
- 에이전트 AI
지난 몇 분기 동안 기업에서 에이전트 워크플로우를 채택하는 경우가 엄청나게 증가했어요. 대기업은 GraphRAG가 기존 RAG보다 더 정확한 결과를 제공하고, 다중 홉 추론이 많은 고부가가치 사용 사례에 필수적이며, 메모리 및 컨텍스트 그래프가 정확한 의사 결정에 중요하다는 것을 깨닫고 있죠. 하지만 기업은 제로 카피 아키텍처를 원해요. 그들은 그래프 인텔리전스의 이점을 활용하기 위해 데이터 웨어하우스, 레이크하우스, 운영 데이터베이스의 데이터를 Neo4j로 이동하거나 복제하고 싶어하지 않죠. 오늘 우리는 모든 기업 데이터에 대한 그래프 인텔리전스의 힘을 활용하고 있어요.
저희는 Neo4j Virtual Graph를 발표합니다! 현재 비공개 미리보기로 제공되고 있어요. Virtual Graph를 사용하면 Snowflake, Databricks 및 기타 데이터베이스와 레이크하우스에 이미 있는 데이터에 대해 직접 Cypher `쿼리`와 그래프 알고리즘을 실행할 수 있어요. 저희의 제로 카피 아키텍처는 여러분의 데이터가 기존 제어에 따라 관리되는 동시에 Neo4j의 AI 기반 그래프 도구의 성능을 계속 활용할 수 있음을 의미해요. 관리할 새로운 기록 시스템이 없는 거죠!.
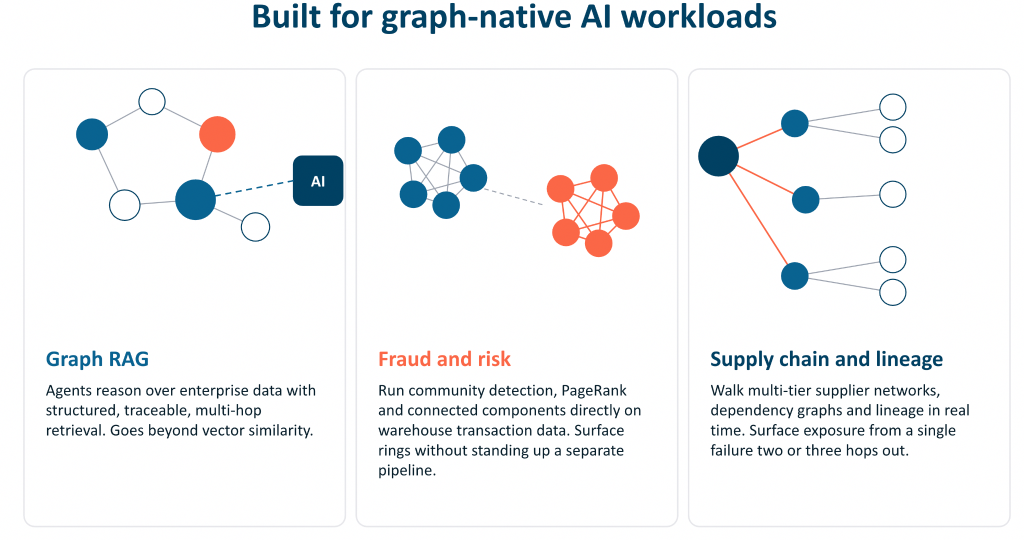
Virtual Graph는 테이블이 항상 암시했지만 결코 노출하지 않은 `관계`를 표면화하여 그래프 `쿼리`, 그래프 알고리즘 및 이를 추론해야 하는 AI 에이전트를 준비시켜요.
왜 Virtual Graph인가?
AI를 활용해서 팀을 빌딩하다 보면 똑같은 문제에 부딪히게 돼요. 언어 모델은 정말 강력한 추론 도구이긴 하지만, 언어 모델이 접근하는 데이터 시스템은 연결된 데이터를 그래프 형태로 제공하도록 만들어지지 않았거든요. 상담원이 "공급업체 중단이 발생한 모든 고객을 보여줘" 라거나 "실소유주가 3홉 떨어진 계정을 찾아줘" 같은 질문에 답해야 한다면, 단순히 플랫 테이블 쿼리나 벡터 검색만으로는 부족하죠. 에이전트에게는 그래프가 필요한 거예요.
저희는 전 세계의 데이터 및 AI 팀으로부터 똑같은 질문들을 받았어요.
- Neo4j에서 이미 실행 중인 그래프와 함께, 이미 웨어하우스에 있는 데이터에 그래프 추론을 적용하려면 어떻게 해야 할까요?
- 너무 크거나, 통제가 심하거나, 운영 중이라서 옮길 수 없는 데이터 세트에 Neo4j의 AI 기반 그래프 도구를 어떻게 적용할 수 있을까요?
- ETL 파이프라인을 구축하지 않고도 웨어하우스 데이터에서 GraphRAG의 가치를 테스트해볼 수 있을까요?
- 레이크하우스에 단일 정보 소스를 유지하면서, 여기에 대한 그래프 추론을 얻으려면 어떻게 해야 할까요?
- 몇 초에서 몇 분 정도의 지연 시간이 적절한 배치 및 분석 에이전트 워크로드의 경우, 병렬 그래프 스택 구축을 피하려면 어떻게 해야 할까요?
Virtual Graph는 이 모든 질문에 대한 해답을 제시하기 위해 만들어졌답니다.
Virtual Graph를 만나보세요
기존 웨어하우스에서 바로 Graph Database를 가리키고, 데이터 이동이나 스키마 재작성, 유지 관리해야 할 새로운 파이프라인 없이도 몇 분 만에 시작할 수 있다고 상상해보세요. 바로 그게 Virtual Graph예요.
AuraDB에서 이미 사용하고 있는 것과 동일한 환경에서 Neo4j Aura에서 기본적으로 실행돼요. 데이터 소스에 연결해서 테이블에서 그래프 데이터 모델을 자동으로 생성하고 쿼리를 시작할 수 있죠. 그 뒤에서는 Cypher 쿼리가 현재 데이터에 대해 컴파일되고 실행되니까, 이미 데이터를 관리하는 시스템에서 이미 비용을 지불한 컴퓨팅으로 무거운 작업을 처리할 수 있어요. 그래프의 표현력과 데이터 레이크 규모를 둘 중 하나를 선택하지 않아도 된다니, 정말 좋죠?
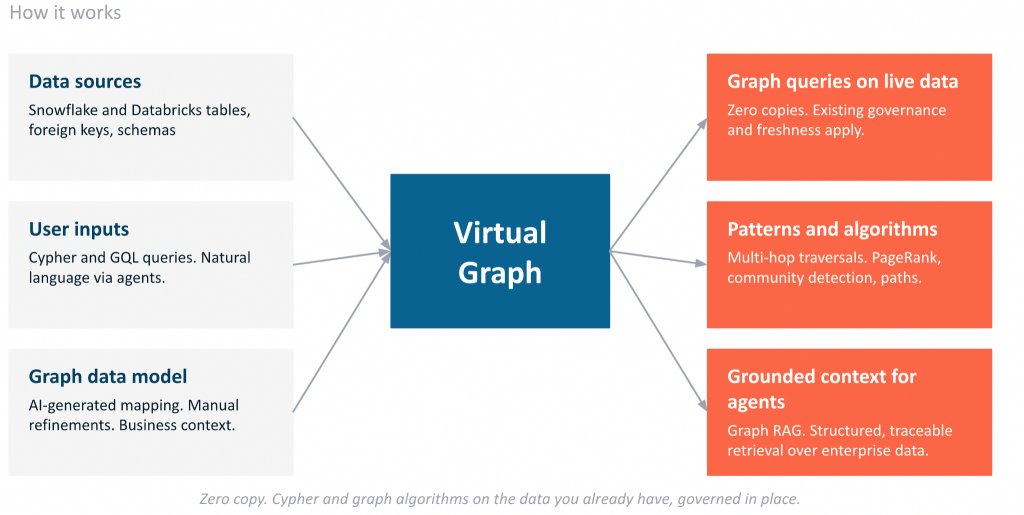
실제 모습은 이렇습니다.
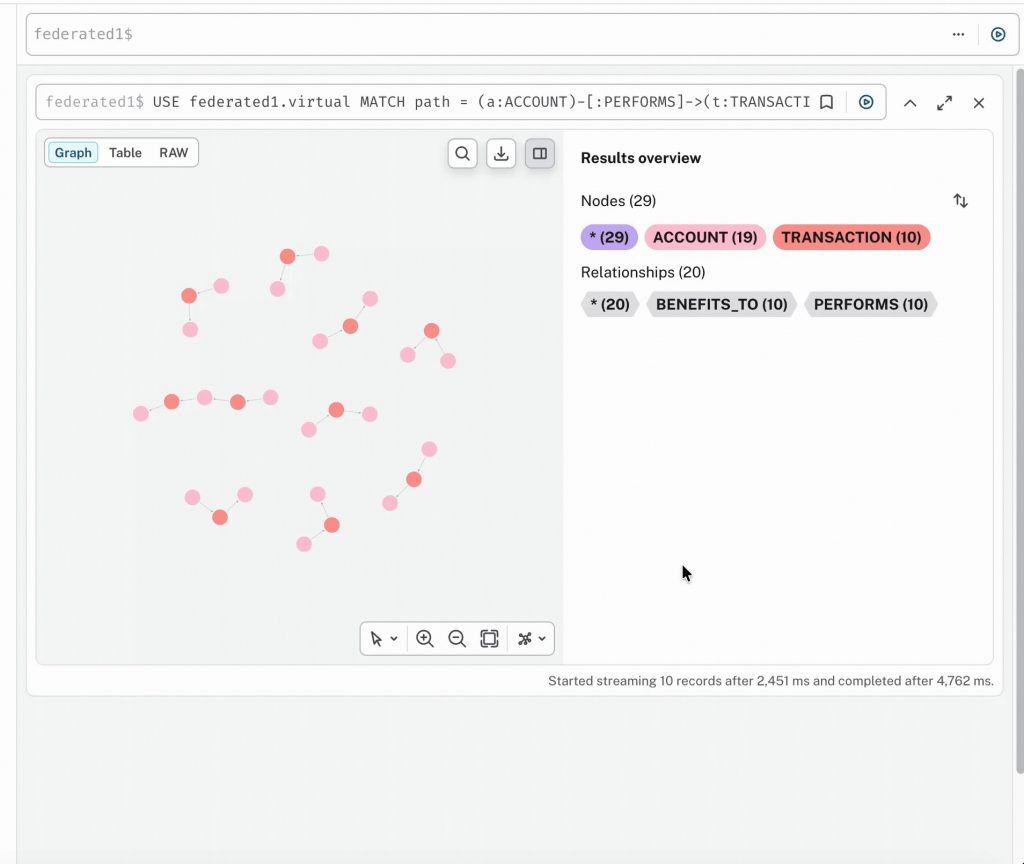
1. 웨어하우스 데이터에 대한 직접적인 Cypher 및 그래프 알고리즘
Virtual Graph를 Snowflake 또는 Databricks 작업 영역에 연결하면 몇 분 안에 이미 신뢰하는 테이블에 대해 Virtual Graph가 작동하게 될 거예요. 복사 작업, 야간 로드, 유지 관리할 파이프라인이 없다는 점! 최신 버전의 데이터에 대해 직접 Cypher 패턴, 그래프 순회 및 경로 찾기를 실행해 보세요.
예를 들어:
“내 거래 데이터 내에서 순환 결제를 찾고, 이를 연결하는 경로를 반환해줘.”
여러분이 작성한 Cypher는 웨어하우스가 이미 이해하고 있는 SQL로 컴파일되고, 작업은 제자리에서 실행되며, 답변은 그래프 결과로 돌아올 거예요. 데이터는 이동되지 않아요! 왜냐하면 컴파일은 LLM 기반이 아닌 경우에는 매번 동일한 SQL을 얻게 되니까요. 즉, 예측 가능한 성능 및 비용을 보장한다는 거죠.
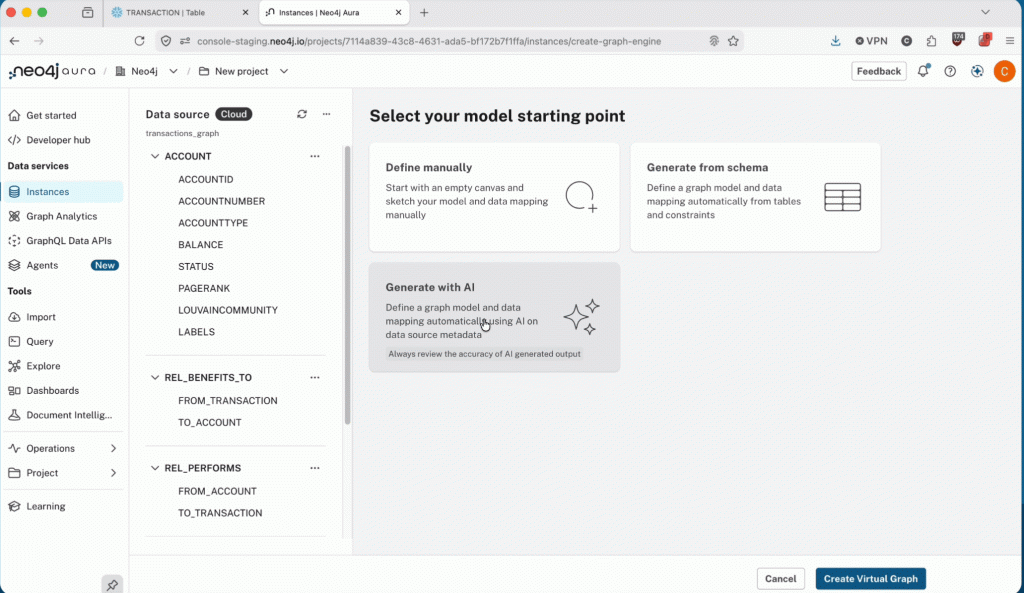
2. 기존 테이블에서 AI 생성 데이터 모델
예전에는 워크숍에서나 가능했던 그래프 모델링이 이제는 클릭 한 번으로 가능해졌어요. 테이블에 가상 그래프를 지정하면 내장된 AI가 그래프 모델을 제안해 준답니다. 어떤 엔터티가 Node가 되어야 하는지, 어떤 외래 키가 Relationship이 되어야 하는지 (심지어 외래 키를 선언하지 않은 웨어하우스의 Relationship까지 추론해요!), 어떤 열이 속성이 되어야 하는지까지 제안한다니, 정말 놀랍죠? 제안된 모델을 검토하고 필요에 따라 조정한 후 적용하면 끝!
이렇게 한번 시도해 보세요:
“내 은행 스키마의 고객, 거래, 계정 테이블에서 그래프 모델을 생성합니다.”
가상 그래프는 기존 스키마를 검사하고 엔터티와 Relationship을 추론해서, 커밋하기 전에 시각적으로 편집할 수 있는 모델을 제시해 준답니다.
작동 원리
Virtual Graph는 애플리케이션과 기존 데이터 사이에 위치하며, 다음 세 가지 요소가 함께 작동해요.
- : 소스 스키마에서 AI에 의해 자동으로 생성되어 엔진 인스턴스에 저장돼요. 여러분이 직접 소유하고 편집할 수 있으며, 테이블과 동기화된 상태를 유지할 수 있죠.
- : Cypher 패턴을 최적화된 SQL로 컴파일하고, 해당 작업을 웨어하우스 엔진에 푸시해요. 여러분의 데이터는 거버넌스 경계를 벗어나지 않는답니다.
- 그래프 계산 계층: SQL만으로는 효율적으로 표현할 수 없는 패턴 일치, 순회, 알고리즘과 같은 그래프 관련 작업을 처리해요.
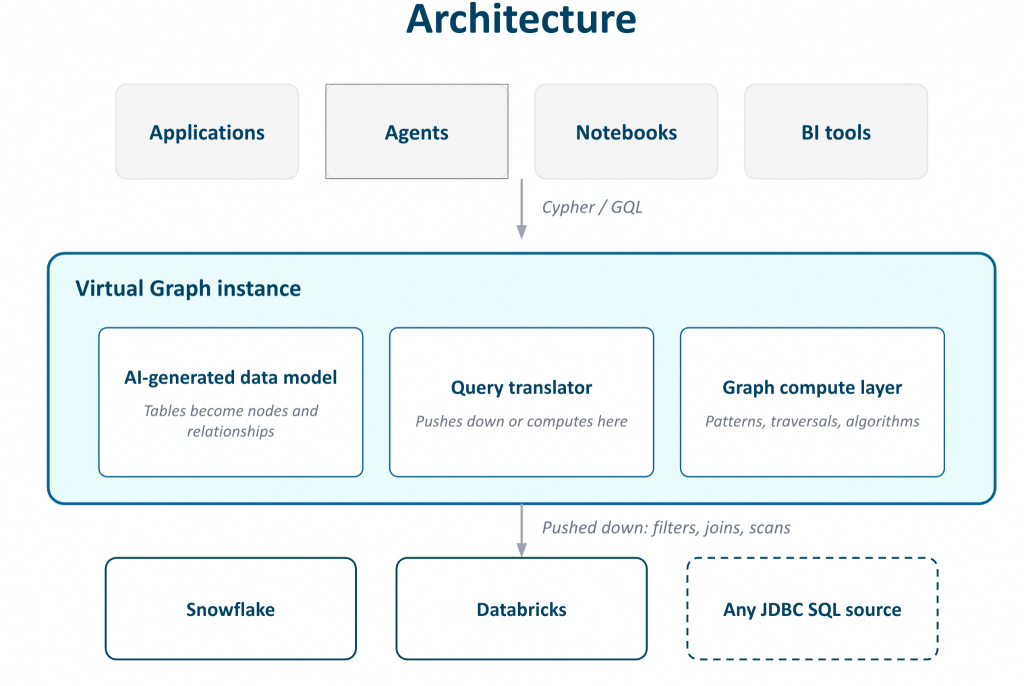
결과적으로 관계형 분석이 이미 실행되고 있는 바로 그 장소에서, 기존의 보안, 거버넌스, 그리고 최신 데이터 상태를 그대로 활용하면서 그래프 추론을 얻을 수 있다는 거죠!
가상 그래프와 Neo4j 저장 그래프, 언제 써야 할까요?
가상 그래프와 Neo4j에 저장된 그래프는 서로 대체하는 게 아니에요. 서로 다른 문제를 해결해주기 때문에, 그래프를 잘 활용하는 기업은 둘 다 사용하고 있죠.
어떤 웨어하우스가 좋을까요? Snowflake, Databricks 같은 엔진은 밀리초 단위의 짧은 대기 시간보다는 데이터 최신성이 더 중요한 대규모 데이터 세트, 일괄 처리, 분석 워크로드에 최적화되어 있어요. 컬럼 형식 스캔, 대규모 팩트 테이블 조인, 비즈니스 분석 계층을 제공하는 데 아주 뛰어나죠. 하지만 짧은 대기 시간이 중요한 순회 작업에는 적합하지 않아요.
Neo4j에 저장된 그래프의 장점은 뭘까요? Neo4j에 저장된 그래프는 짧은 대기 시간과 높은 처리량으로 순회하는 데 특화되어 있어요. 깊이 있는 멀티 홉 패턴, 핫 데이터에 대한 경로 찾기, 실시간 패턴 매칭, ACID 트랜잭션을 보장하는 쓰기 작업, 에이전트가 시간당 수천 번 호출하는 상시 그래프 워크로드에 적합하죠. 게다가 기본 스토리지는 AI 기반 모델링, Semantic Search, 고객들이 오랫동안 구축해온 Knowledge Graph 같은 프로덕션 환경에서 사용할 수 있는 Neo4j 그래프 도구들을 활용할 수 있게 해줘요.
가상 그래프는 어떤 경우에 적합할까요? 이런 경우에 Virtual Graph를 사용하면 좋아요.
- 병렬 파이프라인을 구축하지 않고, 이미 웨어하우스에 있는 데이터에 대한 그래프 추론을 하고 싶을 때
- 워크로드가 웨어하우스 수준의 대기 시간을 허용할 때 (GraphRAG, 배치 보강, 분석가 중심 탐색, 몇 초에서 몇 분 정도의 시간이 허용되는 에이전트 워크플로우)
- 기본적으로 어떤 데이터를 그래프로 표현할지 결정하기 전에 기존 데이터에서 그래프 패턴의 가치를 테스트해보고 싶을 때
- 데이터 거버넌스, 규모, 또는 정책 때문에 데이터를 현재 위치에 그대로 둬야 할 때
Neo4j에 저장된 그래프는 어떤 경우에 적합할까요? 이런 경우에는 AuraDB나 자체 관리형 Neo4j를 활용해보세요.
- 워크로드에 실시간 에이전트 의사 결정, 온라인 사기 점수 매기기, 세션 내 추천, 실시간 ID 확인처럼 밀리초 단위의 순회 대기 시간이 필요할 때
- 그래프가 지속적으로 업데이트되고, 쓰기 작업에 ACID 트랜잭션이 보장되어야 할 때
- 데이터가 원래부터 구조화되지 않은 문서로 구축된 Knowledge Graph, 관계 밀도가 높은 고객 360, 공급망, 상담원을 위한 메모리 그래프처럼 그래프 형태에 잘 맞을 때
- 전체 Cypher, 그래프 알고리즘, AI 기반 그래프 도구를 한 곳에서 사용하고 싶을 때
일반적인 패턴은 이래요. 많은 고객들이 두 가지를 모두 사용하고 있어요. Virtual Graph를 통해서는 웨어하우스에 있는 참조 데이터(거래, 계정, 제품 카탈로그)에 접근하고, 운영 그래프(Knowledge Graph, 메모리 그래프, 실시간 고객 그래프)는 대기 시간이 중요한 AuraDB에 두는 거죠. 복합적인 쿼리가 AuraDB에 도달하면, 단일 쿼리문으로 두 가지 쿼리를 모두 처리할 수 있어요.
가장 간단한 규칙은 이거에요: 워크로드를 '몇 초 안에 생각해야 하는 에이전트'로 설명할 수 있다면 Virtual Graph가 적합하고, '밀리초 단위로 작동해야 하는 에이전트'로 설명해야 한다면 그래프를 기본적으로 저장하는 게 좋겠죠.
다음 단계: 가상화에서 가속화까지
Virtual Graph는 현재 가상화 계층으로 출시되었어요. 이건 의도적인 선택이었는데요, 모든 팀이 부담 없이 기존 데이터에 대한 그래프를 시험해볼 수 있기를 바랐기 때문이에요. 하지만 여기서 멈추지 않을 거예요.
로드맵은 다음과 같아요.
- 더 많은 소스. JDBC나 SQL 인터페이스가 있는 모든 시스템이 대상이에요. 데이터가 어디에 있든, 그 위에 그래프를 표현할 수 있게 될 거예요.
- 적응형 캐싱. 핫 서브 그래프를 구체화해서 반복되는 에이전트 워크로드에 대한 대기 시간을 대폭 줄이고, 동일한 순회를 수천 번 실행하면서 발생하는 외부 컴퓨팅 비용을 절감하는 기능이에요. Virtual Graph가 비용 중립적인 수준에서 비용 절감 효과를 가져다주는 거죠.
- AuraDB와 Virtual Graph에 대한 복합 쿼리. 예를 들어 AuraDB의 Knowledge Graph와 Snowflake의 주문 내역 Virtual Graph를 포괄하는 단일 Cypher 문을 작성하는 거예요. 현재 자체 관리형 Neo4j에서 AuraDB로 제공되고 있어요.
- 더욱 심층적인 에이전트 통합. 에이전트가 Neo4j 그래프 도구를 통해 그래프를 호출하는 방식을 위해 설계된 기본 그래프-RAG 기본 요소, Semantic Layer 훅, 도구 정의가 포함될 거예요.
- Cypher와 GQL 패리티. 전체 적용 범위를 통해 이미 AuraDB에 대해 작성한 쿼리가 Virtual Graph에서도 변경 없이 작동하게 될 거예요.
에이전트 기업을 위한 Knowledge Layer
에이전트는 추론할 수 있는 컨텍스트만큼만 유능해요. 실시간 의사 결정이 필요한 워크로드의 경우, 기본 Neo4j 스토리지는 AI 기반 그래프 도구, 전체 Cypher, 그리고 고객들이 오랫동안 프로덕션 그래프 시스템을 구축해온 성능을 통해 가장 중요한 그래프 데이터를 위한 최적의 장소로 남아있을 거예요. 엔터프라이즈 데이터의 나머지 부분, 즉 쿼리가 도달할 수 없는 관계를 가진 웨어하우스와 레이크에 있는 데이터에 대해서는 Virtual Graph가 제로 카피와 제로 새로운 기록 시스템을 사용해서 그래프 추론을 가능하게 해줄 거예요.
둘 다 사용해보세요. 이것이 바로 가장 성숙한 그래프 기업들이 구축하는 방식이니까요.
여러분이 뭘 만들지 정말 궁금하네요!
시작할 준비 되셨나요?
Neo4j Virtual Graph는 현재 비공개 미리보기로 제공되고 있어요. Snowflake와 Databricks가 출시 시점에 지원될 예정이고, 앞으로 더 많은 소스가 추가될 예정이에요.
- : 여러분의 사용 사례를 알려주세요. 를 통해 알려주시면 저희 팀에서 연락드릴 거예요.
- : 3분 둘러보기를 통해 Snowflake 작업 공간에서 Virtual Graph를 연결하고, 모델링하고, 쿼리하는 방법을 확인해보세요.
- : 방법 알아보기그래프를 데이터 웨어하우스로 가져오는 방법을 알아보세요.
- : FAQ 읽기
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'Agent AI' 카테고리의 다른 글
| A Tour of the Neo4j Agent Memory Service (NAMS) (0) | 2026.07.08 |
|---|---|
| Build a Semantic Layer from GCP with Neocarta (0) | 2026.06.16 |
| Building Graph-Based Agentic Systems: Failures, Fixes, and How the Answer Gets There — Part 2 (0) | 2026.05.12 |
| Introducing Create Context Graph (0) | 2026.05.08 |
| Agent tools: What they are, how they work, and how AI agents use them (0) | 2026.05.07 |