
GraphRAG는 성능을 향상시키는 강력한 검색 메커니즘이에요. GenAI 애플리케이션을 만들 때, 그래프 데이터 구조의 풍부한 컨텍스트를 활용할 수 있게 해주죠.
엔터프라이즈 GenAI 시스템은 신뢰할 수 있고 믿을 수 있는 결과를 내야 한다는 중요한 과제에 직면해 있어요. 순수한 LLM(Large Language Model) 기반 솔루션은 이 점에서 부족한 경우가 많죠. 왜냐하면, LLM은 사실성보다는 유용성을 우선시하도록 훈련되었고, 사전 훈련 데이터에는 중요한 최신 정보가 부족한 경우가 많거든요. 결과적으로 사실과 다른 설명을 만들어내는 경향이 있는데, 이는 특히 중요한 비즈니스 영역 및 사용 사례에 해로울 수 있어요.
이러한 문제를 해결하기 위해, Retrieval-Augmented Generation(RAG) 아키텍처가 솔루션으로 떠올랐어요. RAG는 LLM 답변이 기존 지식 소스의 정확한 정보만을 기반으로 하도록 보장해서 GenAI 구성 요소의 신뢰성을 높여준답니다.
기본적인 RAG 시스템은 격리된 텍스트 조각들을 검색하고 순위를 매기기 위해 Vector Database의 Semantic Search에만 의존해요. 이 접근 방식은 일부 관련 정보를 찾을 수는 있지만, 이러한 조각들을 연결하는 컨텍스트를 포착하는 데는 실패하죠. 그래서 기본적인 RAG 시스템은 복잡한 다중 홉 질문에 답하기에는 적합하지 않아요.
바로 이럴 때 GraphRAG가 등장하는 거죠! Knowledge Graph는 더 많은 데이터 포인트뿐만 아니라 그 관계도 포착하기 위해 정보를 표현하고 연결하거든요. 따라서 그래프 기반 검색기는 종종 명확하지 않지만 정보 상관 관계에 중요한 숨겨진 연결을 찾아내서, 더 정확하고 관련성이 높은 결과를 제공할 수 있어요.
이번 블로그 포스팅에서는 GraphRAG가 어떻게 작동하는지 자세히 알아보고, 다른 RAG 아키텍처와 비교했을 때 답변 품질과 설명 가능성을 향상시키는 장점을 살펴볼 거예요. 그리고 Neo4j 예제를 사용해서 실제 적용 사례를 보여드릴게요.
Retrieval-Augmented Generation(RAG) 소개
GraphRAG의 자세한 내용을 살펴보기 전에, RAG의 기본 개념을 이해하는 것이 중요해요. RAG의 세 가지 주요 단계를 자세히 살펴볼까요?
검색(Retrieval): 이 단계에서 RAG 시스템은 사용자의 Query를 기반으로 문서나 Database와 같은 외부 데이터 소스에서 관련 정보를 검색해요. 검색 프로세스에서는 유사성 검색이나 Database Query 등 가장 관련성이 높은 데이터를 식별하기 위해 다양한 기술을 사용할 수 있죠. 그런 다음 검색어와의 관련성을 기준으로 결과의 순위를 매기고 점수를 매긴답니다.
증강(Augmentation): 증강 단계에서는 검색된 정보가 추가 지침이나 컨텍스트와 함께 원래 사용자 질문과 결합돼요. 이렇게 증강된 Prompt는 Language Model이 응답을 생성하는 데 더 풍부한 컨텍스트를 제공하죠. 목표는 정확하고 유용한 출력을 생성하기 위해 모델이 관련 정보만 사용하도록 하는 거예요.
생성(Generation): 마지막 단계에서는 증강된 Prompt가 사전 훈련된 지식에 의존하지 않고 제공된 컨텍스트만을 사용하여 요청된 형식으로 답변을 생성하는 LLM에 의해 처리돼요. 응답은 소스 정보와 추가 메타데이터를 연결할 수도 있답니다.
외부 지식으로 Language Model을 강화하고 모델의 Natural Language Understanding 기능을 사용하여 이 정보를 검색하고 처리함으로써, RAG 시스템은 사전 훈련된 지식에만 의존하는 독립 실행형 Language Model에 비해 더 정확하고 유익한 응답을 생성할 수 있어요.
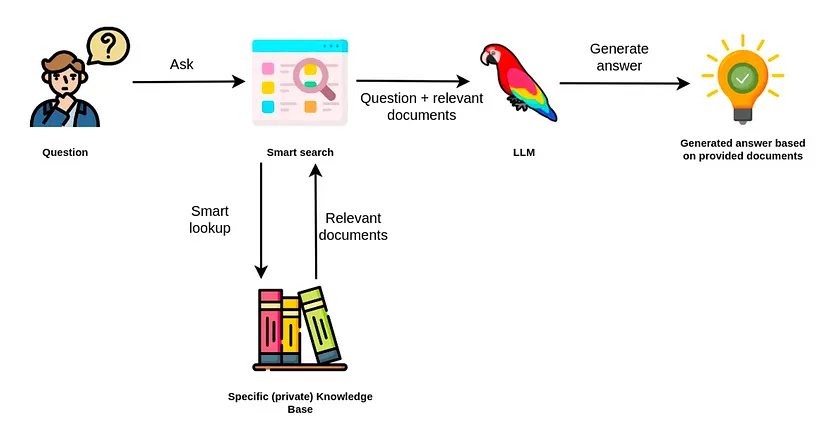
Vector 전용 RAG의 한계
많은 기본적인 RAG 시스템은 Vector Search를 사용해서 정보 검색을 해요. 이때 텍스트의 의미를 숫자 벡터로 표현하는 Vector Embedding을 활용하죠. 소스 문서는 텍스트 조각의 의미를 정확하게 담기 위해 더 작은 단위로 쪼개진 다음, 검색, 인덱싱, 저장을 거치게 돼요.
하지만 이 방법에는 한계가 있어요. Vector Search에만 의존하면 답변 내용이 검색된 텍스트 조각에 갇히게 되거든요. 그래서 답변이 불완전하거나 단편적으로 보일 수 있죠.
예를 들어, 사용자가 특정 제품 기능에 대해 질문했을 때, 벡터 전용 RAG 시스템은 그 제품을 언급하는 텍스트 조각만 찾아낼 수 있어요. 더 포괄적인 답변을 줄 수 있는 다른 관련 정보는 놓칠 수 있다는 거죠.
게다가 Vector Embedding과 Vector Search는 블랙박스처럼 작동해서 정보를 어디서 가져왔는지 설명하기 어려워요. 사용자와 개발자는 특정 텍스트 조각이 왜 검색되었고, 생성된 답변에 어떻게 기여했는지 알기 힘들다는 뜻이죠. 투명성과 책임이 중요한 의료나 금융 분야에서는 이런 설명력 부족이 큰 단점이 될 수 있어요.
이런 단점을 극복하기 위해 RAG 프로세스(검색, 확대, 생성)의 여러 단계를 개선하는 새로운 기술들이 등장하고 있어요.
LLM에 제공되는 정보는 답변의 품질에 엄청난 영향을 주기 때문에, 검색 메커니즘을 개선하는 게 가장 중요할 때가 많아요. GraphRAG는 Knowledge Graph에 저장된 구조화된 도메인 지식을 활용해서 검색 성능을 끌어올리는 방법이에요. Knowledge Graph의 풍부한 연결과 의미론적 관계를 이용해서 Vector Search 기반 RAG의 한계를 극복하고, 더 정확하고 설명 가능한 답변을 제공하는 게 목표죠.
데이터 표현을 위한 Knowledge Graph
Knowledge Graph는 연결된 요소로 데이터를 구조화해서 표현하는 데 아주 효과적이에요. 기존 데이터베이스처럼 엄격한 스키마를 강요하지 않아서 데이터 모델이 훨씬 유연하죠. 그래프 모델을 사용하면 풍부한 실제 정보를 효율적으로 저장, 관리, 쿼리하고 처리할 수 있어요. RAG 시스템에서 Knowledge Graph는 요약, 번역, 추출 같은 LLM의 언어 능력을 유연하게 보완해주는 메모리 역할을 해요.

Knowledge Graph에서는 사실과 개체가 다음과 같이 표현돼요. Nodes는 속성을 가지고, 연결된 Relationships 또한 자격에 대한 속성을 가질 수 있죠. 이 그래프 모델은 단순한 가계도에서부터 수백만, 수십억 개의 연결을 통해 직원, 고객, 프로세스, 제품, 파트너십, 리소스를 포괄하는 회사의 완전한 디지털 트윈까지 확장될 수 있어요.
그래프 구조는 구조화된 비즈니스 도메인, (계층적) 문서 표현, 그래프 알고리즘으로 계산된 신호 등 다양한 소스에서 시작될 수 있답니다.
AI를 위한 Knowledge Graph에 대한 무료 Gartner® 보고서를 읽어보세요.
GraphRAG 검색기를 위한 Graph Querying
다음과 같은 간단한 패턴을 따라 그래프를 탐색할 수 있어요. (node:Type)-[relationship:TYPE]->(node:Type) 또는 Cypher나 GQL 같은 Graph Query Language로 표현된 더 복잡한 형태로도 가능하죠. 패턴 매칭을 사용하면 SQL과 같은 다른 Query Language에서처럼 Node, Relationship, Attribute를 필터링, 집계 및 정렬할 수 있는 경로가 생성돼요. 다음은 Vector Embedding 검색에서 이웃 정보를 반환하는 Graph Query의 예시입니다.
CALL db.index.vector.queryNodes(docs, 5, $embedding) yield node as doc, score
RETURN score, doc, COLLECT {
MATCH path = (doc)-[rel]-(neighbor)
RETURN path
} as paths
ORDER BY score DESC LIMIT 10GraphRAG가 검색을 향상시키는 방법
GraphRAG 검색을 통해 다음을 찾을 수 있어요. 은 Vector, 전체 텍스트, 공간 또는 기타 검색을 통해 찾고, 이 데이터 네트워크에서 관련 Relationship을 따라 사용자 Query를 만족시키기 위해 추가 정보를 수집하는 거죠. 관련성을 높이기 위해 사용자와 작업의 컨텍스트가 고려돼요. 캡처된 모든 Node, Relationship 및 해당 Attribute는 증강 단계에서 컨텍스트로 반환되기 전에 필터링되고 순위가 매겨질 수 있답니다.

이 접근 방식은 Vector 전용 RAG 시스템에 비해 다음과 같은 몇 가지 장점을 제공해요.
- 그래프 구조를 탐색하고 관련된 relationships을 따라가면서, GraphRAG는 검색된 chunk의 초기 세트에서 직접 언급되지 않은 정보까지 검색할 수 있어서 더 포괄적이고 맥락에 맞는 답변을 제공할 수 있어요.
- 사용자의 상황과 작업에 맞춰 검색된 정보를 필터링하고 순위를 매기는 기능 덕분에, GraphRAG는 가장 관련성이 높은 정보의 우선순위를 정해서 답변의 퀄리티를 높일 수 있죠.
- GraphRAG는 검색된 정보 간의 relationships을 캡처해서 더 나은 설명 가능성을 제공하고, 답변 뒤에 숨겨진 출처와 추론을 더 쉽게 추적할 수 있도록 도와줘요.
- GraphRAG는 계산된 신호뿐만 아니라 구조화된 데이터와 구조화되지 않은 데이터를 통합하는 Knowledge Graph의 기능을 사용해서, 더 넓은 범위의 정보 소스에서 얻어지는 더 많은 정보와 미묘한 답변을 제공할 수 있어요.
검색 단계가 이렇게 개선되면서 GraphRAG는 벡터 전용 RAG 시스템보다 더 정확하고 관련성 높으며 추적 가능한 답변을 만들어낼 수 있는 거죠.
GraphRAG Retriever 유형
실제 그래프 검색은 사용 사례와 도메인에 따라 달라져요. 다양한 유형의 retriever를 결합할 수 있고, 결과의 순위를 매기거나 결합하거나 순서를 지정할 수도 있죠. 에이전트 설정에서 retriever는 LLM이 선택하고 반복적으로 실행해서 질문에 답하는 데 필요한 정보가 수집될 때까지 parameter와 결과를 전달하는 도구가 될 수 있어요.
GraphRAG retriever 유형의 예시를 몇 가지 살펴볼까요?
- 벡터(embedding), 전체 텍스트, 공간 또는 기타 검색 index: 사용자 질문의 정보와 함께 index 검색을 사용해서 추가 탐색을 위한 그래프의 시작점을 결정해요.
- : 정보를 context에 추가하기 위해 Node의 직접 또는 간접적인 이웃에 접근해요.
- : 시작 entity 사이의 경로를 찾고, 이웃과의 relationships을 확장하고, 추가 관련 문서, claim 및 기타 entity를 검색해요.
- 글로벌 Query: 사전 계산된 주제 간 요약 및 통찰력에 대한 기타 글로벌 표현을 사용해서 일반적인 질문에 답변해요 (Query 중심 요약이 포함된 Microsoft의 GraphRAG를 참고하세요).
- : 질문 category에 대한 사용 사례별 Query는 도메인 전문가가 제공하며, 동일한 시작점을 가질 수 있지만 다른 하위 그래프를 탐색할 수 있고, 질문을 분류해서 선택할 수 있어요.
- (Text2Cypher): (Fine-tuning된) LLM은 사용자 질문과 그래프 Schema 설명에서 Cypher Query를 생성해서 구체적이고 구조적인 질문에 답해요.
- : LLM은 다양한 retriever를 사용해서 계획된 순서에 따라 이를 선택하고 실행해서 질문에 답하기 위한 모든 정보를 수집해요.
- : embedding을 사용해서 Node 주변의 "본질"을 표현하고 후보 embedding을 일치시켜 퍼지 토폴로지 검색을 허용해요.
GraphRAG 패턴 카탈로그에서 더 많은 예제를 찾아볼 수 있어요. graphrag.com.
Knowledge Graph 구축
GraphRAG가 제대로 작동하려면 데이터가 관련성이 높고 연결된 정보 조각을 정확하게 나타내는 모양을 가지고 있는지 확인해야 해요. 이 Knowledge Graph를 만들려면 두 단계를 수행해야 하고, 이를 반복해서 개선할 수 있죠.
- 도메인 데이터를 나타내기 위해 관련 Node와 Relationship을 모델링해요.
- 이 그래프 모델에 맞게 그래프 구조를 가져오거나 생성하거나 계산해요.

다양한 데이터 소스를 통합할 수 있다는 점이 매력적이죠.
- 데이터베이스, 파일 또는 API에서 기존의 구조화된 데이터를 가져올 수 있어요.
- 구조화되지 않은 데이터(텍스트, 오디오, 비디오)를 문서 구조/계층의 그래프 표현으로 변환하고, 청크에 대한 Vector Embedding 및 전체 텍스트 Index를 추가할 수 있어요.
- 텍스트 정보로부터 구조화된 엔터티(선택적 임베딩 포함)와 해당 Relationships를 구성하거나 연결할 수 있어요.
- 주제 클러스터링 요약(예: Microsoft Query Focused Summarization), 유사성 Relationship 및 개인화된 페이지 순위(PPR) 점수와 같은 추가 계산 또는 알고리즘을 사용하여 기존 그래프를 더욱 풍성하게 만들 수 있어요.
이러한 그래프 모델과 소스는 GraphRAG 패턴 카탈로그에도 자세히 설명되어 있답니다.
Neo4j를 사용한 GraphRAG 예시
GraphRAG의 흔한 사용 사례는 단순히 "PDF로 채팅"하는 것보다 훨씬 더 깊이 있는 정보 분석이에요. Vector 기반의 Semantic Search 방식에서는 검색기에서 반환된 데이터가 도메인이나 서로의 개념과 어떻게 연결되는지에 대한 정보가 거의 없는 텍스트 덩어리일 뿐이죠.
하지만 GraphRAG 방식을 사용하면 문서에 나타나는 사람, 조직, 기사, 논문, 생물학적 프로세스, 상태, 질병, 약물, 유전자, 표현, 노출 및 경로와 같은 엔터티를 추출해서 풍부한 정보 네트워크를 구축할 수 있어요.
이걸 보여드리기 위해 오픈 소스를 사용해서 Knowledge Graph를 구성하는 예시를 한번 살펴볼까요? neo4j-graphrag 패키지를 사용하면 된답니다. LangChain, LlamaIndex 등과의 도 지원하고 있어요.
이 예시에서는 여러 기본 설정을 제공하고 아래 설명된 단계를 실행하는 SimpleKGPipeline을 사용할 거예요.
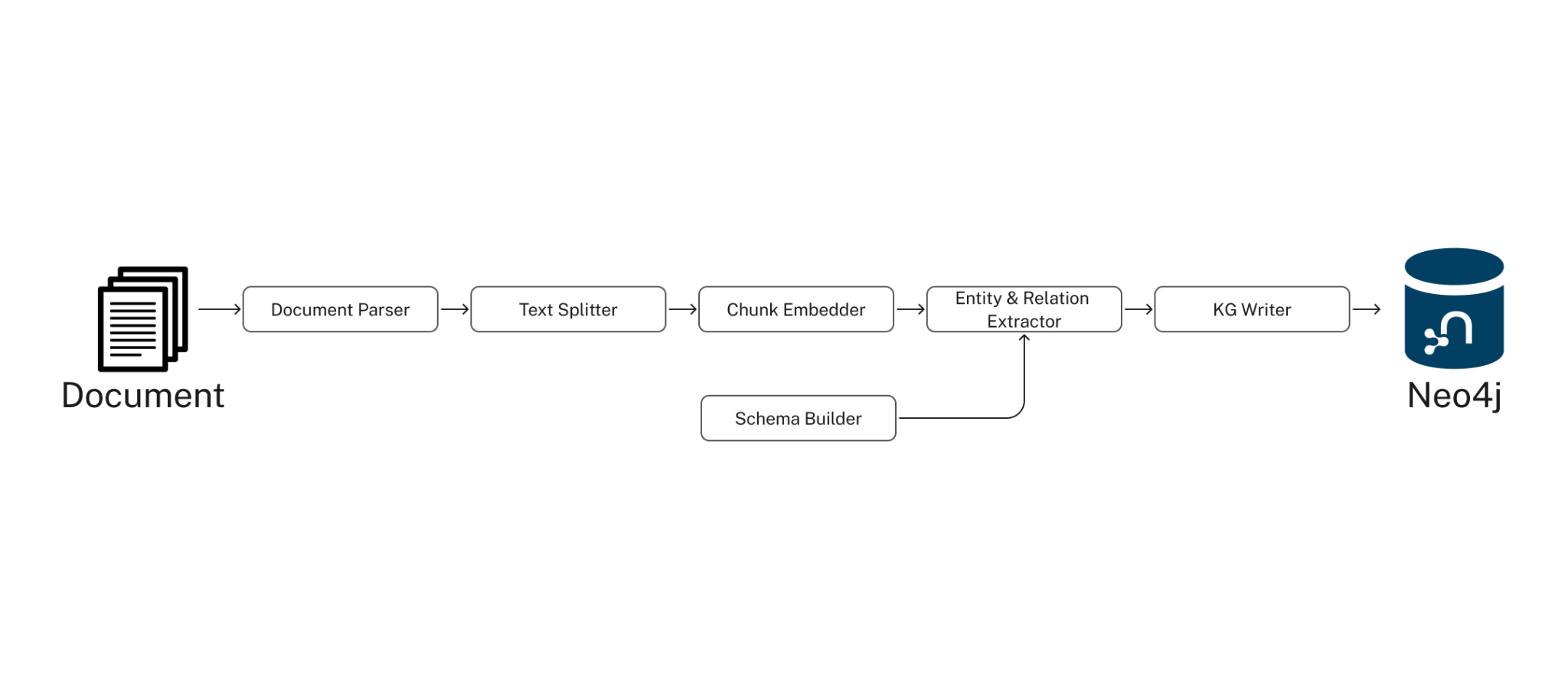
이 추출을 실행하기 위해 다음 구성 요소로 파이프라인을 구성할 거예요.
- LLM(예: OpenAI의 gpt-4o-mini)
- Embedding 모델
- Graph 스키마
구성이 완료되면 생물의학 연구 논문 데이터 세트에서 파이프라인을 실행할 수 있어요.
driver = neo4j.GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USERNAME, NEO4J_PASSWORD))
ex_llm=OpenAILLM(
model_name="gpt-4o-mini",
model_params={
"response_format": {"type": "json_object"},
"temperature": 0
}
)
embedder = OpenAIEmbeddings()
node_labels = ["Anatomy", "BiologicalProcess", ...]
rel_types = ["ACTIVATES", "AFFECTS", "ASSESSES",..."TREATS", "USED_FOR"]
kg_builder_pdf = SimpleKGPipeline(
llm=ex_llm,
driver=driver,
text_splitter=FixedSizeSplitter(chunk_size=500, chunk_overlap=100),
embedder=embedder,
entities=node_labels,
relations=rel_types,
prompt_template=prompt_template,
from_pdf=True
)
pdf_file_paths = ['biomolecules-11-00928-v2.pdf', 'GAP-between-patients-and-clinicians_2023_Best-Practice.pdf','pgpm-13-39.pdf']
for path in pdf_file_paths:
graph_data = await kg_builder_pdf.run_async(file_path=path)청크된 문서 데이터와 그래프 데이터를 Neo4j에 저장한 후 쿼리 도구를 사용하여 시각화할 수 있죠.

이제 GraphRAG 검색기를 실행하고 그 결과를 Vector RAG 검색기와 비교해 볼 수 있어요.
이 검색기는 먼저 인덱싱된 텍스트 청크에 대한 벡터 검색을 실행한 다음 최대 2홉 아웃까지 청크가 아닌 관계를 따라가면서 직접 추출된 엔터티뿐만 아니라 해당 엔터티의 1차 및 2차 이웃도 검색해요. 프롬프트 확대 및 답변 생성의 최종 단계에서 사용할 컨텍스트로 청크 텍스트와 엔터티-관계-엔티티 쌍을 반환하는 거죠.
from neo4j_graphrag.retrievers import VectorCypherRetriever
graph_retriever = VectorCypherRetriever(
driver,
index_name="text_embeddings",
embedder=embedder,
retrieval_query="""
//1) Go out 2-3 hops in the entity graph and get relationships
WITH node AS chunk
MATCH (chunk)<-[:FROM_CHUNK]-(entity)-[relList:!FROM_CHUNK]-{1,2}(nb)
UNWIND relList AS rel
//2) collect relationships and text chunks
WITH collect(DISTINCT chunk) AS chunks, collect(DISTINCT rel) AS rels
//3) format and return context
RETURN apoc.text.join([c in chunks | c.text], '\n') +
apoc.text.join([r in rels |
startNode(r).name+' - '+type(r)+' '+r.details+' -> '+endNode(r).name],
'\n') AS info
"""
)다음으로, 적절한 LLM(여기서는 더 나은 OpenAI gpt-4o 사용)과 함께 각 검색기를 사용하여 벡터 및 GraphRAG 파이프라인을 구축하고 질문 답변을 요청할 거예요.
llm = LLM(model_name="gpt-4o", model_params={"temperature": 0.0})
rag_template = RagTemplate(template='''Answer the Question using the following Context. Only respond with information mentioned in the Context. Do not inject any speculative information not mentioned.
# Question:
{query_text}
# Context:
{context}
# Answer:
''', expected_inputs=['query_text', 'context'])
vector_rag = GraphRAG(llm=llm, retriever=vector_retriever, prompt_template=rag_template)
graph_rag = GraphRAG(llm=llm, retriever=graph_retriever, prompt_template=rag_template)
q = "Can you summarize systemic lupus erythematosus (SLE)? including common effects, biomarkers, and treatments? Provide in detailed list format."
vector_rag.search(q, retriever_config={'top_k':5}).answer
graph_rag.search(q, retriever_config={'top_k':5}).answer답변을 비교해보면 GraphRAG 응답이 훨씬 더 포괄적이고 관련 컨텍스트를 더 많이 포함하고 있다는 것을 알 수 있어요.

더 자세한 내용은 다음을 참조하세요. GraphRAG Python 패키지: Knowledge Graph로 GenAI 가속화 리소스 섹션을 확인해 보세요.
일반적인 GraphRAG 사용 사례
GraphRAG는 출력이 중요한 비즈니스 의사 결정에 사용되기 때문에, 더 높은 수준의 신뢰가 필요한 애플리케이션 및 도메인에 적합해요. 몇 가지 예를 들어볼까요?
- 법률 및 규정 준수: 계약, 판례, 법률, 규정 등을 검토하고 분석하는 데 활용돼요.
- : 조직, 사람, 경쟁사, 시장 및 동향을 조사하는 데 쓰이죠.
- : 약물 발견 및 용도 변경, 임상 시험 및 연구를 위한 Knowledge Graph에 액세스하는 데 사용돼요.
- : 다양한 비즈니스 데이터 소스를 조직의 응집력 있는 관점으로 통합하는 데 활용돼요.
- : 제품 및 생산 프로세스의 위험 평가, 규정 준수, 지속 가능성에 대한 조사를 수행하는 데 쓰여요.
- : 자금세탁(AML), 보험 사기, 기타 사기 행위를 식별하고 예방하는 데 사용돼요.
- : 뉴스 기사 및 조사를 위해 대규모 데이터 세트에서 연관성과 패턴을 찾아내는 데 활용돼요.
- 자연어 검색 및 챗봇: 사용자 친화적인 인터페이스를 통해 기존 지식 기반에 대한 액세스를 민주화하는 데 쓰이죠.
GraphRAG: 엔터프라이즈급 AI 앱 활성화
RAG 아키텍처는 현재 신뢰할 수 있는 데이터 소스의 데이터를 사용하여 GenAI 비즈니스 애플리케이션에 안정적인 콘텐츠를 제공하는 가장 효과적인 방법이에요. GraphRAG는 여기서 한 단계 더 나아가 품질과 설명 가능성 모두에서 기본 벡터 기반 RAG를 개선하죠.
보다 관련성이 높은 컨텍스트를 고려하고 문서, 도메인 및 계산된 그래프 구조를 탐색하는 다양한 검색기를 사용함으로써 GraphRAG는 더욱 정확하고 신뢰할 수 있으며 추적 가능한 결과를 제공해요. 실제 정보를 풍부하게 표현하는 Knowledge Graph와 고급 언어 기술을 갖춘 LLM을 결합하여 기업 사용 사례를 위한 강력하고 안정적인 솔루션을 만드는 거죠.
점점 더 많은 조직이 GenAI를 채택함에 따라 GraphRAG는 이러한 시스템의 정확성, 신뢰성 및 투명성을 보장하고 더 나은 의사 결정과 향상된 비즈니스 결과를 위한 길을 닦는 데 필수적일 거예요.
필수 GraphRAG
Knowledge Graph를 통해 RAG의 잠재력을 최대한 활용해보세요. Manning으로부터 최종 가이드를 무료로 받아보실 수 있어요!
GraphRAG에 대해 더 자세히 알고 싶으시다면, 다음 자료들을 확인해보세요!
- GraphRAG 선언문
- Knowledge Graph란 무엇일까요?
- Neo4j를 사용한 생성적 AI
- GraphRAG 패턴 카탈로그
- 온라인 Neo4j LLM Knowledge Graph 빌더(LangChain 사용)
- Neo4j GraphRAG Python 패키지
- RAG 과정을 위한 DeepLearning.AI Knowledge Graph
- 무료 GraphAcademy GenAI 강좌
- GraphRAG
- RAG
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'GraphRAG' 카테고리의 다른 글
| 검색 증강 생성 (RAG)이란 무엇일까요? (0) | 2026.06.09 |
|---|---|
| GraphRAG란 무엇일까요? (0) | 2026.06.09 |
| 그래프 데이터베이스를 거닐며 발견하는 의미: Neo4j와 GraphRAG의 세계 (0) | 2026.06.08 |
| NEuler에서 그래프 임베딩 알고리즘 결과 시각화하기 (0) | 2026.06.08 |
| 벡터와 그래프, 함께하면 더 강력해진다: Neo4j와 GraphRAG의 시너지 (0) | 2026.06.08 |