
Knowledge Graph에 대한 관심이 뜨거운데요. 하지만 Knowledge Graph를 구축하는 조직들은 그래프 성능을 저하시키는 중복된 `Node` 때문에 어려움을 겪고 있어요. 최고의 기술팀조차도 이런 중복 `Node`를 해결하는 데 어려움을 느낀다니까요.
이 문제에 대한 해결책은 바로 Entity Resolved Knowledge Graph(ERKG)에요! Knowledge Graph는 엔터티 해결 기능을 활용해서 Knowledge Graph의 정확성, 명확성, 그리고 유용성을 높여준답니다.
이번 글에서는 Entity Resolved Knowledge Graph에 대한 간단한 소개와 함께 실습 튜토리얼을 준비했어요.
- Knowledge Graph란 무엇일까요?
- 엔터티 해결이란 무엇일까요?
- Entity Resolved Knowledge Graph가 왜 중요할까요?
- ERKG – Before & After
- Neo4j 환경 설정
- 입력 데이터 세트 설치
- Senzing 라이브러리 설치
- Entity Resolved Knowledge Graph 구축
Knowledge Graph란 무엇일까요?
Knowledge Graph(KG)는 연결된 데이터를 유연하고 구조화된 방식으로 표현해서 고급 검색, 분석, 시각화, 추론 등 다양한 기능을 지원해요. 다른 방법으로는 얻기 힘든 기능들이죠. 다시 말해, Knowledge Graph는 연결된 세상에서 나오는 데이터를 맥락화하고 이해하는 데 도움을 줘요. 특히 데이터 간의 *관계*를 이해하는 데 유용하죠.
최근에는 Retrieval-Augmented Generation(RAG)이 AI 애플리케이션을 더 강력하게 만들면서 Knowledge Graph가 다시 주목받고 있어요.
엔터티 해결이란 무엇일까요?
(ER)은 동일한 실제 엔터티를 참조하는 데이터 레코드를 식별하고 연결하기 위한 고급 데이터 매칭 및 관계 검색 기술이에요.
예를 들어, 여러분의 비즈니스 데이터에는 간과된 중복 엔터티(예: 고객, 공급업체)가 있을 수 있어요. 이름이나 주소의 변화 때문에 놓칠 수도 있죠. 이런 중복 때문에 데이터 품질 문제가 생길 수 있어요. 예를 들어, 실제로 고객이 몇 명인지 정확히 알 수 없게 되는 거죠.
서로 다른 데이터 소스에 걸쳐 엔터티를 연결하려고 하면 문제는 더 심각해져요. 고객에 대한 전사적인 360도 뷰를 얻고 싶을 때 특히 그렇죠.
정확한 고객 수를 파악하거나, 데이터 세트 전체에 걸쳐 레코드를 연결하고 싶거나, 다운스트림 분석, 의사 결정 시스템, 모델 훈련 또는 다른 AI 애플리케이션에서 데이터를 활용하고 싶다면, 수백만 개의 서로 다른 엔터티를 이해하는 것이 정말 중요해요. 바로 이럴 때 엔터티 해결이 큰 도움이 된답니다.
Entity Resolved Knowledge Graph가 왜 중요할까요?
엔터티 해결 기능이 없는 Knowledge Graph는 중복된 `Node`(동의어) 때문에 어려움을 겪는 경우가 많아요. 그래프에 중복된 `Node`가 있으면 분석 잠재력이 제한되죠. 예를 들어, 고객이 6명인지, 아니면 6개의 정보를 가진 한 명의 고객인지 헷갈릴 수 있어요. 또, 중복된 `Node`는 시각화를 복잡하게 만들고 중요한 패턴을 찾기 어렵게 만들 수도 있어요.
그래프에서 중복된 `Node`를 해결하면 그 그래프는 Entity Resolved Knowledge Graph가 돼요. Entity Resolved Knowledge Graph는 다운스트림 그래프 분석, 그래프 기반 Machine Learning, 시각화 등의 정확성을 높여준답니다.
Entity Resolved Knowledge Graph는 사기 방지 시스템, 의료 분야의 임상 시험, 고객 서비스, 마케팅, 심지어 내부자 위협 및 유권자 등록을 포함한 다양한 분야에서 필수적이에요.
ERKG: Before & After
아래 시각화는 공개 소스에서 가져온 라스베이거스 비즈니스에 대한 85,000개 레코드로 구성된 그래프를 보여줘요. 이 데이터의 중복률은 2%이지만, 일부 기업에서는 최대 14개의 중복 레코드가 발견되기도 해요. 이 예시에서는 Entity Resolved Knowledge Graph를 사용했고, 그래프 분석을 통해 결과를 더 쉽게 이해할 수 있었어요. 실행하고 시각화하는 과정도 훨씬 빨라졌죠.
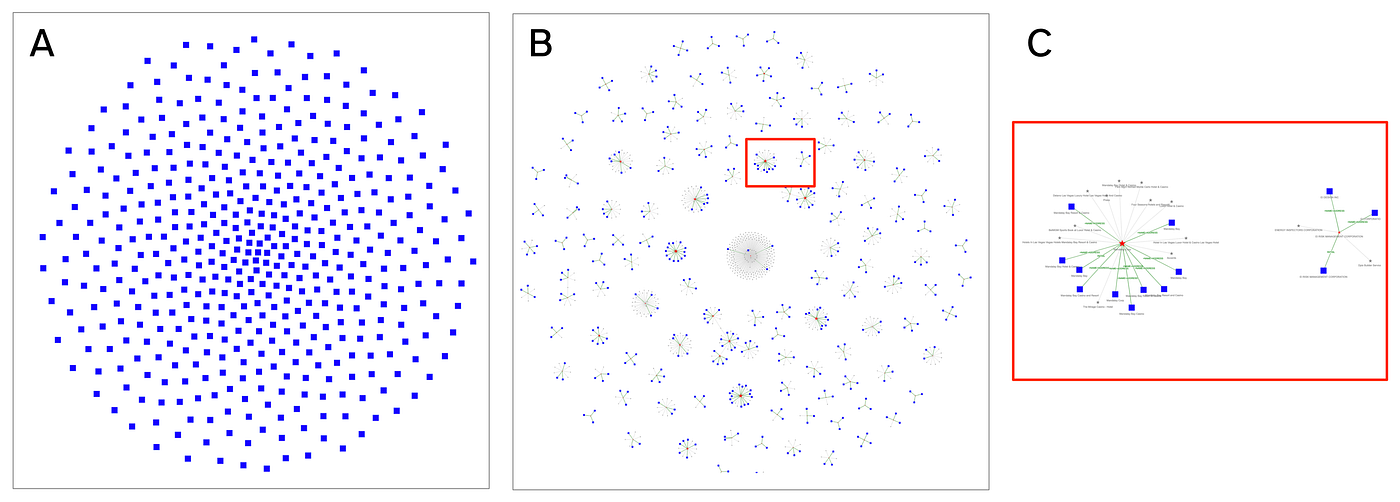
Knowledge Graph에 엔터티 분석을 적용하면 조직은 기업 데이터에서 더 나은 결정을 내리고, 경쟁력을 높이고, 사기를 줄이고, 고객에게 더 나은 서비스를 제공할 수 있어요. 많은 조직에서 엔터티 분석을 그래프로 가져오는 데 어려움을 겪고 있는데, 더 이상 힘들 필요가 없다는 사실!
이 작업을 수행하는 방법, 한번 살펴볼까요?
Python으로 작성된 이 실습 튜토리얼은 Senzing과 를 통합하여 엔터티 해결 Knowledge Graph를 구축하는 방법을 보여줘요. 코드는 다운로드하기 쉽고 따라하기도 쉬우니, 여러분의 데이터로도 한번 시도해 보세요!
다음은 예상 프로젝트 시간이 35분인 엔터티 해결 Knowledge Graph를 생성하기 위해 수행할 단계입니다.
- 라스베거스 지역 비즈니스에 대한 세 가지 데이터 세트(85,000개 레코드, 2% 중복)를 사용합니다.
(10분) - Run 중복된 상호 및 주소를 해결하기 위해 Senzing에서
(15분) - 내보낸 결과를 구문 분석하여 Knowledge Graph를 Neo4j에 넣습니다.
(5분) - 분석하고 시각화하세요. 엔터티 해결 Knowledge Graph.
(5분)
Neo4j Desktop을 기반으로 한 예제 코드를 살펴볼게요. Graph Data Science(GDS) 라이브러리를 사용하여 그래프에서 Cypher 쿼리를 실행하고 다운스트림 분석 및 시각화를 위한 데이터를 준비합니다. Jupyter, Pandas, Seaborn, 그리고 Pyvis를 활용하는 거죠.
이 튜토리얼에서는 두 가지 환경에서 작업하게 되는데, 구성과 코딩은 데이터 과학 분야에서 일하는 대부분의 사람들에게 익숙한 수준일 거예요. 다음 방법을 숙지해야 합니다.
- 데스크톱/노트북 애플리케이션을 설치합니다.
- GitHub에서 공개 저장소를 복제합니다.
- 클라우드에서 서버를 시작하세요.
- 간단한 Linux 명령줄을 사용하세요.
- Python으로 코드를 작성해 보세요.
클라우드 컴퓨팅 예산: 이 튜토리얼에서 Senzing용 클라우드 인스턴스를 실행하는 데 드는 비용은 총 $0.04 USD 정도예요.
Neo4j 환경 설정
는 트랜잭션 및 분석 워크로드를 확장하기 위한 엔터프라이즈급 보안 제어 기능과 함께 네이티브 그래프 스토리지, Graph Data Science, 파워 그래프 알고리즘, Machine Learning, 분석, 시각화 등을 제공해요. 2010년에 처음 출시된 Neo4j는 Cypher를 사용하는데, 이는 선언적 그래프 쿼리 언어이자 레이블이 지정된 Property Graph랍니다.
그래프는 **관계**를 이해하는 데 도움을 줘요. 관계형 데이터베이스, 데이터 웨어하우스, 데이터 레이크, 데이터 레이크하우스 등과는 달리 말이죠.
영어와 마찬가지로 Cypher에서도 명사는 Node(즉, 엔터티)를 그래프로 표시하는 반면 동사는 Relationship가 엔터티를 연결해요. Cypher는 Label을 정의하여 Node에서 영어로 이러한 범주가 고유 명사가 사람, 장소 또는 사물인지 등을 결정하죠. Cypher는 또한 Property를 정의하는데, 영어의 형용사인 Node와 Relationship 모두에 해당해요. Cypher 쿼리의 표현력 덕분에 SQL의 유사한 앱보다 10배 적은 코드로 데이터 분석 애플리케이션을 구축할 수 있다는 사실! 정말 흥미롭죠?
코딩을 시작하려면 먼저 Neo4j Desktop 애플리케이션부터 시작해야겠죠? 다운로드 지침에 따라 데스크톱이나 노트북에 설치해주세요. Neo4j를 시작하는 방법은 여러 가지가 있지만, Desktop은 필요한 기능들을 빠르게 시작할 수 있도록 도와줘요. Mac, Linux, Windows 모두 지원한답니다.
다음으로는 새 프로젝트와 데이터베이스를 만들어볼까요? 비밀번호도 설정해주고요. 설정은 다음과 같이 할 거예요.
- 프로젝트:
Entity Resolution(자격 증명에는 필요 없는 설정이에요) - 데이터베이스:
Senzing(자격 증명에는 필요 없는 설정이에요) - DBMS:
neo4j(기본값, 변경하지 않을 거예요) - 사용자 이름:
neo4j(기본값, 변경하지 않을 거예요) - 비밀번호:
uSIv!RFx0Dz(저희 설정이에요. 무작위로 생성했답니다)
Neo4j 버전도 선택해야 해요. 여기서는 글을 쓰는 시점에서 최신 버전인 5.17.0을 사용할게요.
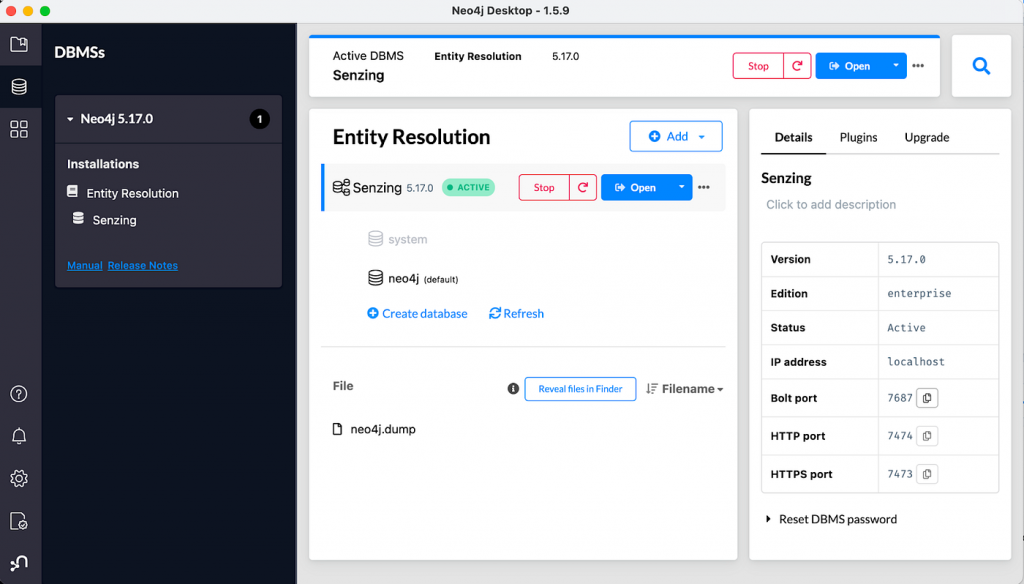
새로 생성된 데이터베이스를 클릭하면 "Neo4j Desktop" 그림처럼 오른쪽 패널에 설정 및 관리 링크가 나타날 거예요. 여기서 Plugin 링크를 클릭하고 Graph Data Science Library 드롭다운에서 GDS 플러그인을 설치해주세요. GDS 라이브러리를 사용해서 Python 코드로 Neo4j에 접근할 거거든요.
다음으로 Start 버튼을 클릭하세요. GDS 플러그인이 설치되고, 그래프 데이터베이스에 접근하기 위한 로컬 서비스 엔드포인트가 준비되어야 해요. 그런 다음 Details 링크를 클릭해서 Bolt 프로토콜의 포트 번호를 찾아보세요. 저희 예시에서는 7687이 Bolt 포트 번호랍니다.
이제 브라우저 창을 열어서 GitHub 공개 저장소에서 이 튜토리얼 코드를 다운로드할 차례에요.
"GitHub에서 공개 저장소 복제" 그림에 보이는 것처럼 GitHub에서 해당 URL을 복사해서 저장소를 복제하면 돼요. 복제된 저장소를 다음 단계에 따라 working directory로 사용해서 이 튜토리얼을 진행할 거예요.
작업 디렉토리에 연결한 후 다음과 같은 파일을 만들어요. .env 파일에는 Bolt를 통해 Neo4j Desktop의 데이터베이스에 액세스하는 데 필요한 자격 증명 (Bolt URL, DBMS, 사용자 이름, 비밀번호)을 넣어주세요.
Neo4j Desktop은 Graph Database를 탐색하고 실행하기 위한 브라우저를 포함해서 정말 유용한 도구들을 많이 제공해요. Cypher 쿼리나 Bloom 데이터 시각화 도구도 사용할 수 있죠. 디스크에 있는 데이터베이스의 "덤프"를 내보내고 가져와서 백업을 관리할 수도 있고요.
Neo4j는 정말 최고예요! 이 튜토리얼의 나머지 부분에서는 Neo4j 데스크톱 애플리케이션을 백그라운드에서 계속 실행할 거예요. Python API와 Python 코드를 사용하는 Graph Data Science(GDS) 라이브러리를 통해 액세스할 거고요. 이러한 라이브러리에 대해 자세히 알아보려면 다음 링크를 참고해주세요.
입력 데이터 세트 설치
저희는 세 가지 데이터 세트를 사용해서 엔터티 확인을 실행하고 Knowledge Graph를 구축할 거예요. 시작하려면 Python 환경을 설정하고 필요한 라이브러리를 설치해볼게요. 그런 다음 내부에서 코드 예제를 실행할 수 있어요. Jupyter 노트북에서요. 여기서는 Python 3.11의 사용법을 보여줄 건데, 다른 최신 버전의 Python도 잘 작동할 거예요.
Python용 가상 환경을 설정하고 필요한 종속성을 로드해볼게요.
이 튜토리얼에서는 데이터 과학 작업에서 일반적으로 사용되는 몇 가지 인기 있는 라이브러리를 사용할 거예요.
이제 Jupyter를 시작해볼까요?
JupyterLab은 브라우저에서 자동으로 열릴 거예요. 그렇지 않은 경우에는 http://localhost:8888/lab을 새 브라우저 탭에서 열어주세요. 그런 다음 datasets.ipynb 노트북을 열어주세요.
먼저, 실행할 코드에 필요한 Python 라이브러리 종속성을 가져와야 해요.
다시 한번 확인해볼게요. Watermark를 사용해서 시스템 종속성 문제를 해결해야 하는 경우를 대비해 추적해두는 게 좋겠죠.
예를 들어 결과는 다음과 같아야 해요.
Python, Jupyter, GDS, Pandas, 정말 좋네요! 이제 이걸 활용해서 우리가 사용할 데이터세트를 한번 살펴볼까요?
이 튜토리얼에서는 데이터세트에 따라 이름, 주소 및 기타 세부 정보 등 비즈니스 정보를 설명하는 세 가지 데이터세트를 사용할 거예요.
- SafeGraph: (POI).
- 미국 노동부: 임금 및 시간 준수 조치 데이터(WHD).
- 미국 중소기업청: $150,000 이상의 PPP 대출 (PPP).
이 튜토리얼에서는 라스베거스 대도시 지역 내의 기업으로 제한된 이러한 데이터 세트 버전을 사용하고 있어요. 우리는 또한 DATA_SOURCE 열을 사용하는데, 나중에 Senzing에서 레코드를 로드하고 추적하는 데 사용될 거예요.
이 데이터 세트를 다운로드해주세요 (튜토리얼 결과를 일관되게 만들기 위해 시간에 따른 스냅샷).
간결성을 위해 파일 이름을 다음과 같이 줄였어요. poi.json, dol.json, 그리고 ppp.json, 각각.
각 데이터 세트를 한번 살펴볼까요? 이를 돕기 위해 유틸리티 함수를 정의할게요. sample_df() 함수는 Pandas의 열의 하위 집합을 표시하는 데 사용될 거예요. DataFrame 객체에서요.
이제 (POI) 데이터 세트를 SafeGraph에서 가져와볼게요.
저희는 name 열을 복사해서 LOCATION_NAME_ORG라는 새로운 열을 만들었어요. 이는 나중에 Neo4j에 레코드를 로드하고 그래프를 시각화하는 데 사용될 거고, Senzing에 로드되는 데이터의 일부는 아니에요.
컬럼명을 살펴보면, DATA_SOURCE, RECORD_ID, 그리고 RECORD_TYPE 열은 고유한 레코드를 식별하기 위해 Senzing에서 필요한 열이고, 엔터티 확인 중에 이름이나 주소와 관련된 다른 열도 사용될 거예요.
참고로 SafeGraph 문서에서 각 열의 데이터에 대한 자세한 설명을 확인할 수 있어요.
몇 가지 주요 열을 확인해볼게요.
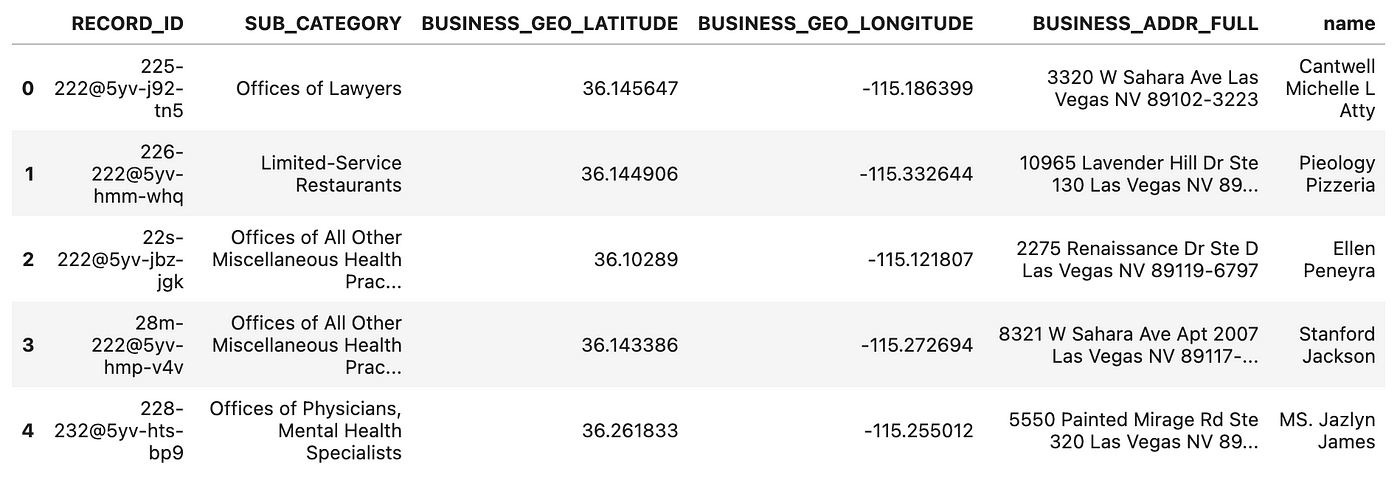
이 샘플에서 RECORD_ID 외에 업체 이름과 주소도 추가되어 있네요. 비즈니스 카테고리 값은 Knowledge Graph에 구조를 추가하는 데 사용될 수 있어요. 이걸 바로 Taxonomy라고 하죠. 그리고 와 지리 좌표는 그래프 쿼리 결과를 지도 시각화로 변환하는 데도 도움이 될 거에요.
다음 열의 데이터 값을 분석해 볼까요?

우리가 작업할 수 있는 레코드가 79,946개나 되네요! RECORD_ID 값은 모두 고유하고요. 388가지의 다양한 비즈니스 카테고리가 있는데, 시각화하면 정말 재미있을 것 같아요.
비즈니스 이름에는 67,555개의 고유 값이 있고, 31,831개의 고유 값이 BUSINESS_ADDR_FULL 열에 있네요. 이러한 중복 법인은 뭘까요? 여러 위치에 있는 업체(예: BurgerKing)일 수도 있고, 동일한 위치에 있는 여러 업체(예: Gallery Mall)일 수도 있겠죠? 알아보기 위해서는 Entity Resolution을 돌려봐야겠어요!
다음으로는 Wage and Hour Compliance Action Data (WHISARD), 즉 미국 노동부 데이터를 살펴볼게요:
노동부가 발표한 데이터 사전 웹사이트에서 각 필드에 대한 설명을 확인할 수 있어요.
열 이름을 다시 살펴보니 DATA_SOURCE, RECORD_ID, 회사 이름 및 주소 정보, 시간제 근로자에 대한 DoL 규정 준수 데이터가 많이 보이네요.
좀 더 흥미로운 열을 확인해 볼까요?

이번에도 고유한 레코드 ID, 회사 이름, 주소가 있고, NAICS 비즈니스 분류 정보도 포함되어 있어요. 이 정보는 POI 데이터세트에도 포함되죠. case_violtn_cnt 컬럼은 규정 준수 위반 사례 수를 제공하는데, 나중에 그래프 쿼리에 활용하면 정말 흥미로울 것 같아요.
이 샘플의 데이터 값을 분석해볼까요?

레코드 ID는 고유하지만 업체 이름과 주소가 중복되는 경우가 있어요. 하지만 여기에는 1,554개의 기록만 있어서, 해결된 모든 법인이 노동부 규정 준수 정보에 연결되는 건 아니에요. 그래도 있는 데이터를 최대한 활용해봐야죠!
다음으로는 $150,000 이상의 PPP 대출(PPP) 데이터세트인데요, 미국 중소기업청에서 제공하는 라스베이거스 데이터에요.
이 데이터 세트는 코로나19 팬데믹 기간 동안 PPP 대출(있는 경우)을 기반으로 각 기업에 대한 미국 연방 공개 데이터의 자세한 내용을 담고 있어요.
샘플을 한번 살펴볼까요?

좋아요! 여기에서 비즈니스 유형에 대한 자세한 정보를 얻을 수 있고, 고용에 대한 새로운 세부 정보도 얻을 수 있네요. 이 두 가지 모두 DoL WHISGARD 데이터 세트를 보완해줄 수 있을 것 같아요.
이 샘플의 데이터 값 분석:

다시 말하지만, 레코드 ID는 고유하고 업체 이름과 주소가 겹치는 경우가 있어요. 3,488개의 고유 레코드가 있으니, 해결된 모든 엔터티에 PPP 데이터가 있는 건 아니겠죠. 14가지 다양한 비즈니스 유형이 있다는 점도 Knowledge Graph에 구조를 추가하는 데 도움이 될 수 있을 것 같아요.
이제 세 가지 데이터 세트가 준비되었으니, 이 레코드들을 Neo4j에 로드해볼게요. 먼저, .env 파일에 저장된 자격 증명을 사용해서 Neo4j Desktop에서 실행되는 Senzing Graph Database에 연결하기 위한 GDS 인스턴스를 생성해야 해요.
그래프에 구조를 추가하기 전에, 먼저 입력 데이터 레코드를 나타내는 Node의 고유성을 보장해야 해요.
다음으로, 데이터 세트에서 데이터를 정리하고 준비하는 유틸리티 메서드를 정의할 거예요.
이제 Neo4j에 레코드를 로드할 수 있어요. Cypher 절 UNWIND는 DataFrame (예: $rows 파라미터)를 개별 행으로 변환해 준답니다.
하위 쿼리와 결합된 이 절은 일괄 로드처럼 작동해요. 10,000개의 미니 배치를 사용하면 한 번에 하나의 트랜잭션을 반복하여 행을 로드하는 것보다 훨씬 빠르게 실행할 수 있죠.
이제 이 접근 방식을 사용하여 세 가지 데이터 세트를 로드해 볼게요.
짜잔! 이제 Neo4j에는 거의 85,000개의 레코드가 Node로 표시돼요. 하지만 이 Node들에는 연결이 없네요. 분명히 업체 이름과 주소 간에 중복이 있었지만, 아직 법인으로 확인된 항목은 없어요. 다음에는 이 문제를 수정하고 이 데이터가 어떻게 그래프가 되기 시작하는지 한번 살펴볼까요?
로드된 각 레코드의 Neo4j Node에는 다음이 포함돼요.
- A
:RecordLabel: 다른 종류의 Node와 구별하기 위한 Label이에요. - 고유 ID
uid: 입력 데이터 세트 레코드에 다시 연결돼요. - 데이터세트의 다른 필드를 나타내는 속성: 데이터세트의 다른 필드를 나타내는 Property에요.
Senzing 라이브러리 설치
Senzing은 실시간 엔터티 해결을 위해 특별히 제작된 AI를 제공해요. 6세대 산업용 엔진으로 을 개발자에게 쉽게 만들어주죠. 회사의 모토는 "우리는 자동차가 아닌 변속기를 판매한다"에요. 분명히 말하면, 이 기술의 모든 것은 최고 품질의 ER을 위한 속도, 정확성 및 처리량을 제공하는 데 중점을 두고 있으며, 올바른 데이터를 올바른 사람에게 실시간으로 연결해요. 이 분야에 대한 회사의 전문성은 정말 뛰어나죠. 팀의 엔지니어들은 평균 20년 이상 이 기술을 위해, 종종 극단적인 생산 사용 사례에서 함께 작업해 왔대요.
Senzing 바이너리는 클라우드 또는 온프레미스 인프라에서 완전히 로컬로 다운로드되고 실행돼요. 또한 GitHub에서 30개 이상의 공개 저장소를 찾을 수 있어요. 최대 100,000개의 레코드에 대한 무료 라이센스를 사용하여 즉시 다운로드하고 실행할 수 있다는 점! 이는 가장 큰 사용 사례부터 노트북에서 실행하는 것까지 확장된다고 하니 정말 유용하죠? GitHub에서 소스로 사용 가능한 Docker 컨테이너 또는 다음의 이미지에서 실행할 수 있고, Docker Hub, 또는 다음을 사용하여 코드를 개발할 수도 있어요. API 바인딩 자바와 파이썬용으로 말이죠.
여러 가지 편리한 방법이 있네요. 프로덕션 사용 사례는 일반적으로 컨테이너에서 실행되는 Senzing API를 마이크로서비스로 호출하는 Java 또는 Python 애플리케이션을 개발해요. 이 튜토리얼에서는 클라우드의 Linux 서버에서 Senzing을 실행해 볼 거예요. Linux 명령줄을 통해 액세스하는 단계는 간단하며 이미 Python에서 사용할 수 있는 데모 코드가 있답니다. 데이터 세트를 클라우드 서버로 가져온 다음 파일 전송을 사용하여 ER 결과를 내보낼 수 있어요.
Debian(Ubuntu) Linux 사용을 기반으로 단계를 따라가 볼게요. 먼저, 4개의 vCPU와 16GB 메모리를 갖춘 Ubuntu 20.04 LTS 서버를 실행하는 인기 있는 클라우드 제공업체 중 하나(하나 선택)를 사용하여 Linux 서버를 시작해야 해요. 메모리를 충분히 구성하는 것이 중요해요.
이제 Senzing 설치 프로그램 이미지를 다운로드하고 실행해 보세요.
Linux 배포판 및 버전에 따라 마지막 두 단계에서 설치가 필요할 수 있어요. libssl1.1 올바르게 실행되기 전에 말이죠. 가장 확실히, apt 이 경우 설치 프로그램 유틸리티는 오류 메시지를 통해 알려줄 거예요! 지침은 StackOverflow의 질문-답변에 나와 있어요.
이제 Senzing 라이브러리를 설치할 준비가 되었어요.
이 설치 위치는 /opt/senzing/data/current 에요. Senzing, 정말 멋지죠!
다음으로 Senzing용 샘플 데이터 로더를 사용해 볼게요. G2Loader Python으로 작성된 건데요, 이 애플리케이션은 프로덕션 사용 사례에서 사용하는 것과 동일한 API인 Senzing API를 호출해요. 자세한 내용이 궁금하다면 코드를 확인하고, GitHub의 다른 예를 참고해 보세요.
G2Loader를 위한 프로젝트를 만들어 볼게요. 이름은 ~/senzing 사용자 홈 디렉터리에 만들 거예요:
그런 다음 구성을 설정해 줄게요.
다음으로 세 가지 데이터세트를 클라우드 서버에 업로드해야 해요. 예를 들어, 클라우드 공급자의 스토리지 그리드에 있는 버킷을 통해 이러한 파일을 전송할 수 있어요. 이 튜토리얼에서는 이러한 파일을 다음 위치에 배치했어요. lv_data 하위 디렉터리에 말이죠:
다음으로, 이러한 데이터세트를 Senzing으로 로드할 준비를 해 주세요. 로 말이죠:
실행하는 것이 더 간단할 수도 있어요. ./python/G2ConfigTool.py 쉘 프롬프트에 위에 표시된 명령을 입력하는 대신 대화형으로 구성 도구를 사용하면 된답니다.
이제 Senzing에서 ER을 실행할 준비가 되었어요. 입력 프로세스를 병렬화하기 위해 최대 16개의 스레드를 사용하도록 지정해 볼게요. 이러한 방식으로 다음 단계는 여러 CPU 코어를 활용하고 몇 분 내에 완료될 거예요.
이제 한 줄을 사용하여 확인된 엔터티를 JSON 파일로 내보낼 수 있어요.
이 결과를 직접 확인하려면 export.json 파일을 열어보면 되는데요, 여기에는 각 줄마다 사전 형태로 데이터가 들어있어요. 간단한 명령어를 사용해서 첫 번째로 해결된 엔터티를 예쁘게 출력해 볼 수 있어요.
전체 내용을 다 보여드리진 않겠지만, 출력 결과는 대략 이런 식으로 시작될 거예요.
export.json 파일을 클라우드 서버에서 데스크톱/노트북으로 가져온 다음 작업 디렉토리로 옮겨주세요.
자, 이제 끝났어요! 정말 빠르죠? 클라우드 서버를 띄우고, Senzing을 설치하고, 3개의 데이터 세트를 로드하고, 엔터티 분석을 실행한 다음 결과를 다운로드하는 데 1시간도 안 걸렸어요. 이걸 다 하는데 총 $0.04 USD 정도 들었네요 (클라우드 서버 설정에 따라 다르겠지만요). 물론 로컬에서 Docker 컨테이너를 실행해서 Senzing을 마이크로서비스처럼 호출할 수도 있지만, 지금은 다룰 내용이 좀 더 많아질 것 같아요.
엔터티 해결 Knowledge Graph 구축
Jupyter 브라우저 탭으로 돌아가서 graph.ipynb 노트북을 열어볼게요. 잊지 말고 Python 라이브러리 의존성을 다시 가져와야 해요.
그리고 워터마크 추적도 확인해 주세요.
이제 Senzing의 *엔터티 해결* 결과를 사용해서 Neo4j에 *Knowledge Graph*를 구축할 준비가 끝났어요. ER에서 파생된 엔터티와 관계는 KG의 구조를 연결하는 데 사용될 거예요.
ER의 구문 분석된 결과를 Python 객체로 표현하기 위해 dataclass를 정의해 볼게요.
이제 클라우드 서버에서 다운로드한 export.json 파일에서 JSON 데이터를 구문 분석해 볼까요? 고유 식별자로 인덱싱된 엔터티 사전을 만들어서 나중에 KG를 구성할 때 사용할 각 엔터티의 "해결된" 레코드와 "관련된" 레코드를 모두 추적할 거예요.
그렇게 최신 Mac 노트북에서는 이 작업이 약 3초 만에 끝났어요.
해결된 엔터티에 대한 입력 데이터 준비를 마무리하기 위해 레코드 연결을 빠르게 탐색하고, 시각화할 그래프에 관계가 있는 "흥미로운" 엔터티에 대해 has_ref 플래그를 설정해 볼게요.
구문 분석된 엔터티 레코드 중 하나를 한번 살펴볼까요?
엔터티와 레코드에 대한 고유 ID가 있으니, 이걸 사용해서 그래프 데이터의 관계로 연결할 수 있겠죠. 게다가 레코드 일치가 어떻게 결정되었는지에 대한 흥미로운 정보도 얻을 수 있는데, 이건 그래프 관계의 속성으로 활용할 수 있을 거예요.
다음으로 Neo4j Graph Database에 연결하기 위한 GDS 인스턴스를 생성한 다음 :Entity 노드를 만들어볼게요:
이제 엔터티를 노드로 로드하는 건 정말 간단해졌어요.
각 엔터티를 해결된 레코드와 연결해 줄게요.
마찬가지로 각 엔터티를 관련 엔터티와 연결해 줍니다.
자, 이제 지금까지 Graph Database에 구축한 것, 즉 지금까지의 KG의 구조에 대한 *개요*를 한번 살펴볼까요? Neo4j Desktop 창의 Browser에서 다음 Cypher 명령어를 실행해서 neo4j$ 데이터베이스 스키마를 시각화하라는 메시지를 표시해 주세요.
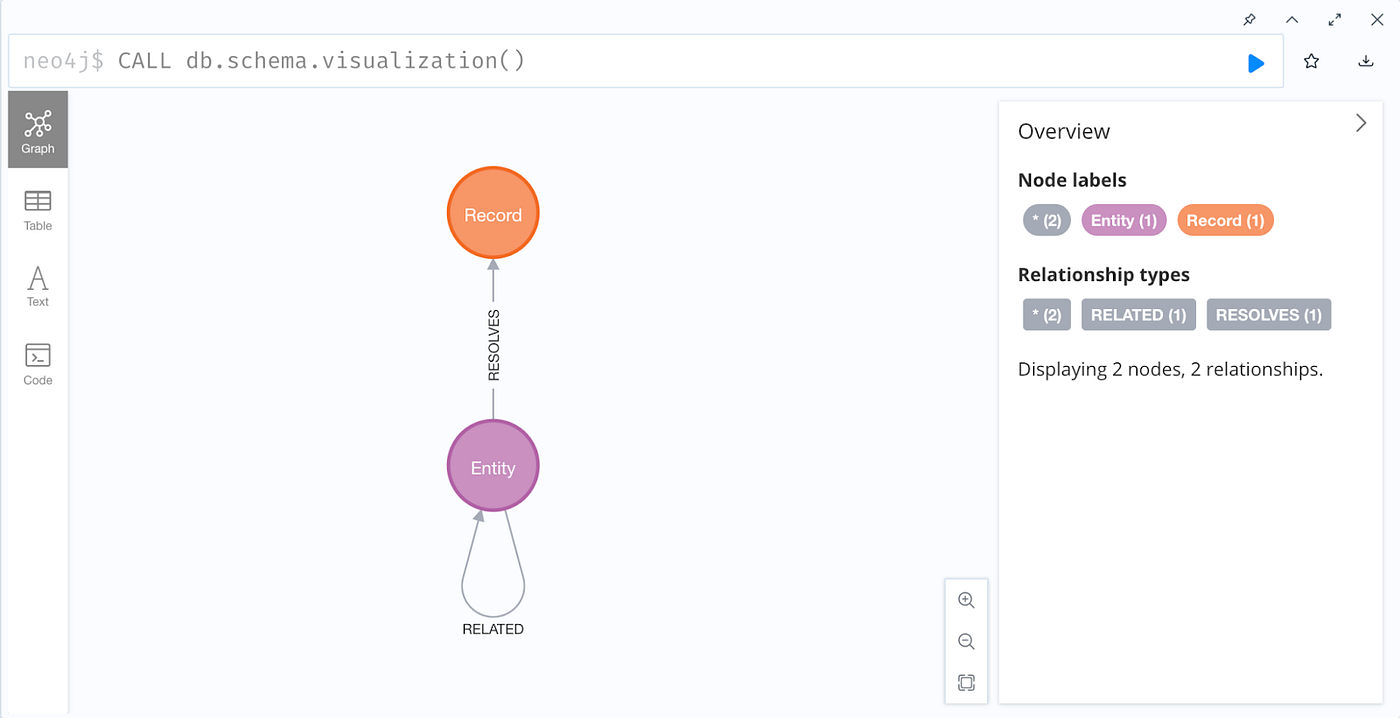
이제 Knowledge Graph처럼 보이기 시작했죠? 좀 더 자세히 알아볼까요?
세 가지 데이터 세트에 걸쳐 레코드를 연결하려고 하니까, ER 프로세스가 입력 데이터 세트 간에 레코드를 얼마나 통합했는지 측정하는 게 도움이 될 거예요. 특히 다음 사항을 이해하면 도움이 될 텐데요.
- 총 엔터티 수
- 연결된 참조가 있는 엔터티 수 (100%여야 해요)
- 엔터티당 연결된 레코드 수
- 엔터티당 관련 엔터티 수
Jupyter 브라우저 탭에서 impact.ipynb 노트북을 열어볼게요. 이전과 마찬가지로 필요한 라이브러리를 임포트하고 워터마크를 확인한 후 GDS 인스턴스를 생성할게요. 그런 다음 GDS를 활용해서 Pandas, Seaborn 등으로 분석을 실행할 거예요.
결과는 다음과 같아요.
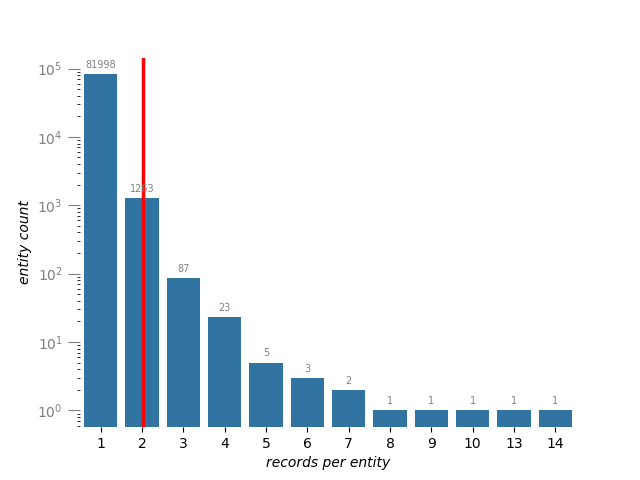
좋아요! 입력 레코드의 100%가 예상대로 엔터티로 확인되었네요. 이러한 기록 중에서 평균 ~2%의 중복률이 감지되었어요.
해결된 기록 및 관련 엔터티의 분포를 확인해 볼게요.

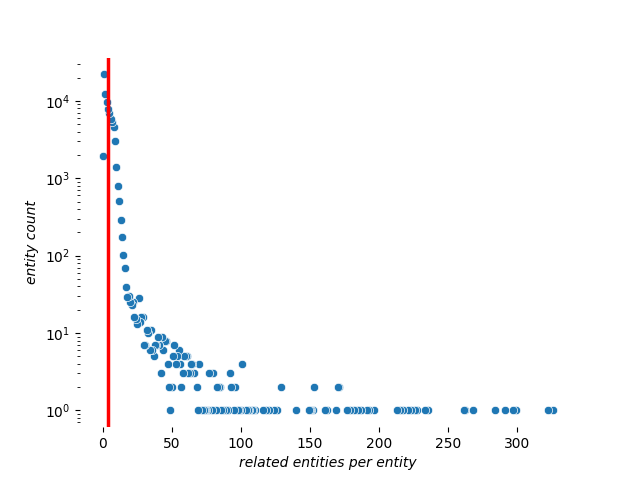
엔터티당 해결된 레코드의 평균 개수는 약 1.02개이고, 관련 엔터티의 평균 개수는 엔터티당 약 4.13개에요. 일부 엔터티는 300개 이상의 관련 엔터티를 가지고 있네요!
해결된 엔터티에 대해 좀 더 자세한 통계 분석을 해볼까요? 다음 단계를 반복해볼게요. Graph Data Science는 연결을 탐색하기 위한 일련의 단계로 구성되어 있어요:
- GDS를 사용하여 Neo4j에서 Cypher `Query`를 실행합니다.
- Pandas로 `Query` 결과를 `DataFrame` 객체에 수집합니다.
- Seaborn을 사용해서 결과를 분석하고 시각화합니다.
Pyvis라는 Python 라이브러리를 사용해서 Knowledge Graph의 관계를 시각화해볼게요. 먼저 연결되지 않은 부분을 보여드릴 건데요. 입력 레코드에서 중복되지 않은 비즈니스 엔터티를 필터링해서 ER의 영향을 시각적으로 비교할 수 있도록 할 거예요.
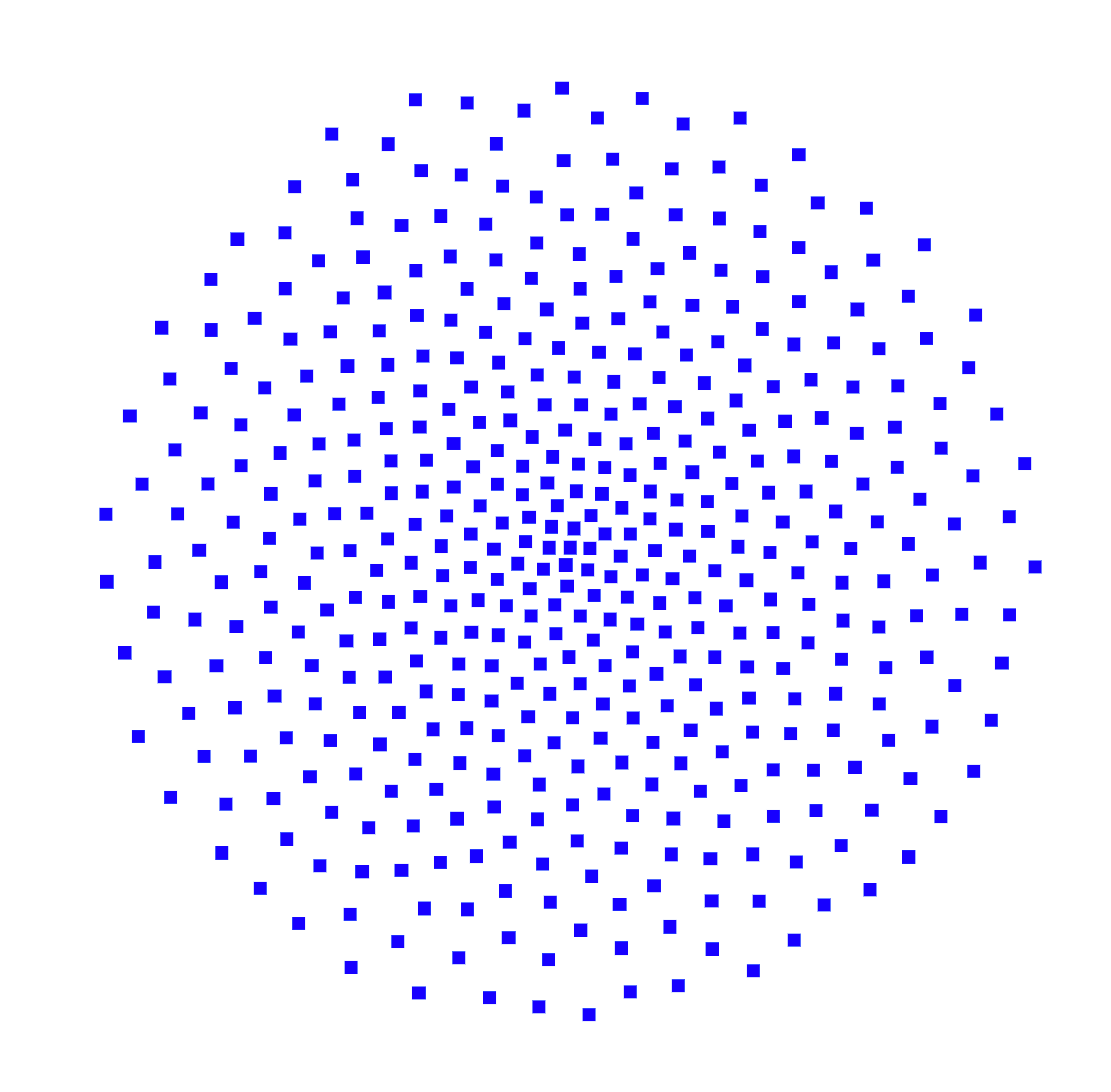
위 시각화는 Neo4j에 로드된 세 가지 데이터 세트의 레코드만 보여주고 있어요. 이 단계에서는 이걸 라고 할 수 있겠죠. 아직 링크가 없으니까요! 차이점은 데이터 그래프가 Knowledge Graph보다 구성 수준이 낮다는 점이에요. 특히 출처에 대한 자세한 내용을 제공하지만 KG에 대한 의미가 부족하답니다.
이제 엔터티 해결을 통해 데이터 세트 레코드가 어떻게 수렴되는지 설명해 드릴게요.
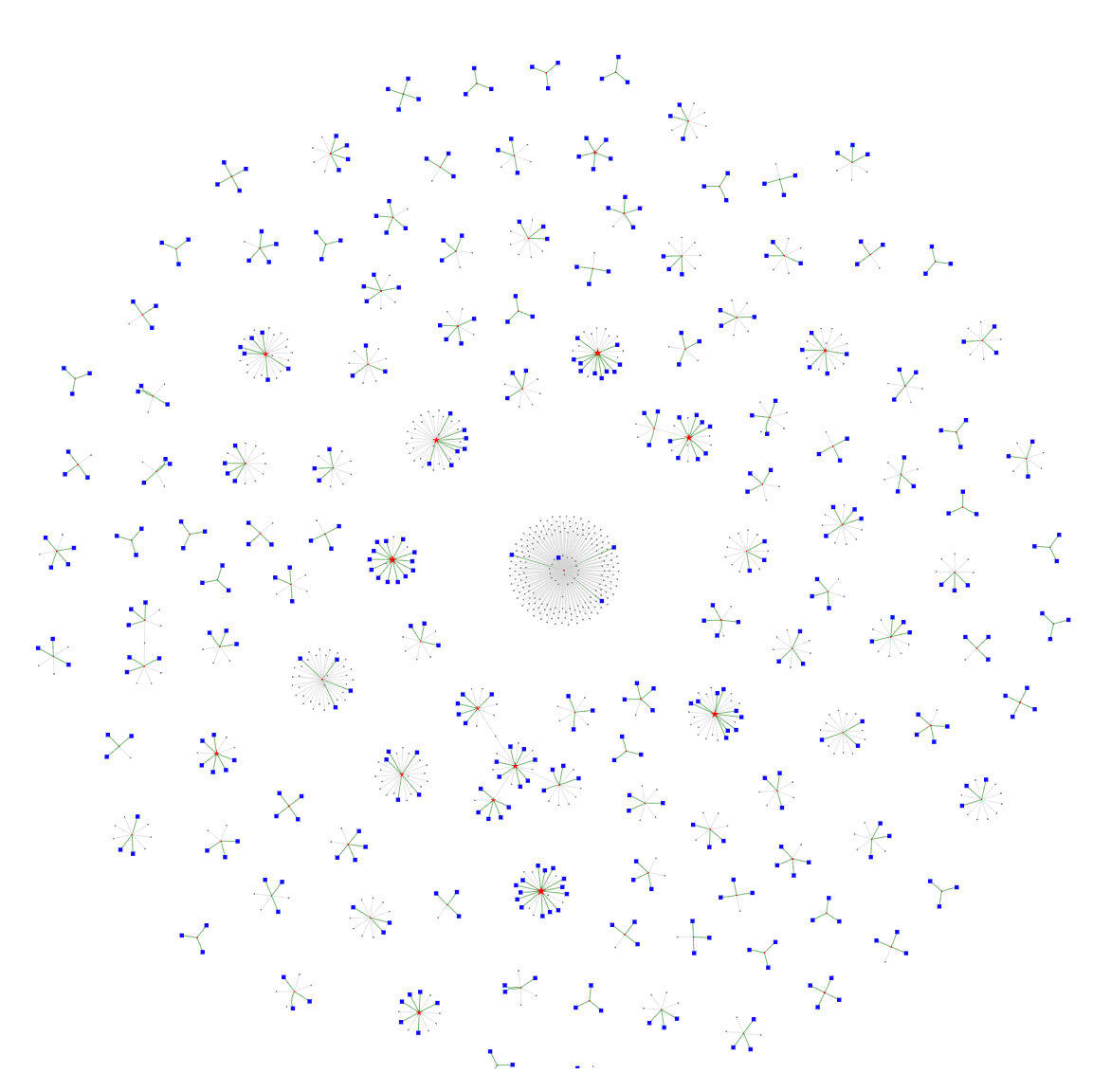
짜잔! 그래프가 나타나기 시작했어요! 전체 HTML+JavaScript 파일은 용량이 커서 로드하는 데 몇 분 정도 걸릴 수 있다는 점 참고해주세요. 또한 big_vegas.2.html 파일을 웹 브라우저에 넣어주세요.
여기서 빨간색 별은 엔터티이고 파란색 사각형은 입력 데이터 레코드에요. 이 클러스터들을 주목해주세요. 그 중 일부에는 동일한 엔터티에 연결된 12개 이상의 레코드가 있답니다.
시각화 중앙 바로 위의 그래프를 확대해서 한번 살펴볼까요? MATCH_KEY 라벨과 엔터티 해결 중 결정을 설명하는 :RESOLVES 관계를 주목해주세요:
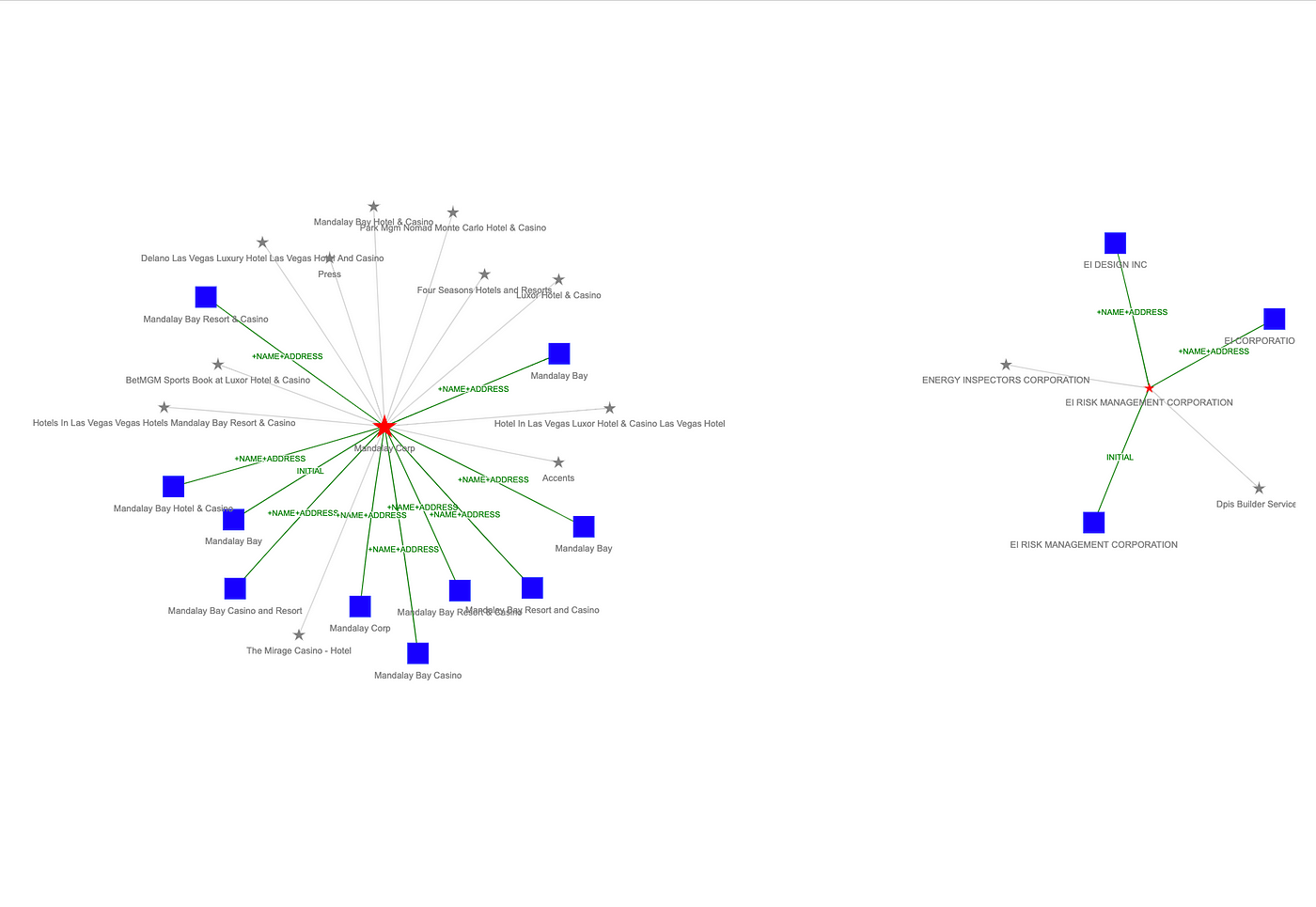
우리가 설정한 방식에 따라 title 속성을 :Record 노드에 설정했기 때문에 "플라이오버"를 통해 해당 레코드의 모든 속성을 볼 수 있어요.

다시 Neo4j Desktop으로 돌아가서 왼쪽 사이드바 메뉴에서 Neo4j Bloom을 클릭해 보세요. 훨씬 더 강력한 인터랙티브 그래프 시각화 및 분석 도구죠.
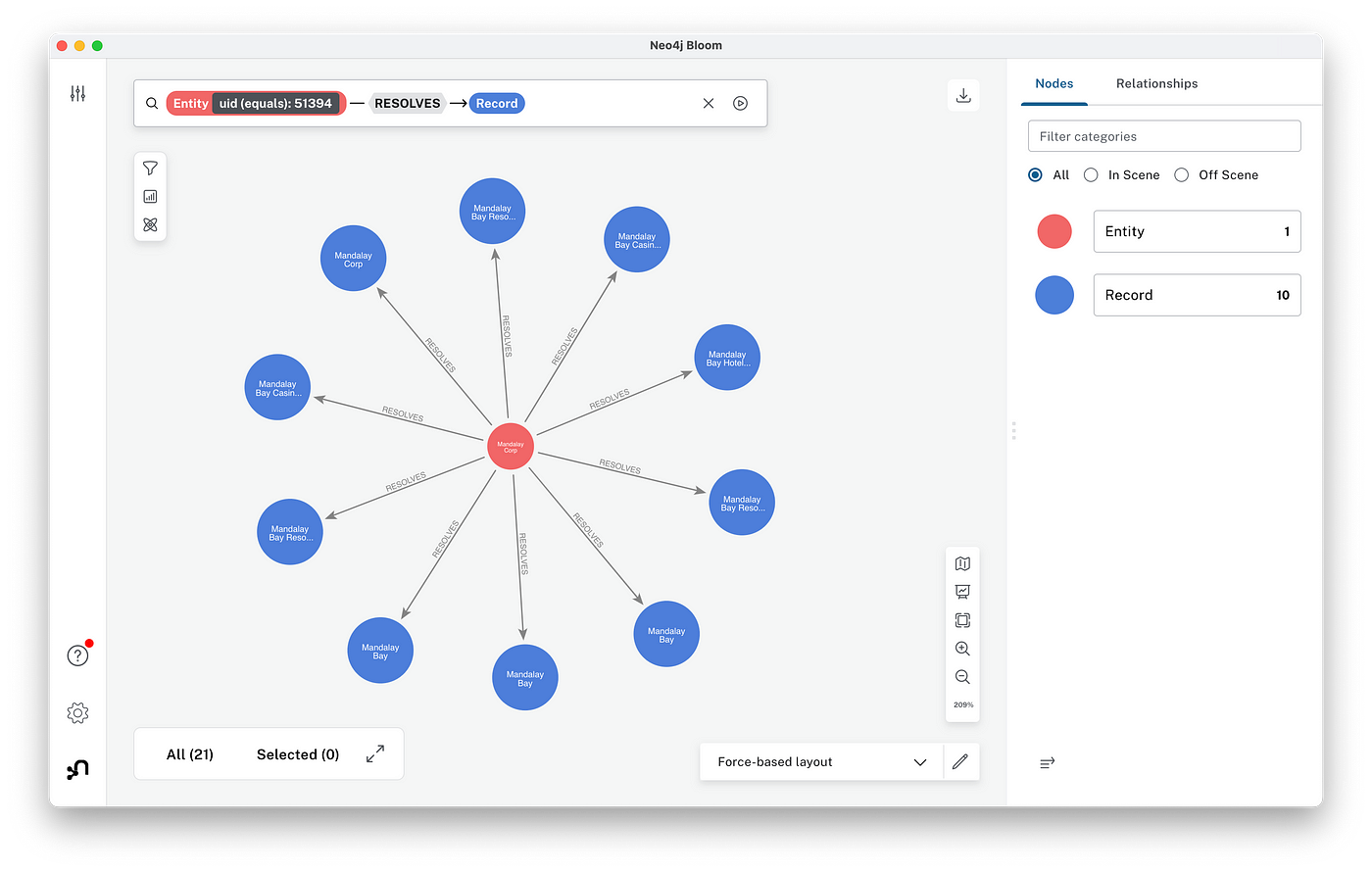
왼쪽 상단의 쿼리 상자를 클릭하면 Bloom에서 탐색하려는 관계를 설명하는 창이 나타날 거예요. 오른쪽에는 속성, 색상, 모양 등을 지정하는 데 사용할 수 있는 패널이 있답니다. 위 그림은 (:Entity)-[:RESOLVES]->(:Record) 관계를 보여주고 있어요. 이 그래프를 확대하면 Mandalay를 나타내는 엔터티로 확인된 10개의 레코드가 표시되는데, 대부분 DoL WHISARD 데이터 세트에서 나온 중복 항목들이에요.
Senzing에서 엔터티 확인의 가장 강력한 기능 중 하나는 특정 엔터티를 감사하고 업데이트할 수 있다는 점이에요. 마찬가지로 Neo4j의 Knowledge Graph의 힘은 해결 기록을 통해 빠르고 편리하게 탐색하여 업데이트가 필요한 사례를 식별할 수 있다는 데 있죠. AI 사용 사례와 같은 ERKG 기반의 다운스트림 애플리케이션은 수정된 엔터티 데이터를 활용하는 데 아주 유용할 거예요.
지금까지 우리가 해낸 작업 목록을 한번 살펴볼까요?
- 이 튜토리얼에 필요한 코드를 얻기 위해 Neo4j Desktop을 설치하고 공개 GitHub 저장소를 로컬로 복제했어요.
- 라스베이거스의 기업에 대한 세 가지 데이터세트를 로드했어요. 85,000개의 기업에 대한 기록이었고, 이름과 주소의 약간의 변화에 따라 2%가 중복되었죠.
- Pandas를 사용하여 입력 데이터를 검토한 다음 Neo4j에 레코드를 로드했어요. 이 시점에서는 연결되지 않은 Nodes와 속성으로 기록되었답니다.
- Linux 클라우드 서버 인스턴스에 Senzing을 설치하고 세 가지 데이터 세트를 업로드한 후 *엔터티 해결*을 실행했어요.
- ER 결과를 데스크탑/노트북으로 다시 내보낸 다음 JSON을 구문 분석하고 엔터티를 Neo4j에 로드했죠.
- 엔터티를 입력 레코드와 연결했어요.
- Seaborn을 사용하여 ER이 만드는 차이를 정량적 및 히스토그램으로 분석했어요.
- PyViz를 사용하여 "이전"의 대화형 시각화를 구축했어요. *데이터 그래프* 대 "이후" *엔터티 해결 Knowledge Graph*죠.
- 또한 이 데이터를 마이닝하여 KG에 더 많은 구조를 구축하고 이를 활용하는 방법에 대해 많이 생각했어요. *GraphRAG*를 통해 라스베가스에 대한 궁금증을 해결해주는 맞춤형 LLM 애플리케이션을 구축하는 것도 고려해봤답니다.
엔터티 해결 Knowledge Graph를 LLM 애플리케이션과 결합했을 때 우리가 답할 수 있는 질문들을 상상해보세요. 예를 들어, "자전거 판매점과 영화관 근처에 직원 수가 많고 규정 위반 이력이 없는 피자 레스토랑이 어디에 있나요?" 와 같은 질문에요.
더 자세한 사용법을 알고 싶다면, 아래 비디오를 꼭 시청해보세요. Mel Ricchi가 설명하는 Entity Resolution Knowledge Graph 데모 영상이랍니다! (Entity Resolution Knowledge Graph 분석)
Senzing AI와 Entity Resolution 작동 방식에 대해 더 자세히 알고 싶다면 다음 자료들을 참고하세요:
- Entity Resolution이란 무엇일까요? Entity Resolution 정의
- Entity Resolution을 단계별로 설명해드릴게요
- Entity Resolution: AI 애플리케이션에 대한 통찰력 및 시사점
- Entity Resolution Knowledge Graph의 이점
Neo4j에 대해 더 많은 정보를 얻고 싶으신가요? 온라인에는 정말 다양한 자료들이 준비되어 있고, 멋진 개발자 커뮤니티도 있답니다. 에서 그래프 기술을 지원하는 70개 이상의 공개 저장소를 확인해보세요. 최근에는 Neo4j 소개 영상도 올라왔네요. GraphAcademy에서는 다양한 온라인 강좌, 인증 프로그램 및 기타 리소스를 찾아볼 수 있어요.
- Entity Resolution
- erkg
- rag
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'Ontology & Knowledge Graph' 카테고리의 다른 글
| BearingPoint와 함께 그래프 탐험: 5분 인터뷰 (1) | 2026.06.23 |
|---|---|
| 지식 그래프로 유럽 천연 가스 네트워크 탐험하기 (1) | 2026.06.22 |
| Top 10 활용 사례: ID 및 접근 관리 (0) | 2026.06.22 |
| 엔터프라이즈 그래프: Dan Woods와의 5분 인터뷰 (1) | 2026.06.21 |
| 지식 그래프로 RAG 애플리케이션 정확도 높이기 (0) | 2026.06.21 |