
- Graph Data Science
편집자 주: 이프레젠테이션은 Adi Dev Katiyar님이GraphSummit 방갈로르에서 발표한 내용이에요.
이번 시리즈의 여덟 번째 프레젠테이션에서는 방갈로르 투어의 하이라이트를 소개할게요. Yokogawa의 클라우드 기술 설계자인 Adi Dev Katiyar님의 프레젠테이션을 통해, 회사가 어떻게 디지털 혁신을 주도하고 Knowledge Graph를 통해 서로 다른 정보를 통합하는지 알아볼까요?
재밌게 봐주세요! 더 궁금한 점이 있다면 daniel.ng@neo4j.com으로 편하게 메일 주세요.

Yokogawa는 하드웨어 제품을 만들고 석유 및 가스 정유소를 완벽하게 모니터링하는 제어 시스템을 배포하는 회사예요. 100년 넘게 운영되어 온 회사라서 디지털 세계로 쉽게 전환할 수 없는 레거시 자산이 많죠. 그래서 이런 자산을 **Knowledge Graph**에 통합해서 맥락을 파악하고 분석을 수행하면서 천천히 발전해 왔어요.
저희 제품과 고객은 극한의 온도와 압력 조건에서 작동하기 때문에 안전이 정말 중요해요. 저희 엔지니어의 약 75%는 운영 기술 엔지니어인데, 보통 화학 엔지니어거나 계측 엔지니어들이에요. 나머지 25%는 IT 전문가들이고요. IT 전문가들은 복잡한 글로벌 가치 사슬에 통합해야 하는 수많은 데이터 사일로를 다루고 있어요. 예를 들어, 사우디아라비아나 러시아에서 석유를 전 세계적으로 정제하는데, 그 과정 전체에서 원유의 특성이 변하거든요. 이 모든 정보를 추적해서 **Knowledge Graph**에 통합해야 해요.
주요 과제
저희의 주요 과제는 다음과 같아요:
- 자산의 전체 용량을 활용할 수 있도록 자동화 시스템을 디지털 방식으로 혁신하는 것.
- 여러 데이터베이스, 기술 스택, 그리고 인프라에 분산된 서로 다른 데이터 소스를 통합하는 것. 보통 정유소에 서비스를 제공하는 유일한 공급업체는 아니기 때문에 Honeywell, Siemens, ABB 같은 다른 회사와 긴밀히 협력해서 현장 문제를 해결하고 있어요.
이런 문제를 해결하기 위해 저희는 협력하는 모든 정유소에서 작동하는 **Knowledge Graph**로 다양한 정보 모델을 점진적으로 구축해야 했어요. 그래서 **Neo4j Graph Database**를 사용하기 시작한 거죠.
엔지니어링 지원: 애플리케이션 엔지니어 및 도메인 엔지니어
저희는 도메인 엔지니어와 애플리케이션 엔지니어 모두가 직관적이고 시각적인 그래프 형태로 지식을 전달할 수 있도록 돕고 싶었어요. **Knowledge Graph**를 사용해서 정보를 템플릿화하고, 다양한 정유소와 고객 간에 정보를 확장하고 전송할 수 있었죠.
**Neo4j**의 설계를 통해 속도와 민첩성을 높이고 데이터 소스 전체에서 작업할 수 있어요. **Knowledge Graph**는 정보 모델을 구현하는 IT 엔지니어와 머릿속에 모델을 갖고 있는 OT 엔지니어 사이의 간극을 해소해 줘요. **Graph** 데이터 모델의 유연한 구조 덕분에 이런 기능들의 기술을 하나의 기술로 결합할 수 있는 거죠.
엔지니어링 애플리케이션의 용이성
모델을 만든 후에는 최종 고객 애플리케이션에서 사용하고 싶었어요. 예를 들어, 새로 생성된 **Graph** 모델을 다른 변수 집합을 사용해서 고객에게 적용할 수 있지만, 기본 모델은 여전히 동일해요. 그런 다음 다른 변수를 사용해서 다른 고객에게 접근할 수 있지만, 다시 한번 동일한 모델을 사용하는 거죠. 솔루션이 모델 템플릿을 인스턴스화하고 이를 최종 사용자의 실시간 변수에 바인딩하기 때문에 로우 코드 또는 노 코드 솔루션 엔지니어링의 용이성이 크게 향상돼요.
물론 이런 모델은 고정되어 있지 않고 비즈니스 시나리오에 따라 계속 발전하고 있어요. 예를 들어, 저희는 일본 회사이기 때문에 러시아에서 사업하는 게 어려워졌어요. 프로세스가 변경되거나 직원이 변경되면 모델은 엔지니어가 쉽게 변경할 수 있도록 해당 변경 사항을 구현하는 방법을 업데이트해요.
기타 사용 사례
저희는 전문가가 그린 모델을 쉽게 가져올 수 있기를 바라요. 엔지니어가 마인드 맵 스케치를 그렸다고 가정해 볼까요? 손으로 그린 마인드 맵을 어떻게 데이터베이스나 IT 인프라로 가져올 수 있을까요?
또 바라는 점은 분석 및 AI 파이프라인에 반영되는 고성능 모델을 설계하는 거예요. 이건 저희에게 미래 지향적인 질문이죠. 첫 번째 단계는 다양한 IT 데이터 사일로를 모두 통합해서 정보 모델을 구축하고 여기에 컨텍스트를 추가하는 거예요. 그런 다음 이걸 분석이나 AI 파이프라인에 제공하고 통찰력을 도출하기 시작하는 거죠.
저희는 항상 기존 인프라 투자 위에 이런 지식 도구를 구축하는 방법을 찾고 있어요. 공장 자산이나 인프라를 교체하는 건 결코 쉬운 일이 아니고, 대개 공장 현장에 이미 있는 것을 그대로 유지해야 하거든요. 이런 현지화 때문에 데이터 사일로가 너무 많은 이유 중 하나이기도 하고요.
저희는 모델 수명 주기 전체에서 직관적이고 일반적인 기술 스택을 지원할 수 있어야 하고, 모든 사용 사례에서 엔드투엔드 서비스를 제공하는 스택을 채택하고 싶어요. **Graph Database**는 이걸 수행하는 데 도움이 되지만, Linux Foundation에서도 홍보하는 개방형 표준인 GraphQL도 마찬가지예요. 저희가 구축하고 있는 기술 스택은 모델 템플릿을 저장하고, 직관적이고 효율적인 검색을 허용해야 하며, 정보 사일로를 허물고 모델을 발전시켜 통찰력을 얻어야 해요.
Graph Database 및 도구 살펴보기

저희는 어떤 기술 스택이 적절한지 살펴보기 시작했어요. 이 여정을 시작했을 때 **Graph Database**는 생각도 못 했죠. 네 가지 평가 기준을 통해 **Graph Database**가 저희 요구 사항에 적합하고 매우 직관적이라는 걸 천천히 발견했어요.
첫 번째 경우에는 Arrows와 **Neo4j**의 Data Importer를 사용할 계획이에요. 이걸 통해 엔지니어는 정보 모델이 어떤 모습일지 머릿속으로 묘사하고, 무료 도구에서 **Graph Database**로 변환할 수 있죠.
정보 저장을 위해 Neo4j Graph Database와 정보 저장용 브라우저가 있어요. 이러한 정보 모델을 검색하기 위해 Cypher와 GraphQL을 사용하죠. 통찰력은 다음을 사용하여 얻을 수 있고요. Bloom and Neo4j Graph Data Science. Neo4j에서는 그래프 분석을 수행하는 것이 정말 훌륭해요.
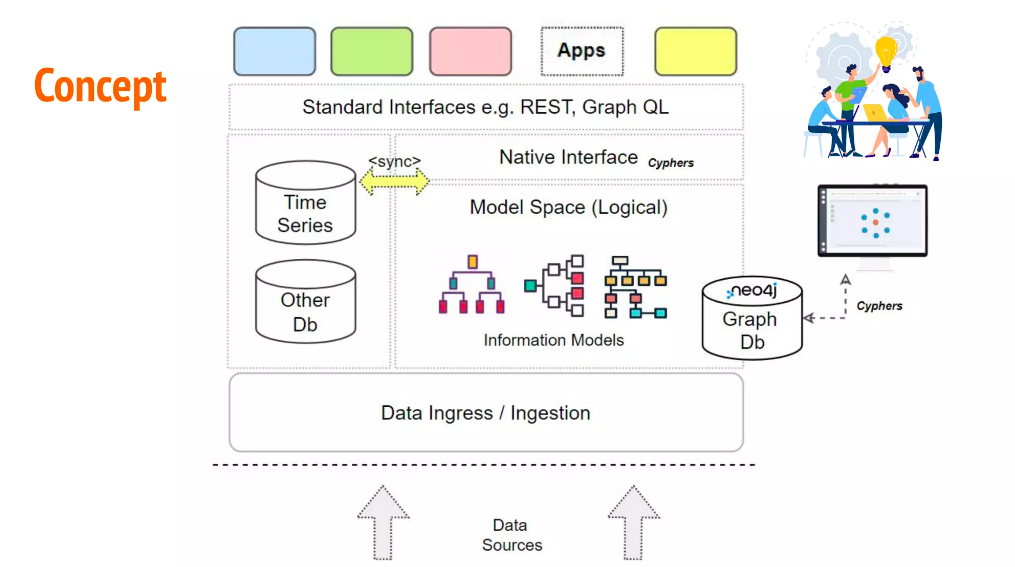
이것은 파트너 중 하나로서 Neo4j를 위해 그린 개념적 아키텍처에 대한 조감도에요. 하단에는 사이트에 있는 사일로 시스템의 데이터 소스가 표시되며 이를 클라우드로 받죠. 관계형 데이터 저장을 위한 시계열 데이터베이스 및 PostScript와 같은 다른 데이터베이스를 이미 가지고 있고요. 그런 다음 이러한 다양한 데이터 소스를 가져와 해당 정보 모델을 그래프와 함께 동기화해요. 그런 다음 그래프와 그래프가 제공하는 모든 컨텍스트를 저장합니다 (그래프에 모든 내용을 담기에는 너무 큰 시계열 데이터베이스는 제외하고요!). 우리는 이 모든 정보를 고객이 사용할 수 있도록 Knowledge Graph 위에 있는 애플리케이션에 공개하고 있어요.
우리는 직원을 위한 로우 코드 및 노 코드 솔루션을 활성화하기 위해 Neo4j와 함께 여정을 계속할 거예요. 이는 모델을 통합하고 애플리케이션 및 운영 엔지니어를 지원하기 위한 환상적인 경로이죠.
- 그래프 데이터 과학
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'Ontology & Knowledge Graph' 카테고리의 다른 글
| 엔터프라이즈 그래프: Dan Woods와의 5분 인터뷰 (1) | 2026.06.21 |
|---|---|
| 지식 그래프로 RAG 애플리케이션 정확도 높이기 (0) | 2026.06.21 |
| Neo4j 지식 그래프로 Microsoft Agent Framework 역량 강화하기 (0) | 2026.06.20 |
| Elsevier, Neo4j로 전 세계 COVID-19 연구에 날개를 달다 (0) | 2026.06.20 |
| DXC Career Navigator: 데이터 기반 직원 커리어 개발 및 몰입도 향상 (1) | 2026.06.20 |