
여러분, 혹시 RAG(Retrieval Augmented Generation) 시스템을 탐험하다가 GraphRAG라는 용어를 우연히 발견한 적 있으신가요? 그렇다면 혼자가 아니에요! 이 용어가 요즘 엄청 핫하지만, 정확히 뭘 의미하는지 파악하기 어려울 수 있죠. 어떤 경우에는 특정 검색 방법일 수도 있고, 또 다른 경우에는 Microsoft처럼 전체 소프트웨어 제품군을 의미하기도 하거든요. 예를 들어 GraphRAG는 "데이터 파이프라인 및 변환 제품군"이라고 하네요. 이렇게 다양한 용도로 사용되다 보니, RAG에 열광하는 사람들조차도 헷갈릴 수밖에 없을 거예요.
그렇다면 GraphRAG는 정확히 뭘까요? 저희 생각에는, 검색을 위해 그래프 구조를 활용하는 RAG 패턴들의 모음이라고 할 수 있어요. 각 패턴이 효과적으로 작동하려면 고유한 데이터 구조 또는 그래프 패턴이 필요하죠. 흥미롭지 않나요? 이번 포스팅에서는 GraphRAG 패턴의 세부 사항을 자세히 살펴보고, 각 패턴의 속성과 전략을 분석해 볼 거예요.
RAG에 대한 소개를 찾고 있다면, "검색 증강 생성(RAG)이란 무엇입니까?"를 확인해 보세요. 아니면 NODES 컨퍼런스 녹화본을 시청하는 것도 좋은 방법이에요. NODES 컨퍼런스는 24시간 동안 진행되는 무료 온라인 이벤트인데, 전 세계 연사들이 Knowledge Graph와 AI에 대해 발표한답니다.
여기 제시된 각 패턴은 GraphRAG 패턴 카탈로그에 직접 연결되어 있어요. 이 카탈로그는 최신 패턴 발전에 대한 정보를 얻기 위한 오픈 소스 이니셔티브예요. 아직 패턴 수집을 시작한 지 얼마 안 돼서 빠진 부분도 많지만, 여러분이 GraphRAG 패턴에 대한 포괄적인 카탈로그를 구축하는 데 도움을 주시면 정말 감사할 것 같아요! GraphRAG Discord 채널에 참여해서 함께 만들어나가요!
더 명확하게 보여드리기 위해, 이번 포스팅에서 설명할 패턴 목록을 준비했어요:
기본 GraphRAG 패턴:
- Basic Retriever (GraphRAG 패턴 카탈로그에서 확인)
- Parent-Child Retriever (에서 확인)
- Hypothetical Question Retriever (에서 확인)
중급 GraphRAG 패턴:
- Cypher Templates (에서 확인)
- 동적 Cypher 생성 ()
- Text2Cypher ()
고급 GraphRAG 패턴:
- 그래프 강화 벡터 검색 ()
- 글로벌 커뮤니티 요약 검색기 ()
몇 가지 배경 정보부터 시작해 볼게요.
주제별 분류
RAG 패러다임에는 순진한 RAG, 고급 RAG, 모듈형 RAG(Gao et al.)가 있어요:
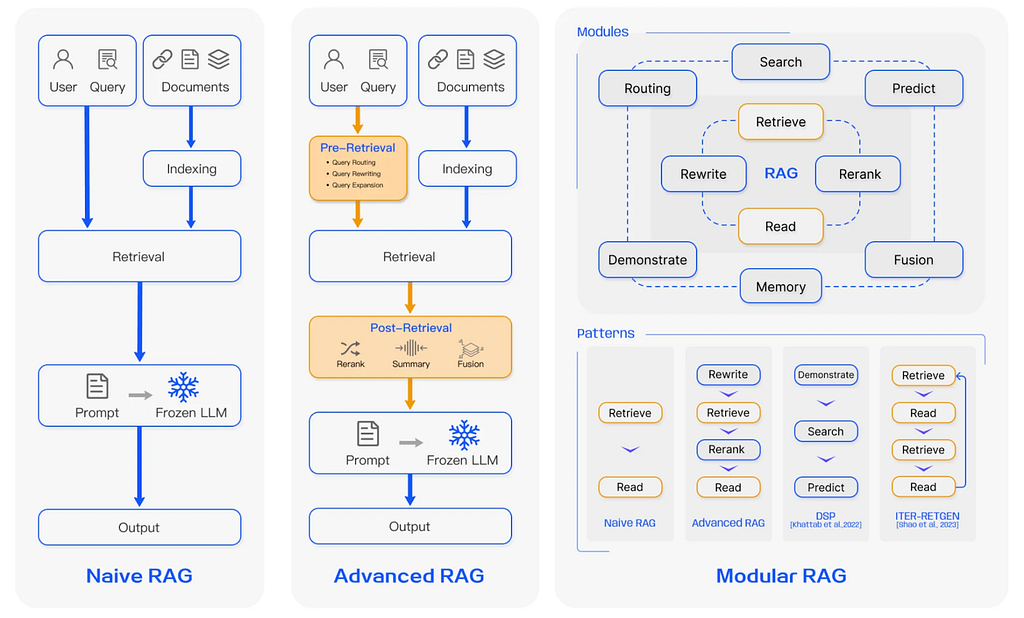
고급 RAG 패러다임에서는 검색 전 및 검색 후 단계가 순진한 RAG 패러다임에 추가되죠. 모듈식 RAG 시스템에는 사용자 쿼리의 조정 및 라우팅이 필요한 더 복잡한 패턴이 포함되어 있고요.
고급 RAG 시스템의 단계:
- — 쿼리 재작성, 쿼리 엔티티 추출, 쿼리 확장 등
- : 관련 맥락
- 검색 후: 순위 재지정, 정리 등
여기서는 검색 단계에 중점을 두고 가장 자주 참조되는 GraphRAG 검색 패턴과 필요한 그래프 패턴에 대한 조사를 해보려고 해요. 여기에 있는 패턴은 완전한 목록은 아니라는 점 참고해주세요!
왜 그래프인가?
검색 패턴을 자세히 살펴보면 가장 발전된 기술이 데이터 내의 연결에 어떻게 의존하는지 알 수 있을 거예요. 특정 저자 또는 특정 주제에 대한 기사 검색과 같은 메타데이터 필터링이든, 텍스트 청크의 상위로 다시 탐색하여 맥락이 풍부한 답변을 위해 LLM에 폭을 제공하는 부모-자식 검색기이든 이러한 방법은검색할 데이터 간의 관계를 활용하죠.
일반적으로 이러한 구현은 클라이언트 측 데이터 구조와 광범위한 Python 코드에 크게 의존해요. 하지만 Graph Database에서는 실제 관계를 설정하고 간단한 패턴으로 쿼리하는 것이 더 효율적이에요.
LangChain을 사용하여 여기서 논의된 검색기를 구현하려는 경우 Neo4j 벡터 구현을 참고하면 돼요. 여기서는 Neo4j 기반 검색기에 대한 Python 프로젝트 설정을 다루지는 않을 거예요. 다른 곳에서 잘 문서화되어 있거든요 (예: Neo4j GraphAcademy: Python을 사용하여 Neo4j 지원 챗봇 구축).
대신 우리는 흥미로운 부분에 초점을 맞출 거예요: 검색_쿼리 인수를 통해 논의할 GraphRAG 패턴을 구현하는 거죠. 각 패턴의 세부 정보에는 해당 쿼리가 포함될 거예요.
쿼리를 작성할 때 지정된 Node Label 및 속성에 대해 Vector Embedding 검색을 수행하는 보이지 않는 "첫 번째 부분"이 있다는 점을 기억하세요 (from_existing_graph 메서드의 node_label 및 embedding_node_property 매개 변수 참조). Neo4j 벡터 문서를 참고하면 좋아요. 이 첫 번째 부분은 발견된 Node와 해당 유사성 점수를 Node 및 점수로 반환해요. 그런 다음 이를 검색 쿼리에서 사용하여 추가 순회를 실행할 수 있죠. 질문 삽입을 위해 사용자 정의 매개변수와 $embedding 매개변수를 사용할 수도 있고요. 다음은 이것이 어떻게 보이는지에 대한 예시예요 (LangChain Neo4j 벡터 문서):
retrieval_query = """
RETURN "Name:" + node.name AS text, score, {foo:"bar"} AS metadata
"""
retrieval_example = Neo4jVector.from_existing_index(
OpenAIEmbeddings(),
url=url,
username=username,
password=password,
index_name="person_index",
retrieval_query=retrieval_query,
)
retrieval_example.similarity_search("Foo", k=1)위의 예에서 Vector Embedding 유사성 검색은 사용자 입력 "Foo"를 사용하여 기존 인덱스 person_index에서 실행되며 이름, 점수 및 일부 메타데이터가 가장 적합한 Node(k=1)에 대해 반환돼요.
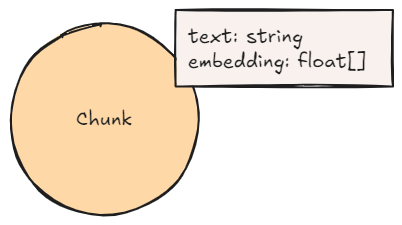
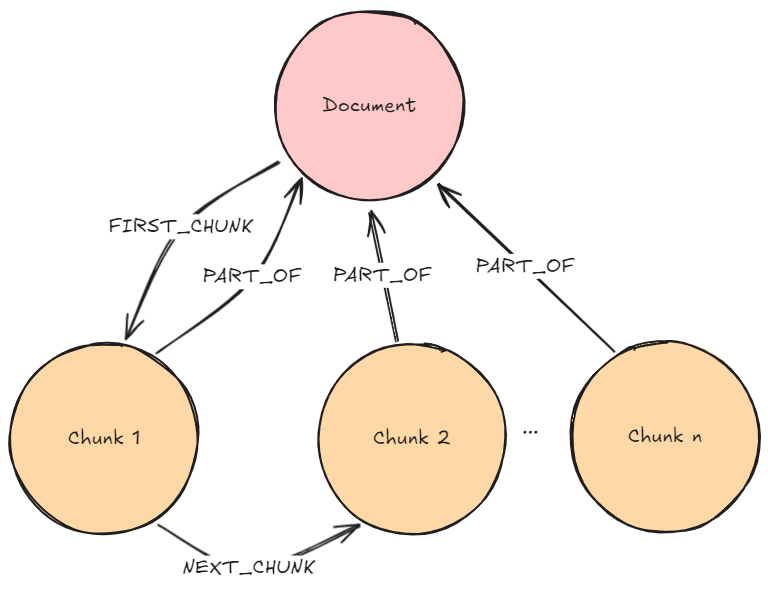
거의 모든 패턴의 그래프 패턴에는 청크 Node가 표시될 거예요. 이는 대부분의 GraphRAG 패턴의 기초이며 최소한 텍스트와 임베딩이라는 두 가지 속성을 가지고 있죠. 여기서 텍스트에는 사람이 읽을 수 있는 청크의 텍스트 문자열이 포함되고 임베딩에는 텍스트의 계산된 임베딩이 포함돼요.
이제 다양한 GraphRAG 패턴을 살펴볼게요.
기본 GraphRAG 패턴 — 어휘 그래프의 검색 패턴
아마 이전에 이런 RAG 패턴을 접해본 적 있을 거예요. 구조화되지 않은 데이터에 대한 RAG를 살펴볼 때 흔히 보이는 패턴이죠. 종종 Vector Database에 나타나는 이러한 패턴은 실제로 데이터 내의 관계에 의존한답니다.
기본 리트리버
이름: 기본 리트리버
다음으로도 알려져 있습니다. 나이브 리트리버, 베이스라인 RAG, 일반 RAG
문맥: 임베딩을 생성할 때 큰 문서를 작은 청크로 나누는 게 유용해요. 임베딩은 텍스트 내용의 의미를 포착하는 텍스트의 의미론적 표현이거든요. 주어진 텍스트가 길고 다양한 주제를 너무 많이 포함하면 임베딩의 정보 가치가 떨어지죠.
필수 전처리: 문서를 청크로 분할하고 임베딩 모델을 사용해서 청크의 텍스트 콘텐츠를 임베딩해요.
필수 그래프 패턴: 기본 어휘 그래프
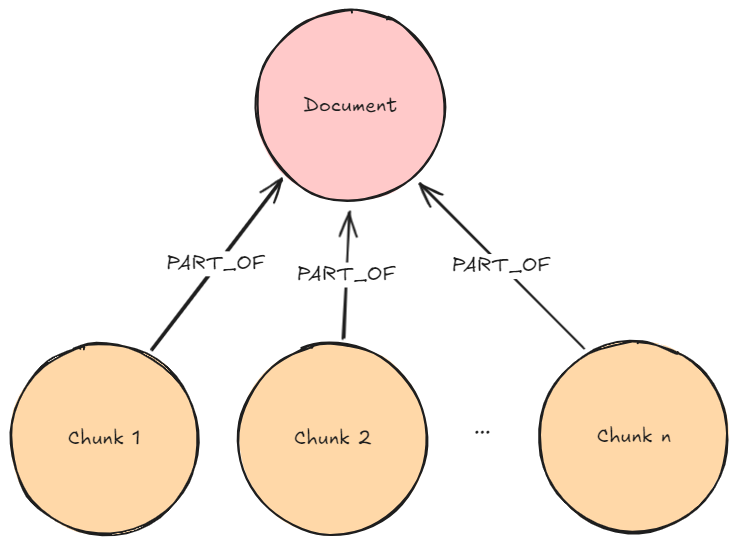
설명: 사용자 질문은 청크 임베딩을 생성하기 위해 이전에 사용된 것과 동일한 임베더를 사용해서 임베딩돼요. Vector Similarity Search는 청크 임베딩에서 실행되어 검색됩니다. k (이전에 개발자/사용자가 구성한 번호) 가장 유사한 청크를요.
용법: 이 패턴은 사용자가 하나 이상의 (그러나 너무 많지는 않은) 청크에 존재하는 주제에 대한 특정 정보를 요청하는 경우 유용해요. 질문에는 전체 데이터 세트에 대한 복잡한 집계나 지식이 필요하지 않죠. 패턴에는 Vector Similarity Search만 포함되므로 이해하고 구현하고 시작하기가 쉬워요.
검색 Query: Neo4j Vector Searcher는 기본적으로 유사한 청크를 검색하므로 추가 Query가 필요하지 않아요.
자원: RAG를 개선하기 위한 고급 리트리버 기술, Neo4j를 사용하여 고급 RAG 전략 구현
GraphRAG 패턴 카탈로그: 기본 리트리버
기존 구현: LangChain 리트리버: 벡터 스토어 기반 리트리버, LangChain: Neo4jVector
구현 예: LangChain 템플릿: Neo4j Advanced RAG
부모-자식 리트리버
이름: 부모-자식 리트리버
다음으로도 알려져 있습니다. 상위 문서 검색자
문맥: 앞서 언급했듯이 임베딩은 텍스트의 의미론적 의미를 나타내요. 텍스트의 범위가 좁을수록 여러 주제에서 발생하는 노이즈가 적기 때문에 더 의미 있는 Vector 표현이 생성되죠. 하지만 LLM이 답변 생성을 위해 작은 정보만 수신하는 경우 정보에 컨텍스트가 누락될 수 있어요. 발견된 정보가 포함된 더 넓은 주변 텍스트를 검색하면 문제가 해결된답니다.
필수 전처리: 문서를 (더 큰) 청크로 분할합니다 () 그리고 이 청크를 더 작은 청크로 분할합니다 (). 임베딩 모델을 사용하여 하위 청크의 텍스트 콘텐츠를 임베딩해요. 상위 청크는 유사성 검색이 아닌 답변 생성에만 사용되므로 내장할 필요가 없어요.
필수 그래프 패턴: 상위-하위 어휘 그래프
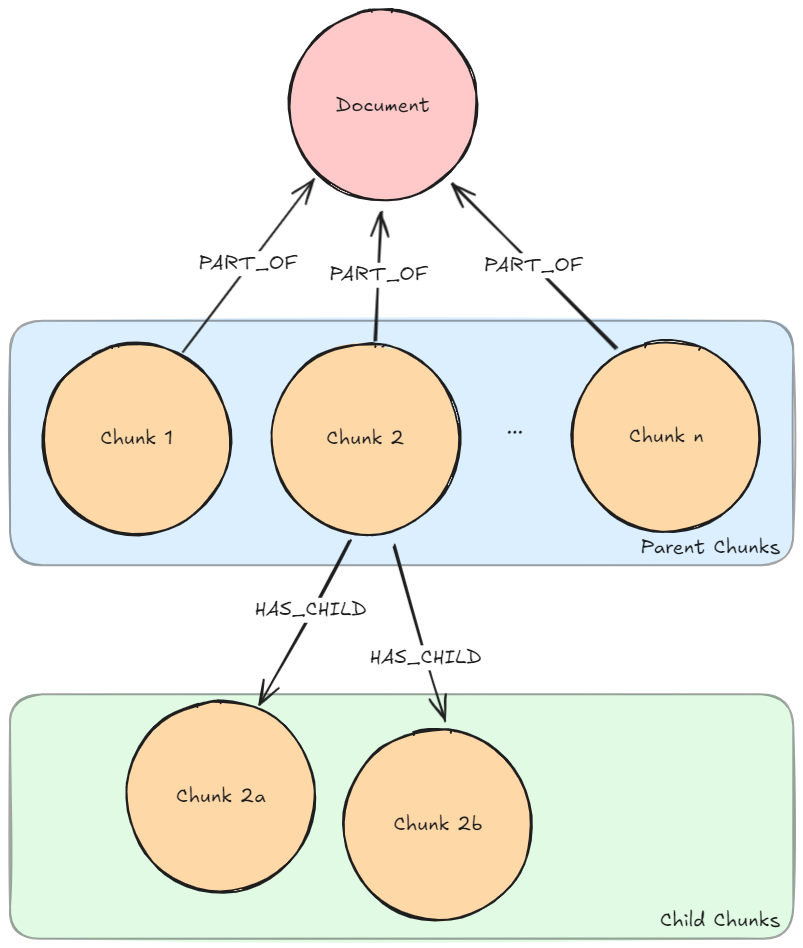
설명: 사용자 질문은 청크의 Vector Embedding을 생성하는 데 사용된 것과 동일한 임베더를 사용해서 임베딩돼요. 벡터 유사성 검색은 하위 청크 임베딩에 대해 실행되어서 k (개발자/사용자가 이전에 구성한 숫자)개의 가장 유사한 청크를 찾죠. 발견된 하위 청크의 상위 청크를 검색하는 방식이에요.
용법: 이 패턴은 기본 리트리버의 유용한 발전된 형태라고 할 수 있어요. 여러 주제가 하나의 청크로 다뤄져서 임베딩 품질에 부정적인 영향을 미칠 때 특히 유용하죠. 작은 청크는 더 의미 있는 벡터 표현을 가지게 되어서 더 나은 유사성 검색 결과를 얻을 수 있게 돼요. 제한된 추가 노력으로 더 나은 결과를 얻을 수 있다니, 정말 흥미롭죠?
검색 쿼리:
retrieval_query = """
MATCH (node)<-[:HAS_CHILD]-(parent)
WITH parent, max(score) AS score // deduplicate parents
RETURN parent.text AS text, score, {} AS metadata
"""자원: RAG를 개선하기 위한 고급 리트리버 기술, Neo4j를 사용하여 고급 RAG 전략 구현
GraphRAG 패턴 카탈로그: graphrag.com: 부모-자식 리트리버
기존 구현: LangChain 리트리버: 상위 문서 리트리버
구현 예: LangChain 템플릿: Neo4j Advanced RAG
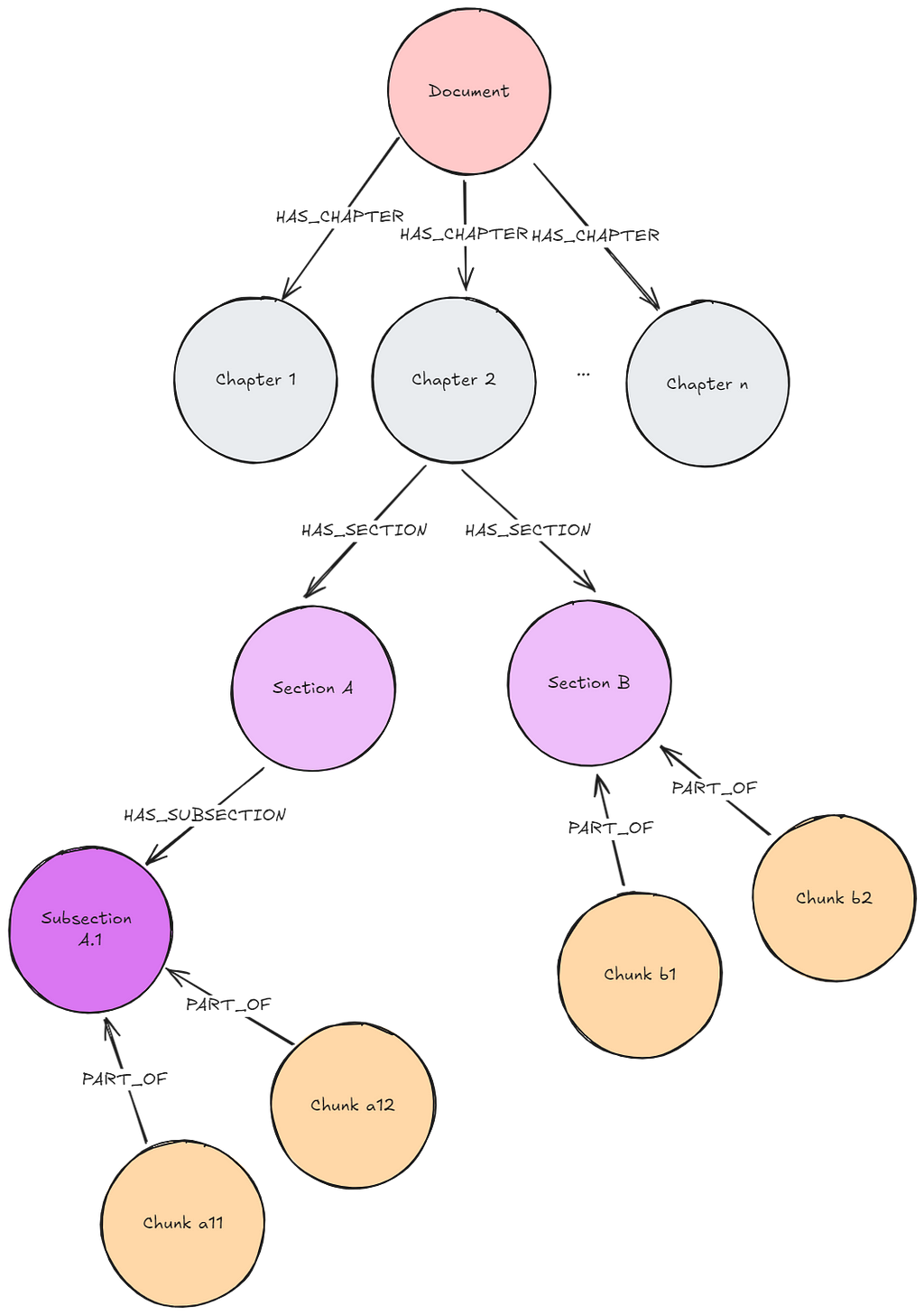
유사한 패턴을 다음에서도 구현할 수 있어요: 형제 구조를 갖는 어휘 그래프 또는 계층 구조의 어휘 그래프. 여기서 추가 컨텍스트는 상위 문서만 검색하는 것이 아니라 형제 문서 또는 이전에 설정된 구조 깊이를 검색하는 것에서 비롯되죠. 예를 들어, 형제 구조를 가진 어휘 그래프는 현재 Neo4j의 LLM Knowledge Graph 빌더에서 구현되고 있어요.
계층 구조를 가진 어휘 그래프에는 두 가지 종류의 검색기가 가능하다는 점에 유의해야 해요.
- : 리프 Node에서 검색을 실행하고 트리의 더 높은 위치에 있는 다른 청크를 검색해요 (참조: Going Meta 24회 — 그래프, 의미론, 지식에 관한 시리즈)
- : 최상위 Node를 사용해서 검색에 고려할 하위 트리를 결정해요. 유사성 검색을 위한 Node 집합이 합리적으로 좁아질 때까지 이 방법론을 반복하는 거죠 (참조: RAG 전략 — 계층적 Index 검색).
가상 질문 검색기
이름: 가상 질문 검색기
문맥: 질문의 임베딩과 적절한 답변 또는 텍스트 소스의 텍스트 임베딩 간의 벡터 유사성은 매우 낮을 수 있어요. 사용 가능한 질문-청크 쌍이 있는 경우 질문 임베딩에 대해 벡터 유사성 검색을 실행할 수 있고, 이는 아마도 원본 텍스트 청크에 대한 벡터 유사성 검색보다 훨씬 더 나은 결과를 제공할 거예요.
필수 전처리: LLM을 사용해서 청크 내에서 답변이 가능한 가상 질문을 생성하세요. 임베딩 모델을 사용해서 질문을 임베드하고요. 질문과 답변이 포함된 덩어리 사이의 Relationship을 기록해야 해요.
필수 그래프 패턴: 가상 질문이 포함된 어휘 그래프
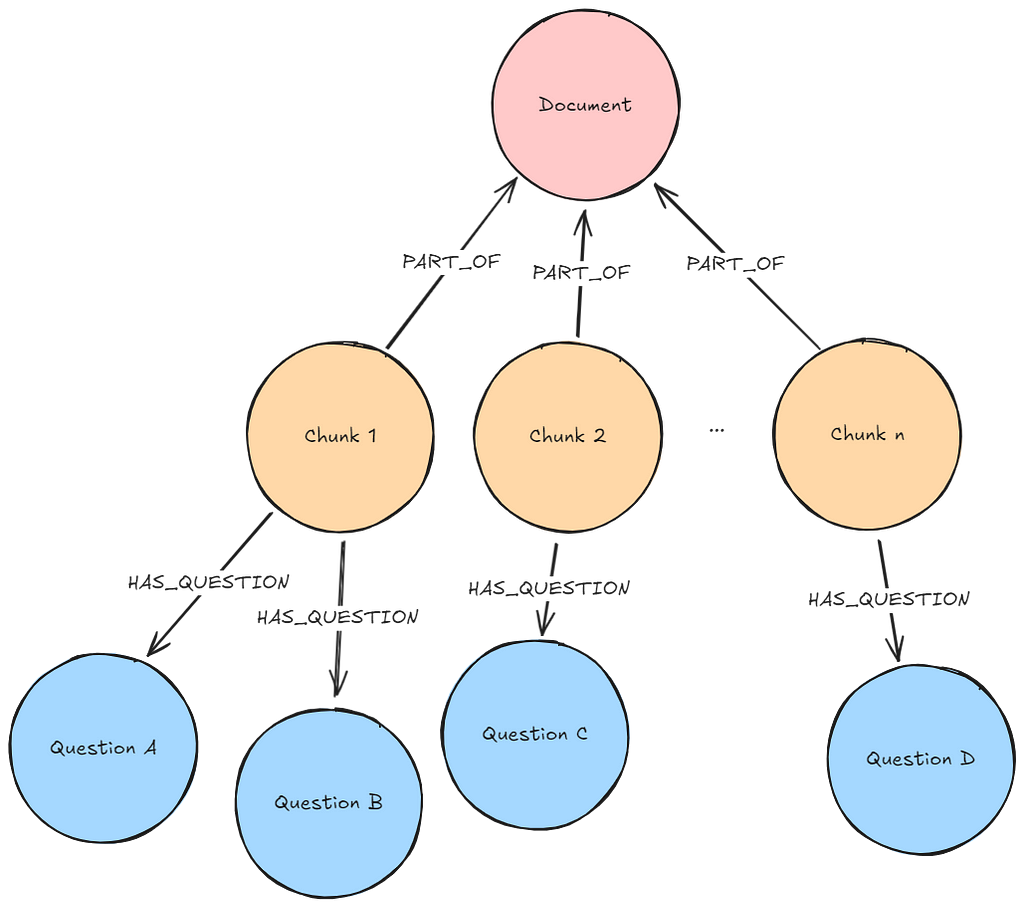
설명: 사용자 질문은 질문 임베딩을 생성하는 데 사용된 것과 동일한 임베더를 사용하여 임베드돼요. 벡터 유사성 검색은 이전에 생성된 질문에 대해 실행되죠. k(개발자/사용자가 미리 구성한 번호) 가장 유사한 질문을 찾아 관련 청크를 검색하는 거예요.
용법: 이 패턴은 위의 패턴에 추가된 패턴이에요. 벡터 유사성 검색에서 더 나은 결과를 얻을 수 있죠. 하지만 질문 생성을 위한 LLM 요청에는 더 많은 사전 처리 노력과 비용이 필요해요.
검색 쿼리:
retrieval_query = """
MATCH (node)<-[:HAS_QUESTION]-(chunk)
WITH chunk, max(score) AS score // deduplicate chunks
RETURN chunk.text AS text, score, {} AS metadata
"""가설 질문 검색기는 HyDE(가설 문서 삽입) 검색기와 매우 유사해요 (참조: LangChain을 사용한 RAG: 5부 — 가설 문서 임베딩). 그 뒤에 있는 주요 아이디어는 사용자 질문과 사용 가능한 텍스트 간의 유사성을 높이는 것이죠. 가설 질문 검색기에서는 사용자 질문과 일치하는 가설 질문을 생성해요. HyDE 검색기에서 LLM은 기본 데이터베이스를 사용하지 않고 사용자 질문에 대한 가상 답변을 생성한 다음 가상 답변을 데이터베이스의 실제 청크와 일치시켜 가장 적합한 것을 찾아요. HyDE 검색기는 검색 단계가 아닌 RAG 전처리 단계에 있고 특정 유형의 기본 그래프 패턴이 필요하지 않기 때문에 더 자세히 살펴보지 않을 거예요.
중급 GraphRAG 패턴 — 도메인 그래프의 검색 패턴
도메인 그래프에는 비즈니스 도메인 지식이 포함되어 있어요. 여기에는 엔터티와 엔터티 간의 관계가 포함되죠. 자주 사용되는 예제 도메인 그래프는 다음과 같아요: 무비 그래프 또는 북풍 그래프.
도메인 그래프는 기본 도메인에 따라 다르게 보이기 때문에 모양에 대한 청사진을 제공하는 것은 불가능해요. 여기에는 스키마를 준수하는 구조화된 데이터가 포함되어 있다는 점에 유의하세요.
Natural Language 쿼리가 (결정적) 구조화된 데이터 검색으로 이어지는 질문-답변 애플리케이션 내에서 도메인 그래프에 포함된 정보를 제공하는 것은 여러 가지 방법으로 실행될 수 있어요.
Cypher 템플릿
이름: Cypher 템플릿
문맥: 구조화된 데이터를 검색하려면 사용자 질문을 데이터베이스에서 실행할 수 있는 쿼리로 변환해야 해요. 기본적인 접근 방식은 사용자 질문을 매핑할 수 있도록 도메인 전문가가 작성한 사전 정의된 쿼리를 갖는 것이죠.
필수 전처리: 여러 도메인별 Cypher 쿼리(매개변수 포함)와 해당 쿼리에 대한 설명이 LLM에 제공돼요.
필수 그래프 패턴: 도메인 그래프
설명: 사용자 질문이 주어지면 LLM은 사용할 Cypher 템플릿을 결정해요. LLM은 사용자 질문에서 매개변수를 추출하여 템플릿에 연결할 수 있죠. 쿼리는 데이터베이스에 대해 실행되고 결과는 답변을 생성하기 위해 LLM에 다시 제공돼요.
용법: 사용자가 도메인 그래프에 제기할 질문 유형이 이전에 알려진 경우 템플릿을 만들 수 있어요. 이 접근 방식의 단점은 주어진 템플릿 쿼리에 대한 제한이에요. 사용자가 템플릿에 존재하지 않는 쿼리를 초래하는 질문을 하면 어떻게 될까요?
자원: 의미 계층을 통해 언어 모델과 그래프 데이터베이스 간의 상호 작용 향상
GraphRAG 패턴 카탈로그:graphrag.com: 사이퍼 템플릿
동적 Cypher 생성
이름: Dynamic Cypher Generation
문맥: 구조화된 데이터에 대한 사용자 질문은 다양한 필터를 포함할 수 있는데, 항상 똑같은 필터가 사용되진 않아요. 예를 들어, 동영상 그래프를 생각해 볼까요? 이런 질문들이 있을 수 있겠죠.
– 스티븐 스필버그가 감독한 영화는 무엇인가요?
– 스티븐 스필버그가 2000년부터 2010년까지 감독한 영화는 무엇인가?
– 스티븐 스필버그가 2000년에서 2010년 사이에 감독한 영화는 무엇입니까?
이런 질문 목록은 끝없이 이어질 수 있어요. 이 모든 질문에 대해 Cypher 템플릿을 만들고 싶진 않을 거예요. 해결책은 사용자 질문에 실제로 주어진 파라미터를 기반으로 Cypher 쿼리를 (부분적으로) 동적으로 생성하는 거죠.
필수 전처리: 파라미터화된 Cypher 쿼리의 조각과 해당 쿼리가 수행하는 작업에 대한 설명을 LLM에 제공해야 해요.
필수 그래프 패턴: 도메인 그래프
설명: 사용자 질문이 주어지면 LLM은 사용할 스니펫을 결정해요. LLM은 사용자 질문에서 파라미터를 추출하고 이를 스니펫에 연결한 다음, 결합해서 전체 쿼리를 생성하죠. 쿼리는 데이터베이스에 대해 실행되고, 결과는 답변을 생성하기 위해 LLM에 다시 제공돼요.
용법: 이 패턴은 Cypher 템플릿에서 한 단계 더 나아간 유용한 발전이에요. 훨씬 더 유연해져서 더 다양한 사용자 질문에 대한 답변을 얻을 수 있죠. 하지만 제공된 스니펫은 질문의 범위를 제한한다는 점을 기억해야 해요.
자원: Llama 3.1, NVIDIA NIM 및 LangChain을 사용하여 Knowledge Graph 기반 에이전트 구축
GraphRAG 패턴 카탈로그: graphrag.com: Dynamic Cypher Generation
Text2Cypher
이름: Text2Cypher
문맥: GraphRAG 패턴인 Cypher 템플릿과 Dynamic Cypher Generation은 구현 중에 정의된 쿼리 및 쿼리 조각에 의해 제한될 수 있어요.
필수 전처리: LLM은 도메인 설명과 함께 데이터베이스 스키마를 얻어야 해요. 이렇게 하면 결과가 훨씬 좋아지죠. 질문에서 쿼리로의 값 변환을 개선하기 위해 선택적으로 실제 데이터 값 샘플, 분포 또는 범주형 값 목록을 통해 스키마를 향상시킬 수도 있어요.
필수 그래프 패턴: 도메인 그래프
설명: 사용자 질문은 LLM에 의해 Cypher 쿼리로 변환돼요. 쿼리는 데이터베이스에 대해 실행되고, 결과는 답변을 생성하기 위해 LLM에 다시 제공되죠.
용법: 이 패턴은 정말 유연해요. 미리 정의된 쿼리가 없어서 이론적으로 LLM은 모든 쿼리를 생성할 수 있죠. 하지만 100% 신뢰할 수는 없어요. LLM은 텍스트를 Cypher로 번역할 때 완벽하지 않거든요. LLM이 주어진 사용자 쿼리를 올바르게 번역할 수 없다면 어떤 답변도 제공할 수 없어요.
자원: Neo4j를 LangChain 생태계에 통합, LangChain Cypher Search: 팁과 요령
GraphRAG 패턴 카탈로그: graphrag.com: Text2Cypher
기존 구현: LangChain: GraphCypherQAChain
Cypher Templates, Dynamic Cypher Generation, 그리고 Text2Cypher를 비교하면 다음과 같은 비유를 사용할 수 있어요 (아래 이미지 참고).
- Cypher Templates는 하나의 조각으로 구성된 서로 다른 유사한 장난감을 갖는 것과 같아요. 자유도가 별로 없죠.
- Dynamic Cypher Generation은 벽돌을 쌓는 것과 같아요. 조합하는 방법은 더 자유로워졌지만, 여전히 실패할 염려가 있죠.
- Text2Cypher는 그림과 같아요. 자유도는 높지만 쉽게 실패할 수도 있어요.

위 패턴들에도 똑같은 문제가 발생할 수 있어요. 즉, 사용자 질문에서 엔터티를 추출할 때 엔터티 별칭이 데이터베이스의 기존 값과 일치해야 한다는 거죠. 그렇지 않으면 쿼리가 결과를 반환하지 못할 거예요. 향상된 스키마를 제공하거나, 다음과 같이 데이터베이스에서 전체 텍스트 인덱스 검색을 사용해서 이 문제를 완화할 수 있어요: LangChain 템플릿: Neo4j Advanced RAG(Neo4j Cypher FT).
Text2Cypher 패턴은 가장 유연하지만, 가장 신뢰하기 어려울 수 있어요. 하지만 신뢰성을 향상시키기 위한 많은 연구가 진행되고 있답니다. 접근 방식은 다음과 같아요.
- 자연어에서 Cypher 번역으로의 LLM Fine-tuning (예: Text2Cypher에서 Llama3 Fine-tuning)
- Few-shot 예제 사용 최적화 (예: Neo4j Live: 상황별 학습 및 Fine-tuning으로 text2cypher 향상 또는 몇 번의 예시에서 암시적 추론을 통해 다중 홉 질문 응답을 위한 LLM 기반 KGQA 개선)
- 자가 치유 생성 - 생성된 쿼리가 데이터베이스에서 실행될 수 없는 경우, 더 나은 쿼리를 생성할 수 있는 또 다른 기회를 얻는 LLM에 획득된 예외 메시지와 함께 쿼리를 반환합니다 (예: 모든 그래프 스키마에서 ChatGPT 4를 사용하여 Cypher 쿼리 생성)
언어 모델의 선택은 결과에 큰 영향을 미쳐요. 모든 언어 모델은 저마다 강점과 약점이 있거든요. 이 주제에 대해서는 강연 중에 더 자세히 이야기할 예정이에요 (LLM 쿼리 벤치마크: Cypher와 SQL). 올해 NODES 회의는 Knowledge Graph와 관련된 모든 것을 다루는 24시간 무료 온라인 이벤트랍니다.
고급 GraphRAG 패턴 — 어휘 그래프와 도메인 그래프가 결합된 검색 패턴
어휘 그래프와 도메인 그래프를 함께 사용하는 시나리오는 정말 많아요. 예를 들어, 이미 도메인 그래프가 있는데 구조화되지 않은 문서를 추가해서 더 풍부하게 만들 수도 있고, 반대로 구조화되지 않은 문서만 가지고 있는데 여기서 엔터티를 추출해서 도메인 그래프를 만들 수도 있죠. Vector Search에 텍스트 속성을 사용하는 경우도 있고요. 이런 모든 시나리오에서 추가적인 GraphRAG 검색 패턴을 활용해서 검색 결과를 훨씬 더 좋게 만들 수 있답니다.
그래프 강화 Vector Search
이름: 그래프 강화 Vector Search
다음으로도 알려져 있습니다. 그래프 + 벡터, 증강 Vector Search
문맥: 기본적인 GraphRAG 패턴의 가장 큰 문제점은 질문에 필요한 모든 관련 맥락을 찾는 건데요. 이 맥락이 여러 조각으로 흩어져 있어서 검색으로 찾기 어려울 수 있어요. 하지만 각 조각에 있는 실제 엔터티들을 서로 연결하고, Vector Search를 통해 이 관계들을 찾아낸다면, 그 조각들이 참조하는 엔터티에 대한 추가적인 맥락을 얻을 수 있죠. 엔터티 네트워크를 이용해서 조각들을 서로 연결하는 방법도 있답니다.
필수 전처리: LLM을 사용해서 각 조각에서 엔터티와 관계를 추출해야 해요. 그리고 추출된 트리플을 그래프로 가져와야 하죠.
필수 그래프 패턴: 추출된 항목이 포함된 어휘 그래프
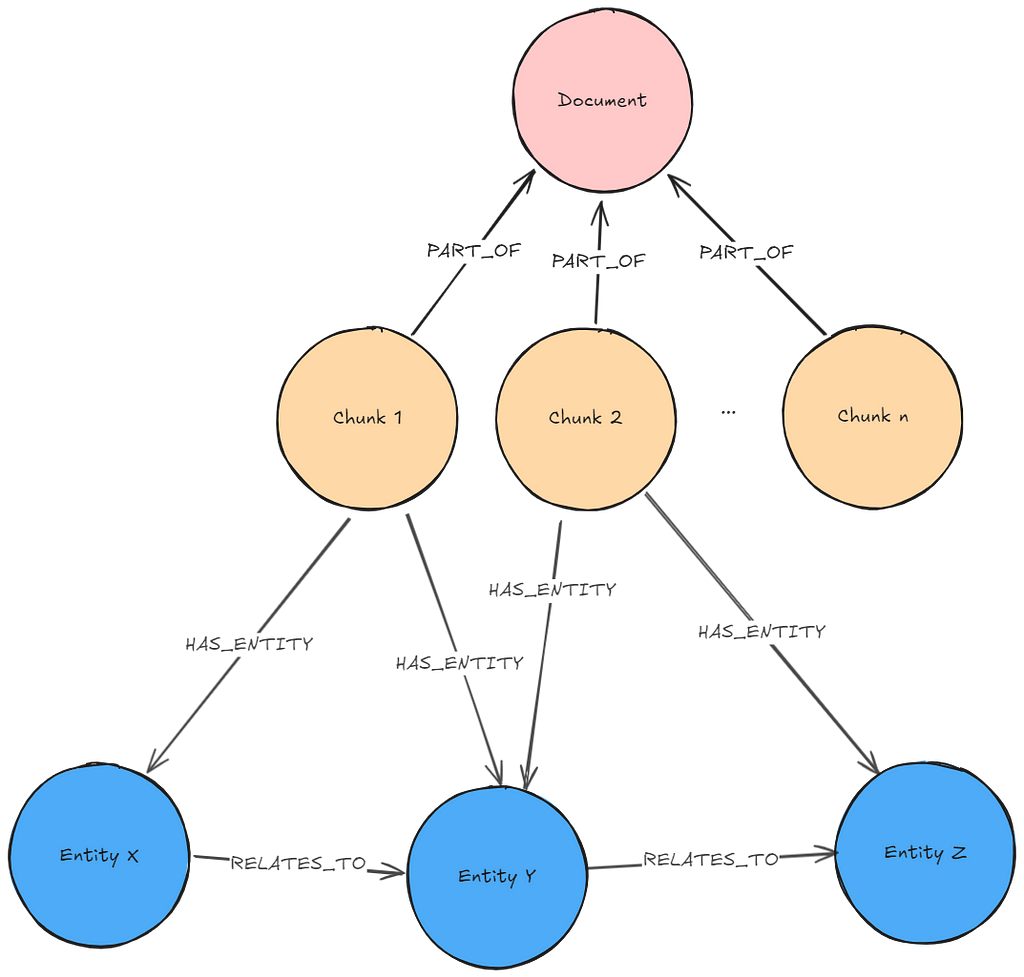
설명: 사용자 질문은 청크 임베딩을 생성하는 데 사용된 것과 동일한 임베더를 사용해서 임베딩돼요. Vector 유사성 검색은 청크 임베딩에서 실행되어서, 가장 유사한 k (개발자/사용자가 미리 설정한 숫자)개의 청크를 찾습니다. 그리고 발견된 청크에서 시작하는 도메인 그래프 순회가 실행되어서 더 많은 맥락을 검색하죠.
용법: 이 패턴은 Vector Search만 실행했을 때보다 훨씬 풍부한 맥락을 검색하는 데 유용해요. 추가적인 순회를 통해 제공된 데이터 내에서 엔터티들의 상호 작용을 찾을 수 있거든요. 특정 텍스트 청크를 검색하는 것보다 훨씬 많은 정보를 얻을 수 있고, 결과적으로 답변 생성을 위한 더 좋은 품질의 입력을 제공할 수 있어요. 물론 이 GraphRAG 패턴을 사용하려면 전처리 과정에 더 많은 노력과 비용(시간과 돈 모두!)이 들겠죠. 게다가 그래프 순회에서 반환되는 정보의 양이 LLM이 처리해야 하는 맥락의 크기를 상당히 늘릴 수도 있다는 점도 기억해야 해요.
검색 쿼리:
retrieval_query = """
MATCH (node)-[:PART_OF]->(d:Document)
CALL { WITH node
MATCH (node)-[:__HAS_ENTITY__]->(e)
MATCH path=(e)(()-[rels:!HAS_ENTITY&!PART_OF]-()){0,2}(:!Chunk&!Document)
…
RETURN …}
RETURN …
"""이 검색기에는 몇 가지 변형이 있답니다.
- 엔터티 명확성(Entity Resolution) — 단순한 엔터티 추출 파이프라인은 텍스트에서 모든 엔터티를 가져오죠. 하지만 여러 엔터티는 텍스트에서 다르게 언급될 수 있지만, 실제로는 같은 엔터티를 의미할 수 있어요. **Knowledge Graph**를 깔끔하게 유지하려면, 이런 엔터티들을 병합하는 엔터티 명확화 단계를 거쳐야 해요. 자세한 방법은 다음 링크에서 확인할 수 있습니다. Neo4j 및 LangChain을 사용하여 '로컬에서 글로벌로' GraphRAG 구현: 그래프 구성 그리고 LlamaIndex에서 Relik을 사용한 엔터티 연결 및 관계 추출를 참고하세요.
- 질문 안내/스키마 정의 추출(Question Guiding/Schema Definition Extraction) — **Large Language Model(LLM)**이 모든 종류의 엔터티와 관계를 추출하도록 하는 대신, 애플리케이션과 관련된 도메인 지식만 추출하도록 안내하는 질문이나 고정된 **스키마**를 제공하는 거예요. 이렇게 하면 추출 범위와 양을 좁힐 수 있죠. 예를 들어, WhyHow.AI 오픈 소스 **Knowledge Graph** 스키마 라이브러리 소개 — 더 빠르게 실험 시작을 참고해보세요.
- 엔터티 임베딩(Entity Embedding) — **LLM**을 사용해서 엔터티와 관계를 추출할 때, **LLM**에게 엔터티와 관계에 대한 설명도 생성/추출하도록 지시할 수 있어요. 이렇게 추출된 설명은 **Vector Embedding**으로 저장해서, 나중에 탐색 과정에서 초기 **벡터 검색**이나 다른 지침으로 활용할 수 있답니다.
- 온톨로지 기반 순회(Ontology-Based Traversal) — 순회를 애플리케이션 코드에 하드 코딩하는 대신, 순회에 대한 온톨로지를 제공할 수 있어요. 이 접근 방식은 메타로의 전환— Ep 24: KG+LLM: 온톨로지 기반 RAG 패턴에서 자세히 설명되어 있습니다.
글로벌 커뮤니티 요약 검색기
이름: 글로벌 커뮤니티 요약 검색기
다음으로도 알려져 있습니다: Microsoft GraphRAG, 글로벌 리트리버
맥락: 전체 데이터 세트에 대해 질문할 때, 특정 질문은 일부 덩어리에만 존재하는 내용과 관련되는 것이 아니라, 데이터 세트에서 가장 중요한 전체 메시지를 검색해야 할 때가 있어요. 앞서 언급한 패턴들은 이런 종류의 "글로벌" 질문에 답하는 데 적합하지 않죠.
필수 전처리: 엔터티와 해당 관계를 추출하는 것 외에도, 도메인 그래프 내에 계층적 커뮤니티를 형성해야 해요. 이는 Leiden 알고리즘을 사용해서 할 수 있죠. 모든 커뮤니티에 대해 **LLM**은 엔터티 및 관계 정보를 커뮤니티 요약으로 요약합니다.
필수 그래프 패턴: 추출된 엔터티 및 커뮤니티 요약이 포함된 어휘 그래프
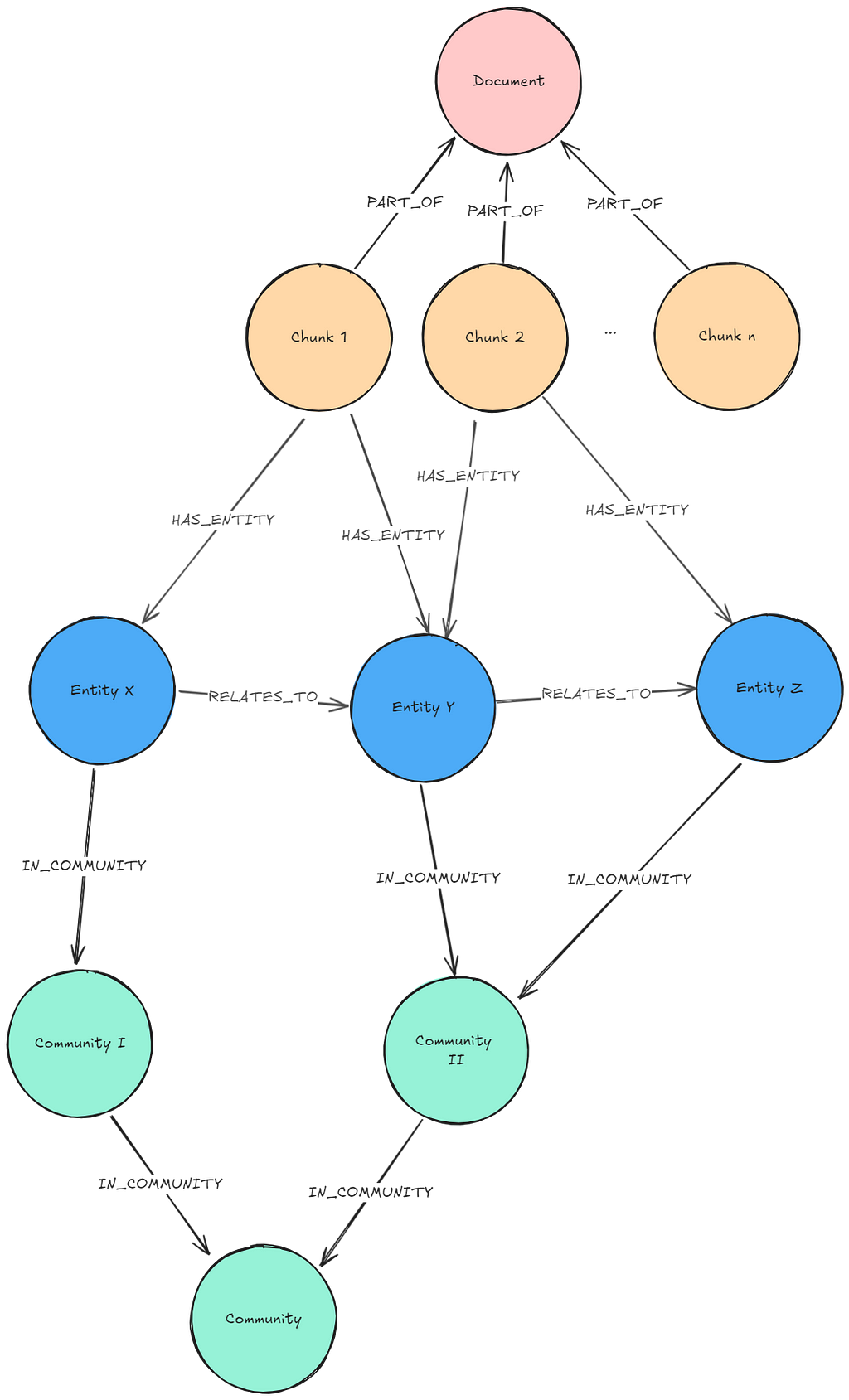
설명: 사용자 질문과 특정 커뮤니티 레벨이 주어지면, 커뮤니티 요약이 검색되어 **LLM**에 제공됩니다.
용법: 이 패턴은 전역적인 성격을 갖는 질문에 유용해요. 예를 들어 전체 데이터베이스의 내용을 요약하거나, 전체 데이터에서 주제 구조를 찾는 것과 같은 경우죠. 엔터티 및 관계 추출, 커뮤니티 감지, 커뮤니티 요약 등 수행해야 할 단계가 많기 때문에, 필요한 그래프 패턴을 설정하는 데 노력이 많이 들어요. 이러한 작업 중 **LLM**이 실행해야 하는 작업과 전처리 비용을 허용 가능한 수준으로 유지하기 위해 다르게 처리할 수 있는 작업은 무엇인지 고려해야 합니다.
검색 쿼리: 이 접근 방식은 유사한 **벡터** **노드**를 가져오기 위해 Neo4j **Vector**를 사용하지 않아요. 특정 레벨의 모든 커뮤니티 요약을 가져옵니다. 다음은 **쿼리**의 예시입니다.
community_summaries = """
MATCH (c:__Community__)
WHERE c.level = $level
RETURN c.full_content AS output
"""자원: 로컬에서 글로벌로: 쿼리 중심 요약에 대한 그래프 RAG 접근 방식, Neo4j 및 LangChain을 사용하여 '로컬에서 글로벌로' GraphRAG 구현: 그래프 구성, Microsoft GraphRAG를 Neo4j에 통합
GraphRAG 패턴 카탈로그: graphrag.com: 글로벌 커뮤니티 요약 검색기
구현 예: 마이크로소프트 그래프RAG
추출된 엔터티, 커뮤니티 및 커뮤니티 요약과 함께 어휘 그래프를 사용할 수 있는 몇 가지 변형이 있어요.
- 질문에 따라 먼저 커뮤니티 요약의 임베딩에 대한 벡터 유사성 검색을 실행해서 질문과 관련된 하위 그래프를 식별한 다음 커뮤니티에서 엔터티 및 청크로 순회하여 정보를 검색할 수도 있죠.
요약
다양한 GraphRAG 패턴을 탐색해봤는데요, 이건 정말 흥미로운 여정의 시작일 뿐이에요. 현재 목록은 GraphRAG 진화의 초기 단계를 보여주고 있죠. 앞으로 나아가면서 새로운 패턴들이 나타나 신선한 통찰력과 가능성을 가져올 거라고 생각해요.
각 RAG 패턴은 특정 유형의 질문에 답하도록 맞춰져 있고, 고유한 그래프 패턴과 전처리 단계가 필요해요. 애플리케이션에 맞는 완벽한 GraphRAG 패턴을 찾는 건 쉽지 않죠. 다양한 검색 패턴을 실험하고 결과를 적절하게 평가해야 해요. 하나의 단일 패턴이 모든 목적에 적합하지 않을 가능성이 매우 높고, 이는 다양한 쿼리에 적응하는 에이전트적 접근 방식이 거의 항상 필요한 이유이기도 해요. 여기에 제시된 패턴은 사용자 질문에 대한 답변에 대한 컨텍스트가 제공되는 모든 대상 전략이며 데이터베이스를 한 번만 쿼리해요. 더 복잡한 질문에는 또는 패러다임(참조: 그래프 검색-증강 생성: 설문 조사 검색 패러다임에 대한 자세한 내용은 참조)이 필요할 수 있고, 다양한 패턴의 사용을 결합할 수도 있겠죠.
이상적인 GraphRAG 패턴을 발견하기 위한 여정은 시행착오와 혁신으로 가득 찬 흥미진진한 여정이에요. 이 여행을 함께 시작해봐요! 오픈소스 GraphRAG 패턴 카탈로그를 확인하고 기여해주세요. 아직 나열되지 않은 다른 패턴이 있나요? 피드백이나 제안 사항이 있거나 애플리케이션을 공유하고 싶다면 언제든지 이슈를 열어주세요. GraphRAG 패턴에 대해 토론하고 싶다면 GraphRAG Discord 채널을 방문해주세요.
호기심을 갖고 계속 실험해보세요. 다음에 어떤 획기적인 패턴을 발견하게 될지 누가 알겠어요!
필수 GraphRAG
지식 그래프를 통해 RAG의 잠재력을 최대한 활용하세요. 한정된 기간 동안 Manning으로부터 최종 가이드를 무료로 받아보세요.
- GraphRAG
- RAG
에이치시스템즈의 LogTree는 Neo4j 기반 GraphRAG 플랫폼으로, 데이터를 자동으로 지식그래프화하고 자연어 질의로 즉시 답을 제공합니다.
'GraphRAG' 카테고리의 다른 글
| GraphRAG 실전 활용: 고객 파악 조사를 위한 간단한 Agent 구축 (0) | 2026.05.13 |
|---|---|
| Neo4j, GenAI를 위한 GraphRAG 기능을 Google Cloud에 탑재 (0) | 2026.05.12 |
| GraphRAG 시작하기: Neo4j 생태계 도구 활용법 (0) | 2026.05.11 |
| GraphRAG: 카드 게임으로 즐기는 그래프 RAG! (0) | 2026.05.11 |
| GraphRAG와 에이전트 아키텍처: Neo4j 및 NeoConverse를 활용한 실전 실험 (0) | 2026.05.11 |