
제 인생에서 6개월 정도, 저는 데이터베이스 개발자였어요.
시작하면서 가장 먼저 배운 건 데이터 모델링이었죠. 우리 팀은 관계형 데이터베이스(RDBMS), 특히 MySQL(나중에 Postgres로 전환)을 사용하고 있었어요. 당시 많은 백엔드 개발자들처럼 우리도 의도적으로 RDBMS를 사용하는 건 그냥 기본 설정이었거든요(더 이상은 아니지만요).
당연히 데이터 모델링 수업은 관계형 데이터 모델을 따랐고, 결말은 뻔했죠. 좀짜증났어요.
RDBMS 모델이 항상 나쁘다거나(그렇지 않아요) 항상 엉망이라는(그렇지 않아요) 말은 아니에요. 하지만 모든 프로젝트와 애플리케이션에 대해 단 하나의 데이터 모델로 사용될 때는 문제가 많을 거예요.
좋은 소식은 관계형 모델이 기본 모델일 필요는 없다는 거죠!
다른 데이터 모델도 존재하고 정말 훌륭해요. 오늘은 특히 그래프 데이터 모델에 대해 자세히 살펴보고, 처음보다 훨씬 나은 데이터 모델링 경험을 만들어 드릴게요.
이초보자를 위한 그래프 데이터베이스 블로그 시리즈에서는 그래프 기술에 대한 배경 지식이 거의 없거나 전혀 없다는 가정하에 기본 사항을 안내해 드릴 거예요. 지난 몇 주 동안 우리는 그래프 기술이 미래인 이유와 연결된 데이터가 중요한 이유에 대해 다뤘어요.
이번 주에는 그래프 기술을 사용한 데이터 모델링의 기본 사항에 대해 이야기해 볼 거예요.
(잠깐! 이미 데이터 모델링 전문가라면, 숙련된 기술을 그래프 데이터베이스 모델에 적용하는 방법에 대한 이 기사를 확인해 보세요.)
데이터 모델링이란 정확히 무엇일까요?
데이터는 물과 같아요. 유용한 용기에 담지 않으면 쓸모가 없을 거예요. 용기의 모양, 크기 및 기능은 사용 목적에 따라 다르지만, 일반적으로.
데이터도 마찬가지예요. 새로운 애플리케이션이나 데이터 솔루션을 만들려면 해당 데이터에 대한 구조를 제공해야 해요. 이 구조화 과정을 바로 데이터 모델링이라고 불러요.
주로 고위 데이터베이스 관리자(DBA)나 주요 개발자에게만 국한되는 데이터 모델링은 때때로 일반인에게는 알려지지 않은 난해한 기술로 여겨지기도 해요. 멀리서 전문 데이터 모델러를 숭배하는 경우도 있죠.
물론 데이터 모델링 시나리오는 전문가에게 맡기는 게 좋지만, 기본적으로 어려울 필요는 없어요. 사실 데이터 모델링은적인 측면이 더 중요해요. 코드를 한 줄도 몰라도 괜찮다는 뜻이죠.
누구나 기본적인 데이터 모델링을 할 수 있고, 그래프 데이터베이스 기술 덕분에 데이터를 일관된 모델과 일치시키는 게 훨씬 쉬워졌어요.
데이터 모델링 프로세스에 대한 간략한 개요
데이터 모델링은 추상화 과정이에요. 비즈니스 및 사용자 요구 사항(예: 애플리케이션에서 수행하려는 작업)부터 시작하죠. 그런 다음 모델링 프로세스에서 이러한 요구 사항을 데이터를 저장하고 구성하기 위한 구조로 매핑해요. 간단하게 들리죠?
기존 데이터베이스 관리 시스템에서는 모델링이 그렇게 간단하지 않아요.
초기 아이디어를 화이트보드에 적은 후, 관계형 데이터베이스에서는 논리적 모델을 만든 다음 해당 구조를 테이블 형식의 물리적 모델로 억지로 변환해야 해요. 데이터베이스 작업을 시작할 때쯤이면 원래 화이트보드 스케치와는 완전히 달라 보일 거예요(사용자 요구 사항을 충족하는지 확인하기 어려울 수도 있죠).
반면에, 그래프 기술을 위한 데이터 모델링은 이보다 더 간단할 수 없어요. 화이트보드 구조가 어떻게 생겼을지 상상해 보세요. 아마도 화살표와 선으로 연결된 원과 상자의 집합일 거예요.
핵심은 이거예요. 여러분이 그린 그 모델은 그래프예요. 여기서 그래프 데이터베이스를 만들려면 코드 몇 줄만 실행하면 돼요.
관계형 데이터 모델링과 그래프 데이터 모델링: 매치업
예를 들어 살펴볼까요?
이에 데이터 센터 관리 도메인(아래 그림)을 보면, 여러 데이터 센터는 가상 머신 및 로드 밸런서와 같은 infrastructure를 사용해서 여러 application을 지원하고 있어요.
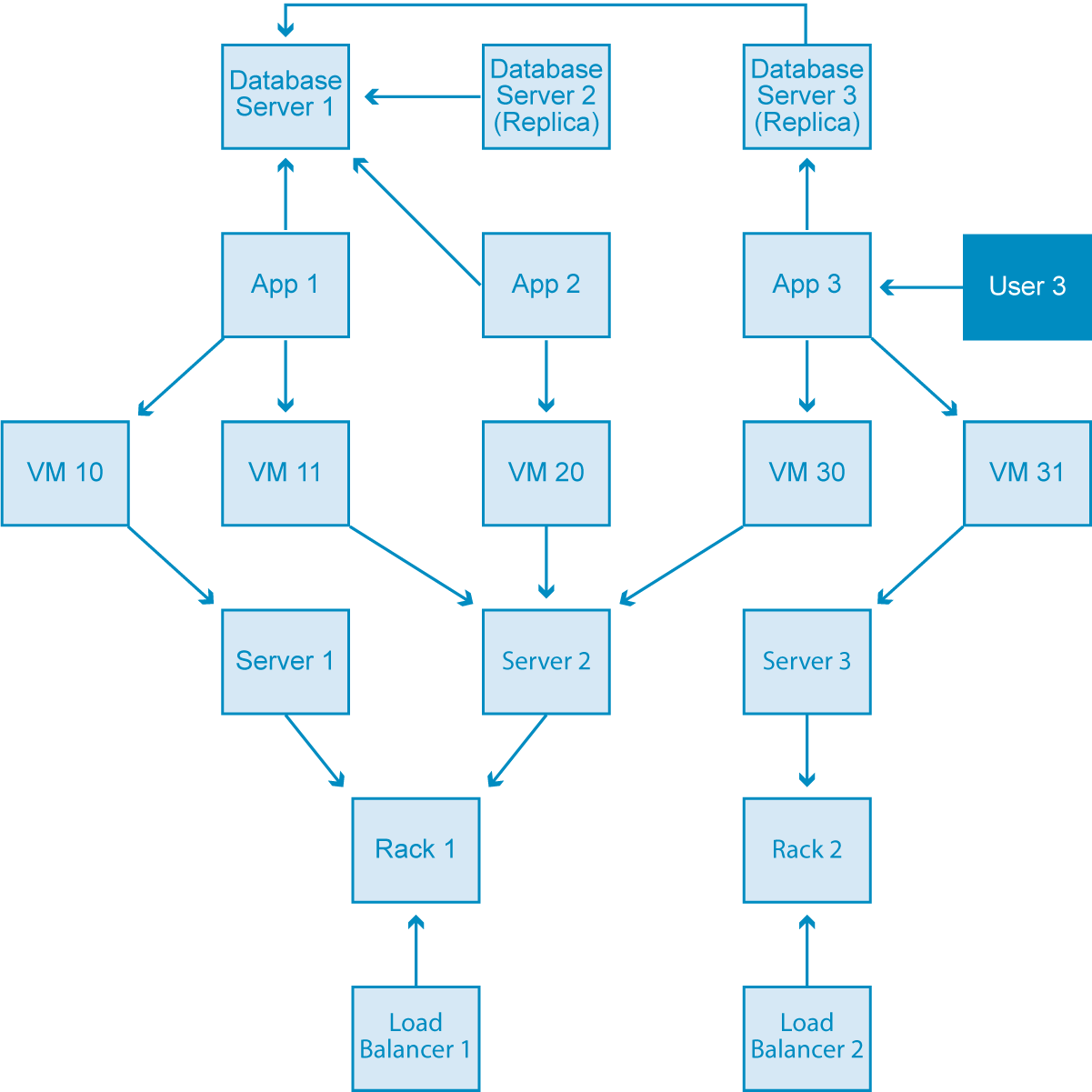
우리는 이 데이터 센터 infrastructure를 관리하고 통신하는 application을 만들고 싶으니까, 모든 관련 요소를 포함하는 데이터 모델을 만들어야 해요.
이제 우리의 대결을 위해!
관계형 데이터 모델
관계형 데이터베이스로 작업하는 경우, 비즈니스 리더, 해당 분야 전문가 및 시스템 설계자가 모여서 이 도메인의 entity, 상호 연관 방식 및 도메인에 적용되는 모든 규칙을 보여주는 위 이미지와 유사한 데이터 모델을 만들 거예요. 가능한 모든 예외나 규칙 위반(즉, 모델 위반) instance에 대해 계획을 세우려면 많은 가정과 생각이 필요하죠.
긴 회의가 될 거예요.
거기에서 선임 DBA는 이 초기 화이트보드 스케치에서 논리적 모델을 생성한 후 아래에서 볼 수 있는 table과 관계에 매핑해요.

위 다이어그램에서는 관계형 모델에 적합하도록 시스템에 많은 복잡성을 추가해야 했어요. 첫째, 주석 FK(기술 용어: 외래 키)를 볼 수 있는 모든 곳에서 복잡성이 추가되는 또 다른 지점이죠. 그리고 만약 여러분이 노련한 시스템 관리자라면, "복잡성"이라는 말을 들었을 때 무엇을 생각해야 하는지 알려드릴게요. 문제가 더 자주 발생할 거라는 거죠!
무엇보다도 다음과 같은 새로운 테이블이 다이어그램에 추가되었어요. AppDatabase and UserApp. 이러한 새 테이블을 JOIN 테이블이라고 해요. (“JOIN”은 업계 관례에 따라 모두 대문자로 작성되지만 JOIN 테이블이 여러분에게 소리를 지르는 것으로 생각하는 것도 훌륭한 시각적 보조 도구예요. 작업하기 어렵기 때문에 소리를 지르는 거죠.)
나쁜 소식을 전하는 사람이 되는 건 싫지만 JOIN 테이블은 쿼리 속도를 크게 저하시킨답니다. (그리고 업무상 중요한 엔터프라이즈 애플리케이션을 통해 연중무휴로 얼마나 많은 쿼리가 실행될지 상상해 보세요. 네, lots!). 불행하게도 관계형 데이터 모델에서는 필요악이기도 해요.
Graph Data Model
이제 Graph Data Model링 접근 방식을 사용하여 동일한 애플리케이션을 구축하는 방법을 살펴볼까요? 처음에는 우리의 작업이 동일해요. 의사 결정권자들이 모여 데이터 모델의 기본 화이트보드 스케치를 작성했죠(참조용으로 아래 그림 참조). 하지만 이 회의에는 중요한 차이점이 있어요. 그들은 일찍 나가서 (누구나 그렇듯이) 몇 시간 동안 추가로 제트 스키 곡예를 즐긴다는 거예요.
왜 그럴까요? Graph Data Model을 사용하면 데이터베이스에 영향을 미칠 수 있는 모든 확장, 예외 또는 화재 위험에 대해 계획할 필요가 없었기 때문이에요. 오늘 회의는 시작일 뿐이고, 나중에 무슨 일이 생기면 모델은 적응 가능하다. 걱정할 필요가 없죠!
제트 스키를 신나게 타고 돌아온 데이터 모델러는 프로세스의 다음 단계로 돌아갑니다. 초기 화이트보드 작업 후에는 모든 것이 새롭게 보일 거예요. 이제 초기 화이트보드 모델을 테이블과 JOIN으로 *변경*하는 대신, 비즈니스 및 사용자 요구에 따라 화이트보드 모델을 *확장*할 수 있게 되었죠.
맞아요. 데이터 모델은 *더 나은* 모델이지, *더 나쁜* 모델이 아니에요.
확장 후, 레이블, 속성, 그리고 관계를 추가한 새로운 데이터 모델은 다음과 같아요.

보시다시피, 강화된 데이터 모델은 초기 화이트보드 스케치와 크게 다르지 않죠? 오히려 훨씬 더 도움이 될 거예요. 실제로 이 데이터 모델은 이제 Graph Database(예: !) 덕분에 화이트보드에 스케치한 내용이 그대로 데이터베이스에 저장된다는 점이 핵심이에요.
결론은 이거예요. 완성된 데이터 모델과 여러분 사이에는 EXPO 마커와 빈 화이트보드밖에 없다는 거죠.
데이터 모델링이 일회성 활동이 아닌 이유 (어떤 데이터베이스를 사용하든)
관계형 데이터베이스와 Graph Database 간의 데이터 모델링의 주요 차이점을 간과하기 쉬운데요. 결국 데이터 모델링은 애플리케이션 개발 초기에 딱 한 번만 완료하면 되는 활동이라고 생각할 수 있어요. 그렇지 않죠!
다시 이야기 시간으로 돌아가 볼게요. RDBMS 데이터 모델링은 인문학 전공자에게는 꽤나 힘든 일이었는데, 그 이후로는 상황이 훨씬 더 복잡해졌어요.
아직 화이트보드에 그림을 그리고 브레인스토밍하는 단계에서는 데이터 모델을 쉽게 변경할 수 있었어요. 물론 어떤 관계가 일대일이어야 하고 어떤 관계가 일대다여야 하는지 파악하는 게 항상 쉬운 건 아니었지만, 이런 변경 사항을 적용하는 건 정말 간단했죠. 하지만 화이트보드 단계를 벗어나면 상황이 달라져요.
화이트보드 모델을 Postgres에 연결하고 나면 변경이 훨씬 더 어려워졌어요. Schema 마이그레이션은 누구도 좋아하지 않는 데이터베이스 작업이니까요 (아마 댓글 섹션에 "그 사람"이 있을지도 모르겠지만요!). 그리고 데이터베이스가 실제로 운영되기 시작하면, 변경 제안에 대한 제 대답은 보통 "그냥 잊어버려요" 였어요.
물론, 윗분들도 그걸 잊지 않으셨죠. 사용자 요구 사항이 계속 바뀌니까 변화는 여전히 필요했어요. 그리고 비즈니스 요구 사항도 끊임없이 바뀌었죠. 왜냐하면 삶의 진리: 변화는 항상 일어나기 때문이에요.
왜 데이터 모델에 변화가 없을 거라고 생각하는 사람이 있을까요? 피할 수 없는 상황에 대비하기보다는 변화를 당연한 것으로 받아들이고, 변화에 대비하는 데이터 모델을 사용하는 게 훨씬 낫지 않을까요?
결론: 믿을 수 있는 변화
시스템은 변화하고, 특히 요즘 개발 환경에서는 변화가 정말 잦아요. 심지어 애플리케이션이나 솔루션은 개발 중에도 크게 바뀔 수 있죠. 애플리케이션의 수명 동안 데이터 모델은 변화하는 비즈니스 및 사용자 요구 사항을 충족하기 위해 끊임없이 진화하고 발전해요.
엄격한 Schema와 복잡한 모델링 프로세스를 가진 관계형 데이터베이스는 급격한 변화에 적합하지 않아요. 필요한 건 성능 저하 없이 데이터 무결성을 유지하면서 지속적인 발전을 지원하는 데이터 모델이죠.
이제 데이터 모델링의 기본을 알았으니, 선택은 분명해졌을 거라고 생각해요.
잘 이해되고 변경이 최소화된 데이터 모델을 사용해서 애플리케이션을 만들 때는 검증된 관계형 데이터베이스를 사용하는 게 좋아요. 이미 효과가 있는 것을 고수하는 거죠!
하지만 여러분의 길이 다른 곳으로 향하고 있을 수도 있잖아요? 어쩌면 새로운 것을 창조하고 있을 수도 있고요. 미지의 영역을 개척하고 있을 수도 있죠. 사용자가 어떤 질문을 할지조차 모르기 때문에, 모든 정답을 갖춘 데이터베이스를 미리 계획할 수 없을 수도 있어요.
이것이 여러분의 다음 프로젝트를 설명해 준다면, 민첩한 데이터 모델이 필요할 거예요. 개발과 함께 발전하는(무너지거나 뒤처지지 않는) 데이터 모델이 필요하죠. 바로 그래프 데이터 모델이 필요하답니다.
미래는 불확실하니까요(믿으세요!). 이런 현실에 맞는 데이터 모델을 선택하세요.
Knowledge Graph 구축을 고려 중이신가요?
개발자 가이드: Knowledge Graph 구축 방법을 다운로드하여 자신 있게 구축을 시작하기 위해 알아야 할 모든 것을 단계별로 알아보세요.
초보자를 위한 그래프 데이터베이스 시리즈의 나머지 부분도 한번 살펴볼까요?
- 그래프 기술이 미래인 이유
- 피해야 할 데이터 모델링 함정
- 데이터베이스 쿼리 언어가 중요한 이유
- 명령형 쿼리 언어와 선언형 쿼리 언어: 차이점은 무엇인가요?
- 그래프 이론 및 예측 모델링
- NoSQL 데이터베이스가 필요한 이유
- ACID 대 BASE 설명
- 네이티브 및 비네이티브 그래프 기술
- 데이터 모델링
- 그래프 데이터 모델
- Graph 기술
- MySQL
- Postgres
- RDBMS
- 관계형 데이터 모델
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'Ontology & Knowledge Graph' 카테고리의 다른 글
| Neo4j로 구축하는 DeFi 지식 그래프 (0) | 2026.06.18 |
|---|---|
| 제품 DNA 해독: AI & Knowledge Graph로 PDM을 한 단계 업그레이드하다 (1) | 2026.06.17 |
| 데이터 파이프라인 심층 분석: Knowledge Graph를 활용한 데이터 리니지 추적 (0) | 2026.06.17 |
| 5분 인터뷰: 파이낸셜 타임즈의 시니어 메타데이터 DevOps, Dan Murphy를 만나다 (0) | 2026.06.16 |
| Tom Sawyer Perspectives로 범죄 네트워크 분석하기 (0) | 2026.06.16 |