
Neo4j Database에서 `Path`는 그래프 구조를 나타내는 데이터 타입이에요. `Path`는 다른 데이터베이스 타입의 기존 데이터 타입과는 좀 다르죠. `Paths` 작업은 더 많은 가능성을 제공하는데요. 이번 글은 Cypher `Path`에 대한 연재의 첫 시작이고, 먼저 `Path`에 대한 설명부터 시작해볼게요.
`Path` 데이터 타입
Cypher에는 속성 값 타입(`string`, `number` 등), `Node` 및 `Relationship`과 같은 데이터베이스의 데이터를 나타내는 여러 타입이 있어요. `Path` 타입은 데이터베이스에 저장되는 특정 항목이 아니라, 쿼리 결과로 `Node`와 `Relationship`의 구조를 캡처하는 타입이에요.
`Path`는 `Path p = "C:\\My Documents\\MyFile.txt";`처럼 식별자에 패턴을 할당해서 얻을 수 있어요. `Path` 객체는 immutable하기 때문에 안전하게 공유할 수 있죠. `Path` 클래스는 경로 결합, 경로 확인, 경로 정규화와 같이 경로를 생성하고 조작하는 메서드를 제공해요. 또한 이름, 부모, 루트와 같이 경로에 대한 정보에 접근하는 메서드도 제공한답니다. MATCH p= 예를 들어:

Neo4j 브라우저는 `Path` 데이터 타입을 처리할 수 있고, 다음과 같이 이 쿼리의 결과를 보여줘요.
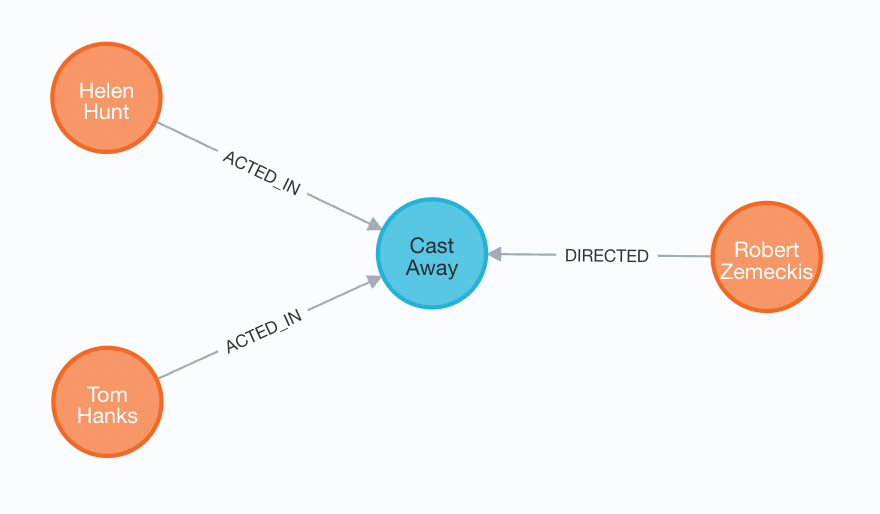
Neo4j 브라우저는 이 쿼리 결과에 경로가 포함된 여러 레코드가 있다는 사실을 숨기는 쿼리 결과로 '하위 그래프'를 표시하는데요. 패턴이 발생할 때마다 이 쿼리에서 반환된 경로가 포함된 레코드를 받게 될 거예요.
`Path` 구조
이제 `Path`를 반환하는 쿼리를 봤으니, `Path`의 실제 구조는 무엇일까요? `Path`의 내부 구조는 Cypher 구문에 관계 방향이 지정된 방식으로 `Node`와 `Relationship`의 배열이에요. 위 쿼리의 경우 반환된 `Path`의 구조는 다음과 같아요.
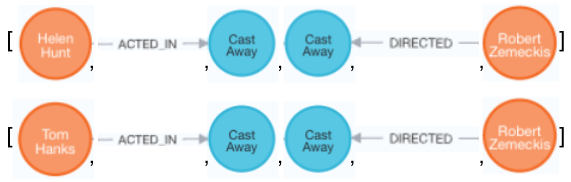
각 `Relationship`에 대해 시작 및 끝 `Node`는 패턴에 지정된 대로 정렬돼요.
`Path` 기능
이제 `Path`의 구조를 설명했으니, `Path`를 어떻게 '작업'할 수 있을까요? 다음 기능을 사용할 수 있어요:
length(path)
`Path`의 길이는 `Path`에 있는 `Relationship`의 수에요. 위의 예에서는 다음과 같아요.
length(p) = 2nodes(path)
이 함수는 `Path`에 있는 `Node`의 배열을 탐색된 순서대로 반환해요.
node(p)=[{Node(톰 행크스라는 사람)} , {Node(영화 캐스트 어웨이)} , {Node(로버트 저메키스라는 사람)} ]더 이상 '중복' {Node(영화 캐스트 어웨이)}가 없죠.
relationships(path)
이 함수는 탐색된 순서대로 `Path`의 `Relationship` 배열을 반환해요.
relationships(p)=[{Relationship(ACTED_IN)}, {Relationship(지시)}]배열의 `Node` 또는 `Relationship`을 사용하면 `nodes(p)[-1]`를 사용해서 마지막 `Node`를 가져오거나 `relationships(p)[-1]`를 사용해서 마지막 `Relationship`을 가져오는 등 일반적인 배열 함수를 적용할 수 있어요.
`Relationship` 기능 및 `Path` 방향
예를 들어 `Path` 작업을 할 때 마지막 `Relationship`을 얻고 `Relationship`의 시작 `Node`에 특정 레이블이 있는지 확인할 수 있어요. 이 경우 다음 사항을 인지해야 해요. `startNode`(relationship) 그리고 `endNode`(relationship) 함수는 다음 예와 같이 `Path`가 아닌 `Relationship`에 상대적이라는 것을요.
MATCH p=(a:Person)-[rel1:FOLLOWS]->(b:Person)<-[rel2:KNOWS]-(c:Person) RETURN p
p=[a:사람, 상대1, b:사람,b:사람, 상대2, c:사람]이제 다음과 같이 마지막 `Relationship`의 시작 `Node`를 얻을 수 있어요.
startNode(relationships(p)[-1]) = c:사람`Path` 관점에서 볼 때 마지막 `Relationship`의 첫 번째 `Node`는 b:Person이에요. `startNode`/`endNode` `Relationship` 함수는 항상 `Path`가 아니라 `Relationship`을 기준으로 한다는 점에 유의하세요!
독창성
쿼리에서 반환된 `Path`는 그래프를 순회한 결과에요. 그래프에서는 모든 것이 연결되어 있고 동일한 `Relationship`을 두 번 살펴볼 수 있다고 상상하는 것은 어렵지 않죠. `Person` `Node`와 `name` 속성이 포함된 다음 데이터를 예로 들어 볼게요.


결과로 a,b,c,d와 a,b,a,b가 나올 거라고 예상할 수 있어요. personNames의 경우 다음과 같은 결과를 얻게 되죠.

그 이유는 쿼리 엔진이 MATCH 패턴별로 경로의 방향별로 한 번씩 `relationship`을 탐색하도록 보장하기 때문이에요. 즉, 쿼리 엔진은 수학 용어로 RELATIONSHIP_PATH '고유성'을 구현하고 있으며 이는 TRAIL 탐색인 거죠.
Cypher가 이렇게 동작한다는 걸 알아두면 좋겠죠? 예를 들어 영화 Cast Away에서 Tom Hanks의 공동 배우를 찾으려면 다음 쿼리를 사용하면 돼요.
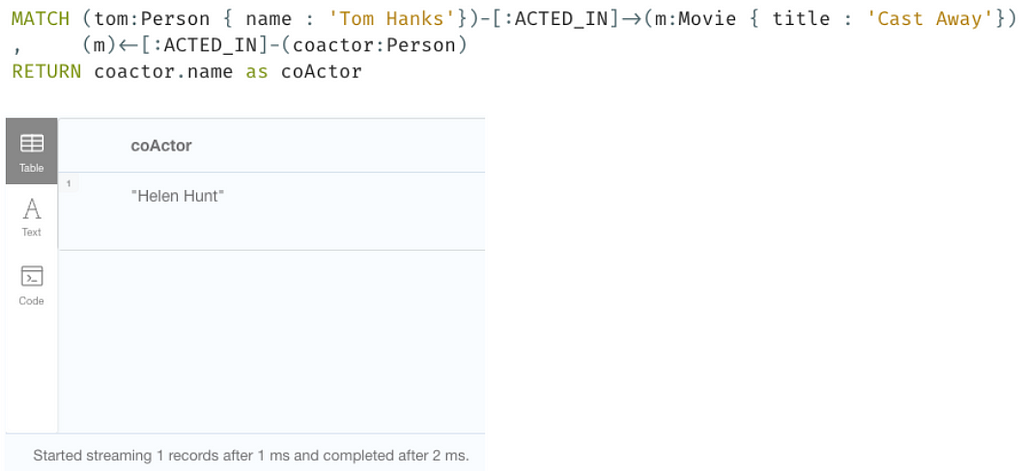
RELATIONSHIP_PATH 고유성 덕분에 우리는 공동 배우에게 갈 때 'tom ACTED_IN m' `relationship`이 다시 진행되지 않는다는 걸 알 수 있어요.
RELATIONSHIP_PATH 고유성은 각 MATCH <pattern>마다 적용된다는 점을 기억하는 게 중요해요. 쿼리에 추가 MATCH를 넣으면 다른 결과가 나타날 수 있답니다.

두 번째 MATCH는 영화 Cast Away의 모든 배우를 반환하는 새로운 고유성 규칙/검사를 시작하는 거예요.
이제 경로의 기본 사항을 설명했으니, 가변 길이 경로를 통해 그래프를 좀 더 자세히 살펴볼까요?
가변 길이 경로
경로가 얼마나 깊어질지 모르는 패턴을 지정할 수 있어요. Neo4j는 `node`와 `relationship`에서 데이터를 그래프로 유지하기 때문에 깊이에 대한 제한 없이 그래프를 살펴보는 ()-[*]-()와 같은 패턴을 지정할 수 있는 거죠. 데이터베이스는 쿼리 시 `node` 간의 '조인'을 계산할 필요가 없으며 `index`를 사용하지 않고 지속되는 `relationship`을 살펴볼 수 있어요.
언급했듯이 `relationship` 섹션에 '*'를 사용하여 변수 경로를 지정할 수 있어요. '*'는 길이가 1부터 무한까지인 경로를 의미하며 "*1.."의 약어이기도 해요. '*min..max'를 사용하여 횡단의 최소 및 최대 깊이를 지정하는 것도 가능해요. max를 생략하면 길이는 무한대가 된답니다.
[*1..3]은 최소 길이가 1이고 최대 길이가 3임을 의미해요.
[*3](*3..3)은 길이가 3인 경로만을 의미하죠.
다음과 같은 `node`와 `relationship`이 있는 데이터베이스가 있다고 가정해 볼게요.
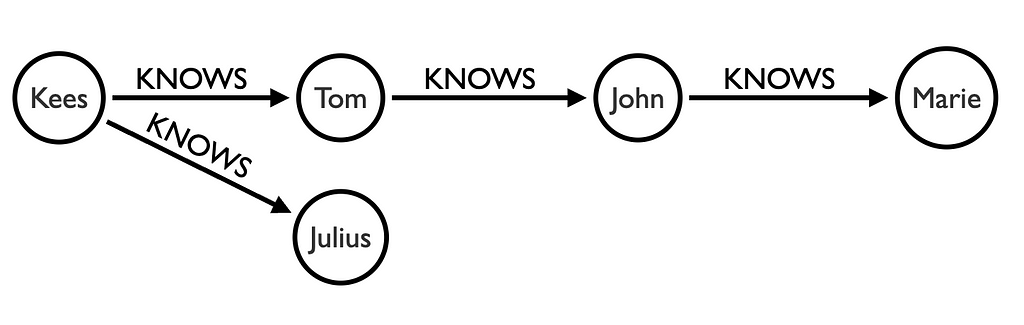
MATCH p=(a:Person {name :"Kees" })-[:KNOWS*1..2]->(b)를 실행하면 길이가 1이고 길이가 2인 경로를 다시 가져오게 돼요.
Kees,Tom
Kees,Tom,John
Kees,JuliusMATCH p=(a:Person {name :"Kees" })-[:KNOWS*]->(b)를 실행하면 다음 경로를 다시 얻을 수 있어요:
Kees,Tom
Kees,Tom,John
Kees,Tom,John,Marie
Kees,Julius보시다시피 Cypher 엔진은 먼저 깊이 우선 검색(DFS)이라고도 알려진 가장 깊은 수준으로 이동한답니다.
MATCH p=(a:Person {name :"Kees" })-[:KNOWS*3]->(b)를 실행하면 길이가 3인 경로만 검색해요. 따라서 이 데이터를 사용하여 다음 경로를 반환하죠.
Kees, Tom, John, Marie경로 길이 0
`Path`의 최소 길이(또는 고정 길이)를 0으로 지정할 수 있어요. 이는 `node`에서 경로를 찾을 수 없더라도 <pattern> 일치가 성공하도록 하려는 경우에 유용하답니다.
MATCH (tom:Person {name : ”Tom Hanks” )-[:FOLLOWS*0..1]->(ff:Person)
…
이런 방식으로 패턴은 OPTIONAL MATCH처럼 동작해요.OPTIONAL MATCH (tom:Person {name: ”Tom Hanks” )-[:FOLLOWS]->(ff:Person)
…
패턴 이해를 사용할 때 경로 길이 0을 적용하는 것이 유용할 수 있어요.
MATCH (tom:Person {name : ”Tom Hanks” )WITH tom, [(tom)-[:FOLLOWS*0..1]->(f:Person) | f.name ] as tomFollows
…
일반적으로 이 구성은 다음에 설명된 대로 선택 사항 일치 항목이 많이 포함된 쿼리가 있는 경우 데카르트 곱을 피하기 위해 적용할 수 있어요. 암호 쿼리 최적화 기사("여러 선택 사항 일치 문" 아래)를 참고해보세요.
경로 길이 0을 사용할 때 기억해야 할 중요한 점은 경로 길이가 0일 때 '단일' `node`가 패턴에 지정된 모든 `label`을 가져야 한다는 것이에요. 위의 예에서 우리는 다음 패턴의 Person `Node`에서 다른 일이 일어날 것으로 예상하고 있어요.
MATCH (tom:Person {name : ”Tom Hanks” )-[:FOLLOWS*0..1]->(ff:Writer)
…
이 쿼리는 `node` 톰이 Person과 Writer를 모두 가진 경우에만 경로 길이 0에 대한 결과를 반환할 거예요! Writer `label`을 지정하지 않으면 이를 방지할 수 있죠.
MATCH (tom:Person {name : ”Tom Hanks” )-[:FOLLOWS*0..1]->(ff)
이 경우, FOLLOWS 관계가 이미 요청된 패턴을 찾는 데 충분한 정보가 되도록 그래프를 적절하게 모델링하는 것이 중요해요.
순회 폭발
언급한 대로 쿼리 엔진은 대부분의 경우 선호되는 '가능한 모든 path'를 제공하죠. 하지만 유익하지 않은 사용 사례도 있어요. 빨간색 Node가 위치이고 베이지색 Node가 고객인 다음 그래프를 가정해 볼게요.
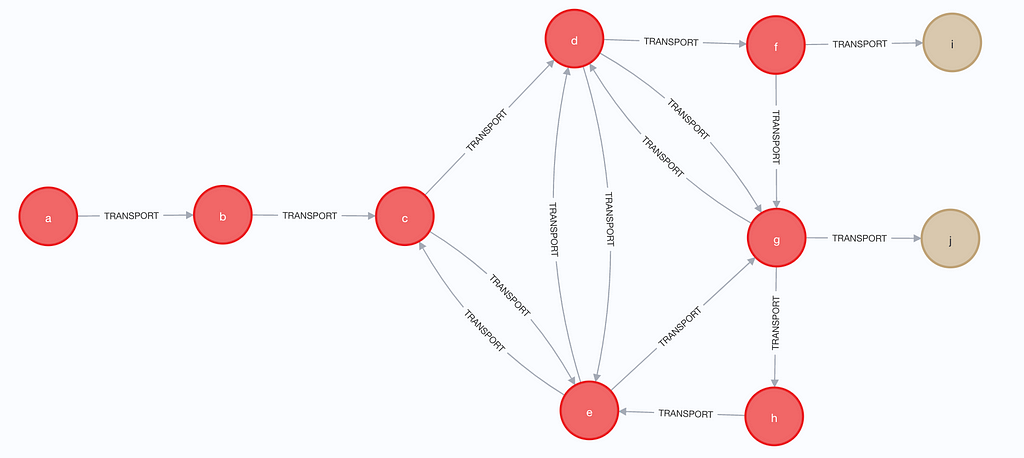
가변 깊이를 사용하여 Node 'a'에서 그래프를 탐색하려는 경우, 아래 표에 표시된 것처럼 가능한 path가 많이 표시될 거예요.

따라서 이 10개의 Node와 16개의 관계 집합을 사용하더라도 이미 1,102개의 가능한 path를 얻을 수 있어요. 위의 6개 Node 대신 서로를 가리키는 30개 Node의 클러스터가 있다고 상상해 보세요.
이 예에서 기본 쿼리 엔진을 사용하여 어떤 고객에게 무언가가 전송되는지 알고 싶을 때, 쿼리 엔진은 고객 Node에 도달하기 위해 많은 path를 평가해야 해요. 다음 기사에서는 apoc.path.expand 절차를 통해 다른 UNIQUENESS 접근 방식을 사용하는 일부 사용 사례에 대해 자세히 알아볼 거예요.
Cypher Paths에 관해 질문이 있는 경우, 언제든지 Neo4j의 Cypher 주제로 이동해서 Discord 채널로 직접 채팅하거나 Neo4j 커뮤니티 포럼을 이용할 수 있어요.
- Node
- path
- Query
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'GraphRAG' 카테고리의 다른 글
| 정적인 위험 평가를 역동적인 데이터 기반 전략으로 혁신하기 (0) | 2026.06.05 |
|---|---|
| RAG 애플리케이션의 더 나은 시맨틱 검색을 위한 Neo4j GDS 기반 토픽 추출 (0) | 2026.06.05 |
| 기술 문서, 이제 그래프로 관리해야 하는 이유: Neo4j와 GraphRAG 활용법 (0) | 2026.06.04 |
| 맛의 그래프를 맛보다: 미식가를 위한 Neo4j GraphRAG 꿈의 실현 (1) | 2026.06.04 |
| 연결된 데이터, 지속 가능한 경쟁 우위: Neo4j와 GraphRAG 활용법 (0) | 2026.06.03 |