
다중 모달 모델 사용 사례
이번 튜토리얼에서는 Google의 Gemini Pro를 사용해서 ER(엔터티 관계) 다이어그램에서 엔터티, 관계, 필드를 추출한 다음, Neo4j에 저장된 Property Graph 모델의 자산으로 변환하는 게 얼마나 쉬운지 보여드릴게요.
프로젝트 소스 코드(Colab Notebook)는 여기 GitHub에서 확인하실 수 있어요.
Gemini 모델이 뭐죠?
Google Gemini는 지금까지 가장 발전된 AI 모델이라고 해요. 텍스트, 코드, 오디오, 이미지, 비디오 등 다양한 유형의 정보를 이해하고 생성할 수 있도록 설계된 **다중 모드** 모델이거든요. 수많은 벤치마크에서 최첨단 성능을 보여주고, 차세대 다중 모드 추론 기능을 도입했다고 하네요.
일반적으로 텍스트 전용 모델이나 이미지 전용 모델처럼 하나의 형식만 전문으로 하는 기존 모델과는 달리, **다중 모드 생성 모델**은 여러 유형의 데이터를 결합한 콘텐츠를 처리하고 생성할 수 있어서 더 포괄적인 이해와 풍부한 생성 기능을 제공해요.
Gemini는 Ultra, Pro, Nano 세 가지 버전으로 최적화되었는데요. 그중 **Gemini 1.0 Pro Vision**은 프롬프트 요청에 텍스트, 이미지, 비디오를 포함하고 텍스트나 코드 응답을 얻을 수 있어요. Google 온라인 문서에 따르면, Gemini는 광범위한 사용 사례를 가능하게 하는 시각적 이해 기능을 구현했다고 해요.
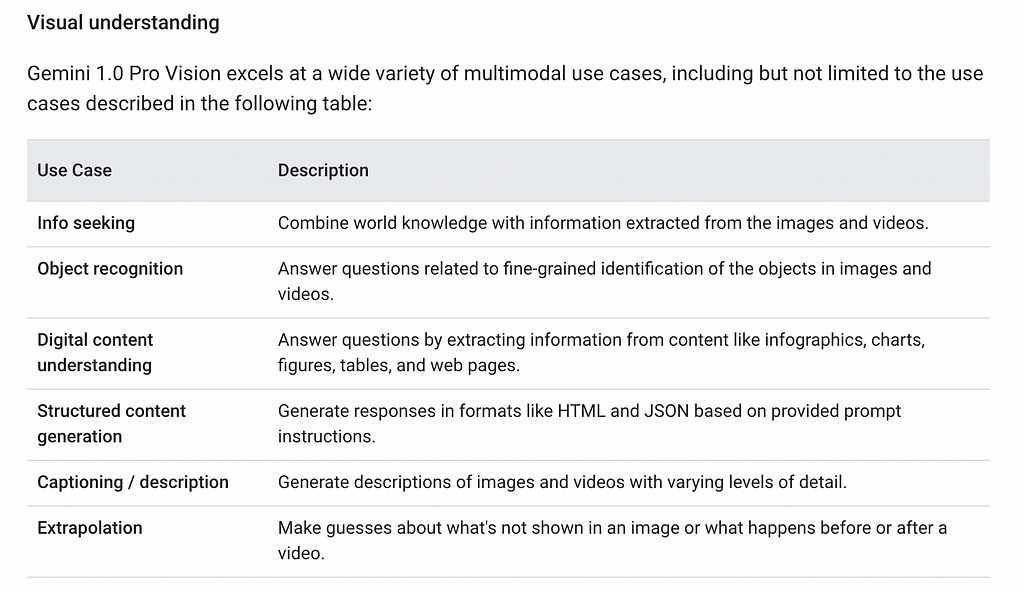
이번 튜토리얼에서는 **Gemini Vision Pro 1.0**을 사용해서 ER 다이어그램 그림에서 항목, 관계, 필드를 추출한 다음, Neo4j에 저장된 Property Graph 모델의 자산으로 변환하는 단계를 보여드릴게요.
Gemini 소개: 가장 크고 가장 유능한 AI 모델
Label Property Graph란 무엇인가요?
**LPG**(Label Property Graph)는 Node, Relationship, Property를 사용하는 Graph Database 모델의 한 유형이에요. LPG의 Node와 Relationship에는 그래프 내에서 해당 유형이나 역할을 정의하는 Label이 있을 수 있어요. Property는 Node 및 Relationship에 연결된 키-값 쌍으로, 추가 정보를 저장할 수 있죠. 이런 구조 덕분에 복잡하고 상호 연결된 데이터를 유연하고 직관적으로 모델링할 수 있어서 소셜 네트워크, 추천 시스템, Knowledge Graph처럼 풍부한 데이터 관계가 필요한 애플리케이션에 LPG가 유용해요.
다음은 Neo4j 웹사이트에 있는 간단한 그래프 예시입니다.
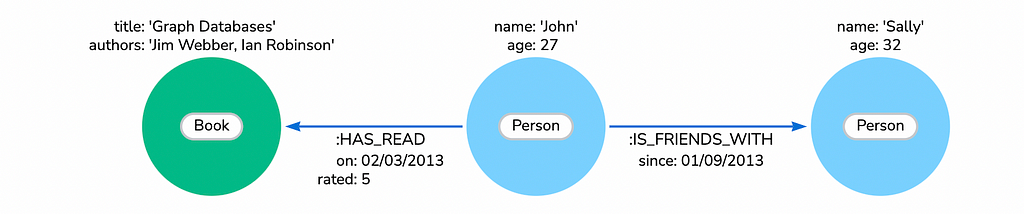
여기서 다음 사항을 확인할 수 있어요.
- **Node**(원)는 **Label**로 분류된 개체를 나타내요(예: 책, 사람 등).
- Node는 **Property**(이름/값 쌍)를 가질 수 있어요.
- **Relationship**(화살표)은 Node를 연결하고 작업을 나타내요.
- Relationship은 방향성이 있으며 **Property**(이름/값 쌍)를 가질 수 있어요.
Graph 모델은 특히 데이터 포인트 간의 연결이 데이터 자체만큼 중요한 경우에 관계를 처리하는 데 아주 뛰어나요. 관계 탐색의 깊이와 속도가 성능에 큰 영향을 미칠 수 있는 소셜 네트워크, 추천 엔진, 사기 탐지, Knowledge Graph, 공급망 같은 애플리케이션에 정말 중요하죠. Graph Database는 연결된 데이터를 Query할 때 유연성과 효율성을 제공하고, 특정 유형의 Query와 데이터 구조에 대해 더 나은 확장성을 제공해서 **관계형 데이터베이스보다 더 적합**할 수 있어요.
GenAI 관련 애플리케이션에서 Graph Database를 사용하는 방법에 대해 더 자세히 알고 싶으시다면, 제가 쓴 다른 블로그 게시물도 한번 확인해 보세요.
- PDF 문서에서 Graph+LLM 기반 RAG 애플리케이션 구축
프롬프트만 있으면 돼요
다음은 영화 데이터베이스에 대한 ER 다이어그램이에요.
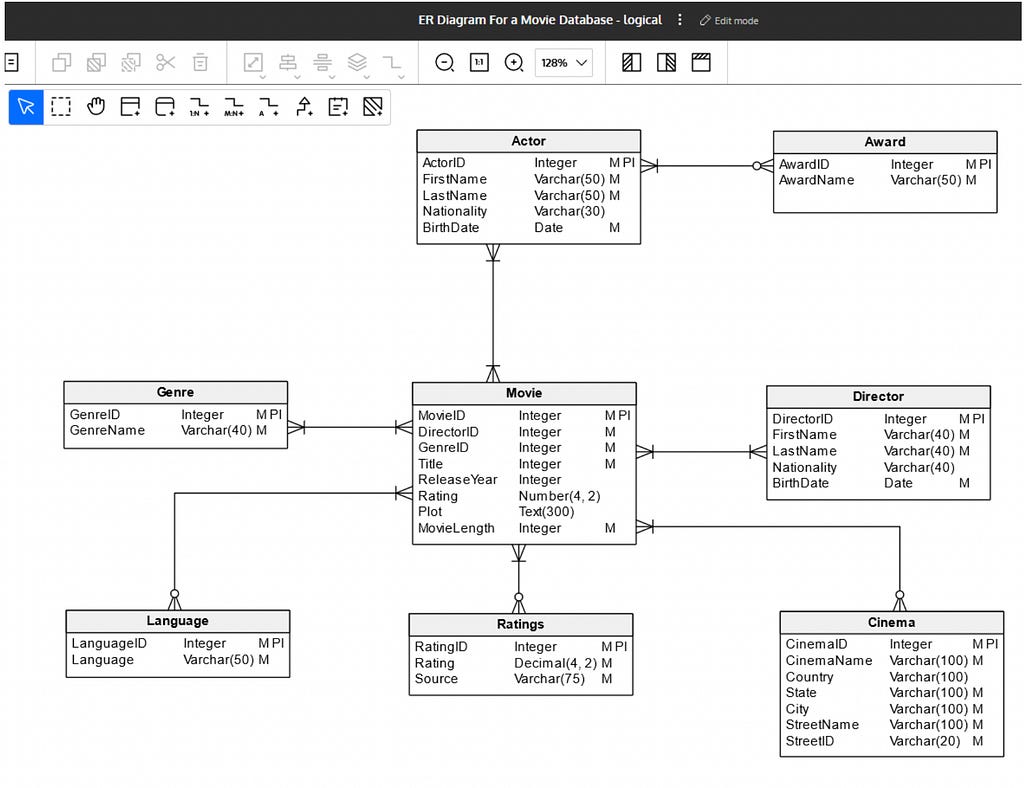
Gemini를 사용해서 ER 다이어그램에서 entity, relationship, field를 추출하는 건 정말 간단해요. 딱 3단계면 되거든요!
1 ) 준비
2 ) 프롬프트
3 ) 생성
from vertexai.generative_models import (
GenerationConfig,
GenerativeModel,
Image,
Part,
)
# Prepare an instance of gemini pro vision model
multimodal_model = GenerativeModel("gemini-1.0-pro-vision")다중 모달 모델의 경우, prompt는 아래 코드 스니펫처럼 텍스트, 이미지, 심지어 동영상으로 구성될 수도 있어요.
image_er_url = "https://github.com/Joshua-Yu/graph-rag/raw/main/gemini-multimodal/resources/movie-er.jpg"
image_er = load_image_from_url(image_er_url)
prompt = "Document the entities and relationships in this ER diagram and structure your response in JSON format for entity, relationship and their fields."
contents = [prompt, image_er]이제 남은 건 응답을 생성하는 거죠.
# Use a more deterministic configuration with a low temperature
generation_config = GenerationConfig(
temperature=0.1,
top_p=0.8,
top_k=40,
candidate_count=1,
max_output_tokens=2048,
)
responses = multimodal_model.generate_content(
contents,
generation_config=generation_config,
stream=True,
)
finalResponse = ""
print("n-------Response--------")
for response in responses:
# Because streaming mode is enabled, we need to collect all pieces of generated text
finalResponse += response.text
print(response.text)응답에는 ER 다이어그램에 따라 entity, relationship, 그리고 해당 field에 대해 인식된 자세한 정보가 담겨 있을 거예요.
-------Response--------
```json
{
"entities": [
{
"name": "Actor",
"fields": [
{
"name": "ActorID",
"type": "Integer",
"primary_key": true,
"not_null": true
},
},
... ... MORE ENTITIES TO FOLLOW ... ...
],
"relationships": [
{
"name": "Actor-Award",
"type": "many-to-many",
"source-entity": "Actor",
"source-field": "ActorID",
"target-entity": "Award",
"target-field": "AwardID"
},
... ... MORE RELATIONSHIPS TO FOLLOW ... ...
]
}
```ER-Graph Schema Mapping
관계형 모델을 그래프 모델로 변환하려면 다음 원칙부터 시작하는 게 좋아요.
- 테이블을 Node Label로
- 개별 Node Instance에 대한 행
- Node를 연결하는 Relationship/Edge에 대한 Foreign Key
- Node 및 Edge의 속성이 되는 속성/Field
이런 변환은 복잡한 관계와 계층을 관계형 테이블보다 더 자연스럽고 효율적으로 표현하는 Graph Database의 기능을 활용해서 상호 연결된 데이터에 대한 더 빠르고 직관적인 Query를 가능하게 해줘요. 이 접근 방식은 깊은 관계 순회가 필요하거나 연결된 데이터에서 실시간 통찰력을 얻어야 하는 애플리케이션의 성능과 확장성을 향상시켜 준답니다.
더 자세한 설명이 필요하다면 Neo4j 웹사이트의 이 글을 추천드려요.
관계형 데이터베이스에서 그래프 데이터베이스로 전환 – 시작하기
No-SQL 네이티브 Graph Database인 Neo4j는 Schema-light 스토리지를 구현했어요. 즉, Node나 Relationship에 대한 Schema 정의가 필수는 아니라는 거죠. DBMS는 데이터가 저장되는 동안 유형을 처리해요. 반면에 Neo4j는 Schema 일관성과 데이터 품질을 보장하기 위해 특정 Constraint를 제공하기도 한답니다.
다음 코드 조각은 응답으로 Entity를 살펴보고 Primary Key 속성()과 Null을 허용하지 않는 속성()에 대한 CREATE CONSTRAINT 문을 생성하는 예시를 보여줘요.
cypher_constraints = ""
cypher_load_nodes = ""
cypher_build_relationships = ""
# a.1 Iterate through entities and create UNIQUENESS and/or EXISTENCE constraints
for entity in responseJson.get("entities"):
entity_name = entity.get("name")
for field in entity.get("fields"):
field_name = field.get("name")
if field.get("primary-key") == "true":
cypher = f"CREATE CONSTRAINT {entity_name}_{field_name}_unique FOR (n:{entity_name}) REQUIRE n.{field_name} IS UNIQUE;n"
cypher_constraints += cypher
if field.get("not-null") == "true" and not field.get("primary-key") == "true": # primary-key must be unique
cypher = f"CREATE CONSTRAINT {entity_name}_{field_name}_notnull FOR (n:{entity_name}) REQUIRE author.{field_name} IS NOT NULL;n"
cypher_constraints += cypher
print(cypher_constraints)출력은 다음의 모음이에요. Cypher 명령문(Neo4j의 쿼리 언어)이죠:
CREATE CONSTRAINT Actor_ActorID_unique FOR (n:Actor) REQUIRE n.ActorID IS UNIQUE;
CREATE CONSTRAINT Actor_FirstName_notnull FOR (n:Actor) REQUIRE author.FirstName IS NOT NULL;
CREATE CONSTRAINT Actor_LastName_notnull FOR (n:Actor) REQUIRE author.LastName IS NOT NULL;
... ... ... ...
데이터 수집
각 테이블에 대해 추출된 레코드를 저장하는 CSV 파일이 있다고 가정하면, 생성된 응답을 사용하여 데이터 수집 스크립트를 생성하는 것도 어렵지 않아요.
내보낸 레코드가 CSV 파일이고, 열 헤더는 실제 속성 이름이라고 가정해 볼게요. 파일 이름은 런타임 시 작업 조정자에 의해 로 전달될 거예요.
> 엔터티 레코드 수집
다음 Python 코드는 각 항목에 대해 LOAD CSV 문을 생성해요.
for entity in responseJson.get("entities"):
entity_name = entity.get("name")
cypher_load_nodes = f"// ----------- LOAD CSV for nodes of {entity_name} -----------n"
cypher_load_nodes += f":autonWITH $filenamenLOAD CSV FROM $filename AS linenCALL " + "{" + f"nMERGE (n:{entity_name} "
set_statement = "SET "
for field in entity.get("fields"):
field_name = field.get("name")
if field.get("primary-key") == "true":
cypher_load_nodes += "{" + f"{field_name}:line.{field_name}" + "}" + ")n"
else:
set_statement = set_statement + f"n.{field_name} = line.{field_name},"
cypher_load_nodes += set_statement[:len(set_statement)-1]
cypher_load_nodes += "n} IN TRANSACTIONS 2000;"
print(cypher_load_nodes)샘플 출력:
// ----------- LOAD CSV for nodes of Actor -----------
:auto
WITH $filename
LOAD CSV FROM $filename AS line
CALL {
MERGE (n:Actor {ActorID:line.ActorID})
SET n.FirstName = line.FirstName,n.LastName = line.LastName,n.Nationality = line.Nationality,n.BirthDate = line.BirthDate
} IN TRANSACTIONS 2000;
여기서 강조할 점은 다음과 같아요.
a. LOAD CSV: CSV 파일의 각 레코드/라인을 살펴보고 지정된 label과 속성을 사용하여 node를 생성해요.
b. MERGE는 UPSERT와 같아요. 기본 키/속성은 node의 존재를 확인하는 데 사용되죠. 이는 위에 정의된 고유성 제약 조건에 의해 보장되고요.
c. 2000개의 레코드마다 업데이트가 하나의 트랜잭션으로 데이터베이스에 커밋돼요. 이를 통해 대량 데이터 수집의 성능과 안정성이 향상되죠.
> 관계 기록 수집
엄격하게 호환되는 3NF 데이터베이스에서 다대다 관계는 소위 관계 테이블 또는 조인 테이블에 저장될 가능성이 높아요. 여기서는 해당 테이블의 기록도 열 헤더가 있는 CSV 파일로 내보내진다고 가정해 볼게요.
다음 프로세스는 수집 관계에 대한 LOAD CSV 문을 읽고 생성할 수 있어요.
# a.3 Iterate Relationships to create relationship between nodes
#
# Naming conventions:
# - for source_node:SourceLabel -> target_node:TargetLabel, the name of relationship is HAS_<TargetLabel> in big cases
for relationship in responseJson.get("relationships"):
source_entity = relationship.get("source-entity")
source_field = relationship.get("source-field")
target_entity = relationship.get("target-entity")
target_field = relationship.get("target-field")
relation_name = relationship.get("name")
cypher_create_relationships = f"// ----------- LOAD CSV for relationships of {relation_name} -----------n"
cypher_create_relationships += f":autonWITH $filenamenLOAD CSV FROM $filename AS linenCALL " + "{n"
cypher_create_relationships += f"MATCH (e1:{source_entity}" + "{" + f"{source_field}:line.{source_field}" + "})n"
cypher_create_relationships += f"MATCH (e2:{target_entity}" + "{" + f"{target_field}:line.{target_field}" + "})n"
cypher_create_relationships += f"MERGE (e1) -[:HAS_{target_entity.upper()}]-> (e2)n" + "} IN TRANSACTIONS 2000;n"
print(cypher_create_relationships)샘플 출력:
// ----------- LOAD CSV for relationships of Actor-Award -----------
:auto
WITH $filename
LOAD CSV FROM $filename AS line
CALL {
MATCH (e1:Actor{ActorID:line.ActorID})
MATCH (e2:Award{AwardID:line.AwardID})
MERGE (e1) -[:HAS_AWARD]-> (e2)
} IN TRANSACTIONS 2000;Cypher에서는 관계가 생성 방향을 가져요. -> or <- 를 사용해서 방향을 나타내죠. 여기서 방향은 항상 Primary Key가 있는 항목을 가리키는 Foreign Key가 있는 항목에서 나온답니다.
결론
이 게시물이 올라오기 며칠 전에 Google은 무려 100만 개의 토큰을 지원하는 최신 Gemini 1.5 모델을 출시했어요. 정말 놀랍죠?
다양한 데이터 유형에 걸쳐 정보를 처리하고 생성할 수 있는 더욱 정교한 AI 시스템을 통해 GenAI의 미래가 펼쳐지고 있어요. 말이죠. 이러한 진화는 인간과 유사한 방식으로 세상을 더 잘 이해하고 상호 작용하는 모델로 이어질 가능성이 높고, AI-인간 인터페이스, 창의적인 콘텐츠 생성, 그리고 다양한 분야에서 복잡한 문제 해결에 획기적인 발전을 가져올 수 있을 거예요.
생성적 데이터 변환은 다중 모드 기능을 통해 지원되는 많은 사용 사례 중 하나일 뿐이에요. 앞으로 더 많은 소식을 기대해주세요!
Gemini - Google DeepMind
Gemini 1.5 기술 문서: .
- 쌍둥이자리
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'Ontology & Knowledge Graph' 카테고리의 다른 글
| LLM과 그래프의 만남: GenAI 그래프 축제 이야기 (0) | 2026.06.27 |
|---|---|
| 생성형 AI 윤리: 원칙과 리스크 완벽 분석 (0) | 2026.06.27 |
| GDPR 준수: GDPR 솔루션 구축을 위한 4가지 간단한 단계 (0) | 2026.06.26 |
| AI의 미래: Machine Learning과 Knowledge Graph의 만남 (0) | 2026.06.26 |
| I built a digital twin of my amateur-built airplane (0) | 2026.06.26 |