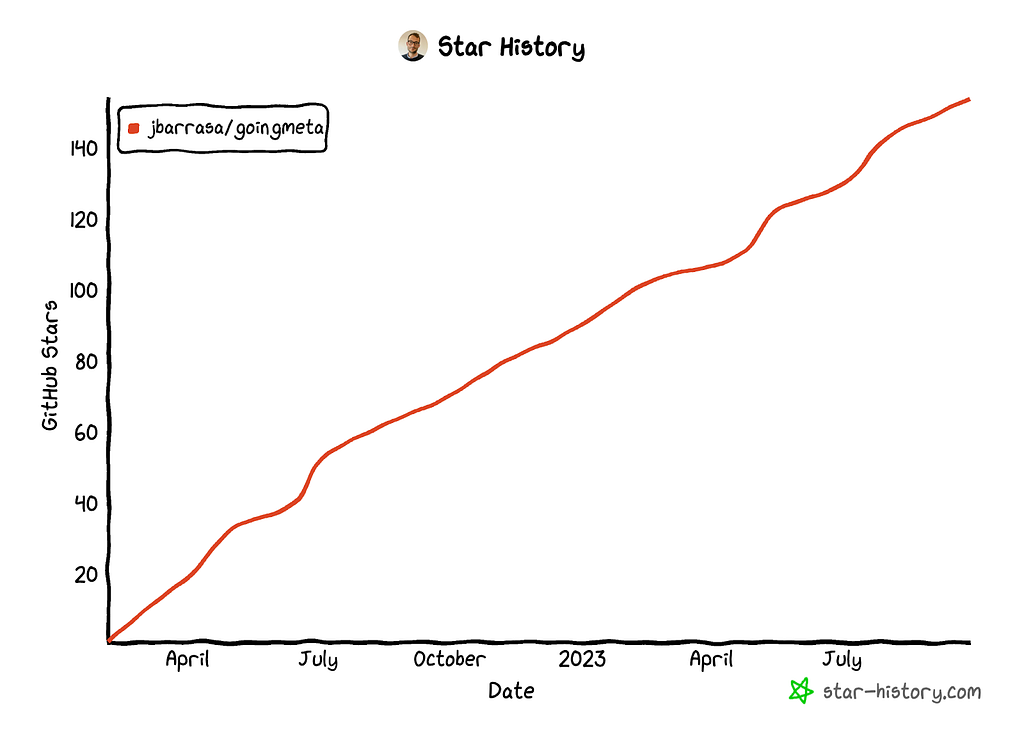 https://star-history.com/#jbarrasa/goingmeta&Date
https://star-history.com/#jbarrasa/goingmeta&Date요약 – 테마 등장
에피소드 20에서는 시간이 지나면서 게시했던 내용들을 되돌아보고, 콘텐츠를 정리하고, 구조를 좀 잡아보고 싶었어요. 저희에게도 꽤 흥미로운 작업이었죠. 왜냐하면 보통 스트리밍 직전에 다룰 내용을 결정하거든요. 핵심 테마는 분명히 있었겠지만, 혹시 숨겨진 패턴 같은 게 있었을까요? 정답은 '네, 있었어요!' 였고, 저희는 4가지 다른 트랙을 빠르게 찾아낼 수 있었답니다.
이 블로그를 가이드 삼아 콘텐츠를 탐색하고, 여러분에게 가장 관련 있는 내용을 찾아보세요. 의견이 있거나 특정 주제 (새로운 주제나 이미 다룬 주제 모두 좋아요!) 에 관심이 있다면 언제든지 의견을 남겨주세요 (아니면 엄지 척! 👍).

여러분이 데이터 엔지니어라면 데이터 파이프라인, 데이터 품질, 데이터 이동 (마이그레이션 등) 에 관심이 많을 텐데요. 이 트랙에서는 대상 스키마 (온톨로지) 의 의미론적 정의에 따라 움직이는 데이터 파이프라인 생성, Neo4j 및 RDF 소스/싱크와의 그래프 데이터 가져오기/내보내기를 다루는 에피소드를 찾을 수 있을 거예요. 특히 Neo4j에서 데이터 품질을 관리하고 제어하기 위해 그래프의 모양을 제한하는 방법에 대해 (정말 많이!) 집중적으로 다뤘답니다.
에피소드 (이 트랙):
3 - SHACL을 사용하여 그래프 모양 제어
5 – 온톨로지 기반 Knowledge Graph 구축
9 – 감독되지 않은 KG 구성. 그래프 관찰성
11 - 그래프 기대치에 따른 그래프 데이터 품질
18 – Triple Store에서 Neo4j로의 손쉬운 전체 그래프 마이그레이션
혹시 여러분이 지식 엔지니어, 온톨로지 전문가, 정보 설계자라면 의미론, 온톨로지, 공유 어휘에 관심이 많겠죠? 온톨로지는 마치 증강된 스키마처럼 데이터에 구조를 제공하는데요. 이를 위해서는 온톨로지를 관리해야 하고, 어떻게 관리하는지, 그리고 웹 프로테제 같은 도구를 사용해서 어떻게 작업하는지에 대한 예시를 보여드릴게요. Neo4j를 사용하면 온톨로지를 분석 및 관리하고, 시각적으로 탐색할 수 있으며, 구조적으로 분석해서 온톨로지 간의 불일치나 모순을 감지할 수 있다는 점! 정말 흥미롭죠?
에피소드 (이 트랙):
6 – 그래프 데이터로부터 온톨로지 학습
14 – 분류 Fine-tuning
16 – 분류의 의미 유사성 측정
19 – Neo4j의 온톨로지 버전 관리
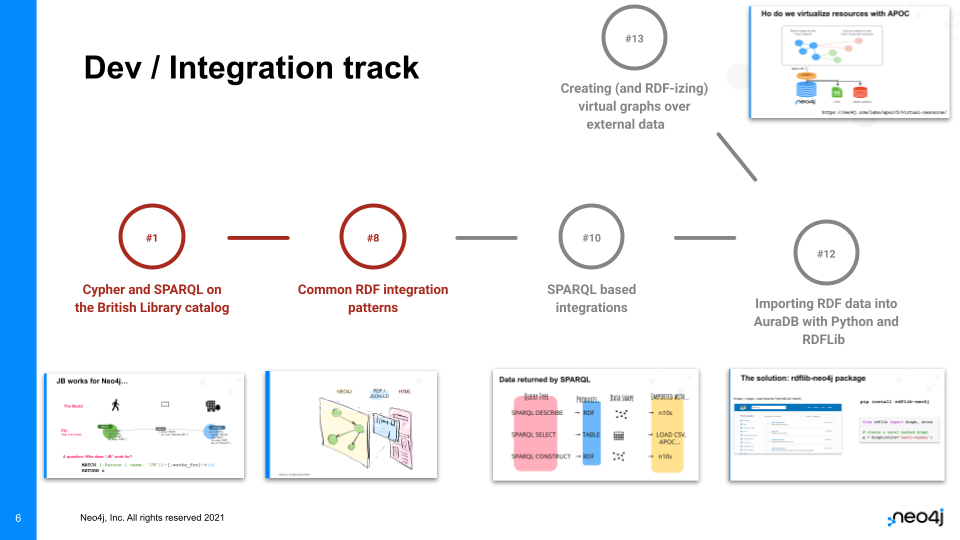
이건 상호 운용성/통합 트랙이에요. 의미론이나 Knowledge Graph 프로젝트에 필요한 엔진룸이라고 생각하면 될 것 같아요. 다양한 도구가 어떻게 함께 작동하는지, 그리고 이러한 프로세스를 가장 잘 설정하는 방법을 보여주죠. 그래서 이 트랙에서는 SPARQL 또는 다른 엔드포인트를 사용해서 RDF 데이터를 그래프로 가져오는 방법도 다루는 게 당연하겠죠?
에피소드 (이 트랙):
1 – 영국 도서관 카탈로그의 Cypher 및 SPARQL
8 – 일반적인 RDF 통합 패턴
10 – SPARQL 기반 통합
12 – Python 및 RDFLib를 사용하여 RDF 데이터를 AuraDB로 가져오기
13 – 외부 데이터에 대한 가상 그래프 생성(및 RDF화)
이건 거의... 이전 트랙의 후속 조치라고 봐도 될 것 같아요. 그래프에 데이터와 온톨로지가 있다면, 이제 뭘 해야 할까요? 이제 데이터와 온톨로지를 기반으로 추론을 자동화해서 지능형 애플리케이션을 구축할 수 있어요. 이 트랙에서는 이에 대한 몇 가지 예를 보여드릴게요.
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.