
이전 블로그에서는 4줄의 코드로 구성된 GenAI 기반 노래 찾기를 통해, 벡터 검색을 사용해서 노래 설명을 기반으로 노래를 찾았어요. 우리는 단순히 문서를 찾기 위해 Vector Embedding을 사용했지만, Retrieval-Augmented Generation(RAG)을 사용하면 검색 결과를 챗봇(예: ChatGPT)에 대한 컨텍스트로 활용해서 근거 있는 답변을 제공함으로써 환각을 피할 수 있고, 소스 참조를 제공하며, 챗봇이 모르는 것에 대해 질문할 수도 있죠.
표준 RAG에서는 벡터 검색을 사용해서 데이터 소스에서 관련 문서를 찾아요. 그런 다음 이를 챗봇에 제공해서 해당 문서의 내용을 기반으로 질문에 대한 답변을 요청하는 거죠.
GraphRAG를 사용하면 벡터 검색을 사용해서 문서를 찾을 수도 있지만, Knowledge Graph의 기능을 사용해서 이를 확장하고 제공할 더 관련성 높은 문서를 찾을 수 있어요.
영화 그래프
이를 입증하기 위해 2024년 2월 현재 영화, TV 시리즈, 비디오 게임 등의 그래프와 해당 작업에 종사하는 사람들을 구축했어요. 그래프에는 약 천만 개의 타이틀과 약 1,300만 명의 사람들이 포함되어 있고, 약 1억 6백만 개의 Relationships가 있죠. 그 중 약 130만 권에 시놉시스가 첨부되어 있어요. 이 그래프의 데이터 모델은 다음 이미지와 같아요.
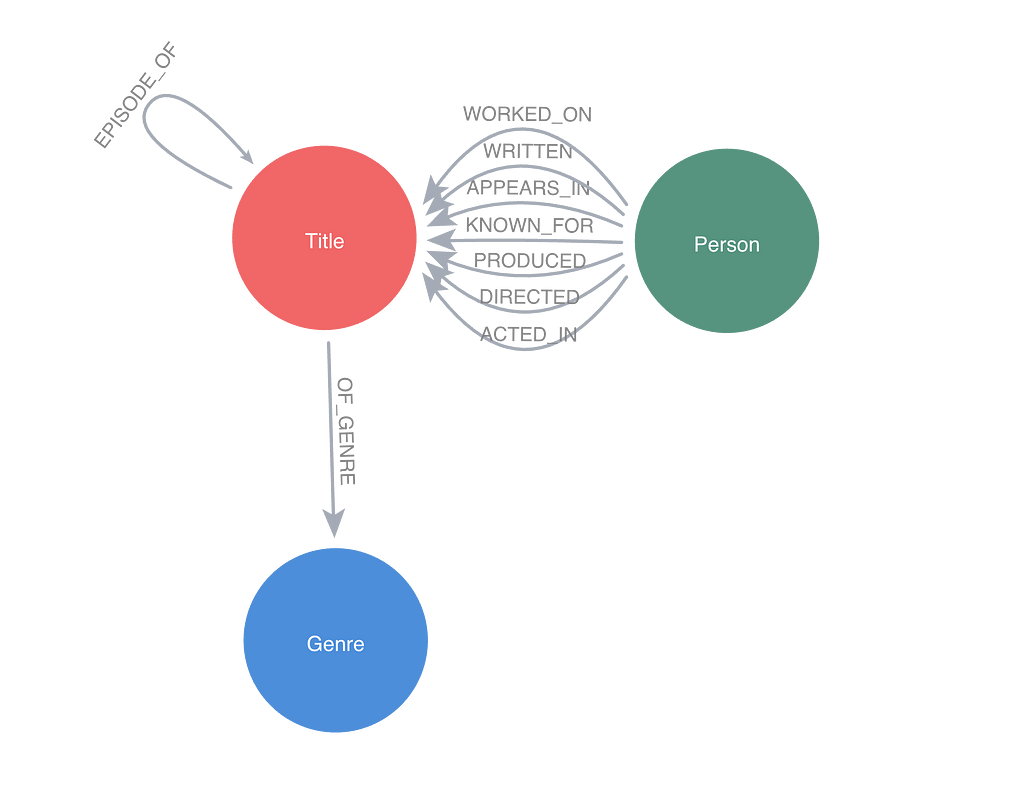
그래프는 IMDB(인터넷 영화 데이터베이스) 및 TMDB(영화 데이터베이스)의 비상업적 공개 데이터 세트를 사용해서 생성되었어요. 데이터는 2024년 2월 22일에 가져왔고요.
이전 블로그 게시물과 마찬가지로 이번에는 제목의 시놉시스 속성에 대해 벡터 Index와 Vector Embedding을 수행할 거예요. Index 생성부터 시작해 볼까요?
CREATE VECTOR INDEX synopsis_embeddings IF NOT EXISTS
FOR (t:Title) ON (t.embedding)
OPTIONS {
indexConfig: {
`vector.dimensions`: 1536,
`vector.similarity_function`: 'cosine'
}
}이제 임베딩을 수행할게요. 음악 블로그에서는 단순히 모든 속성을 일괄 임베딩에 제공할 수 있지만, OpenAI는 일괄 처리에서 2,048개의 속성만 지원하고 우리는 130만 개의 속성을 가지고 있잖아요. 그래서 0이 반환될 때까지 이 쿼리를 실행하는 스크립트를 만들었어요.
MATCH (title:Title)
WHERE title.synopsis IS NOT NULL AND title.embedding IS NULL
WITH title LIMIT 2048
WITH collect(title.synopsis) AS synopsis, collect(title) AS titles
CALL genai.vector.encodeBatch(synopsis, "OpenAI", {token: $apiKey}) YIELD index, resource, vector
CALL db.create.setNodeVectorProperty(titles[index], "embedding", vector)
RETURN COUNT(index) AS embedded위의 쿼리와 이후의 모든 쿼리에는 매개변수로 설정할 수 있는 OpenAI의 API 키가 필요해요.
:params
{
apiKey: "*****"
}질문
음악 블로그에서는 설명을 바탕으로 한 곡을 검색하기 위해 벡터 검색을 활용했죠. 하지만 이 경우에는 ChatGPT가 영화 데이터베이스의 시놉시스를 기반으로 답변하기를 원하는 질문을 표현하고, 답변을 찾은 위치에 대한 참조도 제공하려고 해요. 그래서 우리가 대답하고 싶은 질문은 다음과 같아요.
Robb Stark는 어떤 가족과 전쟁을 시작하나요?
우리 대부분은 이것이 왕좌의 게임에서 나온 것이라는 것을 알고 있다고 생각하지만, 우리가 모른다고 가정해 봅시다. 우리는 이 질문에 대한 답을 원해요. ChatGPT에는 130만 개의 시놉시스를 제공할 수 없으니까, 이 질문에 대한 답을 찾을 가능성이 가장 높은 곳을 찾아야겠죠.
질문을 매개변수로 설정하는 것부터 시작해 볼게요.
:params
{
question: "With what family does Robb Stark start a war?",
apiKey: "*****"
}이제 음악 블로그에서 했던 것처럼 벡터 검색을 수행해 볼게요.
WITH genai.vector.encode($question, "OpenAI", {token: $apiKey}) AS embedding
CALL db.index.vector.queryNodes('synopsis_embeddings', 1, embedding) YIELD node AS title, score
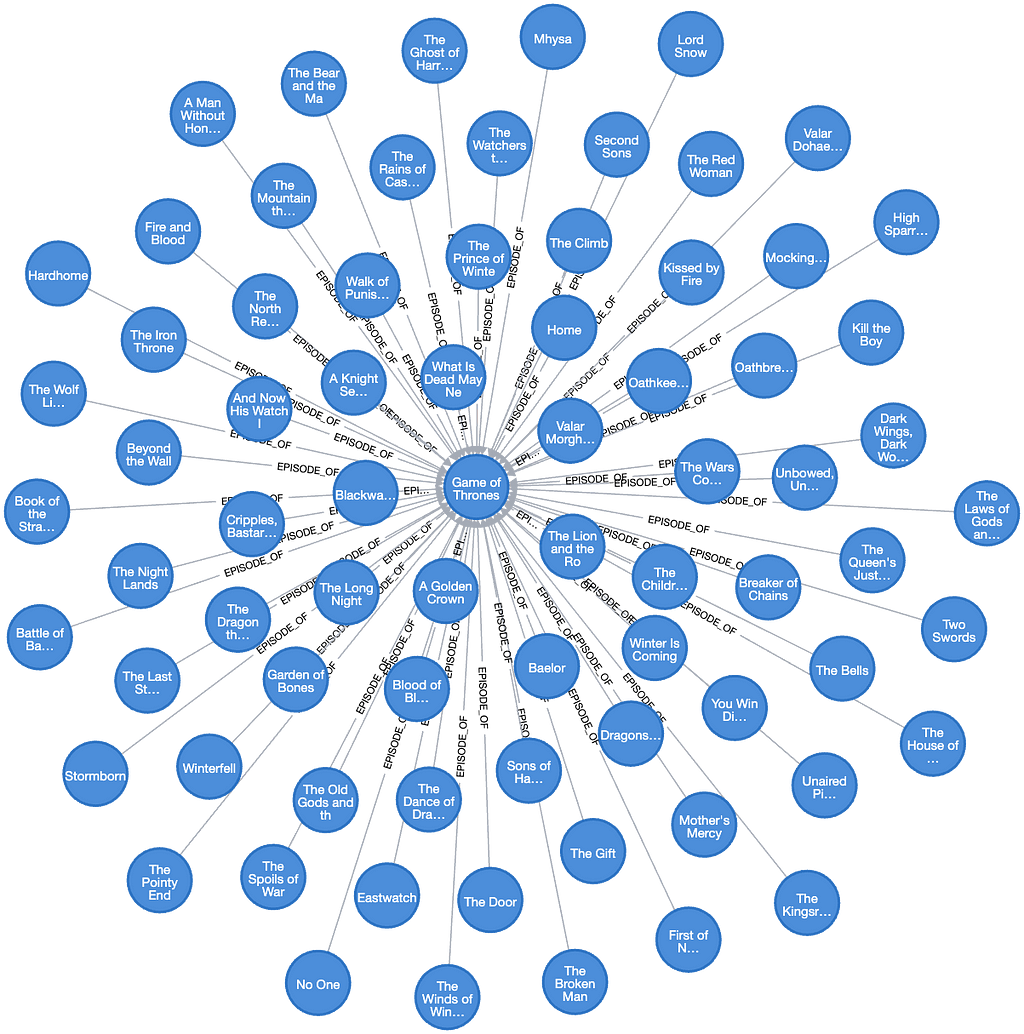
RETURN title이것은 우리에게 "The Watchers on the Wall" from 왕좌의 게임 시즌 4, 에피소드 9를 제공하네요. 130만 개의 타이틀 중에서 올바른 TV 시리즈를 찾았다는 게 정말 인상적이고, 1초도 안 돼서 찾아냈다는 점도 놀라워요. 하지만 이 에피소드의 개요는 ChatGPT가 다음 요청에 대한 답변을 찾는 데 도움이 되지 않아요.
Jon Snow와 Night's Watch는 큰 도전에 직면합니다.
여기서 우리는 Knowledge Graph의 힘을 활용할 거예요. Vector Search에서 제목을 반환할 뿐만 아니라, 제목이 TV 시리즈인 경우 모든 에피소드도 포함하고, 에피소드인 경우(이 경우처럼) 시리즈와 다른 모든 에피소드를 포함하도록 쿼리를 확장하죠.
WITH question, genai.vector.encode($question, "OpenAI", {token: $apiKey}) AS embedding
CALL db.index.vector.queryNodes('synopsis_embeddings', 1, embedding) YIELD node AS title, score
OPTIONAL MATCH (title)-[:EPISODE_OF]->(series:Title)
OPTIONAL MATCH (title)<-[:EPISODE_OF]-(other1:Title)
OPTIONAL MATCH (series)<-[:EPISODE_OF]-(other2:Title)
WITH collect(title)+collect(series)+collect(other1)+collect(other2) AS allTitles
UNWIND allTitles AS titles
RETURN DISTINCT titles이는 다음과 같은 결과를 제공해줘요.
RAG
이제 실제 RAG 부분이 나오는데요. 여기서는 모든 개요를 수집하고 ChatGPT에 이를 기반으로 질문에 대한 답변을 요청할 거예요. 이를 위해서는 OpenAI에 REST 호출을 수행해야 하죠. 이는 (현재) Neo4j에 내장된 절차가 아니므로 자체 애플리케이션에서 수행해야 하거나 Neo4j의 자체 인스턴스를 호스팅하고 APOC Extended를 실행할 수 있는 경우 거기에서 절차를 사용할 수 있어요. 저는 후자를 선택할 거예요.
ChatGPT에 물어볼 질문은 다음과 같아요.
Answer the following Question based on the Context only and provide a reference to where in the context you found it.
Only answer from the Context.
If you don't know the answer, say 'I don't know'.
The context is a list of titles followed by a synopsis, separated by colon.
Context: [All titles and synopsises separated by colon]
Question: [Our original question]다음은 APOC 확장 프로시저를 통해 해당 질문이 처리되는 전체 Cypher 쿼리의 모습이에요.
WITH question, genai.vector.encode($question, "OpenAI", {token: $apiKey}) AS embedding
CALL db.index.vector.queryNodes('synopsis_embeddings', 1, embedding) YIELD node AS title, score
OPTIONAL MATCH (title)-[:EPISODE_OF]->(series:Title)
OPTIONAL MATCH (title)<-[:EPISODE_OF]-(other1:Title)
OPTIONAL MATCH (series)<-[:EPISODE_OF]-(other2:Title)
WITH collect(title.primaryTitle + ":" + title.synopsis)+collect(series.primaryTitle + ":" + series.synopsis)+collect(other1.primaryTitle + ":" + other1.synopsis)+collect(other2.primaryTitle + ":" + other2.synopsis) AS allTitles
UNWIND allTitles AS titles
WITH DISTINCT titles
WITH apoc.text.join(collect(titles), "n") AS context
CALL apoc.ml.openai.chat([
{role:"user", content:"Answer the following Question based on the Context only and provide a reference to where in the context you found it. Only answer from the Context. If you don't know the answer, say 'I don't know'. The context is a list of titles followed by a synopsis, separated by colon.nnContext: " + context + "nnQuestion: " + $question}
], $apiKey) yield value
RETURN value.choices[0].message.content AS Title우리가 돌려받는 대답은 The Lannisters이에요. "북쪽은 기억합니다: Robb Stark와 그의 북부 군대가 Lannisters와의 전쟁을 계속하면서..." — 환각이 없으며 출처 참조가 제공되죠.
다음 레벨
제가 이것을 동료에게 보여주었을 때 그는 "멋지네요. 하지만 ChatGPT는 Game of Thrones에 대해 알고 있고 어쨌든 답변을 제공할 수 있었을 거예요. ChatGPT가 교육을 받았을 때 존재하지 않았던 타이틀로 어떻게 작동할 수 있었겠어요?"라고 말했어요.
당시 ChatGPT는 2023년 4월에 마지막 학습을 했어요. 그래서 2023년 4월부터 2024년 2월 사이에 출시된 것을 제가 본 적이 있는 것을 찾아서 이에 대한 질문을 할 수 있었죠. 제가 생각한 것은 영화 아가일이었어요. 제가 생각해낸 질문은 다음과 같아요.
엘리 콘웨이의 고양이 이름은 무엇인가요?
우선 RAG 없이 평범한 Prompt로 ChatGPT에 문의했더니 돌아온 대답은 "엘리 콘웨이의 고양이 이름은 루시입니다. 엘리 콘웨이는 'Big Little Lies', 'Nine Perfect Strangers' 등의 작품으로 유명한 호주 작가 Liane Moriarty의 가명입니다. Lucy는 작가와 관련된 인터뷰와 소셜 미디어 게시물에서 자주 언급됩니다." 였어요.
여기서 우리는 환각에 걸린 것 같아요. ChatGPT는 영화가 늦게 개봉해서 몰랐을 뿐만 아니라, “모른다”는 대신 거짓 답변을 내놓았어요. Elly Conway라는 가명을 사용하는 Liane Moriarty에 대한 정보는 전혀 찾을 수 없죠.
하지만 위에서 사용했던 것과 똑같은 RAG 쿼리를 실행하면, 이렇게 완벽하게 정확한 답변을 얻을 수 있어요. "Alfie (맥락: 은둔 작가 Elly Conway의 가상 스파이 소설 줄거리가 실제 스파이 조직의 은밀한 행동을 반영하기 시작하면서, 집에서 조용한 저녁 시간은 과거의 일이 됩니다. 그녀의 고양이 Alfie와 고양이 알레르기가 있는 스파이 Aiden과 함께…)."
짜잔! 거의 순수한 Cypher로 GraphRAG를 구현했어요.
추가 자료
앞서 말씀드렸듯이, Neo4j는 GraphRAG 애플리케이션을 더 쉽게 만들 수 있도록 다양한 AI 기술 스택과 통합되어 있어요. 관련해서 더 자세한 내용을 다루는 글들을 소개해 드릴게요.
- LLM Knowledge Graph Builder: 5분 만에 0에서 GraphRAG까지
- GenAI 생태계 – Neo4j Labs
- GraphRAG
- RAG
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'GraphRAG' 카테고리의 다른 글
| 그래프, 세상을 먹여 살리다: Neo4j와 GraphRAG의 힘 (0) | 2026.05.18 |
|---|---|
| GraphRAG Python 패키지: 지식 그래프로 GenAI 가속화하기 (0) | 2026.05.14 |
| GraphRAG 선언문: GenAI에 지식 더하기 (1) | 2026.05.14 |
| LLM 지식 그래프 빌더: 5분 만에 Zero에서 GraphRAG까지 (0) | 2026.05.13 |
| GraphRAG 실전 활용: 상업 계약서에서 다이나믹 Q&A 에이전트까지 (1) | 2026.05.13 |