
문제 설명
Neo4j로 구축하는 거의 모든 클라이언트 애플리케이션은 데이터베이스에 어떤 데이터가 있는지 궁금해하죠. 실제 데이터 말고, 데이터의 형태, 즉 스키마요.
아직 스키마를 설명하는 표준적인 방법이 없어서, 각 애플리케이션마다 스키마 형태에 대한 고유한 표현 방식을 가지게 되는 상황이 발생해요.
어떤 도구는 스키마를 메모리에 저장하고, 어떤 도구는 가벼운 저장소(웹 브라우저 로컬 스토리지 같은 곳)에 저장하고, 또 어떤 도구는 Neo4j 자체에 저장하기도 해요. 스키마를 추론하는 방법도 정말 다양하죠. 샘플링을 하는 도구도 있고, 전체 저장소를 검색하는 도구도 있어요.
탐색적인 작업에만 의존하지 않는 대부분의 애플리케이션에는 공통적인 사실이 하나 있어요. 스키마가 없을 수 없다는 거예요. 항상 스키마는 존재하죠.
데이터베이스가 스키마를 제공하거나, 애플리케이션이 GraphQL 스키마나 OGM 같은 객체 매핑, 또는 암묵적인 가정을 통해 스키마를 가정하고 적용하는 거예요. 데이터 모델은 곧 스키마를 의미하니까요.
탐험
이 프로젝트를 시작하면서, Neo4j 내부의 모든 이해 관계자들을 모아서 다음과 같은 목록을 만들어봤어요.
- 기존 데이터 모델을 추론하는 방법
- 어떤 형식으로 저장하는지
- 어떤 문제에 직면했는지
- 무엇을 바꾸고 싶은지
프로젝트 초기에 분명해진 점은, 데이터 모델을 직렬화해서 전송하고 유지할 수 있어야 한다는 거였어요. 이렇게 하면 더 긴밀한 통합이 가능해지고, 더 나은 사용자 경험을 위해 애플리케이션들이 서로 모델 인스턴스를 전달할 수도 있게 되죠 (자세한 내용은 아래에서 설명할게요).
목표
이 프로젝트의 목표는 JSON 기반 데이터 모델의 가능성을 확인하는 거예요. 그래서 데이터베이스를 검사하고 JSON 스키마에 대해 유효성을 검사하는 JSON 응답을 생성하는 플러그인(프로시저)을 만들었어요. 완벽한 추론 알고리즘을 찾거나 만드는 건 이 프로젝트의 목표가 아니었답니다.
참고: 이 글은 이름 짓기가 얼마나 어려운지 보여주는 좋은 예시 같아요. 데이터베이스 스키마(JSON으로 표현됨) 콘텐츠의 구체적인 인스턴스를 검증하는 도구를 허용하는 JSON 스키마가 있거든요. 이 글에서는 후자를 데이터 모델이라고 부르고 있어요.
스키마
스키마는 현재 다음 위치에 게시되어 있어요. 스키마를 직접 작성하거나 검증할 때 $schema 참조로 사용할 수 있어요.
JSON 스키마는 토큰(Node Label 및 Relationship Type)과 Node 및 Relationship 모델 요소(객체 유형)의 구체적인 인스턴스를 분리하는 아이디어를 기반으로 해요. 클래스와 구체적인 객체 인스턴스처럼 생각하면 이해하기 쉬울 거예요.
이 접근 방식은 기본적으로 이미 여러 목적으로 사용되고 있어요. 데이터베이스 인스턴스 내부의 모든 Label과 Type에 대한 읽기 쉬운 카탈로그와 표준화된 조합을 갖는다는 의미죠.
에 포함된 Neo4j의 토큰 세트는 다음과 같아요.
{
"graphSchemaRepresentation": {
"graphSchema": {
"nodeLabels": [
{ "$id": "nl:Person", "token": "Person" },
{ "$id": "nl:Actor", "token": "Actor" },
{ "$id": "nl:Director", "token": "Director" },
{ "$id": "nl:Movie", "token": "Movie" }
],
"relationshipTypes": [
{ "$id": "rt:ACTED_IN", "token": "ACTED_IN" },
{ "$id": "rt:DIRECTED", "token": "DIRECTED" }
],
"nodeObjectTypes": [],
"relationshipObjectTypes": []
}
}
}다음 요약은 이전 토큰을 기반으로 두 개의 구체적인 Node 객체 유형과 하나의 Relationship을 보여줘요 (실제 영화 그래프는 훨씬 크지만, 간결함을 위해 내용을 편집했어요).
{
"graphSchemaRepresentation": {
"graphSchema": {
"nodeLabels": [],
"relationshipTypes": [],
"nodeObjectTypes": [
{
"$id": "n:Person",
"labels": [{ "$ref": "#nl:Person" }],
"properties": [
{
"token": "born",
"type": { "type": "integer" },
"nullable": false
},
{ "token": "name", "type": { "type": "string" }, "nullable": false }
]
},
{
"$id": "n:Movie",
"labels": [{ "$ref": "#nl:Movie" }],
"properties": [
{
"token": "title",
"type": { "type": "string" },
"nullable": false
},
{
"token": "release",
"type": { "type": "date" },
"nullable": false
}
]
}
],
"relationshipObjectTypes": [
{
"$id": "r:ACTED_IN",
"type": { "$ref": "#rt:ACTED_IN" },
"from": { "$ref": "#n:Actor:Person" },
"to": { "$ref": "#n:Movie" },
"properties": [
{
"token": "roles",
"type": { "type": "array", "items": { "type": "string" } },
"nullable": false
}
]
}
]
}
}
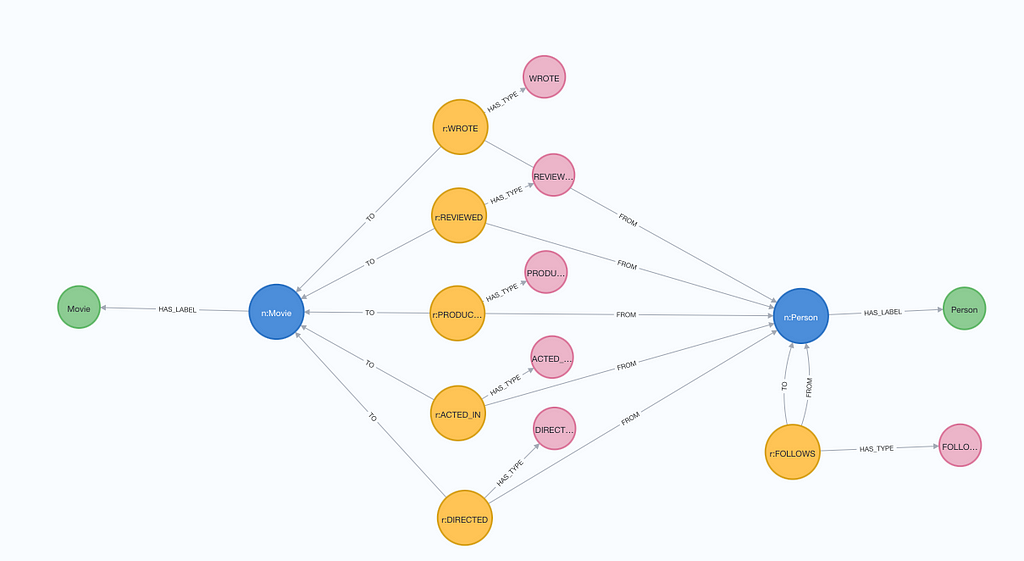
}영화 그래프 데이터 모델에 대한 JSON 스키마 인스턴스의 그래픽 시각화는 다음과 같아요.
알고리즘
개념 증명은 Neo4j가 제공하는 것과 유사한 알고리즘을 사용해요. Neo4j-GraphQL:
- 공식 커널 APIs를 사용하여 사용 중인 label 및 relationship type 검색
- 모든 label 조합에 대한 모든 property를 검색하려면 기존 db.schema.nodeTypeProperties를 사용하세요. 정렬된 label 조합으로 그룹화하여 node object 인스턴스 생성
- 모든 relationship property를 검색하려면 기존 db.schema.relTypeProperties를 사용하고 기존 type의 올바른 시작 및 끝 node를 평가하려면 전체 저장소 검색을 사용하세요. relationship의 type과 대상별로 그룹화하여 relationship 인스턴스를 생성합니다.
이 단계에서는 기본적으로 샘플링을 수행하고 기본적으로 type 및 property당 100개의 구체적인 relationship만 비교합니다(여기서 구체적인 relationship는 (n:LabelA) -[:TYPE]-> (b:Label2)뿐만 아니라 :TYPE 을 의미함)
relationship type과 대상 모두를 그룹화하는 집합 기반 접근 방식은 동일한 type의 relationship가 서로 병합되지 않으므로 현재 db.schema.visualization으로 사용할 수 있는 방식보다 우수해요.
스키마는 참조를 많이 사용하므로 모든 항목에 ID가 있어야 해요. 위의 인쇄된 예에서 ID는 token에서 파생되었으며 쉽게 공유하고 기억할 수 있어요. 그러나 알고리즘은 여러분을 위해 ID를 생성할 수도 있어요. 시간 정렬 고유 식별자(TSID)를 사용하면 되죠. 읽기 쉽고 잘 정렬될 거예요. 스키마의 ID는 식별자라는 것 외에는 다른 의미가 없어요. 값은 token에서 파생돼요.
Cypher 구문에 사용될 때 인용 및/또는 정리가 필요한 모든 token은 기본적으로 인용 및 정리돼요. 따라서 구성표의 모든 내용은 다음을 사용하여 Cypher 구문을 작성하는 것이 안전해요(해당 주제에 관심이 있다면 다음을 살펴보는 것이 좋을 거예요. Cypher-DSL의 스키마 이름 지원).
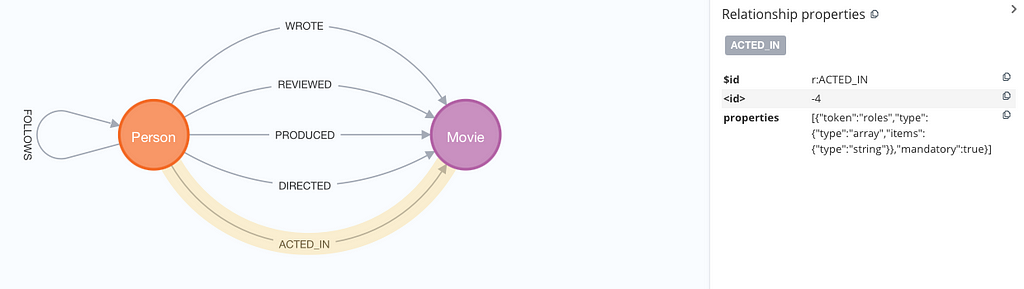
우리의 개념 증명은 다음과 같이 JSON 스키마를 구체화하지 않고도 데이터 모델 자체를 시각화할 수도 있어요.
사용 사례
Neo4j 작업공간
작업 공간의 모든 하위 애플리케이션(가져오기, 쿼리 및 탐색)은 다양한 목적으로 그래프 스키마를 사용해요.
수입
Neo4j 임포터 도구는 사용자가 데이터 모델을 생성하고 모델에 맞게 CSV 파일에서 데이터를 매핑/가져올 수 있는 곳이에요. 이 경우 모델은 사용자가 기존 모델을 다시 방문하고 비교할 수 있도록 스키마 형식으로 저장돼요. 증분 가져오기의 경우 데이터베이스의 기존 스키마를 추론하여 가져오기 모델/매핑을 생성하면 시간이 절약되죠.
질문
쿼리에는 연결된 데이터베이스에 어떤 label, relationship type 및 property key가 있는지 사용자에게 알려주는 사이드바가 있어요. 이를 통해 사용자는 예상 데이터베이스에 연결되어 있고 간단한 마우스 클릭만으로 쿼리를 실행할 수 있다는 확신을 갖게 되죠.
스키마, 이제 더 쉽게 다루자!
Workspace의 탐색 기능은 관점과 장면을 생성하고, 검색 쿼리를 작성할 때 사용자를 돕기 위해 데이터베이스의 스키마를 활용해요. 핵심 그래프 모델 위에 스타일 메타데이터를 추가하고 있답니다.
Cypher 에디터
Cypher 편집기는 미리 로드된 스키마를 기반으로 더 빠르고 스마트한 자동 완성 기능을 제공할 수 있어요. 데이터베이스를 왔다 갔다 할 필요가 없죠! 예를 들어 라벨 및 유형에 대한 자동 완성은 물론, 속성 자동 완성도 지원하고, 필수 속성이 누락된 경우 DML 문 힌트를 작성하는 동안 알려준답니다.
Neo4j GraphQL 검사기
프로젝트에 사용된 알고리즘은 현재 Neo4j GraphQL 검사기에 있는 알고리즘과 거의 동일해요. 그래서 Neo4j GraphQL은 네트워크 지연 시간 없이 핵심 제품 자체에서 유지 관리되는 것으로 원활하게 전환할 수 있고, 사용자가 좋아하는 기능을 그대로 유지하면서 더 빠른 커널 API를 사용할 수 있다는 장점이 있죠.
Neo4j-OGM
Java용 Neo4j-OGM은 그래프-객체-매핑 프레임워크예요. 기본적으로 주석이 달린 Java 클래스를 통해 Neo4j에 대한 스키마를 정의하죠. 이러한 Java 클래스는 대부분 직접 작성되거나, 때로는 모델링 도구를 통해 생성되는데요. 제안된 스키마는 JavaPoet과 같은 Java용 소스 생성기를 조작해서 해당 클래스를 생성하고 책임을 반대 방향으로 전환하는 데 사용될 수 있어요. 자주 생성되는 소스가 항상 고급 사용자의 취향이나 요구 사항에 딱 맞지는 않지만, 기존 데이터베이스의 모양을 재조립하는 클래스 그래프에 그래프를 매핑하고 싶어 하는 대부분의 사용자에게는 큰 도움이 될 거예요.
일반 매퍼 생성
모든 공식 언어 드라이버인 Neo4j-OGM 및 Spring Data Neo4j는 레코드에서 해당 언어의 객체로의 플러그형 매핑 메커니즘을 지원해요. 이러한 매퍼는 레코드의 모양, 혹은 최소한 그러한 레코드의 node 모양이 알려진 경우 가장 간단한 형태로 생성될 수 있죠. 스키마의 도움으로 생성된 코드는 아주 정교한 코드는 아니지만(관계 등을 기반으로 로컬 그래프를 다시 생성하는 일반적인 OGM 접근 방식은 아니라는 뜻이에요), 사용자에게 충분히 도움이 될 거라고 생각해요. 게다가 클래스 클라이언트 슬라이드의 동적인 검사 필드를 기반으로 하는 솔루션보다 훨씬 빠를 수도 있답니다.
개념 증명 절차를 한번 시도해 보세요!
Neo4j 설치 내에서 실행하고 싶다면, 다음 링크에서 조기 액세스 릴리스를 받을 수 있어요. 릴리스 페이지. graph-schema-introspector-1.0.0-SNAPSHOT.jar라는 이름의 jar 파일을 찾아보세요.
Java 개발에 익숙하고 Java 17이 설치되어 있다면, README의 안내에 따라 직접 빌드할 수도 있답니다.
해당 파일을 찾을 수 있는 위치에 다운로드하고, 다음과 같이 Neo4j 설치 폴더에 복사해 주세요.
cp ~/Downloads/graph-schema-introspector-1.0.0-SNAPSHOT.jar
~/Applications/Neo4j/neo4j-enterprise-5.5.0/plugins Neo4j 버전과 에디션, 그리고 경로도 다를 수 있지만, 이 플러그인은 5.x Neo4j 시리즈 범위의 커뮤니티 및 엔터프라이즈 에디션 모두에서 잘 작동할 거예요. 파일을 복사한 후에는 Neo4j를 다시 시작해야 한다는 점, 잊지 마세요!
Docker에서 실험을 진행하는 경우에는 다음 순서를 따라 주세요.
mkdir -p $HOME/neo4j/plugins
cp ~/Downloads/graph-schema-introspector-1.0.0-SNAPSHOT.jar $HOME/neo4j/plugins
docker run
--publish=7474:7474 --publish=7687:7687
--volume=$HOME/neo4j/plugins:/plugins
neo4j:5.5.0Introspector는 다음과 같이 실행할 수 있어요.
스키마를 JSON으로 예쁘게 출력하기
CALL experimental.introspect.asJson({prettyPrint: true})스키마 시각화 (브라우저에서만)
CALL experimental.introspect.asGraph({})기존 시각화와 유사한 스키마 시각화 (브라우저에서만)
CALL experimental.introspect.asGraph({flat:true})해당 절차에는 더 많은 옵션이 있으니, README를 참고해 주세요!
JSON 스키마 작업
유틸리티 라이브러리
JSON은 직렬화된 형식이므로 내부에 핫 참조 경로가 있을 수 없지만(위 예시를 참고해주세요!), 문자열에 의한 참조는 가능해요.
($ref -> $id).
이 때문에 프로그래밍 방식으로 작업하고 유틸리티 라이브러리를 구축하기 시작했는데, 그게 바로 그래프-스키마-json-js-utils (TypeScript로 작성)랍니다.
이 유틸리티 라이브러리를 사용하면 JSON에서 JS 그래프(즉, $ref가 연결된 상태)로, 또 JS 그래프에서 다시 JSON으로 원활하게 이동할 수 있어요.
예제 코드는 README를 참고하거나, npm install @neo4j/graph-schema-utils를 통해 설치해 보세요.
JSON 형식의 그래프 스키마를 검증하기 위해 유틸리티 라이브러리에는 검증 기능도 함께 제공된답니다. 덕분에 사용을 시작하기 전에 입력 내용을 쉽게 신뢰할 수 있죠.
피드백
JSON 스키마와 데이터 모델이 구체화되는 방식, 검사기 알고리즘 및 관련 유틸리티에 대한 여러분의 의견을 기다리고 있어요!
동료 덕분에오스카 하네이 주제와 이야기를 위해 저와 함께 일해 주셔서 감사해요.
- json-스키마
- Property Graph
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'Ontology & Knowledge Graph' 카테고리의 다른 글
| 엔터프라이즈 지식 그래프로 숨겨진 역량 발견하기 (0) | 2026.06.19 |
|---|---|
| Neo4j AuraDB Free 24주차: NYTimes 기사 지식 그래프 파헤치기 (1) | 2026.06.19 |
| 5분 인터뷰: Nulli 창립자 겸 CEO, Derek Small에게 듣는 이야기 (0) | 2026.06.18 |
| 그래프로 풀어보는 ESG 보고의 모든 것 (0) | 2026.06.18 |
| Neo4j로 구축하는 DeFi 지식 그래프 (0) | 2026.06.18 |